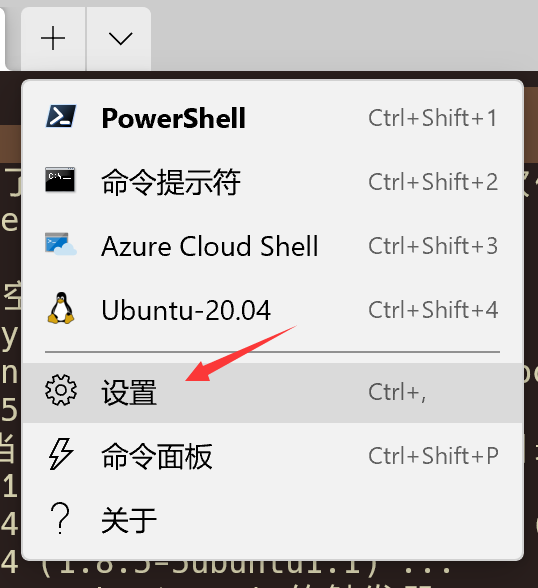
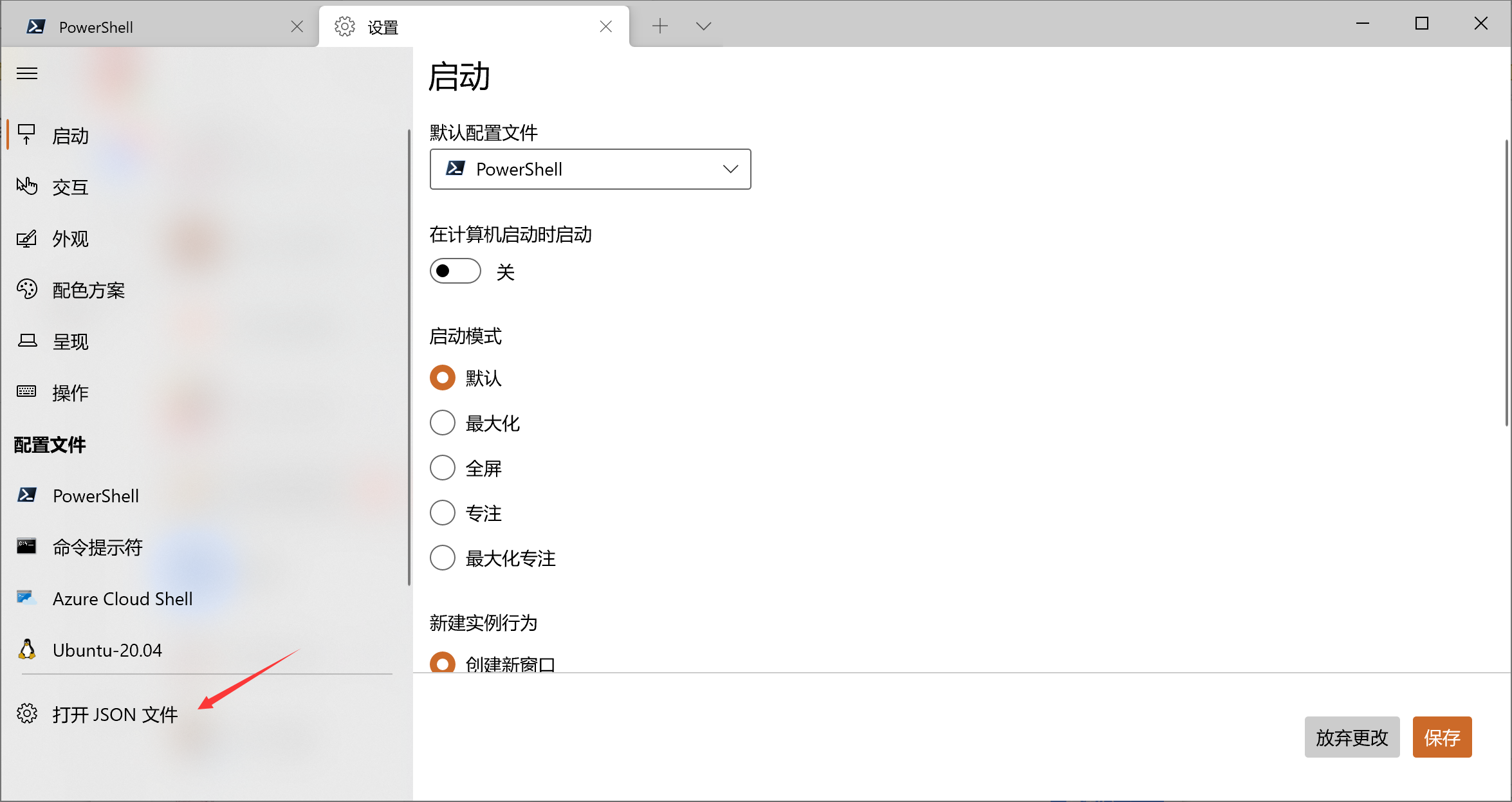
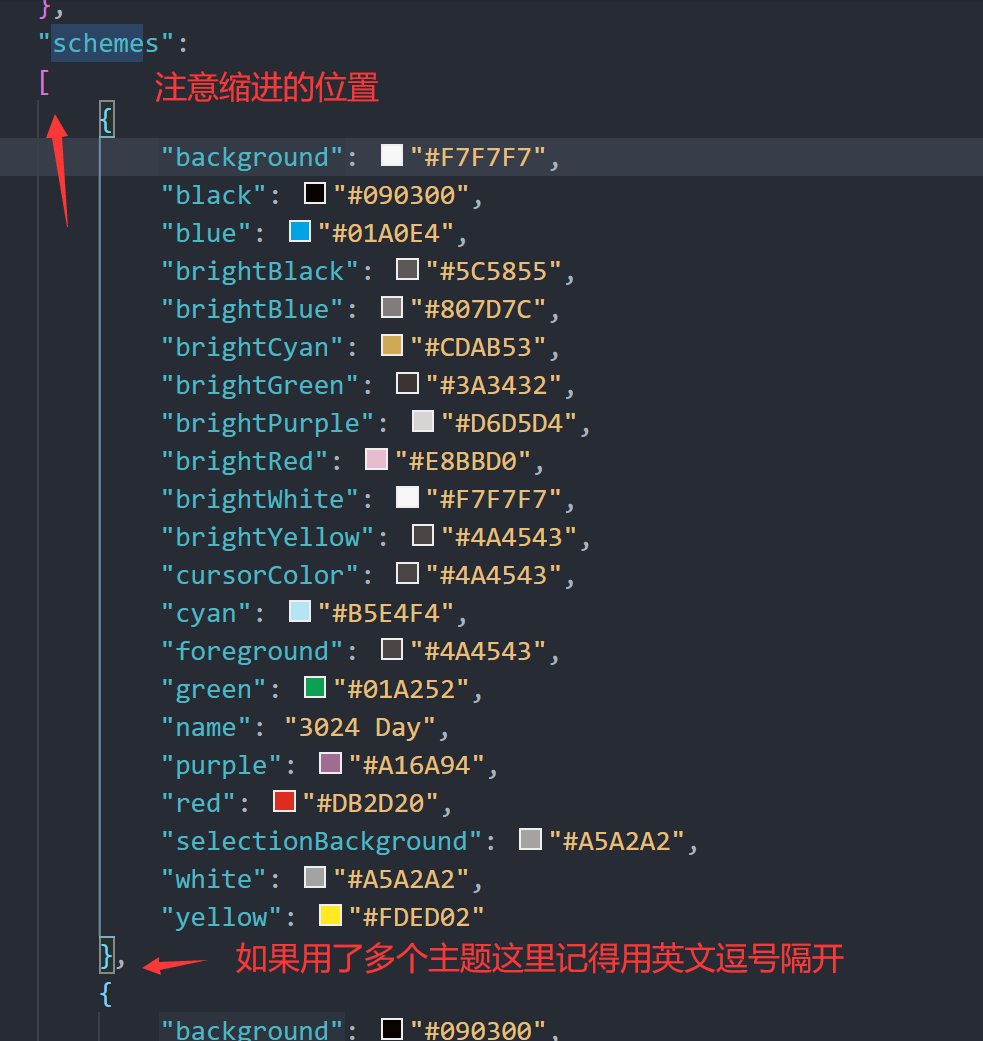
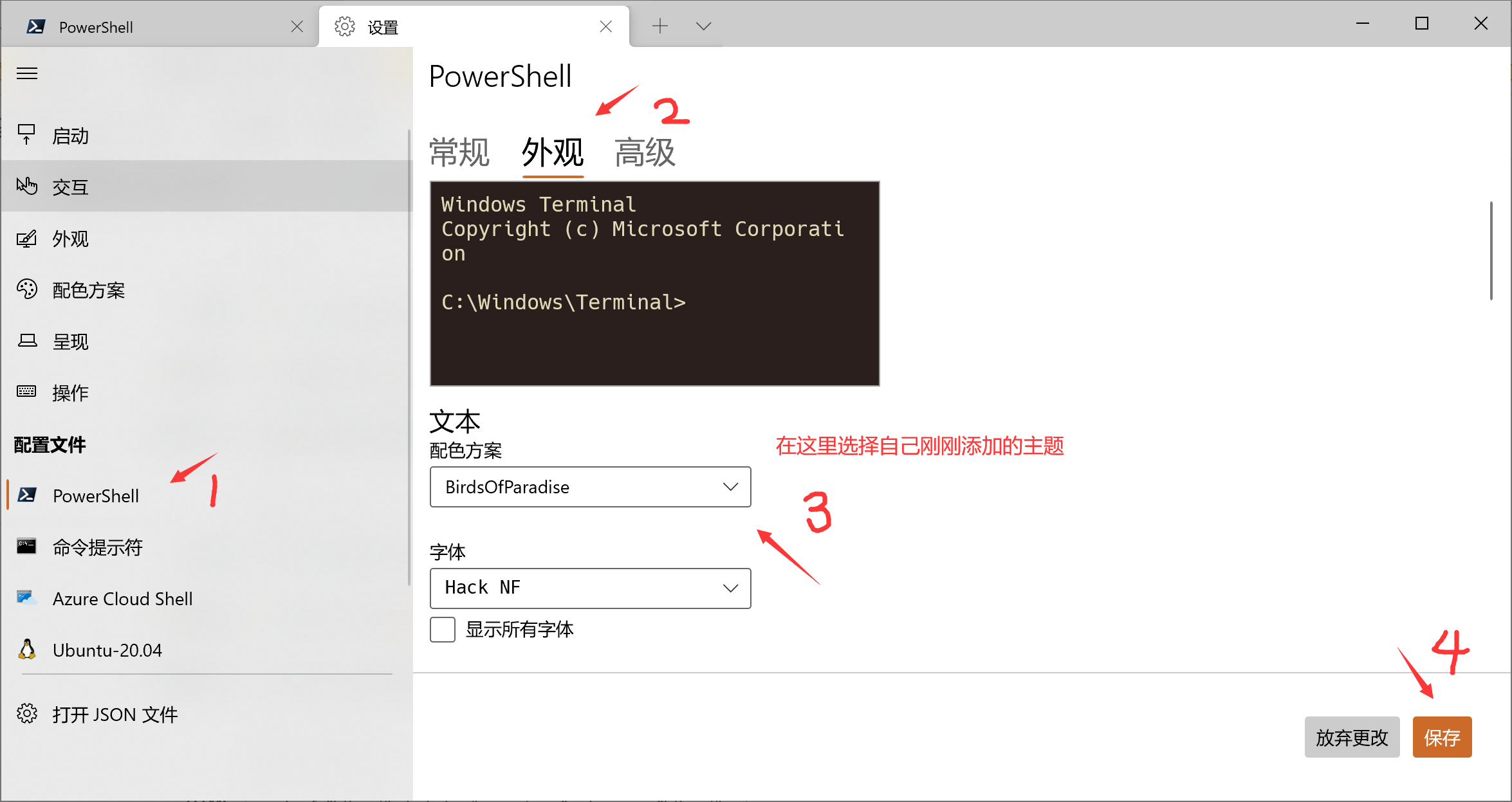
友链 - Halcyon Zone 在下方留言申请加入我的友链,按如下格式提供信息:
博客名:Fluid 简介:Fluid 主题官方博客 链接:https://hexo.fluid-dev.com 图片:https://hexo.fluid-dev.com/img/favicon-pic.png 博客在允许 JavaScript 运行的环境下浏览效果更佳
+
+
+
+
+ 原理分析:UDP和TCP在NAT环境下的P2P打洞实现
+ /p/bb3a9deb.html
+
+ 在当前互联网的结构模式下,大部分的数据通信和交互都是以C/S结构进行通信,即一个客户端和一个中心服务器,客户端通过将数据交给服务器,再有服务器将数据进行适当的处理后与客户端进行交互。除了C/S,还有一种常见的结构,即P2P通信。在P2P网络下,主要的通信双方为“节点”,节点和节点之间的通信是直达的,不需要中心服务器对信息进行处理。
由于这篇博客本身的目的并不是非要在C/S和P2P中抉择出一个好坏,重点主要放在P2P的技术实现上,就不做优劣对比了。P2P网络本质上是一种去中心化的网络结构,每个节点都直接与其他节点交互,共享节点和节点之间的资源与服务。这种结构相对来说可以更有效的利用资源,提高传输效率和可靠性(打洞成功的情况下)。
但是既然有这么多好处,那么必然也有相对应的挑战:P2P网络最核心的本质还是需要节点和节点能够直接通信。但是在当前国内的网络环境下,大部分的家庭用户并没有一个自己的公网IP。很多时候想实现节点和节点的直接通信,我们都需要想一个办法跨过防火墙,来让两个节点能够“握手”并“通信”,而这个过程便称为“打洞”。
内网请求 :用户设备(内网IP地址为192.168.1.10)通过端口5000发起对外部服务器的请求。地址转换 :路由器接收到来自内网用户的请求后,使用NAT机制将源地址从内网IP转换为路由器的公网IP地址(203.0.113.45),同时,源端口从5000更改为1024。NAT通过这一端口映射的过程,来维护外网和内网设备的通信。请求转发 :经过地址转换后,路由器将修改后的请求通过互联网转发至目标服务器(IP地址为51.68.141.240)的80端口。s服务器响应 :服务器接收到请求后,对该请求进行处理,并通过相同的端口(80)向互联网发送响应数据。响应数据路由 :互联网将服务器的响应数据发回路由器的公网IP地址(203.0.113.45)的1024端口。反向地址转换 :路由器接收到响应数据后,再次使用NAT机制,将响应数据包的目标地址从路由器的“公网IP地址(203.0.113.45):端口(1024)”映射回用户的”内网IP地址(192.168.1.10)和端口5000“。内网传递响应 :最后,路由器将响应数据发送回内网用户,完成整个通信过程。
注册与穿透服务器 :两个客户端A和B分别与穿透服务器S建立UDP会话。在此过程中,服务器S记录每个客户端的两个Endpoint:客户端自认为用来与S通信的内网Endpoint对,以及服务器观察到的客户端用来进行通信的公网Endpoint。Endpoint信息的记录与交换Endpoint信息,并从IP和UDP头部提取公网Endpoint信息。如果客户端不在NAT后面,这两个Endpoint应该是相同的。发起UDP打洞请求 :假设客户端A想要直接与客户端B建立UDP会话。A首先不知道如何到达B,因此A请求S帮助建立与B的UDP会话。服务器响应 :S回复A,包含B的公网和内网Endpoint信息。同时,S使用其与B的UDP会话向B发送包含A的公网和内网Endpoint的连接请求消息。收到这些消息后,A和B知道了对方的公网和内网Endpoint。双向打洞 :A收到B的公网和内网Endpoint后,开始向这两个Endpoint发送UDP数据包,并锁定首先从B处获得有效响应的Endpoint。类似地,B在收到转发的连接请求后,开始向A的已知Endpoint发送UDP数据包,锁定第一个有效的Endpoint并以此通讯。由于A和B相互发送数据包的操作本身是异步的,因此A和B发送数据包的前后顺序并没有严格要求。
建立会话 :客户端A与服务器S建立UDP会话,NAT分配公网端口62000。端口分配 :客户端B也与服务器S建立UDP会话,NAT为其分配公网端口62005。连接请求 :客户端A请求使用打洞技术与客户端B建立通信,并通过服务器S作为介绍人。交换Endpoint信息 :服务器S向客户端A发送客户端B的公网和内网Endpoint信息,并将客户端A的信息转发给客户端B。尝试直接通信 :客户端A和B尝试向彼此的公网和内网Endpoint发送UDP数据包。选择通信路径 :根据NAT的支持情况,客户端可能通过NAT(支持Hairpin转译)或直接(不支持Hairpin转译)进行通信。Hairpin是NAT中的一种转译技术,其主要实现了让NAT后的两台设备都可以通过公网的IP和端口进行直接通信,具体的效果如下
客户端A发送数据 :假设客户端A想要发送数据到客户端B。首先,客户端A会将数据包发送到NAT设备,目标是客户端B的公网Endpoint(例如155.99.25.11:62005)。NAT设备处理 :NAT设备接收到来自客户端A的数据包,并查看目标地址。这里涉及Hairpin转译,因为数据包的源地址和目标地址都是由NAT设备分配的公网地址。Hairpin转译动作 :如果NAT设备支持Hairpin NAT,它会识别出虽然目标地址是公网地址,但实际上目的地是内网中的另一个客户端。NAT设备将会将数据包的目标地址从B的公网Endpoint转换为B的内网IP地址(10.1.1.3),同时可能还会更改源地址从A的公网Endpoint到A的内网IP地址(10.0.0.1)。数据包转发给客户端B :完成地址转换后,NAT设备将数据包转发到客户端B的内网地址上。此时,数据包好像是从客户端A直接发送给客户端B而不是经过互联网,即使它们实际上是通过NAT设备的公网地址进行通信的。客户端B接收数据 :客户端B收到了来自客户端A的数据包,尽管这些数据包最初是发送到NAT设备的公网地址的。在P2P通信中,由于内网Endpoint比公网的Endpoint要更早到达客户端B,也就是说Hairpin转译的通信流程还没走完,客户端A通过内网Endpoint和B建立的通信就完成了。因此在实际的通信中,由于内网路由通常比经过NAT的路由更快,客户端A和B更倾向于使用内网Endpoint进行后续的常规通信。
会话初始化 :客户端A和B分别从它们的本地端口4321发起到服务器S的1234端口的UDP通信会话。端口映射 :NAT A为客户端A分配公网端口62000,而NAT B为客户端B分配公网端口31000。注册与记录 :A和B向服务器S注册它们的内网和公网Endpoint。请求协助 :客户端A请求服务器S帮助与客户端B建立连接。Endpoint交换 :服务器S向两个客户端交换彼此的公网和内网Endpoint信息。尝试直连 :A和B尝试直接向彼此的公网和内网Endpoint发送UDP数据包。NAT行为 :如果NAT A和NAT B表现良好,它们将保留公网到内网的映射,为P2P通信“打洞”。通信验证 :一旦客户端验证了公网Endpoint的可用性,且因为在两个不同的NAT后,内网Endpoint不可达,它们将停止向内网Endpoint发送消息,只用公网Endpoint通信。
客户端发起连接 - 客户端A和B分别从它们的内网地址发起到服务器S的UDP连接。NAT A和B映射 - NAT A和NAT B各自为客户端A和B创建了公网到内网的地址映射。NAT C建立映射 - 在ISP级别的NAT C为两个会话建立了公网到内网的地址映射。尝试建立P2P连接 - 客户端A和B尝试通过UDP打洞技术建立直接的P2P连接。NAT C的Hairpin转译 - 如果NAT C支持Hairpin转译,它会处理从A到B和从B到A的数据包。数据包路由 - NAT C将数据包正确地路由到另一端的客户端。数据包到达目的地 - 经过NAT的转译,数据包成功到达对方客户端。当NAT不支持Hairpin转发的时候就无能为力了,目前Hairpin的普及度也需要打一个问号。也存在一些特殊的NAT结构,让P2P的成功率更加没有保证。如果希望P2P打洞的成功率变高,则需要整个互联网都推动这一块的发展。
即使在通过上述的几种不同的方法打洞成功,这种方法打出的隧道也并不是可以一直可靠的。大部分的NAT内部都有一个维护UDP转换信息的计时器:如果在一段时间内某个端口上不再有数据通信,那么这个隧道就会因为空闲超时被关闭掉。
如果希望P2P的隧道能不受NAT网关的时间限制,就需要通过发送持续的心跳包来维持这个隧道的活跃状态。
除了心跳包的方法,当然也可以在双方长时间没有数据往来的时候将当前的隧道关闭,并在下一次需要通信的时候建立连接。通过这样的方式避免不必要的流量浪费。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ DNS
+
+
+
+
+
+
+
+
+ 镜像构建:Windows Cloud Image
+ /p/b9295ba3.html
+
+ Ubuntu和Debian等常见Linux系统都有官方自带cloud-init的cloud image可供下载使用,但是Windows系统在微软中心只找到了ISO镜像的下载路径。当需要在pve等常见虚拟化环境中部署Windows服务器的时候,无论是virtio的驱动,还是iso安装漫长的等待时间都是个问题,所以需要构建cloud image来方便快捷的进行部署
工具使用的是提供给OpenStack的构建工具:
构建出来的镜像可以在各种虚拟化环境中部署和运行。
一台开启了Hyper-V的Windows宿主机,用于构建镜像。 一个Windows Server的部署镜像,这里以Windows2022为例。 Windows虚拟机的virtio驱动,可以在这里 下载到最新的iso。镜像的构建本身不会污染宿主机环境,但是需要在宿主机中启用Hyper-V,以便于创建虚拟机。(启用教程网上很多,不做阐述) 启用了Hyper-V以后,为了尽可能构建稳定独立的镜像环境,需要在Hyper-V中创建一个额外的网卡,用于单独构建虚拟机。 通过Windows的搜索功能打开Hyper-V管理器
根据下面的流程创建一个虚拟交换机
配置虚拟交换机属性
等待应用更改结束后就可以退出Hyper-V管理器了
只要双击打开下载好的Windows2022的iso文件,Windows就会自动对虚拟光驱进行挂载了。这里假设我挂载以后的盘符为D:\
首先在Windows宿主机上克隆构建工具的仓库
1 git clone https://github.com/cloudbase/windows-imaging-tools .git
以管理员权限执行Powershell,并进入刚刚clone的仓库目录下
为当前的Powershell临时加载镜像构建需要的模块
1 2 3 Import-Module .\WinImageBuilder.psm1Import-Module .\Config.psm1Import-Module .\UnattendResources\ini.psm1
指定配置文件的目录,并初始化对应的文件内容
1 2 $ConfigFilePath = ".\config.ini" New-WindowsImageConfig -ConfigFilePath $ConfigFilePath
(可跳过)快速初始化配置文件
1 2 3 Set-IniFileValue -Path (Resolve-Path $ConfigFilePath ) -Section "DEFAULT" `-Key "wim_file_path" `-Value "D:\Sources\install.wim"
因为有一些具体的参数还需要调整,因此这一步可以在下一步手动修改config的时候进行
手动完善刚刚通过命令行创建的config.ini文件,以下是一些注意事项和自己没搞明白的地方
image_name这个配置项需要对install.wim执行Get-WimFileImagesInfo来获取一个列表,然后选出你需要的那个镜像名字。比如对带有桌面环境的Windows Server 2022标准版而言,就是Windows Server 2022 SERVERSTANDARD[vm]的配置参数是指构建用的虚拟机的参数。在构建完成后这个虚拟机会被销毁,一般不用在意。在构建失败的时候可以通过管理员密码进入虚拟机查看信息[vm]的external_switch中需要填入的就是我们刚刚创建好的Hyper-V虚拟网卡名字,比如按照上图中我们选用的是external,这里直接填入即可。[drivers]的部分需要选择你下载的virtio镜像地址time_zone这块不太清楚格式应该怎么填,无论是Asia/Shanghai还是China Standard Time,在自己构建的时候都失败了。如果出现了同样问题的小伙伴建议就默认留空试试其他具体是用qcow2还是vhdx就按需填写即可
执行构建命令,等待镜像构建成功即可
1 New-WindowsOnlineImage -ConfigFilePath $ConfigFilePath
镜像构建的过程中,会有一段时间Powershell一直输出查询日志,这个时候可以去Hyper-V管理器那边查看创建好的虚拟机中的构建状态,如果出现了报错的话直接将虚拟机删除,重新调整配置文件再构建即可。
理论上来说整个构建流程都可以无人值守完成,构建成功了一次以后配置文件和路径在确定的情况下可以保留用于下一次的构建
构建成功后,生成的对应镜像会存放于config.ini中的image_path配置目录下。
整个构建流程对Windows宿主机一般而言不会有环境污染的问题。在构建完成以后,只需要删掉创建的Hyper-V虚拟交换机就可以恢复初始环境。如果在构建用虚拟机构建过程中出现问题,只需要删掉对应的虚拟机和虚拟机对应的磁盘文件即可。
如果是在加载驱动的过程中手动中止了构建,也只需要将挂载的虚拟目录弹出或删除,然后从头开始整个流程即可。
如果构建成功的话,虚拟机会自动关机并重启,这段时间可能会存在一段时间黑屏情况,不用太在意,等待一段时间以后Powershell会接收到虚拟机的配置信息,从而开始镜像的打包流程。
+
+ 小技巧
+
+
+
+
+
+
+ Windows
+
+ Cloud
+
+
+
+
+
+
+
+
+ 性能测试:跨墙的内网穿透工具选择
+ /p/59e029c8.html
+
+ 由于需要将家里HomeLab的服务内网穿透到外网服务器上,如果使用Zerotier一类的服务进行穿透的话,在经过GFW以后速度会暴跌。因此需要使用带加密的服务来进行建立连接。
在大约一年前的时候使用了Frp作为跨墙的内网穿透工具,但是因为不知名的原因,当时Frps和Frpc的连接总是容易断开,当时也没有做具体的原因分析。这段时间在新购买了海外VPS之后决定花一些时间对不同的内网穿透工具在跨越GFW的情况下的性能和丢包做一个对比
综合性能、带宽和丢包率来看,最新版本的Frp已经是不错的选择。不过目前还不确定在特殊时期Frp能否经历防火墙的考验,而V2Ray虽然在Benchmark的结果上不如人意,但是在跨墙可用性来说是身经百战的。Rathole在个人当前的应用场景下则没有太大的优势。
内网虚拟机一台,配置为2C4G,后文简称client。该机器位于家庭宽带环境中,没有公网IP。 外网机器一台,配置为1C1G,后文简称server。使用的是洛杉矶的机器,国内线路有做优化。 V2RAY:使用ws+tls协议,其中tls部分由nginx进行处理。版本为:5.4.1 FRP:服务端除了auth.token不添加任何多余的参数,性能方面均以默认配置文件为主。版本为:0.53.2 Rathole:同样以默认配置文件为主,最新的源码65b27f076c编译而来的二进制文件。版本为:0.5.0 其中V2RAY与FRP均使用Docker的方式进行部署,Rathole通过screen直接运行在后台。
该测试环境存在诸多不合理的地方,该测试主要为自己的特定使用场景做参考。如果有问题还请斧正
通过三套不同的工具,分别将client上的5201端口转发到server的5201(v2ray),15201(frp)和25201(rathole)上。
在server端输入以下指令,以Json文件获取120s内tcp连接的带宽和稳定性
1 iperf3 -J --logfile ./xxx_result.log -c localhost -p xxx -t 120s
将测试结果统计后以可视化的形式进行对比
V2Ray:部署复杂度较高,配置文件可读性较差。对于ws+tls来说,不但要部署v2ray本身,在服务端还需要额外的域名和Nginx进行转发。同时如果我有多个client的时候,会出现不确定到底是代理到哪个机器的问题,在不进行额外配置的情况下容易出现502报错。 FRP;部署难度极低,配置文件可读性极好,上手难度极低。 Rathole:部署难度中等,每次添加端口需要同时修改服务端和客户端的配置文件,后续维护是最麻烦的。 在通过上述测试流程后,对日志进行分析统计,可以得到以下统计图表:
带宽:Frp和Rathole没有明显差距,V2Ray的带宽相对来说较低,但是没有拉开明显差距 丢包率:Frp相比Rathole略有优势,在晚高峰的时候依旧能保证丢包率控制在30以下。V2Ray相比之下则更容易丢包 由于网站只有小范围用户使用,因此对拥塞控制并没有很高的需求。不过从这份Benchmark中也可以看出,在高并发场景下,Rathole可能会更有优势 资源占用:V2Ray由于加密解密的严谨性,资源消耗相比Rathole与Frp都要多。在资源占用这一点上,Frp几乎是毫无悬念的领先 综上,从配置难度以及性能对比的角度来看,暂时使用Frp会是一个不错的选择。如果后续出现了性能的不稳定性也会在这里进行补充说明。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ Frp
+
+ Rathole
+
+ V2Ray
+
+ 内网穿透
+
+
+
+
+
+
+
+
+ 获取Cloudflare Tunnel下用户真实IP
+ /p/f09b73d7.html
+
+ 部署在内网中,在80端口部署了PHP的服务器一台。 使用了Cloudflare Tunnel对内网http://127.0.0.1进行了转发,并提供https支持 SSPanel需要拥有https的情况下才可以正常使用,但是使用Cloudflare Tunnel默认的设置的情况下,所有的用户登入请求都会被记录为Tunnel的转发地址(在这种情况下即127.0.0.1)。
在这种情况下,当用户通过Tunnel访问我的网站时,Cloudflare会通过CF-Connecting-IP这个HTTP请求头传递原始访问者的IP地址。因此也就可以通过修改Nginx配置的方法来获取到对应用户的真实IP地址了。
先在这里贴上修改了的配置文件和注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 server {listen 80 ;listen [::]:80 ;root /path/to/site/public;index index.php;server_name your.domain.com;set_real_ip_from 127.0.0.1 /32 ; real_ip_header CF-Connecting-IP;location / {try_files $uri /index.php$is_args $args ;location ~ \.php$ {try_files $fastcgi_script_name =404 ;include fastcgi_params;fastcgi_index index.php;fastcgi_buffers 8 16k ;fastcgi_buffer_size 32k ;fastcgi_pass unix:/run/php/php-fpm.sock;fastcgi_param DOCUMENT_ROOT $realpath_root ;fastcgi_param SCRIPT_FILENAME $realpath_root $fastcgi_script_name ;fastcgi_param REMOTE_ADDR $remote_addr ;
对于上面修改的不同配置项的作用如下
set_real_ip_from 127.0.0.1/32;
set_real_ip_from指令用于指定哪些IP地址可以设置真实IP地址。在这种情况下,127.0.0.1/32表示本地地址。这是因为Cloudflare Tunnel将流量转发到您的本地服务器,通常表现为来自127.0.0.1(即本地主机)的请求。 这条指令告诉Nginx,如果请求来自本地主机(127.0.0.1/32),则应该考虑使用另一个HTTP头中的IP地址作为访问者的真实IP地址。 real_ip_header CF-Connecting-IP;
real_ip_header指令用于指定包含真实客户端IP地址的HTTP头。CF-Connecting-IP是由Cloudflare设置的一个特殊的HTTP头,它包含了发起请求的原始访问者的IP地址。通过这个配置,Nginx将使用CF-Connecting-IP头中的值来重写访问者的IP地址,这样PHP应用程序就可以获取到访问者的真实IP,而不是Cloudflare Tunnel的本地地址。 在PHP FastCGI 配置块中添加的指令:
fastcgi_param REMOTE_ADDR $remote_addr;这一行将Nginx内部变量$remote_addr的值传递给FastCGI进程。由于我们已经使用set_real_ip_from和real_ip_header配置了Nginx,$remote_addr将包含经过Cloudflare处理的真实客户端IP。 通过将此参数传递给FastCGI(在这种情况下是PHP-FPM),在PHP应用程序中的$_SERVER['REMOTE_ADDR']将包含正确的客户端IP地址。
+
+ 小技巧
+
+
+
+
+
+
+ cloudflare
+
+
+
+
+
+
+
+
+ 虚拟化:初识IOMMU(TODO)
+ /p/4416e368.html
+
+ 最近在尝试给朋友的小主机安装ZStack作为虚拟化管理平台的时候,遇到了一个需求:通过HDMI直接将Windows虚拟机的画面输出到外界显示器。需要解决这个问题自然而然的就需要使用直通的方法将显卡直通给虚拟机。不过之前直通都是直接找别人的博客一步一步傻瓜式执行下去,对于每个指令发生了什么,以及iommu是如何工作的都不清楚。刚好趁着这个机会了解并记录下自己的学习历程
我自己现在有一台基于Proxmox VE的All in one小主机了,这里就叫做主机A,而我朋友的主机则称为主机B。在安装ZStack之前,我原以为直通的过程依旧可以无脑用脚本来实现,但是实际执行过程中却发现在PVE中应该成功的ACS的改动在ZStack中却并没有成功。这便引起我了从ACS到IOMMU作用的好奇。
首先,在主机A和主机B的BIOS上都启用IOMMU的功能,可以发现原本的iommu分组都十分混乱,大部分设备杂糅在一起。为了解决这个问题,便有了叫做ACS的技术。
ACS的主要功能
设备隔离 :ACS允许对PCIe设备进行更细粒度的控制,增强了设备间的隔离。这在虚拟化环境中尤为重要,因为它可以帮助确保虚拟机之间的安全隔离,防止一个虚拟机访问另一个虚拟机的PCIe设备。控制I/O访问 :ACS可以控制PCIe设备的I/O访问,例如控制哪些设备可以发起对其他设备或内存的直接内存访问(DMA)。提高安全性 :通过对设备间访问的更严格控制,ACS有助于提高系统的整体安全性,尤其是在多租户或需要高安全性的环境中。通过启用iommu的同时启用acs,就可以将系统中iommu的group分成更细的设备单位,具体修改的操作实现参数可能不尽相同,但是基本上都是先对/etc/default/grub中的GRUB_CMDLINE_LINUX进行修改,添加amd_iommu=on和pcie_acs_override=downstream,multifunction即可
对于分组情况的查看,在PCI passthrough via OVMF - ArchWiki (archlinux.org) 可以找到一个脚本来列出当前的IOMMU Groups的情况
1 2 3 4 5 6 7 8 # !/bin/bash
当我在自己的PVE主机上执行这个脚本之后,可以发现显卡是单独在一个Groups中的
但是在ZStack平台上执行以后可以发现核显并不是单独在一个Groups里面的
当时的log没有保存,这里假象一个其他的例子代替,是一个GTX 970显卡的例子,一般来说独显是会有单独的Groups的
1 2 3 4 5 6 7 ......
具体问题的产生原因还不清楚(找到问题以后会来更新博客),不过就IOMMU的分组情况大概是这样。
对于什么是iommu,找到这样一个简单扼要的概括
大家知道,I/O设备可以直接存取内存,称为DMA(Direct Memory Access);DMA要存取的内存地址称为DMA地址(也可称为BUS address)。在DMA技术刚出现的时候,DMA地址都是物理内存地址,简单直接,但缺点是不灵活,比如要求物理内存必须是连续的一整块而且不能是高位地址等等,也不能充分满足虚拟机的需要。后来dmar就出现了。 dmar意为DMA remapping,是Intel为支持虚拟机而设计的I/O虚拟化技术,I/O设备访问的DMA地址不再是物理内存地址,而要通过DMA remapping硬件进行转译,DMA remapping硬件会把DMA地址翻译成物理内存地址,并检查访问权限等等。负责DMA remapping操作的硬件称为IOMMU。做个类比:大家都知道MMU是支持内存地址虚拟化的硬件,MMU是为CPU服务的;而IOMMU是为I/O设备服务的,是将DMA地址进行虚拟化的硬件。
而在这其中,IOMMU分组则是实现设备直通的关键,每个分组都包含了可以共享一同一个虚拟内存映射的设备集合。如果一个设备独占一个IOMMU分组,直通它是很简单的。但是如果多个设备共享同一个分组,比如显卡和USB接口,那么就无法只直通其中一个设备。
后续就是找时间尝试研究为什么ACS在ZStack中没有正常被启用,并将结论补充到这篇博客当中。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ iommu
+
+
+
+
+
+
+
+
+ 知识复盘:操作系统的作用
+ /p/e429c37a.html
+
+ 该部分博客为自己在学习《程序员的自我修养:链接、装载与库》的时候对于过去零碎知识点的一个整理和复盘,并非照搬原文,其中会加入一些自己的联想与理解,如有错误还请指出。
操作系统在计算机中主要有两个功能:
在计算机的使用过程中,需要消耗时间的任务部分大致可以分为两种情况:
消耗CPU算力的计算密集型操作 需要等待设备响应处理的I/O密集型操作 我们知道在计算机中有南桥和北桥两个概念,北桥连同了CPU等高速芯片,而南桥则负责了磁盘、鼠标、键盘等低速设备。因此我们可以抽象出一个结论:计算密集型操作 和 I/O密集型操作 是由不同的设备分别处理的。接下来对于操作系统调度分析则会都以这一前提条件进行分析。
假设我们现在需要完成一个很复杂的数学问题,且假设完成这个数学问题分为两个步骤:
在草稿纸上"随意"的打草稿并推演计算过程,最终计算出答案(计算密集型操作) 将整个推演过程有条理并工整的誊抄在答卷上,便于他人阅读自己的答案(I/O密集型操作) 那么如果我们有很多个这样的题目需要完成。那么最高效的方法自然是分配两个同学A和B。假设同学A的计算能力很强,同学B的书写则十分端正,同时可以看懂同学A的草稿,那么我们便可以让同学A只需要负责计算和打草稿,只要做完了第一题就直接开始写第二题,而同学B则在同学A开始计算第二题的过程中开始誊抄第一题的答案。这样便可以让同学A和同学B的时间都统筹利用起来,以此提升效率。
在计算机中也是同样的道理。在计算机刚刚发展的时候,每次执行一个任务都需要先让CPU计算完后,CPU还要等待诸如打印机等设备输出了结果以后,再进行下一个问题的计算。
为了解决这个问题,人们便想到使用一个监控程序来监管CPU的运算,当监控程序发现在CPU进行完毕某一次运算以后,如果后续还有其他问题需要使用CPU进行计算的话,则让CPU直接进行下一个问题的计算,而不是等待第一个问题的I/O操作进行完毕以后再进行第二个问题的计算。这就是多道程序的雏形
但是随着计算机功能的逐步发展,多道程序则体现出了一个弊端:那就是任务的执行需要所有人都依次排队,前面的人如果没有解决他的问题就轮不到下一个人。
假设在银行中有一个人的业务处理需要花费特别特别长的时间,从而导致后面所有人直到银行下班都没完成自己的业务,这无疑是非常令人恼火的一件事情。但是如果这个人将自己的一个任务拆分成多个不同的部分,每完成一个部分就让后面的人先处理下,这样相对而言就能顾及他人的感受,有利于提高处理问题数量的效率。
因此,我们就了分时系统的概念,在分时系统中,程序可以通过在编写的时候主动调用某个“系统调用”来实现通知操作系统我现在这部分的工作已经完成了一部分,如果后面有其他任务需要执行的话可以先执行其他的任务,再来执行我的任务。从而在一定程度上解决了阻塞问题。
但是分时系统在计算机的衍变过程中也展现出了自己的弊端。
依据以下两个分时系统 的特点:
是否让出CPU是由程序自身决定的。程序需要主动调用特定的系统调用来通知操作系统它愿意让出CPU。 这种机制的问题是,如果一个程序不主动让出CPU(例如,由于编程错误或恶意行为),那么操作系统不能强制地从该程序中夺回CPU控制权。因此,其他程序可能会被迫等待,导致整个系统的响应性下降。 假设我们遇到一个程序员在程序中忘记调用分时的“系统调用”,还写了一个死循环的错误代码。那么整个操作系统都将会因为这个问题而出现宕机。
由此我们就需要一个更高端的操作系统来解决我们的问题,即现代操作系统的解决方案:多任务系统。
多任务系统 的基础是建立在此时操作系统对所有硬件资源进行了直接的接管。而所有的应用程序都以进程(Process)的方式运行在操作系统这个大Boss之下。所有进程的调度都需要受到操作系统的管理,并且每个进程和进程之间就像是一个小房间,他们的地址空间也都是相互隔离且独立的。
在这种情况下,CPU就变成了操作系统大Boss来进行管理的一个资源,而不是和之前分时系统一样由应用自己直接对CPU进行管理了。这样的好处是可以让所有程序都听操作系统这个领导的话,而不是和之前一样我想一直占用CPU就一直占用,如果我不调用接口主动释放CPU你们谁都别想用上CPU。
对于操作系统来说,每个进程就是一个任务,每个任务则又有自己的任务优先级。对于优先级高的任务,操作系统会先进行;对优先级低的任务则后执行。如果一个进程的运行时间超过了某个限制,则会将该程序暂停以分配给其他同时间内也许更需要CPU资源的线程任务。
在此基础上还会牵扯到一些诸如多级反馈队列、上下文切换开销等问题。这里就不做过多的展开。
这里放一个之前写OSTEP课后实验相关的博客链接,便于自己查阅
有关于设备驱动的内容直接概述过于枯燥无味,因此下面这段解释为使用 GPT-4 生成的一个概述,觉得生动有趣就搬上来了
想象一下,你正在玩一个超级复杂的电子游戏,但你只需要按下一个按钮,就能完成一个复杂的动作,比如打怪兽或跳跃。这个按钮就像是操作系统,而那些复杂的动作就是硬件的操作。你不需要知道每一个细节,只需要按下按钮,游戏就会为你完成所有的事情。
操作系统就是这样的“神奇按钮”。它位于硬件之上,为上层的应用程序提供了一个统一的方式来访问硬件。想象一下,如果每次你想在屏幕上画一条线,都需要知道你的电脑使用的是什么显卡、屏幕的大小和分辨率,然后写一大堆复杂的代码。这听起来很麻烦,对吧?但是,有了操作系统,你只需要调用一个简单的函数,比如LineTo(),然后操作系统会为你处理所有的细节。
在操作系统的早期,程序员确实需要直接与硬件交互,这是一件非常繁琐和复杂的事情。但随着时间的发展,操作系统逐渐成熟,它开始为程序员提供了一系列的“抽象”概念,使得程序员可以更加轻松地开发应用程序,而不需要关心硬件的细节。比如,在UNIX系统中,访问硬件设备就像访问普通文件一样简单;在Windows系统中,图形和声音设备被抽象成了特定的对象。
但是,谁来处理这些复杂的硬件操作呢?答案是:硬件驱动程序 。它们是操作系统的一部分 ,专门负责与特定的硬件设备交互。这些驱动程序通常由硬件制造商开发,而操作系统提供了一系列的接口和框架,使得这些驱动程序可以在操作系统上运行。
最后,让我们以读取文件为例。当你想读取一个文件时,你不需要知道这个文件在硬盘上的具体位置。你只需要告诉操作系统你想读取的文件名,然后操作系统会找到这个文件在硬盘上的位置,读取它,并将数据返回给你。这一切都是由文件系统和硬盘驱动程序共同完成的。
总之,操作系统就像是一个超级英雄,它为我们处理了所有复杂的硬件操作,使得我们可以更加轻松地开发和使用计算机程序。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ DNS问题排查思路
+ /p/23c3db21.html
+
+ 这篇博客主要是在推特中无意翻到了这篇博客,尝试以翻译的形式做一套笔记,分享的同时加强自己的记忆。
当我们发起一个DNS请求的时候,基本上发生的就是下面两件事
电脑向一个被标记为resolver的服务器发送一个DNS请求。 resolver服务器首先会检查缓存,并且在必要的时候再向authoritative nameservers发送查询请求。但是在这两件事情背后,我们有几个问题需要思考
解析服务器(即上面提到的resolver)的缓存中存放了一些什么东西?
在计算机中,在发起一个DNS请求的时候调用的是哪一部分的库?
举个例子,一个请求有可能是由libc中提供的getaddrinfo发起的,这部分代码或是来自glibc,或是musl,又或者是apple提供的库文件;这个请求也有可能是在浏览器中发起,由浏览器进行处理;当然也有可能是某些特定的自定义实现。
在不同的阶段和方法进行DNS请求做的事情都会略有不同,他们或多或少会有不一样的配置、缓存以及功能。举个例子来说,直到今年(2023)musl的DNS才开始支持TCP询问
解析器和权威域名服务器(即上文中提到的authoritative nameservers)之间是如何进行通话的?
在这里我们如果能知道在DNS请求期间询问了哪些下游的权威域名服务器,以及他们提供了哪些信息,则很多东西都会非常好理解。
为了让我们可以在获取DNS请求的时候,获取到更多的调试信息,我们可以尝试用dig工具来获取一些信息。一个例子如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ dig @223.5.5.5 whatdontexist.lol ] 8:26 PM
在上面这个示例中,我通过向一个不存在的域名:whatdontexist.lol发起了一个DNS请求。我们可以在这里看到许多有意思的信息,比如我们是对223.5.5.5这个DNS服务器,通过UDP发起的请求等等。
通过使用dig,我们可以知道很多额外的信息。举个例子,我们可以使用dig +norecurse指令来弄清楚DNS解析服务器目前有没有针对某个特定记录的缓存。对于某个特定的记录,如果不存在缓存,则会返回一个SERVFAIL的状态
举个例子,我们首先可以向223.5.5.5这个阿里的DNS请求www.baidu.com的DNS条目(大概率来说应该是缓存了百度的域名解析的)
我们可以看到上图中获取到的status为NOERROR,也就意味着百度在阿里云的DNS服务器中可以正常返回需要的结果。
现在我们再尝试请求一个不是很常见的域名homestarrunner.com,我们可以发现status变成了SERVFAIL
这里的SERVFAIL并不代表不存在对于homestarrunner.com的域名解析,只是在阿里云的服务器中并没有缓存这个域名而已。
不过对于上面这一长串由dig提供的调试信息,如果我们不是经常和它打交道的话看着还是会有点迷惑。比如:
->>HEADER<<-,flags:,OPT PSEUDOSECTION:,QUESTION SECTION:,MSG SIZE rcvd: 59这些都是啥玩意?为什么有的地方看起来是新内容但没换行(比如OPT PSEUDOSECTION:和QUESTION SECTION:)? 为什么有的返回报文中MSG SIZE rcvd: 59这里是59,而有的报文又是90?不同的报文之间是有啥不同的字段吗? 总之,从上面的一些问题中,我们可以发现dig的一些输出内容有点像是某些人临时写的一个用于获取这些信息的脚本,而并非有意为了可读性进行一些刻意的设计,为此我们有的时候需要查阅文档来搞懂发生了什么。
这里有一篇文章是原博客作者介绍了如何使用dig的:How to use dig (jvns.ca)
还有三个工具可以用于更友好的进行一些简单的调试:
不过对于这些工具有的时候会缺少一些高级功能,比如在原博客发布的时候dog和doggo都还不支持+norecurse这样的功能。所以有的时候学会dig还是有用的
通过添加一个+yaml的参数,可以让dig的输出信息更加格式化。不过这样的缺点是返回的信息有点太多了。
在DNS请求中,总是会出现一些奇奇怪怪但是容易不小心就掉进去的陷进。
一些更常见的问题可以翻阅这篇博客:Some ways DNS can break (jvns.ca)
被动缓存:由于DNS会记录不存在的域名 ,因此假设你在类似cloudflare一类的平台添加自己的DNS解析之前,如果先在自己电脑上访问并被系统缓存了"该域名不存在解析条目"这个结果,即使你后面为这个域名添加了有效的记录,但也要等到之前那条缓存失效了,新的有效结果才能被识别到。
在不同平台上对于getaddrinfo的实现并不相同,比如在今年之前,你是没法通过tcp来在musl平台上发起一个dns请求的。
有的解析服务器并不尊重解析本应该有的TTL,比如原本你设置了一个域名abc.com的TTL为一分钟或者两分钟。但是路由器认为大部分网络服务都是稳定的(对于非开发人员来说其实倒也是),有可能就会忽略这一点,而硬给你设置一个比如一两个小时的TTL。结果就会导致本来两分钟就应该生效的修改过了一两个小时都没好
在Nginx中,如果你按下面的方式配置了一个反向代理
1 2 3 location / {proxy_pass https://some.domain.com;
那么Nginx只会在第一次启动的时候尝试解析这个域名,之后则再也不会进行解析。如果你在这个过程中修改了some.domain.com域名指向的IP,就很有可能会出现一些不应该出现的问题。
这个问题实际上也有一些解决方案,不过不是这篇博客的重点
ndonts会使得k8s中的DNS请求变慢:Kubernetes pods /etc/resolv.conf ndots:5 option and why it may negatively affect your application performances (pracucci.com)
由于我自己对k8s目前接触不多,因此这里只是贴了一个链接。等以后有接触以后再回过头来研究研究
在DNS上踩坑往往可能是一件不起眼,但是遇到了就挺难排查的问题。也许最好的解决方案还是尽可能的去见识下别人遇到的问题。再放一次作者记录的常见问题:Some ways DNS can break (jvns.ca)
]]>
+
+ 知识记录
+
+
+
+
+
+
+ DNS
+
+
+
+
+
+
+
+
+ 网络抓包记录
+ /p/3930e42b.html
+
+ 这个博客主要记录了自己尝试通过抓包分析并解决一些问题的心路历程,从结果上来说很可能问题并没有解决,但是尝试解决这个问题的过程中遇到的一些问题以及自己的思考想通过写博客的方式先记录下来,在以后自己知识储备扩充的时候也许就可以回过头来看看解决下。
今天在尝试部署zerotier的zeronsd私有DNS服务的时候遇到了一个问题:无论是在我之前国内的服务器A上还是香港的服务器B上,zeronsd的部署都是只需要无脑复制粘贴指令就能成功,但是今天尝试在新租赁的国内服务器C上部署的时候则遇到了一个报错:Error Response
在翻阅zeronsd源码的时候发现这块逻辑本来应该是对应请求zerotier那边获取到局域网内所有设备的IP以便于创建私有的DNS条目。
可以看见这部分错误处理里面并没有Error Response的产生原因,而且同时我在香港的服务器上依旧可以正常使用zeronsd。因此也产生了想尝试通过抓包找到问题所在的想法。
lsof获取目标IP既然知道了问题是来自于zeronsd,而且应该是一个和网络Response有关系的问题,那么通过抓包应该是最通用的排查方法。在这里首先通过lsof工具查询zeronsd打开的连接
最开始找到的指令是先通过pidof zeronsd找到进程的pid,然后通过pid来用lsof查询,指令大概是lsof -p $(pidof zeronsd),结果后面翻了下lsof的手册,发现可以直接用-c来找进程,不过pidof以后也感觉会用到,姑且做个记录。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@Aliyun:~]# lsof -c zeronsd
可以发现下面有创建一个TCP连接,并且是处于SYN_SENT的状态。同时在我短时间内重复输入lsof的指令(蠢但有效.jpg),发现返回的依旧是SYN_SENT。一般来说SYN握手的速度应该是很快的,这里很长时间内都处于SYN_SENT的状态就明显很不对劲,所以接下来就需要通过抓包来分析。
在我多次尝试了lsof之后,发现即使有的时候能让连接处于ESTABLISHED的状态,但是过了一会以后依旧会被掐断,并且返回Error Response。通过分析不同的lsof建立TCP连接的目标ip,发现服务器总是向151.101.109.91和146.75.113.91建立连接,应该是请求的域名有做CDN所以解析到了不同的IP。接下来知道了目标IP,抓包就很容易了。这里采取的是通过tshark在配置较弱的服务器上获取到了数据包以后再导出到本地计算机的Wireshark的方法进行分析。
tshark抓包分析首先使用下面的指令对所有http请求进行抓取,并将抓包的内容保存在data.cap文件中
1 tshark -d tcp.port==443,http -w data.cap
之后再将这个文件下载到本地电脑使用Wireshark过滤选定目标IP追踪TCP流,可以发现数据流如下图
可以发现就这一次的数据来说SYN握手的部分是成功了的,TLS的四次握手也能成功建立,但是在发送了一些应用数据之后,云的服务器就开始向远端服务器发送RST报文来请求强制终止连接了。重新抓包以后又发现出现了多次TCP数据包的重传。
对于在TCP连接中,先发送了FIN,然后发送RST的一个可能性的原因如下:
您的流中的FIN和RST数据包并不直接相关。通过发送FIN,表示没有更多要发送的数据。它仍然可以从连接的另一端接收更多数据。然而,当有更多数据到达时,发送RST来表示应用程序将不再从套接字读取任何数据。
如果一个应用程序想要干净地关闭TCP连接而不引发任何RST数据包,则必须首先使用shutdown系统调用关闭写入套接字,同时保持读取套接字处于打开状态。在关闭写入套接字之后,它仍然需要读取所有对方要发送的数据,然后才能完全关闭套接字。
但是zeronsd对于这次连接的重置是返回了Error的,所以基本上可以判断并不是zeronsd本身发送的rst阻断连接。
在这里为了让后续抓包更容易复现,首先对于TLS建立握手的第一个数据包,我们可以直接查询到域名
之后我就尝试通过curl -vL my.zerotier.com的方法来通过抓取curl包分析问题。为了区分成功和失败的区别,我在这里也使用了curl -vL www.baidu.com作为对照组。
返回的抓包内容大致如下:
可以发现整个连接没有大问题,只是在连接结束以后百度那边发送了一个rst包给我们,但是tcp的四次挥手是正常完成了的。
可以发现在想要结束连接的时候并没有正常挥手,在客户端这边接收到服务器那边的FIN之前就开始给服务器发送RST报文尝试断开连接
这次抓包本身没有获取到啥决定性的信息可以确定问题产生的原因,因此目前自己也只能借由Zerotier和百度请求的对比,怀疑是因为Zerotier是国外网站,被服务商阻断了(但是在FIN之后再阻断也很奇怪,虽然会在FIN之后发送RST报文,但是curl还是可以读取到my.zerotier.com的网页信息),暂时对进一步的排查没有头绪。
我尝试在同一台服务器上部署一个VOIP服务器。也是一样使用别的服务器的时候一点问题都没有,但是在这台国内的服务器上就遇到问题了。这次遇到问题就想尽可能的搞懂原因,因此做了以下实验
实验设备:一台香港服务器(对照组),一台阿里云国内服务器(样本组),以及自己的Windows设备
实验情景:在香港和国内服务器上都部署Mumble的服务器(一个VOIP程序),然后使用Windows对这两台服务器进行连接,其中Mumble连接采取了TLS加密的方式,加密证书均为自签。
实验步骤:
使用IP直连香港服务器上在端口64738部署的murmur(Mumble服务端的别称) 使用域名voice1.abc.com连接香港服务器在端口64738部署的murmur 使用IP直连国内服务器上在端口64738部署的murmur 使用域名voice2.abc.com连接国内服务器在端口64738部署的murmur 实验期望:四种不同的方式连接murmur都能成功,且不会有明显区别
实验结果:方法1-3都可以正常访问,但是方法4连接被服务器阻断
在对以上四种情况进行抓包以后,获取到的Wireshark图像大致如下
香港服务器使用域名连接
香港服务器使用IP直连
国内服务器使用IP直连
国内服务器使用域名连接
到这里基本上很明显可以发现只有在国内服务器使用域名连接的时候,服务器那边会在进行TLS握手的时候直接进行阻断,让你无法成功建立TLS连接
这次抓包也没获得啥特别有用的信息。不过由于这个问题是在用阿里云的时候才遇到,之前用同样在国内的腾讯云没有遇到,则初步怀疑是阿里云对任意端口(非443)现在都做了备案检测,只要是没备案的域名/网站,无论是TLS还是明文,只要检测到你用了域名就禁封。相比之下腾讯那边就要宽松一些,至少murmur在腾讯云上是可以正常使用域名进行连接通讯的。
]]>
+
+ 小技巧
+
+
+
+
+
+
+ Wireshark
+
+
+
+
+
+
+
+
+ 基础算法(一)
+ /p/83fa91fc.html
+
+ 题目链接:785. 快速排序 - AcWing题库
快排的主要思想是基于分治
对于一整串数组,首先找到一个值作为分界点。分界点的取值有三种取值方法:
让分界点(设为x)前面的区间部分全都是小于等于x的值,数组后面的部分则都是大于等于x的部分。
再对区间的左和右分别进行排序,只要两侧都成功排序那么整个区间就完成了排序。
该问题在处理的过程中主要的操作就是调整区间。并且最后的效果是让区间处于了两种互斥的不同状态。因此可以用双指针的做法,同时从前和末端向中间进行扫描,当他们一方扫描到需要进行交换的异端分子的时候,就等待另一端也扫描出同样的异端分子。当双方都扫描到对方的异端分子的时候,只需要将这两个异端分子同时交换,当两个指针相遇的时候,也就是处理好了所有异端分子的时候。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void quick_sort (int q[], int l, int r) if (l >= r)return ;int x = q[(l + r) / 2 ], i = l - 1 , j = r + 1 ;while (i < j) {do while (q[i] < x);do while (q[j] > x);if (i < j)swap (q[i], q[j]);quick_sort (q, l, j), quick_sort (q, j + 1 , r);
题目链接:786. 第k个数 - AcWing题库
分界点的选取和快排相同。不同的是由于我们这里只需要第k小的数,因此在此时对划分出来的区间长度进行判断。如果k的大小小于左区间长度l,那么说明k在左区间,继续从左区间寻找第k小的数。如果k的大小大于l,说明k在右区间,在右区间寻找第(k - l)小的数。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int k_sort (int l, int r, int k) if (l >= r)return q[l];int x = q[(l + r) >> 1 ], i = l - 1 , j = r + 1 ;while (i < j) {do while (q[i] < x);do while (q[j] > x);if (i < j)swap (q[i], q[j]);int sl = j - l + 1 ;if (k <= sl)return k_sort (l, j, k);else return k_sort (j + 1 , r, k - sl);
题目链接:787. 归并排序 - AcWing题库
确定分界点:mid = (l + r) / 2 分别递归排序左区间和右区间 将两个数组合并 归并排序的主要思路就是将原本一个大数组,使用分治的思想,从单个数字的小数组进行不断的归并,最后获得的就是一个有序的新数组。因此主要的操作也就是在合并的这个操作上。
我们需要合并的数组有两个,因此这部分只需要用两个数组分别指向这两个数组的开头。然后再创建一个临时数组用于存放归并的结果。归并的过程中只需要每次都将两个指针中最小的那个输入加入临时数组中,然后将存入的指针后移,直到两个数组中其中一个被归并完毕,再将另外一个数组后面所有的结果合入答案的临时数组,最后将临时数组的结果写入原数组中即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void merge_sort (int q[], int l, int r) if (l >= r)return ;int mid = (l + r) >> 1 ;merge_sort (q, l, mid), merge_sort (q, mid + 1 , r);int merged = 0 , i = l, j = mid + 1 ;while (i <= mid && j <= r) {if (q[i] <= q[j]) {else {while (i <= mid) {while (j <= r) {for (i = l, j = 0 ; i <= r; i++, j++) {
题目链接:788. 逆序对的数量 - AcWing题库
逆序对:5 2 2 1 4,只要前面一个数比后面一个数字大,即为一个逆序对,因此有[5, 2], [5, 2], [2, 1], [5, 1], [5, 4]。这五个逆序对
首先,这个问题可以在对一个区间对半切割以后分为三种情况
在左区间中存在两个数字是逆序对 在右区间中存在两个数字是逆序对 在中间的两个黄色中,左区间存在一个数字是右区间的逆序对 其次,在这里引入归并排序的思想。在归并排序中,对于整个区间的排序本质上是对于最小区间(两个数字)之间的大小比较和扶正,最后扩展为整个区间的大小比较和扶正(分治)。带入到这个问题中,其实就是首先视 第三种情况 为最小的情况,然后最后的所有结果其实都是第三种情况的总和,所谓的第一种情况和第二种情况将会在最小区间的过程中被直接统计进入结果当中,也就是说我们只需要求出所有第三种情况逆序对的数量再加起来就是最后答案。
目前我们只考虑黄色的情况,因此对于一个区间,我们可以分成p和q两个部分来考虑。假设在p和q上有符合归并排序的两个指针i和j,且当前的情况符合了逆序对的p[i] > q[j]的定义。此时我们可以很容易就知道从i到mid这整个区间的数字都是大于q[j]的,而这个区间内数字的数量为mid - i + 1。通过这个规律,我们就可以知道如果我们想要统计所有的黄色情况中逆序对的数量,我们只需要将所有符合p[i] > q[j]情况的mid - i + 1数量加起来,就是最后答案。
代码实现:
关于计算逆序对的数量问题,假设总共有n个数据,由于每两个数据是一组,从n和n-1可以为一组的情况下来考虑,最后总共可以有(n(n - 1))/2大小的答案,如果数据集到达了类似100000量级的时候,最后答案会超过int的范围,因此有可能需要使用long long
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 const int N = 100010 ;int tmp[N], q[N], n;long long count_pair (int l, int r) if (l >= r)return 0 ;int mid = (l + r) >> 1 ;long long res = merge_sort (l, mid) + merge_sort (mid + 1 , r);int merged = 0 , i = l, j = mid + 1 ;while (i <= mid && j <= r) {if (q[i] <= q[j]) {else {1 ;while (i <= mid) {while (j <= r) {for (i = l, j = 0 ; i <= r; i++, j++) {return res;
二分算法的本质为在一个区间中,存在一个位置使得区间的性质发生了变化,进而来寻找这个变化的点。
以上面这个图为例,对于红色区间和绿色区间,假设他们有不同的性质,且一个以A作为分界点,一个以B作为分界点。那么在使用二分的时候就有两种考虑
在分类之前,首先对于所有的二分情况都有一个check()函数,用于判断某个点是否符合某个状态。在这里我们假设为某个点是否符合某个颜色(红/绿)区间的范围内
如果我们需要使用二分法来取得A点的位置,那么假设我们先设了中点mid=(l + r)/2,那么就有两种情况。第一种情况是mid处于红色范围内,那么我们便很容易可以知道点A一定在mid到r之间
此时我们只需要有新的l = mid,然后从l到r中再次进行二分,直到l和r不为l < r的关系即可
和上图相反,如果我们是mid处于了绿色范围中,那么我们首先可以知道的是,mid这个点自身是不符合红色区间的范围的。因此我们也只需要有新的r = mid - 1即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 int bsearch_left (int l, int r) while (l < r) {int mid = (l + r + 1 ) >> 1 ;if (check (mid)) {else {1 ;return l;
绿色区间和红色区间主要思路完全相同,只有区间在移动边界的时候条件不同。当需要右移区间的时候,有l = mid + 1,而区间如果要左移,只需要r = mid即可。因为这里这里不存在mid当区间长度为2的时候,如果右移区间会死循环的问题,因此mid直接取(l + r) >> 1即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 int binary_search (int l, int r) while (l < r) {int mid = (l + r) >> 1 ;if (check (mid)) {else {1 ;return l;
题目链接:789. 数的范围 - AcWing题库
首先对于二分的题目,首先找出区分***红色区间***和***绿色区间*的check()函数。在这个题目中,主要目的是找到针对某个数字target,求出在数组中target最小的区间边界和最大的区间边界。因此可以通过 大于等于target和 小于等于target**来写出两个二分的函数,分别用于寻找左边界和右边界的位置
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int bsearch_left (int l, int r, int value) while (l < r) {int mid = (l + r) >> 1 ;if (numbers[mid] >= value) {else {1 ;return l;int bsearch_right (int l, int r, int value) while (l < r) {int mid = (l + r + 1 ) >> 1 ;if (numbers[mid] <= value) {else {1 ;return l;
题目链接:791. 高精度加法 - AcWing题库
高精度加法本质就是以字符串将数字读入以后,代码模拟手动计算十进制的过程,大于十就进一位。
模板实现:
这里一定要注意A[i]或者B[i]是否为数字,如果是字符的话还需要进行- '0'来让结果变成数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<int > add (const vector<int > &A, const vector<int > &B) {int > C;int t = 0 ; for (int i = 0 ; i < A.size () || i < B.size (); i++) {if (i < A.size ())if (i < B.size ())push_back (t % 10 );10 ;if (t)push_back (1 );return C;
题目链接:792. 高精度减法 - AcWing题库
高精度减法在实现之前,首先要确定被减项比减去的值要大,如果小的话则要提前分类讨论输出一个负号。
判断大小的一个简单实现:
1 2 3 4 5 6 7 8 9 10 11 bool operator >(const vector<int > &rhs, const vector<int > &lhs) {if (rhs.size () != lhs.size ())return rhs.size () > lhs.size ();for (int i = rhs.size () - 1 ; i >= 0 ; i--) {if (rhs[i] != lhs[i]) {return rhs[i] > lhs[i];return false ;
对于减法的模拟流程,和加法主要的不同就是借位的操作。借位主要体现在计算第i位的A[i]和B[i]的运算的时候,如果有A[i] - B[i]结果是负数的话,那么A[i]就需要向A[i + 1]进行借位。这个时候我们只需要单独使用一个变量t,如果当前运算结果为负数需要借位了则让t为1,并且在每次运算前让A[i]减去t来实现借位的操作。
同时在执行完了减法的逻辑之后,由于减法和加法不同,可能会出现"0001"这种数字,我们还需要将所有除了最后一位(因为答案可能为"0")的所有0给去掉。因为通过vector存储的数字是倒序,也就是说"0001"在数组里面是[1, 0, 0, 0]。因此我们只需要每次都把答案的末尾给剔除即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 vector<int > sub (const vector<int > &A, const vector<int > &B) {int > ans;for (int i = 0 , t = 0 ; i < A.size (); i++) {if (i < B.size ())push_back ((t + 10 ) % 10 );if (t < 0 ) {1 ;else {0 ;while (ans.size () > 1 && ans.back () == 0 )pop_back ();return ans;
题目链接:793. 高精度乘法 - AcWing题库
高精度乘法的主要思路和高精度加法差不多,这类题目通常为一个大整数乘以一个小整数。对于这种情况下的乘法,我们只需要先将大整数和之前一样序列化成一个vector<int>的变量,然后和加法一样让容器每一位都和小整数相乘,大于10的部分留给下一位用于进位即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vector<int > mul (const vector<int > &A, int b) {if (b == 0 ) {return {0 };int > ans;for (int i = 0 , t = 0 ; i < A.size () || t; i++) {if (i < A.size ())push_back (t % 10 );10 ;return ans;
题目链接:794. 高精度除法 - AcWing题库
高精度除法的题目一般形式为一个大数除以一个小数。此时假设大数是123456789,小数是11。这种情况下按照正常计算逻辑大致如下:
由于在加减乘法中,我们都是将数字以[9, 8, 7, 6, 5, 4, 3, 2, 1]的顺序存储的,因此我们在计算除法的时候需要从A[A.size() - 1]的位置开始正常除法的计算逻辑,直到A[0]。其中在每次除的过程中,假设经过上次运算(默认的r = 0)的r是r',那么在下一次计算的时候用于计算的余数则是r = r' + A[i],然后只需要将除数放入ans的数组中,然后余数继续留给下一次计算即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<int > div (const vector<int > &A, int diver, int &reminder) {int > ans;0 ;for (int i = A.size () - 1 ; i >= 0 ; i--) {10 + A[i];push_back (reminder / diver);reverse (ans.begin (), ans.end ());while (ans.size () > 1 && ans.back () == 0 ) {pop_back ();return ans;
+
+ 知识记录
+
+
+
+
+
+
+ 算法
+
+
+
+
+
+
+
+
+ 使用clink优化cmd
+ /p/82bd449c.html
+
+ 苦于powershell每次都要一秒多的启动速度,偶然这两天发现了clink这个用于提升cmd体验的工具,尝试了下发现经过简单的配置以后可以替代平时绝大部分ps的需求。因此在这里记录一下基本配置流程。
clink和clink-flex-prompt都可以使用scoop在Windows中完成安装。其中clink的大致效果就是在启动cmd的时候进行注入,来实现一些额外功能的扩展。clink-flex-prompt提供的功能则是类似oh-my-zsh的prompt自定义,让交互界面不至于太苍白
1 scoop install clink clink-flex-prompt
这两个组件都是在scoop默认的main仓库就有,不需要添加额外的bucket就能直接安装。
在使用scoop安装了clink之后,还需要使用
指令来实现每次启动cmd之前都自动启用clink,也可以使用clink inject来在当前的cmd当中暂时体验一下clink的效果
依据Clink官方文档 中的提及,原本是会有一个Use enhanced default settings的选项来默认实现一些自动填充或快捷键的功能。但在使用scoop安装clink的情况下,至少可以发现自动显示suggestions补全的功能是没有被配置好的。
对于autosuggest的功能,只需要执行下面的指令就可以实现
1 clink set autosuggest.enable true
类似zsh有一个.zshrc,对于clink来说也有一个.inputrc的文件用于初始化clink的配置文件。
使用CMD输入下面的指令来在Windows的用户目录创建inputrc
1 notepad %userprofile% \.inputrc
创建好了以后可以在其中粘贴以下内容来实现一些基本的功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 # Some common Readline config settings.set colored-stats on # Turn on completion colors.set colored-completion-prefix on # Color the typed completion prefix.in Clink.if clinkset search-ignore-case on # Case insensitive history searches.set completion-auto-query-items on # Prompt before showing completions if they'll exceed half the screen.
