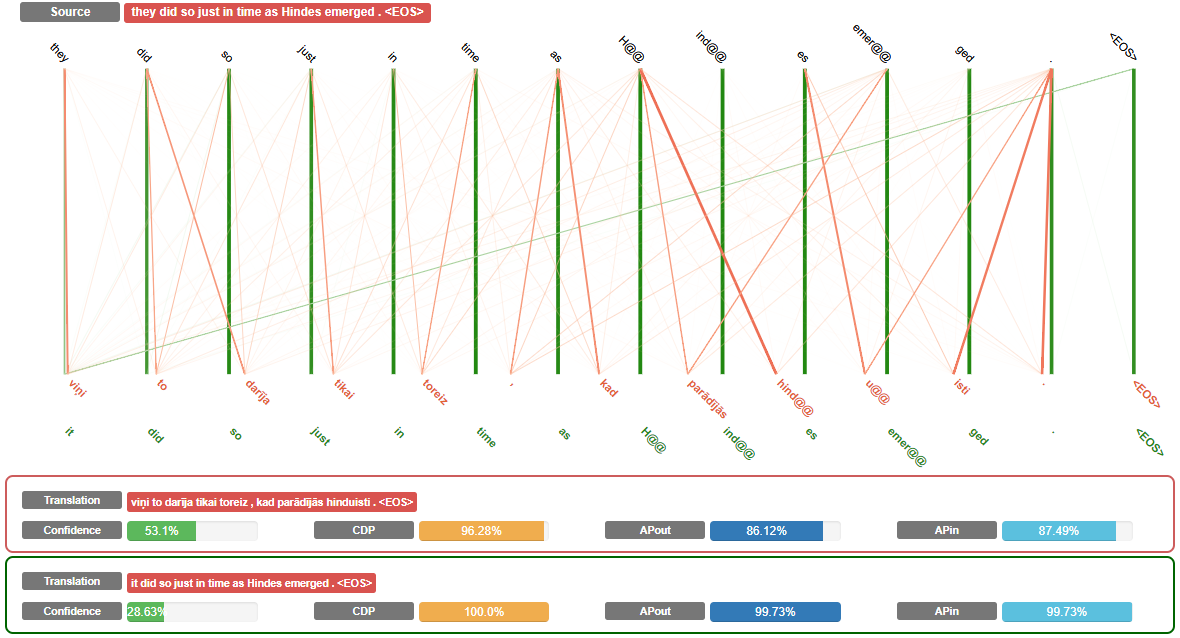
An attention alignment visualization tool for command line and web.
A part of the web version was borrowed from Nematus utils
The Machine Translation Marathon 2019 tutorial can be found here

