TLVC Developer Notes
A collection of experiences, document references, system/hardware peculiarities and more gathered while developing TLVC.
When IDE - Integrated Drive Electronics - appeared about the same time as the PC/AT (1986), it was a great blessing. An incredible step forward, a great simplification of something that had been very complicated, costly and incompatible. From a technical perspective the evolution is obvious: Moving the interface to the drive itself and creating a simple protocol for the host to interact with the drive was a logical step and a simplification for both drive manufacturers and their customers - the system (PC) builders. An innovation that literally changed the (technical) world and accelerated the proliferation of PCs into every corner of our everyday life.
Fast forward to today, ATA - which IDE was renamed to around 1990 - still exists although in vastly different forms and formats, for obvious reasons. The stretch from the mid 80s and its 20, 40 and 130 MB drives with parallel interfaces to the Serial ATA (aka 'S-ATA') 12TB drives and 2TB SSDs of present day is unfathomable. The original (parallel) ATA interface was replaced by Serial ATA in the early 2000s and the original was renamed PATA.
IDE moved the physical stuff - the characteristics of the drive - away from the PC and turned the drive into a storage device that stored - read and wrote - data blocks. Technically but not practically - and this is where the complications start. IDE had to deal with history and history was CHSW - cylinders, heads and sectors – and WPCOM, write pre-compensation parameters (we'll get to that).
So even if it was possible, having a block addressable storage device was something the market was ready to embrace. The PC BIOSes of the day had tables containing drive types with physical parameters (CHSW) for each drive. The actual drive type(s) - a simple number referencing an entry in the 'type table' - were stored in the so-called CMOS chip (which wasn't CMOS but that's a different story) along with the real time clock data and a few other settings. So when the PC booted, it pulled the boot drive type from CMOS, looked up the CHSW values from the table and used those to properly access the drive.
You probably knew all this, but I'm repeating because it is relevant for the discussion below.
So, even though the PC could just query the IDE drive for its CHS data, most of them did not (until many years later) because of history - and an attempt to be backwards compatible.
Even back then, drives changed rapidly - increased capacity, speed, smaller physical formats etc. Also, drives with the same capacity from different manufactures had different physical (CHS) data, while the BIOSes with their drive tables did not change (and were not field-upgradeable). IDE fixed that too. Even the earliest drives could be programmed to show and (appear to) use CHS values different from the physical ones. Good - except it made the physical values that could be read off the IDE interface less useful - some times even confusing.
So - as simple as it may seem, even back then IDE was not a walk in the park. Eventually, new BIOSes got their own configuration interfaces which among many other things made available user defined drive types. That helped a lot, but not when we're trying to revive old clunkers with old drives and old BIOSes - or even new drives and old BIOSes. Here are some of the challenges we run into:
- In order to get access to the data on the drive (and/or share the drive among several OSes), you need to know the drive type - the CHS values used when the volumes/file systems were created.
- That access is particularly important for booting: When booting, the BIOS startup code reads the first sector off the boot drive - a location indifferent to any CHS configuration. The boot code from that first sector looks at the partition table (if it exists), and determines where to get the secondary boot code, located at the beginning of the currently active partition. The partition table uses CHS values to specify the start and end of each partition. Obviously, a mismatch between the CHS data used by the BIOS and those used when creating the partition table will cause a boot failure. Correction: If the HS (head/sector) data are wrong, boot will fail. The number of cylinders don't matter (and most BIOSes don't care if you access a cylinder beyond what's specified on the BIOS drive table).
- This indifference to cylinder count provides some flexibility: If you have a drive that doesn't match any of the entries in the BIOS drive-type list, find an entry in which the number of heads and sectors match, and booting will work fine. After that, the OS is in control and provides access to the entire drive. This even works for MS-DOS and (old) Windows although the numbers and/or capacities reported by some utilities will be confusing.