对于具体inputrc的配置写法可以看这里:Init File
使用scoop安装了flex-prompt以后的使用方式也很简单。只需要在cmd里面执行flexprompt configure以后,就可以像p10k那样来自定义一个自己需要的,较为美观的终端提示了。这一块都是有可视化交互的,就不做过多的赘述。
平时写代码的时候因为也主要是用Linux系统,对ls和rm这种指令已经敲出肌肉记忆了。Powershell里面对这些指令做了兼容,因此用的时候没有什么额外的感觉,但是切换到cmd的时候就会发现这些指令都不一样了,dir和del一类的指令用的很不顺手。这个时候就有两种解决方法。一种方法算是曲线救国,通过调用git-bash里面提供的工具来实现类似原生Linux的指令,这也是比较推荐的一种方式。
在Windows中安装好了Git之后,往往都会有一个git-bash,而我们则可以通过git-bash来实现一些本来在Linux才能执行的指令。而之所以能达到这种效果,是因为Git在安装好了以后在安装目录下有一个/usr/bin的文件夹,里面已经预先放好了可以使用的类似Linux中的一些基本指令,诸如ls和cat这种常用工具都已经有了。因此我们只需要在系统的环境变量中,将<Git的安装路径>\usr\bin添加到PATH中即可。
比如我是使用scoop安装了git,因此我的git安装路径如下:
1 C:\Users \Halc \scoop \apps \git \current \usr \bin
然后我就只需要在环境变量中把这个路径添加到PATH中,我就可以使用我需要的基础工具了:
cmd脚本预先配置好alias还有一种方式是创建alias,以替代原生cmd的一些指令。这种方法是我最先使用的方法,后面发现了git-bash中的工具是需要额外配置环境变量以后就没有使用这种方法了。
在Windows上创建alias的方法是使用doskey来执行创建,clink则支持在启动的时候自动执行一个cmd脚本,来实现doskey的读入。为此clink默认会从以下路径来寻找clink_start.cmd文件,用以初始化cmd控制台
Windows XP: C:\Documents and Settings\<username>\Local Settings\Application Data\clink Windows Vista以及更高的版本:C:\Users\<username>\AppData\Local\clink 如果需要修改clink_start.cmd的位置,可以参考这部分文档:File Locations
在这里我的操作系统目前是Windows 10,因此我只需要在C:\Users\<username>\AppData\Local\clink目录下创建clink_start.cmd文件,并写入以下内容
1 2 3 4 5 6 @echo off
然后保存以后,就会在下一次启动cmd之前执行这些doskey指令,来实现alias的效果了。
最后的最后,只需要在Windows Terminal里面设置cmd为默认的应用,就可以实现每次启动wt的时候,都是秒开cmd的效果了,再也不用每次都等powershell启动才能输入指令了。
+
+ 安装引导
+
+
+
+
+
+
+ Windows
+
+ cmd
+
+
+
+
+
+
+
+
+ CS144-Lab6 计算机网络:路由转发
+ /p/195b5fa9.html
+
+ 这个实验就是最后一个需要写代码的实验了。主要需要解决的问题是一个IP数据包传入之后,如何通过已有的路由表确定下一跳的IP地址
这个实验中主要的问题点就是CIDR的匹配。解决这个问题,我们只需要先将CIDR转为子网掩码,也就是以0为基数,左移(32 - 前缀)位,最后得到的也是子网掩码的值。但是这里有一个问题就是,当mask是uint32_t的时候,如果前缀的长度为0,那么子网掩码会变成255.255.255.255,但是实际上应该是0,因此我们需要对前缀是否为0进行判断。
在判断完毕之后,只需要将网关的IP地址和子网掩码按位与运算,然后将目标IP地址也和子网掩码按位与运算,如果最后的结果相同,那么就说明子网匹配
1 2 3 4 5 6 7 8 9 10 11 auto path = _route_table.end ();const auto &dst_ip = dgram.header ().dst;for (auto entry = _route_table.begin (); entry != _route_table.end (); entry++) {const uint32_t &mask = entry->prefix_length ? (~0U ) << (32 - entry->prefix_length) : 0 ;const auto network_address = entry->route_prefix & mask;if ((dst_ip & mask) == network_address) {
如果没有匹配到对应的路由规则,或者这个数据包已经经过了太多次转发都没有找到目的地,那么就将这个数据包丢弃掉。
1 2 3 4 if (path == _route_table.end () || dgram.header ().ttl-- <= 1 ) {return ;
如果没有丢弃的话,那么就只需要按照正确的接口将数据包发送出去就行,如果没有下一跳的IP地址,说明数据包已经到达了对应的目的地,只需要直接发送给目标IP即可
1 2 3 4 5 6 7 if (path->next_hop.has_value ()) {send_datagram (dgram, path->next_hop.value ());else {send_datagram (dgram, Address::from_ipv4_numeric (dgram.header ().dst));
终于也是写完了Lab0-6的所有博客总结😭,Lab7的部分不需要写代码,只需要直接运行程序聊天就行,就不写博客总结了
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ CS144-Lab5 计算机网络:Network Interface的功能
+ /p/db490294.html
+
+ 在通过TCP协议将数据包进行封装准备好以后,就需要“快递公司”来对这些数据包进行分发了。这个过程可以划分为两个部分,一个是数据包在中转转发的过程中需要经过的“中转”设备有哪些,其次就是如何选择“中转”的线路。
在网络接口的部分,主要实现的逻辑是作为发送的某一个节点,在知道了下一个中转站的IP地址以后,如何将数据包进行交付。
首先对目前的知识进行一个梳理。首先在前面四个Lab里面,主要完成的是TCP数据包从一串简单的字符串,到最后封装成一个完整的,可以用于建立连接沟通的TCP数据包。TCP数据包本身并不关心数据包是如何从源IP到目标IP的,这一部分的主要实现是由网络层的IP路由和数据链路层进行沟通。
在数据链路层中,我们假设已经通过网络层的路由知道了下一条的IP地址,但是要知道一个网口今天可以是192.168.1.1,明天就可以是10.0.0.1,因此我们只知道IP地址是不足以让我们从硬件层面将数据包进行中转发送的,我们还需要针对每一个特定网口本身的硬件地址,也就是MAC地址,来硬件和硬件之间可以正确的发送数据。
由于硬件地址和IP地址的映射关系有可能是动态的,而每次发送数据都向所有设备广播询问一次MAC和IP的映射关系的话在交流频繁的网络情况下资源利用率十分低下,因此我们也需要在中转设备中动态维护一个缓存用的映射表,同时为这个映射表中每一个条目设定对应的TTL来保证数据的实时性,在超过一定时间以后就删除该缓存。
1 2 3 4 5 6 7 8 9 10 11 12 struct ArpEntry {uint32_t raw_ip_addr;bool operator <(const ArpEntry &rhs) const { return raw_ip_addr < rhs.raw_ip_addr; }const size_t arp_max_ttl = 30000 ;size_t > _arp_table{};
而获取IP和MAC地址对应关系的这个步骤则是由ARP协议实现,在硬件自己不知道要发送的下一个网口的MAC地址的时候,他就会给所有的网口广播ARP,正确的设备识别到了这个ARP是发送给自己的以后就返回自己的MAC地址,如果不是发送给自己的则丢弃不处理。同时和TCP中的超时重传一样,ARP探针自己也有可能会因为硬件链路的问题而导致对方没有收到自己的报文,所以也需要有一个超时重传的逻辑,来让自己尽可能的收到对方的回复。
1 2 3 4 5 6 7 8 9 10 11 12 struct ArpEntry {uint32_t raw_ip_addr;bool operator <(const ArpEntry &rhs) const { return raw_ip_addr < rhs.raw_ip_addr; }const size_t arp_probe_ttl = 5000 ;size_t > _probe_table{};
在有了以上两个大体部分以后,我们就只需要实现
发送(IPV4/ARP)报文 接受(IPV4/ARP)报文 超时重传探针,以及管理ARP映射的TTL 两个部分即可。
在发送报文之前,我们首先需要将IP地址转换为uint_32,以用于报文的封装,然后检查这个IP地址我们是否已经缓存了它对应的MAC地址
1 2 3 4 5 6 7 8 9 10 11 const uint32_t next_hop_ip = next_hop.ipv4_numeric ();for (const auto &entry : _arp_table) {if (entry.first.raw_ip_addr == next_hop_ip) {break ;
如果这个IP地址对应的MAC地址我们已经缓存了,那么就只需要将这个IP报文封装成网络帧进行发送
1 2 3 4 5 6 7 8 if (next_eth.has_value ()) {header () = {next_eth.value (), _ethernet_address, EthernetHeader::TYPE_IPv4};payload () = dgram.serialize ();push (eth_frame);return ;
如果这个IP地址在我们维护的ARP映射表中并不存在对应的映射关系,那么我们首先要判断我们是否就这个IP发送过ARP探针,如果发送过探针了那么我们也没必要再发送一次,只要等待之前的探针让对方返回正确的MAC地址给我们即可。
1 2 3 4 5 6 for (auto &probe : _probe_table) {if (probe.first.raw_ip_addr == next_hop_ip) {return ;
如果没有发送的话,那么我们就需要封装一个ARP探针,用于检测目标IP对应的MAC地址,探针目标的IP地址就是IP数据包下一跳的IP,MAC地址则是广播地址(在该实验中直接将目标MAC设置为空即可)。
1 2 3 4 5 6 7 8 9 10 11 ipv4_numeric ();header () = {ETHERNET_BROADCAST, _ethernet_address, EthernetHeader::TYPE_ARP};payload () = arp_probe.serialize ();push (probe_frame);
同时由于探针有超时重传的机制,因此对于这个新发送的报文,我们也需要将其加入缓存表中并设定TTL
1 2 3
所有的代码
在接受报文的部分,我们无非会收到两种报文,一种是包含IP数据的报文,一种是对方给我们发过来的ARP报文
对于这两种报文,首先我们判断它是不是要发送给我们的或是否是一个广播的网络帧
1 2 3 4 if (frame.header ().dst != _ethernet_address && frame.header ().dst != ETHERNET_BROADCAST) {return {};
如果这是一个确定源MAC和目标MAC的IP数据包,那么我们只需要接受这个数据包然后返回对应的数据即可
1 2 3 4 5 6 if (frame.header ().type == EthernetHeader::TYPE_IPv4) {parse (frame.payload ());return datagram;
但是如果这是一个ARP探针,我们首先对其进行分析
1 2 3 4 5 6 7 parse (frame.payload ());
其中_update_arp_table用于更新arp表,具体代码如下
1 2 3 4 5 6 void NetworkInterface::_update_arp_table(initializer_list<ArpEntry> arp_entry) {for (auto &entry : arp_entry) {
在解析了网络帧之后,我们大致可以得到以下三种分类
丢弃过滤
1 2 3 4 if (dst.raw_ip_addr != _ip_address.ipv4_numeric ()) {return {};
返回我们的MAC地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (arp_msg.opcode == ARPMessage::OPCODE_REQUEST) {ipv4_numeric ();header () = {src.eth_addr, _ethernet_address, EthernetHeader::TYPE_ARP};payload () = reply.serialize ();push (reply_frame);return {};
更新自己的ARP映射表,同时检查是否有对应目标MAC地址的报文等待发送
1 2 3 4 5 6 7 8 9 for (auto entry = _probe_table.begin (); entry != _probe_table.end ();) {if (entry->first.raw_ip_addr == src.raw_ip_addr) {send_datagram (entry->first.datagram, Address::from_ipv4_numeric (entry->first.raw_ip_addr));erase (entry);else {
在这里我们只需要做两件事
对于正常的条目和探针,我们只需要让其TTL减少即可,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void NetworkInterface::tick (const size_t ms_since_last_tick) for (auto entry = _arp_table.begin (); entry != _arp_table.end ();) {if (entry->second < ms_since_last_tick) {erase (entry);else {for (auto entry = _probe_table.begin (); entry != _probe_table.end (); entry++) {if (entry->second < ms_since_last_tick) {ipv4_numeric ();header () = {ETHERNET_BROADCAST, _ethernet_address, EthernetHeader::TYPE_ARP};payload () = re_probe_arp.serialize ();push (re_probe_frame);else {
这个实验主要实现的逻辑都是数据链路层的,和之前几个Lab没有直接的关系。不过值得一提的就是在Lab4测试的时候运行的TUN和TAP很有意思。这两个词之前好奇还是在使用Clash的时候既可以是TUN也可以是TAP模式,而且通常来说TUN模式的性能要比TAP要好。当时还不知道为什么,在写完这个实验以后搜了一些资料,目前浅显的理解大致认为是TAP的网络代理模拟是有处理到数据链路层的,也就是MAC地址也进行了模拟,而TUN则只是模拟到了IP层,并没有自己的MAC地址,因此损耗也要少一些。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ CS144-Lab4 计算机网络:TCP Connection的实现
+ /p/10e77bc5.html
+
+ TCP Connection的部分本身并不难,这个实验的主要核心是学习使用tshark或wireshark一类的工具对TCP的网络状况进行分析,找出正确或错误的数据包。
在这个实验中我们需要将前面写的TCP Sender和TCP Receiver两个部分的逻辑进行合并,使得两者之间可以进行数据的传输。
除了几个可以直接调用前面实验函数的函数以外,我们主要需要完成的我认为是收到某个报文以后的处理函数segment_received(const TCPSegment &seg)和时间函数tick()。
对于接受报文这个函数,首先通过对实验报告的分析,我们可以知道我们主要要做的事情可以分为以下三个大逻辑:
记录收到这个报文的时间,无论对错 检查这个报文是否是带RST标志的报文,如果是的话则直接断开连接 如果是在LISTEN状态的时候接受到这个报文的,则要判断对方是否连接 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 0 ;if (seg.header ().rst) {stream_out ().set_error ();stream_in ().set_error ();false ;return ;if (not _receiver.ackno ().has_value ()) {if (seg.header ().syn) {fill_window ();else {return ;
接受这个报文,如果带有ACK信息则更新对方已经确认了的ackno和对方当前的window_size
1 2 3 4 5 6 7 segment_received (seg);if (seg.header ().ack) {ack_received (seg.header ().ackno, seg.header ().win);
这部分是我认为Lab4里面在理解上较难的部分。其中,TCP的断开分为三种不同的情况:
由于RST标志导致的强制退出(unclean shutdown) 正常的通讯结束而导致的关闭(clean shutdown) 但是对于第二种情况,我们可以进一步分为两种情况:
首先是最简单的四次挥手报文:
Client发送完毕数据,告诉Server我结束(FIN)了Client客户端在给Server发送完毕了所有数据以后,主动发送FIN数据包,表示自己的数据已经发送完毕了。然后Server在收到Client的FIN报文并处理完毕以后则会返回一个FIN ACK报文,来告诉Client他发过来的数据已经在服务端被处理完成了。
Server也发送完毕了数据,告诉Client我结束(FIN)了Server也会给Client发送一个FIN的报文,同样等待Client那边确认,如果Client发送了确认报文来确认这个ACK,则代表客户端那边也处理完了,这个时候按理来说首先提出数据发送完毕的Client就可以断开链接了。
但是,服务端有可能收不到 这最后一个ACK确认报文,从而导致自己一直在等待客户端向自己发送ACK确认报文。
为了避免这种情况,最简单的处理方法就是让Client给Server发送了FIN ACK报文以后不要急着断开连接,而是设置一个计时器,等待看看Server会不会重传FIN报文。
如果重传了FIN则代表Server并没有收到先前发送的FIN ACK,这个时候Client就需要重新发送一个ACK回去,告知Server可以断开连接了。
如果超过了计时器的时间,Client也没有收到Server的重传报文,那么我们就假设Server已经收到了FIN ACK,并且已经关闭了他那边的连接,这个时候Client就可以断开连接了。而这段计时器的等待时间,就是实验中的linger_time = 10 *_cfg.rt_timeout,这个时间往往是比Server超时重传的时间大很多的,也就留给了Server足够多的时间来重传FIN报文。
服务端这边就很简单了,在发送完自己的FIN之后,只需要正常等待Client的ACK确认报文,如果没有等到则重传FIN,如果等到了则直接断开连接。
知道了上面的区分以后,我们实现起来就很简单了,只需要通过添加一个变量_linger_after_streams_finish来判断到底是对方先结束还是自己先结束。如果是对方先结束,则我们不需要等待linger_time,在后面收到了FIN报文以后直接断开连接即可。否则则需要在后面tick()函数的部分添加超时断开连接的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 if (_receiver.stream_out ().eof () && not _sender.stream_in ().eof ()) {false ;if (_sender.stream_in ().eof () && bytes_in_flight () == 0 && not _linger_after_streams_finish) {false ;
这部分逻辑就很简单了,如果在接受了对方传来的有序列号消耗数据包以后,我们并没有数据要传输(即无法告知对方我们接受到了数据),那么我们就需要单独传输一个ACK数据包给对方,告知我们已经接收到了对方的数据。(如果对方发送给我们的是一个ACK数据包,我们则不需要回复,也就是收到了占用序号为零的包)
1 2 3 4 if (_sender.segments_out ().empty () &&length_in_sequence_space () || seg.header ().seqno != _receiver.ackno ())) {send_empty_segment ();
其中seg.header().seqno != _receiver.ackno()代表的是一种特殊情况,在TCP连接中,有的时候为了确认当前连接是否依旧有效,对方有可能会随机发送一个错误的序列号给我们,这个时候我们就需要回复一个ACK报文给对方,以此告知对方这个连接依旧是有效的,同时也可以让对方更新我们的窗口大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 void TCPConnection::segment_received (const TCPSegment &seg) 0 ;if (seg.header ().rst) {stream_out ().set_error ();stream_in ().set_error ();false ;return ;if (not _receiver.ackno ().has_value ()) {if (seg.header ().syn) {fill_window ();else {return ;segment_received (seg);if (seg.header ().ack) {ack_received (seg.header ().ackno, seg.header ().win);if (_receiver.stream_out ().eof () && not _sender.stream_in ().eof ()) {false ;if (_sender.stream_in ().eof () && bytes_in_flight () == 0 && not _linger_after_streams_finish) {false ;if (_sender.segments_out ().empty () && (seg.length_in_sequence_space () || seg.header ().seqno != _receiver.ackno ())) {send_empty_segment ();
另外一个需要注意的函数就是tick()函数了。其实这一部分的重要也主要是连带了前面接受报文部分的关闭连接,主要要注意的就是添加一个对linger_time的判断。整个tick()函数的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void TCPConnection::tick (const size_t ms_since_last_tick) tick (ms_since_last_tick);if (_sender.consecutive_retransmissions () > TCPConfig::MAX_RETX_ATTEMPTS) {return ;if (time_since_last_segment_received () >= _linger_time && _sender.stream_in ().eof () &&stream_out ().input_ended ()) {false ;
Lab4实验主要的难点感觉还是在即使跑通了前面大部分的基本测试,也还是有可能因为Lab2和Lab3里面的疏忽,而导致后面模拟真实通讯的时候很容易难以下手。但是在掌握了Wireshark抓包一类的工具用法以后还是很容易发现问题所在并加以纠正的。
比如我在Lab3中,对于TCPSender在填充窗口大小的时候,一开始并不是设置了一个额外的变量fill_space来控制可以发送的空闲空间的大小,而是直接使用了ack_received方法中收到的最新窗口大小,忽略了bytes_in_flight()也需要考虑在窗口占用里面的问题。在使用Wireshark抓包的时候就明显发现了发送数据包的序号要远超于接收方的确认序号
而这个问题也在我通过修改Lab3对应空闲窗口大小的逻辑之后得到了解决。
我还遇到过的第二个问题就是在小窗口的情况下,没有正确处理链接的关闭。在通过Wireshark抓包以后可以看到
在发送方还没有给接收方发送完所有数据的时候,接收方就提前终止了自己的连接,这个问题主要出在tick()函数里面关于linger_time的逻辑错误,我并没有等到接收方接受到EOF就直接关闭了链接。错误代码如下:
1 2 3 if (time_since_last_segment_received () >= _linger_time && _sender.stream_in ().eof ()) {false ;
修改后的代码如下:
1 2 3 4 if (time_since_last_segment_received() >= _linger_time && _sender.stream_in().eof()+ && _receiver.stream_out().input_ended()) {
整个Lab4的代码可以在Github的仓库查看:
tcp_connection.cc tcp_connection.hh
]]>
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ 使用Yadm管理Linux配置文件
+ /p/4457ea2b.html
+
+ 今年暑假看Missing-course的时候开始意识到备份Linux配置文件的重要性,以后即使切换机器也可以很容易的恢复自己喜欢的编程环境。在简单搜索了几个方式以后,决定使用yadm作为管理工具,并且写了一个模板,便于分享和使用。该仓库的主要用途为使用yadm作为管理工具,通过Github来同步自己的Dotfiles
先在自己当前环境下安装yadm,具体安装说明参照Installation
通过Use this template或者下载源码的方式,创建并上传到自己的一个仓库中,最好是Private类型
在本身没有经过配置Dotfiles的环境下(或提前备份好自己的Dotfiles)输入以下指令拉取模板到本地进行管理
1 yadm clone https://github.com/<your id>/<your repository> --bootstrap
在附带--boostrap的情况下执行完毕上述指令以后将会按默认模板文件使用git来对自己的Dotfiles进行管理
在clone仓库的时候如果附带了bootstrap将会自动执行以下三件事
在以 apt/yum/pacman 作为包管理器的情况下安装zsh vim tmux curl wget openssl 安装 oh-my-zsh,并以p10k为主题。安装zsh-autosuggestions,zsh-syntax-highlighting和zsh-proxy三个插件 切换 zsh 为当前用户的默认终端 配置了rust国内镜像 添加了transfer 用于分享文件(输入transfer /path/to/file即可) 使用pws作为powershell.exe的alias,便于wsl环境下使用powershell 启用了vi的normal模式,在输入命令的时候按Esc即可 配置默认使用~/.gitignore作为全局ignore`文件 在使用https时的验证交由.git-credentials文件纯文本保存密码(有风险,可加密) 对于类似.ssh/id_rsa或者.git-credentials文件可以通过yadm自带的encrypt工具进行加密,使用步骤如下
在.config/yadm/encrypt文件内写入需要加密的文件路径,支持正则匹配
假设在.ssh/目录下所有文件(例如config, id_rsa)都需要进行加密,则在.config/yadm/encrypt写入.ssh/*后输入以下指令(安装openssl为前提)
则会要求输入一个密码来进行加密
加密完则会在.local/share/yadm目录下产生一个archive作为加密打包后的文件,将该文件添加并上传到Github
虽然加密文件本身有一定安全性,但为了保险起见还是推荐使用Private仓库来存储自己的Dotfiles
1 2 3 yadm add ~/.local/share/yadm/archive
原本的文件此时将会依旧本地存在于(例如config, id_rsa),但不需要上传到Github当中
在下次重装系统/更换环境的时候,如果需要通过yadm对环境进行复原并解密加密文件,则只需要输入以下指令
就会将加密打包的文件解密到对应的文件目录,保证一定的安全性
+
+
+
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+ Yadm
+
+
+
+
+
+
+
+
+ CS144-Lab3 计算机网络:TCP Sender的实现
+ /p/73e1b791.html
+
+ 追踪Receiver返回的windows_size(可接受的剩余容量)和ackno(已经确认接收的字符位置) 只要数据来了就直接对数据进行封装并发送,只有在窗口被消耗为零的情况下才停止发送 将没有被acknowledge的数据包存储起来,在超时的时候进行发送 对于超时重传的时间判断,使用已经提供的tick()函数,每次调用的时候传入多少时间就消耗了多少时间 超时重传的默认基准值会以成员变量的形式在TCPSender中进行初始化 在TCPSegment中有一个_segments_out的成员,只需要向这个queue内push一个TCPSegment就相当于将这个数据段发送了 对于计时器的部分,为了方便抽象管理,我这里选择直接创建一个类来进行封装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class TCPTimer {private :size_t _tick_passed = 0 ; size_t _rto_timeout = 0 ; unsigned int _rto_count = 0 ; bool _is_running{false }; public :void reset (const uint16_t retx_timeout) 0 ;0 ;void run () true ; }void stop () false ; }bool is_running () const return _is_running; }unsigned int rto_count () const return _rto_count; }void slow_start () 2 ;void update (const size_t ms_since_last_tick) bool is_timeout () const return _is_running && _tick_passed >= _rto_timeout; }void restart () 0 ; }
在private的部分定义则如下:
1 2 3 4 5 6 7 8 9 10 11 size_t _ackno = 0 ;size_t _window_size = 1 ;
额外定义的函数主要作用为将已经封装好的TCP报文进行发送,如果在发送的时候检测到RTO重传计时器并没有工作,则发送的同时激活重传计时器。同时在发送了报文后对seqno序号进行消耗,移动_next_seqno指针
1 2 3 4 5 6 7 8 9 10 11 12 void TCPSender::_send_segment(const TCPSegment &seg) {const size_t seg_len = seg.length_in_sequence_space ();push (seg);push (seg);if (not _rto_timer.is_running ()) {run ();reset (_initial_retransmission_timeout);
对于需要封装的报文,大致可以分为三类,一类是最开始用于建立连接的SYN报文,一类是携带数据的PAYLOAD报文,最后一类是用于发送结束连接的挥手FIN报文。在该方法中主要的难点就是通过对目前已经确认的ackno和next_seqno等数据来判断当前需要封装的报文具体是哪一类,以及根据还未接收到的数据以及零窗口本身的机制来判断空闲的窗口大小
首先,为了防止出现对方当前空闲窗口已满,而sender就一直啥也不发的情况出现,因此在接受到的窗口大小是0的时候,要将其改为1,来避免零窗口堵塞。同时由于部分数据还在传输的路上,这一部分的数据也需要被减掉,从而得到最后的空闲大小fill_space。
1 2 size_t fill_space = _window_size ? _window_size : 1 ;bytes_in_flight ();
SYN报文的判断很简单,因为发送SYN的话无非是打开连接的建立者A自己,又或者是收到了A发来报文的B返回一个携带ACK的SYN报文进行确认。而对于A和B来说,由于SYN报文都是他们自己发送的第一个报文,因此在封装的过程中,他们的“下一个发送序列号”_next_seqno显而易见的应该为零。大致逻辑代码如下
1 2 header ().syn = (_next_seqno == 0 );
对于含有内容的报文,主要的工作就是对payload长度的合理切割,对此只需要在TCPConfig::MAX_PAYLOAD_SIZE和当前剩余``中取最小值并从_stream当中读入。
1 2 3 size_t segment_payload_size = min (TCPConfig::MAX_PAYLOAD_SIZE, fill_space);payload () = _stream.read (segment_payload_size);
在_stream发送完毕,并且被我方全部接受了的时候发送一个携带FIN的报文,告知对方我方已经发送完毕。由于FIN本身需要消耗一个序列号,因此发送前需检查当前数据段是否还有一个空位来放FIN
1 2 3 4 if (_stream.eof () && fill_space > section.length_in_sequence_space ()) {header ().fin = true ;
在标记完了FIN之后,如果这个报文依旧不占用序列号,则说明这个报文不是TCP Sender处理的部分;又或者此时在FIN已经发送的基础上,重复发送了一个FIN,这时多的FIN应该被抛弃
1 2 3 4 if (section.length_in_sequence_space () == 0 || _next_seqno == _stream.bytes_written () + 2 ) {return ;
最后总的代码如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void TCPSender::fill_window () size_t fill_space = _window_size ? _window_size : 1 ;bytes_in_flight ();while (fill_space > 0 ) {header ().seqno = next_seqno ();header ().syn = (_next_seqno == 0 );size_t segment_payload_size = min (TCPConfig::MAX_PAYLOAD_SIZE, fill_space);payload () = _stream.read (segment_payload_size);if (_stream.eof () && fill_space > section.length_in_sequence_space ()) {header ().fin = true ;if (section.length_in_sequence_space () == 0 || _next_seqno == _stream.bytes_written () + 2 ) {return ;length_in_sequence_space ();
这个感觉可能是看起来最简单的一个函数了,因为用了_ackno来记录已经确认过的报文,同时_next_seqno又代表的是将要发送的数据流位置,因此只需要将_next_seqno - _ackno返回的就是正在发送中的数据长度了。(最开始想实现的时候还在考虑要不要在每次fill_window和ack_received的时候添加计数器。。)
1 uint64_t TCPSender::bytes_in_flight () const return _next_seqno - _ackno; }
确认报文主要需要的逻辑有以下四个部分:
只处理有效并且正确的ackno。如果ackno有效,记录ackno和window_size用以fill_window()来进行报文的封装 记录ack报文中包含的窗口大小 如果曾经的报文已经确认过,则报文已经送达,将送达的报文从缓冲区中弹出,如果所有的报文都被弹出了,则关闭RTO计时器 如果接受到了对方这时的窗口又有了空闲大小,则使用fill_window()来填充新的空报文 对于判断ackno是否是正确的ackno,只需要判断ackno是否处于已经记录的_ackno和_next_seqno之间,如果在这个区间之外,意味着要么是老的ackno,要么是确认了不存在的数据,需要进行短路丢弃,逻辑如下
1 2 3 4 5 uint64_t abs_ackno = unwrap (ackno, _isn, _next_seqno);if (abs_ackno < _ackno || abs_ackno > _next_seqno) {return ;
在接受到了窗口大小之后只需要直接将其记录
1 2
这部分都是属于对于超时重传的处理,其中主要需要实现的是对缓冲区确认后的报文进行弹出,同时弹出所有报文后取消对RTO的占用,初始化超时重传的等待时间并记录当前的时间。
其中弹出操作只有在_ackno确认的是第一个报文对应的seqno和length的时候才进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bool has_reset = false ;while (not _cache.empty () &&front ().header ().seqno.raw_value () + _cache.front ().length_in_sequence_space () <= ackno.raw_value ()) {if (not has_reset) {reset (_initial_retransmission_timeout);true ;pop ();if (_cache.empty ()) {stop ();fill_window ();
最后总的代码如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void TCPSender::ack_received (const WrappingInt32 ackno, const uint16_t window_size) uint64_t abs_ackno = unwrap (ackno, _isn, _next_seqno);if (abs_ackno < _ackno || abs_ackno > _next_seqno) {return ;bool has_reset = false ;while (not _cache.empty () &&front ().header ().seqno.raw_value () + _cache.front ().length_in_sequence_space () <= ackno.raw_value ()) {if (not has_reset) {reset (_initial_retransmission_timeout);true ;pop ();if (_cache.empty ()) {stop ();fill_window ();
该函数主要的作用是推动时间流动,并且判断是否触发超时重传,如果触发了超时重传首先将计时器更新到当前时间。然后当对方窗口不繁忙的情况下(window_size非零)触发了重传就把下次重传的等待时间翻倍,并且记录一次重连;如果对方窗口正处于繁忙期(window_size为零),则不翻倍连接时间。然后再将缓冲区内第一个发送的报文进行重新发送。代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void TCPSender::tick (const size_t ms_since_last_tick) update (ms_since_last_tick);if ((not _rto_timer.is_timeout ())) {return ;if (_window_size != 0 ) {slow_start ();if (_rto_timer.rto_count () <= TCPConfig::MAX_RETX_ATTEMPTS) {push (_cache.front ());restart ();
这个函数就是直接返回次数的,直接返回_rto_timer.rto_count();的大小即可。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ CS144-Lab2 计算机网络:TCP Receiver的实现
+ /p/4e68707.html
+
+ 为了节省在TCP Header当中的空间,在StreamReassembler里面写的index虽然是一个uint64_t的类型,但是在实际的Header中是使用一个uint32_t的seqno来进行标记位置的。对于uint32_t的seqno和uint64_t的index的相互转换则是通过以4GiB (2^32 bytes)为一个长度进行取模来实现。
同时为了提高TCP本身的安全性,并且确保每次获得的segments数据段都是来自于本次连接的,因此提出了ISN(Initial Sequence Number)的概念,即本次链接是从序号为isn开始作为seqno进行通信,大于isn的seqno所代表的index是本次链接所需要的数据段,早于isn的seqno则是来自于上一次连接的老数据段,并不需要处理。
如果想要将uint32_t的seqno转为一个uint64_t则需要一个checkpoint作为定位,防止seqno被定位到错误的位置上。这个checkpoint在实现中就是最后一个重新组装后的字符位置
按lab2的原文:In your TCP implementation, you’ll use the index of the last reassembled byte as the checkpoint.
通过寻找距离checkpoint最近的seqno就可以定位到本来需要插入的seqno位置了
对于将uint32_t转为uint64_t的代码实现很简单,只需要将uint64_t的index加上isn的值之后对2^32进行取模就行了,具体代码实现如下
1 2 3 4 WrappingInt32 wrap (uint64_t n, WrappingInt32 isn) {uint64_t result = (n + isn.raw_value ()) % (static_cast <uint64_t >(UINT32_MAX) + 1 );return WrappingInt32 (static_cast <uint32_t >(result));
而对于将wrap后的seqno转回index,我直接通过类似分类讨论的枚举找到了四个临界点,只需要判断checkpoint相对于临界点的位置就可以得到答案。代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 uint64_t unwrap (WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) const uint64_t L = (1ul << 32 );const uint64_t a = (checkpoint / L) * L - isn.raw_value () + n.raw_value ();if (checkpoint > a + (L * 3 ) / 2 ) {return a + 2 * L;else if (checkpoint > a + L / 2 ) {return a + L;else if (checkpoint < L) {return n.raw_value () < isn.raw_value () ? a + L : a;else {return checkpoint < a - L / 2 ? a - L : a;
通解推导 由以下公式
( i n d e x + i s n ) m o d L = s e q n o \left ( index+isn \right )\mod{ L } = seqno ( i n d e x + i s n ) m o d L = s e q n o
通过推导可以得到
i n d e x = s e q n o + k ∗ L − i s n index = seqno + k * L - isn i n d e x = s e q n o + k ∗ L − i s n
因此如果需要得到离checkpoint最近的index就只需要找到合适的k即可,在这里不妨设
m = c h e c k p o i n t / L m = checkpoint / L m = c h e c k p o i n t / L
取m作为一个附近值,通过画图可以知道,在一般情况下,答案一定在checkpoint附近的三个区间内
在这种情况下,checkpoint的前中后三个区间都存在,只要列举并讨论范围就很简单了
当seqno - isn为正数的时候,index可能的一个取值会落在第②个区间上,有
i n d e x ′ ′ = m ∗ L + s e q n o − i s n index'' = m * L + seqno - isn i n d e x ′ ′ = m ∗ L + s e q n o − i s n
此时第①区间和第③区间上的index可以分别表示为
i n d e x ′ = i n d e x ′ ′ − L i n d e x ′ ′ ′ = i n d e x ′ ′ + L index' = index'' - L \\\\index''' = index'' + L i n d e x ′ = i n d e x ′ ′ − L i n d e x ′ ′ ′ = i n d e x ′ ′ + L
对index'、index''和index'''的中间值进行判断,很容易得到以下规律
a = m ∗ L + s e q n o − i s n L = U I N T 32 _ M A X + 1 { c h e c k p o i n t < a − L / 2 index=a-L a − L / 2 ≤ c h e c k p o i n t < a + L / 2 index=a a + L / 2 ≤ c h e c k p o i n t index=a+L \begin{array}{l} a = m*L+seqno-isn \\\\ L = UINT32\_MAX+1 \\\\ \left \{\begin{matrix} checkpoint < a - L/2 & \text{index=a-L}\\\\ a-L/2\leq checkpoint< a+L/2 & \text{index=a}\\\\ a+L/2\leq checkpoint & \text{index=a+L}\end{matrix}\right.\end{array} a = m ∗ L + s e q n o − i s n L = U I N T 3 2 _ M A X + 1 ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ c h e c k p o i n t < a − L / 2 a − L / 2 ≤ c h e c k p o i n t < a + L / 2 a + L / 2 ≤ c h e c k p o i n t index=a-L index=a index=a+L
注:此时checkpoint一定小于 a+L,因为a+L属于第③区间,而checkpoint在第②区间内
此时因为是从m*L的位置向前移动,所以相比于上面,三个可能是答案的index的分布则改为了
i n d e x ′ = m ∗ L + s e q n o − i s n i n d e x ′ ′ = i n d e x ′ + L i n d e x ′ ′ ′ = i n d e x ′ + 2 ∗ L index' = m * L + seqno - isn\\index'' = index' + L\\index''' = index' + 2 * L i n d e x ′ = m ∗ L + s e q n o − i s n i n d e x ′ ′ = i n d e x ′ + L i n d e x ′ ′ ′ = i n d e x ′ + 2 ∗ L
所以很容易得到以下结果
a = m ∗ L + s e q n o − i s n L = U I N T 32 _ M A X + 1 { c h e c k p o i n t < a + L / 2 index=a a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 index=a + L a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a+2*L \begin{array}{l} a = m*L+seqno-isn\\ L = UINT32\_MAX+1\\ \left \{\begin{matrix} checkpoint < a + L/2 & \text{index=a}\\ a+L/2\leq checkpoint< a+(3*L)/2 & \text{index=a + L}\\ a+(3*L)/2\leq checkpoint & \text{index=a+2*L}\end{matrix}\right.\end{array} a = m ∗ L + s e q n o − i s n L = U I N T 3 2 _ M A X + 1 ⎩ ⎨ ⎧ c h e c k p o i n t < a + L / 2 a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a index=a + L index=a+2*L
将以上两种规律整合,我们很容易可以得到以下通解
a = m ∗ L + s e q n o − i s n L = U I N T 32 _ M A X + 1 { c h e c k p o i n t < a − L / 2 index=a-L a − L / 2 ≤ c h e c k p o i n t < a + L / 2 index=a a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 index=a + L a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a+2*L \begin{array}{l} a = m*L+seqno-isn\\ L = UINT32\_MAX+1\\ \left \{\begin{matrix} checkpoint < a - L/2 & \text{index=a-L}\\ a-L/2\leq checkpoint< a+L/2 & \text{index=a}\\ a+L/2\leq checkpoint< a+(3*L)/2 & \text{index=a + L}\\ a+(3*L)/2\leq checkpoint & \text{index=a+2*L}\end{matrix}\right.\end{array} a = m ∗ L + s e q n o − i s n L = U I N T 3 2 _ M A X + 1 ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ c h e c k p o i n t < a − L / 2 a − L / 2 ≤ c h e c k p o i n t < a + L / 2 a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a-L index=a index=a + L index=a+2*L
特殊情况 在checkpoint < L的时候,通解中对于a - L的一部分(即checkpoint < a + L)就不适用了,不过分析起来也很简单,由于有
( i n d e x + i s n ) m o d L = s e q n o \left ( index+isn \right )\mod{ L } = seqno ( i n d e x + i s n ) m o d L = s e q n o
所以当seqno小于isn的时候,答案一定在下一个区间,因此答案即L - isn + seqno,当seqno大于isn且checkpoint < a + L,所以答案一定为a
所以就可以得到上述代码了。
这部分代码逻辑完成的是tcp握手中对于tcp段的接受处理。
我自己增加的私有成员和用途大致为:
_is_syn: 判断链接是否建立_isn: 存入第一次建立连接时接受的seqno来初始化_is_fin: 用于判断结束输入的报文是否传入对于ackno和checkpoint的实现机制是:
ackno: 本质上就是返回已经整合好的数据量,也就是bytes_stream的bytes_written(),同时建立连接后一定存在syn所以可以直接加一,之后只需要判断fin是否到达并且整合完毕,然后再次加一即可。checkpoint: 和ackno差别不大,只需要直接返回已经写入完成的字符个数即可知道了上述几个逻辑以后就只需要通过调整简单的逻辑flag加上lab1里面的push_substring来对payload()进行整合就可以通过了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void TCPReceiver::segment_received (const TCPSegment &seg) if ((_is_syn == 0 ) && seg.header ().syn) {1 ;header ().seqno;else if (_is_syn == 0 ) {return ;const uint64_t checkpoint = _reassembler.stream_out ().bytes_written () + 1 ;uint64_t stream_index = unwrap (seg.header ().seqno, _isn, checkpoint) - 1 + seg.header ().syn;push_substring (seg.payload ().copy (), stream_index, seg.header ().fin);if (seg.header ().fin) {1 ;optional<WrappingInt32> TCPReceiver::ackno () const {stream_out ().bytes_written ();if ((_is_fin != 0 ) && _reassembler.unassembled_bytes () == 0 ) {return _is_syn ? optional <WrappingInt32>(result) : nullopt ;size_t TCPReceiver::window_size () const return _capacity - _reassembler.stream_out ().buffer_size (); }
这里有一个让我感觉很疑惑的点就是在单元测试中存在两种测试样例,这里做个记录,后面如果知道了原因就来解决一下
存在同时携带SYN和FIN报文,按照正常的TCP握手感觉这是不合理的 在接受SYN的同时会接受一部分的Data进行处理,按正常的TCP也是不会这么做的
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ CS144-Lab1 计算机网络:字节流重组器
+ /p/aeda2510.html
+
+ 这个方案是采用了一个无限长的字符串cache,所有的TCP段中的部分数据先寄存在cache当中。之后通过创建一个在cache上滑动的写入位指针write_p来将能够顺序写入的内容写入_output当中,其中write_p每次滑动的距离len受限于_output还剩下的可容纳空间。
添加的私有成员:
1 2 3 4 5 6 7 8 size_t write_p;size_t end_p;
对于push_string方法的实现:
检查传入的index是否在可写入范围,如果超出可写入范围则直接退出,保证程序的鲁棒性
因为写入的数据长度不能超过capacity,因此需要将扩容的长度设置为index + data.length()和write_p + _output.remaining_capacity()中较小的那个
将传入的数据(包括可能超过范围的部分)写入cache中,同时将dirty_check中对应的位置标记为1
将cache的长度缩回到正确扩容后应该的长度,这样可以将多余的内容丢弃
检查write_p的位置上是否有数据可以被写入,如果有则通过滑动len来将内容写入_output,否则跳过
检查write_p和end_p是否相同,如果相同则代表写入结束,调用_output.end_input()
具体代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 void StreamReassembler::push_substring (const string &data, const size_t index, const bool eof) size_t extend_size = index + data.length ();if (eof) {if (extend_size > cache.length ()) {resize (extend_size);resize (extend_size);replace (index, data.length (), data);replace (index, data.length (), data.length (), '1' );if (expand_size > cache_raw_length) {resize (expand_size);resize (expand_size);if (dirty_check[write_p]) {size_t len = 0 ;size_t output_remaining = _output.remaining_capacity ();while (dirty_check[write_p + len] && len < output_remaining) {write (cache.substr (write_p, len));if (write_p == end_p) {end_input ();
对于没有统计的字符数量,直接使用一个循环进行统计即可
1 2 3 4 5 6 7 8 9 size_t StreamReassembler::unassembled_bytes () const size_t n = write_p;for (size_t i = write_p; n != cache.length () && not dirty_check[i]; i++) {return cache.length () - n;
对于判断缓冲区是否使用完毕则是
1 2 bool StreamReassembler::empty () const return _output.eof () && not unassembled_bytes (); }
使用上面这种写法的话虽然可以达到100% tests passed,并且时间也都能控制在0.5s以内,但是在复习了真实情况下的重组过程发现这个思路存在一些BUG是测试案例没有检测出来的。
以如下的test为例
1 2 3 4 5 6 7 8 9 10 {6 };execute (SubmitSegment{"defg" , 3 });execute (BytesAssembled (0 ));execute (SubmitSegment{"abc" , 0 });execute (BytesAvailable ("abcdef" ));execute (BytesAssembled (6 ));execute (SubmitSegment{"kmg" , 7 });execute (BytesAvailable ("" ));
运行后可以发现有报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Test Failure on expectation:
可以发现,本来在传入第一个defg的时候,字符g应该因为超出capacity而被抛弃,但是是将并没有,导致g停留在了index为6的位置上。读取了_output的所有内容之后,_output的窗口应该是从index为6的位置上开始准备写入,但是由于这个位置上的g在上一个窗口期中并没有被抛弃,结果导致了index为7的kmg写入的时候,连带前面存在的g一起将gkmg写入了_output的窗口当中,从而出现了以下报错。
The reassembler was expected to have 0 bytes available, but there were 4
同时对于EOF的位置判断也有类似的BUG,测试样例如下
1 2 3 4 5 6 7 8 9 10 11 {6 };execute (SubmitSegment{"defx" , 3 }.with_eof (true ));execute (BytesAssembled (0 ));execute (SubmitSegment{"abc" , 0 });execute (BytesAvailable ("abcdef" ));execute (BytesAssembled (6 ));execute (SubmitSegment{"g" , 6 });execute (BytesAvailable ("g" ));execute (NotAtEof{});
运行后得到如下结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Test Failure on expectation:
本来在第一个操作的时候作为eof的x应该是被抛弃掉并不读取的,但是在最后这个位置的eof_p还是触发了EOF判断,导致产生了不应该出现的EOF。
本质的问题就是没有丢弃掉unacceptable的字节,这里采取了一个比较省事但是很不优雅的操作,我是选择在最后扩容后重新再用resize()函数将不需要的那部分丢弃掉,来达到限制容量的目的,最后修正完毕的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 void StreamReassembler::push_substring (const string &data, const size_t index, const bool eof) bool eof_flag = false ;size_t expand_size = index + data.length ();if (index > write_p + _output.remaining_capacity ()) {return ;if (index + data.length () <= write_p + _output.remaining_capacity ()) {true ;length ();else {remaining_capacity ();if (eof && eof_flag) {const size_t cache_raw_length = cache.length ();if (expand_size > cache_raw_length) {resize (expand_size);resize (expand_size);replace (index, data.length (), data);replace (index, data.length (), data.length (), '1' );if (expand_size > cache_raw_length) {resize (expand_size);resize (expand_size);if (dirty_check[write_p]) {size_t len = 0 ;size_t output_remaining = _output.remaining_capacity ();while (dirty_check[write_p + len] && len < output_remaining) {write (cache.substr (write_p, len));if (write_p == end_p) {end_input ();
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ CS144-Lab0 计算机网络:流的输入和读出
+ /p/2ca0860a.html
+
+ lab0前后分为两个较为简单的小任务,第一个任务是写一个类似telnet中通信的webget小应用,第二个任务是实现一个简单的ByteStream的类,只需要在单线程的情况下能正常运行即可
第一个任务的参考主要是从项目文件本身的doctests开始着手,其中在提示中已经说了我们将会使用到TCPSocket和Address,在对应的doctests/socket_example_2.cc和doctests/address_example_1.cc中,我们可以得到对于他们的使用例子,只需要创建一个以目标Address初始化并连接的TCPSocket,然后以这个socket向目标服务器发送类似telnet的请求即可获得我们需要的内容
1 2 3 4 5 TCPSocket socket;connect (Address (host, "http" ));write ("GET " + path + " HTTP/1.1\r\n" );write ("Host: " + host + "\r\n" );write ("Connection: close\r\n\r\n" );
由于最后在输入完Connection: close之后,我们本来也要输入一个回车将请求发送,因此在这里需要两个换行符
在处理socket.read()的时候,起初没有仔细考虑pdf中提到的a single call to read is not enough的具体含义,以为是首先会接受所有的文本信息,然后对于结果需要将最后的EOF也打印出来,所以第一次写的时候只是简单的调用了两次read()
1 cout << socket.read () << socket.read ();
然而在make check_webget的时候并没有通过,为了找到问题所在,首先找到check_webget的脚本,发现测试的内容为对cs144.keithw.org下的接口/nph-hasher/xyzzy发送请求,并获取最后一行的内容,而这行内容应该是一串正确的HASH。但是在这个时候尝试以上文的方式运行webget的时候则发现输出的只有以下两行
1 2 HTTP/1.1 200 OK
但是通过telnet的情况下,正常的输入应该是以下的内容
1 2 3 4 HTTP/1.1 200 OK
这个时候就懂了多次调用read()的含义直到遇到eof的含义应该是一直读取到所有缓冲区内的内容都被读取完毕,将代码修改如下就可以通过测试了
1 2 3 4 5 6 7 8 9 10 11 void get_URL (const string &host, const string &path) connect (Address (host, "http" ));write ("GET " + path + " HTTP/1.1\r\n" );write ("Host: " + host + "\r\n" );write ("Connection: close\r\n\r\n" );while (!socket.eof ()) {read ();close ();
第二个任务主要是要我们自己根据头文件的内容来实现一个简单的ByteStream,并且只需要考虑单线程的情况,不用考虑并发等情况。
最后完成的答案先直接贴上来,这块难度也不会很大,在写的时候先大致按要求写出一个逻辑,即使不是很清楚具体实现对不对也问题不大,只需要通过调试逐步修改即可
首先添加的成员变量如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class ByteStream {private :const size_t buffer_max_size;bool is_input_end = false ;size_t write_count, read_count;bool _error{}; public :
最后接口的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 ByteStream::ByteStream (const size_t capacity) : buffer_max_size (capacity), buffer (), write_count (0 ), read_count (0 ) {}size_t ByteStream::write (const string &data) size_t cnt = min (remaining_capacity (), data.length ());substr (0 , cnt);return cnt;string ByteStream::peek_output (const size_t len) const { return buffer.substr (0 , len); }void ByteStream::pop_output (const size_t len) erase (0 , len);std::string ByteStream::read (const size_t len) {substr (0 , len);pop_output (len);return output;void ByteStream::end_input () true ; }bool ByteStream::input_ended () const return is_input_end; }size_t ByteStream::buffer_size () const return buffer.length (); }bool ByteStream::buffer_empty () const return buffer.empty (); }bool ByteStream::eof () const return input_ended () && buffer.empty (); }size_t ByteStream::bytes_written () const return write_count; }size_t ByteStream::bytes_read () const return read_count; }size_t ByteStream::remaining_capacity () const return buffer_max_size - buffer.length (); }
接口的逻辑实现都不难,不过写这个lab的时候的第一次在vscode的环境下使用cmake来进行调试,在这里简单记录一下调试的步骤和需求。
相关code插件 : CMake, CMake Tools, C/C++(Cpptools)
在这里以write()函数中缺少了write_count += cnt这一行为例,使用make check_lab0可以发现在最后有报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 56% tests passed, 4 tests failed out of 9
此时可以将注意力先集中在最上面的t_byte_stream_one_write上,cmake中将byte_stream_one_write作为target编译并运行,可以得到以下报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Test Failure on expectation:
从这里可以知道是测试"write-end-pop"中的第五个执行中,bytes_written并没有返回预期希望的数字3。因此只需要在tests/byte_stream_one_write.cc内"write-end-pop"的test.execute(BytesWritten{3});的位置打上断点,然后直接使用vscode下方栏中cmake的debug图标(需要安装C/C++插件才可以使用快速调试,具体参考这里 )就可以逐步找到自己逻辑中出错的地方并修改即可。
热身的两个lab提供的成就感很足,希望自己能尽快完成下一个lab。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ cs144
+
+ network
+
+
+
+
+
+
+
+
+ ArchWSL安装及基础配置
+ /p/cdfd3649.html
+
+ 在Windows上安装ArchWSL直接使用scoop来安装是比较便捷的一种方案,具体如何在Windows上配置·scoop`可以参考这篇教程:
在配置好了scoop以后,首先通过以下指令安装ArchWSL
只要按正常流程,按win+s,通过Windows搜索找“Turn Windows features on or off”或“启用或关闭Windows功能”,然后在里面将 Virtual Machine Platform 和 Windows Subsystem for Linux 勾选上,重启电脑即可。
重启电脑之后只需要在命令行中输入arch即可启动,如果出现报错或无法使用 WSL2 的情况可以通过搜索引擎或在这里下载Linux内核更新包 来解决
在/etc/pacman.d/mirrorlist内已经有Arch预置好的部分国内镜像源,我们只需要将我们对应需要的镜像前面的注释取消即可使用。
或者也可以通过下面这个脚本来一键启用所有China部分的镜像源
1 sed -E '/China/,/##/s/^#S(.)/S\1/g' /etc/pacman.d/mirrorlist~ > /etc/pacman.d/mirrorlist
通过以下指令将archlinuxcn相关源直接写入/etc/pacman.conf当中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat >> /etc/pacman.conf << EOF # 国内archlinuxcn镜像源 [archlinuxcn] Server = https://mirrors.aliyun.com/archlinuxcn/\$arch Server = https://repo.archlinuxcn.org/\$arch Server = https://mirrors.bfsu.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cloud.tencent.com/archlinuxcn/\$arch Server = https://mirrors.163.com/archlinux-cn/\$arch Server = https://repo.huaweicloud.com/archlinuxcn/\$arch Server = https://mirrors.zju.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cqupt.edu.cn/archlinuxcn/\$arch Server = https://mirrors.sjtug.sjtu.edu.cn/archlinux-cn/\$arch Server = https://mirrors.tuna.tsinghua.edu.cn/archlinuxcn/\$arch EOF
首先通过以下指令,来更新软件源、安装archlinuxcn证书、yay和部分基础工具(其中yadm是一个用来备份dotfiles的工具,用于恢复自己常用的Linux环境下的自定义文件)
1 2 pacman -Syyu --noconfirm ;
创建用户 (注意替换下文的用户名)
1 useradd -m -G wheel -s /bin/zsh 用户名
将wheel组内的成员给予sudo的权限
如果希望安全考虑,在sudo之前要输入密码的话,可以输入下面的指令来配置visudo
1 echo '%wheel ALL=(ALL:ALL) ALL' | sudo EDITOR='tee -a' visudo
如果偷懒,不希望每次都输入密码的话可以用下面的指令来配置visudo
1 echo '%wheel ALL=(ALL:ALL) NOPASSWD: ALL' | sudo EDITOR='tee -a' visudo
2.5. 以上所有操作全部可以自动完成,只需要将以下脚本内的用户名替换为自己的用户名即可(默认sudo不需要密码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 sed -E '/China/,/##/s/^#S(.)/S\1/g' /etc/pacman.d/mirrorlist~ > /etc/pacman.d/mirrorlistcat >> /etc/pacman.conf << EOF # 国内archlinuxcn镜像源 [archlinuxcn] Server = https://mirrors.aliyun.com/archlinuxcn/\$arch Server = https://repo.archlinuxcn.org/\$arch Server = https://mirrors.bfsu.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cloud.tencent.com/archlinuxcn/\$arch Server = https://mirrors.163.com/archlinux-cn/\$arch Server = https://repo.huaweicloud.com/archlinuxcn/\$arch Server = https://mirrors.zju.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cqupt.edu.cn/archlinuxcn/\$arch Server = https://mirrors.sjtug.sjtu.edu.cn/archlinux-cn/\$arch Server = https://mirrors.tuna.tsinghua.edu.cn/archlinuxcn/\$arch EOF echo '%wheel ALL=(ALL:ALL) NOPASSWD: ALL' | sudo EDITOR='tee -a' visudo
给root用户和自定义用户设置密码(自行操作)
修改root用户密码
修改自定义用户密码
(可选)切换到自定义用户下并配置oh-my-zsh
通过以下指令切换用户
配置zsh为oh-my-zsh可以参考这篇教程(Ubuntu配置和Arch大同小异,可以选择性参考)
Ubuntu下安装Oh My Zsh引导
如果希望设置ArchWSL为WSL的默认发行版,并将刚刚自己创建的用户作为默认用户的话只需要分别在Powershell下执行这两条指令
1 Arch config --default-user 用户名
+
+ 安装引导
+
+
+
+
+
+
+ WSL
+
+ Arch
+
+
+
+
+
+
+
+
+ Shell:管道符与重定向
+ /p/db6cc46f.html
+
+ 到目前位置自己还没专门花时间研究过Linux上那些日日都在用的工具(如Shell和Vim)他们本来的用法和含义,本来觉得没必要,不过在看了missing-semester之后顿时感觉效率提高了不少。因此做一个笔记,把一些很实用但是自己并不会去关注的简单用法给记录一下。
在使用最基础的bash作为命令行的时候,常常能发现用户后面有的时候是$二有的时候是#
1 2 [halc@Zephyrus blog]$ su
这里$代表了当前用户为普通用户,而#的含义则代表当前是在root用户下
在shell程序中,程序的执行主要分为 输入流 和 输出流 两种不同的流,程序会从输入流中读取信息,然后在通过处理之后打印到输出流当中。
以cat为例,其作用为将一个文件的内容打印到输出流当中,通过使用 > file 和 < file 来对流进行重定向,可以覆写或者创建对应内容的文件
1 2 3 4 5 6 7 8 # 将我存于github的pubkey打印输出成id_rsa.pub文件 # 将id_rsa.pub的内容重定向 **追加** 到authorized_keys当中 # 将id_rsa.pub的内容先重定向给cat ,再由cat 输出到pubkey当中
拓展补充 1:所有的Linux进程都包含3个文件描述符,分别是 标准输入 ,标准输出 和 错误输出 。<或<<来操作>或>>来操作2>或2>>来操作
补充拓展 2:>/dev/null 2>&1和2>&1 >/dev/null的区别
对于>/dev/null 2>&1是指先将标准输出指向黑洞设备,然后再将错误输出指向标准输出的指向内容(此时是黑洞),因此标准输出和错误输出都将不输出 对于2>&1 >/dev/null是先将错误输出指向标准输出(此时为屏幕),然后将标准输出指向黑洞,因此此时错误输出将打印到屏幕,而标准输出将不输出 1 2 # 运行example.sh,并将标准输出重定向至stdout.log,将错误输出重定向至stderr.log
以一个简单的test.cpp程序为例
1 2 3 4 5 6 7 8 #include <iostream> using namespace std;int main () "This is stand output" << endl;"This is error output" << endl;return 0 ;
通过编译并重定向运行
1 2 3 4 5 6 7 8 [halc@Zephyrus ~]$ g++ test.cpp -o test
如果希望将对应的文件描述符关闭的话有两种方法
1 2 3 4 # $-指关闭对应的文件操作符 # /dev/null为linux内的黑洞设备
对于>操作符,首先会判断右侧的文件是否存在,如果存在就删除再创建,如果不存在则直接创建,并且右侧的文件一定会置空。 一条命令执行前会检查0,1,2三个I/O设备是否正常,如果异常则不会进行命令执行 如果想要将内容输出重定向到某个文件,以cat举例有两种不同的办法
1 2 3 4 # 将read.md的内容重定向至write.md # "<< EOF" 指对流进行重定向输入,直到遇到"EOF" (可修改)作为末尾则结束
摘自:How does “<<” operator work in linux shell?