- Train a neural MT system (using Marian, Sockeye or Neural Monkey)
- Translate text and get word or subword level alignments
- Visualize the alignments
- in the command line standard output
- in a web browser (PHP required)
From the repository - this way you get all files including test data and the web version for viewing.
git clone https://github.com/M4t1ss/SoftAlignments.git
cd SoftAlignments
python softalignments/process_alignments.py -i test_data/nematus/alignments.txt -o color -f Nematus -n 1From the PyPI via pip - this will install only the Python part without the PHP web version. For now only color, block and block2 output forms work with this.
pip install softalignments
wget https://raw.githubusercontent.com/M4t1ss/SoftAlignments/master/test_data/nematus/alignments.txt
softalignments -i alignments.txt -o color -f Nematus -n 1-
Python 3.6 or newer
-
NLTK for BLEU calculation(requires Python versions 3.5, 3.6, 3.7, or 3.8)
-
Numpy
pip install numpy nltk
-
-
PHP 5.4 or newer (for web visualization)
-
Nematus (This worked for the Theano version. Not sure about the current Tensorflow version...)
- Run nematus/translate.py with the
--output_alignmentor-aparameter
- Run nematus/translate.py with the
-
- In the training.ini file add
[alignment_saver] class=runners.word_alignment_runner.WordAlignmentRunner output_series="ali" encoder=<encoder> decoder=<decoder>
and add alignment_saver to the runners in main
runners=[<runner_greedy>, <alignment_saver>]- In the translation.ini file in eval_data add
s_ali_out="out.alignment"
-
- Run marian-decoder with the parameter
--alignment soft - If you use the transformer model architecture, you will need to train it with guided alignments. See the MT Marathon 2019 Tutorial for details about this.
- Run marian-decoder with the parameter
-
OpenNMT Run translate.lua to translate with the
-save_attentionparameter to save attentions to a file -
- Run sockeye.translate to translate with the
--output-typeparameter set totranslation_with_alignment_matrixto save attentions to a file. - If you use the transformer model architecture, you will need to implement (copy in the correct places) code from this pull requst. Otherwise, Sockeye will return attention values of 0 for all tokens.
- Run sockeye.translate to translate with the
-
Other The easiest format to use (and convert to) is the one used by Nematus.
For each sentence the first row should be
<sentence id> ||| <target words> ||| <score> ||| <source words> ||| <number of source words> <number of target words>After that follow
<number of target words> + 1 (for <EOS> token)rows with<number of source words> + 1 (for <EOS> token)columns with attention weights separated by spaces.After each sentence there should be an empty line.
Note that the values of
<sentence id>,<score>,<number of source words>and<number of target words>are actually ignored when creating visualizations, so they may as well all be 0.An example:
0 ||| Obama welcomes Netanyahu ||| 0 ||| Obama empfängt Net@@ any@@ ah@@ u ||| 7 4 0.723834 0.0471278 0.126415 0.000413103 0.000774298 0.000715227 0.10072 0.00572539 0.743366 0.0342341 0.000315413 0.00550132 0.00150629 0.209351 0.0122618 0.0073559 0.909192 0.000606444 0.00614908 0.00256837 0.0618667 0.00110054 0.0214063 0.0759918 0.000446028 0.104856 0.0435644 0.752634
If you use this tool, please cite the following paper:
Matīss Rikters, Mark Fishel, Ondřej Bojar (2017). "Visualizing Neural Machine Translation Attention and Confidence." In The Prague Bulletin of Mathematical Linguistics volume 109 (2017).
@inproceedings{Rikters-EtAl2017PBML,
author = {Rikters, Matīss and Fishel, Mark and Bojar, Ond\v{r}ej},
journal={The Prague Bulletin of Mathematical Linguistics},
volume={109},
pages = {1--12},
title = {{Visualizing Neural Machine Translation Attention and Confidence}},
address={Lisbon, Portugal},
year = {2017}
}-
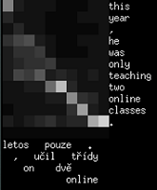
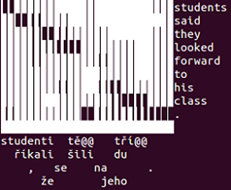
in the command line as shaded blocks. Example with Neural Monkey alignments (separate source and target subword unit files are required)
python softalignments/process_alignments.py \ -i test_data/neuralmonkey/alignments.npy \ -o color \ -s test_data/neuralmonkey/src.en.bpe \ -t test_data/neuralmonkey/out.lv.bpe \ -f NeuralMonkey
-
the same with Nematus alignments (source and target subword units are in the same file)
python softalignments/process_alignments.py \ -i test_data/nematus/alignments.txt \ -o color \ -f Nematus
-
in a text file as Unicode block elements
python softalignments/process_alignments.py \ -i test_data/neuralmonkey/alignments.npy \ -o block \ -s test_data/neuralmonkey/src.en.bpe \ -t test_data/neuralmonkey/out.lv.bpe \ -f NeuralMonkey
or
python softalignments/process_alignments.py \ -i test_data/neuralmonkey/alignments.npy \ -o block2 \ -s test_data/neuralmonkey/src.en.bpe \ -t test_data/neuralmonkey/out.lv.bpe \ -f NeuralMonkey -
in the browser as links between words (demo here)
softalignments/python process_alignments.py \ -i test_data/marian/marian.out.lv \ -s test_data/marian/marian.src.en \ -o web \ -f Marian
| Option | Description | Required | Possible Values | Default Value |
|---|---|---|---|---|
| -f | NMT framework where the alignments are from | No | 'NeuralMonkey', 'Nematus', 'Marian', 'OpenNMT', 'Sockeye' | 'NeuralMonkey' |
| -i | input alignment file | Only if no configuration file is provided | Path to file | |
| -s | source sentence subword units | For Neural Monkey or Marian | Path to file | |
| -t | target sentence subword units | For Neural Monkey | Path to file | |
| -o | output type | No | 'web', 'color', 'block', 'block2', 'compare' | 'web' |
| -r | reference file for calculating BLEU score | No | Path to file | |
| -n | Number of a specific sentence | No | Integer | -1 (show all) |
| -c | configuration file | No | Path to file | |
| -d | Combine subword units (De-BPE) | No | Integer | |
| -v | NMT framework where the 2nd alignments are from | For output type'compare' | 'NeuralMonkey', 'Nematus', 'Marian', 'OpenNMT', 'Sockeye' | 'NeuralMonkey' |
| -w | input file for the 2nd alignments | For output type'compare' | Path to file | |
| -x | 2nd source sentence subword unit file | For output type'compare' and Neural Monkey or Marian | Path to file | |
| -y | 2nd target sentence subword unit file | For output type'compare' and Neural Monkey | Path to file |
The parameters can be provided via configuration .ini file to have a smaller mess in the command line when calling the script.
| Block | Option | Description |
|---|---|---|
| AlignmentsOne | From | NMT framework where the alignments are from |
| AlignmentsOne | InputFile | input alignment file |
| AlignmentsOne | SourceFile | source sentence subword units |
| AlignmentsOne | TargetFile | target sentence subword units |
| AlignmentsOne | ReferenceFile | reference file for calculating BLEU score |
| Options | OutputType | output type |
| Options | Number | Number of a specific sentence |
| AlignmentsTwo | From | NMT framework where the 2nd alignments are from |
| AlignmentsTwo | InputFile | input file for the 2nd alignments |
| AlignmentsTwo | SourceFile | 2nd source sentence subword unit file |
| AlignmentsTwo | TargetFile | 2nd target sentence subword unit file |
For example, create a config.ini file:
[AlignmentsOne]
InputFile: ./test_data/neuralmonkey/alignments.npy
SourceFile: ./test_data/neuralmonkey/src.en.bpe
TargetFile: ./test_data/neuralmonkey/out.lv.bpe
From: NeuralMonkey
[Options]
OutputType: colorAnd run:
python softalignments/process_alignments.py -c config.iniColor, Block, Block2

Web

Compare