In acceptance of this practice, the second generation IDE specification (aka ATA 1.0) provided for two sets of CHS data for the drive – stored in the drive's ID block: Physical, located at the beginning of the block, and actual, stored further down (the original IDE used only the first 24 bytes of the 512 byte ID data block, ATA-1 used 128 bytes, some vendors even more). In many cases the two are the same. Which one to use is determined by bit 0 of ID word 53. If set, use the actual data, if not use the physical data. Old drives (which don't have the actual data in the ID segment) require the SPECIFY command to be used at boot/initialization time to set the CHS values - or they will default to some value you most likely don't want. With newer drives, the SPECIFY command is optional. Most drives will make the smart choice.
Unrelated to the CHS data, drives of different generations support different command sets. Newer and more advanced commands are tempting since they may increase functionality or speed or both, but at the driver level care must obviously be taken to maintain backwards compatibility. Not complicated but requires extra code which takes extra space, so it must be evaluated whether it's worth it. Also it's worth noting that old drives are slow and sensitive to heavy polling. Polling a status register at processor speed may not work (hangs) because the polling interrupts the drive which never gets around to change some status. So wait loops which do something in between every poll are important. A reminder that the old drives would benefit from using interrupts at command completion, not just polling. (See also the section on multisector IO below).
In addition to CHS, early drives needed 'write precompensation' (WPCOMP) to be specified. A single, non-varying number telling the drive at which cylinder extra (timing) compensation should be applied to handle the increased data density as the sectors get physically shorter towards the center of the drive. The BIOS' drive table has correct values for each drive type, but it seems like most (maybe all except possibly RLL drives) are fine with a 0xff value. In fact, since the number of cylinders can be indirectly programmed (by changing the Head/Sector values), it's unclear what the WPCOM cylinder actually is.
Anyway, to the problem at hand: Compaq Portable III 286/12.5MHz with Conner 42MB drive:
- The drive reports CHS 806/4/26 (physical)
- The BIOS says drive type 17, CHS 980/5/17 ('logical' or 'actual')
- For curiosity: When the image is mounted on QEMU, it uses 1223/4/17.
- Accessing the drive using the physical CHS values works fine and provides access to the entire drive capacity. BUT - for every 0x5500 sectors, 0x50 sectors are 'inserted' - most likely read off the drive, but these are sectors invisible when the other (BIOS) CHS setting is used.
- So while the physical CHS values deliver slightly more capacity than the 'actual', it cannot be used if we want 'old data' available and compatibility (with other OSes).
The question is - how to tell TLVC the actual (or 'preferred' if you like) CHS values when they're different from physical? The options are:
- Query the BIOS. Except we want the OS to be completely independent of the BIOS (even though the BIOS is still doing the boot loading).
- Query the CMOS for the drive type, which require us to keep a table matching the drive type to actual CHS data.
- Add a boot config (/bootopts) setting to specify the CHS value to use.
- Hardcode (not really acceptable).
Querying the BIOS is the easiest, /bootopts is the best - not the least because it allows us to juggle the cylinder values at boot time instead of at compile time. And /bootopts is the one selected. As of December 2023 you can add a statement like hdparm=615,4,17,-1 in /bootopts, and these values will be used of the system finds an old IDE drive as unit 0. The 4th number is WPCOM, write precompensation as discussed above. A second quadruple may be added for a 2nd drive. This parameter is also used by the MFM (xd) driver.
By the way, the example, 615,4,17, is the value to use if your system has an original 20M drive type 2.
Again, the CHS trickery is only useful in order to preserve compatibility with other OSes using the same disk. If not, using the drive's native values is always better.
Many IDE/ATA-1 drives (the first generation from the 80s being the exception) have two read/write modes: Single sector and multi sector. The difference is a little different from what you may think: In both cases we send a single command to the drive telling it how many sectors we want read or written. Then the requested data are transferred either one sector at a time or the entire block. Confusing? A little. Here's how it works:
Single sector: Send command, say read 6 sectors. Then enter a loop to read one sector, wait for a ready signal from the drive (DRQ), read the next etc. until finished.