<< 操作符主要有以下三个操作逻辑
首先执行该操作符左侧的程序,在上面的例子中就是cat 抓取用户包括换行等所有的输入内容,直到输入的内容为用户指定的EOF结尾内容(在上面的例子中则恰好也是EOF)则停止 将所有除了EOF的内容都作为(1)程序的标准输入执行 实例:通过bash脚本创建一个test.cpp文件
1 2 3 4 5 6 7 8 9 10 11 #!/bin/bash cat > test.cpp << EOF #include<iostream> using namespace std; int main() { cout << "This is stand output" << endl; cerr << "This is error output" << endl; return 0; } EOF
1、文件类型上
2、管道触发两个子进程执行 “|” 两边的程序,而重定向是在一个进程内执行。
1 2 3 4 5 $ (sed -n '1,$p' | grep -n 'output' ) < test.cpp # 等价于 sed -n '1,$p' < test.cpp | grep -n 'output' # 对于管道运算符,如果希望将`test.cpp`传递给前面的第一个可执行文件`sed`,则需要使用单括号将整个管道传输看作一个单独的指令,否则`test.cpp`将传入`grep`内
由于标准输入和标准输出在管道运算符中的重定向是发生在"内容输出"之前的,因此可以通过重定向来修改管道中传输的数据
Because pipeline assignment of standard input or standard output or both takes place before redirection, it can be modified by redirection.
举个例子来说,本来管道传输默认只传输标准输出的内容,并不会传输错误输出
1 [halc@Zephyrus ~]$ command1 2>&1 | command2
通过上面的指令,首先command1的 错误输出 会在执行前被重定向至标准输入,然后command1执行,将 标准输出 和 错误输出 一并通过管道进行传输,作为command2的标准输入
1 2 3 4 # 首先将test.sh的内容通过cat 打印到标准输出, 然后管道传输该输出给tee , # 在tee 执行之前通过&>将tee 的标准输入和错误输出都重定向至/dev/null中, # 然后执行tee 将管道获取的内容写入text.txt,并且将相同的内容写入null设备当中
> 输出重定向,往往在命令最右边(也可以用到命令中间),接收左边命令的输出结果,重定向到指定文件。
1 2 3 4 5 6 7 8 # 如果管道符左侧的程序已经将标准重定向指向了其他文件,那么在bash中管道传输的数据将为空 # 此时无输出 # 但是log 内应该是有内容匹配的
在自己实验的时候发现zsh下即使重定向了标准输出和错误输出依旧可以通过管道读取内容,这主要是zsh有一个可以将输出重定向给多个文件的特性,对于管道也会进行二次传递
参考 Redirection and pipe behavior in bash vs. zsh
Read the MULTIOS documentation in the zshmisc man page. It’s a feature of zsh which causes it to redirect the output to multiple files at the same time, and it can also be a pipe.
具体举例
上面这个命令在bash当中只有文件a会有内容,而b中并没有获取到标准输出。但是在zsh下执行上面的命令,则a和b中都会拥有相同的输出内容。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ missing-semester
+
+ shell
+
+
+
+
+
+
+
+
+ 快速部署rclone为services
+ /p/bbde595d.html
+
+ 在Linux上安装rclone可以直接使用默认发行版仓库的版本,也可以官方脚本安装
1 curl https://rclone.org/install.sh | sudo bash
安装完成了之后通过输入以下指令可以在交互式页面当中添加、修改或删除连接信息
在配置完成之后,如果需要将rclone的内容挂载到本地,执行类似以下格式的指令
1 rclone mount remote_name:path/to/directory path/to/mount_point
其中可以添加以下参数来对本地的文件进行缓存设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 --transfers:该参数控制最大同时传输任务数量,如果你cpu性能差,建议调低,但太低可能会影响多个文档同时传输的速度。
在挂载的时候可以添加--deamon参数来让rclone后台临时挂载,如果要取消挂载则输入以下指令
1 fusermount -u path/to/mount_point
如果需要配置开机自启动挂载对应的Rclone服务,只需要创建以下文件(以onedrive为例,参数和名字可自定义):~/.config/systemd/user/rclone-onedrive.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [Unit]# 挂载在当前用户的~目录的OneDrive文件夹内,需要提前创建好~/OneDrive # Make sure we have network enabled # 启用vfs模式,将onedrive挂载给/home/xxx/OneDrive文件夹 # 取消挂载 # Restart the service whenever rclone exists with non-zero exit code # Autostart after reboot
写入完成之后,通过执行以下两个指令在当前用户下生效该服务
1 2 systemctl --user daemon-reload
+
+ 小技巧
+
+
+
+
+
+
+ rclone
+
+
+
+
+
+
+
+
+ 总结:2022年5月
+ /p/795cfa1d.html
+
+ 这个月算是找回了感觉,还算充实。这个月应该算是最平常的一个月了,整个人谈不上有动力,也谈不上完全摆烂。月初刚开始的时候把OSTEP上操作系统虚拟化的部分基本上写完了,然后就开始关注开源之夏项目申请相关的内容。在之前某个学长的推荐下看过一篇xmake-clangd配置vscode写cpp环境的知乎的帖子,当时对于cpp编译和链接相关的知识还完全没有概念,在开源之夏的时候模模糊糊搜了下xmake发现居然有项目能申请,就怂恿和gofaquan一起报了相关的项目。在五月底到六月初花了大概一百多RMB学习了cpp常见的一些项目管理会遇到的问题,感觉还蛮值的,希望最后项目申请能成功中标,给暑假的自己找点事情做。
学校也快到期末了,这学期的大作业还算应付的过来,大部分大作业都能组队解决,不能组队的也不算麻烦,基本上1-2天的时间也都能搞定,希望下个月的期末考试能一切顺利,别挂科。
这个月主要的学习部分应该也就是上半个月和六月份初了。五月中旬的时候学校终于有了解封相关的信息,于是开始到处想办法出去吃,报复性消费了好几顿过度饮食,体重直接涨了十多斤。现在期末考试临近,也没有什么减肥的想法,打算在考试前可能就通过不断的摄入碳水来缓解压力了,减肥啥的还是等考完期末考试再说了XD。
然后就是每次考试前都日常想要有的报复性消费。这学期把自己之前Niz那个108键的键盘换成了68配位的。目前过渡到日常使用已经没什么问题了,后面看看能不能开发点新功能,再提高提高效率(其实就是差生文具多 )
希望期末考试算顺利复习完,不挂科 能熟悉xmake要导入的包相关源码 在期末考试结束以前是不指望有什么生活质量了,只能寄托希望给暑假的自己了
减肥!至少恢复160-以下 调整自己的作息,打破在家必摆烂的心态(感觉不太可能)
+
+
+
+
+ 个人总结
+
+
+
+
+
+
+ 总结
+
+
+
+
+
+
+
+
+ OSTEP:分页的计算
+ /p/c1ec22c4.html
+
+ 对于线性页表,只要知道第一个Page的地址,存于寄存器当中,就可以通过这个地址依次陆续推算下一个或后面任意一个有效的地址范围。对于多级页表,通过多次搜索,依旧可以在只有最初的页表的地址的情况下,通过多次的偏移查询来定位到最后需要的特定地址。
这里取例子说明算法,具体答案通过-c参数可直接输出
这里以seed为0的时候为例
首先,在README.md中可以得到以下信息
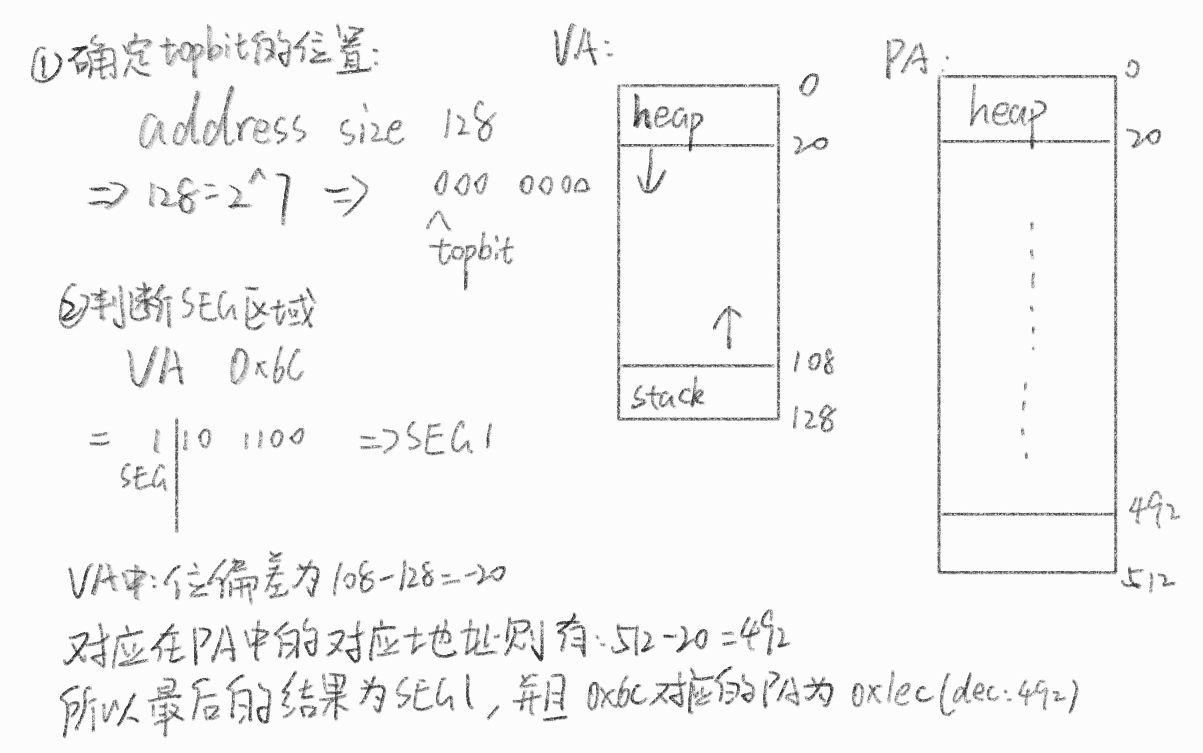
Page Size: 32 bytes Virtual Address Space:32 KB(1024个分页 2^15)虚拟地址需要 15 bits (VPN 占 10 bit,offset 占 5 bit) Physical Memory: 128个分页(2^12)物理地址需要 12 bits (PFN 占 7bit, offset 占 5 bit ) Virtual Address Space 的前五位对应了Page Directory的索引 通过seed生成0对应的地址数据,用于PDE查表,内容如下
Page Content 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 page 0:1b1d05051d0b19001e00121c1909190c0f0b0a1218151700100a061c06050514
并且根据模拟生成的PDBR: 108可以知道Page 108对应的内容即是第一级PDE的映射
接下来就可以进行计算了,这里取一个vaild和invaild的答案分析计算过程
1 2 3 4 5 6 7 8 Virtual Address 611c:
Virtual Address 611c
将611c按二进制转换为Virtual Address Space对应的 15 bits 为 11000 01000 11100。对PDE分割前五位有11000(decimal 24)
这个时候对最顶层的PDTR对应的Page 108进行查表操作
首先可以通过Page Content得到Page 108内容如下
1 2 Page 108: 83 fe e0 da 7f d4 7f eb be 9e d5 ad e4 ac 90 d6 92 d8 c1 f8 9f e1 ed e9 a1 e8 c7 c2 a9 d1 db ff
通过查表找到对应Index的内容可以知道24(11000)对应位置的内容是a1,转换为二进制为1010 0001,读取最高位为1可以知道是vaild。再通过后面的0010 0001转换为十进制为33,因此再继续查询Page 33的内容
1 2 Page 33:7f 7f 7f 7f 7f 7f 7f 7f b5 7f 9d 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f f6 b1 7f 7f 7f 7f
611c的[1-5]位为PDE,这时我们则需要通过[6-10]位来通过PTE寻找VPN对应的PFN地址。由611c为11000 01000 11100可以知道这次为01000即(decmial 8),对照上面page 33可以发现第八个对应的内容为53,因此可以知道最终VPN对应上了PFN的Page 53。最后再通过offset的11100,配合Page 53对应的二进制PFN地址11 0101结合offset的11100有110101 11100,也就是最后答案的0x6bc,其中通过offset在Page 53中查表可以找到对应的 Value 为 08
Virtual Address 3da8
和611c同理,将3da8转为二进制01111 01101 01000,得到pde index为01111(15),对应的Value为0xd6(1101 0110),通过1101 0110最高位可以知道目标分页为vaild,去掉vaild bit可以得到索引的pte为0x56(0101 0110 | 86)
检索Page 86,由PTE index为01101可以找到对应的Value为0x7f(0111 1111)由于最高位为0,因此是invaild,也就是说pte无效,无法访问
其他的情况也是依次类推,即可算出结果是否有效
根据个人理解,具体缓存hit或miss的概率主要由对应内存上的数据决定。对于访问次数较多的内容hit缓存加快速度的概率自然更高;而对于不重复的多次查询(比如上面的练习),自然miss的概率会更高。因此对于进程来说,如果能将数据尽量集中在某一块分页上则能有效提高内存访问和处理的速度。
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:TLB缓存命中和非命中的开销差距
+ /p/20416971.html
+
+ 本章为测量实验,主要要求为写一份tlb.c来测试在TLB miss和TLB hit的情况下性能开销的变化,以感受TLB的重要性
对于题中问题的回答
由于gettimeofday()的函数只能精确到微秒,不足以测试较为精确的时间,因此使用CLOCK_PROCESS_CPUTIME_ID和clock_gettime();搭配即可获得纳秒级的时间测量,具体代码实现如下
具体代码实现如下
tlb.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/time.h> #include <pthread.h> void lockCpu (int cpuId) cpu_set_t mask;if (sched_setaffinity(0 , sizeof (mask), &mask) < 0 )fprintf (stderr , "set thread affinity failed\n" );int main (int argc, char *argv[]) if (argc != 3 )fprintf (stderr , "Usage: ./tlb pages trials" );exit (EXIT_FAILURE);0 );int page_numebr = atoi(argv[1 ]);int trials = atoi(argv[2 ]);if (page_numebr <= 0 )fprintf (stderr , "Invaild Input" );exit (EXIT_FAILURE);int jump = sysconf(_SC_PAGE_SIZE) / sizeof (int );struct timespec start , end ;struct timespec start_hit , end_hit ;int sum_miss = 0 ;int sum_hit = 0 ;int cnt = 0 ;while (trials--)for (int step = 0 ; step < page_numebr * jump; step += jump)int *array = calloc (page_numebr, getpagesize());array [step] += 0 ;array [step + 1 ] += 0 ;free (array );int miss_average = sum_miss / cnt;int hit_average = sum_hit / cnt;printf ("Time per access(TLS miss): %d\n" , miss_average);printf ("Time per access(TLS hit): %d\n" , hit_average);return 0 ;
该程序主要思路为
统计访问内存需要的总时间 首先统计TLB miss的情况,在miss之后TLB被激活 统计对应分页内存的后一位,此时TLB hit,能够成功快速定位 将总时间除以操作的总次数,得到最后的平均每次时间(单位为ns) 大致结果如下
1 2 3 > ./tlb 1000 10
可以明显发现未命中的时候访问时间要远高于TLB hit时的时间
通过Python对tlb进行调用,大致结果为4.的效果
统计结果如下
其中蓝色对应TLB miss的时间,橙色对应了TLB hit的开销时间
Python画图代码如下
Matplotlib 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import osimport sysimport reimport matplotlib.pyplot as pltdef execRelocation (page_number, trival ):'./tlb %d %d' % (page_number, trival))r"(\d+)" return tlb1 ]2 ]for vpn in range (1 , int (page_number), 128 ):print (str (vpn) + "/" + str (page_number))int (trival))int (tlb[0 ]))int (tlb[1 ]))"Virtual Page Number" )"Time Per Access" )"Hit" )"Miss" )"./paging.png" )
添加-O0的参数可以防止gcc在编译的时候不进行优化
示例如下
在上下文切换 时,解决方案为使用Docker创建一个单核的虚拟机来进行实验操作,这次实验中,使用sched_setaffinity函数来设置进程对CPU亲和力,以让程序在某一单一CPU上运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/time.h> #include <pthread.h> void lockCpu (int cpuId) cpu_set_t mask;if (sched_setaffinity(0 , sizeof (mask), &mask) < 0 )fprintf (stderr , "set thread affinity failed\n" );
通过使用calloc()函数,可以在对堆内的变量进行分配内存的同时进行初始化操作,并且在每一次循环进行之前都销毁数组重新创建,可以减少对实验测试的影响
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:分页的原理
+ /p/44838b9c.html
+
+ 在虚拟地址中,vpn=address space size/page size. 所以在分页大小不变的情况下增加址空间大小会增加分页数量,在地址空间大小不变的情况下增加分页大小会减少分页数量。
如果使用了很大的分页,当程序只需要很小一部分内存的时候依旧会申请过大的内存,造成不必要的内存浪费
每次当某个分页被地址空间使用后,PTE中对应的Vaild Bit就会置为1。当提高used paged数量后,操作系统总是能找到vpn对应的pfn
在这三种分配来说,前两种分页的大小相对于地址空间本身来说太大了,而在第三个例子当中,相对于256m,修改分页大小1m为更小的值将更加有助于提高空间的利用效率。
首先,地址空间和物理空间的大小都要是分页大小的倍数,其次,物理空间必须要比地址空间更大,否则会无法访问对应的地址空间。
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:内存碎片的管理
+ /p/3d85131.html
+
+ 执行题目给出的参数可以得到以下内容
answer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 seed 0
这里以开头两段为例子分析,后面的算法相同
1 2 3 4 5 6 7 8 9 10 11 12 13 ptr[0] = Alloc(3) returned 1000 (searched 1 elements)
首先,根据开头参数可以知道目前分配方式不考虑Header头指针,并且不考虑内存合并
ptr[0] = Alloc(3)会从1000开始分配大小为3的内存(此时空间足够,分配成功),并返回1000的地址作为开头。此时空闲空间Free List只有一块,从1003开始,总大小为97
之后的Free(ptr[0])则将刚刚分配的内存释放,释放后由于并未合并,因此出现了[3]->[97]的空闲空间表,之后再进行ptr[1] = Alloc(5)。由于第一个空闲空间为[3]不足以容纳[5]的分配,因此第二个空间是从1003作为内存开始的地址,并使用了5的内存空间
然后再进行Free(ptr[1])的操作释放内存并且不合并,则有了[3]->[5]->[92]的空闲可用空间。后面的运算以此类推
如果出现了在空闲的大内存中分配了新的小内存
1 2 ptr[4] = Alloc(2) returned 1000 (searched 4 elements)
则占用部分内存后,新的剩余内存将被作为新的内存段保留使用,并且已分配内存也会产生新的内存碎片
使用最差匹配有如下输出
answer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 seed 0
比对可以发现,在最差匹配的情况下,第二次重复分配8大小的空间时不会重复利用本身空闲的长度为8的空间,而是依旧从后面的最大空闲空间中分配8大小的空间出来,此时地址从1024开始分配,并且1008开头的地址不会被复用
1 2 3 4 5 6 7 8 9 10 11 Free(ptr[2])- ptr[3] = Alloc(8) returned 1008 (searched 4 elements) - Free List [ Size 3 ]: [ addr:1000 sz:3 ][ addr:1003 sz:5 ][ addr:1016 sz:84 ] + ptr[3] = Alloc(8) returned 1016 (searched 4 elements) + Free List [ Size 4 ]: [ addr:1000 sz:3 ][ addr:1003 sz:5 ][ addr:1008 sz:8 ][ addr:1024 sz:76 ]
在使用FIRST进行匹配的情况下,空间分配的情况与BEST无异,在本例题示范当中,由于FIRST是找到可以用的内容后直接进行匹配,而示例当中恰好所有可用空间最小的情况匹配了FIRST的情况,因此只有搜索的次数变少,效率变快,其他差异不大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 + policy FIRST - policy BEST + ptr[3] = Alloc(8) returned 1008 (searched 3 elements) - ptr[3] = Alloc(8) returned 1008 (searched 4 elements) + ptr[4] = Alloc(2) returned 1000 (searched 1 elements) - ptr[4] = Alloc(2) returned 1000 (searched 4 elements) + ptr[5] = Alloc(7) returned 1008 (searched 3 elements) - ptr[5] = Alloc(7) returned 1008 (searched 4 elements)
三种不同的参数分别对应了以下三种不同的内存分配方式
ADDSORT: 空闲的地址在搜索的时候是按地址的顺序进行排序搜索SIZESORT-: 空闲的地址在搜索的时候按地址块的大小,先搜索大的,后搜索小的SIZESORT+: 空闲的地址在搜索的时候按地址快的大小,先搜索小的,后搜索大的由于BEST和WORSE分配的方法都需要把所有内存段全部搜索后再分配,因此在根据这两种不同的调度之后产生的内存碎片的数量是相同的。在三种不同的调度中采取FIRST控制空闲变量则将会造成比较大的影响。对于SIZESORT-的情况来说,由于未分配的大块内存一直在最前面,因此很容易在反复删除小内存段的过程中不断积累内存碎片;优点是每次直接扫描的第一个就将是可以直接使用的内存,搜索的次数明显减少。采用SIZESORT+的情况下,由于小碎片都积累在前面,因此如果此时遇到比较大块的内存需要分配时,则会增加需要搜索的内存段数量,时间会增加;优点是每次分配的时候都尽量先匹配比较小的内存段,对于多次分配小内存的情况来说,不会那么容易产生浪费。
首先,如果对内存段不采用合并处理的话,随着时间推移,内存碎片将会越来越多,并且后面能够成功分配内存需要的搜索次数以及成功概率都会升高。其次,由于内存合并是在地址连续的基础上才会进行合并,因此如果采用了SIZESORT的分配方法,打乱了地址的顺序,虽然依旧有成功合并的可能,但是效率还是要低于以ADDRSORT方法对空闲内存段进行排序。
如果-P设置的太高,模拟的则是在平时写程序的过程中一直不对申请的内存空间进行Free释放,则会导致空间过早的就被使用完毕,后续无法再继续分配,设置的低的情况下则代表了内存每次使用分配完毕以后都立即释放,这样就能够一直有空闲的内存等待分配。
如果要生成高度碎片化的空间,只要让空闲的空间碎片始终不被合并,并且分配的时候根据上述中第四题得到的规律增加搜索次数,让即使被Free的内存块也无法被使用或增加使用次数即可。
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ qBittorrent与jellyfin搭建自动追番引导
+ /p/8d2011c6.html
+
+ Docker Engine: 20.10.15 Ubuntu: 20.04.4 LTS X86平台 部署使用的是老电脑上的Ubuntu 20.04.4 LTS,为了便于备份配置以及轻量上手,采用了Docker-Compose的一件式部署方式,该方案主要倾向解决追番问题,目前基本解决刮削问题。
请在百度等搜索引擎直接搜索对应自己平台的"Docker 安装 教程"
推荐的qBittorrent+Jellyfin部署配置文件如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 version: '3' services: jellyfin: image: nyanmisaka/jellyfin:latest restart: unless-stopped container_name: jellyfin volumes: - $PWD/conf/jellyfin:/config - $PWD/cache:/cache - $PWD/downloads/media:/media ports: - "8096:8096" environment: - TZ=Asia/Shanghai - UID=1000 - GID=1000 devices: - /dev/dri:/dev/dri qbittorrent: image: johngong/qbittorrent:latest restart: unless-stopped hostname: qbittorrent container_name: qbittorrent volumes: - $PWD/conf/qbit:/config - $PWD/downloads:/Downloads network_mode: "host" environment: - UID=0 - GID=0 - TRACKERSAUTO=YES - WEBUIPORT=8995 - TRACKERS_LIST_URL=https://cdn.jsdelivr.net/gh/ngosang/trackerslist@master/trackers_all.txt - UMASK=022
如果出现了qBittorrent配置有可能随着更新有变化,如果使用过程中出现问题,或需要自己额外配置,具体参考johngong/qbittorrent 内的介绍进行修改即可。
下载 EpisodeReName.zip 并且解压在qbittorrent挂载的Downloads目录下,用于下文中设置自动改名
在诸如蜜柑计划 的网站,找到自己想要看的番剧或电视剧对应的RSS链接
在qbittorrent当中添加RSS规则,示例如下
添加完毕RSS规则以后,则需要设置下载路径。由于Jellyfin刮削为识别文件夹名字进行刮削,因此这里的命名必须要符合规范来提高成功率
在qbittorrent设置内开启自动下载,后续只要识别到了RSS更新,就能自动下载到目标文件夹下
自动修改剧集名字使用的为Episode-ReName 工具
下载并将Episode-ReName放于Docker挂载后的downloads目录下
配置下载完毕自动运行EpisodeRename来对番剧重命名
配置参数如下
1 2 3 /Downloads/EpisodeReName "%D/%N" 10
由于重命名后的文件无法直接继续做种,因此在qbittorrent内同样要设置自动取消做种上传
秉承BT分享的精神,或者使用PT站的朋友可以学习如何设置硬链接等方式对文件实现共享,本文不做解释
元数据刮削主要用的是TheMovieDb, AniDB, AniSearch和AniList这几个插件,不过依旧存在抓取的时候抓到英文介绍为多的问题,不过暂且算是能使用,海报和宣传图也基本上都有,日常使用没有很大问题
]]>
+
+ 安装引导
+
+
+
+
+
+
+ qbittorrent
+
+ jellyfin
+
+ docker
+
+
+
+
+
+
+
+
+ WSL配置Proxy代理引导
+ /p/6088c65c.html
+
+ 在三番五次被wsl的proxy问题折腾的心态爆炸,并重装了好几次系统以后,总算理清楚了WSL如果想要搭配windowns上的clash for windows的正确使用方法。把之前无论是需要脚本还是各种复杂操作的博客都删了,在这里记录一个完全不需要任何脚本,也不需要额外配置防火墙的合理方案。
WSL 2 ArchLinux(理论上来说其他发行版应该相同)Windows 11(win10应该同理)Clash For Windows改方案为WSL继承System Proxy来达到代理上网的目的,使用TUN Mode直接用就行,不需要额外设置
正常配置好Clash For Windows,并且启用Allow LAN的设置
在允许应用或功能通过 Windows Defender防火墙中寻找是否有clash-win64.exe的规则配置,注意不是 Clash For Windows ,CFW本身只是clash的一个前端,在启动CFW的时候有概率防火墙只添加CFW本身,而不添加作为核心的clash的防火墙规则,这个时候则需要我们手动修改
如果已经有了clash-win64.exe的规则,则只需要配置专有和公共网络同时允许 即可。如果没有clash-win64.exe的规则,可以通过下方的允许其他应用手动添加规则,具体clash核心文件的路径可以通过任务管理器后台或Clash for Windows\resources\static\files\win\x64\clash-win64.exe类似的路径查询到。添加规则的时候同时允许专用和公共 即可
之前经常折腾好了防火墙但过了三四个月或者一段时间后wsl和windows之间就因为防火墙断开,但总找不到原因,现在想想很有可能是当时clash for windows升级安装的时候规则被覆盖或路径变化导致的。WSL2的网络对Windows来说也是一个Public的公开网络,在设置了单独程序允许通信之后,虽然wsl有可能无法ping通windows的主机,但正常访问clash的代理端口是没有问题的
到这里为止防火墙的问题就解决了,只需要通过合理的方法配置好WSL下的代理变量就可以正常使用。其中主机名.local这个域名是会直接在wsl内映射到作为dns服务器的宿主机上,因此并不需要写额外的脚本来添加映射
较为简单的方法即通过zsh终端下oh my zsh+ zsh-proxy 插件,通过设置proxy来实现全局基本功能的代理配置,而在config_proxy步骤中的代理IP填入类似Zephyrus.local:7890格式的地址即可。
Zephyrus为我Windows的设备名,可在Windows设置中重命名,一般来说默认设置应该为类似DESKTOP-XXXX.local:7890,修改和查看的方法可通过搜索引擎自己解决
通过以上方式配置后的WSL就可以正常通过Windows上的Clash代理了。每次WSL出网络问题总是感觉莫名其妙没头绪,之前也试过通过New-NetFireWallRule一类的方法放行防火墙,但都不是很好用或者后面偶尔突然就出问题,现在总算弄清楚了原因而且能很舒服的使用win里面的代理了。
]]>
+
+ 小技巧
+
+
+
+
+
+
+ zsh
+
+ WSL
+
+ Clash
+
+
+
+
+
+
+
+
+ OSTEP:通过分段管理内存
+ /p/783d8b13.html
+
+ 这里记录一个样例作为例子,其他的答案则跳过重复的计算步骤
运行第一个seed可以得到以下输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ARG seed 0
对于VA 0: 0x0000006c (decimal: 108)的情况计算如下
由Address Size为128(2^7)得到高位为第7位 将VA的0x6c(108)转为二进制,按7位来算则是1 101100,因此可以知道这是SEG 1的地址 栈是从最下方的内存反方向增加,VA最底部内存位为0x80(128),因此0x6c(108)的VA对应偏移量为108 - 128 = -20 VA中0x80(128)的地址对应PA为0x200(512),因此按偏移量-20算可以得到VA中0x6c(108)对应的PA为0x1ec(492)
答案 1 2 3 4 5 6 Virtual Address Trace
以第一题为参考;在虚拟地址中SEG 0的范围是0-19,SEG 1的范围是108-127,非法地址为20-107。
以下为通过运行-A标志对分界点进行分别测试有如下结果
1 2 3 4 5 6 7 Virtual Address Trace
设置为以下指令即可
1 ./segmentation.py -a 16 -p 128 -A 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 --b0 0 --l0 2 --b1 16 --l1 1 -c
输出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Virtual Address Trace
要让90%的地址可以被访问,则对于SEG 0的界限寄存器到SEG 1的界限寄存器中间地址差要为总虚拟地址的10%即可。
( b 1 − l 1 − ( b 0 + l 0 ) ) A d d r e s s S i z e < 10 % \frac{(b1 - l1 - (b0 + l0))}{Address Size} < 10\% A d d r e s s S i z e ( b 1 − l 1 − ( b 0 + l 0 ) ) < 1 0 %
所以地址都失效代表没有可以访问的地址,因此l0和l1界限寄存器都设置为0即可
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:虚拟内存和物理内存地址转换
+ /p/1724953e.html
+
+ 该章节主要引出了基址寄存器和界限寄存器的概念,表述了在操作系统内程序执行的时候虚拟内存的分布和物理内存的地址转换关系
判断是否越界只需要将访问内存地址大小和Limit进行比较,在小于Limit的情况下直接做加法即可
获取到所有访问的数据后,可以发现访问的地址中最大的为
1 VA 9: 0x000003a1 (decimal: 929)
因此只需要将-l设置为930即可
补充为什么不是929
界限寄存器是在基址寄存器的基础上开始limit个单位的内存可被使用,就好比数组中的limit为10个空间的情况下,只有0-9可以被使用。对应到该题,如果想要让(0x000003a1)的地址不越界,则需要设置930个可用空间
题目默认的物理地址为16k,也就是16,384,只需要设置-b为16384 - 100 = 16284即可
和上文实验差别不大,其中-a参数是设置随即生成的取地址的大小范围,-p为设置物理内存的最大范围,实际内存主要是否越界只和-b的基址寄存器、-l的界限寄存器以及-p的物理内存有关系,-a作为一个随机数范围没有实际含义
通过PyPlot画图,在默认的-n情况下,当limit从0逐渐增加到asize的时候,可以得到大致如下的图片
附画图代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import osimport reimport matplotlib.pyplot as pltdef execRelocation (seed, limit, num ):'python3 relocation.py -s %d -l %d -c' % (seed, limit))"VALID" )return pass_num / numif __name__ == '__main__' :1024 for i in range (0 , limitTop, 50 ):sum = 0 for j in range (0 , 20 ):sum += execRelocation(j, i, 10 )sum / 10 )"limit" )"pass rate" )"limit.png" )
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ 修复WSL中env:'bash\r'的冲突问题
+ /p/b3a8b5ef.html
+
+ 由于之前C/C++环境配置出问题,近期把WSL重装了一次,结果在配置zsh-proxy的时候出现了报错
1 /usr/bin/env: ‘bash\r’: No such file or directory
直接搜索的方案要么是直接屏蔽掉Windows的Path继承,要么是说重启下wsl就好,但都比较模棱两可
后面在查看了proxy相关的报错后,发现只有配置git的proxy时会出现这个问题,同时根据Stack Overflow上别人类似情况的提问,发现npm同样也无法使用。检查后发现是在Windows对应的Path内,git和npm本身没有.exe的后缀就能启动,而wsl内是可以执行Windows下的部分可执行文件的,因此wsl调用了基于Windows的环境变量,从而导致了换行符与wsl的linux格式不兼容。
本来想的是怎么处理屏蔽Windows的相关Path,后面发现只需要在WSL上重新安装好git和npm后重启wsl
1 2 3 wsl --shudown -t Arch
就可以解决问题了。之前在Stack Overflow上其他人能直接通过重启wsl解决问题,应该也是无意中自己已经覆盖安装过了对应的工具,然后重启才取得了效果,在这里做个记录以做备忘。
]]>
+
+ 小技巧
+
+
+
+
+
+
+ WSL
+
+
+
+
+
+
+
+
+ 使用Github Actions自动部署Hexo
+ /p/7bfa5e14.html
+
+ 之前博客一直用的都是Jekyll框架,在使用Github Pages进行部署的时候并不需要自己手动配置,不过在换了Hexo主题之后,每次写完了博客除了要push一次commit到博客的内容分支上,还需要自己手动deploy一次。虽然也不会很麻烦,不过用Github Actions来完成这个过程也要更顺畅一些。原本觉得这个需求应该很简单,直接在Actions上执行一次hexo g -d的指令就好,结果因为Github在HTTPS上对Token的验证,以及Hexo自带的one-command-deployment存在BUG ,折腾到凌晨两三点才发现,并且通过issues里面提供的修改链接使用oauth进行url验证的方法还是失败了,最后花了半小时改成了ssh密钥验证很轻松就完成了。。下面为对Hexo的Actions的脚本的一个备份
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 name: Hexo Deploy on: push: branches: - hexo jobs: deploy: runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2 with: ref: hexo - name: Cache node modules uses: actions/cache@v1 id: cache with: path: node_modules key: ${{ runner.os }}-node-v2-${{ hashFiles('**/package-lock.json') }} restore-keys: | ${{ runner.os }}-node-v2 - name: Install Dependencies if: steps.cache.outputs.cache-hit != 'true' run: | npm ci - name: Build and Deploy run: | mkdir -p ~/.ssh/ echo "${{ secrets.DEPLOY_KEY }}" > ~/.ssh/id_rsa chmod 600 ~/.ssh/id_rsa ssh-keyscan github.com >> ~/.ssh/known_hosts git config --global user.email "halc-days@outlook.com" git config --global user.name "HalcyonAzure" npx hexo g -d rm -rf ~/.ssh/id_rsa
整个脚本大致流程为
检测到hexo的内容分支有push之后,checkout到内容分支。
判断是否有nodejs的modules缓存。
如果检测到有效缓存则跳过安装步骤,直接进行下一步。 如果没有检测到有效缓存则对模块进行部署 创建id_rsa密钥文件,并将仓库中DEPLOY_KEY的secret写入密钥文件,并且配置github.com的信任和全局帐号邮箱
对hexo进行generate & deploy操作
删除写入的密钥文件
+
+ 小技巧
+
+
+
+
+
+
+ hexo
+
+
+
+
+
+
+
+
+ 解决Windows未使用端口被占用问题
+ /p/22453a61.html
+
+ Hortonworks Docker Sandbox environment cannot start default-dynamic-port-range-tcpip-chang 在无脑跟着网上教材开启Windows的SandBox的时候开启了Hyper-V的功能,结果尝试在6800端口运行和往常一样的Aria2的Docker容器的时候出现了端口报错的情况,通过netstat排查也没发现6800端口被占用了,后面发现应该是Windows的动态端口在开了Hyper-V之后被修改了
通过以下指令可以分别查看ipv4/ipv6的tcp/udp起始端口
1 2 3 4 netsh int ipv4 show dynamicport tcp
在我的情况下,起始端口从原本默认的49152被修改成了从1024开始,因此6800端口无法使用
在参考问题中找到了对应的解决方案
如果需要继续使用windows Virtual platform form windows feature(不确定这里是不是指Hyper-V,所以不翻译了)则
关闭Windows服务上对应的功能,关闭后系统会请求重启
通过以下指令修改动态起始端口 (49152是Windows默认设置) 在使用adb连WSA的调试时,发现默认端口为58526,所以还是用100000把
1 2 3 4 netsh int ipv4 set dynamicport tcp start =64536 num=1000 set dynamicport udp start =64536 num=1000 set dynamicport tcp start =64536 num=1000 set dynamicport udp start =64536 num=1000
重新启用对应的功能
如果没有Hyper-V使用需求的情况下,可以尝试直接关闭Hyper-V,然后检查起始端口是否恢复,如果没有恢复的再通过上面的指令手动重新设置起始端口即可
]]>
+
+ 小技巧
+
+
+
+
+
+
+ Windows
+
+
+
+
+
+
+
+
+ OSTEP:系统API的调用
+ /p/264bf58c.html
+
+ 执行null文件后并没有提示或报错,代码如下
1 2 3 4 5 6 int main () int *pt = NULL ;free (pt); return 0 ;
在执行完gdb null后的run后,提示了以下信息
log 1 2 3 (gdb) run
在使用valgrind检查后,可以得到以下输出信息
log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ==9579== Memcheck, a memory error detector
根据C/C++ Preference 上free()的介绍如下
If is a null pointer, the function does nothing. ptr
首先使用malloc()函数对内存空间进行分配,但是不使用free()对内存进行释放
1 2 3 4 5 6 int main () int *pt = (int *)malloc (sizeof (int ));return 0 ;
使用gdb对可执行文件进行调试如下
gdb log 1 2 Starting program: /home/halc/code/cpp/null
使用valgrind对可执行文件调试入如下
valgrind log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ valgrind --leak-check=yes ./null
这个时候通过valgrind工具即可检查出,在堆空间中有definitely lost(确定的内存泄露)为4 bytes in 1 blocks,正好对应了代码中sizeof(int)的大小和数量
首先使用malloc()函数分配100个int的空间给指针data,然后在data[100]的位置赋值
1 2 3 4 5 6 7 int main () int *data = (int *)malloc (sizeof (int ) * 100 );100 ] = 0 ;free (data);return 0 ;
程序直接运行的时候不会报错,没有任何提示。但是使用valgrind进行检查的时候有如下日志
log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ valgrind --leak-check=yes ./null
可以看到valgrind成功检测出一个无效的写入,在内存分配之后,只有data[0] - data[99]是可以正常写入的,data[100]并不存在,因此出现了无效写入的错误
用和第五题相似的方法创建一个数组,然后通过free()函数对内存释放,然后对已经释放的空间进行读取
1 2 3 4 5 6 7 int main () int *data = (int *)malloc (sizeof (int ) * 100 );free (data);printf ("%d\n" , data[0 ]);return 0 ;
在本地电脑上直接运行的时候输出了0,使用valgrind工具进行检查的时候输出了如下日志
log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ==10682== Memcheck, a memory error detector
可以看见检测出了无效的读写Invalid read of size 4
对data数组中的data[50]进行内存释放,然后输出data[0]
1 2 3 4 5 6 7 8 int main () int *data = (int *)malloc (sizeof (int ) * 100 );free (data + 50 );printf ("%d\n" , data[0 ]);return 0 ;
在直接运行的时候会直接报错
1 2 3 $ ./null
不需要用valgrind也可以检查出此处有free()的问题
根据 c-free-invalid-pointer 的回答,可以知道
When you have in fact allocated a block of memory, you can only free it from the pointer returned by. That is to say, only from the beginning of the block.
当我们分配了一块内存的时候,我们只能从返回的指针开始对这块内存进行释放,也就是说我们只能从内存块的开头对某一处内存进行释放
通过realloc()函数实现一个类似vector的操作
1 2 3 4 5 6 7 8 9 10 int main () int *pt = (int *)malloc (sizeof (int )); 10 ; int *)realloc (pt, sizeof (int ) * 2 ); 1 ] = 20 ; printf ("%d, %d\n" , pt[0 ], pt[1 ]); free (pt); return 0 ;
程序编译可以成功通过,使用valgrind也正常通过,没有无效读写错误
通过这种操作实现的vector可以在访问的时候直接通过index进行访问,时间复杂度为O(1),并且他并不需要和链表一样创建一个指向next的指针,不过在向后添加内容的时候依旧需要O(n)的时间复杂度来向后添加元素。
顺便记录一个Tips, 在C中是允许void *类型进行任意转换的,因此即使没有(int *)也不会出现报错,而在C++中对类型转换的限制更多,并不允许直接进行这样的操作,必须要进行类型转换(通过static_cast转换运算符)才能分配空间给对应的指针。
偷懒,懒得写
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:比例份额的调度策略
+ /p/13271c5f.html
+
+ 在CPU资源进行调度的时候,有的时候我们很难让每个程序都尽量公平的分配到资源。“彩票调度(lottery scheduling)”通过给不同的任务分配不同的彩票数,再通过随机数和期望分布来对资源进行调度,实现一个类似于平均分配的调度方法
本章中文译本内缺少对Linux系统的CFS调度的说明,不过不影响课后练习
完成随机种子1、2和3对应的习题计算
该题目的主要思路即判断随机数取模后的数字和tickets的数量比较,然后依次逐步执行判断即可
当彩票分布设计的十分极端的情况下,由于第一个Job0 10:1获得的票数太少,几乎不可能在Job1 10:100前完成任务,将会在结果上滞后Job0的完成
通过设立不同的seed,可以得到不同的情况如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ ./lottery.py -l 100:100,100:100 -s 1 -c
可以大致看出在任务的长度足够大的情况下,调度分布基本公平,最后的结果趋紧于类似RR切换任务的平均期望
在修改了quantum大小之后,由于时间片变大,相当于任务本身的长度缩短,整个任务的公平性会偏向不稳定和不公平,大致结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ ./lottery.py -l 100:100,100:100 -q 20 -c -s 1
这题主要用来当Python练习了,模拟生成图像的代码如下(和lottery.py实验代码放于同一目录下)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import osimport reimport matplotlib.pyplot as pltimport numpy as npdef countLottery (length, seed ):"./lottery.py -l " + length + ":100," + length + ":100 -c" + " -s " + seed)r"^--> .*(\d*)" , text, re.M)return int (lottery_time[0 ])/int (lottery_time[1 ])def average (length ):sum = 0 20 for i in range (1 , time):sum += countLottery(length, str (i))return sum / (time - 1 )1 100 5 for i in np.arange(length_start, length_end, step):str (int (i))))"Fairness" )"Job Length" )'b-' )"./lottery.png" )
最后生成的图片效果
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ 总结:2022年3月
+ /p/18b05b6b.html
+
+ 这个月直接写出的可以用的贡献不是很多,主要成就感应该就是来自Python的抓包和发包写一些打卡脚本的目标完成了,实现了学校的打卡自由和机场的签到流量自由。
Rust的学习和CS144的学习在这个月成功被我换成了C++的学习和OSTEP的学习,写lab完成之后带来的快感感觉完全不亚于玩老头环成功挑战Boss后的成就感,OSTEP的学习笔记和答案也有一直在博客里面更新,希望自己这个学期能全部做完加深对操作系统的了解
这个学期也第一次写了一个能用的repo出来:HalcyonAzure/lsky-pro-docker 。虽然整个Dockerfile还是抄袭了issues里面别人的劳动成果,但是在调试的过程中遇到的许多问题也加深了自己对container的了解,而且学会了用dev container来做一些临时开发,同时自己写yaml用github actions来自动部署一些项目(白嫖服务器的感觉是真的爽),总的来说成就感可以说是非常强了。
喔,对了,这个月还把博客重构了一下,改成了用Hexo的Fluid的主题,看着比原来Jekyll的TeXt花里胡哨了不少😉
这个月由于都忙着Coding,没什么游戏时间。不过让我没想到的是南昌居然也会受到疫情的波及,连续上了近一整个月的网课,伙食方面不能吃烧烤或火锅来释放自己的多巴胺果然感觉还是很难受啊😢,希望能早点解封然后出去吃餐好的
核酸检测虽然说做的次数也满多,不过学校后面几次安排的时间都蛮合适的,整个流程下来不超过30min,因此也没什么怨言,同时托网课的福,自己也才有了那么多时间能做自己想做的事情,写自己想写的东西,这种无忧无虑不用考虑绩点和平时作业的时候如果多一些就好啦😣
参加计算机设计大赛,看看能不能摸个奖回来,丰富下经历 OSTEP的Lab每个礼拜写两篇 绝对、绝对绝对开始跑步或打排球,调整自己的生活质量 早睡早起!!! 水果封校已经不做指望了,就希望能控制住自己的饮食😥
+
+ 个人总结
+
+
+
+
+
+
+ 总结
+
+
+
+
+
+
+
+
+ OSTEP:进程的调度策略
+ /p/28ea7a49.html
+
+ 参数介绍:
Response:响应时间,即任务第一次运行的时间
Turnaround: 完成时刻(周转时间),即任务完成那一刻对应的时间
Wait: 等待中时间,即任务处于Ready状态,但当前CPU在执行其他任务的等待时间
执行结果如下
FIFO:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ARG policy FIFOfor 200.00 secs ( DONE at 200.00 )for 200.00 secs ( DONE at 400.00 )for 200.00 secs ( DONE at 600.00 )
同时,对于SJF(Short Job First),由于每个任务的执行时间相同,所以策略上的处理结果和FIFO相同,不额外列出
在按照300,200和100的顺序一次执行任务的时候,对于FIFO策略依次执行,而依据SJF策略,则会先执行时间短的100,依次到最常的300。具体结果如下
FIFO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ARG policy FIFOfor 300.00 secs ( DONE at 300.00 )for 200.00 secs ( DONE at 500.00 )for 100.00 secs ( DONE at 600.00 )
SJF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ARG policy SJFfor 100.00 secs ( DONE at 100.00 )for 200.00 secs ( DONE at 300.00 )for 300.00 secs ( DONE at 600.00 )
SJF的好处在于可以先执行时间短的程序,后执行时间长的程序,同时优化了程序的响应、完成和等待时间。缺点在于因为必须先完整的运行某个任务,后执行下一个任务。如果此时需要高频率执行某任务则无能为力(比如高频率的io输出)
采用RR策略,时间片设置为1,依次执行10、20和30有以下结果
RR策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 ARG policy RRfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secs ( DONE at 28.00 )for 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secs ( DONE at 49.00 )for 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secs ( DONE at 60.00 )
采用RR策略的时候通过轮转运行三个程序,达到类似"同时"运行程序的效果,缩短了任务的反应时间。缺点是由于轮询过程会同时运行其他任务,因此总体的完成时刻和等待时间都会延长。
由于SJF是“短任务优先”的调度策略,因此当到达的任务顺序为先短时间的任务,后长时间任务的时候,SJF和FIFO的周转时间是相同的
当RR策略的量子时间大于等于SJF的单个任务最长工作时间时,SJF和RR可以提供相同的响应时间
当工作长度逐渐增加的时候,SJF的响应时间会逐渐增加,因为SJF必须要完成一个完整的任务才会运行下一个任务,因此后面的任务响应时间必须等待前一个任务的完成,模拟省略。
假定所有任务的长度都大于量子长度,且完成任务的时间都为量子长度的倍数,则可推得以下公式
∑ i = 1 N − 1 i Q N = Q ∑ i = 1 N − 1 i N = Q ∗ N ( N − 1 ) 2 N = Q ( N − 1 ) 2 \frac{\sum_{i=1}^{N-1} iQ}{N}=\frac{Q \sum_{i=1}^{N-1} i}{N}=\frac{Q * \frac{N(N-1)}{2}}{N}=\frac{Q(N-1)}{2} N ∑ i = 1 N − 1 i Q = N Q ∑ i = 1 N − 1 i = N Q ∗ 2 N ( N − 1 ) = 2 Q ( N − 1 )
]]>
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:程序上下文切换的开销
+ /p/4b65fa48.html
+
+ 由于该实验要求在单个CPU上运行两个进程并在他们两个UNIX管道,而书中介绍的sche_affinity()函数的具体调用不是很清楚,所以这里通过Docker的参数限制,创建了一个只使用宿主机一个CPU资源的容器进行实验。
单核Docker容器的创建
1 docker run -it -d --cpuset-cpus="0" --name=os ubuntu:latest
注:在以上环境中如果使用函数查询CPU核心数依旧可以发现为16或其他多核,但是在通过指令stress -c 4实际测试后,性能只会在宿主机的单一CPU核心上运行,不影响实验。但是如果在创建Docker容器的时候使用的是--cpus=1,由于负载均衡,并不能达到单核进行实验的目的。
通过gettimeofday()增加时间戳函数,获取执行时间
创建10个管道,循环5次,每次循环的时候分别在两个管道之间反复通信,并输出上下文切换时间差
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <stdint.h> #include <sys/time.h> uint64_t getTimeTick () struct timeval tv ;NULL );return tv.tv_usec;int main () int fd[10 ][2 ];for (int i = 0 ; i < 10 ; i++)if (pipe(fd[i]) < 0 )"pipe" );exit (1 );char timeWrite[256 ], timeRead[256 ];for (int i = 0 ; i < 9 ; i += 2 )int rc = fork();switch (rc)case -1 : "fork" );exit (EXIT_FAILURE);case 0 :0 ], timeRead, sizeof (timeRead));printf ("Read - Write %d: %lu\n" , i, getTimeTick() - atol(timeRead));sprintf (timeWrite, "%lu" , getTimeTick());1 ][1 ], timeWrite, sizeof (timeWrite));exit (0 );default :sprintf (timeWrite, "%lu" , getTimeTick());1 ], timeWrite, sizeof (timeWrite));1 ][0 ], timeRead, sizeof (timeRead));printf ("Read - Write %d: %lu\n" , i + 1 , getTimeTick() - atol(timeRead));break ;return 0 ;
1 2 3 4 5 6 7 8 9 10 Read - Write 0: 24
由于在执行完write之后会继续执行主进程,下方的read也会运行,因此最后结果中奇数进程的结果时间会比偶数进程的时间长,正确答案应该靠近偶数(已经在代码中用注释写明)。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ OSTEP:进程的简单使用
+ /p/897b63ef.html
+
+ 子进程和父进程的变量x的值内容相互独立。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> #include <sys/wait.h> int main (int argc, char *argv[]) int x = 100 ;int rc = fork();if (rc < 0 )printf ("fork failed\n" );exit (1 );else if (rc == 0 )printf ("Child: %d\n" , x);100 ;printf ("Child + 100: %d\n" , x);else int wc = wait (NULL );printf ("Parent: %d\n" , x);100 ;printf ("Parent + 100: %d\n" , x);printf ("Final Address: %d\n" , x);return 0 ;
测试结果如下:
1 2 3 4 5 6 Child: 100
同时打开文件p4.output并且分别写入Child process和Parent Process,可以正常并发写入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdio.h> # include <stdlib.h> # include <unistd.h> # include <fcntl.h> int main () close (STDOUT_FILENO);open ("./p4.output" , O_CREAT | O_WRONLY | O_TRUNC, 0700 );int rc = fork();if (rc < 0 )fprintf (stderr, "fork failed\n" );exit (1 );else if (rc == 0 )printf ("Child process\n" );else printf ("Parent process\n" );return 0 ;
结果(p4.output文件)
1 2 Child process
或(并发输出的先后顺序不同)
1 2 Parent process
题目要求的是在不适用wait()函数下实现子进程和父进程的先后,通过vfork()函数可以实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # include <stdio.h> # include <stdlib.h> # include <unistd.h> # include <fcntl.h> int main () close (STDOUT_FILENO);open ("./p4.output" , O_CREAT | O_WRONLY | O_TRUNC, 0700 );int rc = vfork ();if (rc < 0 )fprintf (stderr, "fork failed\n" );exit (1 );else if (rc == 0 )printf ("Child process\n" );else printf ("Parent process\n" );return 0 ;
数据结果可以参考题目2的第一个情况。不过这里插入Stack Overflow 上书原作者的话作为备注:
Without calling wait() is hard, and not really the main point. What you did – learning about signals on your own – is a good sign, showing you will seek out deeper knowledge. Good for you!
Later, you’ll be able to use a shared memory segment, and either condition variables or semaphores, to solve this problem.
针对不同的调用和变种,写了一篇详细的博客进行解析:区分不同exec()形式
在父进程使用wait(),等待子进程完成后,wait()会返回子进程的pid
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int main () int rc = fork();if (rc < 0 )"fork failed" << endl;exit (1 );else if (rc == 0 )printf ("I am child process %d\n" , getpid ());else int ws = wait (NULL );printf ("I am parent process %d\n" , getpid ());printf ("Return Value of wait() is %d\n" , ws);return 0 ;
运行结果
1 2 3 I am child process 4878wait () is 4878
在子进程中使用wait()则会返回-1,并且在失败后依旧会执行当前子进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int main () int rc = fork();if (rc < 0 )"fork failed" << endl;exit (1 );else if (rc == 0 )int fake_ws = wait (NULL );printf ("I am child process %d\n" , getpid ());printf ("fake_ws = %d\n" , fake_ws);printf ("Test\n" );else int ws = wait (NULL );printf ("I am parent process %d\n" , getpid ());printf ("Return Value of wait() is %d\n" , ws);return 0 ;
运行结果
1 2 3 4 5 I am child process 5011wait () is 5011
针对waitpid()的使用,总结了笔记:waitpid()调用
子进程中关闭标准输出,父进程输出子进程和本身pid
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int main () int rc = fork();if (rc < 0 )printf ("fork failed\n" );exit (1 );else if (rc == 0 )close (STDOUT_FILENO);printf ("Hello from child\n" );else int ws = wait (NULL );printf ("Hello from parent, child exited with status %d\n" , ws);return 0 ;
运行结果,子进程中的输出被关闭,只有父进程输出。
1 Hello from parent, child exited with status 1326
通过pipe()管道进行传输数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 int main () int fd[2 ]; int rc_pipe = pipe (fd); char msg[] = "Hello_World!" ; char buff[100 ]; int rc_1 = fork(); if (rc_1 == 0 )for (int i = 0 ; i < 5 ; i++)printf ("Child Process 1: %d\n" , i);sleep (1 );close (fd[0 ]); dup2 (fd[1 ], STDOUT_FILENO); printf ("%s" , msg); close (fd[1 ]); exit (0 ); int rc_2 = fork();if (rc_2 == 0 )for (int i = 0 ; i < 3 ; i++)printf ("Child Process 2: %d\n" , i);sleep (1 );close (fd[1 ]); dup2 (fd[0 ], STDIN_FILENO); scanf ("%s" , buff); close (fd[0 ]); printf ("%s" , buff); exit (0 ); return 0 ;
输出结果
1 2 3 4 5 6 7 8 9 Child Process 1: 0
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ Linux系统中waitpid函数的使用实例
+ /p/840f43e7.html
+
+ 在写完OSTEP第五章课后习题之后,通过第八题的答案记录一下自己目前对waitpid()的尝试结果,目前的尝试仅限于进程执行的阻塞和等待,轮询和非阻塞的状态暂时没有遇到,日后补充。waitpid()不能用于子进程等待更早的另外一个子进程,如果尝试运行则会返回-1。(在父进程中则等待并返回子进程对应的pid)
这里举例说明,以下为一个不包含任何waitpid()的原始代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int main () int rc_1 = fork(); if (rc_1 == 0 )exit (0 );int rc_2 = fork();if (rc_2 == 0 )exit (0 )return 0 ;
该代码通过waitpid()函数可以实现在rc_1和rc_2都执行完毕之后,再执行主进程的内容,修改如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int main () int rc_1 = fork();int rc_2 = fork();waitpid (rc_1, NULL , 0 ); waitpid (rc_2, NULL , 0 ); return 0 ;
但是在子进程中调用waitpid()是不能做到让rc_2等待rc_1的。参考:stackoverflow
比如修改rc_2的代码如下
1 2 3 4 5 6 int rc_2 = fork();if (rc_2 == 0 )int wr = waitpid (rc_1, NULL , 0 );exit (0 )
通过以上的代码并不能让rc_2等待rc_1,如果尝试输出wr会得到wr == -1(在父进程中则应该是等待进程的pid)
]]>
+
+
+
+
+ 知识记录
+
+
+
+
+
+
+ os
+
+
+
+
+
+
+
+
+ Linux中不同版本exec函数区分
+ /p/b9e46cb4.html
+
+ 该问题为OSTEP第五章进程API上的一个问题,在搜Stack overflow的时候发现一个很好记的答案,单独写一个博客记录一下what-are-the-different-versions-of-exec-used-for-in-c-and-c 对于exec()函数,在C/C++中有以下几个不同的版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <unistd.h> extern char **environ;int execl (const char *pathname, const char *arg, ... ) int execlp (const char *file, const char *arg, ... ) int execle (const char *pathname, const char *arg, ... ) int execv (const char *pathname, char *const argv[]) int execvp (const char *file, char *const argv[]) int execvpe (const char *file, char *const argv[], char *const envp[])
其中不同版本的区别通过函数名可以分为以下几个大类:
L:L在这里指的是list,执行的时候的将参数以类似如下方式传入:
1 execl (const char *pathname, const char *arg, ...)
其中省略号代表了后续分别独立传入的参数,其中,第一个参数应是正在执行的文件关联的文件名,并且参数以空字符NULL作为结尾的判定。
V: V在这里指的是vector,执行的时候以char*的形式传入执行指令
1 int execv (const char *pathname, char *const argv[])
对于不确定传入参数的个数的时候,可以使用vector来执行程序。使用带v的函数的时候,首先传入的第一个pathname是指向可执行文件的路径,后面传入的argv[]中,第一个argv的位置上按习惯为可执行文件的名字,后面argv+1等参数则是实际需要调用的可执行文件的参数、
有的命令执行的时候,我们并不知道要传入的参数有几个,而有的命令则必须要一定数量的参数才能运行。通过分别调用带l或带v的函数,在不同的情况下执行某些特定命令很有用
E在这里指代的是Environment,在结尾带e的exec()调用的时候的环境变量env与父进程的env并非一定相同,通过带e的函数即可在调用exec()的同时传入一个env供子进程使用
P在这里指的是系统环境变量中的PATH,含有p的exec()在调用的时候会在系统变量的PATH当中寻找对应的可执行文件,而缺少p的exec()在执行的时候,如果在当前目录下没有对应的文件名字,则需要传入目标可执行文件的绝对或相对路径。
]]>
+
+
+
+
+ 知识记录
+
+
+
+
+
+
+ os
+
+
+
+
+
+
+
+
+ 通过Python提交ncu每日健康信息
+ /p/cf0fd528.html
+
+ 该方法目前稳定性尚不确定,Token有概率会不定时失效,如果使用后果自负 该方法仅作Python学习使用,了解原理后使用后果自负 疫情期间请以实际情况打卡汇报,切勿身体有状况而依旧以无状况打卡。 简单三步,用 Python 发邮件 - 知乎 (zhihu.com) github action获取仓库secrets 通过Github Actions,在每天通过cron设定的时间实现企业微信打卡
Github Actions
QQ号以及QQ的SMTP密码
在打卡界面中"复制链接",并在电脑上打开
电脑浏览器打开链接,按F12,此时可能是电子ID,不用管,在右上角找到Network,并打开。
(如果提示要按Ctrl+R,按就行)
在Network下方找到loginByToken,并且找到右边的Token信息,复制保存。
百度搜索:获取QQ邮箱的SMTP密码
大致思路就是通过对应接口抓包后发包即可,更新Token通过接口LoginByToken实现,打卡通过SignIn接口实现。Scripts/ncu.py
为了仓库的信息安全,所有的密码通过Github仓库下secrets来进行设置,然后参考 github action获取仓库secrets 中提及的方法修改设置即可。
每个人都有义务在疫情大环境下对自己的真实信息负责
]]>
+
+ 小技巧
+
+
+
+
+
+
+ python
+
+
+
+
+
+
+
+
+ Github的PAT口令的密码记录和保存方案
+ /p/a126ef4d.html
+
+ 最简单的方案是讲自己的配置文件用明文保存,在文档 中查询可知道指令如下
1 git config --global credential.helper store
在设置credential.helper为全局store之后,下一次的验证会出现提示并保存,之后则会使用存在~/.git-credentials的明文帐号密码进行登入
为了更好的管理Github的Token,需要一个Git凭证助手来帮我们记忆用户名和对应的PAT,以下为Git-Credential-Manager-Core引导
安装Lateset Release 的GCM,并初始化设置
1 2 sudo dpkg -i <path-to-package>
在Linux上使用GCM需要额外设置credential.credentialStore,其中包含的设置方法如下:
该方法需要系统有GUI显示功能
1 2 3 export GCM_CREDENTIAL_STORE=secretservice
这个办法通过libsecret库来和Secret Service进行交互,所有的凭证都存储在“collections”当中。如果要查看的话,可以通过secret-tool或seahorse来进行查看。注:在请求用户帐号信息的时候会通过GUI来进行交互。
1 2 3 export GCM_CREDENTIAL_STORE=cache
这种方法保存的密码不会以可长期读取的文件形式存在硬盘上,如果是需要链接一些临时性的服务可以用这个方法。默认来说git credential-cache会储凭证900s,可以通过如下指令修改:
1 2 3 export GCM_CREDENTIAL_CACHE_OPTIONS="--timeout 300" "--timeout 300"
这办法不安全
1 2 3 export GCM_CREDENTIAL_STORE=plaintext
这种办法保存的密码默认会存在~/.gcm/store目录下,目录可通过GCM_PLAINTEXT_STORE_PATH环境变量来进行修改,如果文件不存在则会被创建新创建的文件权限为700.
这种方法需要有一对GPG密钥
1 2 3 export GCM_CREDENTIAL_STORE=gpg
这种办法主要使用了pass 工具,默认情况下文件会保存在~/.password-store文件下,该目录可以通PASSWORD_STORE_DIR来进行修改。在使用这种办法进行凭证管理之前,首先需要通过一对GPG密钥对pass进行初始化操作。
这里的<gpg-id>指的是当前使用gpg密钥对的用户的系统id。通过以下指令可以创建一个自己的gpg密钥对:
+
+ 小技巧
+
+
+
+
+
+
+ Github
+
+
+
+
+
+
+
+
+ OSTEP:进程的概念理解
+ /p/e328a303.html
+
+ 作业来自: ostep-homework
两个程序都只使用CPU,所以CPU的利用率是100%,测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Time PID: 0 PID: 1 CPU IOs
总共使用了11 ticks的时间,测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 Time PID: 0 PID: 1 CPU IOs
交换顺序后,在PID0进行io操作的时候,PID1会切换成RUNNING的状态,提高了CPU的利用效率,所以交换顺序重要。测试可得:
1 2 3 4 5 6 7 8 Time PID: 0 PID: 1 CPU IOs
由于加上了SWITCH_ON_END的标签,此时PID0进行IO操作的时候CPU会空闲等待至IO操作完成,浪费了一定的时间。测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 Time PID: 0 PID: 1 CPU IOs
由于这次会在等待IO的时候进行进程的切换,所以在io操作时,CPU没有等待,而是切换到了另外一个进程上继续工作,提高了利用率。测试可得:
1 2 3 4 5 6 7 8 Time PID: 0 PID: 1 CPU IOs
由于IO操作的优先级不是最高的,即使io操作的WAITING结束了,也会等待CPU先将其他进程执行之后,再对IO进行切换,由于IO操作需要消耗比较多的额外时间,而这部分时间没有被CPU利用,所以系统资源没有得到有效利用。测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Time PID: 0 PID: 1 PID: 2 PID: 3 CPU IOs
在使用了IMMEDIATE标签后,每次io_done之后CPU都会先切换io操作,然后用io处理的时间来处理其他进程,提高了系统资源的利用率。测试如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Time PID: 0 PID: 1 PID: 2 PID: 3 CPU IOs
开放题随机,和前七题大致相同。
+
+ 知识记录
+
+
+
+
+
+
+ OS
+
+
+
+
+
+
+
+
+ 总结:2022年2月
+ /p/ba5740b2.html
+
+ 这个月因为游戏的问题,我又犯了拖延症的老毛病,导致计划中的学习任务没有一个完成。玩起游戏的时候总会高估自己的效率,导致就想着一直玩到通关为止。规划的二月份的学习计划没有一个完成的事实,让我感到挺沮丧的。但我还是觉得要写一篇总结来记录这个月的所做所为。尝试了用Postman工具进行抓包,不过由于自己偷懒没仔细看文档以及对代理设置的不当配置,前前后后断断续续折腾了四五天还是换回Wireshark进行数据抓包,Python抓包发包本身学习倒是简单不少,一到两个小时就完成了学习,Appium目前也还没有开始接触。Rust相关的课程完全搁置没有进度。CS144的lab搭建好环境并在别人现成已有的Blog下完成了第一个实验,但是由于照葫芦画瓢,成就感很低并且了解不彻底,需要重新完成。力扣打卡断断续续持续了半个月,在2.25艾尔登法环发售到3.6通关群星结局过程没有其他进度。
虽然二月份就学习内容上来说摆烂几乎没有进度,但是用了一个礼拜的高强度游戏来感悟宫崎老贼的“魂系”游戏也完全不会让我觉得是在浪费时间。超大的世界观框架+完全自由的探索+五花八门的怪物+永远可以带来惊喜的各种武器,在初高中的时候总幻想一个所有人都可以一起探索的世界,这个世界在玩艾尔登法环的时候完全能够切身体验。在目前的开荒时期,除了自己推图可以发现各种各样的东西,同时最让人流连于其中的则是在目前世界观巨大的情况下,还没有完备的攻略来引导玩家“必须/流水线”的一套教程,同时全网玩家又在一起对这个世界进行发掘,让这个本来“单机”的游戏在某种意义上又变成了全网大家一起探索的异次元,这种开荒的乐趣加上老头环本身庞大的世界观绝对能称为我心中的“年度游戏”。
在不下雨的天气每天跑至少1.2km,同时保持良好的作息习惯 饮食上一个礼拜只吃一次非常规饮食,同时定期吃水果,改掉只吃维生素药片的习惯 这几天玩游戏的时候一直觉得这个月做的事情太少了,心里很不舒服。看到知乎一些“焦虑推送文”的时候也总觉得自己不务正业。造成这种情况的主要原因还是对玩艾尔登法环的时候一心想着开荒,对时间分配及其不合理导致状态的失衡,不过就取舍来说,作为几年难得一遇的优质游戏,和好兄弟一起联机攻克boss和开荒的快感不知下次得等几年,并不觉得这一个礼拜的时间有所亏欠,只是需要在这个月加把劲,把二月欠的任务完成!
]]>
+
+
+
+
+ 个人总结
+
+
+
+
+
+
+ 总结
+
+
+
+
+
+
+
+
+ Ubuntu上开启内核BBR算法来提高TCP吞吐性能
+ /p/2f2e6810.html
+
+ 参考文章:How to enable BBR on Ubuntu 20.04 默认情况下Linux 使用 Reno 和 CUBIC 拥塞控制算法,Linux kernal 4.9以上版本的内核已经自带该功能,由于Ubuntu 20.04的为5.4.0 kernel,我们可以直接启用
通过以下指令检查目前可选择的拥塞控制算法:
1 sysctl net.ipv4.tcp_available_congestion_control
输出大致为(可用的算法有reno和cubic两种):
1 2 root@vps:~## sysctl net.ipv4.tcp_available_congestion_control
通过以下指令检查目前的拥塞控制算法:
1 sysctl net.ipv4.tcp_congestion_control
输出大致为(目前是cubic):
1 2 root@vps:~## sysctl net.ipv4.tcp_congestion_control
在文件etc/sysctl.conf中写入以下内容:
1 2 net.core.default_qdisc=fq
保存并退出
重置sysctl设置
此时会有大致输出:
1 2 3 root@vps:~## sysctl -p
检查BBR是否在系统中正确启用:
1 sysctl net.ipv4.tcp_congestion_control
大致输出:
1 2 root@vps:~## sysctl net.ipv4.tcp_congestion_control
完成
]]>
+
+
+
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ 总结: 2022年1月
+ /p/9130a701.html
+
+ 当我回顾这个月的所做所为时,我发现自己虽然有些困难和拖延,但还是完成了一些有意义的事情。学习了 Rust 的初级语法。虽然考完试后完全松懈没有进度,但我对 Rust 的学习充满了信心,希望在未来能够深入学习。另外,也把家里的 Homelab 更换迁移成了 ESXi 基础的虚拟机,并在此之上将之前服务器上的服务器重新分开部署,每次折腾家里的HomeLab总能让我感觉成就感很足。此外,我还尝试了自己投稿文章,虽然初次尝试,但在机核的反馈中感觉有希望继续写下去。
虽然说是说这个月没有为本来的计划和目标努力,但还算是折腾了一些有意思的东西:
学习了Rust的初级语法,在期末考试前完成了Microsoft Learning上入门Rust 的40%内容,考完试后完全松懈没有进度。 把家里的Homelab更换迁移成了EXSi基础的虚拟机,并在此之上将之前服务器上的服务器重新分开部署 第一次尝试自己投稿文章 ,在机核的反馈感觉有希望继续写下去 在之外就是通宵熬夜生死存亡的期末考试复习了。
学习一下Python对于网页抓包数据的一些模拟,和对于Appium的使用 完成Rust整个的入门课程 CS144的6个lab至少完成2个(考虑拖延的情况下),有时间充裕就完成3-4个 力扣每天题库非困难题打卡 完成家里面Homelab关于流媒体服务器的部署 通过Python+Appium的组合,看看能不能全自动化学校企业微信打卡内容 找2-3部电影看完,内容随意 开学前每天锻炼半小时,睡眠作息开始调整为十一点睡觉,六点到七点起床 整个流程下来还是感觉和记流水帐一样吧,不过这样记录了以后感觉负罪感也强了一些,也算是最自己的一个监督。希望能离年初的目标越来越近。
]]>
+
+
+
+
+ 个人总结
+
+
+
+
+
+
+ 总结
+
+
+
+
+
+
+
+
+ Linux通过alternatives切换程序版本环境
+ /p/afb272ac.html
+
+ How to install and switch between different python versions in ubuntu 16.04 在切换Java版本的时候,通过update-alternatives可以很方便的进行版本之间的切换,而在Python里面,如果用Ubuntu自己的apt包管理器同时下载了多个版本的Python的话,则需要自己手动对Python的版本进行切换设定(切换版本还有alias等方法,这里不提及)。指令如下:
在安装了多个版本的Python之后(其他语言同理),通过类似以下指令的格式添加对应的程序优先级:
1 2 sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 1
由上面设置的程序指令为python,接下来通过以下指令对python的版本进行切换:
1 sudo update-alternatives --config python
输入之后可以见到类似如下的选择:
1 2 3 4 5 6 7 8 9 There are 2 choices for the alternative python (providing /usr/bin/python).
只需要在number后面输入对应需要的优先级,即可对python的版本进行切换。
每次都会忘记是update alternatives还是alternatives-update,所以写一篇博客记录一下…自己还是太Native了。
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ 2021年度总结
+ /p/1153f279.html
+
+ 往年本来都没有在年初或者年末的时候写一个一年总结的习惯,今年也算是突发奇想,打算写一篇博客稍微记录下自己的学习和生活。希望能在2022年里面养成时不时记录一下自己生活的习惯,养成正视自己的一个态度。
从2020年高三高考结束,到2021年大一升大二,也算是对大学生活有了一些认知和了解。整个大一的时间不能说浑浑噩噩,但总觉得自己心里缺了点什么。
现在仔细想想感觉就是缺少对自己的一个自视,总觉得心里空空的,不自在。刚上大学的时候就对“信息差”这个词很敏感,整个大一的过程也感觉一直在忙忙碌碌的处理各种各样的“信息”。无论是平时上课、考试还是处理一些生活中的问题,也总是把能搜罗到的各种信息的优先级置于自己“能力”的优先级之上,对外界环境的信任远高于对自己的信任。
这种自己信任上的缺乏感在最近听Daniel Sloss的Jigsaw(拼图)的Live Show 之后,感觉悟到自己经常总是忽视自己,一直感觉空虚因而不断的向外界索取信息,大抵也就是自己尚且不能适应孤独的感觉。上了大学以后本来觉得能聊的人多了,孤独的感觉应该弱化了,但现在想想过去一年里面反而应该是越来越强了。想过也许是不是谈恋爱就能让自己生活不那么孤独,但现在想想,问题应该还是出在自己对自己的不信任上。
连自己都不能做到100%爱自己的话,也很难爱其他人
总之,希望在将来到的2022年里面,能增加自己正视自己的态度。争取每个月写一个总结,来达到”给自己泼一盆冷水醒一醒“的作用。
有的话,说出来了才有力量警醒自己
这个学期除了学校本身的内容,学习密度最大的时候应该是年初倒腾软路由的时候开始的。从最初依赖带有GUI界面的openwrt的luci界面,到现在已经习惯了terminal的方式进行各种操作,这种对Linux一类命令行态度的转变有一种拿到了普罗米修斯的火把的感觉,一切原来觉得”麻烦“或者难以折腾的东西,突然都明朗了起来,即使遇到了问题,相比原来无脑cp各路解决方案的脚本指令,现在会下意识的思考和提前验证其中的原理和造成的影响了。
对于项目而言,去年算是或多或少接触或者熟悉了Nginx、Docker、MySQL等等零零碎碎的知识和技术,也搭建了一台以家里电脑为处理服务器,香港云服务器作为跳板的公网服务器,在上门也尝试部署过许多不同的demo或者项目,其中也通过对ZeroTier一类的工具的深入研究,也算是对计算机网络的学习和经验埋下了兴趣。
不过去年一年中,也和性格相关,大部分时候只是在通过搜刮各种”信息“,来搭建各种别人的项目然后进行一些很小的改动,一直在重复着”遇到问题“->”寻找别人的解决方案“->”不断选择最优解并且排错“->”解决问题“的过程,而总是不会把**”自己创造解决方案“排在首要位置。今年的博客内容也能体现我目前”知识密度“低下的严重不足,大部分时候只是写个机械性的总结草草了事,缺少很多思考和加工的过程。
平时在学校一个人虽然自在,但也还是和在家里一样一直倾向于变化越少越好,很少出门,出门吃饭也都只是找平时能难得线下面对面聊的比较多的同学,线上聊的比较多的同学和学长就经常”社恐“了。
在今年年末的时候,高考那会的储蓄也算是消耗殆尽了,钱的概念也越来越深刻了。不过还算幸运的是有需要的东西基本上也都备齐了,之后需要的东西开销应该也不会很大,目前的电子产品和设备就足够我把玩好一阵子了。
今年上半年的时候一直在忙忙碌碌的在不同的互联网上”冲浪”,一直在到处寻找已有的工具和服务然后不断上手和试验。看上去很忙但实际上也都学的是一些花时间,而不用花精力就能学会的“三脚猫”功夫。下半年的话反而玩了好几款3A大作而觉得整一年都充实了不少(手柄玩游戏是真的闲适),总的效率上虽然没做什么事情,但情绪要比上半年积极快乐多了。
2022年也到了,之前也没做过啥新年计划,今年也算是第一年尝试看看了,姑且列出以下几个目标,看看年末的时候能实现多少吧:
每个月写一篇总结,大致总结一下这个月发生了什么,就当是自己对自己态度的一个正视,也算是自己和自己对话了。 减肥,希望能减到BMI标准的水平。 接触至少三种不同的编程语言,了解相关的项目,并提交出自己的第一个PR 游戏开发入门,制作自己的一个游戏demo 学习一门额外的技能,目前的计划包括但不限于:日语入门(问就是二次元) 拾回Adobe全家桶 系统性学习建模软件 争取能参加一次GameJam 以上应该算是对2021年的一个缺胳膊少腿的总结吧,其中也发生了很多值得纪念和回味的细节事情,包括和不同的人相识又或者和第一次和同学去旅游,在旅游的时候又和曾经的同学见面…写博客的目的还是希望能把那些原来不会对别人,也不会对自己说的话记录下来,也是对自己的一个警示了。
2022年1月7号 - 凌晨3:14
(感冒还没好全 & 期末预习备战中… 希望这学期别挂XD)
]]>
+
+ 个人总结
+
+
+
+
+
+
+ 总结
+
+
+
+
+
+
+
+
+ 快慢指针
+ /p/76495b47.html
+
+ 以下内容仅为刷题总结,只记录目前遇到过的情况,如果后面遇到了更多可能性再做记录。
快慢指针的主要思想有点类似追击问题,通过让两个不同的小人以不同的速度在线性路径上行进,来招到某个特殊的相对位置。通常可以用来解决大致一下两类问题:
线性路径上某特殊点的位置和对应的操作 判断链表中是否存在循环(以及循环的点位置) 一般的思路是让两个不同的小人先以某一个相对的路径进行移动,之后再以一定倍率的相对速度进行继续移动,如果发生了『追击』、『相遇』或者『触底』等特殊事件的时候,就可以作为解题需要的特殊位置来进行处理。
如何判断出链表的中点位置?
答:通过两个速度分别为v和2v的指针同时从表头开始出发,当2v速度的指针『触底』的时候,以速度v前进的指针指向的位置理应为中点。
如果链表的长度为偶数的话,具体是停留在中间位置的左边还是右边要结合具体情况进行判断
如何判断链表内是否有循环?
答:让两个不同速度的指针分别出发,如果有环存在的话,则必然会有两个指针在环内相遇。
如何判断链表内开始进入环的位置?
答:让两个指针分别以速度v和2v出发,相遇则说明环存在。这个时候假入环前的长度为D,设环的长度为C,入环点到相遇点的距离为S1,相遇点重新回到入环点的距离则为S2。
此时快指针比慢指针多走n圈,所以走的距离必然为D+S1+nC 慢指针走一圈的时候,快指针能走两圈。所以相遇必然发声在第一个环内,所以慢指针走的距离为D+S1 由于2 * (D + S1) == D + S1 + nC和C = S1 + S2,所以不难得出D = (n - 1)(S1 + S2) + S2,即D = (n - 1)C + S2的结论,翻译一下则为,入环点前面的长度D即为慢指针再走S2,到达入环点之后,再走n-1圈的长度 。 所以这个时候只需要再设定一个指针,让它从头开始走,当走到入环点D的时候,理论上来说慢指针也将走完第n-1圈,所以他们会相遇,同时慢指针的步数即为进入环的长度! 如何删除链表中的倒数第N个节点?
答:让两个起始位置相差n的指针以同样的速度运动,当前面的指针『触底』的时候,后面的指针自己就是「倒数第n个」节点了。
实际操作的时候,由于单向链表需要知道前一个节点才能对后一个节点进行操作,所以通常会让走的快的节点比自己先走一步。
+
+ 知识记录
+
+
+
+
+
+
+ 算法
+
+
+
+
+
+
+
+
+ 链表
+ /p/2362a8ea.html
+
+ 以下内容仅为刷题总结,只记录目前遇到过的情况,如果后面遇到了更多可能性再总结
在链式存储当中,对于节点是使用指针指向的方式进行数据的存储,其结点定义类似如下形式:
1 2 3 4 5 6 struct LinkNode {int val;LinkNode () {}LinkNode (int x) : val (x), next (NULL ) {}
链表的好处是在添加或者删除特定节点的时候时间复杂度比顺序存储要小。在经常需要删除和添加操作节点的时候,通过直接修改节点的指针,可以快捷的对节点进行对应操作。
链表划分为三个部分,头+中间的数据节点+尾。
其中头节点有两种常见的处理方式,一种是通过一个虚拟的dummyhead来当作头结点,之后才是真实的数据节点。这样的好处是可以在对实际含有意义的头节点进行操作的时候,不需要有额外的特判就可以完成,通过增加一个头结点在部分题目中有的时候可以有很好的效果。
尾节点和头结点一样,也有实际意义上存在的数据节点和最后指向的一个尾巴节点,不过根据节点的定义来看,可以知道尾节点后面通常都跟有一个无意义的nullptr。在有的时候需要对尾节点进行处理的时候,增加一个虚拟的dummytail也许也能起到很好的效果。(p.s. 比如在写双向链表的时候)
创建链表的时候,通常会创建一个指针节点来表示整个链表的头节点。
1 LinkNode *ListA = new LinkNode ();
以上代码的含义即为创建一个LinkNode的节点,同时创建一个叫做List
A的指针,指向的是这个节点的内存。
而在对单向链表的进行操作的时候,如果我们移动了链头,很多时候意味着操作都是不可逆的。因此如果需要对链表中某个特定节点进行操作的时候,往往都会创建一个指向需要节点的指针来进行单独操作,操作完毕后将指针释放即可。
以下举例,阐明节点和节点指针之间的关系:(感觉有点废话)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 LinkNode *cur = new LinkNode (); new LinkNode (114 ); new LinkNode (115 ); "cur addr:" <<cur<<" " <<"A addr:" <<A<<" " <<"B addr:" <<B<<endl;"cur addr:" <<cur<<" " <<"A addr:" <<A<<" " <<"B addr:" <<B<<endl;return 0 ;
在注释了delete tmp的时候,最后输出的cur->val会依旧是114这个A曾经的值,而如果执行了对应的delete操作,由于原本A对应内存上的结构体被释放了,所以这个时候cur就没有指向一个有效的节点。
常用的终止条件有三种:
cur != nullptr 指针会停留在nullptr的尾节点上cur->next != nullptr 指针会停留在最后一个有效节点上cur != nullptr && cur->next != nullptr多用于快慢指针,用于判断快指针是否到队尾。之所以两种情况都判断为循环跳出的条件原因:由于nullptr本身相当于最后一个有效节点的附加尾巴。类比于线段上有区间(a, b)和区间[a,b],快指针的目的是为了判断长度,而这两种区间长度都是b - a,只是对于第一种情况(a, b)如果不将b节点本身纳入有效节点则会出现区间长度变为a -> (b - 1)的情况。对于第三种终止条件,还可以类比为:
cur == nullptr终止的情况就是区间(a, b),此时cur在走到b的时候快指针已经越界,刚好碰壁cur->next == nullptr终止的情况就是区间[a, b],此时cur在走到b时,刚好到达边界,也同样碰壁。
+
+ 知识记录
+
+
+
+
+
+
+ 算法
+
+
+
+
+
+
+
+
+ 程序main函数入口arg参数的用处
+ /p/98326a13.html
+
+ 今天在看一些代码的时候偶然看到自己刚开始学C的时候,main()函数中都会有一个(int argc,char* argv[],char **env)的传参。但是到现在依旧不理解这几个参数的意义和它们代表的作用,在稍微查阅了一下以后,浅显的总结一下。
如果要使用argc和argv的话(char **env暂时没遇到,不做记录),只需要在main函数当中添加这两个参数即可,大致参考写法类似如下:
1 2 3 4 5 int main (int argc, char ** argv) return 0 ;
argc是一个整形的参数,代表了程序运行的时候发送给main()函数的参数个数。
argv则是一个字符串的数组,用来指向存放对应参数的字符串。
其中,argv[]数组中的元素有argc个,并且有:
argv[0]包含的是程序运行的路径名字argv[1]包含的是程序命名后的第一个字符串argv[2]包含的是程序命名后的第二个字符串… argv[argc]为NULL为让以上解释更加形象,这里引入示例代码进行解释:
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> using namespace std;int main (int argc, char * argv[]) for (int i = 0 ; i < argc; i++)"Argument" <<i<<" is " <<argv[i]<<endl;return 0 ;
假设代码文件存放于./b.cpp文件当中,通过编译器编译后的可执行文件为b。在执行如下指令:
返回的内容为:
在执行如下指令:
1 ./b oneString twoString threeString
返回的内容为:
1 2 3 4 Argument0 is ./b
对应了上文中的argc的元素个数和argv的字符串内容,即./b后面的oneString、twoString和threeString。
]]>
+
+ 知识记录
+
+
+
+
+
+
+ cpp
+
+
+
+
+
+
+
+
+ Ubuntu下安装Oh My Zsh引导
+ /p/80f884dc.html
+
+ 1 2 3 sudo apt install zsh -y
1 wget https://github.com/robbyrussell/oh-my-zsh/raw/master/tools/install.sh -O - | sh
字体安装(Hack NF)
其他字体:ryanoasis/nerd-fonts
编辑zsh配置文件
修改主题(以powerlevel10k 为例)
拉取主题仓库
1 git clone --depth=1 https://gitee.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k
在~/.zshrc下修改主题内容
1 ZSH_THEME="powerlevel10k/powerlevel10k"
安装zsh-autosuggestions、zsh-syntax-highlighting、zsh-proxy和z
1 2 3 git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
配置插件,编辑.zshrc文件,在plugins处添加,类似效果如下:
1 2 3 4 #
zshrc完整文件配置帮助
1 2 3 4 5 6 # # #
+
+ 安装引导
+
+
+
+
+
+
+ Linux
+
+ zsh
+
+
+
+
+
+
+
+
+ C++学习记录 - const限定符
+ /p/d08cfaf4.html
+
+ 总结自C++ Primer,仅供自己学习参考
引用本身只是目标对象的一个别名,自己本身并不是对象
变量引用可以间接对变量进行修改
常量别名代表的只能是常量 ,如果常量别名一个变量,也是先通过创建一个临时量 ,然后对这个临时量 创建别名
变量别名不能指向一个常量 ,也不能指向运算后的值 后的结果,e.g.
1 2 3 4 5 6 7 8 9 10 11 int pi = 3 ;const int PI = 3 ;int &revPI = pi; int &revPIt = pi *2 ; const int &cRevPI = pi; int &cstRevPI = PI; const int &cstcRevPI = PI;
引用在decltype出并非是对象的同义词,而表示的是对应类型的引用
1 2 3 4 const int ci = 0 , &cj = ci;decltype (ci) x = 0 ; decltype (cj) y = x; decltype (cj) z;
而对于表达式,在使用decltype关键词的时候,由于表达式本身可以返回一个值,所以会被识别为一个引用类型
1 2 3 int i = 0 ;decltype ((i)) d; decltype (i) e;
指针本身是一个对象,其含义为指向目标对象的地址 void指针可以指向任意一种变量代表的地址常量指针必须初始化 ,其中通过const关键词有两种表达意思:int *const ptr指的是常量指针,地址不可改变,指向一个int类型的变量 const int *ptr指的是常量的指针是常量类型,地址可改变,指向的是const int类型的常量 对于*const关键词修改的指针,虽然地址不能改变,但是依旧可以通过这个指针修改对应变量的值 。 顶层const:指针本身是一个常量
底层const:指针所指的对象是一个常量
+
+ 知识记录
+
+
+
+
+
+
+ cpp
+
+
+
+
+
+
+
+
+ Windows上通过Scoop管理和安装软件
+ /p/f15c20eb.html
+
+ 「一行代码」搞定软件安装卸载,用 Scoop 管理你的 Windows 软件 Scoop - 最好用的 Windows 包管理器 - P3TERX ZONE 在知道并安装Scoop的时候只是稍微听说过winget-cli一类的工具,不过由于一直对Windows系统的软件管理早就绝望,下意识的认为对Windows来说,这种终端的程序管理应该几乎没什么用。但在前几天偶然希望在Windows Terminal上寻找一个类似Linux的sudo的程序,发现了Scoop这个神器,并且在使用了一两天尝到甜头后,决定写一篇博客把大概的使用功能都记录一下。
安装在联网的情况下有直接的指令,但是安装之前需要保证环境满足以下要求:
Windows 的版本不低于 Windows 7 Windows 的 PowerShell 版本不低于 PowerShell 3 拥有能自由前往Github,保证传输稳定的网络环境 Windows的用户名为英文或者数字(非中文)用户名 Scoop默认情况下和Linux中一样,只有普通用户的权限,其中Scoop本身和他默认安装的软件,会安装在%USERPROFILE\scoop目录下,使用管理员权限进行全局安装的软件会在C:\ProgramData\scoop目录下。
打开PowerShell
设置用户的安装路径
1 2 $env:SCOOP ='\PathTo\' Environment ]::SetEnvironmentVariable('SCOOP' , $env:SCOOP , 'User' )
设置全局安装的路径
1 2 $env:SCOOP_GLOBAL ='\PathToGlobal\' Environment ]::SetEnvironmentVariable('SCOOP_GLOBAL' , $env:SCOOP_GLOBAL , 'Machine' )
然后就可以开始愉快的安装了。
在PowerShell中输入以下内容,来保证本地脚本的执行:
1 set-executionpolicy remotesigned -scope currentuser
用下面的命令来安装Scoop
1 iex (new-object net.webclient).downloadstring('https://get.scoop.sh' )
安装完成,可以通过以下指令来查询帮助
由于网络可能有的时候不稳定,大部分Scoop的软件在安装的时候可能会出现安装失败的情况,就需要我们自己手动进行代理的设置,设置代理的命令如下:
1 scoop config proxy [IP /DNS ]:[端口]
aria2
常用的强力下载工具,设置好aria2的conf文件并创建session文件,配合以下vbs脚本,创建快捷方式以后,在Win+R后运行Shell:Common Startup,将快捷方式放于其中,就可以当日用的下载工具了。
VBScript:
1 CreateObject ("WScript.Shell" ).Run "aria2c.exe --conf-path=aria2.conf" ,0
在安装完毕aria2后,scoop会默认用aria2来下载所有其他的软件,如果有的时候发现aria2下载不好使了,可以通过下面的指令来禁用aria2下载
1 scoop config aria2-enabled false
另外参考P3TERX大佬的博客中,其他选项可以按如下设置:
单任务最大连接数设置为 32,单服务器最大连接数设置为 16,最小文件分片大小设置为 1M
1 2 3 >scoop config aria2-split 32 -max-connection-per-server 16 -min-split-size 1 M
sudo
一个提权工具,可以让Windows下实现和Linux类似的提权效果
git
应该没啥好说的,必备安装。
nerd-fonts字体
在终端美化中常见的一种Powerline字体,使用以下指令添加库然后就能安装
1 scoop bucket add nerd-fonts
查询可以用的所有字体
因为安装字体需要管理员权限,所以需要添加sudo,指令如下(以Hack NF为例)
1 sudo scoop install Hack-NF
LANDrop 局域网文件分享
一个很好用的局域网文件共享工具,可以高速在不同系统平台之间分享文件。
大部分的使用帮助通过scoop help命令都可以直接列出并查看,常见的search、install、update和uninstall等指令不多做赘述。这里提供一些常见自己需要查阅的指令,以供日后使用参考。
Scoop 会保留下载的安装包,对于卸载后又想再安装的情况,不需要重复下载。但长期累积会占用大量的磁盘空间,如果用不到就成了垃圾。这时可以使用 scoop cache 命令来清理。
scoop cache show - 显示安装包缓存scoop cache rm <app> - 删除指定应用的安装包缓存scoop cache rm * - 删除所有的安装包缓存如果你不希望安装和更新软件时保留安装包缓存,可以加上 -k 或 --no-cache 选项来禁用缓存:
scoop install -k <app>scoop update -k *当软件被更新后 Scoop 还会保留软件的旧版本,更新软件后可以通过 scoop cleanup 命令进行删除。
scoop cleanup <app> - 删除指定软件的旧版本scoop cleanup * - 删除所有软件的旧版本与安装软件一样,删除旧版本软件的同时也可以清理安装包缓存,同样是加上 -k 选项。
scoop cleanup -k <app> - 删除指定软件的旧版本并清除安装包缓存scoop cleanup -k * - 删除所有软件的旧版本并清除安装包缓存全局安装就是给系统中的所有用户都安装,且环境变量是系统变量,对于需要设置系统变量的一些软件就需要全局安装,比如 Node.js、Python ,否则某些情况会出现无法找到命令的问题。
使用 scoop install <app> 命令加上 -g 或 --global 选项可对软件进行全局安装,全局安装需要管理员权限,所以需要提前以管理员权限运行的 PowerShell 。更简单的方式是先安装 sudo,然后用 sudo 命令来提权执行:
1 2 scoop install sudo
达成在 Windows 上使用sudo的成就
使用 scoop list 命令查看已装软件时,全局安装的软件末尾会有 *global* 标志。
此外对于全局软件的更新和卸载等其它操作,都需要加上 -g 选项:
sudo scoop update -g * - 更新所有软件(且包含全局软件)sudo scoop uninstall -g <app> - 卸载全局软件sudo scoop uninstall -gp <app> - 卸载全局软件(并删除配置文件)sudo scoop cleanup -g * - 删除所有全局软件的旧版本sudo scoop cleanup -gk * - 删除所有全局软件的旧版本(并清除安装包包缓存)
+
+ 安装引导
+
+
+
+
+
+
+ Windows
+
+ Scoop
+
+
+
+
+
+
+
+
+ Windows字体切换的两种方法
+ /p/87ec6922.html
+
+ Tatsu-syo/noMeiryoUI 如何更换win10系统的字体 noMeiryoUI进行修改(推荐)在网站上找到自己喜欢的字体,通常为ttf、otf或fnt等文件。 在noMeiryoUI的repo中下载该工具:Tatsu-syo/noMeiryoUI 解压后启动其中的noMeiryoUI.exe程序 选择自己想要的字体并更改,应用的时候可能会较为卡顿,耐心等待生效即可。 该方法存在一定风险,在替换Windows原本字体之前,请务必备份
下载自己想要用于替换的日用字体,并根据类型分别命名为msyh.ttc、msyhbd.ttc和msyhl.ttc
在C盘根目录新建文件夹TempFonts用于临时存放需要替换的字体
打开Windows的设置,找到"更新与安全"->“恢复”->“高级启动”,在高级启动之后,选择"高级选项",选择"命令提示符",选择自己的帐号登入
输入以下指令,将C盘下TempFonts文件夹内的字体替换为系统默认字体。
1 xcopy C:\TempFonts\* C:\Windows\Fonts\
回车后按下A来全部覆盖替换(一定要备份好之前的系统文件再执行这一步
输入exit回车后进入Windows系统,即可看到自己的字体应用生效,同理,如果想要将字体恢复,只需要用备份的字体文件进行覆盖操作即可。
+
+ 小技巧
+
+
+
+
+
+
+ Windows
+
+
+
+
+
+
+
+
+ Oh My Posh美化Windows Terminal引导
+ /p/d26abad0.html
+
+ 更新PowerShell本身和Windows Terminal没啥直接关系,单纯做个提醒放一个一键更新指令在这里:
1 iex "& { $ (irm https://aka.ms/install-powershell.ps1) } -UseMSI"
这条命令的作用是安装最新版本的PowerShell,截至发博客为止可用于安装PowerShell 7
打开Microsoft Store 搜索Windows Terminal 安装 在Win+R中输入wt回车即可呼出Windows Terminal Windows Terminal中链接了一些Linux下可用的指令,诸如ls等如果要在Windows Terminal下使用vim编辑器,只需要在安装了Git的前提下将C:\Program Files\Git\usr\bin设置为环境变量即可。(如果Git安装在其他目录下进行相对应的调整就好,设置好了以后重启一次Windows Terminal即可) 如未特别说明,接下来将用wt作为Windows Terminal的简写
注:本文个性化配置包括:
修改Windows Terminal的配色
安装posh-git和oh-my-posh
安装Nerd Font字体
配置oh-my-posh来修改wt的配色和样式
不包括(以下设置在最新版的wt设置中已经包含):
在mbadolato/iTerm2-Color-Schemes 下滑,找到自己喜欢的配色的截图,在截图的左上方会有该配色的代号。
在iTerm2-Color-Schemes/windowsterminal 上找到配色对应的json文件并复制所有的内容。
在wt中打开设置,以下图为例:
打开JSON设置,以图下为例:
将刚刚复制的代码粘贴到有scheme字样的配置目录下,以下图为例:
保存后,回到wt的设置,选择平时主要使用的窗口界面(e.g.PowerShell)然后选择外观,然后选择自己添加的主题,以下图为例:
教程以Hack NF字体为例,如果需要使用其他字体请自行选择。
在这个页面下载的Hack.zip:
ryanoasis/nerd-fonts
解压Hack.zip,然后全选所有文件,右键点击安装
在wt中需要的终端,按配色修改 第6步修改字体为Hack NF即可。
以下教程需要电脑上安装了Git才能使用
使用PowerShell安装post-git和oh-my-posh
指给当前用户(非Administrator)安装:
1 2 Install-Module posh-git -Scope CurrentUserInstall-Module oh -my-posh -Scope CurrentUser
给所有用户安装:
1 2 Install-Module posh-git -Scope AllUsersInstall-Module oh -my-posh -Scope AllUsers
列出所有可用主题
找到自己喜欢的主题,然后使用指令预览(这里以spaceship为例):
1 Set-PoshPrompt -Theme spaceship
在预览结束以后,为了让主题每次启动都生效,需要创建一个脚本。
输入以下指令:
按下按键i,进入插入模式,然后填入以下内容:
1 2 3 Import-Module posh-git
键盘键入:wq然后回车,代表保存并退出。
重新启动wt即可看到自己个性化配置的Windows Terminal界面了。
+
+ 小技巧
+
+
+
+
+
+
+ Windows
+
+ PowerShell
+
+
+
+
+
+
+
+
+ ZeroTier的私有DNS服务器ZeroNSD搭建引导
+ /p/447b77e9.html
+
+ 翻译的时间为2021-9-9,其中部分内容有删改,只提取了主观认为有用的信息,仅供参考
这个功能目前还在Beta测试当中 这个功能将会内嵌在未来将出现的ZeroTier 2.0当中,不过目前它是一个独立的软件 接下来的步骤将会有一定困难 当ZeroTier加入了一个网络后,它将会创建一个虚拟网口 当ZeroTier加入了多个网络后,也会有多个虚拟网口 当ZeroNSD启动了之后,它将绑定在某一个特定的网口上 如果你需要对多个网络都使用ZeroNSD,那你也需要创建多个ZeroNSD服务绑定在它对应的网口上 该教程使用了两台不同的机器,一台是在云上的Ubuntu虚拟机,另外一台为Windows笔记本,如果要跟着来完成这个快速上手,最好使用相同的平台,如果使用了不同的平台,你最好要有能力弄清楚自己要做什么。
按正常流程创建、链接并授权一个以在ZeroTier官网 创建的network
在自己的帐号的Account页面下创见一个新的API Token,ZeroNSD将会利用这个token来获取对应网络下设备的不同名字,来达到自动分配dns的效果。
创建一个文件来让ZeroNSD能够以文件的方式读取token,参考指令如下 需要修改token为自己的token :
1 2 3 sudo bash -c "echo ZEROTIER_CENTRAL_TOKEN > /var/lib/zerotier-one/token"
安装ZeroTier的进程管理应用
zerotier-systemd-manager的rpm和deb安装包发布在这个网站:https://github.com/zerotier/zerotier-systemd-manager/releases ,请自行替换下面指令为最新的安装包。
1 2 wget https://github.com/zerotier/zerotier-systemd-manager/releases/download/v0.2.1/zerotier-systemd-manager_0.2.1_linux_amd64.deb
重启所有的ZeroTier服务
1 2 3 4 sudo systemctl daemon-reload
ZeroNSD针对每一个网络需要都创建一个独立的服务,对DNS来说延迟是很敏感的,所以最好让客户端和服务端尽可能接近
安装ZeroNSD,它的安装包发布在这里 ,请自行替换下面指令为最新的安装包。
1 2 wget https://github.com/zerotier/zeronsd/releases/download/v0.1.7/zeronsd_0.1.7_amd64.deb
如果默认发布的地方没有对应平台的安装包,可以通过Cargo自行编译安装
1 2 > sudo /usr/bin/apt-get -y install net-tools librust-openssl-dev pkg-config cargo > sudo /usr/bin/cargo install zeronsd --root /usr/local
对于你希望启用DNS服务的网络,执行类似以下的命令:
/var/lib/zerotier-one/token为token文件所在路径 (在上文设置token中有提及)
beyond.corp为你希望的域名后缀
af78bf94364e2035为你自己的网络ID
1 2 3 sudo zeronsd supervise -t /var/lib/zerotier-one/token -w -d beyond.corp af78bf94364e2035
服务器需要开放53端口,让客户端可以请求到DNS 客户端需要启用Allow DNS的选项(安卓等平台默认启用,可以无视) 假设笔记本的设备名为laptop,那么此时就可以通过设备名和dns后缀ping通设备了(不考虑防火墙)
1 2 3 4 5 6 7 PS C:\Users\AzureBird> ping laptop.beyond.corp
如果后续需要更新配置(比如TLD),使用类似如下指令即可。(记得修改为自己设置的ID等参数):
1 2 3 sudo zeronsd supervise -t /var/lib/zerotier-one/token -w -d beyond.corp af78bf94364e2035
ZeroNSD还可以添加本地的hosts作为私有的DNS服务,不过由于该部分内容并不复杂,且属于进阶内容,故不做教程,此贴仅作入门参考使用的快速手册。
]]>
+
+ 安装引导
+
+
+
+
+
+
+ ZeroTier
+
+
+
+
+
+
+
+
+ Windows下修改网络优先级广播ZeroTier进行游戏
+ /p/aa5ce7f4.html
+
+ 经常能遇到需要和朋友联机玩一些P2P的联机游戏,但游戏服务器总是因为各种原因延迟很高或者连不上的情况。在使用诸如ZeroTier等一类软件进行组网的时候,在此给出能够让Windows提高虚拟网卡的优先级,让游戏能够在一些无法输入IP的游戏中扫描到同一虚拟局域网下用户的方法。
在谷歌搜索“创建ZeroTier网络”关键词即可找到许多对应教程,在此不多赘述
在有条件的情况下,可以自己搭建Moon中转节点来加速(非必须),教程:ZeroTier下Moon服务器的搭建
该教程以Windows10为例,其他版本的Windows可参考设置
在电脑右下角打开“网络和Internet ”选项
打开"更改适配器选项 "
打开对应ZeroTier的ID的网络属性
打开"Internet 协议版本 4 "下的"属性 "
打开属性中的“高级 ”
修改自动跃点
自动跃点的修改就笔者目前看来对日常使用影响不大,介意的可以在和好友联机结束以后重新勾选即可。并且由测试来看,只要重新连接了网络,Windows都会设置回为“自动跃点”
将优先级设置为1如果不放心的话可以设置为小一点的数字,不过也许有概率无法自动扫描局域网内其他游戏玩家。
在进行了上面的操作,并且两个用户都处于同一ZeroTier的网络下之后,直接打开游戏存档并进入,应该就能在局域网联机中自动扫描到对方。目前已经测试的游戏有:无主之地3、GTFO等,理论上所有可以使用局域网加入的游戏应该都能用相同的方法进行操作。
]]>
+
+ 小技巧
+
+
+
+
+
+
+ ZeroTier
+
+ Windows
+
+
+
+
+
+
+
+
+ 将OpenClash设置为Adguard Home的上级DNS
+ /p/690287f9.html
+
+ 参考结合adguard home 使用 DNS 设置求教 · Issue #99 中hankclc和icyleaf的回答,总结一下设置步骤作为参考
将AdGuard Home的上游DNS设置为OpenClash的DNS地址
OpenClash的DNS地址可以在全局设置中看到,一般为127.0.0.1:7874
关闭OpenClash的本地DNS劫持
AdGuard Home的重定向模式选择使用53端口替换dnsmasq
OpenClash不要用TUN或TUN混合模式(还未自己测试)
]]>
+
+ 小技巧
+
+
+
+
+
+
+ OpenWRT
+
+
+
+
+
+
+
+
+ Rsync使用方法摘抄
+ /p/6d032e05.html
+
+ rsync 用法教程 RSYNC备份服务 Remote-Sync,意味远程动态同步,可以在不同的主机之间进行同步操作,相比一般将文件一次性全部备份而不同的好处是,Rsync可以做到每次增量同步,只对部分文件进行修改,目前个人主要用来和WebDAV挂载的本地目录进行配合使用,对服务器进行备份处理
TODO
TODO
]]>
+
+ 知识记录
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Linux通过修改init.d脚本自启动脚本
+ /p/f3eca903.html
+
+ 创建脚本文件,这里以startup.sh示例
给脚本添加可执行权限,并移动脚本位置
1 2 chmod +x startup.sh
设置为开机脚本
1 2 sudo update-rc.d /etc/init.d/startup.sh defaults 100#
如果需要删除脚本,用remove即可
1 2 sudo update-rc.d /etc/init.d/startup.sh remove
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Docker传递操作进容器内的不同方式
+ /p/14cd2588.html
+
+ 使用docker exec -it命令进入容器(推荐)
假设操作的容器ID为icontainer,如果想要进入icontainer执行指令,只需要输入以下指令:
1 docker exec -it icontainer /bin/bash
如果需要退出容器,输入exit或者Ctrl+C即可
使用docker attach命令进入
同样以icontainer举例,则需要输入以下指令来进入容器终端
1 docker attach icontainer
但这样有缺点,即退出终端的同时,该容器也会同样退出,所以推荐使用exec的方法进入容器
先直接上指令,以容器icontainer为例,我需要将该容器下的/opt/demo/demo.zip拷贝到宿主机的/opt/Backup/下,那么我的指令如下:
1 docker cp icontainer:/opt/demo/demo.zip /opt/Backup/
同理,如果我需要将Backup下的demo.zip传递到容器内,我也可以使用如下指令传输到容器的recover文件夹内:
1 docker cp /opt/Backup/demo.zip icontainer:/opt/recover/
备注:文件传递和容器是否启动无关,都会直接对文件进行修改
+
+ 小技巧
+
+
+
+
+
+
+ Docker
+
+
+
+
+
+
+
+
+ Samba使用说明
+ /p/87299c69.html
+
+ 更新软件
1 2 3 sudo apt-gets upgrade
安装samba服务器
1 sudo apt-get install samba samba-common -y
创建Samba共享文件夹,如共享已存在文件夹则可忽略
按需设置文件夹的访问权限
1 sudo chmod 777 /mnt/Files
创建名为[username]的Samba用户
1 sudo smbpasswd -a [username]
创建或修改Samba服务端配置文件
1 sudo vi /etc/samba/smb.conf
在配置文件最后添加类似以下模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [shareFolderName]# 是否能浏览 # 路径 # 是否以root操作路径内的文件 # 是否公开 #
关闭Ubuntu 防火墙
1 2 sudo ufw disable
重启Samba服务器
1 sudo service smbd restart
安装完毕,在Windows+R下连接
按Windows+R,然后输入"\\IP地址"检查是否能连接
安装必要的软件包(如果尚未安装):
1 sudo apt-get install cifs-utils
创建一个本地挂载点(如果尚不存在):
1 sudo mkdir -p /root/samba
创建凭证文件(如果您尚未创建): 为了安全起见,最好使用一个凭证文件而不是直接在fstab中存储用户名和密码。创建一个文件(例如/root/.smbcredentials),并添加您的用户名和密码:
1 2 username = usernamepassword = password
然后修改该文件的权限:
1 sudo chmod 600 /root/.smbcredentials
编辑/etc/fstab文件: 打开/etc/fstab文件进行编辑:
在文件的末尾添加以下行:
1 // path/to/ smb /root/ samba cifs credentials=/root/ .smbcredentials,iocharset=utf8 0 0
这里,iocharset=utf8确保了正确的字符编码,特别是对于非英文文件名。
挂载测试:可以通过以下命令手动挂载:
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Docker指令和配置手册
+ /p/abf1d877.html
+
+ 参考链接:CSDN-Ubuntu 18.04 DOCKER的安装 停止、删除所有的docker容器和镜像 Docker官网文档 设置用户组docker,让用户不需要sudo也可以使用docker相关命令
1 2 3 4 sudo groupadd docker$USER docker
查看当前所有在运行的Docker容器
docker ps -a
在库内搜索需要的docker容器运行
docker search [name]
获取需要的容器
docker pull [name]
停止所有的容器
docker stop $(docker ps -aq)
删除所有的容器
docker rm $(docker ps -aq)
删除所有目前没有在运行的容器
docker container prune
删除所有的镜像
docker rmi $(docker images -q)
删除所有未被使用的镜像
docker image prune
删除所有未被引用的容器,镜像和各种cache
docker system prune
重命名容器
1 docker rename [Docker的Name] [修改后的Name]
Docker在运行的过程中有许多额外设置,其中包括不同的网络结构,不同的运行模式,交互方法等,目前在这里只记录一些简单用得上的,后续如果还有比较常用的指令再进行补充添加。
docker run -d --restart=always --network host --name CloudMusic nondanee/unblockneteasemusic
docker run
运行docker容器
-d
以后台模式运行
--restart-always
每次docker如果重启了的话也总是自动运行
--network host
以host网络模式运行docker容器,而不是以默认的NAT分布
--name CloudMusic
给这个容器命名为CloudMusic
进入容器docker attach <ID>docker -it <ID> /bin/bash或者docker -it <ID> /bin/sh 通过systemctl设置docker开机自启动
systemctl enable docker.service
docker容器使用--restart=always参数启动
如果已经启动了可以通过docker update --restart=always <ID>添加参数 重启系统以后通过docker ps -a可以看到服务已经在正常运行了
用命令修改
1 docker container update --help
使用这个指令可以在不停止容器的情况下更新部分内容,比如容器的启动方式
配置文件修改
首先要停止容器,才能对容器的配置文件进行修改 配置路径为/var/lib/docker/containers/容器ID下的hostconfig.json就是配置文件
+
+
+
+
+ 知识记录
+
+
+
+
+
+
+ Docker
+
+
+
+
+
+
+
+
+ Linux下有关用户和组的文件权限变动
+ /p/be72c31c.html
+
+ 参考文章1.Ubuntu群组管理
Linux下拥有着不同的用户和群组,群组可以是一个用户的集群,通过修改Linux的用户和对应的群的权限可以较为安全的对文件进行操作。
接下来所有的内容都是基于Ubuntu 20.04 LTS
在我们需要对多个用户进行相同的权限管理的时候,可以通过创建对应群组来进行管理,这里以demog为例
以demo用户为例,在有root权限的情况下输入以下指令来设置demo的初始组为demog
首先是组然后才是用户
要查询当前用户所在的组信息,可以使用类似如下指令
如果要把一个用户添加到多个群组可以用如下指令(先去除后添加,请勿直接尝试指令)
1 groups -G demog1 demog2 demog3 demo
配合-g或者-G参数的时候,会把用户从原本的组里面剔除,然后加入到新的组里面,如果需要的是-a的参数,表示的是“追加”
指令很简单,如下格式
+
+
+
+
+ 知识记录
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Linux通过davfs2挂载WebDav网盘
+ /p/39b9efc1.html
+
+ 注:已改用rclone作为较优方案
davfs挂载与使用缺陷 输入以下指令安装
创建需要挂载的硬盘,这里以/opt/Backup为例,挂载网址为http://localhost:8080/dav/,账号为admin,密码为123456
将硬盘挂载到对应路径
1 sudo mount.davfs http://locaohost:8080/dav/ /opt/Backup/
输入账号密码并手动连接
编辑/etc/davfs2/davfs2.conf,找到其中的use_lock取消注释,并修改值为0
修改/etc/davfs2/secrets,在末尾添加
1 http://localhost:8080/dav/ admin 123456
编辑/etc/fstab,在最后一行添加以下内容
1 http://localhost:8080/dav/ /opt/Backup/ davfs defaults 0 0
以上的http://localhost:8080/dav/和用户名密码均为示例,请在了解WebDav 之后替换为自己需要的值
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Linux下通过硬盘UUID进行挂载
+ /p/c9fc3bb5.html
+
+ 重启后盘符发生变化解决办法 将硬盘接入系统
使用以下指令查询目前磁盘分区的盘符
使用以下指令查询特定盘符的UUID
1 blkid /dev/sda1 ## 这里的sda1要看具体情况填
在/etc/fstab/内编辑类似以下内容挂载磁盘
1 UUID=c26cfce4-xxxx-xxxx-xxxx-403439946c8c /opt ext4 defaults 0 0 ## /opt为具体挂载的目录,ext4为磁盘格式
使用以下指令检查是否设置成功,如果成功则不会返回任何异常信息
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Minecraft服务器配置域名SRV记录隐藏端口
+ /p/1dcf9daa.html
+
+ 目前对于SRV记录了解还不清楚,没有查询具体可以使用的服务等。目前需要的也只是达到转发MC的端口,达到隐藏端口的目的,所以只是一个无脑式记录。
拥有一个域名,并且指向了一个带有端口的MC服务器,比如rpg.vastl.icu:25566
在DNS控制台添加解析记录。
1 2 3 主机记录:_minecraft._tcp.xx ## xx为子域名
最后应用即可。
+
+ 小技巧
+
+
+
+
+
+
+ Minecraft
+
+
+
+
+
+
+
+
+ ZeroTier搭建Planet服务器引导
+ /p/1e0fb80b.html
+
+ Running MPLS over ZeroTier Part 1 · Gotz Networks 把ZeroTier的项目在本地克隆一份
1 git clone https://github.com/zerotier/ZeroTierOne.git
打开在attic文件夹下的world文件夹
1 cd ZeroTierOne/attic/world
编辑mkworld.cpp文件,把ZeroTier Controller默认的IP删除,添加自己的IP上去。
编译文件
运行mkworld文件
应该会产生一个新的world.bin文件,这个文件需要在所有自己的客户端添加
将这个world.bin文件复制到ZeroTier的文件夹下,在Linux中的指令为
1 cp world.bin /var/lib/zerotier-one/planet
重启ZeroTier
1 sudo systemctl restart zerotier-one.service
重复第七步和第八步,在所有希望使用自己Planet服务器的客户端中添加这个节点
完全使用自己的服务器,数据等不通过ZeroTier自己的官网。
]]>
+
+ 安装引导
+
+
+
+
+
+
+ ZeroTier
+
+
+
+
+
+
+
+
+ Ubuntu删除无用的包和垃圾文件
+ /p/77f84830.html
+
+ Ubuntu删除无用缓存及垃圾文件 1 2 3 sudo apt-get autoclean ## 清理旧版本的软件缓存
这三个指令主要是用于清理升级时候产生的缓存和无用的包
包在/var/cache/apt/archives 没有下载完毕的在/var/cache/apt/archives/partial 1 2 sudo apt-get remove --purge [软件名字] ## 卸载某个软件
1 sudo apt-get install deborphan -y
见博客:删除多余的Ubuntu内核,解决因grub无法正常启动的问题
]]>
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Ubuntu通过systemd禁用系统睡眠
+ /p/2f594679.html
+
+ How To: Disable Sleep on Ubuntu Server (unixtutorial.org) 1 sudo systemctl status sleep.target
理论上会返回类似如下的内容,里面会注明系统休眠的时间等信息
1 2 3 4 5 6 7 8 9 10 root@azhal:~## systemctl status sleep.target
1 sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
[引用文章原话] This is obviously a very simple way of disabling power management, but I like it because it’s standard and logical enough – there’s no need to edit config files or create cronjobs manually controlling sleep functionality.