Multiple sectors: The block size has been set during initialization with its own command (SET_MULTIPLE), say 16 which is very common - it's always a multiple of two and actually reflects the buffer size on the drive. This value is read from the drive ID block discussed above. Then submit the read or write multiple command which says (say) 20 sectors. If it's a read we then enter a loop that first reads 16 sectors continuously, waits for the DRQ signal, then reads the remaining 4 sectors.
The benefits of the latter are obvious and the flexibility may be surprising. Setting block size to (say) 16, doesn't mean we have to read (or write) at least that many sectors. We may just as well ask for 2 sectors and it's fine - one partial 'block'. However, be aware that on some drives, reading/writing a single sector with a read/write multiple command will fail. The spec doesn't say whether this should be allowed or not, so it's just something we don't do. Use the 'read/write single' command if that's what we want. The TLVC driver does that.
It is also worth noting that the SET_MULTIPLE command may be sent to the drive at any time, so changing the block size on the fly is easy. Given the flexibility between the blocks size and the actual number requested, such changes do not seem very useful although the chosen block size may have performance implications for older drives.
Of course there is more to it, such as handling/recovering from/reporting errors - which is fairly easy. Take a look at the driver source for more details.
TBD
TBD
[TL;DR]: Check out the summary at the bottom.
I know the heading sounds like click-bait, but it isn't. The 'catastrophe' is real enough if approaching the subject from the right (actually wrong) angle. Here's the thing: While XT/IDE is a welcome addition to any XT class machine, they're a BIG mess. Not so much for the DOS user or any other environment in which the embedded BIOS driver is being used for IO, but for those of us writing drivers, accessing the hardware directly, bypassing the built in BIOS code that tries its best too hide the mess.