大概翻译过来就是指这样的操作标准且合理,因为这样省去了编辑任何文件的麻烦,并且也达到了禁用休眠的目的。
禁用以后大致会变成这样:
1 2 3 4 5 6 7 8 9 root@azhal:~## systemctl status sleep.target
1 sudo systemctl unmask sleep.target suspend.target hibernate.target hybrid-sleep.target
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Linux下7zip的使用手册
+ /p/cc7f9b10.html
+
+ 直接使用apt安装即可
压缩文件/文件夹
1 7za a -t7z -r MyTest.7z FolderToZip/*
将FolderToZip文件夹下所有文件压缩到当前目录的MyTest.7z文件中
a 代表添加文件/文件夹到压缩包
解压缩文件夹
将MyTest.7z解压到当前目录
x 代表解压缩文件,并且是以原本文件夹的方式解压(还有一个参数是e,会直接把所有文件从根目录解压)
参考文章:
linux下安装7z命令及7z命令的使用
+
+ 知识记录
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Cloudflare Partner的CDN配置
+ /p/6a6a7409.html
+
+ 由于服务器本身搭建使用的是香港的服务器,建站不需要域名备案。为了不使用Cloudflare默认的海外CDN,而使用我们需求的自定义CDN,需要把域名托管到一个非Cloudflare的平台下,这里直接托管到腾讯云Dnspod的解析下。
备份Cloudflare下的解析信息
在控制台下修改Name Server为Dnspod控制台提供的NS服务器
将之前备份的解析信息再次添入
(这里没找到Dnspod的导入域名信息,所以手动添入)
开启"域名设置"下的CNAME加速,减少CNAME的解析次数
注册Cloudflare邮箱,这里不做解释
在 楠格 (或者类似Cloudflare Partner网站) 登入自己的Cloudflare账号
将自己需要使用CDN的域名添加到控制台下,TTL设置两分钟,CDN设置为开启
添加完毕以后在CNAME接入处可以看到主机名对应的CNAME信息,在Dnspod设置对应的解析就可以使用CDN的解析服务。
CNAME信息
Dnspod设置
通过参考网上的IP表,在Dnspod的控制台中再次添加域名对应的A记录解析,可以设置不同的运营商解析不同的IP,来达到让流量走自定义加速的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 172.64.32.1/24 (推荐移动,走香港)
设置了对应的A记录后保存退出,可通过ping example.com来测试是否设置成功。
参考网站:
针对使用Cloudflare CDN国内网站的速度优化方案 - 闪电博 (wbolt.com)
+
+ 小技巧
+
+
+
+
+
+
+ CDN
+
+
+
+
+
+
+
+
+ Linux多个不同版本内核卸载管理
+ /p/24f916f9.html
+
+ 查看当前的内核
1 2 root@azhal:~## uname -a
查看当前系统中所有的内核
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 root@azhal:~## dpkg --get-selections |grep linux
移除多余的内核
1 sudo apt-get remove <name of kernel>
再次检查内核是否为deinstall状态
1 dpkg --get-selections |grep linux
更新系统引导
参考文章
Ubuntu删除多余的内核 - 阳光与叶子 - 博客园 (cnblogs.com)
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Nginx配置CDN回源重定向导致的无法访问问题
+ /p/a2277ea0.html
+
+ 在部署好了CloudReve和Nginx以后,想通过Cloudflare的免费的CDN服务来达到一个节省流量的目的,但是在直接开启CDN代理之后发现原本的网站一直出现Network Error的问题,在此记录一下解决方案。
首先记录一下现状:
CloudReve部署在自己家的服务器上,通过ZeroTier和香港的服务器虚拟局域网相连,并且通过Nginx反代 Nginx配置好了SSL证书,开启了强制使用HTTPS链接 测试的现状:
在开启强制HTTPS链接的时候使用CDN加速,连接CloudReve的时候会出现Network Error,网页控制台报错重定向次数过多。 关闭强制HTTPS链接使用CDN加速并且通过HTTPS进行链接的时候正常。 参考了的可能有帮助的解决方案
踩坑记录:CDN开启强制https之后返回重定向次数过多的问题 由于CDN是先到香港的服务器,是https访问,然后香港的服务器到自己的网盘是http访问,根据上方参考的"踩坑记录"方案一,给家里的服务器的cloudreve加了一个ssl证书再次尝试代理,问题依旧。
同根据“踩坑记录”,在nginx的配置文件中添加以下配置
proxy_set_header X-Forwarded-Proto $scheme;
附上解释原因:
设置http头部X-Forwarded-Proto,这个头部的作用是用于识别协议(HTTP 或 HTTPS),主要针对内部访问重定向时的协议。因此,只要在反向代理时添加以上配置就好了
$scheme是nginx的内部变量,表明当前访问的协议,当前如果是https,那么转发到后台服务的时候就是https。这样问题就解决了。
但是问题依旧
之后认为问题不出在香港服务器到家中服务器,寻找其他的解决方案。
在查询和强制HTTPS有关词条的时候查询到这是CDN云加速很容易遇到的一个问题,解决方案主要有三种。
设置CDN的回源端口为443端口,让CDN回源的时候以HTTPS请求源站,这样就不会触发源站的强制跳转的逻辑了。 在CDN的控制台中设置回源设置为“跟随”(一般会有三个选项,分别是“回源”,“HTTP”和“HTTPS”。) 放弃强制跳转HTTPS,在Nginx关闭强制。 由于没有找到Cloudflare上有类似CDN控制台的地方(感觉毕竟是免费的,没有正常。不过也可能是我太菜了不知道在哪里),于是上面的三种办法都不得不作罢,只能另寻其他办法。
香港的服务器上关闭Nginx的强制https 在cloudflare的"Rules"里面添加Page Rules,设置里面添加对应的域名,然后开启始终使用HTTPS 有一说一,结果是启用了免费的CDN以后速度还是比较慢,而且多线程下载也没有缓存很多文件,后期还是试试Cloudflare Partner或者其他的项目比较好。
+
+ 小技巧
+
+
+
+
+
+
+ Nginx
+
+ CDN
+
+
+
+
+
+
+
+
+ Google镜像站创建引导
+ /p/15b685e1.html
+
+ 步骤如下:在Nginx中创建Google的Nginx反代www.google.com.hk
配置SSL证书并保存,启用HTTPS
配置upstream设置
在server中配置防爬虫和禁止IP访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 server if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot") { return 403; } # 禁止用其他域名或直接用IP访问,只允许指定的域名访问 #forbid illegal domain if ( $host != " yourdomain.com" ) { return 403; } ... }
检查并重启配置文件
nginx -t && nginx -s reload
在宝塔防火墙中关闭’GET’过滤,否则会导致搜索某些关键词的时候被误判封锁IP
参考文章:
(´∇` ) 被你发现啦~ 搭建google镜像网站(适用最新版nginx)Module for Google Mirror – 深海 (oyi.me)
+
+
+
+
+ 安装引导
+
+
+
+
+
+
+ Nginx
+
+
+
+
+
+
+
+
+ SSH技巧总结
+ /p/cff2e0b5.html
+
+ 在客户端电脑上输入以下指令生成rsa私钥和公钥
ssh-keygen -t rsa -C "your@email.com"
生成一对以你的邮箱为标签的密钥
在/.ssh/文件夹下的id_rsa为密钥文件,id_rsa.pub为公钥文件
在当前用户的主目录中的/.ssh/中添加或者修改authorized_keys文件,将刚刚客户端的id_rsa.pub内容复制到authorized_keys中 编辑sshd_config文件
vi /etc/ssh/sshd_config
禁用密码验证
将PasswordAuthentication的注释取消,并修改为
PasswordAuthentication no
重启SSH服务
注意,重启SSH服务之前建议保留一个会话,以免出现密码登入失败的情况
在建立连接的时候,如果是第一次对一个服务器建立连接,经常会问到我们是否信任对方,并且在第一次建立连接之后,如果同一个IP地址后的服务器有过重装,还会因为之前保存的证书而出现连接失败的情况。
因此可以在~/.ssh/config文件中添加以下配置
1 2 StrictHostKeyChecking no # 关闭主机公钥的确认信息,去掉了连接时候的提问,不过也因此有安全隐患,需要自己权衡
同时,有的时候我们需要频繁访问同一个服务器,反复输入ssh root@xxx.xxx.xxx.xxx是很令人恼火的一件事(即使有的域名或历史记录)。这个时候我们就可以通过在config中添加一个Host来给我们需要的服务器添加一个简单易懂的别名来建立连接
1 2 3 Host router
假设我们路由器的IP地址是192.168.100.123,那么我们就可以将原本的
1 ssh root@192.168.100.123
改为
这样ssh就会使用root用户来登入192.168.100.123了
对于一些有GUI的Linux系统来说,有的时候我们并不希望远程整个桌面,而是通过SSH来运行部分图形化的程序。在Windows当中,我们可以通过安装VcXsrv来提供一个SSH的转发接口,然后在~/.ssh/config中对应的服务器添加如下参数
1 2 3 4 5 Host study
这样我们在和对应服务器建立连接以后,就可以通过在自己电脑上的cli运行远程服务器中带有GUI
在有的时候ssh需要连接的主机可能很多,放在一个文件里面可能会不便于管理。这个时候我们就可以通过Include关键字,来添加其他的config合并进来。
假设当前我们的.ssh目录的结构如下
1 2 3 4 5 6 7 8 ~ [ tree .ssh ] 1:40 PM
那么我们就可以在config当中添加Include conf.d/home来实现对于home文件的多文件配置涵盖。参考如下
1 2 3 4 5 6 7 8 9 10 11 StrictHostKeyChecking no
在home当中就可以添加正常的ssh配置了
]]>
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+ SSH
+
+
+
+
+
+
+
+
+ 二分查找
+ /p/e8eb0481.html
+
+ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int bsl (int l, int r) while (l < r)int mid = l + r >> 1 ;if (check (mid)) else 1 ; return l;int bsr (int l, int r) while (l < r)int mid = l + r + 1 >> 1 ;if (check (mid)) else 1 ;
bsl为例 二分的主要的作用,是取得一个“分界点”。采取的思路为测试中间点是否符合条件,如果不符合则对区间进行缩小操作,重新测试区间,直到区间为一个数字。在模板一中,首先确定中间点mid,然后测试中间点mid是否符合条件,如果符合条件,则每次都会 将区间的右端点进行左移的操作,直到不能左移为止 ,所以返回的最后位置为最接近答案的最左边的端点 。如果不符合条件,由于**确定了mid的位置为无效位置,所以下一次刷新区间的时候将mid剔除掉。**剔除的操作可以达到防止死循环的效果
由于二分是每次都将一个区间一分为二,并且对整个区间进行一次操作,所以最后的时间复杂度为O(logN)
在bsr中,由于在每次正确的时候修改的都是左边界l,但是在计算除2的时候会存在mid/2取整为l的情况,这样会导致最后结果的死循环。所以需要定义mid为mid = l+r+1>>1来避免死循环。可以记为 返回右边界的时候需要+1,因为右边比左边大(bushi
+
+ 知识记录
+
+
+
+
+
+
+ Algorithm
+
+
+
+
+
+
+
+
+ CloudReve个人网盘引导
+ /p/713e2886.html
+
+ 安装好宝塔面板,并且预先安装好LNMP环境 Aria2离线下载配置 在FreeSSL 上获取SSL证书和密钥 前往官方库 下载最新版的对应系统的可执行文件
在BT面板内添加网站CloudReve,并且设置对应的域名和根目录(下图为示例)
将可执行文件上传到在宝塔面板设置的根目录中,并cd到当前目录
运行CloudReve,并记录初始的账号密码
1 2 chmod +x ./cloudreve
登入http://ip:5212,在控制面板中修改默认的管理员账号和密码
自带的数据库是SQLite,这里需要修改为MySql
在宝塔面板创建一个MySql数据库
在运行一次CloudReve后,根目录会有一个conf.ini的文件,根据自己情况加入以下配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ; 数据库相关,如果你只想使用内置的 SQLite数据库,这一部分直接删去即可
这里使用Ubuntu自带的systemd进行进程守护
编辑配置文件
vim /usr/lib/systemd/system/cloudreve.service
将下文的PATH_TO_CLOUDREVE更改为宝塔面板中设置的根目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [Unit]
载入进程守护并运行
1 2 3 systemctl daemon-reload
在宝塔面板的站点设置中,添加反向代理,配置按下图类比设置(主要还是第二步)
点击配置文件,将原本的location /{}的内容替换如下内容
1 2 3 4 5 6 7 8 9 location / {$proxy_add_x_forwarded_for ;$http_host ;
保存配置文件,通过宝塔中设置的网站域名即可直接访问网盘地址
在FreeSSL获取证书以后,在KeyManager中导出证书和私钥,分别为.crt和.key文件 在站点设置中找到SSL,使用其他证书,然后通过编辑器打开crt证书文件和key文件,分别将其中的内容复制到密钥(KEY)和证书(PEM格式)中 保存并开启强制HTTPS,即可通过SSL访问云盘并且进行配置了。 参考网站:
Cloudreve对接onedrive搭建属于自己的网盘系统 (lanhui.co) CloudReve官方文档
+
+ 安装引导
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Linux配置局域网下网络唤醒
+ /p/12aa3ef8.html
+
+ 安装网络管理工具
sudo apt install ethtool
查询网口信息
ip a
记录需要启动的网口名字
通过指令手动启动wol服务
ethtool -s [INTERFACE] wol g
查询是否成功
ethtool [INTERFACE]
输出信息中如果显示wol:g则代表开启成功
创建开机进程
sudo vi /etc/systemd/system/wol.service
写入以下内容
1 2 3 4 5 6 7 8 9 [Unit]
载入systemd并启动
1 2 3 sudo systemctl daemon-reloadenable wol.service
参考博客
1.WOL持久化设置
]]>
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Docker的安装和镜像设置
+ /p/92f7b8a.html
+
+ 参考资料:Docker-从入门到实践 在挂载网易云音乐灰色代理的时候终于还是发现了screen后台运行的坏处,经常会出现不小心重启以后忘记开启服务的情况,由于之前一直听说过docker容器,并且灰色代理有现成的docker容器可以使用,在简单查询和操作了一下以后记录一下docker启动网易云音乐并且进行网易云音乐代理的实战
(可选) 通过一键脚本进行安装,安装完成后可跳过以下所有步骤
1 2 curl -fsSL get.docker.com -o get-docker.sh
如果要安装测试版的Docker,则用以下脚本
1 2 curl -fsSL test.docker.com -o get-docker.sh
使用apt进行安装
1 2 3 4 5 6 7 8 sudo apt-get update
替换国内软件源
1 2 3 4 5 curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgecho \"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
安装Docker
1 2 sudo apt update
启动Docker
1 2 sudo systemctl enable docker
检测是否已经设置镜像
请首先执行以下命令,查看是否在 docker.service 文件中配置过镜像地址。
1 $ systemctl cat docker | grep '\-\-registry\-mirror'
如果该命令有输出,那么请执行 $ systemctl cat docker 查看 ExecStart= 出现的位置,修改对应的文件内容去掉 --registry-mirror 参数及其值,并按接下来的步骤进行配置。
设置镜像
创建并编辑/etc/docker/daemon.json
写入以下内容
1 2 3 4 5 6 {
重启服务
1 2 sudo systemctl daemon-reload
检测是否正常
docker run --rm hello-world
通过检查返回信息检查是否成功安装并且部署Docker环境
+
+
+
+
+ 安装引导
+
+
+
+
+
+
+ Docker
+
+
+
+
+
+
+
+
+ Linux通过fdisk分区引导
+ /p/3efcbb51.html
+
+ 参考地址:CSDN-树莓派Openwrt SD卡扩展问题 在给自己的R2S使用64G的SD卡的时候,安装完毕系统启动发现内存卡中有将近50多G的空间没有得到合理的使用,记录一下通过网上树莓派磁盘扩展分区的步骤来在R2S上同样对SD卡进行分区拓展
磁盘检查
df -h 检查已经使用的磁盘容量
fdisk /dev/mmcblk0 查看磁盘分区,并进行部分操作
检查磁盘分区情况并且进行分区
在fdisk后的Command( m for help):后输入p来查看分区情况
其中可以看到最后分区的End为3817471
新建磁盘
输入n进行新建磁盘,之后会有几个询问,分别对应以下几点
输入磁盘编码,一般按Default的设置即可 输入扇区的起始位置,这里输入最后一个分区+1的数值大小,比如上图中End后为3817471,那我这里就输入3817472 输入终止扇区,这里可以填入Default设置,就会设置最大可用扇区 输入w进行保存 把新建的分区格式化为ext4格式
mkfs.ext4 /dev/mmcblk0p3
分区挂载
方法一在Openwrt的管理界面的挂载点中,直接使用"自动挂载"进行磁盘的挂载 方法二mount -v -t ext4 -o rw /dev/mmcblk0p3 [pathToMount] 通过df -h命令查看,可以发现已经挂载成功
+
+
+
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+ OpenWRT
+
+
+
+
+
+
+
+
+ Linux下通过swap或zram管理内存
+ /p/5a7c7761.html
+
+ 参考网址:Ubuntu开启zram和zswap~ 使用zram进行内存压缩 Ubuntu添加swap分区 Swap分区在系统的物理内存不够用的时候,把物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap分区中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。
Swap分区虽然可以达到扩大内存的作用,但缺点依旧很明显,相比直接使用物理内存,Swap必然速度上会出现一定的取舍。
新建一个文件夹来作为swap的文件
1 2 3 mkdir swap
其中sfile是文件的名字,可以自己设置,count=2000000是Swap分区的大小,这里指2G
转化为swap文件
sudo mkswap sfile
激活swap文件
sudo swapon sfile
查看效果
free -m
1 2 3 total used free shared buff/cache available
已经成功挂载了
添加开机加载
修改配置文件,添加Swap文件(Swap文件的路径为/root/swap/sfile)
/root/swap/sfile none swap sw 0 0
类似如下
1 2 3 4 /dev/vda1 / ext4 defaults 1 1
swap空间在机械硬盘的设备上往往不一定是个好选择,这个时候牺牲一定的CPU性能来使用zram则会比较好
zram 是在 Linux Kernel 3.2 加入的一个模块,其功能是在内存中开辟一块空间,用来存储压缩后的内存数据,这样可以在牺牲一定的 CPU Cycle 的情况下,在内存中存储尽量多的数据而不需要写入到磁盘。
安装zram-config,并重启系统
1 2 sudo apt install zram-config
通过zramctl查看zram的情况(默认情况下ALGORITHM为lzo)
1 2 NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
注意到这里的压缩算法,有两种算法 lzo 和 lz4 可选,默认是 lzo。根据 Benchmark ,lz4 的压缩和解压性能在压缩率和 lzo 持平的情况下显著高于后者,因此我们应该采用 lz4 而非 lzo 以获得更高的系统效率。
修改配置文件来使用lz4算法
usr/bin/init-zram-swapping
将源文件的以下部分
1 2 3 4 5 6 7 #
替换为
1 2 3 4 5 6 7 8 #
载入新的配置
systemctl restart zram-config
编辑grub文件
sudo vi /etc/default/grub
在文件末尾加上
1 GRUB_CMDLINE_LINUX=”zswap.enabled=1″
保存退出
在终端输入命令
sudo update-grub
重启系统
zswap是一种新的轻量化后端构架,将进程中正交换出的页面压缩,并存储在一个基于RAM的内存缓冲池中。除一些为低内存环境预留的一小部分外,zswap缓冲池不预先分配,按需增加,最大尺寸可用户自定义。
Zswap启动存在于主线程中的一个前端,称为frontswap,zswap/frontswap进程在页面真正交换出之前监听正常交换路径,所以现有的交换页面选择机理不变。
Zswap也引入重要功能,当zswap缓冲池满时自动驱除页面从zswap缓冲池到swap设备。防止陈旧页面填满缓冲池。
+
+
+
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ ZeroTier配置Moon服务器
+ /p/c1161a88.html
+
+ 参考链接:什么值得买-ZeroTier配置Moon节点 2.ZeroTier官方手册
ZeroTier本身的PLANET服务器位于国外,并且由于免费的性质以至于在一些高峰时期经常出现无法打通隧道的情况,这个时候通过自己搭建国内的Moon节点并且进行配置可以达到国内中转加速的作用。
将需要设置moon节点的VPS加入到需要加速的局域网内
zerotier-cli join <network id>
生成moon模板
1 2 cd /var/lib/zerotier-one
修改moon.json
vi moon.json
修改stableEndpoints为VPS的公网IP,可以添加ipv6地址,例如:
"stableEndpoints": [ "10.0.0.2/9993","2001:abcd:abcd::1/9993" ]
完整的文件内容示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 {"id" : "deadbeef00" ,"objtype" : "world" ,"roots" : ["identity" : "deadbeef00:0:34031483094..." ,"stableEndpoints" : [ "10.0.0.2/9993" ,"2001:abcd:abcd::1/9993" ]"identity" : "feedbeef11:0:83588158384..." ,"stableEndpoints" : [ "10.0.0.3/9993" ,"2001:abcd:abcd::3/9993" ]"signingKey" : "b324d84cec708d1b51d5ac03e75afba501a12e2124705ec34a614bf8f9b2c800f44d9824ad3ab2e3da1ac52ecb39ac052ce3f54e58d8944b52632eb6d671d0e0" ,"signingKey_SECRET" : "ffc5dd0b2baf1c9b220d1c9cb39633f9e2151cf350a6d0e67c913f8952bafaf3671d2226388e1406e7670dc645851bf7d3643da701fd4599fedb9914c3918db3" ,"updatesMustBeSignedBy" : "b324d84cec708d1b51d5ac03e75afba501a12e2124705ec34a614bf8f9b2c800f44d9824ad3ab2e3da1ac52ecb39ac052ce3f54e58d8944b52632eb6d671d0e0" ,"worldType" : "moon"
生成moon签名文件
zerotier-idtool genmoon moon.json
通过winscp等工具将000000xxxx.moon的签名文件拷贝下来,或者记住moon.json中"id": "idtoremember"的id
将moon节点加入网络
1 2 mkdir moons.dmv ./*.moon ./moons.d
重启ZeroTier,到此Moon服务器的配置结束。
在搭建moon服务器的第五步中,记录下moon节点的id,然后在客户端上运行命令
zerotier-cli orbit idtoremeber idtoremeber
在不同设备的ZeroTier根目录下添加moons.d文件夹
1 2 3 4 5 其中,不同系统对应的ZeroTier的位置如下:
将生成的0000xxx.moon文件放置于moons.d文件夹下
OpenWrt需要修改一个脚本,因为其var目录是一个内存虚拟的临时目录,重启后原有配置不会保留。
通过ssh连接到Openwrt并修改zerotier的启动脚本
在add_join(){}上方插入两行代码
1 2 mkdir -p $CONFIG_PATH /moons.dcp /home/moons.d/* $CONFIG_PATH /moons.d/
如下图所示:
在/home文件夹下创建moons.d文件夹(修改cp /home/moons.d可以修改需要设置的路径)
把moon的签名文件00000xxx.moon放于该文件夹内,并重启ZeroTier即可
启动Openwrt上的ZeroTier
输入以下指令
1 cp -a /var/lib/zerotier-one /etc/zerotier
修改/etc/config/zerotier的配置文件,添加以下内容
option config_path '/etc/zerotier'
+
+
+
+
+ 安装引导
+
+
+
+
+
+
+ ZeroTier
+
+
+
+
+
+
+
+
+ Openwrt系统内配置Frpc自启动
+ /p/99e48799.html
+
+ Frpc在Openwrt上的客户端多多少少有点问题,为了方便自己使用,在这里记录一下如果用命令行启动和编辑Frpc的流程
首先,在 fatedier/frp 中下载最新版的frp打包程序,以下以0.35.1版本为例
1 2 3 wget https://github.com/fatedier/frp/releases/download/v0.35.1/frp_0.35.1_linux_amd64.tar.gzrm frp_0.35.1_linux_amd64.tar.gz
首先切换到frp的目录下,把frpc和配置文件放于service对应的目录下
1 2 3 4 5 cd frp_0.35.1_linux_amd64mv frpc /usr/binchmod 755 /usr/bin/frpc mkdir /etc/frpmv frpc.ini /etc/frp
之后通过指令编辑frpc.ini
sudo vi /etc/frp/frpc.ini
之后,编辑/etc/init.d/frpc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #!/bin/sh /etc/rc.common "/usr/bin/frpc -c /etc/frp/frpc.ini" start_service command $PROC service_triggers "rpcd"
脚本来自OpenWRT/LEDE下开机脚本
配置文件就结束了之后只需要直接启用和启动frpc即可
1 2 /etc/init.d/frp startenable && echo on
另外由于不需要配置frps服务,可以回到上级目录并把下载的文件全部删除
1 2 cd ~rm -rf frp_0.35.1_linux_amd64
+
+ 安装引导
+
+
+
+
+
+
+ Frp
+
+
+
+
+
+
+
+
+ 拓展Ubuntu服务器内LVM分区容量引导
+ /p/2dda2597.html
+
+ 参考文章:解决 Linux /dev/mapper/ubuntu–vg-ubuntu–lv 磁盘空间不足的问题
通过命令查看LVM卷组的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root@azhal:/mnt/Ar2Dread /write
可以看到可扩容大小
Free PE / Size 186882 / <730.01 GiB
使用命令进行扩容
按不同需求有以下命令:
1 2 3 4 5 6 lvextend -L 10G /dev/mapper/ubuntu--vg-ubuntu--lv //增大或减小至19G
具体操作:
1 2 3 4 5 6 7 8 root@azhal:/mnt/Ar2D
检查是否扩容成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root@azhal:/mnt/Ar2Dread /write
可以看到Free Size已经变成0,即扩容成功。
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+
+
+
+
+
+
+
+ Windows系统中校验文件哈希值
+ /p/a9706dff.html
+
+ 每次要查询一个文件的hash值的时候总要打开一个hash校验工具,觉得有些麻烦了,加上也不是所有文件都会经常需要校验,就常常并不想单独下载一个工具,查询到Windows有自带的hash校验指令,于是记录一下,以下内容摘自知乎 使用certutil
Windows从Win7开始,包含了一个CertUtil命令,可以通过这个命令来计算指定文件的杂凑值(Hash Value)
使用的指令为:
certutil -hashfile [fileName] [algorithm]
其中[algorithm]指不同的hash算法,可以取的值有:MD2、MD4、MD5、SHA1、SHA256、SHA384、SHA512 。
例子:
certutil -hashfile D:\test.txt MD5
使用Get-FileHash
Get-FileHash [fileName] -Algorithm [algorithm]
其中,支持的算法有MACTripleDES、MD5、RIPEMD160、SHA1、SHA256、SHA384、SHA512 。
显示效果:
其中,为了方便观察可以通过管道使用Format-List
Get-FileHash .\test.txt -Algorithm SHA512 | Format-List
显示效果:
+
+
+
+
+ 小技巧
+
+
+
+
+
+
+ Windows
+
+
+
+
+
+
+
+
+ 搭建ZeroTier Controller管理网络引导
+ /p/41385a4a.html
+
+ 本来的理解 : 在使用ZeroTier的时候经常会出现穿透失败,或者穿透延迟过大但是中转服务器不好用的情况,之前有参考过网上的教程来通过一台国内的VPS搭建自己的MOON节点来达到加速的目的,但是最后的效果不尽人意,而且还存在安卓端添加mood节点并不轻松的问题,所以在这里采取直接通过key-networks/ztncui: ZeroTier network controller UI 搭建自己的ZeroTier根服务器
最近在使用zerotier-cli listpeers指令的时候发现设置的控制器是一个LEAF而不是本来预期的PLANT,在查阅了一部分资料之后发现如果想要加速网络的话目前比较好的方便还是MOON服务器进行中转,详情参考另外一篇ZeroTier下Moon服务器的搭建。
准备好一台在国内,至少开放端口3443端口的服务器(暂未测试对其他端口是否有需求)
在服务器内安装ZeroTier,以下为一键安装脚本
curl -s https://install.zerotier.com | sudo bash
如果服务器有安装GPG,则需要多几个步骤
1 2 curl -s 'https://raw.githubusercontent.com/zerotier/ZeroTierOne/master/doc/contact%40zerotier.com.gpg' | gpg --import && \if z=$(curl -s 'https://install.zerotier.com/' | gpg); then echo "$z " | sudo bash; fi
sudo yum install https://download.key-networks.com/el7/ztncui/1/ztncui-release-1-1.noarch.rpm -y
sudo yum install ztncui -y
(可选择):添加服务器自己的TLS/SSL证书,或者添加服务器自认证的证书 - 后文有教程
开放服务器的3443端口(已开放可忽略)
sudo sh -c "echo 'HTTPS_PORT=3443' > /opt/key-networks/ztncui/.env"
sudo sh -c "echo 'NODE_ENV=production' >> /opt/key-networks/ztncui/.env"
sudo systemctl restart ztncui
通过HTTPS来在服务器的3443端口访问控制界面,比如
e.g. https://my.network.controller:3443
通过默认的账号admin和密码password.
curl -O https://s3-us-west-1.amazonaws.com/key-networks/deb/ztncui/1/x86_64/ztncui_0.7.1_amd64.deb
sudo apt-get install ./ztncui_0.7.1_amd64.deb
(可选择):添加服务器自己的TLS/SSL证书,或者添加服务器自认证的证书 - 后文有教程
开放服务器的3443端口(已开放可忽略)
sudo sh -c "echo 'HTTPS_PORT=3443' > /opt/key-networks/ztncui/.env"
sudo sh -c "echo 'NODE_ENV=production' >> /opt/key-networks/ztncui/.env"
sudo systemctl restart ztncui
通过HTTPS来在服务器的3443端口访问控制界面,比如
e.g. https://my.network.controller:3443
通过默认的账号admin和密码password.
如果要添加额外的监听端口,只需要在/opt/key-network/ztncui下面添加一个.env文件,其中附带一行
HTTPS_PORT=3443
或者任意一个大于1024的端口即可。
如果存在.env文件来指向特定的一个端口,那么ztncui将会在所有的端口监听网络,如果希望限制一个特定的IP进行监听的话,只需要在.env文件中再添加一行
HTTPS_HOST=12.34.56.78
来设置自己制定的IP或者域名即可。
这种方法添加的证书会存在浏览器警告的问题,不过由于是自己使用,平时也不会一直盯着控制界面,所以影响应该不会很大,如果有共用或者对安全有需求建议自行添加
以下为无脑脚本
1 2 3 4 5 6 sudo -icd /opt/key-networks/ztncui/etc/tlsrm -f privkey.pem fullchain.pemchown ztncui.ztncui *.pemchmod 600 privkey.pem
由于ztnui是自己搭建的一个ZeroTier服务器,所以并没有预先设置好的DHCP分配,需要自己设置分配范围。如果需要添加一个新的网络,在使用账号密码登入以后,点击Add network就可以添加一个自己的虚拟局域网络
点击Add network
设置好network的名字并create
如果需要设置"隐私"与否,在Private中设置即可,这里稍作翻译即可看懂,所以不多解释
点击如下图所示的Easy Setup来快速完成一个IPv4的DHCP分配
如下图所示填入对应信息
以下为一个例子:
1 2 3 网关:192.168.192.0/24
然后点submit即可快速创建,也可以通过generate network address的方式自动随机填入。
如果需要设置NAT路由,则只需要在Routes下进行配置和添加即可。
+
+ 安装引导
+
+
+
+
+
+
+ ZeroTier
+
+
+
+
+
+
+
+
+ Devc++调试相关选项配置
+ /p/c9774a05.html
+
+ 由于蓝桥杯比赛需要使用Devc作为IDE工具,平时用习惯了vscode的snap和其他功能以后觉得如果不提前适应一下Devc 的编译环境的话在比赛的时候会吃很大的亏,于是决定之后的学习都用Devc进行,在此记录一下Devc 启用调试之前需要的一些基本设置
貌似在按F5准备进行调试的时候,即使自己没有进行以下设置,Devc++依旧会询问并且可以直接打开进行设置,这里只做一个提前设置的记录,并非必须
首先,打开devc++之后,找到上方的Tools(工具),如下图所示,打开其中的Compiler options(编译选项)
然后按下图开启调试信息(设置为yes)
再次打开Tools,并且打开Enviroment options
启用下图黄线部分的选项,开启显示指针所指变量的值
+
+ 小技巧
+
+
+
+
+
+
+ Devc++
+
+
+
+
+
+
+
+
+ Ubuntu下创建拥有sudo权限的用户
+ /p/9232cf7b.html
+
+ 添加用户
添加sudo权限
1 2 # 表示将username追加到sudo权限组当中
检查是否拥有sudo权限
1 2 # 更新ubuntu软件源
+
+ 小技巧
+
+
+
+
+
+
+ Ubuntu
+
+ Linux
+
+
+
+
+
+
+
+
+ 手动在服务器上安装Frp
+ /p/1d3a895d.html
+
+ 首先,在 fatedier/frp 中下载最新版的frp打包程序,以下以0.35.1版本为例
1 2 3 wget https://github.com/fatedier/frp/releases/download/v0.35.1/frp_0.35.1_linux_amd64.tar.gzrm frp_0.35.1_linux_amd64.tar.gz
首先切换到frp的目录下,把frpc和配置文件放于service对应的目录下
1 2 3 4 5 cd frp_0.35.1_linux_amd64mv frpc /usr/binchmod 755 /usr/bin/frpc mkdir /etc/frpmv frpc.ini /etc/frp
之后通过指令编辑frpc.ini
sudo vi /etc/frp/frpc.ini
之后,切换到services的目录下,将frpc.service移动到系统的systemctl进程守护下,并启用权限
1 2 3 4 5 cd ./systemdmv frpc.service /usr/lib/systemd/systemchmod 644 /usr/lib/systemd/system/frpc.servicemv frpc@.service /usr/lib/systemd/systemchmod 644 /usr/lib/systemd/system/frpc@.service
配置文件就结束了之后只需要直接启用和启动frpc即可
1 2 sudo systemctl enable frpc
另外由于不需要配置frps服务,可以回到上级目录并把下载的文件全部删除
1 2 cd ~rm -rf frp_0.35.1_linux_amd64
对于Frps的安装,可以使用该仓库下的一键安装脚本进行配置:frps-onekey
+
+ 安装引导
+
+
+
+
+
+
+ Frp
+
+
+
+
+
+
+
+
+ Ubuntu禁用系统休眠
+ /p/dea4f344.html
+
+ 由于用笔记本做服务器的时候并不需要屏幕显示,并且屏幕显示会带来多余的耗电,于是就想试着把笔记本屏幕关上的同时能让Ubuntu Server正常运行,而不是进入休眠模式,索性在网上查阅资料以后发现并不是很困难,以此在这里记录需要修改的操作以便以后查阅
修改logind.conf文件
sudo vim /etc/systemd/logind.conf
修改logind.conf中的选项,使得笔记本忽略关闭屏幕对系统的影响
将原本的
改为
1 2 HandleLidSwitch=ignore HandleLidSwitchExternalPower=ignore
使用reboot指令来重启电脑即可。
+
+ 小技巧
+
+
+
+
+
+
+ Ubuntu
+
+
+
+
+
+
+
+
+ 修复Vim的光标兼容问题
+ /p/15b28479.html
+
+ 参考:
Ubuntu的Vi/Vim编辑器的方向键变成ABCD问题_colorfulshark-CSDN博客 Vim入门基本设置 在终端输入如下指令:
1 2 echo "set nocp" >> ~/.vimrcsource ~/.vimrc
出现问题的原因:
set nocp
该命令指定让 VIM 工作在不兼容模式下。在 VIM 之前,出现过一个非常流行的编辑器叫 vi。VIM 许多操作与 vi 很相似,但也有许多操作与 vi 是不一样的。如果使用“:set cp”命令打开了兼容模式开关的话,VIM 将尽可能地模仿 vi 的操作模式。
也许有许多人喜欢“最正统的 vi”的操作模式,对于初学者来说,vi 里许多操作是比较不方便的。
举一个例子,VIM 里允许在 Insert 模式下使用方向键移动光标,而 vi 里在 Insert 模式下是不能移动光标的,必须使用 ESC 退回到 Normal 模式下才行。
+
+ 小技巧
+
+
+
+
+
+
+ Linux
+
+ Vim
+
+
+
+
+
+
+
+
+ Markdown基本语法记录笔记
+ /p/20c326f2.html
+
+ 通过使用Github Pages + jekyll 的方法也算是搭建了自己的第一篇博客,由于之后post主要都以markdown的文章发布,所以第一篇blog就留给markdown的语法了。
本篇文章参考自Markdown基本语法 - 简书 (jianshu.com) ,在学习之后做一个汇总,以便自己后续查看和回忆。
1 2 3 4 5 6 ## 这是一级标题,也就是字最大的 ## 这是二级标题 ### 这是三级标题 #### 这是四级标题 ##### 这是五级标题 ###### 这是六级标题
其中,不同的效果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ---## 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ###### 六级标题 ## 二、字体 - **加粗** `**这里是要加粗的字体**` - *斜体* ``*这里是要倾斜的字体*` `- ***斜体加粗* ** ~~(就是粗体+斜体啦)~~``***这里是要斜体并且加粗的字体***` `- ~~删除线~~``~~这里是要打删除线的字体~~` `## 三、引用 ```markdown > 引用 >> 引用的引用 >>> 引用的引用的引用
引用
引用的引用
引用的引用的引用
分割线有两种实现方式,只要三个,或者三个以上的 ‘-’ 或者 ‘*’ 就可以达到目的,以下为示例
效果如下
Markdown中的图片分为三个部分,分别是“图片介绍”,“图床地址”和“图片信息title”
图片介绍是在图片如果加载失败的时候,将会显示的文字内容 图床地址用于填写图片存放的位置 图片信息显示的title,为鼠标移动到图片上面的时候显示的小字内容(可有可无) 以下为一个示例
1 
示例:
超链接的语法和图片的语法很像,唯一的区别就是前面是否有那个感叹号,示例如下:
1 2 [超链接的内容 ](超链接地址 "超链接的title" )百度 ](http://baidu.com )
百度
HalcyonAzure的Blog
其中Markdown本身的语法目前并不支持超链接打开,需要使用html语言进行修改,由于目前暂时并未学习html有关内容,所以这部分内容直接引用简书 中的内容,暂时不研究。
注:Markdown本身语法不支持链接在新页面中打开,貌似简书做了处理,是可以的。别的平台可能就不行了,如果想要在新页面中打开的话可以用html语言的a标签代替。
1 2 3 4 <a href ="超链接地址" target ="_blank" > 超链接名</a > <a href ="https://www.jianshu.com/u/1f5ac0cf6a8b" target ="_blank" > 简书</a >
直接贴语法:
1 2 3 4 5 `单行代码内容`
示例的话上面的很多内容都采用了代码块的方法,所以就不多做展示了
记录一个实现代码折叠的小技巧
1 2 3 4 <details > <summary > </summary > `code here` </details >
效果
bottom `code here`语法:无序列表使用’-/+/*'的任意一种符号都可以达到效果
显示效果:
如果需要列表嵌套,只需要在回车后重复输入列表(快捷键Tab)即可,示例如下:
Ps: 在使用Typora编辑列表的时候,如果下一行不再需要列表,只需要通过方向键直接移动光标到下一行即可,如果使用回车来换行的话只会进行列表嵌套的操作
通过从无序列表进行引申,可以得到有序列表的语法内容:
示例:
内容1 内容2 由于这两部分内容目前还没有遇到使用需求,所以这里同样引用简书内的介绍,等真正有需要和使用的时候再返回这条Blog进行更新和整理
语法:
1 2 3 4 5 6 7 8 9 10 11 >表头|表头 |表头:--: |---:内容 |内容内容 |内容 包起来。此处省略
示例:
1 2 3 4 5 >姓名|技能 |排行:--: |--:哭 |大哥打 |二哥骂 |三弟
效果如下:
出于Blog的排版问题,只有一个示例
st=>start: 开始op=>operation: My Operationcond=>condition: Yes or No?e=>endst->op->condcond(yes)->econd(no)->op&```~~~第一篇Blog就是把别人的东西抄了一遍.jpg
]]>
+
+ 知识记录
+
+
+
+
+
+
+ Markdown
+
+
+
+
+
+
+
+
+
diff --git a/p/10e77bc5.html b/p/10e77bc5.html
new file mode 100644
index 00000000..2e71bdb5
--- /dev/null
+++ b/p/10e77bc5.html
@@ -0,0 +1,2 @@
+CS144-Lab4 计算机网络:TCP Connection的实现 - Halcyon Zone
TCP Connection的部分本身并不难,这个实验的主要核心是学习使用tshark或wireshark一类的工具对TCP的网络状况进行分析,找出正确或错误的数据包。
在这个实验中我们需要将前面写的TCP Sender和TCP Receiver两个部分的逻辑进行合并,使得两者之间可以进行数据的传输。
除了几个可以直接调用前面实验函数的函数以外,我们主要需要完成的我认为是收到某个报文以后的处理函数segment_received(const TCPSegment &seg)和时间函数tick()。
对于接受报文这个函数,首先通过对实验报告的分析,我们可以知道我们主要要做的事情可以分为以下三个大逻辑:
记录收到这个报文的时间,无论对错 检查这个报文是否是带RST标志的报文,如果是的话则直接断开连接 如果是在LISTEN状态的时候接受到这个报文的,则要判断对方是否连接 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 0 ;if (seg.header ().rst) {stream_out ().set_error ();stream_in ().set_error ();false ;return ;if (not _receiver.ackno ().has_value ()) {if (seg.header ().syn) {fill_window ();else {return ;
接受这个报文,如果带有ACK信息则更新对方已经确认了的ackno和对方当前的window_size
1 2 3 4 5 6 7 segment_received (seg);if (seg.header ().ack) {ack_received (seg.header ().ackno, seg.header ().win);
这部分是我认为Lab4里面在理解上较难的部分。其中,TCP的断开分为三种不同的情况:
由于RST标志导致的强制退出(unclean shutdown) 正常的通讯结束而导致的关闭(clean shutdown) 但是对于第二种情况,我们可以进一步分为两种情况:
首先是最简单的四次挥手报文:
Client发送完毕数据,告诉Server我结束(FIN)了Client客户端在给Server发送完毕了所有数据以后,主动发送FIN数据包,表示自己的数据已经发送完毕了。然后Server在收到Client的FIN报文并处理完毕以后则会返回一个FIN ACK报文,来告诉Client他发过来的数据已经在服务端被处理完成了。
Server也发送完毕了数据,告诉Client我结束(FIN)了Server也会给Client发送一个FIN的报文,同样等待Client那边确认,如果Client发送了确认报文来确认这个ACK,则代表客户端那边也处理完了,这个时候按理来说首先提出数据发送完毕的Client就可以断开链接了。
但是,服务端有可能收不到 这最后一个ACK确认报文,从而导致自己一直在等待客户端向自己发送ACK确认报文。
为了避免这种情况,最简单的处理方法就是让Client给Server发送了FIN ACK报文以后不要急着断开连接,而是设置一个计时器,等待看看Server会不会重传FIN报文。
如果重传了FIN则代表Server并没有收到先前发送的FIN ACK,这个时候Client就需要重新发送一个ACK回去,告知Server可以断开连接了。
如果超过了计时器的时间,Client也没有收到Server的重传报文,那么我们就假设Server已经收到了FIN ACK,并且已经关闭了他那边的连接,这个时候Client就可以断开连接了。而这段计时器的等待时间,就是实验中的linger_time = 10 *_cfg.rt_timeout,这个时间往往是比Server超时重传的时间大很多的,也就留给了Server足够多的时间来重传FIN报文。
服务端这边就很简单了,在发送完自己的FIN之后,只需要正常等待Client的ACK确认报文,如果没有等到则重传FIN,如果等到了则直接断开连接。
知道了上面的区分以后,我们实现起来就很简单了,只需要通过添加一个变量_linger_after_streams_finish来判断到底是对方先结束还是自己先结束。如果是对方先结束,则我们不需要等待linger_time,在后面收到了FIN报文以后直接断开连接即可。否则则需要在后面tick()函数的部分添加超时断开连接的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 if (_receiver.stream_out ().eof () && not _sender.stream_in ().eof ()) {false ;if (_sender.stream_in ().eof () && bytes_in_flight () == 0 && not _linger_after_streams_finish) {false ;
这部分逻辑就很简单了,如果在接受了对方传来的有序列号消耗数据包以后,我们并没有数据要传输(即无法告知对方我们接受到了数据),那么我们就需要单独传输一个ACK数据包给对方,告知我们已经接收到了对方的数据。(如果对方发送给我们的是一个ACK数据包,我们则不需要回复,也就是收到了占用序号为零的包)
1 2 3 4 if (_sender.segments_out ().empty () &&length_in_sequence_space () || seg.header ().seqno != _receiver.ackno ())) {send_empty_segment ();
其中seg.header().seqno != _receiver.ackno()代表的是一种特殊情况,在TCP连接中,有的时候为了确认当前连接是否依旧有效,对方有可能会随机发送一个错误的序列号给我们,这个时候我们就需要回复一个ACK报文给对方,以此告知对方这个连接依旧是有效的,同时也可以让对方更新我们的窗口大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 void TCPConnection::segment_received (const TCPSegment &seg) 0 ;if (seg.header ().rst) {stream_out ().set_error ();stream_in ().set_error ();false ;return ;if (not _receiver.ackno ().has_value ()) {if (seg.header ().syn) {fill_window ();else {return ;segment_received (seg);if (seg.header ().ack) {ack_received (seg.header ().ackno, seg.header ().win);if (_receiver.stream_out ().eof () && not _sender.stream_in ().eof ()) {false ;if (_sender.stream_in ().eof () && bytes_in_flight () == 0 && not _linger_after_streams_finish) {false ;if (_sender.segments_out ().empty () && (seg.length_in_sequence_space () || seg.header ().seqno != _receiver.ackno ())) {send_empty_segment ();
另外一个需要注意的函数就是tick()函数了。其实这一部分的重要也主要是连带了前面接受报文部分的关闭连接,主要要注意的就是添加一个对linger_time的判断。整个tick()函数的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void TCPConnection::tick (const size_t ms_since_last_tick) tick (ms_since_last_tick);if (_sender.consecutive_retransmissions () > TCPConfig::MAX_RETX_ATTEMPTS) {return ;if (time_since_last_segment_received () >= _linger_time && _sender.stream_in ().eof () &&stream_out ().input_ended ()) {false ;
Lab4实验主要的难点感觉还是在即使跑通了前面大部分的基本测试,也还是有可能因为Lab2和Lab3里面的疏忽,而导致后面模拟真实通讯的时候很容易难以下手。但是在掌握了Wireshark抓包一类的工具用法以后还是很容易发现问题所在并加以纠正的。
比如我在Lab3中,对于TCPSender在填充窗口大小的时候,一开始并不是设置了一个额外的变量fill_space来控制可以发送的空闲空间的大小,而是直接使用了ack_received方法中收到的最新窗口大小,忽略了bytes_in_flight()也需要考虑在窗口占用里面的问题。在使用Wireshark抓包的时候就明显发现了发送数据包的序号要远超于接收方的确认序号
而这个问题也在我通过修改Lab3对应空闲窗口大小的逻辑之后得到了解决。
我还遇到过的第二个问题就是在小窗口的情况下,没有正确处理链接的关闭。在通过Wireshark抓包以后可以看到
在发送方还没有给接收方发送完所有数据的时候,接收方就提前终止了自己的连接,这个问题主要出在tick()函数里面关于linger_time的逻辑错误,我并没有等到接收方接受到EOF就直接关闭了链接。错误代码如下:
1 2 3 if (time_since_last_segment_received () >= _linger_time && _sender.stream_in ().eof ()) {false ;
修改后的代码如下:
1 2 3 4 if (time_since_last_segment_received() >= _linger_time && _sender.stream_in().eof()+ && _receiver.stream_out().input_ended()) {
整个Lab4的代码可以在Github的仓库查看:
tcp_connection.cc tcp_connection.hh
CS144-Lab4 计算机网络:TCP Connection的实现
https://halc.top/p/10e77bc5
博客在允许 JavaScript 运行的环境下浏览效果更佳
2021年度总结 - Halcyon Zone
往年本来都没有在年初或者年末的时候写一个一年总结的习惯,今年也算是突发奇想,打算写一篇博客稍微记录下自己的学习和生活。希望能在2022年里面养成时不时记录一下自己生活的习惯,养成正视自己的一个态度。
从2020年高三高考结束,到2021年大一升大二,也算是对大学生活有了一些认知和了解。整个大一的时间不能说浑浑噩噩,但总觉得自己心里缺了点什么。
现在仔细想想感觉就是缺少对自己的一个自视,总觉得心里空空的,不自在。刚上大学的时候就对“信息差”这个词很敏感,整个大一的过程也感觉一直在忙忙碌碌的处理各种各样的“信息”。无论是平时上课、考试还是处理一些生活中的问题,也总是把能搜罗到的各种信息的优先级置于自己“能力”的优先级之上,对外界环境的信任远高于对自己的信任。
这种自己信任上的缺乏感在最近听Daniel Sloss的Jigsaw(拼图)的Live Show 之后,感觉悟到自己经常总是忽视自己,一直感觉空虚因而不断的向外界索取信息,大抵也就是自己尚且不能适应孤独的感觉。上了大学以后本来觉得能聊的人多了,孤独的感觉应该弱化了,但现在想想过去一年里面反而应该是越来越强了。想过也许是不是谈恋爱就能让自己生活不那么孤独,但现在想想,问题应该还是出在自己对自己的不信任上。
连自己都不能做到100%爱自己的话,也很难爱其他人
总之,希望在将来到的2022年里面,能增加自己正视自己的态度。争取每个月写一个总结,来达到”给自己泼一盆冷水醒一醒“的作用。
有的话,说出来了才有力量警醒自己
这个学期除了学校本身的内容,学习密度最大的时候应该是年初倒腾软路由的时候开始的。从最初依赖带有GUI界面的openwrt的luci界面,到现在已经习惯了terminal的方式进行各种操作,这种对Linux一类命令行态度的转变有一种拿到了普罗米修斯的火把的感觉,一切原来觉得”麻烦“或者难以折腾的东西,突然都明朗了起来,即使遇到了问题,相比原来无脑cp各路解决方案的脚本指令,现在会下意识的思考和提前验证其中的原理和造成的影响了。
对于项目而言,去年算是或多或少接触或者熟悉了Nginx、Docker、MySQL等等零零碎碎的知识和技术,也搭建了一台以家里电脑为处理服务器,香港云服务器作为跳板的公网服务器,在上门也尝试部署过许多不同的demo或者项目,其中也通过对ZeroTier一类的工具的深入研究,也算是对计算机网络的学习和经验埋下了兴趣。
不过去年一年中,也和性格相关,大部分时候只是在通过搜刮各种”信息“,来搭建各种别人的项目然后进行一些很小的改动,一直在重复着”遇到问题“->”寻找别人的解决方案“->”不断选择最优解并且排错“->”解决问题“的过程,而总是不会把**”自己创造解决方案“排在首要位置。今年的博客内容也能体现我目前”知识密度“低下的严重不足,大部分时候只是写个机械性的总结草草了事,缺少很多思考和加工的过程。
平时在学校一个人虽然自在,但也还是和在家里一样一直倾向于变化越少越好,很少出门,出门吃饭也都只是找平时能难得线下面对面聊的比较多的同学,线上聊的比较多的同学和学长就经常”社恐“了。
在今年年末的时候,高考那会的储蓄也算是消耗殆尽了,钱的概念也越来越深刻了。不过还算幸运的是有需要的东西基本上也都备齐了,之后需要的东西开销应该也不会很大,目前的电子产品和设备就足够我把玩好一阵子了。
今年上半年的时候一直在忙忙碌碌的在不同的互联网上”冲浪”,一直在到处寻找已有的工具和服务然后不断上手和试验。看上去很忙但实际上也都学的是一些花时间,而不用花精力就能学会的“三脚猫”功夫。下半年的话反而玩了好几款3A大作而觉得整一年都充实了不少(手柄玩游戏是真的闲适),总的效率上虽然没做什么事情,但情绪要比上半年积极快乐多了。
2022年也到了,之前也没做过啥新年计划,今年也算是第一年尝试看看了,姑且列出以下几个目标,看看年末的时候能实现多少吧:
每个月写一篇总结,大致总结一下这个月发生了什么,就当是自己对自己态度的一个正视,也算是自己和自己对话了。 减肥,希望能减到BMI标准的水平。 接触至少三种不同的编程语言,了解相关的项目,并提交出自己的第一个PR 游戏开发入门,制作自己的一个游戏demo 学习一门额外的技能,目前的计划包括但不限于:日语入门(问就是二次元) 拾回Adobe全家桶 系统性学习建模软件 争取能参加一次GameJam 以上应该算是对2021年的一个缺胳膊少腿的总结吧,其中也发生了很多值得纪念和回味的细节事情,包括和不同的人相识又或者和第一次和同学去旅游,在旅游的时候又和曾经的同学见面…写博客的目的还是希望能把那些原来不会对别人,也不会对自己说的话记录下来,也是对自己的一个警示了。
2022年1月7号 - 凌晨3:14
(感冒还没好全 & 期末预习备战中… 希望这学期别挂XD)
2021年度总结
https://halc.top/p/1153f279
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux配置局域网下网络唤醒 - Halcyon Zone
安装网络管理工具
sudo apt install ethtool
查询网口信息
ip a
记录需要启动的网口名字
通过指令手动启动wol服务
ethtool -s [INTERFACE] wol g
查询是否成功
ethtool [INTERFACE]
输出信息中如果显示wol:g则代表开启成功
创建开机进程
sudo vi /etc/systemd/system/wol.service
写入以下内容
1 2 3 4 5 6 7 8 9 [Unit]
载入systemd并启动
1 2 3 sudo systemctl daemon-reloadenable wol.service
参考博客
1.WOL持久化设置
Linux配置局域网下网络唤醒
https://halc.top/p/12aa3ef8
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:比例份额的调度策略 - Halcyon Zone
在CPU资源进行调度的时候,有的时候我们很难让每个程序都尽量公平的分配到资源。“彩票调度(lottery scheduling)”通过给不同的任务分配不同的彩票数,再通过随机数和期望分布来对资源进行调度,实现一个类似于平均分配的调度方法
本章中文译本内缺少对Linux系统的CFS调度的说明,不过不影响课后练习
完成随机种子1、2和3对应的习题计算
该题目的主要思路即判断随机数取模后的数字和tickets的数量比较,然后依次逐步执行判断即可
当彩票分布设计的十分极端的情况下,由于第一个Job0 10:1获得的票数太少,几乎不可能在Job1 10:100前完成任务,将会在结果上滞后Job0的完成
通过设立不同的seed,可以得到不同的情况如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ ./lottery.py -l 100:100,100:100 -s 1 -c
可以大致看出在任务的长度足够大的情况下,调度分布基本公平,最后的结果趋紧于类似RR切换任务的平均期望
在修改了quantum大小之后,由于时间片变大,相当于任务本身的长度缩短,整个任务的公平性会偏向不稳定和不公平,大致结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ ./lottery.py -l 100:100,100:100 -q 20 -c -s 1
这题主要用来当Python练习了,模拟生成图像的代码如下(和lottery.py实验代码放于同一目录下)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import osimport reimport matplotlib.pyplot as pltimport numpy as npdef countLottery (length, seed ):"./lottery.py -l " + length + ":100," + length + ":100 -c" + " -s " + seed)r"^--> .*(\d*)" , text, re.M)return int (lottery_time[0 ])/int (lottery_time[1 ])def average (length ):sum = 0 20 for i in range (1 , time):sum += countLottery(length, str (i))return sum / (time - 1 )1 100 5 for i in np.arange(length_start, length_end, step):str (int (i))))"Fairness" )"Job Length" )'b-' )"./lottery.png" )
最后生成的图片效果
OSTEP:比例份额的调度策略
https://halc.top/p/13271c5f
博客在允许 JavaScript 运行的环境下浏览效果更佳
Docker传递操作进容器内的不同方式 - Halcyon Zone
使用docker exec -it命令进入容器(推荐)
假设操作的容器ID为icontainer,如果想要进入icontainer执行指令,只需要输入以下指令:
1 docker exec -it icontainer /bin/bash
如果需要退出容器,输入exit或者Ctrl+C即可
使用docker attach命令进入
同样以icontainer举例,则需要输入以下指令来进入容器终端
1 docker attach icontainer
但这样有缺点,即退出终端的同时,该容器也会同样退出,所以推荐使用exec的方法进入容器
先直接上指令,以容器icontainer为例,我需要将该容器下的/opt/demo/demo.zip拷贝到宿主机的/opt/Backup/下,那么我的指令如下:
1 docker cp icontainer:/opt/demo/demo.zip /opt/Backup/
同理,如果我需要将Backup下的demo.zip传递到容器内,我也可以使用如下指令传输到容器的recover文件夹内:
1 docker cp /opt/Backup/demo.zip icontainer:/opt/recover/
备注:文件传递和容器是否启动无关,都会直接对文件进行修改
Docker传递操作进容器内的不同方式
https://halc.top/p/14cd2588
博客在允许 JavaScript 运行的环境下浏览效果更佳
修复Vim的光标兼容问题 - Halcyon Zone
参考:
Ubuntu的Vi/Vim编辑器的方向键变成ABCD问题_colorfulshark-CSDN博客 Vim入门基本设置 在终端输入如下指令:
1 2 echo "set nocp" >> ~/.vimrcsource ~/.vimrc
出现问题的原因:
set nocp
该命令指定让 VIM 工作在不兼容模式下。在 VIM 之前,出现过一个非常流行的编辑器叫 vi。VIM 许多操作与 vi 很相似,但也有许多操作与 vi 是不一样的。如果使用“:set cp”命令打开了兼容模式开关的话,VIM 将尽可能地模仿 vi 的操作模式。
也许有许多人喜欢“最正统的 vi”的操作模式,对于初学者来说,vi 里许多操作是比较不方便的。
举一个例子,VIM 里允许在 Insert 模式下使用方向键移动光标,而 vi 里在 Insert 模式下是不能移动光标的,必须使用 ESC 退回到 Normal 模式下才行。
修复Vim的光标兼容问题
https://halc.top/p/15b28479
博客在允许 JavaScript 运行的环境下浏览效果更佳
Google镜像站创建引导 - Halcyon Zone
步骤如下:
在Nginx中创建Google的Nginx反代www.google.com.hk
配置SSL证书并保存,启用HTTPS
配置upstream设置
在server中配置防爬虫和禁止IP访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 server if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot") { return 403; } # 禁止用其他域名或直接用IP访问,只允许指定的域名访问 #forbid illegal domain if ( $host != " yourdomain.com" ) { return 403; } ... }
检查并重启配置文件
nginx -t && nginx -s reload
在宝塔防火墙中关闭’GET’过滤,否则会导致搜索某些关键词的时候被误判封锁IP
参考文章:
(´∇` ) 被你发现啦~ 搭建google镜像网站(适用最新版nginx)Module for Google Mirror – 深海 (oyi.me) Google镜像站创建引导
https://halc.top/p/15b685e1
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:虚拟内存和物理内存地址转换 - Halcyon Zone
该章节主要引出了基址寄存器和界限寄存器的概念,表述了在操作系统内程序执行的时候虚拟内存的分布和物理内存的地址转换关系
判断是否越界只需要将访问内存地址大小和Limit进行比较,在小于Limit的情况下直接做加法即可
获取到所有访问的数据后,可以发现访问的地址中最大的为
1 VA 9: 0x000003a1 (decimal: 929)
因此只需要将-l设置为930即可
补充为什么不是929
界限寄存器是在基址寄存器的基础上开始limit个单位的内存可被使用,就好比数组中的limit为10个空间的情况下,只有0-9可以被使用。对应到该题,如果想要让(0x000003a1)的地址不越界,则需要设置930个可用空间
题目默认的物理地址为16k,也就是16,384,只需要设置-b为16384 - 100 = 16284即可
和上文实验差别不大,其中-a参数是设置随即生成的取地址的大小范围,-p为设置物理内存的最大范围,实际内存主要是否越界只和-b的基址寄存器、-l的界限寄存器以及-p的物理内存有关系,-a作为一个随机数范围没有实际含义
通过PyPlot画图,在默认的-n情况下,当limit从0逐渐增加到asize的时候,可以得到大致如下的图片
附画图代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import osimport reimport matplotlib.pyplot as pltdef execRelocation (seed, limit, num ):'python3 relocation.py -s %d -l %d -c' % (seed, limit))"VALID" )return pass_num / numif __name__ == '__main__' :1024 for i in range (0 , limitTop, 50 ):sum = 0 for j in range (0 , 20 ):sum += execRelocation(j, i, 10 )sum / 10 )"limit" )"pass rate" )"limit.png" )
OSTEP:虚拟内存和物理内存地址转换
https://halc.top/p/1724953e
博客在允许 JavaScript 运行的环境下浏览效果更佳
总结:2022年3月 - Halcyon Zone
这个月直接写出的可以用的贡献不是很多,主要成就感应该就是来自Python的抓包和发包写一些打卡脚本的目标完成了,实现了学校的打卡自由和机场的签到流量自由。
Rust的学习和CS144的学习在这个月成功被我换成了C++的学习和OSTEP的学习,写lab完成之后带来的快感感觉完全不亚于玩老头环成功挑战Boss后的成就感,OSTEP的学习笔记和答案也有一直在博客里面更新,希望自己这个学期能全部做完加深对操作系统的了解
这个学期也第一次写了一个能用的repo出来:HalcyonAzure/lsky-pro-docker 。虽然整个Dockerfile还是抄袭了issues里面别人的劳动成果,但是在调试的过程中遇到的许多问题也加深了自己对container的了解,而且学会了用dev container来做一些临时开发,同时自己写yaml用github actions来自动部署一些项目(白嫖服务器的感觉是真的爽),总的来说成就感可以说是非常强了。
喔,对了,这个月还把博客重构了一下,改成了用Hexo的Fluid的主题,看着比原来Jekyll的TeXt花里胡哨了不少😉
这个月由于都忙着Coding,没什么游戏时间。不过让我没想到的是南昌居然也会受到疫情的波及,连续上了近一整个月的网课,伙食方面不能吃烧烤或火锅来释放自己的多巴胺果然感觉还是很难受啊😢,希望能早点解封然后出去吃餐好的
核酸检测虽然说做的次数也满多,不过学校后面几次安排的时间都蛮合适的,整个流程下来不超过30min,因此也没什么怨言,同时托网课的福,自己也才有了那么多时间能做自己想做的事情,写自己想写的东西,这种无忧无虑不用考虑绩点和平时作业的时候如果多一些就好啦😣
参加计算机设计大赛,看看能不能摸个奖回来,丰富下经历 OSTEP的Lab每个礼拜写两篇 绝对、绝对绝对开始跑步或打排球,调整自己的生活质量 早睡早起!!! 水果封校已经不做指望了,就希望能控制住自己的饮食😥 总结:2022年3月
https://halc.top/p/18b05b6b
博客在允许 JavaScript 运行的环境下浏览效果更佳
CS144-Lab6 计算机网络:路由转发 - Halcyon Zone
这个实验就是最后一个需要写代码的实验了。主要需要解决的问题是一个IP数据包传入之后,如何通过已有的路由表确定下一跳的IP地址
这个实验中主要的问题点就是CIDR的匹配。解决这个问题,我们只需要先将CIDR转为子网掩码,也就是以0为基数,左移(32 - 前缀)位,最后得到的也是子网掩码的值。但是这里有一个问题就是,当mask是uint32_t的时候,如果前缀的长度为0,那么子网掩码会变成255.255.255.255,但是实际上应该是0,因此我们需要对前缀是否为0进行判断。
在判断完毕之后,只需要将网关的IP地址和子网掩码按位与运算,然后将目标IP地址也和子网掩码按位与运算,如果最后的结果相同,那么就说明子网匹配
1 2 3 4 5 6 7 8 9 10 11 auto path = _route_table.end ();const auto &dst_ip = dgram.header ().dst;for (auto entry = _route_table.begin (); entry != _route_table.end (); entry++) {const uint32_t &mask = entry->prefix_length ? (~0U ) << (32 - entry->prefix_length) : 0 ;const auto network_address = entry->route_prefix & mask;if ((dst_ip & mask) == network_address) {
如果没有匹配到对应的路由规则,或者这个数据包已经经过了太多次转发都没有找到目的地,那么就将这个数据包丢弃掉。
1 2 3 4 if (path == _route_table.end () || dgram.header ().ttl-- <= 1 ) {return ;
如果没有丢弃的话,那么就只需要按照正确的接口将数据包发送出去就行,如果没有下一跳的IP地址,说明数据包已经到达了对应的目的地,只需要直接发送给目标IP即可
1 2 3 4 5 6 7 if (path->next_hop.has_value ()) {send_datagram (dgram, path->next_hop.value ());else {send_datagram (dgram, Address::from_ipv4_numeric (dgram.header ().dst));
终于也是写完了Lab0-6的所有博客总结😭,Lab7的部分不需要写代码,只需要直接运行程序聊天就行,就不写博客总结了
CS144-Lab6 计算机网络:路由转发
https://halc.top/p/195b5fa9
博客在允许 JavaScript 运行的环境下浏览效果更佳
手动在服务器上安装Frp - Halcyon Zone
首先,在 fatedier/frp 中下载最新版的frp打包程序,以下以0.35.1版本为例
1 2 3 wget https://github.com/fatedier/frp/releases/download/v0.35.1/frp_0.35.1_linux_amd64.tar.gzrm frp_0.35.1_linux_amd64.tar.gz
首先切换到frp的目录下,把frpc和配置文件放于service对应的目录下
1 2 3 4 5 cd frp_0.35.1_linux_amd64mv frpc /usr/binchmod 755 /usr/bin/frpc mkdir /etc/frpmv frpc.ini /etc/frp
之后通过指令编辑frpc.ini
sudo vi /etc/frp/frpc.ini
之后,切换到services的目录下,将frpc.service移动到系统的systemctl进程守护下,并启用权限
1 2 3 4 5 cd ./systemdmv frpc.service /usr/lib/systemd/systemchmod 644 /usr/lib/systemd/system/frpc.servicemv frpc@.service /usr/lib/systemd/systemchmod 644 /usr/lib/systemd/system/frpc@.service
配置文件就结束了之后只需要直接启用和启动frpc即可
1 2 sudo systemctl enable frpc
另外由于不需要配置frps服务,可以回到上级目录并把下载的文件全部删除
1 2 cd ~rm -rf frp_0.35.1_linux_amd64
对于Frps的安装,可以使用该仓库下的一键安装脚本进行配置:frps-onekey
手动在服务器上安装Frp
https://halc.top/p/1d3a895d
博客在允许 JavaScript 运行的环境下浏览效果更佳
Minecraft服务器配置域名SRV记录隐藏端口 - Halcyon Zone
目前对于SRV记录了解还不清楚,没有查询具体可以使用的服务等。目前需要的也只是达到转发MC的端口,达到隐藏端口的目的,所以只是一个无脑式记录。
拥有一个域名,并且指向了一个带有端口的MC服务器,比如rpg.vastl.icu:25566
在DNS控制台添加解析记录。
1 2 3 主机记录:_minecraft._tcp.xx ## xx为子域名
最后应用即可。
Minecraft服务器配置域名SRV记录隐藏端口
https://halc.top/p/1dcf9daa
博客在允许 JavaScript 运行的环境下浏览效果更佳
ZeroTier搭建Planet服务器引导 - Halcyon Zone
Running MPLS over ZeroTier Part 1 · Gotz Networks 把ZeroTier的项目在本地克隆一份
1 git clone https://github.com/zerotier/ZeroTierOne.git
打开在attic文件夹下的world文件夹
1 cd ZeroTierOne/attic/world
编辑mkworld.cpp文件,把ZeroTier Controller默认的IP删除,添加自己的IP上去。
编译文件
运行mkworld文件
应该会产生一个新的world.bin文件,这个文件需要在所有自己的客户端添加
将这个world.bin文件复制到ZeroTier的文件夹下,在Linux中的指令为
1 cp world.bin /var/lib/zerotier-one/planet
重启ZeroTier
1 sudo systemctl restart zerotier-one.service
重复第七步和第八步,在所有希望使用自己Planet服务器的客户端中添加这个节点
完全使用自己的服务器,数据等不通过ZeroTier自己的官网。
ZeroTier搭建Planet服务器引导
https://halc.top/p/1e0fb80b
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:TLB缓存命中和非命中的开销差距 - Halcyon Zone
本章为测量实验,主要要求为写一份tlb.c来测试在TLB miss和TLB hit的情况下性能开销的变化,以感受TLB的重要性
对于题中问题的回答
由于gettimeofday()的函数只能精确到微秒,不足以测试较为精确的时间,因此使用CLOCK_PROCESS_CPUTIME_ID和clock_gettime();搭配即可获得纳秒级的时间测量,具体代码实现如下
具体代码实现如下
tlb.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/time.h> #include <pthread.h> void lockCpu (int cpuId) cpu_set_t mask;if (sched_setaffinity(0 , sizeof (mask), &mask) < 0 )fprintf (stderr , "set thread affinity failed\n" );int main (int argc, char *argv[]) if (argc != 3 )fprintf (stderr , "Usage: ./tlb pages trials" );exit (EXIT_FAILURE);0 );int page_numebr = atoi(argv[1 ]);int trials = atoi(argv[2 ]);if (page_numebr <= 0 )fprintf (stderr , "Invaild Input" );exit (EXIT_FAILURE);int jump = sysconf(_SC_PAGE_SIZE) / sizeof (int );struct timespec start , end ;struct timespec start_hit , end_hit ;int sum_miss = 0 ;int sum_hit = 0 ;int cnt = 0 ;while (trials--)for (int step = 0 ; step < page_numebr * jump; step += jump)int *array = calloc (page_numebr, getpagesize());array [step] += 0 ;array [step + 1 ] += 0 ;free (array );int miss_average = sum_miss / cnt;int hit_average = sum_hit / cnt;printf ("Time per access(TLS miss): %d\n" , miss_average);printf ("Time per access(TLS hit): %d\n" , hit_average);return 0 ;
该程序主要思路为
统计访问内存需要的总时间 首先统计TLB miss的情况,在miss之后TLB被激活 统计对应分页内存的后一位,此时TLB hit,能够成功快速定位 将总时间除以操作的总次数,得到最后的平均每次时间(单位为ns) 大致结果如下
1 2 3 > ./tlb 1000 10
可以明显发现未命中的时候访问时间要远高于TLB hit时的时间
通过Python对tlb进行调用,大致结果为4.的效果
统计结果如下
其中蓝色对应TLB miss的时间,橙色对应了TLB hit的开销时间
Python画图代码如下
Matplotlib 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import osimport sysimport reimport matplotlib.pyplot as pltdef execRelocation (page_number, trival ):'./tlb %d %d' % (page_number, trival))r"(\d+)" return tlb1 ]2 ]for vpn in range (1 , int (page_number), 128 ):print (str (vpn) + "/" + str (page_number))int (trival))int (tlb[0 ]))int (tlb[1 ]))"Virtual Page Number" )"Time Per Access" )"Hit" )"Miss" )"./paging.png" )
添加-O0的参数可以防止gcc在编译的时候不进行优化
示例如下
在上下文切换 时,解决方案为使用Docker创建一个单核的虚拟机来进行实验操作,这次实验中,使用sched_setaffinity函数来设置进程对CPU亲和力,以让程序在某一单一CPU上运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/time.h> #include <pthread.h> void lockCpu (int cpuId) cpu_set_t mask;if (sched_setaffinity(0 , sizeof (mask), &mask) < 0 )fprintf (stderr , "set thread affinity failed\n" );
通过使用calloc()函数,可以在对堆内的变量进行分配内存的同时进行初始化操作,并且在每一次循环进行之前都销毁数组重新创建,可以减少对实验测试的影响
OSTEP:TLB缓存命中和非命中的开销差距
https://halc.top/p/20416971
博客在允许 JavaScript 运行的环境下浏览效果更佳
Markdown基本语法记录笔记 - Halcyon Zone
本文最后更新于:2022年4月13日 下午
通过使用Github Pages + jekyll 的方法也算是搭建了自己的第一篇博客,由于之后post主要都以markdown的文章发布,所以第一篇blog就留给markdown的语法了。
本篇文章参考自Markdown基本语法 - 简书 (jianshu.com) ,在学习之后做一个汇总,以便自己后续查看和回忆。
1 2 3 4 5 6 ## 这是一级标题,也就是字最大的 ## 这是二级标题 ### 这是三级标题 #### 这是四级标题 ##### 这是五级标题 ###### 这是六级标题
其中,不同的效果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ---## 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ###### 六级标题 ## 二、字体 - **加粗** `**这里是要加粗的字体**` - *斜体* ``*这里是要倾斜的字体*` `- ***斜体加粗* ** ~~(就是粗体+斜体啦)~~``***这里是要斜体并且加粗的字体***` `- ~~删除线~~``~~这里是要打删除线的字体~~` `## 三、引用 ```markdown > 引用 >> 引用的引用 >>> 引用的引用的引用
引用
引用的引用
引用的引用的引用
分割线有两种实现方式,只要三个,或者三个以上的 ‘-’ 或者 ‘*’ 就可以达到目的,以下为示例
效果如下
Markdown中的图片分为三个部分,分别是“图片介绍”,“图床地址”和“图片信息title”
图片介绍是在图片如果加载失败的时候,将会显示的文字内容 图床地址用于填写图片存放的位置 图片信息显示的title,为鼠标移动到图片上面的时候显示的小字内容(可有可无) 以下为一个示例
1 
示例:
超链接的语法和图片的语法很像,唯一的区别就是前面是否有那个感叹号,示例如下:
1 2 [超链接的内容 ](超链接地址 "超链接的title" )百度 ](http://baidu.com )
百度
HalcyonAzure的Blog
其中Markdown本身的语法目前并不支持超链接打开,需要使用html语言进行修改,由于目前暂时并未学习html有关内容,所以这部分内容直接引用简书 中的内容,暂时不研究。
注:Markdown本身语法不支持链接在新页面中打开,貌似简书做了处理,是可以的。别的平台可能就不行了,如果想要在新页面中打开的话可以用html语言的a标签代替。
1 2 3 4 <a href ="超链接地址" target ="_blank" > 超链接名</a > <a href ="https://www.jianshu.com/u/1f5ac0cf6a8b" target ="_blank" > 简书</a >
直接贴语法:
1 2 3 4 5 `单行代码内容`
示例的话上面的很多内容都采用了代码块的方法,所以就不多做展示了
记录一个实现代码折叠的小技巧
1 2 3 4 <details > <summary > </summary > `code here` </details >
效果
bottom `code here`语法:无序列表使用’-/+/*'的任意一种符号都可以达到效果
显示效果:
如果需要列表嵌套,只需要在回车后重复输入列表(快捷键Tab)即可,示例如下:
Ps: 在使用Typora编辑列表的时候,如果下一行不再需要列表,只需要通过方向键直接移动光标到下一行即可,如果使用回车来换行的话只会进行列表嵌套的操作
通过从无序列表进行引申,可以得到有序列表的语法内容:
示例:
内容1 内容2 由于这两部分内容目前还没有遇到使用需求,所以这里同样引用简书内的介绍,等真正有需要和使用的时候再返回这条Blog进行更新和整理
语法:
1 2 3 4 5 6 7 8 9 10 11 >表头|表头 |表头:--: |---:内容 |内容内容 |内容 包起来。此处省略
示例:
1 2 3 4 5 >姓名|技能 |排行:--: |--:哭 |大哥打 |二哥骂 |三弟
效果如下:
出于Blog的排版问题,只有一个示例
st=>start: 开始
+op=>operation: My Operation
+cond=>condition: Yes or No?
+e=>end
+st->op->cond
+cond(yes)->e
+cond(no)->op
+&```
+~~~
+
+
+第一篇Blog就是把别人的东西抄了一遍.jpg
Markdown基本语法记录笔记
https://halc.top/p/20c326f2
博客在允许 JavaScript 运行的环境下浏览效果更佳
解决Windows未使用端口被占用问题 - Halcyon Zone
本文最后更新于:2022年4月28日 中午
Hortonworks Docker Sandbox environment cannot start default-dynamic-port-range-tcpip-chang 在无脑跟着网上教材开启Windows的SandBox的时候开启了Hyper-V的功能,结果尝试在6800端口运行和往常一样的Aria2的Docker容器的时候出现了端口报错的情况,通过netstat排查也没发现6800端口被占用了,后面发现应该是Windows的动态端口在开了Hyper-V之后被修改了
通过以下指令可以分别查看ipv4/ipv6的tcp/udp起始端口
1 2 3 4 netsh int ipv4 show dynamicport tcp
在我的情况下,起始端口从原本默认的49152被修改成了从1024开始,因此6800端口无法使用
在参考问题中找到了对应的解决方案
如果需要继续使用windows Virtual platform form windows feature(不确定这里是不是指Hyper-V,所以不翻译了)则
关闭Windows服务上对应的功能,关闭后系统会请求重启
通过以下指令修改动态起始端口 (49152是Windows默认设置) 在使用adb连WSA的调试时,发现默认端口为58526,所以还是用100000把
1 2 3 4 netsh int ipv4 set dynamicport tcp start =64536 num=1000 set dynamicport udp start =64536 num=1000 set dynamicport tcp start =64536 num=1000 set dynamicport udp start =64536 num=1000
重新启用对应的功能
如果没有Hyper-V使用需求的情况下,可以尝试直接关闭Hyper-V,然后检查起始端口是否恢复,如果没有恢复的再通过上面的指令手动重新设置起始端口即可
解决Windows未使用端口被占用问题
https://halc.top/p/22453a61
博客在允许 JavaScript 运行的环境下浏览效果更佳
链表 - Halcyon Zone
以下内容仅为刷题总结,只记录目前遇到过的情况,如果后面遇到了更多可能性再总结
在链式存储当中,对于节点是使用指针指向的方式进行数据的存储,其结点定义类似如下形式:
1 2 3 4 5 6 struct LinkNode {int val;LinkNode () {}LinkNode (int x) : val (x), next (NULL ) {}
链表的好处是在添加或者删除特定节点的时候时间复杂度比顺序存储要小。在经常需要删除和添加操作节点的时候,通过直接修改节点的指针,可以快捷的对节点进行对应操作。
链表划分为三个部分,头+中间的数据节点+尾。
其中头节点有两种常见的处理方式,一种是通过一个虚拟的dummyhead来当作头结点,之后才是真实的数据节点。这样的好处是可以在对实际含有意义的头节点进行操作的时候,不需要有额外的特判就可以完成,通过增加一个头结点在部分题目中有的时候可以有很好的效果。
尾节点和头结点一样,也有实际意义上存在的数据节点和最后指向的一个尾巴节点,不过根据节点的定义来看,可以知道尾节点后面通常都跟有一个无意义的nullptr。在有的时候需要对尾节点进行处理的时候,增加一个虚拟的dummytail也许也能起到很好的效果。(p.s. 比如在写双向链表的时候)
创建链表的时候,通常会创建一个指针节点来表示整个链表的头节点。
1 LinkNode *ListA = new LinkNode ();
以上代码的含义即为创建一个LinkNode的节点,同时创建一个叫做List
A的指针,指向的是这个节点的内存。
而在对单向链表的进行操作的时候,如果我们移动了链头,很多时候意味着操作都是不可逆的。因此如果需要对链表中某个特定节点进行操作的时候,往往都会创建一个指向需要节点的指针来进行单独操作,操作完毕后将指针释放即可。
以下举例,阐明节点和节点指针之间的关系:(感觉有点废话)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 LinkNode *cur = new LinkNode (); new LinkNode (114 ); new LinkNode (115 ); "cur addr:" <<cur<<" " <<"A addr:" <<A<<" " <<"B addr:" <<B<<endl;"cur addr:" <<cur<<" " <<"A addr:" <<A<<" " <<"B addr:" <<B<<endl;return 0 ;
在注释了delete tmp的时候,最后输出的cur->val会依旧是114这个A曾经的值,而如果执行了对应的delete操作,由于原本A对应内存上的结构体被释放了,所以这个时候cur就没有指向一个有效的节点。
常用的终止条件有三种:
cur != nullptr 指针会停留在nullptr的尾节点上cur->next != nullptr 指针会停留在最后一个有效节点上cur != nullptr && cur->next != nullptr多用于快慢指针,用于判断快指针是否到队尾。之所以两种情况都判断为循环跳出的条件原因:由于nullptr本身相当于最后一个有效节点的附加尾巴。类比于线段上有区间(a, b)和区间[a,b],快指针的目的是为了判断长度,而这两种区间长度都是b - a,只是对于第一种情况(a, b)如果不将b节点本身纳入有效节点则会出现区间长度变为a -> (b - 1)的情况。对于第三种终止条件,还可以类比为:
cur == nullptr终止的情况就是区间(a, b),此时cur在走到b的时候快指针已经越界,刚好碰壁cur->next == nullptr终止的情况就是区间[a, b],此时cur在走到b时,刚好到达边界,也同样碰壁。链表
https://halc.top/p/2362a8ea
博客在允许 JavaScript 运行的环境下浏览效果更佳
DNS问题排查思路 - Halcyon Zone
这篇博客主要是在推特中无意翻到了这篇博客,尝试以翻译的形式做一套笔记,分享的同时加强自己的记忆。
当我们发起一个DNS请求的时候,基本上发生的就是下面两件事
电脑向一个被标记为resolver的服务器发送一个DNS请求。 resolver服务器首先会检查缓存,并且在必要的时候再向authoritative nameservers发送查询请求。但是在这两件事情背后,我们有几个问题需要思考
解析服务器(即上面提到的resolver)的缓存中存放了一些什么东西?
在计算机中,在发起一个DNS请求的时候调用的是哪一部分的库?
举个例子,一个请求有可能是由libc中提供的getaddrinfo发起的,这部分代码或是来自glibc,或是musl,又或者是apple提供的库文件;这个请求也有可能是在浏览器中发起,由浏览器进行处理;当然也有可能是某些特定的自定义实现。
在不同的阶段和方法进行DNS请求做的事情都会略有不同,他们或多或少会有不一样的配置、缓存以及功能。举个例子来说,直到今年(2023)musl的DNS才开始支持TCP询问
解析器和权威域名服务器(即上文中提到的authoritative nameservers)之间是如何进行通话的?
在这里我们如果能知道在DNS请求期间询问了哪些下游的权威域名服务器,以及他们提供了哪些信息,则很多东西都会非常好理解。
为了让我们可以在获取DNS请求的时候,获取到更多的调试信息,我们可以尝试用dig工具来获取一些信息。一个例子如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ dig @223.5.5.5 whatdontexist.lol ] 8:26 PM
在上面这个示例中,我通过向一个不存在的域名:whatdontexist.lol发起了一个DNS请求。我们可以在这里看到许多有意思的信息,比如我们是对223.5.5.5这个DNS服务器,通过UDP发起的请求等等。
通过使用dig,我们可以知道很多额外的信息。举个例子,我们可以使用dig +norecurse指令来弄清楚DNS解析服务器目前有没有针对某个特定记录的缓存。对于某个特定的记录,如果不存在缓存,则会返回一个SERVFAIL的状态
举个例子,我们首先可以向223.5.5.5这个阿里的DNS请求www.baidu.com的DNS条目(大概率来说应该是缓存了百度的域名解析的)
我们可以看到上图中获取到的status为NOERROR,也就意味着百度在阿里云的DNS服务器中可以正常返回需要的结果。
现在我们再尝试请求一个不是很常见的域名homestarrunner.com,我们可以发现status变成了SERVFAIL
这里的SERVFAIL并不代表不存在对于homestarrunner.com的域名解析,只是在阿里云的服务器中并没有缓存这个域名而已。
不过对于上面这一长串由dig提供的调试信息,如果我们不是经常和它打交道的话看着还是会有点迷惑。比如:
->>HEADER<<-,flags:,OPT PSEUDOSECTION:,QUESTION SECTION:,MSG SIZE rcvd: 59这些都是啥玩意?为什么有的地方看起来是新内容但没换行(比如OPT PSEUDOSECTION:和QUESTION SECTION:)? 为什么有的返回报文中MSG SIZE rcvd: 59这里是59,而有的报文又是90?不同的报文之间是有啥不同的字段吗? 总之,从上面的一些问题中,我们可以发现dig的一些输出内容有点像是某些人临时写的一个用于获取这些信息的脚本,而并非有意为了可读性进行一些刻意的设计,为此我们有的时候需要查阅文档来搞懂发生了什么。
这里有一篇文章是原博客作者介绍了如何使用dig的:How to use dig (jvns.ca)
还有三个工具可以用于更友好的进行一些简单的调试:
不过对于这些工具有的时候会缺少一些高级功能,比如在原博客发布的时候dog和doggo都还不支持+norecurse这样的功能。所以有的时候学会dig还是有用的
通过添加一个+yaml的参数,可以让dig的输出信息更加格式化。不过这样的缺点是返回的信息有点太多了。
在DNS请求中,总是会出现一些奇奇怪怪但是容易不小心就掉进去的陷进。
一些更常见的问题可以翻阅这篇博客:Some ways DNS can break (jvns.ca)
被动缓存:由于DNS会记录不存在的域名 ,因此假设你在类似cloudflare一类的平台添加自己的DNS解析之前,如果先在自己电脑上访问并被系统缓存了"该域名不存在解析条目"这个结果,即使你后面为这个域名添加了有效的记录,但也要等到之前那条缓存失效了,新的有效结果才能被识别到。
在不同平台上对于getaddrinfo的实现并不相同,比如在今年之前,你是没法通过tcp来在musl平台上发起一个dns请求的。
有的解析服务器并不尊重解析本应该有的TTL,比如原本你设置了一个域名abc.com的TTL为一分钟或者两分钟。但是路由器认为大部分网络服务都是稳定的(对于非开发人员来说其实倒也是),有可能就会忽略这一点,而硬给你设置一个比如一两个小时的TTL。结果就会导致本来两分钟就应该生效的修改过了一两个小时都没好
在Nginx中,如果你按下面的方式配置了一个反向代理
1 2 3 location / {proxy_pass https://some.domain.com;
那么Nginx只会在第一次启动的时候尝试解析这个域名,之后则再也不会进行解析。如果你在这个过程中修改了some.domain.com域名指向的IP,就很有可能会出现一些不应该出现的问题。
这个问题实际上也有一些解决方案,不过不是这篇博客的重点
ndonts会使得k8s中的DNS请求变慢:Kubernetes pods /etc/resolv.conf ndots:5 option and why it may negatively affect your application performances (pracucci.com)
由于我自己对k8s目前接触不多,因此这里只是贴了一个链接。等以后有接触以后再回过头来研究研究
在DNS上踩坑往往可能是一件不起眼,但是遇到了就挺难排查的问题。也许最好的解决方案还是尽可能的去见识下别人遇到的问题。再放一次作者记录的常见问题:Some ways DNS can break (jvns.ca)
DNS问题排查思路
https://halc.top/p/23c3db21
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux多个不同版本内核卸载管理 - Halcyon Zone
查看当前的内核
1 2 root@azhal:~## uname -a
查看当前系统中所有的内核
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 root@azhal:~## dpkg --get-selections |grep linux
移除多余的内核
1 sudo apt-get remove <name of kernel>
再次检查内核是否为deinstall状态
1 dpkg --get-selections |grep linux
更新系统引导
参考文章
Ubuntu删除多余的内核 - 阳光与叶子 - 博客园 (cnblogs.com) Linux多个不同版本内核卸载管理
https://halc.top/p/24f916f9
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:系统API的调用 - Halcyon Zone
执行null文件后并没有提示或报错,代码如下
1 2 3 4 5 6 int main () int *pt = NULL ;free (pt); return 0 ;
在执行完gdb null后的run后,提示了以下信息
log 1 2 3 (gdb) run
在使用valgrind检查后,可以得到以下输出信息
log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ==9579== Memcheck, a memory error detector
根据C/C++ Preference 上free()的介绍如下
If is a null pointer, the function does nothing. ptr
首先使用malloc()函数对内存空间进行分配,但是不使用free()对内存进行释放
1 2 3 4 5 6 int main () int *pt = (int *)malloc (sizeof (int ));return 0 ;
使用gdb对可执行文件进行调试如下
gdb log 1 2 Starting program: /home/halc/code/cpp/null
使用valgrind对可执行文件调试入如下
valgrind log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ valgrind --leak-check=yes ./null
这个时候通过valgrind工具即可检查出,在堆空间中有definitely lost(确定的内存泄露)为4 bytes in 1 blocks,正好对应了代码中sizeof(int)的大小和数量
首先使用malloc()函数分配100个int的空间给指针data,然后在data[100]的位置赋值
1 2 3 4 5 6 7 int main () int *data = (int *)malloc (sizeof (int ) * 100 );100 ] = 0 ;free (data);return 0 ;
程序直接运行的时候不会报错,没有任何提示。但是使用valgrind进行检查的时候有如下日志
log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ valgrind --leak-check=yes ./null
可以看到valgrind成功检测出一个无效的写入,在内存分配之后,只有data[0] - data[99]是可以正常写入的,data[100]并不存在,因此出现了无效写入的错误
用和第五题相似的方法创建一个数组,然后通过free()函数对内存释放,然后对已经释放的空间进行读取
1 2 3 4 5 6 7 int main () int *data = (int *)malloc (sizeof (int ) * 100 );free (data);printf ("%d\n" , data[0 ]);return 0 ;
在本地电脑上直接运行的时候输出了0,使用valgrind工具进行检查的时候输出了如下日志
log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ==10682== Memcheck, a memory error detector
可以看见检测出了无效的读写Invalid read of size 4
对data数组中的data[50]进行内存释放,然后输出data[0]
1 2 3 4 5 6 7 8 int main () int *data = (int *)malloc (sizeof (int ) * 100 );free (data + 50 );printf ("%d\n" , data[0 ]);return 0 ;
在直接运行的时候会直接报错
1 2 3 $ ./null
不需要用valgrind也可以检查出此处有free()的问题
根据 c-free-invalid-pointer 的回答,可以知道
When you have in fact allocated a block of memory, you can only free it from the pointer returned by. That is to say, only from the beginning of the block.
当我们分配了一块内存的时候,我们只能从返回的指针开始对这块内存进行释放,也就是说我们只能从内存块的开头对某一处内存进行释放
通过realloc()函数实现一个类似vector的操作
1 2 3 4 5 6 7 8 9 10 int main () int *pt = (int *)malloc (sizeof (int )); 10 ; int *)realloc (pt, sizeof (int ) * 2 ); 1 ] = 20 ; printf ("%d, %d\n" , pt[0 ], pt[1 ]); free (pt); return 0 ;
程序编译可以成功通过,使用valgrind也正常通过,没有无效读写错误
通过这种操作实现的vector可以在访问的时候直接通过index进行访问,时间复杂度为O(1),并且他并不需要和链表一样创建一个指向next的指针,不过在向后添加内容的时候依旧需要O(n)的时间复杂度来向后添加元素。
顺便记录一个Tips, 在C中是允许void *类型进行任意转换的,因此即使没有(int *)也不会出现报错,而在C++中对类型转换的限制更多,并不允许直接进行这样的操作,必须要进行类型转换(通过static_cast转换运算符)才能分配空间给对应的指针。
偷懒,懒得写
OSTEP:系统API的调用
https://halc.top/p/264bf58c
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:进程的调度策略 - Halcyon Zone
本文最后更新于:2022年4月23日 下午
参数介绍:
Response:响应时间,即任务第一次运行的时间
Turnaround: 完成时刻(周转时间),即任务完成那一刻对应的时间
Wait: 等待中时间,即任务处于Ready状态,但当前CPU在执行其他任务的等待时间
执行结果如下
FIFO:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ARG policy FIFOfor 200.00 secs ( DONE at 200.00 )for 200.00 secs ( DONE at 400.00 )for 200.00 secs ( DONE at 600.00 )
同时,对于SJF(Short Job First),由于每个任务的执行时间相同,所以策略上的处理结果和FIFO相同,不额外列出
在按照300,200和100的顺序一次执行任务的时候,对于FIFO策略依次执行,而依据SJF策略,则会先执行时间短的100,依次到最常的300。具体结果如下
FIFO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ARG policy FIFOfor 300.00 secs ( DONE at 300.00 )for 200.00 secs ( DONE at 500.00 )for 100.00 secs ( DONE at 600.00 )
SJF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ARG policy SJFfor 100.00 secs ( DONE at 100.00 )for 200.00 secs ( DONE at 300.00 )for 300.00 secs ( DONE at 600.00 )
SJF的好处在于可以先执行时间短的程序,后执行时间长的程序,同时优化了程序的响应、完成和等待时间。缺点在于因为必须先完整的运行某个任务,后执行下一个任务。如果此时需要高频率执行某任务则无能为力(比如高频率的io输出)
采用RR策略,时间片设置为1,依次执行10、20和30有以下结果
RR策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 ARG policy RRfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secs ( DONE at 28.00 )for 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secs ( DONE at 49.00 )for 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secsfor 1.00 secs ( DONE at 60.00 )
采用RR策略的时候通过轮转运行三个程序,达到类似"同时"运行程序的效果,缩短了任务的反应时间。缺点是由于轮询过程会同时运行其他任务,因此总体的完成时刻和等待时间都会延长。
由于SJF是“短任务优先”的调度策略,因此当到达的任务顺序为先短时间的任务,后长时间任务的时候,SJF和FIFO的周转时间是相同的
当RR策略的量子时间大于等于SJF的单个任务最长工作时间时,SJF和RR可以提供相同的响应时间
当工作长度逐渐增加的时候,SJF的响应时间会逐渐增加,因为SJF必须要完成一个完整的任务才会运行下一个任务,因此后面的任务响应时间必须等待前一个任务的完成,模拟省略。
假定所有任务的长度都大于量子长度,且完成任务的时间都为量子长度的倍数,则可推得以下公式
∑ i = 1 N − 1 i Q N = Q ∑ i = 1 N − 1 i N = Q ∗ N ( N − 1 ) 2 N = Q ( N − 1 ) 2 \frac{\sum_{i=1}^{N-1} iQ}{N}=\frac{Q \sum_{i=1}^{N-1} i}{N}=\frac{Q * \frac{N(N-1)}{2}}{N}=\frac{Q(N-1)}{2} N ∑ i = 1 N − 1 i Q = N Q ∑ i = 1 N − 1 i = N Q ∗ 2 N ( N − 1 ) = 2 Q ( N − 1 )
OSTEP:进程的调度策略
https://halc.top/p/28ea7a49
博客在允许 JavaScript 运行的环境下浏览效果更佳
CS144-Lab0 计算机网络:流的输入和读出 - Halcyon Zone
本文最后更新于:2022年12月1日 凌晨
lab0前后分为两个较为简单的小任务,第一个任务是写一个类似telnet中通信的webget小应用,第二个任务是实现一个简单的ByteStream的类,只需要在单线程的情况下能正常运行即可
第一个任务的参考主要是从项目文件本身的doctests开始着手,其中在提示中已经说了我们将会使用到TCPSocket和Address,在对应的doctests/socket_example_2.cc和doctests/address_example_1.cc中,我们可以得到对于他们的使用例子,只需要创建一个以目标Address初始化并连接的TCPSocket,然后以这个socket向目标服务器发送类似telnet的请求即可获得我们需要的内容
1 2 3 4 5 TCPSocket socket;connect (Address (host, "http" ));write ("GET " + path + " HTTP/1.1\r\n" );write ("Host: " + host + "\r\n" );write ("Connection: close\r\n\r\n" );
由于最后在输入完Connection: close之后,我们本来也要输入一个回车将请求发送,因此在这里需要两个换行符
在处理socket.read()的时候,起初没有仔细考虑pdf中提到的a single call to read is not enough的具体含义,以为是首先会接受所有的文本信息,然后对于结果需要将最后的EOF也打印出来,所以第一次写的时候只是简单的调用了两次read()
1 cout << socket.read () << socket.read ();
然而在make check_webget的时候并没有通过,为了找到问题所在,首先找到check_webget的脚本,发现测试的内容为对cs144.keithw.org下的接口/nph-hasher/xyzzy发送请求,并获取最后一行的内容,而这行内容应该是一串正确的HASH。但是在这个时候尝试以上文的方式运行webget的时候则发现输出的只有以下两行
1 2 HTTP/1.1 200 OK
但是通过telnet的情况下,正常的输入应该是以下的内容
1 2 3 4 HTTP/1.1 200 OK
这个时候就懂了多次调用read()的含义直到遇到eof的含义应该是一直读取到所有缓冲区内的内容都被读取完毕,将代码修改如下就可以通过测试了
1 2 3 4 5 6 7 8 9 10 11 void get_URL (const string &host, const string &path) connect (Address (host, "http" ));write ("GET " + path + " HTTP/1.1\r\n" );write ("Host: " + host + "\r\n" );write ("Connection: close\r\n\r\n" );while (!socket.eof ()) {read ();close ();
第二个任务主要是要我们自己根据头文件的内容来实现一个简单的ByteStream,并且只需要考虑单线程的情况,不用考虑并发等情况。
最后完成的答案先直接贴上来,这块难度也不会很大,在写的时候先大致按要求写出一个逻辑,即使不是很清楚具体实现对不对也问题不大,只需要通过调试逐步修改即可
首先添加的成员变量如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class ByteStream {private :const size_t buffer_max_size;bool is_input_end = false ;size_t write_count, read_count;bool _error{}; public :
最后接口的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 ByteStream::ByteStream (const size_t capacity) : buffer_max_size (capacity), buffer (), write_count (0 ), read_count (0 ) {}size_t ByteStream::write (const string &data) size_t cnt = min (remaining_capacity (), data.length ());substr (0 , cnt);return cnt;string ByteStream::peek_output (const size_t len) const { return buffer.substr (0 , len); }void ByteStream::pop_output (const size_t len) erase (0 , len);std::string ByteStream::read (const size_t len) {substr (0 , len);pop_output (len);return output;void ByteStream::end_input () true ; }bool ByteStream::input_ended () const return is_input_end; }size_t ByteStream::buffer_size () const return buffer.length (); }bool ByteStream::buffer_empty () const return buffer.empty (); }bool ByteStream::eof () const return input_ended () && buffer.empty (); }size_t ByteStream::bytes_written () const return write_count; }size_t ByteStream::bytes_read () const return read_count; }size_t ByteStream::remaining_capacity () const return buffer_max_size - buffer.length (); }
接口的逻辑实现都不难,不过写这个lab的时候的第一次在vscode的环境下使用cmake来进行调试,在这里简单记录一下调试的步骤和需求。
相关code插件 : CMake, CMake Tools, C/C++(Cpptools)
在这里以write()函数中缺少了write_count += cnt这一行为例,使用make check_lab0可以发现在最后有报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 56% tests passed, 4 tests failed out of 9
此时可以将注意力先集中在最上面的t_byte_stream_one_write上,cmake中将byte_stream_one_write作为target编译并运行,可以得到以下报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Test Failure on expectation:
从这里可以知道是测试"write-end-pop"中的第五个执行中,bytes_written并没有返回预期希望的数字3。因此只需要在tests/byte_stream_one_write.cc内"write-end-pop"的test.execute(BytesWritten{3});的位置打上断点,然后直接使用vscode下方栏中cmake的debug图标(需要安装C/C++插件才可以使用快速调试,具体参考这里 )就可以逐步找到自己逻辑中出错的地方并修改即可。
热身的两个lab提供的成就感很足,希望自己能尽快完成下一个lab。
CS144-Lab0 计算机网络:流的输入和读出
https://halc.top/p/2ca0860a
博客在允许 JavaScript 运行的环境下浏览效果更佳
拓展Ubuntu服务器内LVM分区容量引导 - Halcyon Zone
参考文章:解决 Linux /dev/mapper/ubuntu–vg-ubuntu–lv 磁盘空间不足的问题
通过命令查看LVM卷组的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root@azhal:/mnt/Ar2Dread /write
可以看到可扩容大小
Free PE / Size 186882 / <730.01 GiB
使用命令进行扩容
按不同需求有以下命令:
1 2 3 4 5 6 lvextend -L 10G /dev/mapper/ubuntu--vg-ubuntu--lv //增大或减小至19G
具体操作:
1 2 3 4 5 6 7 8 root@azhal:/mnt/Ar2D
检查是否扩容成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root@azhal:/mnt/Ar2Dread /write
可以看到Free Size已经变成0,即扩容成功。
拓展Ubuntu服务器内LVM分区容量引导
https://halc.top/p/2dda2597
博客在允许 JavaScript 运行的环境下浏览效果更佳
Ubuntu上开启内核BBR算法来提高TCP吞吐性能 - Halcyon Zone
参考文章:How to enable BBR on Ubuntu 20.04
默认情况下Linux 使用 Reno 和 CUBIC 拥塞控制算法,Linux kernal 4.9以上版本的内核已经自带该功能,由于Ubuntu 20.04的为5.4.0 kernel,我们可以直接启用
通过以下指令检查目前可选择的拥塞控制算法:
1 sysctl net.ipv4.tcp_available_congestion_control
输出大致为(可用的算法有reno和cubic两种):
1 2 root@vps:~## sysctl net.ipv4.tcp_available_congestion_control
通过以下指令检查目前的拥塞控制算法:
1 sysctl net.ipv4.tcp_congestion_control
输出大致为(目前是cubic):
1 2 root@vps:~## sysctl net.ipv4.tcp_congestion_control
在文件etc/sysctl.conf中写入以下内容:
1 2 net.core.default_qdisc=fq
保存并退出
重置sysctl设置
此时会有大致输出:
1 2 3 root@vps:~## sysctl -p
检查BBR是否在系统中正确启用:
1 sysctl net.ipv4.tcp_congestion_control
大致输出:
1 2 root@vps:~## sysctl net.ipv4.tcp_congestion_control
完成
Ubuntu上开启内核BBR算法来提高TCP吞吐性能
https://halc.top/p/2f2e6810
博客在允许 JavaScript 运行的环境下浏览效果更佳
Ubuntu通过systemd禁用系统睡眠 - Halcyon Zone
How To: Disable Sleep on Ubuntu Server (unixtutorial.org) 1 sudo systemctl status sleep.target
理论上会返回类似如下的内容,里面会注明系统休眠的时间等信息
1 2 3 4 5 6 7 8 9 10 root@azhal:~## systemctl status sleep.target
1 sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
[引用文章原话] This is obviously a very simple way of disabling power management, but I like it because it’s standard and logical enough – there’s no need to edit config files or create cronjobs manually controlling sleep functionality.