Actually, XT/IDE is a royal mess regardless. Just take a look at all kinds of technical discussion fora - Reddit, Substack, VCF, etc. What's so messy about it? Well, first there is the BIOS software, the versions, what it does, what it does not and how it does it. Then there is the IO addresses, interrupts and other option settings. And finally, there's the registers.
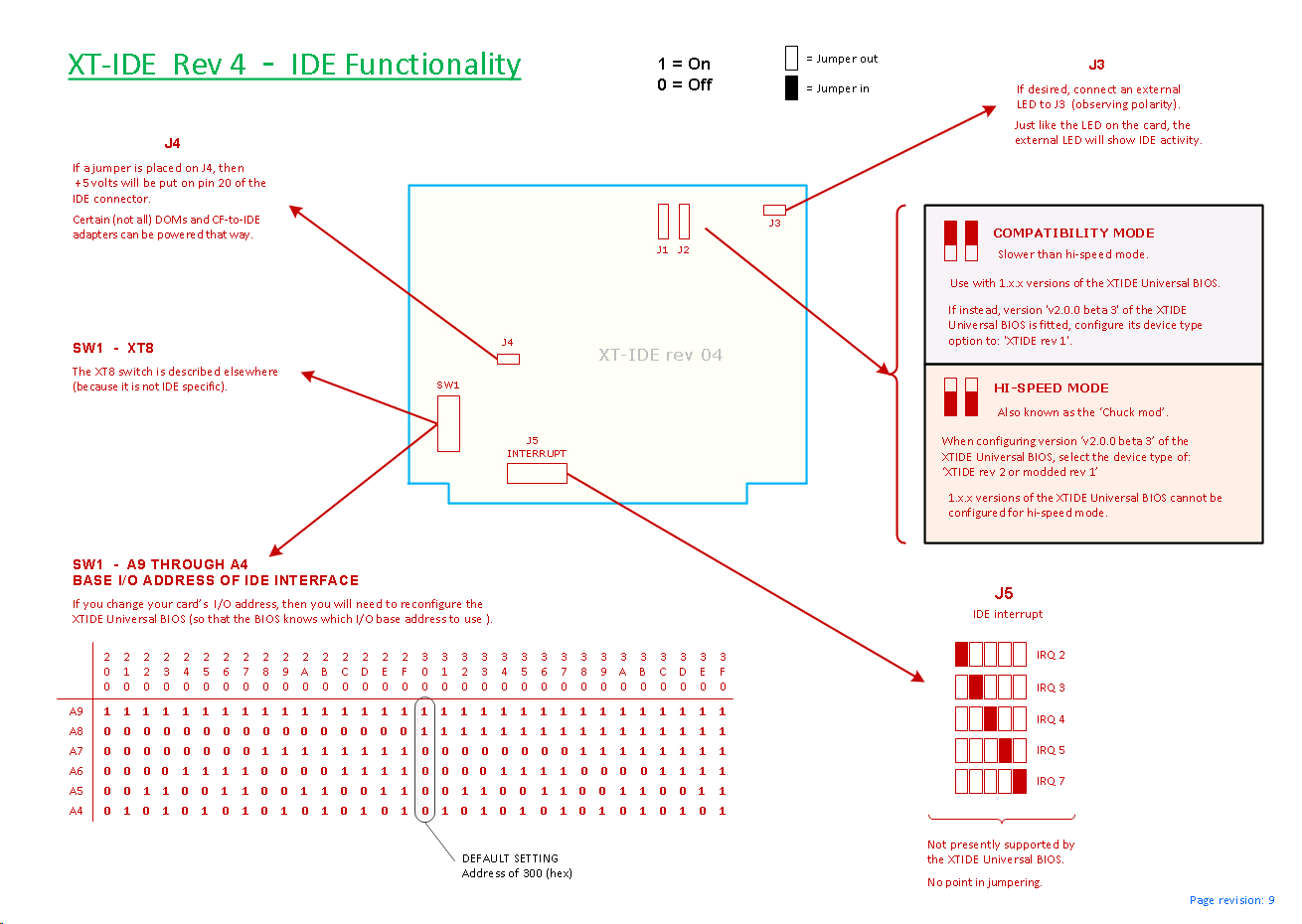
It seems - from the outside - that everything that may be messed up, has been messed up. Like the simplest of things - the base address for IO access. The PC/AT introduced two standard addresses, one for the first (primary) controller, one for the 2nd. In both cases 0x206 can be added to get the to so-called control register (primarily used to reset the controller).
XT/IDE doesn't keep any of that. The typical (default) IO address is 0x300, which potentially collides with any number of other interfaces such as network (NIC) cards. Sure it may be changed, most controllers have switches that allow a host of different settings, but there is a snag, actually two: If the address (or any other jumper/switch setting) is changed, the BIOS code needs to change too, which means reflashing (see the configuration section below). Not all that big of a deal, there are tools for that, but using them is not for the faint of heart and finding the tool that matches your version of the BIOS may be tedious. IOW something most users will avoid.
Why not let the interface read its own switches and adjust? Yes, I know - that would take additional logic and add cost. BTW, now that we're writing a driver, do we need the BIOS code in the first place? After all there is a switch/jumper to disable it? However undesirable, the answer is probably yes: We need the ability to boot off of the XT/IDE 'drive', so the BIOS code needs to work. If we don't need the boot ability, turn it off and we can play freely with the switch and jumpers.
The other port address related issue is that while the span of jumper-selectable addresses is big, it does not include the AT standard IDE interface addresses @ 0x1F0 and 0x170. In most cases it starts at 0x200 and stretches to 0x3ff. Why? It probably saves a little bit of logic on the board, but still, what about usability?