大概翻译过来就是指这样的操作标准且合理,因为这样省去了编辑任何文件的麻烦,并且也达到了禁用休眠的目的。
禁用以后大致会变成这样:
1 2 3 4 5 6 7 8 9 root@azhal:~## systemctl status sleep.target
1 sudo systemctl unmask sleep.target suspend.target hibernate.target hybrid-sleep.target
Ubuntu通过systemd禁用系统睡眠
https://halc.top/p/2f594679
博客在允许 JavaScript 运行的环境下浏览效果更佳
网络抓包记录 - Halcyon Zone
本文最后更新于:2023年8月3日 晚上
这个博客主要记录了自己尝试通过抓包分析并解决一些问题的心路历程,从结果上来说很可能问题并没有解决,但是尝试解决这个问题的过程中遇到的一些问题以及自己的思考想通过写博客的方式先记录下来,在以后自己知识储备扩充的时候也许就可以回过头来看看解决下。
今天在尝试部署zerotier的zeronsd私有DNS服务的时候遇到了一个问题:无论是在我之前国内的服务器A上还是香港的服务器B上,zeronsd的部署都是只需要无脑复制粘贴指令就能成功,但是今天尝试在新租赁的国内服务器C上部署的时候则遇到了一个报错:Error Response
在翻阅zeronsd源码的时候发现这块逻辑本来应该是对应请求zerotier那边获取到局域网内所有设备的IP以便于创建私有的DNS条目。
可以看见这部分错误处理里面并没有Error Response的产生原因,而且同时我在香港的服务器上依旧可以正常使用zeronsd。因此也产生了想尝试通过抓包找到问题所在的想法。
lsof获取目标IP既然知道了问题是来自于zeronsd,而且应该是一个和网络Response有关系的问题,那么通过抓包应该是最通用的排查方法。在这里首先通过lsof工具查询zeronsd打开的连接
最开始找到的指令是先通过pidof zeronsd找到进程的pid,然后通过pid来用lsof查询,指令大概是lsof -p $(pidof zeronsd),结果后面翻了下lsof的手册,发现可以直接用-c来找进程,不过pidof以后也感觉会用到,姑且做个记录。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@Aliyun:~]# lsof -c zeronsd
可以发现下面有创建一个TCP连接,并且是处于SYN_SENT的状态。同时在我短时间内重复输入lsof的指令(蠢但有效.jpg),发现返回的依旧是SYN_SENT。一般来说SYN握手的速度应该是很快的,这里很长时间内都处于SYN_SENT的状态就明显很不对劲,所以接下来就需要通过抓包来分析。
在我多次尝试了lsof之后,发现即使有的时候能让连接处于ESTABLISHED的状态,但是过了一会以后依旧会被掐断,并且返回Error Response。通过分析不同的lsof建立TCP连接的目标ip,发现服务器总是向151.101.109.91和146.75.113.91建立连接,应该是请求的域名有做CDN所以解析到了不同的IP。接下来知道了目标IP,抓包就很容易了。这里采取的是通过tshark在配置较弱的服务器上获取到了数据包以后再导出到本地计算机的Wireshark的方法进行分析。
tshark抓包分析首先使用下面的指令对所有http请求进行抓取,并将抓包的内容保存在data.cap文件中
1 tshark -d tcp.port==443,http -w data.cap
之后再将这个文件下载到本地电脑使用Wireshark过滤选定目标IP追踪TCP流,可以发现数据流如下图
可以发现就这一次的数据来说SYN握手的部分是成功了的,TLS的四次握手也能成功建立,但是在发送了一些应用数据之后,云的服务器就开始向远端服务器发送RST报文来请求强制终止连接了。重新抓包以后又发现出现了多次TCP数据包的重传。
对于在TCP连接中,先发送了FIN,然后发送RST的一个可能性的原因如下:
您的流中的FIN和RST数据包并不直接相关。通过发送FIN,表示没有更多要发送的数据。它仍然可以从连接的另一端接收更多数据。然而,当有更多数据到达时,发送RST来表示应用程序将不再从套接字读取任何数据。
如果一个应用程序想要干净地关闭TCP连接而不引发任何RST数据包,则必须首先使用shutdown系统调用关闭写入套接字,同时保持读取套接字处于打开状态。在关闭写入套接字之后,它仍然需要读取所有对方要发送的数据,然后才能完全关闭套接字。
但是zeronsd对于这次连接的重置是返回了Error的,所以基本上可以判断并不是zeronsd本身发送的rst阻断连接。
在这里为了让后续抓包更容易复现,首先对于TLS建立握手的第一个数据包,我们可以直接查询到域名
之后我就尝试通过curl -vL my.zerotier.com的方法来通过抓取curl包分析问题。为了区分成功和失败的区别,我在这里也使用了curl -vL www.baidu.com作为对照组。
返回的抓包内容大致如下:
可以发现整个连接没有大问题,只是在连接结束以后百度那边发送了一个rst包给我们,但是tcp的四次挥手是正常完成了的。
可以发现在想要结束连接的时候并没有正常挥手,在客户端这边接收到服务器那边的FIN之前就开始给服务器发送RST报文尝试断开连接
这次抓包本身没有获取到啥决定性的信息可以确定问题产生的原因,因此目前自己也只能借由Zerotier和百度请求的对比,怀疑是因为Zerotier是国外网站,被服务商阻断了(但是在FIN之后再阻断也很奇怪,虽然会在FIN之后发送RST报文,但是curl还是可以读取到my.zerotier.com的网页信息),暂时对进一步的排查没有头绪。
我尝试在同一台服务器上部署一个VOIP服务器。也是一样使用别的服务器的时候一点问题都没有,但是在这台国内的服务器上就遇到问题了。这次遇到问题就想尽可能的搞懂原因,因此做了以下实验
实验设备:一台香港服务器(对照组),一台阿里云国内服务器(样本组),以及自己的Windows设备
实验情景:在香港和国内服务器上都部署Mumble的服务器(一个VOIP程序),然后使用Windows对这两台服务器进行连接,其中Mumble连接采取了TLS加密的方式,加密证书均为自签。
实验步骤:
使用IP直连香港服务器上在端口64738部署的murmur(Mumble服务端的别称) 使用域名voice1.abc.com连接香港服务器在端口64738部署的murmur 使用IP直连国内服务器上在端口64738部署的murmur 使用域名voice2.abc.com连接国内服务器在端口64738部署的murmur 实验期望:四种不同的方式连接murmur都能成功,且不会有明显区别
实验结果:方法1-3都可以正常访问,但是方法4连接被服务器阻断
在对以上四种情况进行抓包以后,获取到的Wireshark图像大致如下
香港服务器使用域名连接
香港服务器使用IP直连
国内服务器使用IP直连
国内服务器使用域名连接
到这里基本上很明显可以发现只有在国内服务器使用域名连接的时候,服务器那边会在进行TLS握手的时候直接进行阻断,让你无法成功建立TLS连接
这次抓包也没获得啥特别有用的信息。不过由于这个问题是在用阿里云的时候才遇到,之前用同样在国内的腾讯云没有遇到,则初步怀疑是阿里云对任意端口(非443)现在都做了备案检测,只要是没备案的域名/网站,无论是TLS还是明文,只要检测到你用了域名就禁封。相比之下腾讯那边就要宽松一些,至少murmur在腾讯云上是可以正常使用域名进行连接通讯的。
网络抓包记录
https://halc.top/p/3930e42b
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux通过davfs2挂载WebDav网盘 - Halcyon Zone
注:已改用rclone作为较优方案
davfs挂载与使用缺陷 输入以下指令安装
创建需要挂载的硬盘,这里以/opt/Backup为例,挂载网址为http://localhost:8080/dav/,账号为admin,密码为123456
将硬盘挂载到对应路径
1 sudo mount.davfs http://locaohost:8080/dav/ /opt/Backup/
输入账号密码并手动连接
编辑/etc/davfs2/davfs2.conf,找到其中的use_lock取消注释,并修改值为0
修改/etc/davfs2/secrets,在末尾添加
1 http://localhost:8080/dav/ admin 123456
编辑/etc/fstab,在最后一行添加以下内容
1 http://localhost:8080/dav/ /opt/Backup/ davfs defaults 0 0
以上的http://localhost:8080/dav/和用户名密码均为示例,请在了解WebDav 之后替换为自己需要的值
Linux通过davfs2挂载WebDav网盘
https://halc.top/p/39b9efc1
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:内存碎片的管理 - Halcyon Zone
执行题目给出的参数可以得到以下内容
answer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 seed 0
这里以开头两段为例子分析,后面的算法相同
1 2 3 4 5 6 7 8 9 10 11 12 13 ptr[0] = Alloc(3) returned 1000 (searched 1 elements)
首先,根据开头参数可以知道目前分配方式不考虑Header头指针,并且不考虑内存合并
ptr[0] = Alloc(3)会从1000开始分配大小为3的内存(此时空间足够,分配成功),并返回1000的地址作为开头。此时空闲空间Free List只有一块,从1003开始,总大小为97
之后的Free(ptr[0])则将刚刚分配的内存释放,释放后由于并未合并,因此出现了[3]->[97]的空闲空间表,之后再进行ptr[1] = Alloc(5)。由于第一个空闲空间为[3]不足以容纳[5]的分配,因此第二个空间是从1003作为内存开始的地址,并使用了5的内存空间
然后再进行Free(ptr[1])的操作释放内存并且不合并,则有了[3]->[5]->[92]的空闲可用空间。后面的运算以此类推
如果出现了在空闲的大内存中分配了新的小内存
1 2 ptr[4] = Alloc(2) returned 1000 (searched 4 elements)
则占用部分内存后,新的剩余内存将被作为新的内存段保留使用,并且已分配内存也会产生新的内存碎片
使用最差匹配有如下输出
answer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 seed 0
比对可以发现,在最差匹配的情况下,第二次重复分配8大小的空间时不会重复利用本身空闲的长度为8的空间,而是依旧从后面的最大空闲空间中分配8大小的空间出来,此时地址从1024开始分配,并且1008开头的地址不会被复用
1 2 3 4 5 6 7 8 9 10 11 Free(ptr[2])- ptr[3] = Alloc(8) returned 1008 (searched 4 elements) - Free List [ Size 3 ]: [ addr:1000 sz:3 ][ addr:1003 sz:5 ][ addr:1016 sz:84 ] + ptr[3] = Alloc(8) returned 1016 (searched 4 elements) + Free List [ Size 4 ]: [ addr:1000 sz:3 ][ addr:1003 sz:5 ][ addr:1008 sz:8 ][ addr:1024 sz:76 ]
在使用FIRST进行匹配的情况下,空间分配的情况与BEST无异,在本例题示范当中,由于FIRST是找到可以用的内容后直接进行匹配,而示例当中恰好所有可用空间最小的情况匹配了FIRST的情况,因此只有搜索的次数变少,效率变快,其他差异不大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 + policy FIRST - policy BEST + ptr[3] = Alloc(8) returned 1008 (searched 3 elements) - ptr[3] = Alloc(8) returned 1008 (searched 4 elements) + ptr[4] = Alloc(2) returned 1000 (searched 1 elements) - ptr[4] = Alloc(2) returned 1000 (searched 4 elements) + ptr[5] = Alloc(7) returned 1008 (searched 3 elements) - ptr[5] = Alloc(7) returned 1008 (searched 4 elements)
三种不同的参数分别对应了以下三种不同的内存分配方式
ADDSORT: 空闲的地址在搜索的时候是按地址的顺序进行排序搜索SIZESORT-: 空闲的地址在搜索的时候按地址块的大小,先搜索大的,后搜索小的SIZESORT+: 空闲的地址在搜索的时候按地址快的大小,先搜索小的,后搜索大的由于BEST和WORSE分配的方法都需要把所有内存段全部搜索后再分配,因此在根据这两种不同的调度之后产生的内存碎片的数量是相同的。在三种不同的调度中采取FIRST控制空闲变量则将会造成比较大的影响。对于SIZESORT-的情况来说,由于未分配的大块内存一直在最前面,因此很容易在反复删除小内存段的过程中不断积累内存碎片;优点是每次直接扫描的第一个就将是可以直接使用的内存,搜索的次数明显减少。采用SIZESORT+的情况下,由于小碎片都积累在前面,因此如果此时遇到比较大块的内存需要分配时,则会增加需要搜索的内存段数量,时间会增加;优点是每次分配的时候都尽量先匹配比较小的内存段,对于多次分配小内存的情况来说,不会那么容易产生浪费。
首先,如果对内存段不采用合并处理的话,随着时间推移,内存碎片将会越来越多,并且后面能够成功分配内存需要的搜索次数以及成功概率都会升高。其次,由于内存合并是在地址连续的基础上才会进行合并,因此如果采用了SIZESORT的分配方法,打乱了地址的顺序,虽然依旧有成功合并的可能,但是效率还是要低于以ADDRSORT方法对空闲内存段进行排序。
如果-P设置的太高,模拟的则是在平时写程序的过程中一直不对申请的内存空间进行Free释放,则会导致空间过早的就被使用完毕,后续无法再继续分配,设置的低的情况下则代表了内存每次使用分配完毕以后都立即释放,这样就能够一直有空闲的内存等待分配。
如果要生成高度碎片化的空间,只要让空闲的空间碎片始终不被合并,并且分配的时候根据上述中第四题得到的规律增加搜索次数,让即使被Free的内存块也无法被使用或增加使用次数即可。
OSTEP:内存碎片的管理
https://halc.top/p/3d85131
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux通过fdisk分区引导 - Halcyon Zone
参考地址:CSDN-树莓派Openwrt SD卡扩展问题
在给自己的R2S使用64G的SD卡的时候,安装完毕系统启动发现内存卡中有将近50多G的空间没有得到合理的使用,记录一下通过网上树莓派磁盘扩展分区的步骤来在R2S上同样对SD卡进行分区拓展
磁盘检查
df -h 检查已经使用的磁盘容量
fdisk /dev/mmcblk0 查看磁盘分区,并进行部分操作
检查磁盘分区情况并且进行分区
在fdisk后的Command( m for help):后输入p来查看分区情况
其中可以看到最后分区的End为3817471
新建磁盘
输入n进行新建磁盘,之后会有几个询问,分别对应以下几点
输入磁盘编码,一般按Default的设置即可 输入扇区的起始位置,这里输入最后一个分区+1的数值大小,比如上图中End后为3817471,那我这里就输入3817472 输入终止扇区,这里可以填入Default设置,就会设置最大可用扇区 输入w进行保存 把新建的分区格式化为ext4格式
mkfs.ext4 /dev/mmcblk0p3
分区挂载
方法一在Openwrt的管理界面的挂载点中,直接使用"自动挂载"进行磁盘的挂载 方法二mount -v -t ext4 -o rw /dev/mmcblk0p3 [pathToMount] 通过df -h命令查看,可以发现已经挂载成功
Linux通过fdisk分区引导
https://halc.top/p/3efcbb51
博客在允许 JavaScript 运行的环境下浏览效果更佳
搭建ZeroTier Controller管理网络引导 - Halcyon Zone
本来的理解 : 在使用ZeroTier的时候经常会出现穿透失败,或者穿透延迟过大但是中转服务器不好用的情况,之前有参考过网上的教程来通过一台国内的VPS搭建自己的MOON节点来达到加速的目的,但是最后的效果不尽人意,而且还存在安卓端添加mood节点并不轻松的问题,所以在这里采取直接通过key-networks/ztncui: ZeroTier network controller UI 搭建自己的ZeroTier根服务器
最近在使用zerotier-cli listpeers指令的时候发现设置的控制器是一个LEAF而不是本来预期的PLANT,在查阅了一部分资料之后发现如果想要加速网络的话目前比较好的方便还是MOON服务器进行中转,详情参考另外一篇ZeroTier下Moon服务器的搭建。
准备好一台在国内,至少开放端口3443端口的服务器(暂未测试对其他端口是否有需求)
在服务器内安装ZeroTier,以下为一键安装脚本
curl -s https://install.zerotier.com | sudo bash
如果服务器有安装GPG,则需要多几个步骤
1 2 curl -s 'https://raw.githubusercontent.com/zerotier/ZeroTierOne/master/doc/contact%40zerotier.com.gpg' | gpg --import && \if z=$(curl -s 'https://install.zerotier.com/' | gpg); then echo "$z " | sudo bash; fi
sudo yum install https://download.key-networks.com/el7/ztncui/1/ztncui-release-1-1.noarch.rpm -y
sudo yum install ztncui -y
(可选择):添加服务器自己的TLS/SSL证书,或者添加服务器自认证的证书 - 后文有教程
开放服务器的3443端口(已开放可忽略)
sudo sh -c "echo 'HTTPS_PORT=3443' > /opt/key-networks/ztncui/.env"
sudo sh -c "echo 'NODE_ENV=production' >> /opt/key-networks/ztncui/.env"
sudo systemctl restart ztncui
通过HTTPS来在服务器的3443端口访问控制界面,比如
e.g. https://my.network.controller:3443
通过默认的账号admin和密码password.
curl -O https://s3-us-west-1.amazonaws.com/key-networks/deb/ztncui/1/x86_64/ztncui_0.7.1_amd64.deb
sudo apt-get install ./ztncui_0.7.1_amd64.deb
(可选择):添加服务器自己的TLS/SSL证书,或者添加服务器自认证的证书 - 后文有教程
开放服务器的3443端口(已开放可忽略)
sudo sh -c "echo 'HTTPS_PORT=3443' > /opt/key-networks/ztncui/.env"
sudo sh -c "echo 'NODE_ENV=production' >> /opt/key-networks/ztncui/.env"
sudo systemctl restart ztncui
通过HTTPS来在服务器的3443端口访问控制界面,比如
e.g. https://my.network.controller:3443
通过默认的账号admin和密码password.
如果要添加额外的监听端口,只需要在/opt/key-network/ztncui下面添加一个.env文件,其中附带一行
HTTPS_PORT=3443
或者任意一个大于1024的端口即可。
如果存在.env文件来指向特定的一个端口,那么ztncui将会在所有的端口监听网络,如果希望限制一个特定的IP进行监听的话,只需要在.env文件中再添加一行
HTTPS_HOST=12.34.56.78
来设置自己制定的IP或者域名即可。
这种方法添加的证书会存在浏览器警告的问题,不过由于是自己使用,平时也不会一直盯着控制界面,所以影响应该不会很大,如果有共用或者对安全有需求建议自行添加
以下为无脑脚本
1 2 3 4 5 6 sudo -icd /opt/key-networks/ztncui/etc/tlsrm -f privkey.pem fullchain.pemchown ztncui.ztncui *.pemchmod 600 privkey.pem
由于ztnui是自己搭建的一个ZeroTier服务器,所以并没有预先设置好的DHCP分配,需要自己设置分配范围。如果需要添加一个新的网络,在使用账号密码登入以后,点击Add network就可以添加一个自己的虚拟局域网络
点击Add network
设置好network的名字并create
如果需要设置"隐私"与否,在Private中设置即可,这里稍作翻译即可看懂,所以不多解释
点击如下图所示的Easy Setup来快速完成一个IPv4的DHCP分配
如下图所示填入对应信息
以下为一个例子:
1 2 3 网关:192.168.192.0/24
然后点submit即可快速创建,也可以通过generate network address的方式自动随机填入。
如果需要设置NAT路由,则只需要在Routes下进行配置和添加即可。
搭建ZeroTier Controller管理网络引导
https://halc.top/p/41385a4a
博客在允许 JavaScript 运行的环境下浏览效果更佳
虚拟化:初识IOMMU(TODO) - Halcyon Zone
最近在尝试给朋友的小主机安装ZStack作为虚拟化管理平台的时候,遇到了一个需求:通过HDMI直接将Windows虚拟机的画面输出到外界显示器。需要解决这个问题自然而然的就需要使用直通的方法将显卡直通给虚拟机。不过之前直通都是直接找别人的博客一步一步傻瓜式执行下去,对于每个指令发生了什么,以及iommu是如何工作的都不清楚。刚好趁着这个机会了解并记录下自己的学习历程
我自己现在有一台基于Proxmox VE的All in one小主机了,这里就叫做主机A,而我朋友的主机则称为主机B。在安装ZStack之前,我原以为直通的过程依旧可以无脑用脚本来实现,但是实际执行过程中却发现在PVE中应该成功的ACS的改动在ZStack中却并没有成功。这便引起我了从ACS到IOMMU作用的好奇。
首先,在主机A和主机B的BIOS上都启用IOMMU的功能,可以发现原本的iommu分组都十分混乱,大部分设备杂糅在一起。为了解决这个问题,便有了叫做ACS的技术。
ACS的主要功能
设备隔离 :ACS允许对PCIe设备进行更细粒度的控制,增强了设备间的隔离。这在虚拟化环境中尤为重要,因为它可以帮助确保虚拟机之间的安全隔离,防止一个虚拟机访问另一个虚拟机的PCIe设备。控制I/O访问 :ACS可以控制PCIe设备的I/O访问,例如控制哪些设备可以发起对其他设备或内存的直接内存访问(DMA)。提高安全性 :通过对设备间访问的更严格控制,ACS有助于提高系统的整体安全性,尤其是在多租户或需要高安全性的环境中。通过启用iommu的同时启用acs,就可以将系统中iommu的group分成更细的设备单位,具体修改的操作实现参数可能不尽相同,但是基本上都是先对/etc/default/grub中的GRUB_CMDLINE_LINUX进行修改,添加amd_iommu=on和pcie_acs_override=downstream,multifunction即可
对于分组情况的查看,在PCI passthrough via OVMF - ArchWiki (archlinux.org) 可以找到一个脚本来列出当前的IOMMU Groups的情况
1 2 3 4 5 6 7 8 # !/bin/bash
当我在自己的PVE主机上执行这个脚本之后,可以发现显卡是单独在一个Groups中的
但是在ZStack平台上执行以后可以发现核显并不是单独在一个Groups里面的
当时的log没有保存,这里假象一个其他的例子代替,是一个GTX 970显卡的例子,一般来说独显是会有单独的Groups的
1 2 3 4 5 6 7 ......
具体问题的产生原因还不清楚(找到问题以后会来更新博客),不过就IOMMU的分组情况大概是这样。
对于什么是iommu,找到这样一个简单扼要的概括
大家知道,I/O设备可以直接存取内存,称为DMA(Direct Memory Access);DMA要存取的内存地址称为DMA地址(也可称为BUS address)。在DMA技术刚出现的时候,DMA地址都是物理内存地址,简单直接,但缺点是不灵活,比如要求物理内存必须是连续的一整块而且不能是高位地址等等,也不能充分满足虚拟机的需要。后来dmar就出现了。 dmar意为DMA remapping,是Intel为支持虚拟机而设计的I/O虚拟化技术,I/O设备访问的DMA地址不再是物理内存地址,而要通过DMA remapping硬件进行转译,DMA remapping硬件会把DMA地址翻译成物理内存地址,并检查访问权限等等。负责DMA remapping操作的硬件称为IOMMU。做个类比:大家都知道MMU是支持内存地址虚拟化的硬件,MMU是为CPU服务的;而IOMMU是为I/O设备服务的,是将DMA地址进行虚拟化的硬件。
而在这其中,IOMMU分组则是实现设备直通的关键,每个分组都包含了可以共享一同一个虚拟内存映射的设备集合。如果一个设备独占一个IOMMU分组,直通它是很简单的。但是如果多个设备共享同一个分组,比如显卡和USB接口,那么就无法只直通其中一个设备。
后续就是找时间尝试研究为什么ACS在ZStack中没有正常被启用,并将结论补充到这篇博客当中。
虚拟化:初识IOMMU(TODO)
https://halc.top/p/4416e368
博客在允许 JavaScript 运行的环境下浏览效果更佳
使用Yadm管理Linux配置文件 - Halcyon Zone
今年暑假看Missing-course的时候开始意识到备份Linux配置文件的重要性,以后即使切换机器也可以很容易的恢复自己喜欢的编程环境。在简单搜索了几个方式以后,决定使用yadm作为管理工具,并且写了一个模板,便于分享和使用。
该仓库的主要用途为使用yadm作为管理工具,通过Github来同步自己的Dotfiles
先在自己当前环境下安装yadm,具体安装说明参照Installation
通过Use this template或者下载源码的方式,创建并上传到自己的一个仓库中,最好是Private类型
在本身没有经过配置Dotfiles的环境下(或提前备份好自己的Dotfiles)输入以下指令拉取模板到本地进行管理
1 yadm clone https://github.com/<your id>/<your repository> --bootstrap
在附带--boostrap的情况下执行完毕上述指令以后将会按默认模板文件使用git来对自己的Dotfiles进行管理
在clone仓库的时候如果附带了bootstrap将会自动执行以下三件事
在以 apt/yum/pacman 作为包管理器的情况下安装zsh vim tmux curl wget openssl 安装 oh-my-zsh,并以p10k为主题。安装zsh-autosuggestions,zsh-syntax-highlighting和zsh-proxy三个插件 切换 zsh 为当前用户的默认终端 配置了rust国内镜像 添加了transfer 用于分享文件(输入transfer /path/to/file即可) 使用pws作为powershell.exe的alias,便于wsl环境下使用powershell 启用了vi的normal模式,在输入命令的时候按Esc即可 配置默认使用~/.gitignore作为全局ignore`文件 在使用https时的验证交由.git-credentials文件纯文本保存密码(有风险,可加密) 对于类似.ssh/id_rsa或者.git-credentials文件可以通过yadm自带的encrypt工具进行加密,使用步骤如下
在.config/yadm/encrypt文件内写入需要加密的文件路径,支持正则匹配
假设在.ssh/目录下所有文件(例如config, id_rsa)都需要进行加密,则在.config/yadm/encrypt写入.ssh/*后输入以下指令(安装openssl为前提)
则会要求输入一个密码来进行加密
加密完则会在.local/share/yadm目录下产生一个archive作为加密打包后的文件,将该文件添加并上传到Github
虽然加密文件本身有一定安全性,但为了保险起见还是推荐使用Private仓库来存储自己的Dotfiles
1 2 3 yadm add ~/.local/share/yadm/archive
原本的文件此时将会依旧本地存在于(例如config, id_rsa),但不需要上传到Github当中
在下次重装系统/更换环境的时候,如果需要通过yadm对环境进行复原并解密加密文件,则只需要输入以下指令
就会将加密打包的文件解密到对应的文件目录,保证一定的安全性
使用Yadm管理Linux配置文件
https://halc.top/p/4457ea2b
博客在允许 JavaScript 运行的环境下浏览效果更佳
ZeroTier的私有DNS服务器ZeroNSD搭建引导 - Halcyon Zone
翻译的时间为2021-9-9,其中部分内容有删改,只提取了主观认为有用的信息,仅供参考
这个功能目前还在Beta测试当中 这个功能将会内嵌在未来将出现的ZeroTier 2.0当中,不过目前它是一个独立的软件 接下来的步骤将会有一定困难 当ZeroTier加入了一个网络后,它将会创建一个虚拟网口 当ZeroTier加入了多个网络后,也会有多个虚拟网口 当ZeroNSD启动了之后,它将绑定在某一个特定的网口上 如果你需要对多个网络都使用ZeroNSD,那你也需要创建多个ZeroNSD服务绑定在它对应的网口上 该教程使用了两台不同的机器,一台是在云上的Ubuntu虚拟机,另外一台为Windows笔记本,如果要跟着来完成这个快速上手,最好使用相同的平台,如果使用了不同的平台,你最好要有能力弄清楚自己要做什么。
按正常流程创建、链接并授权一个以在ZeroTier官网 创建的network
在自己的帐号的Account页面下创见一个新的API Token,ZeroNSD将会利用这个token来获取对应网络下设备的不同名字,来达到自动分配dns的效果。
创建一个文件来让ZeroNSD能够以文件的方式读取token,参考指令如下 需要修改token为自己的token :
1 2 3 sudo bash -c "echo ZEROTIER_CENTRAL_TOKEN > /var/lib/zerotier-one/token"
安装ZeroTier的进程管理应用
zerotier-systemd-manager的rpm和deb安装包发布在这个网站:https://github.com/zerotier/zerotier-systemd-manager/releases ,请自行替换下面指令为最新的安装包。
1 2 wget https://github.com/zerotier/zerotier-systemd-manager/releases/download/v0.2.1/zerotier-systemd-manager_0.2.1_linux_amd64.deb
重启所有的ZeroTier服务
1 2 3 4 sudo systemctl daemon-reload
ZeroNSD针对每一个网络需要都创建一个独立的服务,对DNS来说延迟是很敏感的,所以最好让客户端和服务端尽可能接近
安装ZeroNSD,它的安装包发布在这里 ,请自行替换下面指令为最新的安装包。
1 2 wget https://github.com/zerotier/zeronsd/releases/download/v0.1.7/zeronsd_0.1.7_amd64.deb
如果默认发布的地方没有对应平台的安装包,可以通过Cargo自行编译安装
1 2 > sudo /usr/bin/apt-get -y install net-tools librust-openssl-dev pkg-config cargo > sudo /usr/bin/cargo install zeronsd --root /usr/local
对于你希望启用DNS服务的网络,执行类似以下的命令:
/var/lib/zerotier-one/token为token文件所在路径 (在上文设置token中有提及)
beyond.corp为你希望的域名后缀
af78bf94364e2035为你自己的网络ID
1 2 3 sudo zeronsd supervise -t /var/lib/zerotier-one/token -w -d beyond.corp af78bf94364e2035
服务器需要开放53端口,让客户端可以请求到DNS 客户端需要启用Allow DNS的选项(安卓等平台默认启用,可以无视) 假设笔记本的设备名为laptop,那么此时就可以通过设备名和dns后缀ping通设备了(不考虑防火墙)
1 2 3 4 5 6 7 PS C:\Users\AzureBird> ping laptop.beyond.corp
如果后续需要更新配置(比如TLD),使用类似如下指令即可。(记得修改为自己设置的ID等参数):
1 2 3 sudo zeronsd supervise -t /var/lib/zerotier-one/token -w -d beyond.corp af78bf94364e2035
ZeroNSD还可以添加本地的hosts作为私有的DNS服务,不过由于该部分内容并不复杂,且属于进阶内容,故不做教程,此贴仅作入门参考使用的快速手册。
ZeroTier的私有DNS服务器ZeroNSD搭建引导
https://halc.top/p/447b77e9
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:分页的原理 - Halcyon Zone
在虚拟地址中,vpn=address space size/page size. 所以在分页大小不变的情况下增加址空间大小会增加分页数量,在地址空间大小不变的情况下增加分页大小会减少分页数量。
如果使用了很大的分页,当程序只需要很小一部分内存的时候依旧会申请过大的内存,造成不必要的内存浪费
每次当某个分页被地址空间使用后,PTE中对应的Vaild Bit就会置为1。当提高used paged数量后,操作系统总是能找到vpn对应的pfn
在这三种分配来说,前两种分页的大小相对于地址空间本身来说太大了,而在第三个例子当中,相对于256m,修改分页大小1m为更小的值将更加有助于提高空间的利用效率。
首先,地址空间和物理空间的大小都要是分页大小的倍数,其次,物理空间必须要比地址空间更大,否则会无法访问对应的地址空间。
OSTEP:分页的原理
https://halc.top/p/44838b9c
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:程序上下文切换的开销 - Halcyon Zone
由于该实验要求在单个CPU上运行两个进程并在他们两个UNIX管道,而书中介绍的sche_affinity()函数的具体调用不是很清楚,所以这里通过Docker的参数限制,创建了一个只使用宿主机一个CPU资源的容器进行实验。
单核Docker容器的创建
1 docker run -it -d --cpuset-cpus="0" --name=os ubuntu:latest
注:在以上环境中如果使用函数查询CPU核心数依旧可以发现为16或其他多核,但是在通过指令stress -c 4实际测试后,性能只会在宿主机的单一CPU核心上运行,不影响实验。但是如果在创建Docker容器的时候使用的是--cpus=1,由于负载均衡,并不能达到单核进行实验的目的。
通过gettimeofday()增加时间戳函数,获取执行时间
创建10个管道,循环5次,每次循环的时候分别在两个管道之间反复通信,并输出上下文切换时间差
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <stdint.h> #include <sys/time.h> uint64_t getTimeTick () struct timeval tv ;NULL );return tv.tv_usec;int main () int fd[10 ][2 ];for (int i = 0 ; i < 10 ; i++)if (pipe(fd[i]) < 0 )"pipe" );exit (1 );char timeWrite[256 ], timeRead[256 ];for (int i = 0 ; i < 9 ; i += 2 )int rc = fork();switch (rc)case -1 : "fork" );exit (EXIT_FAILURE);case 0 :0 ], timeRead, sizeof (timeRead));printf ("Read - Write %d: %lu\n" , i, getTimeTick() - atol(timeRead));sprintf (timeWrite, "%lu" , getTimeTick());1 ][1 ], timeWrite, sizeof (timeWrite));exit (0 );default :sprintf (timeWrite, "%lu" , getTimeTick());1 ], timeWrite, sizeof (timeWrite));1 ][0 ], timeRead, sizeof (timeRead));printf ("Read - Write %d: %lu\n" , i + 1 , getTimeTick() - atol(timeRead));break ;return 0 ;
1 2 3 4 5 6 7 8 9 10 Read - Write 0: 24
由于在执行完write之后会继续执行主进程,下方的read也会运行,因此最后结果中奇数进程的结果时间会比偶数进程的时间长,正确答案应该靠近偶数(已经在代码中用注释写明)。
OSTEP:程序上下文切换的开销
https://halc.top/p/4b65fa48
博客在允许 JavaScript 运行的环境下浏览效果更佳
CS144-Lab2 计算机网络:TCP Receiver的实现 - Halcyon Zone
本文最后更新于:2023年4月11日 凌晨
为了节省在TCP Header当中的空间,在StreamReassembler里面写的index虽然是一个uint64_t的类型,但是在实际的Header中是使用一个uint32_t的seqno来进行标记位置的。对于uint32_t的seqno和uint64_t的index的相互转换则是通过以4GiB (2^32 bytes)为一个长度进行取模来实现。
同时为了提高TCP本身的安全性,并且确保每次获得的segments数据段都是来自于本次连接的,因此提出了ISN(Initial Sequence Number)的概念,即本次链接是从序号为isn开始作为seqno进行通信,大于isn的seqno所代表的index是本次链接所需要的数据段,早于isn的seqno则是来自于上一次连接的老数据段,并不需要处理。
如果想要将uint32_t的seqno转为一个uint64_t则需要一个checkpoint作为定位,防止seqno被定位到错误的位置上。这个checkpoint在实现中就是最后一个重新组装后的字符位置
按lab2的原文:In your TCP implementation, you’ll use the index of the last reassembled byte as the checkpoint.
通过寻找距离checkpoint最近的seqno就可以定位到本来需要插入的seqno位置了
对于将uint32_t转为uint64_t的代码实现很简单,只需要将uint64_t的index加上isn的值之后对2^32进行取模就行了,具体代码实现如下
1 2 3 4 WrappingInt32 wrap (uint64_t n, WrappingInt32 isn) {uint64_t result = (n + isn.raw_value ()) % (static_cast <uint64_t >(UINT32_MAX) + 1 );return WrappingInt32 (static_cast <uint32_t >(result));
而对于将wrap后的seqno转回index,我直接通过类似分类讨论的枚举找到了四个临界点,只需要判断checkpoint相对于临界点的位置就可以得到答案。代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 uint64_t unwrap (WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) const uint64_t L = (1ul << 32 );const uint64_t a = (checkpoint / L) * L - isn.raw_value () + n.raw_value ();if (checkpoint > a + (L * 3 ) / 2 ) {return a + 2 * L;else if (checkpoint > a + L / 2 ) {return a + L;else if (checkpoint < L) {return n.raw_value () < isn.raw_value () ? a + L : a;else {return checkpoint < a - L / 2 ? a - L : a;
通解推导 由以下公式
( i n d e x + i s n ) m o d L = s e q n o \left ( index+isn \right )\mod{ L } = seqno ( i n d e x + i s n ) m o d L = s e q n o
通过推导可以得到
i n d e x = s e q n o + k ∗ L − i s n index = seqno + k * L - isn i n d e x = s e q n o + k ∗ L − i s n
因此如果需要得到离checkpoint最近的index就只需要找到合适的k即可,在这里不妨设
m = c h e c k p o i n t / L m = checkpoint / L m = c h e c k p o i n t / L
取m作为一个附近值,通过画图可以知道,在一般情况下,答案一定在checkpoint附近的三个区间内
在这种情况下,checkpoint的前中后三个区间都存在,只要列举并讨论范围就很简单了
当seqno - isn为正数的时候,index可能的一个取值会落在第②个区间上,有
i n d e x ′ ′ = m ∗ L + s e q n o − i s n index'' = m * L + seqno - isn i n d e x ′ ′ = m ∗ L + s e q n o − i s n
此时第①区间和第③区间上的index可以分别表示为
i n d e x ′ = i n d e x ′ ′ − L i n d e x ′ ′ ′ = i n d e x ′ ′ + L index' = index'' - L \\\\ index''' = index'' + L i n d e x ′ = i n d e x ′ ′ − L i n d e x ′ ′ ′ = i n d e x ′ ′ + L
对index'、index''和index'''的中间值进行判断,很容易得到以下规律
a = m ∗ L + s e q n o − i s n L = U I N T 32 _ M A X + 1 { c h e c k p o i n t < a − L / 2 index=a-L a − L / 2 ≤ c h e c k p o i n t < a + L / 2 index=a a + L / 2 ≤ c h e c k p o i n t index=a+L \begin{array}{l} a = m*L+seqno-isn \\\\ L = UINT32\_MAX+1 \\\\ \left \{\begin{matrix} checkpoint < a - L/2 & \text{index=a-L}\\\\ a-L/2\leq checkpoint< a+L/2 & \text{index=a}\\\\ a+L/2\leq checkpoint & \text{index=a+L} \end{matrix}\right. \end{array} a = m ∗ L + s e q n o − i s n L = U I N T 3 2 _ M A X + 1 ⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ c h e c k p o i n t < a − L / 2 a − L / 2 ≤ c h e c k p o i n t < a + L / 2 a + L / 2 ≤ c h e c k p o i n t index=a-L index=a index=a+L
注:此时checkpoint一定小于 a+L,因为a+L属于第③区间,而checkpoint在第②区间内
此时因为是从m*L的位置向前移动,所以相比于上面,三个可能是答案的index的分布则改为了
i n d e x ′ = m ∗ L + s e q n o − i s n i n d e x ′ ′ = i n d e x ′ + L i n d e x ′ ′ ′ = i n d e x ′ + 2 ∗ L index' = m * L + seqno - isn\\ index'' = index' + L\\ index''' = index' + 2 * L i n d e x ′ = m ∗ L + s e q n o − i s n i n d e x ′ ′ = i n d e x ′ + L i n d e x ′ ′ ′ = i n d e x ′ + 2 ∗ L
所以很容易得到以下结果
a = m ∗ L + s e q n o − i s n L = U I N T 32 _ M A X + 1 { c h e c k p o i n t < a + L / 2 index=a a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 index=a + L a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a+2*L \begin{array}{l} a = m*L+seqno-isn\\ L = UINT32\_MAX+1\\ \left \{\begin{matrix} checkpoint < a + L/2 & \text{index=a}\\ a+L/2\leq checkpoint< a+(3*L)/2 & \text{index=a + L}\\ a+(3*L)/2\leq checkpoint & \text{index=a+2*L} \end{matrix}\right. \end{array} a = m ∗ L + s e q n o − i s n L = U I N T 3 2 _ M A X + 1 ⎩ ⎨ ⎧ c h e c k p o i n t < a + L / 2 a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a index=a + L index=a+2*L
将以上两种规律整合,我们很容易可以得到以下通解
a = m ∗ L + s e q n o − i s n L = U I N T 32 _ M A X + 1 { c h e c k p o i n t < a − L / 2 index=a-L a − L / 2 ≤ c h e c k p o i n t < a + L / 2 index=a a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 index=a + L a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a+2*L \begin{array}{l} a = m*L+seqno-isn\\ L = UINT32\_MAX+1\\ \left \{\begin{matrix} checkpoint < a - L/2 & \text{index=a-L}\\ a-L/2\leq checkpoint< a+L/2 & \text{index=a}\\ a+L/2\leq checkpoint< a+(3*L)/2 & \text{index=a + L}\\ a+(3*L)/2\leq checkpoint & \text{index=a+2*L} \end{matrix}\right. \end{array} a = m ∗ L + s e q n o − i s n L = U I N T 3 2 _ M A X + 1 ⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ c h e c k p o i n t < a − L / 2 a − L / 2 ≤ c h e c k p o i n t < a + L / 2 a + L / 2 ≤ c h e c k p o i n t < a + ( 3 ∗ L ) / 2 a + ( 3 ∗ L ) / 2 ≤ c h e c k p o i n t index=a-L index=a index=a + L index=a+2*L
特殊情况 在checkpoint < L的时候,通解中对于a - L的一部分(即checkpoint < a + L)就不适用了,不过分析起来也很简单,由于有
( i n d e x + i s n ) m o d L = s e q n o \left ( index+isn \right )\mod{ L } = seqno ( i n d e x + i s n ) m o d L = s e q n o
所以当seqno小于isn的时候,答案一定在下一个区间,因此答案即L - isn + seqno,当seqno大于isn且checkpoint < a + L,所以答案一定为a
所以就可以得到上述代码了。
这部分代码逻辑完成的是tcp握手中对于tcp段的接受处理。
我自己增加的私有成员和用途大致为:
_is_syn: 判断链接是否建立_isn: 存入第一次建立连接时接受的seqno来初始化_is_fin: 用于判断结束输入的报文是否传入对于ackno和checkpoint的实现机制是:
ackno: 本质上就是返回已经整合好的数据量,也就是bytes_stream的bytes_written(),同时建立连接后一定存在syn所以可以直接加一,之后只需要判断fin是否到达并且整合完毕,然后再次加一即可。checkpoint: 和ackno差别不大,只需要直接返回已经写入完成的字符个数即可知道了上述几个逻辑以后就只需要通过调整简单的逻辑flag加上lab1里面的push_substring来对payload()进行整合就可以通过了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void TCPReceiver::segment_received (const TCPSegment &seg) if ((_is_syn == 0 ) && seg.header ().syn) {1 ;header ().seqno;else if (_is_syn == 0 ) {return ;const uint64_t checkpoint = _reassembler.stream_out ().bytes_written () + 1 ;uint64_t stream_index = unwrap (seg.header ().seqno, _isn, checkpoint) - 1 + seg.header ().syn;push_substring (seg.payload ().copy (), stream_index, seg.header ().fin);if (seg.header ().fin) {1 ;optional<WrappingInt32> TCPReceiver::ackno () const {stream_out ().bytes_written ();if ((_is_fin != 0 ) && _reassembler.unassembled_bytes () == 0 ) {return _is_syn ? optional <WrappingInt32>(result) : nullopt ;size_t TCPReceiver::window_size () const return _capacity - _reassembler.stream_out ().buffer_size (); }
这里有一个让我感觉很疑惑的点就是在单元测试中存在两种测试样例,这里做个记录,后面如果知道了原因就来解决一下
存在同时携带SYN和FIN报文,按照正常的TCP握手感觉这是不合理的 在接受SYN的同时会接受一部分的Data进行处理,按正常的TCP也是不会这么做的 CS144-Lab2 计算机网络:TCP Receiver的实现
https://halc.top/p/4e68707
博客在允许 JavaScript 运行的环境下浏览效果更佳
性能测试:跨墙的内网穿透工具选择 - Halcyon Zone
由于需要将家里HomeLab的服务内网穿透到外网服务器上,如果使用Zerotier一类的服务进行穿透的话,在经过GFW以后速度会暴跌。因此需要使用带加密的服务来进行建立连接。
在大约一年前的时候使用了Frp作为跨墙的内网穿透工具,但是因为不知名的原因,当时Frps和Frpc的连接总是容易断开,当时也没有做具体的原因分析。这段时间在新购买了海外VPS之后决定花一些时间对不同的内网穿透工具在跨越GFW的情况下的性能和丢包做一个对比
综合性能、带宽和丢包率来看,最新版本的Frp已经是不错的选择。不过目前还不确定在特殊时期Frp能否经历防火墙的考验,而V2Ray虽然在Benchmark的结果上不如人意,但是在跨墙可用性来说是身经百战的。Rathole在个人当前的应用场景下则没有太大的优势。
内网虚拟机一台,配置为2C4G,后文简称client。该机器位于家庭宽带环境中,没有公网IP。 外网机器一台,配置为1C1G,后文简称server。使用的是洛杉矶的机器,国内线路有做优化。 V2RAY:使用ws+tls协议,其中tls部分由nginx进行处理。版本为:5.4.1 FRP:服务端除了auth.token不添加任何多余的参数,性能方面均以默认配置文件为主。版本为:0.53.2 Rathole:同样以默认配置文件为主,最新的源码65b27f076c编译而来的二进制文件。版本为:0.5.0 其中V2RAY与FRP均使用Docker的方式进行部署,Rathole通过screen直接运行在后台。
该测试环境存在诸多不合理的地方,该测试主要为自己的特定使用场景做参考。如果有问题还请斧正
通过三套不同的工具,分别将client上的5201端口转发到server的5201(v2ray),15201(frp)和25201(rathole)上。
在server端输入以下指令,以Json文件获取120s内tcp连接的带宽和稳定性
1 iperf3 -J --logfile ./xxx_result.log -c localhost -p xxx -t 120s
将测试结果统计后以可视化的形式进行对比
V2Ray:部署复杂度较高,配置文件可读性较差。对于ws+tls来说,不但要部署v2ray本身,在服务端还需要额外的域名和Nginx进行转发。同时如果我有多个client的时候,会出现不确定到底是代理到哪个机器的问题,在不进行额外配置的情况下容易出现502报错。 FRP;部署难度极低,配置文件可读性极好,上手难度极低。 Rathole:部署难度中等,每次添加端口需要同时修改服务端和客户端的配置文件,后续维护是最麻烦的。 在通过上述测试流程后,对日志进行分析统计,可以得到以下统计图表:
带宽:Frp和Rathole没有明显差距,V2Ray的带宽相对来说较低,但是没有拉开明显差距 丢包率:Frp相比Rathole略有优势,在晚高峰的时候依旧能保证丢包率控制在30以下。V2Ray相比之下则更容易丢包 由于网站只有小范围用户使用,因此对拥塞控制并没有很高的需求。不过从这份Benchmark中也可以看出,在高并发场景下,Rathole可能会更有优势 资源占用:V2Ray由于加密解密的严谨性,资源消耗相比Rathole与Frp都要多。在资源占用这一点上,Frp几乎是毫无悬念的领先 综上,从配置难度以及性能对比的角度来看,暂时使用Frp会是一个不错的选择。如果后续出现了性能的不稳定性也会在这里进行补充说明。
性能测试:跨墙的内网穿透工具选择
https://halc.top/p/59e029c8
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux下通过swap或zram管理内存 - Halcyon Zone
参考网址:Ubuntu开启zram和zswap~ 使用zram进行内存压缩 Ubuntu添加swap分区
Swap分区在系统的物理内存不够用的时候,把物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap分区中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。
Swap分区虽然可以达到扩大内存的作用,但缺点依旧很明显,相比直接使用物理内存,Swap必然速度上会出现一定的取舍。
新建一个文件夹来作为swap的文件
1 2 3 mkdir swap
其中sfile是文件的名字,可以自己设置,count=2000000是Swap分区的大小,这里指2G
转化为swap文件
sudo mkswap sfile
激活swap文件
sudo swapon sfile
查看效果
free -m
1 2 3 total used free shared buff/cache available
已经成功挂载了
添加开机加载
修改配置文件,添加Swap文件(Swap文件的路径为/root/swap/sfile)
/root/swap/sfile none swap sw 0 0
类似如下
1 2 3 4 /dev/vda1 / ext4 defaults 1 1
swap空间在机械硬盘的设备上往往不一定是个好选择,这个时候牺牲一定的CPU性能来使用zram则会比较好
zram 是在 Linux Kernel 3.2 加入的一个模块,其功能是在内存中开辟一块空间,用来存储压缩后的内存数据,这样可以在牺牲一定的 CPU Cycle 的情况下,在内存中存储尽量多的数据而不需要写入到磁盘。
安装zram-config,并重启系统
1 2 sudo apt install zram-config
通过zramctl查看zram的情况(默认情况下ALGORITHM为lzo)
1 2 NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
注意到这里的压缩算法,有两种算法 lzo 和 lz4 可选,默认是 lzo。根据 Benchmark ,lz4 的压缩和解压性能在压缩率和 lzo 持平的情况下显著高于后者,因此我们应该采用 lz4 而非 lzo 以获得更高的系统效率。
修改配置文件来使用lz4算法
usr/bin/init-zram-swapping
将源文件的以下部分
1 2 3 4 5 6 7 #
替换为
1 2 3 4 5 6 7 8 #
载入新的配置
systemctl restart zram-config
编辑grub文件
sudo vi /etc/default/grub
在文件末尾加上
1 GRUB_CMDLINE_LINUX=”zswap.enabled=1″
保存退出
在终端输入命令
sudo update-grub
重启系统
zswap是一种新的轻量化后端构架,将进程中正交换出的页面压缩,并存储在一个基于RAM的内存缓冲池中。除一些为低内存环境预留的一小部分外,zswap缓冲池不预先分配,按需增加,最大尺寸可用户自定义。
Zswap启动存在于主线程中的一个前端,称为frontswap,zswap/frontswap进程在页面真正交换出之前监听正常交换路径,所以现有的交换页面选择机理不变。
Zswap也引入重要功能,当zswap缓冲池满时自动驱除页面从zswap缓冲池到swap设备。防止陈旧页面填满缓冲池。
Linux下通过swap或zram管理内存
https://halc.top/p/5a7c7761
博客在允许 JavaScript 运行的环境下浏览效果更佳
WSL配置Proxy代理引导 - Halcyon Zone
在三番五次被wsl的proxy问题折腾的心态爆炸,并重装了好几次系统以后,总算理清楚了WSL如果想要搭配windowns上的clash for windows的正确使用方法。把之前无论是需要脚本还是各种复杂操作的博客都删了,在这里记录一个完全不需要任何脚本,也不需要额外配置防火墙的合理方案。
WSL 2 ArchLinux(理论上来说其他发行版应该相同)Windows 11(win10应该同理)Clash For Windows改方案为WSL继承System Proxy来达到代理上网的目的,使用TUN Mode直接用就行,不需要额外设置
正常配置好Clash For Windows,并且启用Allow LAN的设置
在允许应用或功能通过 Windows Defender防火墙中寻找是否有clash-win64.exe的规则配置,注意不是 Clash For Windows ,CFW本身只是clash的一个前端,在启动CFW的时候有概率防火墙只添加CFW本身,而不添加作为核心的clash的防火墙规则,这个时候则需要我们手动修改
如果已经有了clash-win64.exe的规则,则只需要配置专有和公共网络同时允许 即可。如果没有clash-win64.exe的规则,可以通过下方的允许其他应用手动添加规则,具体clash核心文件的路径可以通过任务管理器后台或Clash for Windows\resources\static\files\win\x64\clash-win64.exe类似的路径查询到。添加规则的时候同时允许专用和公共 即可
之前经常折腾好了防火墙但过了三四个月或者一段时间后wsl和windows之间就因为防火墙断开,但总找不到原因,现在想想很有可能是当时clash for windows升级安装的时候规则被覆盖或路径变化导致的。WSL2的网络对Windows来说也是一个Public的公开网络,在设置了单独程序允许通信之后,虽然wsl有可能无法ping通windows的主机,但正常访问clash的代理端口是没有问题的
到这里为止防火墙的问题就解决了,只需要通过合理的方法配置好WSL下的代理变量就可以正常使用。其中主机名.local这个域名是会直接在wsl内映射到作为dns服务器的宿主机上,因此并不需要写额外的脚本来添加映射
较为简单的方法即通过zsh终端下oh my zsh+ zsh-proxy 插件,通过设置proxy来实现全局基本功能的代理配置,而在config_proxy步骤中的代理IP填入类似Zephyrus.local:7890格式的地址即可。
Zephyrus为我Windows的设备名,可在Windows设置中重命名,一般来说默认设置应该为类似DESKTOP-XXXX.local:7890,修改和查看的方法可通过搜索引擎自己解决
通过以上方式配置后的WSL就可以正常通过Windows上的Clash代理了。每次WSL出网络问题总是感觉莫名其妙没头绪,之前也试过通过New-NetFireWallRule一类的方法放行防火墙,但都不是很好用或者后面偶尔突然就出问题,现在总算弄清楚了原因而且能很舒服的使用win里面的代理了。
WSL配置Proxy代理引导
https://halc.top/p/6088c65c
博客在允许 JavaScript 运行的环境下浏览效果更佳
将OpenClash设置为Adguard Home的上级DNS - Halcyon Zone
参考结合adguard home 使用 DNS 设置求教 · Issue #99 中hankclc和icyleaf的回答,总结一下设置步骤作为参考
将AdGuard Home的上游DNS设置为OpenClash的DNS地址
OpenClash的DNS地址可以在全局设置中看到,一般为127.0.0.1:7874
关闭OpenClash的本地DNS劫持
AdGuard Home的重定向模式选择使用53端口替换dnsmasq
OpenClash不要用TUN或TUN混合模式(还未自己测试)
将OpenClash设置为Adguard Home的上级DNS
https://halc.top/p/690287f9
博客在允许 JavaScript 运行的环境下浏览效果更佳
Cloudflare Partner的CDN配置 - Halcyon Zone
由于服务器本身搭建使用的是香港的服务器,建站不需要域名备案。为了不使用Cloudflare默认的海外CDN,而使用我们需求的自定义CDN,需要把域名托管到一个非Cloudflare的平台下,这里直接托管到腾讯云Dnspod的解析下。
备份Cloudflare下的解析信息
在控制台下修改Name Server为Dnspod控制台提供的NS服务器
将之前备份的解析信息再次添入
(这里没找到Dnspod的导入域名信息,所以手动添入)
开启"域名设置"下的CNAME加速,减少CNAME的解析次数
注册Cloudflare邮箱,这里不做解释
在 楠格 (或者类似Cloudflare Partner网站) 登入自己的Cloudflare账号
将自己需要使用CDN的域名添加到控制台下,TTL设置两分钟,CDN设置为开启
添加完毕以后在CNAME接入处可以看到主机名对应的CNAME信息,在Dnspod设置对应的解析就可以使用CDN的解析服务。
CNAME信息
Dnspod设置
通过参考网上的IP表,在Dnspod的控制台中再次添加域名对应的A记录解析,可以设置不同的运营商解析不同的IP,来达到让流量走自定义加速的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 172.64.32.1/24 (推荐移动,走香港)
设置了对应的A记录后保存退出,可通过ping example.com来测试是否设置成功。
参考网站:
针对使用Cloudflare CDN国内网站的速度优化方案 - 闪电博 (wbolt.com) Cloudflare Partner的CDN配置
https://halc.top/p/6a6a7409
博客在允许 JavaScript 运行的环境下浏览效果更佳
Rsync使用方法摘抄 - Halcyon Zone
rsync 用法教程 RSYNC备份服务 Remote-Sync,意味远程动态同步,可以在不同的主机之间进行同步操作,相比一般将文件一次性全部备份而不同的好处是,Rsync可以做到每次增量同步,只对部分文件进行修改,目前个人主要用来和WebDAV挂载的本地目录进行配合使用,对服务器进行备份处理
TODO
TODO
Rsync使用方法摘抄
https://halc.top/p/6d032e05
博客在允许 JavaScript 运行的环境下浏览效果更佳
CloudReve个人网盘引导 - Halcyon Zone
安装好宝塔面板,并且预先安装好LNMP环境 Aria2离线下载配置 在FreeSSL 上获取SSL证书和密钥 前往官方库 下载最新版的对应系统的可执行文件
在BT面板内添加网站CloudReve,并且设置对应的域名和根目录(下图为示例)
将可执行文件上传到在宝塔面板设置的根目录中,并cd到当前目录
运行CloudReve,并记录初始的账号密码
1 2 chmod +x ./cloudreve
登入http://ip:5212,在控制面板中修改默认的管理员账号和密码
自带的数据库是SQLite,这里需要修改为MySql
在宝塔面板创建一个MySql数据库
在运行一次CloudReve后,根目录会有一个conf.ini的文件,根据自己情况加入以下配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ; 数据库相关,如果你只想使用内置的 SQLite数据库,这一部分直接删去即可
这里使用Ubuntu自带的systemd进行进程守护
编辑配置文件
vim /usr/lib/systemd/system/cloudreve.service
将下文的PATH_TO_CLOUDREVE更改为宝塔面板中设置的根目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [Unit]
载入进程守护并运行
1 2 3 systemctl daemon-reload
在宝塔面板的站点设置中,添加反向代理,配置按下图类比设置(主要还是第二步)
点击配置文件,将原本的location /{}的内容替换如下内容
1 2 3 4 5 6 7 8 9 location / {$proxy_add_x_forwarded_for ;$http_host ;
保存配置文件,通过宝塔中设置的网站域名即可直接访问网盘地址
在FreeSSL获取证书以后,在KeyManager中导出证书和私钥,分别为.crt和.key文件 在站点设置中找到SSL,使用其他证书,然后通过编辑器打开crt证书文件和key文件,分别将其中的内容复制到密钥(KEY)和证书(PEM格式)中 保存并开启强制HTTPS,即可通过SSL访问云盘并且进行配置了。 参考网站:
Cloudreve对接onedrive搭建属于自己的网盘系统 (lanhui.co) CloudReve官方文档 CloudReve个人网盘引导
https://halc.top/p/713e2886
博客在允许 JavaScript 运行的环境下浏览效果更佳
CS144-Lab3 计算机网络:TCP Sender的实现 - Halcyon Zone
本文最后更新于:2023年4月11日 凌晨
追踪Receiver返回的windows_size(可接受的剩余容量)和ackno(已经确认接收的字符位置) 只要数据来了就直接对数据进行封装并发送,只有在窗口被消耗为零的情况下才停止发送 将没有被acknowledge的数据包存储起来,在超时的时候进行发送 对于超时重传的时间判断,使用已经提供的tick()函数,每次调用的时候传入多少时间就消耗了多少时间 超时重传的默认基准值会以成员变量的形式在TCPSender中进行初始化 在TCPSegment中有一个_segments_out的成员,只需要向这个queue内push一个TCPSegment就相当于将这个数据段发送了 对于计时器的部分,为了方便抽象管理,我这里选择直接创建一个类来进行封装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class TCPTimer {private :size_t _tick_passed = 0 ; size_t _rto_timeout = 0 ; unsigned int _rto_count = 0 ; bool _is_running{false }; public :void reset (const uint16_t retx_timeout) 0 ;0 ;void run () true ; }void stop () false ; }bool is_running () const return _is_running; }unsigned int rto_count () const return _rto_count; }void slow_start () 2 ;void update (const size_t ms_since_last_tick) bool is_timeout () const return _is_running && _tick_passed >= _rto_timeout; }void restart () 0 ; }
在private的部分定义则如下:
1 2 3 4 5 6 7 8 9 10 11 size_t _ackno = 0 ;size_t _window_size = 1 ;
额外定义的函数主要作用为将已经封装好的TCP报文进行发送,如果在发送的时候检测到RTO重传计时器并没有工作,则发送的同时激活重传计时器。同时在发送了报文后对seqno序号进行消耗,移动_next_seqno指针
1 2 3 4 5 6 7 8 9 10 11 12 void TCPSender::_send_segment(const TCPSegment &seg) {const size_t seg_len = seg.length_in_sequence_space ();push (seg);push (seg);if (not _rto_timer.is_running ()) {run ();reset (_initial_retransmission_timeout);
对于需要封装的报文,大致可以分为三类,一类是最开始用于建立连接的SYN报文,一类是携带数据的PAYLOAD报文,最后一类是用于发送结束连接的挥手FIN报文。在该方法中主要的难点就是通过对目前已经确认的ackno和next_seqno等数据来判断当前需要封装的报文具体是哪一类,以及根据还未接收到的数据以及零窗口本身的机制来判断空闲的窗口大小
首先,为了防止出现对方当前空闲窗口已满,而sender就一直啥也不发的情况出现,因此在接受到的窗口大小是0的时候,要将其改为1,来避免零窗口堵塞。同时由于部分数据还在传输的路上,这一部分的数据也需要被减掉,从而得到最后的空闲大小fill_space。
1 2 size_t fill_space = _window_size ? _window_size : 1 ;bytes_in_flight ();
SYN报文的判断很简单,因为发送SYN的话无非是打开连接的建立者A自己,又或者是收到了A发来报文的B返回一个携带ACK的SYN报文进行确认。而对于A和B来说,由于SYN报文都是他们自己发送的第一个报文,因此在封装的过程中,他们的“下一个发送序列号”_next_seqno显而易见的应该为零。大致逻辑代码如下
1 2 header ().syn = (_next_seqno == 0 );
对于含有内容的报文,主要的工作就是对payload长度的合理切割,对此只需要在TCPConfig::MAX_PAYLOAD_SIZE和当前剩余``中取最小值并从_stream当中读入。
1 2 3 size_t segment_payload_size = min (TCPConfig::MAX_PAYLOAD_SIZE, fill_space);payload () = _stream.read (segment_payload_size);
在_stream发送完毕,并且被我方全部接受了的时候发送一个携带FIN的报文,告知对方我方已经发送完毕。由于FIN本身需要消耗一个序列号,因此发送前需检查当前数据段是否还有一个空位来放FIN
1 2 3 4 if (_stream.eof () && fill_space > section.length_in_sequence_space ()) {header ().fin = true ;
在标记完了FIN之后,如果这个报文依旧不占用序列号,则说明这个报文不是TCP Sender处理的部分;又或者此时在FIN已经发送的基础上,重复发送了一个FIN,这时多的FIN应该被抛弃
1 2 3 4 if (section.length_in_sequence_space () == 0 || _next_seqno == _stream.bytes_written () + 2 ) {return ;
最后总的代码如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void TCPSender::fill_window () size_t fill_space = _window_size ? _window_size : 1 ;bytes_in_flight ();while (fill_space > 0 ) {header ().seqno = next_seqno ();header ().syn = (_next_seqno == 0 );size_t segment_payload_size = min (TCPConfig::MAX_PAYLOAD_SIZE, fill_space);payload () = _stream.read (segment_payload_size);if (_stream.eof () && fill_space > section.length_in_sequence_space ()) {header ().fin = true ;if (section.length_in_sequence_space () == 0 || _next_seqno == _stream.bytes_written () + 2 ) {return ;length_in_sequence_space ();
这个感觉可能是看起来最简单的一个函数了,因为用了_ackno来记录已经确认过的报文,同时_next_seqno又代表的是将要发送的数据流位置,因此只需要将_next_seqno - _ackno返回的就是正在发送中的数据长度了。(最开始想实现的时候还在考虑要不要在每次fill_window和ack_received的时候添加计数器。。)
1 uint64_t TCPSender::bytes_in_flight () const return _next_seqno - _ackno; }
确认报文主要需要的逻辑有以下四个部分:
只处理有效并且正确的ackno。如果ackno有效,记录ackno和window_size用以fill_window()来进行报文的封装 记录ack报文中包含的窗口大小 如果曾经的报文已经确认过,则报文已经送达,将送达的报文从缓冲区中弹出,如果所有的报文都被弹出了,则关闭RTO计时器 如果接受到了对方这时的窗口又有了空闲大小,则使用fill_window()来填充新的空报文 对于判断ackno是否是正确的ackno,只需要判断ackno是否处于已经记录的_ackno和_next_seqno之间,如果在这个区间之外,意味着要么是老的ackno,要么是确认了不存在的数据,需要进行短路丢弃,逻辑如下
1 2 3 4 5 uint64_t abs_ackno = unwrap (ackno, _isn, _next_seqno);if (abs_ackno < _ackno || abs_ackno > _next_seqno) {return ;
在接受到了窗口大小之后只需要直接将其记录
1 2
这部分都是属于对于超时重传的处理,其中主要需要实现的是对缓冲区确认后的报文进行弹出,同时弹出所有报文后取消对RTO的占用,初始化超时重传的等待时间并记录当前的时间。
其中弹出操作只有在_ackno确认的是第一个报文对应的seqno和length的时候才进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bool has_reset = false ;while (not _cache.empty () &&front ().header ().seqno.raw_value () + _cache.front ().length_in_sequence_space () <= ackno.raw_value ()) {if (not has_reset) {reset (_initial_retransmission_timeout);true ;pop ();if (_cache.empty ()) {stop ();fill_window ();
最后总的代码如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void TCPSender::ack_received (const WrappingInt32 ackno, const uint16_t window_size) uint64_t abs_ackno = unwrap (ackno, _isn, _next_seqno);if (abs_ackno < _ackno || abs_ackno > _next_seqno) {return ;bool has_reset = false ;while (not _cache.empty () &&front ().header ().seqno.raw_value () + _cache.front ().length_in_sequence_space () <= ackno.raw_value ()) {if (not has_reset) {reset (_initial_retransmission_timeout);true ;pop ();if (_cache.empty ()) {stop ();fill_window ();
该函数主要的作用是推动时间流动,并且判断是否触发超时重传,如果触发了超时重传首先将计时器更新到当前时间。然后当对方窗口不繁忙的情况下(window_size非零)触发了重传就把下次重传的等待时间翻倍,并且记录一次重连;如果对方窗口正处于繁忙期(window_size为零),则不翻倍连接时间。然后再将缓冲区内第一个发送的报文进行重新发送。代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void TCPSender::tick (const size_t ms_since_last_tick) update (ms_since_last_tick);if ((not _rto_timer.is_timeout ())) {return ;if (_window_size != 0 ) {slow_start ();if (_rto_timer.rto_count () <= TCPConfig::MAX_RETX_ATTEMPTS) {push (_cache.front ());restart ();
这个函数就是直接返回次数的,直接返回_rto_timer.rto_count();的大小即可。
CS144-Lab3 计算机网络:TCP Sender的实现
https://halc.top/p/73e1b791
博客在允许 JavaScript 运行的环境下浏览效果更佳
快慢指针 - Halcyon Zone
以下内容仅为刷题总结,只记录目前遇到过的情况,如果后面遇到了更多可能性再做记录。
快慢指针的主要思想有点类似追击问题,通过让两个不同的小人以不同的速度在线性路径上行进,来招到某个特殊的相对位置。通常可以用来解决大致一下两类问题:
线性路径上某特殊点的位置和对应的操作 判断链表中是否存在循环(以及循环的点位置) 一般的思路是让两个不同的小人先以某一个相对的路径进行移动,之后再以一定倍率的相对速度进行继续移动,如果发生了『追击』、『相遇』或者『触底』等特殊事件的时候,就可以作为解题需要的特殊位置来进行处理。
如何判断出链表的中点位置?