Similarly, the control register address mentioned above is not where you would expect (base address + 0x206), but instead resides at base address + 14 if using XT/IDE V1 or 'compatible mode' (more about this misnomer below). If using 'hispeed' mode (as opposed to 'compatibility mode') the offset is different. If using the CF-Lite version, neither of these offsets will work, so watch out! Phew, shake off that sweat...
These are complications, the kind of pain-in-the-rear differences that annoys a (software) developer. Not complicated but incompatible and extra code, extra work, extra testing. Fixed, tested and forgotten. The next challenge is a lot more complicated and demanding: They - the XT/IDE developer community - decided to screw around with the IDE register addresses. So much for compatibility. Seriously, the main point of IDE was that you could plug in any IDE drive into any machine and it just worked. Even when the Compact Flash (CF) cards came along we were home free because the interface was, yes, IDE. And it worked.
Why the f… did they do that? The goal is performance, more about that in a minute. First - and before the feeling of complete disaster settles - it's not all bad. XT/IDE rev 1 – and later revisions in so called 'compatibility mode' – keep the original IDE register set, just adds one register at the end, address base+8: The high byte of data IO. This is good.
It means that if the connected drive or CF card is told to run in 8 bit mode, a standard feature in almost all old drives and CF cards, things will almost work right away. Almost because the default IO address (typically 0x300) must be free to use, and equally important, the driver is changed to look for the control register in a new place - not base+0x206 but base+8+6.
If 8 bit mode is not available OR we want more speed and are willing to make a few minor changes in the driver, there is the extra (hi byte) data register I mentioned. The controller does 16bit wide IO with the drive/CF-card and avoids having to turn the it into 8 bit mode, which is good for speed and compatibility. Nice and flexible.
Relatively easy, which is why it's called 'compatible mode' although 'semi-compatible' would be more appropriate. As it turns out this is also the end of anything akin to IDE compatibility (I'm exaggerating, but not much). In order to understand why this mess even got started, keep in mind that we're talking XT class (very slow) systems. Every little speed improvement is big deal. Given the components at hand, how can higher speed be achieved? You guessed it - a clever trick that completely ruins compatibility. Then thing is, even though we're talking 8bit ISA-bus systems and 8088 with its multiplexed 16bit address bus, the processor still has word-wide IO instructions. These word-wide instructions, very effectively turned into two single byte operations in the processor silicon, turn out to be significantly faster than issuing two separate IO instruction from a program. So if the two 8bit registers to be accessed - lo and hi data bytes - can be placed adjacently, we can use inw and outw and reap the benefits.
I don't know how much of a benefit we're talking about, but apparently big enough for the XT/IDE folks to pursue it.
Going back to the 'compatible' V1 interface we discussed above, with the low byte at and the hi byte at <base address + 8>, how do we make them adjacent? Not immediately obvious but then it becomes very clear: We swap the A0 and A3 address lines.
Surprised? Me too - at first. You just cannot do that. But they did. And all by a sudden, the hi byte is just where we want it to be and the pair can be accessed by word-instructions. The other registers? Scattered at even addresses between and <base address + 15>. OK, 'scattered' is an exaggeration, there is obviously a system to it: new_reg_addr = old_reg_addr + (old_reg_addr&1)*7. IOW - registers at even addresses remain in place, those at odd addresses have moved 7 bytes up.
The control register? It actually takes a bit of calculation to find it. It used to be (V1) at base+14, but what is base+14 like when A0 and A3 are switched? Pull out pencil and paper and you get it: base+7! In binary, 14 is 1110, switch bits 0 & 3: 0111, ie. 7.
Ok, not so bad, now that we understand it. But there is more. It turns out, and I don't know why, that the adjacent register trick doesn't always work. In my case, on one controller, it worked well for read, but not for write. The hi byte when writing ended up at eh wrong place, 2 bytes later than it should - so two OUTB instructions were needed anyway. Here's what it looked like, the first line is the original, the second is what was written on the disk:
0000: fa b8 60 00 8e c0 8e d0 31 e4 31 ff 57 8e df be
0000: fa 00 60 b8 8e 00 8e c0 31 d0 31 e4 57 ff df 8e
Notice how the 2nd byte in line 1 becomes the 4th byte in line 2 etc.

This is XT/IDE from V2 and onward, often referred to as 'hispeed mode'. Not so bad after all, is it? I guess that depends, but this is not the end of it. There is more, specifically the so-called CF-Lite version, typically an ISA card with a CF socket on the card itself instead of a 40pin connector. 'Lite' because it's really stripped of everything possible, even sanity - at least that was my first impression (and this was the first XT/IDE card I came in contact with). It makes no attempt to do 16 bit IO with the CF card, in fact the upper IDE 8 datalines aren't even connected. It's a pure 8bit device. So why are the registers seemingly dispersed all over and in a pattern different from the hispeed version above? A closer look reveals a more benign (!) or understandable picture: The A0 line from the bus is not connected to IDE bus (that is, the CF card connector), and the rest of the lines (which means 3 of them, since that's how many it takes to address 8 IDE registers) are shifted right, A1-ISA -> A0-CF, A2-ISA -> A1-CF etc. The result is that seen from the bus (and thus the computer), the registers are now 2 apart. Assuming 0x300 as base address, they're at 0x300, 0x302, etc.

Again, you probably think, just like me, why? And again, the reason is performance, the key is using word IO instructions and the gain possibly even more elusive than in the ´hispeed´case above. Not immediately obvious, at least not to me, but an inw 0x300 instruction (which is the same as inb 0x300; inb 0x301) will now translate to two identical reads from the 8 bit IDE data register at address 0, delivering a full word. Smart? Sure - and in this case it's quite easy to map to the new register positions, although yet another variant undeniably increases complexity another notch.
While on the subject of disconnected or not-connected lines, the CF-Lite controller does not support interrupts. Like the upper data lines, the physical lines is just not there. Most other XT/IDE cards seem to have it, with a jumper selection between reasonable values, IRQ2-7.
Finally, what about card configuration, how hard is it? It's not but the language is hard to understand for 'outsiders'. Like, would like XT-CF PIO8 or maybe XT-CF PIO8 (BIU Offload) ? While making the wrong choices is never dramatic in the sense it doesn't break anything, it is annoying to have to do trial and error because the interface is so cryptic. In all fairness, there is a manual out there, quite good actually (https://www.xtideuniversalbios.org/), make sure you read it before starting, it will save you some time. It will not, however, prevent you from making mistakes, because even the prose is hard to understand at times. Also, like I mentioned above, you may have to search for a while to get the right version of the XTIDECFG.COM program. It may be worth it. I have not timed the difference between 'compatible' mode and 'hispeed' mode, but only getting the IO address away from the 0x300 slot was an incredible blessing. As was stopping the BIOS software from trying to find more than one such card on the bus, a 10 second wait.
If you made it all the way through to this paragraph, you're more than average interested. I wrote this because it took me too long to figure everything out. And in a few months I will have forgotten many of the details. Now I have somewhere to look. If it helps you too, all the better.
In short, this chapter is about the challenges faced when writing drivers for the XT/IDE family of mass storage interfaces. It makes the following key observations:
- XT/IDE V1 is almost compatible with 'standard' AT/IDE. IO port addresses are different, the control ports is located differently and the device must either be set to 8bit mode and all IO passed through the data register, or the 'new' hibyte register must be used to get/put the upper half of each word. The latter is obviously faster but requires more changes to a standard IDE driver.
- XT/IDE V2 and later introduces a 'hispeed' mode which changes the register addressing in such a way that the low byte and hi byte data registers become neighbors. That way, word IO may be used instead of byte IO, speeding up things considerably. The price is that most registers now have new addresses and all backwards compatibility is gone. Caveat: Practical experience shows that word mode doesn't always deliver as expected.
- XT/CF-Lite is very 'lite': Only 8 of the IDE datalines used, so a CF card will always have to be in 8bit mode. Again, the register addresses have been modified, in this case the original order is kept but every register now has an even address, like 0,2,4,6 etc., instead of the regular 0,1,2,3,4. The benefit is (again) that word instructions can be used for IO, increasing the speed.
- Most, probably all XT/IDE cards may be configured and/or upgraded via a utility called IDECFG.COM or XTIDECFG.COM.
Links
- Glitchworks IDE page http://users.glitchwrks.com/~glitch/xt-ide.html
- A great intro and overview with links: https://www.minuszerodegrees.net/xtide/rev_4/XT-IDE%20Rev%204%20-%20general.htm

The direct floppy driver in TLVC was originally written by Linux Torvalds in the early 90s. If that sounds like a good thing, it's not. The only good thing about it is that it's old - like the machines TLVC is targeted to.
It's convoluted to say the least. Created with the best of intentions, and at times quite forward looking in the sense that it includes all kinds of bells and whistles to make it fit into a larger system later. Unfortunately that larger system is a 32 bit system. Early 90s means that the 386 was out, with virtual memory and large address space, like many other processors had had for ages already.
Great, but TLVC is a 16 bit IA16 based system, and every codeline counts - for space and speed.
Also, the driver - as it came to TLVC via ELKS - had not been compiled for aeons and depended on mechanisms and features not only deprecated but sometimes deleted decennia ago. Further, it had been fixed and updated by a number of people during the early 90s which probably made it work at the time, but created classic spaghetti code. It is (or was) complicated. Plenty of operations were repeated (routines called) from many places for the same reason doing the same thing, creating the opposite of what was intended: A slow driver.
That said, things aren't all bad. The floppy driver is possibly the ultimate example of event driven programming, long before the concept was even considered and the term coined. It's unique in the sense that there is nothing like it - for the simple reason that the floppy - any floppy - is VERY slow compared to just about any other component in even the older PC. It's also complicated. A floppy has motor startup delays, head load delays, head unload and seek delays, rotational delays etc. A driver cannot wait for those or the system becomes unbearably slow. [Side note: This is what OSes using the BIOS interface for floppy IO do.]
So most functions in the driver kick off an action and exit, leaving the next step to either a timer or an interrupt. For example, when the driver initiates a read or write operation, it registers the request details, sets the address of the appropriate interrupt handler and exits. Then, when the operation is complete, the FDC will field an interrupt and the selected handler will be called to take the next step.
In other cases, like turning the spindle motor on or off, the driver initiates the action, sets a timer for the expected number of milliseconds and exits. Then the timer expires and the OS calls the callback handler to continue. In the meanwhile the OS has had complete control to do all kinds of other stuff.
TLVC inherited the general driver API from ELKS, which remains unchanged. However, there is more to a driver interface than the API itself - In particular in a system this compact: Global variables, assumptions about the environment, configuration options etc. This document outlines these 'environmental issues' - and is subject to change as the environment evolves.
Most NIC drivers have a ASM-component with functionality that partly overlap. In order to optimize and not the least to increase portability, these components are going away over time, being replaced by C code or being merged into kernel libraries. The exception being the ne2k driver which has significant parts implemented in ASM code and most likely will remain that way for efficiency reasons.
Default configuration settings - irq, ioport, … - for NIC interfaces (and other interfaces) are set in tlvc/include/arch/ports.h. These settings populate the netif_parms-array in init/main.c and are overridden by per-NIC settings from /bootopts at boot time. ports.h is not needed but the drivers.
struct netif_parms netif_parms[MAX_ETHS] = {
/* NOTE: The order must match the defines in netstat.h */
{ NE2K_IRQ, NE2K_PORT, 0, NE2K_FLAGS },
{ WD_IRQ, WD_PORT, WD_RAM, WD_FLAGS },
{ EL3_IRQ, EL3_PORT, 0, EL3_FLAGS },
{ EE16_IRQ, EE16_PORT, EE16_RAM, EE16_FLAGS },
{ LANCE_IRQ, LANCE_PORT, 0, LANCE_FLAGS },
};
tlvc/include/linuxmt/netstat.h defines the structs and macros needed by the drivers. Additionally, some drivers have their own header files for constants and macros.
Inside the driver proper, the global data are conveniently accessed via these macros:
extern struct eth eths[];
/* runtime configuration set in /bootopts or defaults in ports.h */
#define net_irq (netif_parms[ETH_EE16].irq)
#define net_port (netif_parms[ETH_EE16].port)
#define net_ram (netif_parms[ETH_EE16].ram)
#define net_flags (netif_parms[ETH_EE16].flags)
static struct netif_stat netif_stat;
static char model_name[] = "ee16";
static char dev_name[] = "ee0";
The eths array is defined in tlvc/arch/i86/drivers/char/eth.c and holds the file_operations pointers for each driver, plus a pointer to the netif_stat structure, which contains the interface's MAC address and statistics collected by the driver (primarily error stats).
The model_name and dev_name are more consistently used by the networks drivers than elsewhere in the system. dev_name is the device name as found in the dev directory and is always the same for a given driver. The model_name may vary, depending on what the _probe routine finds during initialization. For example, the ne2k may report either ne2k or ne1k as the name, the wd driver may report wd8003 or wd8013 etc.
dev_name is also the name used for per-device configuration in /bootopts and may conveniently be made part of the netif_params struct, saving some string space.
…
if (!strncmp(line,"ne0=", 4)) {
parse_nic(line+4, &netif_parms[ETH_NE2K]);
continue;
}
if (!strncmp(line,"wd0=", 4)) {
parse_nic(line+4, &netif_parms[ETH_WD]);
continue;
}
…
NIC buffering is experimental in TLVC, and currently implemented only in the ne2k NIC driver. Given its experimental nature there are several configuration options in order to evaluate what works and what does not. There is of course a dynamic in this in that what works depends on other components of the system. The more asynchronous the IO system in general becomes, the more useful NIC-buffering becomes as it can take advantage of overlapping IO.
As of July 2024, there is little if any benefit in allocating transmit buffers for NICs. Extensive testing confirms that given the typical speed/performance of the systems involved and the nature of today's networks, a transmitted packet will exit the NIC (and generate a transmit complete interrupt) almost before the write-packet routine has returned to its caller. This means (among other things) that allocation 4 on-NIC tx-buffers, as we do in the ee16-driver with 32k RAM, is a waste.
The current buffer implementation offers 3 buffer strategies:
- No buffers: The driver is moving data directly to/from the requester
(via far mem-move), i.e.
ktcp. - Static buffers: The number of send and receive buffers specified in the NET_OBUFCNT and NET_IBUFCNT defines are allocated statically at compile time. The BUFCNT numbers may be 0, in which case the driver will run as if NO_BUFS was set (except the extra code is compiled in).
- Heap allocation: Buffer space is allocated from the kernel heap, which is slightly different from static allocation in that memory is allocated only if the network is running. Memory consumption will be slightly higher because of the headers in the heap allocation.
When HEAP allocation is used, the # of buffers may be set in /bootopts via the 'netbufs=' directive. 'netbufs=2,1' means 2 receive buffers, 1 transmit buffer. The kernel will not do sanity checking on the netbufs= numbers, it's entirely possible to make the system unbootable by requesting too many buffers. 2,1 or 2,2 are reasonable choices for regular usage. Again, zero is a valid selection and will turn off buffers entirely. When using heap allocation, a header strucure per buffer is also allocated from the heap, 6 bytes per buffer.
AGAIN: zero buffers is always a valid choice - which complicates the driver somewhat but makes benchmarking much more convenient.