答:通过两个速度分别为v和2v的指针同时从表头开始出发,当2v速度的指针『触底』的时候,以速度v前进的指针指向的位置理应为中点。
如果链表的长度为偶数的话,具体是停留在中间位置的左边还是右边要结合具体情况进行判断
如何判断链表内是否有循环?
答:让两个不同速度的指针分别出发,如果有环存在的话,则必然会有两个指针在环内相遇。
如何判断链表内开始进入环的位置?
答:让两个指针分别以速度v和2v出发,相遇则说明环存在。这个时候假入环前的长度为D,设环的长度为C,入环点到相遇点的距离为S1,相遇点重新回到入环点的距离则为S2。
此时快指针比慢指针多走n圈,所以走的距离必然为D+S1+nC 慢指针走一圈的时候,快指针能走两圈。所以相遇必然发声在第一个环内,所以慢指针走的距离为D+S1 由于2 * (D + S1) == D + S1 + nC和C = S1 + S2,所以不难得出D = (n - 1)(S1 + S2) + S2,即D = (n - 1)C + S2的结论,翻译一下则为,入环点前面的长度D即为慢指针再走S2,到达入环点之后,再走n-1圈的长度 。 所以这个时候只需要再设定一个指针,让它从头开始走,当走到入环点D的时候,理论上来说慢指针也将走完第n-1圈,所以他们会相遇,同时慢指针的步数即为进入环的长度! 如何删除链表中的倒数第N个节点?
答:让两个起始位置相差n的指针以同样的速度运动,当前面的指针『触底』的时候,后面的指针自己就是「倒数第n个」节点了。
实际操作的时候,由于单向链表需要知道前一个节点才能对后一个节点进行操作,所以通常会让走的快的节点比自己先走一步。
快慢指针
https://halc.top/p/76495b47
博客在允许 JavaScript 运行的环境下浏览效果更佳
Ubuntu删除无用的包和垃圾文件 - Halcyon Zone
Ubuntu删除无用缓存及垃圾文件 1 2 3 sudo apt-get autoclean ## 清理旧版本的软件缓存
这三个指令主要是用于清理升级时候产生的缓存和无用的包
包在/var/cache/apt/archives 没有下载完毕的在/var/cache/apt/archives/partial 1 2 sudo apt-get remove --purge [软件名字] ## 卸载某个软件
1 sudo apt-get install deborphan -y
见博客:删除多余的Ubuntu内核,解决因grub无法正常启动的问题
Ubuntu删除无用的包和垃圾文件
https://halc.top/p/77f84830
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:通过分段管理内存 - Halcyon Zone
这里记录一个样例作为例子,其他的答案则跳过重复的计算步骤
运行第一个seed可以得到以下输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ARG seed 0
对于VA 0: 0x0000006c (decimal: 108)的情况计算如下
由Address Size为128(2^7)得到高位为第7位 将VA的0x6c(108)转为二进制,按7位来算则是1 101100,因此可以知道这是SEG 1的地址 栈是从最下方的内存反方向增加,VA最底部内存位为0x80(128),因此0x6c(108)的VA对应偏移量为108 - 128 = -20 VA中0x80(128)的地址对应PA为0x200(512),因此按偏移量-20算可以得到VA中0x6c(108)对应的PA为0x1ec(492)
答案 1 2 3 4 5 6 Virtual Address Trace
以第一题为参考;在虚拟地址中SEG 0的范围是0-19,SEG 1的范围是108-127,非法地址为20-107。
以下为通过运行-A标志对分界点进行分别测试有如下结果
1 2 3 4 5 6 7 Virtual Address Trace
设置为以下指令即可
1 ./segmentation.py -a 16 -p 128 -A 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15 --b0 0 --l0 2 --b1 16 --l1 1 -c
输出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Virtual Address Trace
要让90%的地址可以被访问,则对于SEG 0的界限寄存器到SEG 1的界限寄存器中间地址差要为总虚拟地址的10%即可。
( b 1 − l 1 − ( b 0 + l 0 ) ) A d d r e s s S i z e < 10 % \frac{(b1 - l1 - (b0 + l0))}{Address Size} < 10\% A d d r e s s S i z e ( b 1 − l 1 − ( b 0 + l 0 ) ) < 1 0 %
所以地址都失效代表没有可以访问的地址,因此l0和l1界限寄存器都设置为0即可
OSTEP:通过分段管理内存
https://halc.top/p/783d8b13
博客在允许 JavaScript 运行的环境下浏览效果更佳
总结:2022年5月 - Halcyon Zone
这个月算是找回了感觉,还算充实。
这个月应该算是最平常的一个月了,整个人谈不上有动力,也谈不上完全摆烂。月初刚开始的时候把OSTEP上操作系统虚拟化的部分基本上写完了,然后就开始关注开源之夏项目申请相关的内容。在之前某个学长的推荐下看过一篇xmake-clangd配置vscode写cpp环境的知乎的帖子,当时对于cpp编译和链接相关的知识还完全没有概念,在开源之夏的时候模模糊糊搜了下xmake发现居然有项目能申请,就怂恿和gofaquan一起报了相关的项目。在五月底到六月初花了大概一百多RMB学习了cpp常见的一些项目管理会遇到的问题,感觉还蛮值的,希望最后项目申请能成功中标,给暑假的自己找点事情做。
学校也快到期末了,这学期的大作业还算应付的过来,大部分大作业都能组队解决,不能组队的也不算麻烦,基本上1-2天的时间也都能搞定,希望下个月的期末考试能一切顺利,别挂科。
这个月主要的学习部分应该也就是上半个月和六月份初了。五月中旬的时候学校终于有了解封相关的信息,于是开始到处想办法出去吃,报复性消费了好几顿过度饮食,体重直接涨了十多斤。现在期末考试临近,也没有什么减肥的想法,打算在考试前可能就通过不断的摄入碳水来缓解压力了,减肥啥的还是等考完期末考试再说了XD。
然后就是每次考试前都日常想要有的报复性消费。这学期把自己之前Niz那个108键的键盘换成了68配位的。目前过渡到日常使用已经没什么问题了,后面看看能不能开发点新功能,再提高提高效率(其实就是差生文具多 )
希望期末考试算顺利复习完,不挂科 能熟悉xmake要导入的包相关源码 在期末考试结束以前是不指望有什么生活质量了,只能寄托希望给暑假的自己了
减肥!至少恢复160-以下 调整自己的作息,打破在家必摆烂的心态(感觉不太可能) 总结:2022年5月
https://halc.top/p/795cfa1d
博客在允许 JavaScript 运行的环境下浏览效果更佳
使用Github Actions自动部署Hexo - Halcyon Zone
之前博客一直用的都是Jekyll框架,在使用Github Pages进行部署的时候并不需要自己手动配置,不过在换了Hexo主题之后,每次写完了博客除了要push一次commit到博客的内容分支上,还需要自己手动deploy一次。虽然也不会很麻烦,不过用Github Actions来完成这个过程也要更顺畅一些。原本觉得这个需求应该很简单,直接在Actions上执行一次hexo g -d的指令就好,结果因为Github在HTTPS上对Token的验证,以及Hexo自带的one-command-deployment存在BUG ,折腾到凌晨两三点才发现,并且通过issues里面提供的修改链接使用oauth进行url验证的方法还是失败了,最后花了半小时改成了ssh密钥验证很轻松就完成了。。下面为对Hexo的Actions的脚本的一个备份
配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 name: Hexo Deploy on: push: branches: - hexo jobs: deploy: runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2 with: ref: hexo - name: Cache node modules uses: actions/cache@v1 id: cache with: path: node_modules key: ${{ runner.os }}-node-v2-${{ hashFiles('**/package-lock.json') }} restore-keys: | ${{ runner.os }}-node-v2 - name: Install Dependencies if: steps.cache.outputs.cache-hit != 'true' run: | npm ci - name: Build and Deploy run: | mkdir -p ~/.ssh/ echo "${{ secrets.DEPLOY_KEY }}" > ~/.ssh/id_rsa chmod 600 ~/.ssh/id_rsa ssh-keyscan github.com >> ~/.ssh/known_hosts git config --global user.email "halc-days@outlook.com" git config --global user.name "HalcyonAzure" npx hexo g -d rm -rf ~/.ssh/id_rsa
整个脚本大致流程为
检测到hexo的内容分支有push之后,checkout到内容分支。
判断是否有nodejs的modules缓存。
如果检测到有效缓存则跳过安装步骤,直接进行下一步。 如果没有检测到有效缓存则对模块进行部署 创建id_rsa密钥文件,并将仓库中DEPLOY_KEY的secret写入密钥文件,并且配置github.com的信任和全局帐号邮箱
对hexo进行generate & deploy操作
删除写入的密钥文件
使用Github Actions自动部署Hexo
https://halc.top/p/7bfa5e14
博客在允许 JavaScript 运行的环境下浏览效果更佳
Ubuntu下安装Oh My Zsh引导 - Halcyon Zone
本文最后更新于:2022年4月7日 下午
1 2 3 sudo apt install zsh -y
1 wget https://github.com/robbyrussell/oh-my-zsh/raw/master/tools/install.sh -O - | sh
字体安装(Hack NF)
其他字体:ryanoasis/nerd-fonts
编辑zsh配置文件
修改主题(以powerlevel10k 为例)
拉取主题仓库
1 git clone --depth=1 https://gitee.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k
在~/.zshrc下修改主题内容
1 ZSH_THEME="powerlevel10k/powerlevel10k"
安装zsh-autosuggestions、zsh-syntax-highlighting、zsh-proxy和z
1 2 3 git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
配置插件,编辑.zshrc文件,在plugins处添加,类似效果如下:
1 2 3 4 #
zshrc完整文件配置帮助
1 2 3 4 5 6 # # #
Ubuntu下安装Oh My Zsh引导
https://halc.top/p/80f884dc
博客在允许 JavaScript 运行的环境下浏览效果更佳
使用clink优化cmd - Halcyon Zone
苦于powershell每次都要一秒多的启动速度,偶然这两天发现了clink这个用于提升cmd体验的工具,尝试了下发现经过简单的配置以后可以替代平时绝大部分ps的需求。因此在这里记录一下基本配置流程。
clink和clink-flex-prompt都可以使用scoop在Windows中完成安装。其中clink的大致效果就是在启动cmd的时候进行注入,来实现一些额外功能的扩展。clink-flex-prompt提供的功能则是类似oh-my-zsh的prompt自定义,让交互界面不至于太苍白
1 scoop install clink clink-flex-prompt
这两个组件都是在scoop默认的main仓库就有,不需要添加额外的bucket就能直接安装。
在使用scoop安装了clink之后,还需要使用
指令来实现每次启动cmd之前都自动启用clink,也可以使用clink inject来在当前的cmd当中暂时体验一下clink的效果
依据Clink官方文档 中的提及,原本是会有一个Use enhanced default settings的选项来默认实现一些自动填充或快捷键的功能。但在使用scoop安装clink的情况下,至少可以发现自动显示suggestions补全的功能是没有被配置好的。
对于autosuggest的功能,只需要执行下面的指令就可以实现
1 clink set autosuggest.enable true
类似zsh有一个.zshrc,对于clink来说也有一个.inputrc的文件用于初始化clink的配置文件。
使用CMD输入下面的指令来在Windows的用户目录创建inputrc
1 notepad %userprofile% \.inputrc
创建好了以后可以在其中粘贴以下内容来实现一些基本的功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 # Some common Readline config settings.set colored-stats on # Turn on completion colors.set colored-completion-prefix on # Color the typed completion prefix.in Clink.if clinkset search-ignore-case on # Case insensitive history searches.set completion-auto-query-items on # Prompt before showing completions if they'll exceed half the screen.
对于具体inputrc的配置写法可以看这里:Init File
使用scoop安装了flex-prompt以后的使用方式也很简单。只需要在cmd里面执行flexprompt configure以后,就可以像p10k那样来自定义一个自己需要的,较为美观的终端提示了。这一块都是有可视化交互的,就不做过多的赘述。
平时写代码的时候因为也主要是用Linux系统,对ls和rm这种指令已经敲出肌肉记忆了。Powershell里面对这些指令做了兼容,因此用的时候没有什么额外的感觉,但是切换到cmd的时候就会发现这些指令都不一样了,dir和del一类的指令用的很不顺手。这个时候就有两种解决方法。一种方法算是曲线救国,通过调用git-bash里面提供的工具来实现类似原生Linux的指令,这也是比较推荐的一种方式。
在Windows中安装好了Git之后,往往都会有一个git-bash,而我们则可以通过git-bash来实现一些本来在Linux才能执行的指令。而之所以能达到这种效果,是因为Git在安装好了以后在安装目录下有一个/usr/bin的文件夹,里面已经预先放好了可以使用的类似Linux中的一些基本指令,诸如ls和cat这种常用工具都已经有了。因此我们只需要在系统的环境变量中,将<Git的安装路径>\usr\bin添加到PATH中即可。
比如我是使用scoop安装了git,因此我的git安装路径如下:
1 C:\Users \Halc \scoop \apps \git \current \usr \bin
然后我就只需要在环境变量中把这个路径添加到PATH中,我就可以使用我需要的基础工具了:
cmd脚本预先配置好alias还有一种方式是创建alias,以替代原生cmd的一些指令。这种方法是我最先使用的方法,后面发现了git-bash中的工具是需要额外配置环境变量以后就没有使用这种方法了。
在Windows上创建alias的方法是使用doskey来执行创建,clink则支持在启动的时候自动执行一个cmd脚本,来实现doskey的读入。为此clink默认会从以下路径来寻找clink_start.cmd文件,用以初始化cmd控制台
Windows XP: C:\Documents and Settings\<username>\Local Settings\Application Data\clink Windows Vista以及更高的版本:C:\Users\<username>\AppData\Local\clink 如果需要修改clink_start.cmd的位置,可以参考这部分文档:File Locations
在这里我的操作系统目前是Windows 10,因此我只需要在C:\Users\<username>\AppData\Local\clink目录下创建clink_start.cmd文件,并写入以下内容
1 2 3 4 5 6 @echo off
然后保存以后,就会在下一次启动cmd之前执行这些doskey指令,来实现alias的效果了。
最后的最后,只需要在Windows Terminal里面设置cmd为默认的应用,就可以实现每次启动wt的时候,都是秒开cmd的效果了,再也不用每次都等powershell启动才能输入指令了。
使用clink优化cmd
https://halc.top/p/82bd449c
博客在允许 JavaScript 运行的环境下浏览效果更佳
基础算法(一) - Halcyon Zone
题目链接:785. 快速排序 - AcWing题库
快排的主要思想是基于分治
对于一整串数组,首先找到一个值作为分界点。分界点的取值有三种取值方法:
让分界点(设为x)前面的区间部分全都是小于等于x的值,数组后面的部分则都是大于等于x的部分。
再对区间的左和右分别进行排序,只要两侧都成功排序那么整个区间就完成了排序。
该问题在处理的过程中主要的操作就是调整区间。并且最后的效果是让区间处于了两种互斥的不同状态。因此可以用双指针的做法,同时从前和末端向中间进行扫描,当他们一方扫描到需要进行交换的异端分子的时候,就等待另一端也扫描出同样的异端分子。当双方都扫描到对方的异端分子的时候,只需要将这两个异端分子同时交换,当两个指针相遇的时候,也就是处理好了所有异端分子的时候。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void quick_sort (int q[], int l, int r) if (l >= r)return ;int x = q[(l + r) / 2 ], i = l - 1 , j = r + 1 ;while (i < j) {do while (q[i] < x);do while (q[j] > x);if (i < j)swap (q[i], q[j]);quick_sort (q, l, j), quick_sort (q, j + 1 , r);
题目链接:786. 第k个数 - AcWing题库
分界点的选取和快排相同。不同的是由于我们这里只需要第k小的数,因此在此时对划分出来的区间长度进行判断。如果k的大小小于左区间长度l,那么说明k在左区间,继续从左区间寻找第k小的数。如果k的大小大于l,说明k在右区间,在右区间寻找第(k - l)小的数。
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int k_sort (int l, int r, int k) if (l >= r)return q[l];int x = q[(l + r) >> 1 ], i = l - 1 , j = r + 1 ;while (i < j) {do while (q[i] < x);do while (q[j] > x);if (i < j)swap (q[i], q[j]);int sl = j - l + 1 ;if (k <= sl)return k_sort (l, j, k);else return k_sort (j + 1 , r, k - sl);
题目链接:787. 归并排序 - AcWing题库
确定分界点:mid = (l + r) / 2 分别递归排序左区间和右区间 将两个数组合并 归并排序的主要思路就是将原本一个大数组,使用分治的思想,从单个数字的小数组进行不断的归并,最后获得的就是一个有序的新数组。因此主要的操作也就是在合并的这个操作上。
我们需要合并的数组有两个,因此这部分只需要用两个数组分别指向这两个数组的开头。然后再创建一个临时数组用于存放归并的结果。归并的过程中只需要每次都将两个指针中最小的那个输入加入临时数组中,然后将存入的指针后移,直到两个数组中其中一个被归并完毕,再将另外一个数组后面所有的结果合入答案的临时数组,最后将临时数组的结果写入原数组中即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void merge_sort (int q[], int l, int r) if (l >= r)return ;int mid = (l + r) >> 1 ;merge_sort (q, l, mid), merge_sort (q, mid + 1 , r);int merged = 0 , i = l, j = mid + 1 ;while (i <= mid && j <= r) {if (q[i] <= q[j]) {else {while (i <= mid) {while (j <= r) {for (i = l, j = 0 ; i <= r; i++, j++) {
题目链接:788. 逆序对的数量 - AcWing题库
逆序对:5 2 2 1 4,只要前面一个数比后面一个数字大,即为一个逆序对,因此有[5, 2], [5, 2], [2, 1], [5, 1], [5, 4]。这五个逆序对
首先,这个问题可以在对一个区间对半切割以后分为三种情况
在左区间中存在两个数字是逆序对 在右区间中存在两个数字是逆序对 在中间的两个黄色中,左区间存在一个数字是右区间的逆序对 其次,在这里引入归并排序的思想。在归并排序中,对于整个区间的排序本质上是对于最小区间(两个数字)之间的大小比较和扶正,最后扩展为整个区间的大小比较和扶正(分治)。带入到这个问题中,其实就是首先视 第三种情况 为最小的情况,然后最后的所有结果其实都是第三种情况的总和,所谓的第一种情况和第二种情况将会在最小区间的过程中被直接统计进入结果当中,也就是说我们只需要求出所有第三种情况逆序对的数量再加起来就是最后答案。
目前我们只考虑黄色的情况,因此对于一个区间,我们可以分成p和q两个部分来考虑。假设在p和q上有符合归并排序的两个指针i和j,且当前的情况符合了逆序对的p[i] > q[j]的定义。此时我们可以很容易就知道从i到mid这整个区间的数字都是大于q[j]的,而这个区间内数字的数量为mid - i + 1。通过这个规律,我们就可以知道如果我们想要统计所有的黄色情况中逆序对的数量,我们只需要将所有符合p[i] > q[j]情况的mid - i + 1数量加起来,就是最后答案。
代码实现:
关于计算逆序对的数量问题,假设总共有n个数据,由于每两个数据是一组,从n和n-1可以为一组的情况下来考虑,最后总共可以有(n(n - 1))/2大小的答案,如果数据集到达了类似100000量级的时候,最后答案会超过int的范围,因此有可能需要使用long long
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 const int N = 100010 ;int tmp[N], q[N], n;long long count_pair (int l, int r) if (l >= r)return 0 ;int mid = (l + r) >> 1 ;long long res = merge_sort (l, mid) + merge_sort (mid + 1 , r);int merged = 0 , i = l, j = mid + 1 ;while (i <= mid && j <= r) {if (q[i] <= q[j]) {else {1 ;while (i <= mid) {while (j <= r) {for (i = l, j = 0 ; i <= r; i++, j++) {return res;
二分算法的本质为在一个区间中,存在一个位置使得区间的性质发生了变化,进而来寻找这个变化的点。
以上面这个图为例,对于红色区间和绿色区间,假设他们有不同的性质,且一个以A作为分界点,一个以B作为分界点。那么在使用二分的时候就有两种考虑
在分类之前,首先对于所有的二分情况都有一个check()函数,用于判断某个点是否符合某个状态。在这里我们假设为某个点是否符合某个颜色(红/绿)区间的范围内
如果我们需要使用二分法来取得A点的位置,那么假设我们先设了中点mid=(l + r)/2,那么就有两种情况。第一种情况是mid处于红色范围内,那么我们便很容易可以知道点A一定在mid到r之间
此时我们只需要有新的l = mid,然后从l到r中再次进行二分,直到l和r不为l < r的关系即可
和上图相反,如果我们是mid处于了绿色范围中,那么我们首先可以知道的是,mid这个点自身是不符合红色区间的范围的。因此我们也只需要有新的r = mid - 1即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 int bsearch_left (int l, int r) while (l < r) {int mid = (l + r + 1 ) >> 1 ;if (check (mid)) {else {1 ;return l;
绿色区间和红色区间主要思路完全相同,只有区间在移动边界的时候条件不同。当需要右移区间的时候,有l = mid + 1,而区间如果要左移,只需要r = mid即可。因为这里这里不存在mid当区间长度为2的时候,如果右移区间会死循环的问题,因此mid直接取(l + r) >> 1即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 int binary_search (int l, int r) while (l < r) {int mid = (l + r) >> 1 ;if (check (mid)) {else {1 ;return l;
题目链接:789. 数的范围 - AcWing题库
首先对于二分的题目,首先找出区分***红色区间***和***绿色区间*的check()函数。在这个题目中,主要目的是找到针对某个数字target,求出在数组中target最小的区间边界和最大的区间边界。因此可以通过 大于等于target和 小于等于target**来写出两个二分的函数,分别用于寻找左边界和右边界的位置
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int bsearch_left (int l, int r, int value) while (l < r) {int mid = (l + r) >> 1 ;if (numbers[mid] >= value) {else {1 ;return l;int bsearch_right (int l, int r, int value) while (l < r) {int mid = (l + r + 1 ) >> 1 ;if (numbers[mid] <= value) {else {1 ;return l;
题目链接:791. 高精度加法 - AcWing题库
高精度加法本质就是以字符串将数字读入以后,代码模拟手动计算十进制的过程,大于十就进一位。
模板实现:
这里一定要注意A[i]或者B[i]是否为数字,如果是字符的话还需要进行- '0'来让结果变成数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<int > add (const vector<int > &A, const vector<int > &B) {int > C;int t = 0 ; for (int i = 0 ; i < A.size () || i < B.size (); i++) {if (i < A.size ())if (i < B.size ())push_back (t % 10 );10 ;if (t)push_back (1 );return C;
题目链接:792. 高精度减法 - AcWing题库
高精度减法在实现之前,首先要确定被减项比减去的值要大,如果小的话则要提前分类讨论输出一个负号。
判断大小的一个简单实现:
1 2 3 4 5 6 7 8 9 10 11 bool operator >(const vector<int > &rhs, const vector<int > &lhs) {if (rhs.size () != lhs.size ())return rhs.size () > lhs.size ();for (int i = rhs.size () - 1 ; i >= 0 ; i--) {if (rhs[i] != lhs[i]) {return rhs[i] > lhs[i];return false ;
对于减法的模拟流程,和加法主要的不同就是借位的操作。借位主要体现在计算第i位的A[i]和B[i]的运算的时候,如果有A[i] - B[i]结果是负数的话,那么A[i]就需要向A[i + 1]进行借位。这个时候我们只需要单独使用一个变量t,如果当前运算结果为负数需要借位了则让t为1,并且在每次运算前让A[i]减去t来实现借位的操作。
同时在执行完了减法的逻辑之后,由于减法和加法不同,可能会出现"0001"这种数字,我们还需要将所有除了最后一位(因为答案可能为"0")的所有0给去掉。因为通过vector存储的数字是倒序,也就是说"0001"在数组里面是[1, 0, 0, 0]。因此我们只需要每次都把答案的末尾给剔除即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 vector<int > sub (const vector<int > &A, const vector<int > &B) {int > ans;for (int i = 0 , t = 0 ; i < A.size (); i++) {if (i < B.size ())push_back ((t + 10 ) % 10 );if (t < 0 ) {1 ;else {0 ;while (ans.size () > 1 && ans.back () == 0 )pop_back ();return ans;
题目链接:793. 高精度乘法 - AcWing题库
高精度乘法的主要思路和高精度加法差不多,这类题目通常为一个大整数乘以一个小整数。对于这种情况下的乘法,我们只需要先将大整数和之前一样序列化成一个vector<int>的变量,然后和加法一样让容器每一位都和小整数相乘,大于10的部分留给下一位用于进位即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vector<int > mul (const vector<int > &A, int b) {if (b == 0 ) {return {0 };int > ans;for (int i = 0 , t = 0 ; i < A.size () || t; i++) {if (i < A.size ())push_back (t % 10 );10 ;return ans;
题目链接:794. 高精度除法 - AcWing题库
高精度除法的题目一般形式为一个大数除以一个小数。此时假设大数是123456789,小数是11。这种情况下按照正常计算逻辑大致如下:
由于在加减乘法中,我们都是将数字以[9, 8, 7, 6, 5, 4, 3, 2, 1]的顺序存储的,因此我们在计算除法的时候需要从A[A.size() - 1]的位置开始正常除法的计算逻辑,直到A[0]。其中在每次除的过程中,假设经过上次运算(默认的r = 0)的r是r',那么在下一次计算的时候用于计算的余数则是r = r' + A[i],然后只需要将除数放入ans的数组中,然后余数继续留给下一次计算即可。
模板实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<int > div (const vector<int > &A, int diver, int &reminder) {int > ans;0 ;for (int i = A.size () - 1 ; i >= 0 ; i--) {10 + A[i];push_back (reminder / diver);reverse (ans.begin (), ans.end ());while (ans.size () > 1 && ans.back () == 0 ) {pop_back ();return ans;
基础算法(一)
https://halc.top/p/83fa91fc
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux系统中waitpid函数的使用实例 - Halcyon Zone
在写完OSTEP第五章课后习题之后,通过第八题的答案记录一下自己目前对waitpid()的尝试结果,目前的尝试仅限于进程执行的阻塞和等待,轮询和非阻塞的状态暂时没有遇到,日后补充。
waitpid()不能用于子进程等待更早的另外一个子进程,如果尝试运行则会返回-1。(在父进程中则等待并返回子进程对应的pid)
这里举例说明,以下为一个不包含任何waitpid()的原始代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int main () int rc_1 = fork(); if (rc_1 == 0 )exit (0 );int rc_2 = fork();if (rc_2 == 0 )exit (0 )return 0 ;
该代码通过waitpid()函数可以实现在rc_1和rc_2都执行完毕之后,再执行主进程的内容,修改如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int main () int rc_1 = fork();int rc_2 = fork();waitpid (rc_1, NULL , 0 ); waitpid (rc_2, NULL , 0 ); return 0 ;
但是在子进程中调用waitpid()是不能做到让rc_2等待rc_1的。参考:stackoverflow
比如修改rc_2的代码如下
1 2 3 4 5 6 int rc_2 = fork();if (rc_2 == 0 )int wr = waitpid (rc_1, NULL , 0 );exit (0 )
通过以上的代码并不能让rc_2等待rc_1,如果尝试输出wr会得到wr == -1(在父进程中则应该是等待进程的pid)
Linux系统中waitpid函数的使用实例
https://halc.top/p/840f43e7
博客在允许 JavaScript 运行的环境下浏览效果更佳
Samba使用说明 - Halcyon Zone
本文最后更新于:2024年1月24日 上午
更新软件
1 2 3 sudo apt-gets upgrade
安装samba服务器
1 sudo apt-get install samba samba-common -y
创建Samba共享文件夹,如共享已存在文件夹则可忽略
按需设置文件夹的访问权限
1 sudo chmod 777 /mnt/Files
创建名为[username]的Samba用户
1 sudo smbpasswd -a [username]
创建或修改Samba服务端配置文件
1 sudo vi /etc/samba/smb.conf
在配置文件最后添加类似以下模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [shareFolderName]# 是否能浏览 # 路径 # 是否以root操作路径内的文件 # 是否公开 #
关闭Ubuntu 防火墙
1 2 sudo ufw disable
重启Samba服务器
1 sudo service smbd restart
安装完毕,在Windows+R下连接
按Windows+R,然后输入"\\IP地址"检查是否能连接
安装必要的软件包(如果尚未安装):
1 sudo apt-get install cifs-utils
创建一个本地挂载点(如果尚不存在):
1 sudo mkdir -p /root/samba
创建凭证文件(如果您尚未创建): 为了安全起见,最好使用一个凭证文件而不是直接在fstab中存储用户名和密码。创建一个文件(例如/root/.smbcredentials),并添加您的用户名和密码:
1 2 username = usernamepassword = password
然后修改该文件的权限:
1 sudo chmod 600 /root/.smbcredentials
编辑/etc/fstab文件: 打开/etc/fstab文件进行编辑:
在文件的末尾添加以下行:
1 // path/to/ smb /root/ samba cifs credentials=/root/ .smbcredentials,iocharset=utf8 0 0
这里,iocharset=utf8确保了正确的字符编码,特别是对于非英文文件名。
挂载测试:可以通过以下命令手动挂载:
Samba使用说明
https://halc.top/p/87299c69
博客在允许 JavaScript 运行的环境下浏览效果更佳
Windows字体切换的两种方法 - Halcyon Zone
Tatsu-syo/noMeiryoUI 如何更换win10系统的字体 noMeiryoUI进行修改(推荐)在网站上找到自己喜欢的字体,通常为ttf、otf或fnt等文件。 在noMeiryoUI的repo中下载该工具:Tatsu-syo/noMeiryoUI 解压后启动其中的noMeiryoUI.exe程序 选择自己想要的字体并更改,应用的时候可能会较为卡顿,耐心等待生效即可。 该方法存在一定风险,在替换Windows原本字体之前,请务必备份
下载自己想要用于替换的日用字体,并根据类型分别命名为msyh.ttc、msyhbd.ttc和msyhl.ttc
在C盘根目录新建文件夹TempFonts用于临时存放需要替换的字体
打开Windows的设置,找到"更新与安全"->“恢复”->“高级启动”,在高级启动之后,选择"高级选项",选择"命令提示符",选择自己的帐号登入
输入以下指令,将C盘下TempFonts文件夹内的字体替换为系统默认字体。
1 xcopy C:\TempFonts\* C:\Windows\Fonts\
回车后按下A来全部覆盖替换(一定要备份好之前的系统文件再执行这一步
输入exit回车后进入Windows系统,即可看到自己的字体应用生效,同理,如果想要将字体恢复,只需要用备份的字体文件进行覆盖操作即可。
Windows字体切换的两种方法
https://halc.top/p/87ec6922
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:进程的简单使用 - Halcyon Zone
子进程和父进程的变量x的值内容相互独立。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <fcntl.h> #include <sys/wait.h> int main (int argc, char *argv[]) int x = 100 ;int rc = fork();if (rc < 0 )printf ("fork failed\n" );exit (1 );else if (rc == 0 )printf ("Child: %d\n" , x);100 ;printf ("Child + 100: %d\n" , x);else int wc = wait (NULL );printf ("Parent: %d\n" , x);100 ;printf ("Parent + 100: %d\n" , x);printf ("Final Address: %d\n" , x);return 0 ;
测试结果如下:
1 2 3 4 5 6 Child: 100
同时打开文件p4.output并且分别写入Child process和Parent Process,可以正常并发写入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdio.h> # include <stdlib.h> # include <unistd.h> # include <fcntl.h> int main () close (STDOUT_FILENO);open ("./p4.output" , O_CREAT | O_WRONLY | O_TRUNC, 0700 );int rc = fork();if (rc < 0 )fprintf (stderr, "fork failed\n" );exit (1 );else if (rc == 0 )printf ("Child process\n" );else printf ("Parent process\n" );return 0 ;
结果(p4.output文件)
1 2 Child process
或(并发输出的先后顺序不同)
1 2 Parent process
题目要求的是在不适用wait()函数下实现子进程和父进程的先后,通过vfork()函数可以实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # include <stdio.h> # include <stdlib.h> # include <unistd.h> # include <fcntl.h> int main () close (STDOUT_FILENO);open ("./p4.output" , O_CREAT | O_WRONLY | O_TRUNC, 0700 );int rc = vfork ();if (rc < 0 )fprintf (stderr, "fork failed\n" );exit (1 );else if (rc == 0 )printf ("Child process\n" );else printf ("Parent process\n" );return 0 ;
数据结果可以参考题目2的第一个情况。不过这里插入Stack Overflow 上书原作者的话作为备注:
Without calling wait() is hard, and not really the main point. What you did – learning about signals on your own – is a good sign, showing you will seek out deeper knowledge. Good for you!
Later, you’ll be able to use a shared memory segment, and either condition variables or semaphores, to solve this problem.
针对不同的调用和变种,写了一篇详细的博客进行解析:区分不同exec()形式
在父进程使用wait(),等待子进程完成后,wait()会返回子进程的pid
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int main () int rc = fork();if (rc < 0 )"fork failed" << endl;exit (1 );else if (rc == 0 )printf ("I am child process %d\n" , getpid ());else int ws = wait (NULL );printf ("I am parent process %d\n" , getpid ());printf ("Return Value of wait() is %d\n" , ws);return 0 ;
运行结果
1 2 3 I am child process 4878wait () is 4878
在子进程中使用wait()则会返回-1,并且在失败后依旧会执行当前子进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int main () int rc = fork();if (rc < 0 )"fork failed" << endl;exit (1 );else if (rc == 0 )int fake_ws = wait (NULL );printf ("I am child process %d\n" , getpid ());printf ("fake_ws = %d\n" , fake_ws);printf ("Test\n" );else int ws = wait (NULL );printf ("I am parent process %d\n" , getpid ());printf ("Return Value of wait() is %d\n" , ws);return 0 ;
运行结果
1 2 3 4 5 I am child process 5011wait () is 5011
针对waitpid()的使用,总结了笔记:waitpid()调用
子进程中关闭标准输出,父进程输出子进程和本身pid
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int main () int rc = fork();if (rc < 0 )printf ("fork failed\n" );exit (1 );else if (rc == 0 )close (STDOUT_FILENO);printf ("Hello from child\n" );else int ws = wait (NULL );printf ("Hello from parent, child exited with status %d\n" , ws);return 0 ;
运行结果,子进程中的输出被关闭,只有父进程输出。
1 Hello from parent, child exited with status 1326
通过pipe()管道进行传输数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 int main () int fd[2 ]; int rc_pipe = pipe (fd); char msg[] = "Hello_World!" ; char buff[100 ]; int rc_1 = fork(); if (rc_1 == 0 )for (int i = 0 ; i < 5 ; i++)printf ("Child Process 1: %d\n" , i);sleep (1 );close (fd[0 ]); dup2 (fd[1 ], STDOUT_FILENO); printf ("%s" , msg); close (fd[1 ]); exit (0 ); int rc_2 = fork();if (rc_2 == 0 )for (int i = 0 ; i < 3 ; i++)printf ("Child Process 2: %d\n" , i);sleep (1 );close (fd[1 ]); dup2 (fd[0 ], STDIN_FILENO); scanf ("%s" , buff); close (fd[0 ]); printf ("%s" , buff); exit (0 ); return 0 ;
输出结果
1 2 3 4 5 6 7 8 9 Child Process 1: 0
OSTEP:进程的简单使用
https://halc.top/p/897b63ef
博客在允许 JavaScript 运行的环境下浏览效果更佳
qBittorrent与jellyfin搭建自动追番引导 - Halcyon Zone
Docker Engine: 20.10.15 Ubuntu: 20.04.4 LTS X86平台 部署使用的是老电脑上的Ubuntu 20.04.4 LTS,为了便于备份配置以及轻量上手,采用了Docker-Compose的一件式部署方式,该方案主要倾向解决追番问题,目前基本解决刮削问题。
请在百度等搜索引擎直接搜索对应自己平台的"Docker 安装 教程"
推荐的qBittorrent+Jellyfin部署配置文件如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 version: '3' services: jellyfin: image: nyanmisaka/jellyfin:latest restart: unless-stopped container_name: jellyfin volumes: - $PWD/conf/jellyfin:/config - $PWD/cache:/cache - $PWD/downloads/media:/media ports: - "8096:8096" environment: - TZ=Asia/Shanghai - UID=1000 - GID=1000 devices: - /dev/dri:/dev/dri qbittorrent: image: johngong/qbittorrent:latest restart: unless-stopped hostname: qbittorrent container_name: qbittorrent volumes: - $PWD/conf/qbit:/config - $PWD/downloads:/Downloads network_mode: "host" environment: - UID=0 - GID=0 - TRACKERSAUTO=YES - WEBUIPORT=8995 - TRACKERS_LIST_URL=https://cdn.jsdelivr.net/gh/ngosang/trackerslist@master/trackers_all.txt - UMASK=022
如果出现了qBittorrent配置有可能随着更新有变化,如果使用过程中出现问题,或需要自己额外配置,具体参考johngong/qbittorrent 内的介绍进行修改即可。
下载 EpisodeReName.zip 并且解压在qbittorrent挂载的Downloads目录下,用于下文中设置自动改名
在诸如蜜柑计划 的网站,找到自己想要看的番剧或电视剧对应的RSS链接
在qbittorrent当中添加RSS规则,示例如下
添加完毕RSS规则以后,则需要设置下载路径。由于Jellyfin刮削为识别文件夹名字进行刮削,因此这里的命名必须要符合规范来提高成功率
在qbittorrent设置内开启自动下载,后续只要识别到了RSS更新,就能自动下载到目标文件夹下
自动修改剧集名字使用的为Episode-ReName 工具
下载并将Episode-ReName放于Docker挂载后的downloads目录下
配置下载完毕自动运行EpisodeRename来对番剧重命名
配置参数如下
1 2 3 /Downloads/EpisodeReName "%D/%N" 10
由于重命名后的文件无法直接继续做种,因此在qbittorrent内同样要设置自动取消做种上传
秉承BT分享的精神,或者使用PT站的朋友可以学习如何设置硬链接等方式对文件实现共享,本文不做解释
元数据刮削主要用的是TheMovieDb, AniDB, AniSearch和AniList这几个插件,不过依旧存在抓取的时候抓到英文介绍为多的问题,不过暂且算是能使用,海报和宣传图也基本上都有,日常使用没有很大问题
qBittorrent与jellyfin搭建自动追番引导
https://halc.top/p/8d2011c6
博客在允许 JavaScript 运行的环境下浏览效果更佳
总结: 2022年1月 - Halcyon Zone
当我回顾这个月的所做所为时,我发现自己虽然有些困难和拖延,但还是完成了一些有意义的事情。学习了 Rust 的初级语法。虽然考完试后完全松懈没有进度,但我对 Rust 的学习充满了信心,希望在未来能够深入学习。
另外,也把家里的 Homelab 更换迁移成了 ESXi 基础的虚拟机,并在此之上将之前服务器上的服务器重新分开部署,每次折腾家里的HomeLab总能让我感觉成就感很足。此外,我还尝试了自己投稿文章,虽然初次尝试,但在机核的反馈中感觉有希望继续写下去。
虽然说是说这个月没有为本来的计划和目标努力,但还算是折腾了一些有意思的东西:
学习了Rust的初级语法,在期末考试前完成了Microsoft Learning上入门Rust 的40%内容,考完试后完全松懈没有进度。 把家里的Homelab更换迁移成了EXSi基础的虚拟机,并在此之上将之前服务器上的服务器重新分开部署 第一次尝试自己投稿文章 ,在机核的反馈感觉有希望继续写下去 在之外就是通宵熬夜生死存亡的期末考试复习了。
学习一下Python对于网页抓包数据的一些模拟,和对于Appium的使用 完成Rust整个的入门课程 CS144的6个lab至少完成2个(考虑拖延的情况下),有时间充裕就完成3-4个 力扣每天题库非困难题打卡 完成家里面Homelab关于流媒体服务器的部署 通过Python+Appium的组合,看看能不能全自动化学校企业微信打卡内容 找2-3部电影看完,内容随意 开学前每天锻炼半小时,睡眠作息开始调整为十一点睡觉,六点到七点起床 整个流程下来还是感觉和记流水帐一样吧,不过这样记录了以后感觉负罪感也强了一些,也算是最自己的一个监督。希望能离年初的目标越来越近。
总结: 2022年1月
https://halc.top/p/9130a701
博客在允许 JavaScript 运行的环境下浏览效果更佳
Ubuntu下创建拥有sudo权限的用户 - Halcyon Zone
本文最后更新于:2022年7月2日 下午
添加用户
添加sudo权限
1 2 # 表示将username追加到sudo权限组当中
检查是否拥有sudo权限
1 2 # 更新ubuntu软件源
Ubuntu下创建拥有sudo权限的用户
https://halc.top/p/9232cf7b
博客在允许 JavaScript 运行的环境下浏览效果更佳
Docker的安装和镜像设置 - Halcyon Zone
本文最后更新于:2022年6月29日 上午
参考资料:Docker-从入门到实践
在挂载网易云音乐灰色代理的时候终于还是发现了screen后台运行的坏处,经常会出现不小心重启以后忘记开启服务的情况,由于之前一直听说过docker容器,并且灰色代理有现成的docker容器可以使用,在简单查询和操作了一下以后记录一下docker启动网易云音乐并且进行网易云音乐代理的实战
(可选) 通过一键脚本进行安装,安装完成后可跳过以下所有步骤
1 2 curl -fsSL get.docker.com -o get-docker.sh
如果要安装测试版的Docker,则用以下脚本
1 2 curl -fsSL test.docker.com -o get-docker.sh
使用apt进行安装
1 2 3 4 5 6 7 8 sudo apt-get update
替换国内软件源
1 2 3 4 5 curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgecho \"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
安装Docker
1 2 sudo apt update
启动Docker
1 2 sudo systemctl enable docker
检测是否已经设置镜像
请首先执行以下命令,查看是否在 docker.service 文件中配置过镜像地址。
1 $ systemctl cat docker | grep '\-\-registry\-mirror'
如果该命令有输出,那么请执行 $ systemctl cat docker 查看 ExecStart= 出现的位置,修改对应的文件内容去掉 --registry-mirror 参数及其值,并按接下来的步骤进行配置。
设置镜像
创建并编辑/etc/docker/daemon.json
写入以下内容
1 2 3 4 5 6 {
重启服务
1 2 sudo systemctl daemon-reload
检测是否正常
docker run --rm hello-world
通过检查返回信息检查是否成功安装并且部署Docker环境
Docker的安装和镜像设置
https://halc.top/p/92f7b8a
博客在允许 JavaScript 运行的环境下浏览效果更佳
程序main函数入口arg参数的用处 - Halcyon Zone
今天在看一些代码的时候偶然看到自己刚开始学C的时候,main()函数中都会有一个(int argc,char* argv[],char **env)的传参。但是到现在依旧不理解这几个参数的意义和它们代表的作用,在稍微查阅了一下以后,浅显的总结一下。
如果要使用argc和argv的话(char **env暂时没遇到,不做记录),只需要在main函数当中添加这两个参数即可,大致参考写法类似如下:
1 2 3 4 5 int main (int argc, char ** argv) return 0 ;
argc是一个整形的参数,代表了程序运行的时候发送给main()函数的参数个数。
argv则是一个字符串的数组,用来指向存放对应参数的字符串。
其中,argv[]数组中的元素有argc个,并且有:
argv[0]包含的是程序运行的路径名字argv[1]包含的是程序命名后的第一个字符串argv[2]包含的是程序命名后的第二个字符串… argv[argc]为NULL为让以上解释更加形象,这里引入示例代码进行解释:
1 2 3 4 5 6 7 8 9 10 11 #include <iostream> using namespace std;int main (int argc, char * argv[]) for (int i = 0 ; i < argc; i++)"Argument" <<i<<" is " <<argv[i]<<endl;return 0 ;
假设代码文件存放于./b.cpp文件当中,通过编译器编译后的可执行文件为b。在执行如下指令:
返回的内容为:
在执行如下指令:
1 ./b oneString twoString threeString
返回的内容为:
1 2 3 4 Argument0 is ./b
对应了上文中的argc的元素个数和argv的字符串内容,即./b后面的oneString、twoString和threeString。
程序main函数入口arg参数的用处
https://halc.top/p/98326a13
博客在允许 JavaScript 运行的环境下浏览效果更佳
Openwrt系统内配置Frpc自启动 - Halcyon Zone
Frpc在Openwrt上的客户端多多少少有点问题,为了方便自己使用,在这里记录一下如果用命令行启动和编辑Frpc的流程
首先,在 fatedier/frp 中下载最新版的frp打包程序,以下以0.35.1版本为例
1 2 3 wget https://github.com/fatedier/frp/releases/download/v0.35.1/frp_0.35.1_linux_amd64.tar.gzrm frp_0.35.1_linux_amd64.tar.gz
首先切换到frp的目录下,把frpc和配置文件放于service对应的目录下
1 2 3 4 5 cd frp_0.35.1_linux_amd64mv frpc /usr/binchmod 755 /usr/bin/frpc mkdir /etc/frpmv frpc.ini /etc/frp
之后通过指令编辑frpc.ini
sudo vi /etc/frp/frpc.ini
之后,编辑/etc/init.d/frpc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #!/bin/sh /etc/rc.common "/usr/bin/frpc -c /etc/frp/frpc.ini" start_service command $PROC service_triggers "rpcd"
脚本来自OpenWRT/LEDE下开机脚本
配置文件就结束了之后只需要直接启用和启动frpc即可
1 2 /etc/init.d/frp startenable && echo on
另外由于不需要配置frps服务,可以回到上级目录并把下载的文件全部删除
1 2 cd ~rm -rf frp_0.35.1_linux_amd64
Openwrt系统内配置Frpc自启动
https://halc.top/p/99e48799
博客在允许 JavaScript 运行的环境下浏览效果更佳
Github的PAT口令的密码记录和保存方案 - Halcyon Zone
本文最后更新于:2022年3月15日 晚上
最简单的方案是讲自己的配置文件用明文保存,在文档 中查询可知道指令如下
1 git config --global credential.helper store
在设置credential.helper为全局store之后,下一次的验证会出现提示并保存,之后则会使用存在~/.git-credentials的明文帐号密码进行登入
为了更好的管理Github的Token,需要一个Git凭证助手来帮我们记忆用户名和对应的PAT,以下为Git-Credential-Manager-Core引导
安装Lateset Release 的GCM,并初始化设置
1 2 sudo dpkg -i <path-to-package>
在Linux上使用GCM需要额外设置credential.credentialStore,其中包含的设置方法如下:
该方法需要系统有GUI显示功能
1 2 3 export GCM_CREDENTIAL_STORE=secretservice
这个办法通过libsecret库来和Secret Service进行交互,所有的凭证都存储在“collections”当中。如果要查看的话,可以通过secret-tool或seahorse来进行查看。注:在请求用户帐号信息的时候会通过GUI来进行交互。
1 2 3 export GCM_CREDENTIAL_STORE=cache
这种方法保存的密码不会以可长期读取的文件形式存在硬盘上,如果是需要链接一些临时性的服务可以用这个方法。默认来说git credential-cache会储凭证900s,可以通过如下指令修改:
1 2 3 export GCM_CREDENTIAL_CACHE_OPTIONS="--timeout 300" "--timeout 300"
这办法不安全
1 2 3 export GCM_CREDENTIAL_STORE=plaintext
这种办法保存的密码默认会存在~/.gcm/store目录下,目录可通过GCM_PLAINTEXT_STORE_PATH环境变量来进行修改,如果文件不存在则会被创建新创建的文件权限为700.
这种方法需要有一对GPG密钥
1 2 3 export GCM_CREDENTIAL_STORE=gpg
这种办法主要使用了pass 工具,默认情况下文件会保存在~/.password-store文件下,该目录可以通PASSWORD_STORE_DIR来进行修改。在使用这种办法进行凭证管理之前,首先需要通过一对GPG密钥对pass进行初始化操作。
这里的<gpg-id>指的是当前使用gpg密钥对的用户的系统id。通过以下指令可以创建一个自己的gpg密钥对:
Github的PAT口令的密码记录和保存方案
https://halc.top/p/a126ef4d
博客在允许 JavaScript 运行的环境下浏览效果更佳
Nginx配置CDN回源重定向导致的无法访问问题 - Halcyon Zone
在部署好了CloudReve和Nginx以后,想通过Cloudflare的免费的CDN服务来达到一个节省流量的目的,但是在直接开启CDN代理之后发现原本的网站一直出现Network Error的问题,在此记录一下解决方案。
首先记录一下现状:
CloudReve部署在自己家的服务器上,通过ZeroTier和香港的服务器虚拟局域网相连,并且通过Nginx反代 Nginx配置好了SSL证书,开启了强制使用HTTPS链接 测试的现状:
在开启强制HTTPS链接的时候使用CDN加速,连接CloudReve的时候会出现Network Error,网页控制台报错重定向次数过多。 关闭强制HTTPS链接使用CDN加速并且通过HTTPS进行链接的时候正常。 参考了的可能有帮助的解决方案
踩坑记录:CDN开启强制https之后返回重定向次数过多的问题 由于CDN是先到香港的服务器,是https访问,然后香港的服务器到自己的网盘是http访问,根据上方参考的"踩坑记录"方案一,给家里的服务器的cloudreve加了一个ssl证书再次尝试代理,问题依旧。
同根据“踩坑记录”,在nginx的配置文件中添加以下配置
proxy_set_header X-Forwarded-Proto $scheme;
附上解释原因:
设置http头部X-Forwarded-Proto,这个头部的作用是用于识别协议(HTTP 或 HTTPS),主要针对内部访问重定向时的协议。因此,只要在反向代理时添加以上配置就好了
$scheme是nginx的内部变量,表明当前访问的协议,当前如果是https,那么转发到后台服务的时候就是https。这样问题就解决了。
但是问题依旧
之后认为问题不出在香港服务器到家中服务器,寻找其他的解决方案。
在查询和强制HTTPS有关词条的时候查询到这是CDN云加速很容易遇到的一个问题,解决方案主要有三种。
设置CDN的回源端口为443端口,让CDN回源的时候以HTTPS请求源站,这样就不会触发源站的强制跳转的逻辑了。 在CDN的控制台中设置回源设置为“跟随”(一般会有三个选项,分别是“回源”,“HTTP”和“HTTPS”。) 放弃强制跳转HTTPS,在Nginx关闭强制。 由于没有找到Cloudflare上有类似CDN控制台的地方(感觉毕竟是免费的,没有正常。不过也可能是我太菜了不知道在哪里),于是上面的三种办法都不得不作罢,只能另寻其他办法。
香港的服务器上关闭Nginx的强制https 在cloudflare的"Rules"里面添加Page Rules,设置里面添加对应的域名,然后开启始终使用HTTPS 有一说一,结果是启用了免费的CDN以后速度还是比较慢,而且多线程下载也没有缓存很多文件,后期还是试试Cloudflare Partner或者其他的项目比较好。
Nginx配置CDN回源重定向导致的无法访问问题
https://halc.top/p/a2277ea0
博客在允许 JavaScript 运行的环境下浏览效果更佳
Windows系统中校验文件哈希值 - Halcyon Zone
每次要查询一个文件的hash值的时候总要打开一个hash校验工具,觉得有些麻烦了,加上也不是所有文件都会经常需要校验,就常常并不想单独下载一个工具,查询到Windows有自带的hash校验指令,于是记录一下,以下内容摘自知乎
使用certutil
Windows从Win7开始,包含了一个CertUtil命令,可以通过这个命令来计算指定文件的杂凑值(Hash Value)
使用的指令为:
certutil -hashfile [fileName] [algorithm]
其中[algorithm]指不同的hash算法,可以取的值有:MD2、MD4、MD5、SHA1、SHA256、SHA384、SHA512 。
例子:
certutil -hashfile D:\test.txt MD5
使用Get-FileHash
Get-FileHash [fileName] -Algorithm [algorithm]
其中,支持的算法有MACTripleDES、MD5、RIPEMD160、SHA1、SHA256、SHA384、SHA512 。
显示效果:
其中,为了方便观察可以通过管道使用Format-List
Get-FileHash .\test.txt -Algorithm SHA512 | Format-List
显示效果:
Windows系统中校验文件哈希值
https://halc.top/p/a9706dff
博客在允许 JavaScript 运行的环境下浏览效果更佳
Windows下修改网络优先级广播ZeroTier进行游戏 - Halcyon Zone
经常能遇到需要和朋友联机玩一些P2P的联机游戏,但游戏服务器总是因为各种原因延迟很高或者连不上的情况。在使用诸如ZeroTier等一类软件进行组网的时候,在此给出能够让Windows提高虚拟网卡的优先级,让游戏能够在一些无法输入IP的游戏中扫描到同一虚拟局域网下用户的方法。
在谷歌搜索“创建ZeroTier网络”关键词即可找到许多对应教程,在此不多赘述
在有条件的情况下,可以自己搭建Moon中转节点来加速(非必须),教程:ZeroTier下Moon服务器的搭建
该教程以Windows10为例,其他版本的Windows可参考设置
在电脑右下角打开“网络和Internet ”选项
打开"更改适配器选项 "
打开对应ZeroTier的ID的网络属性
打开"Internet 协议版本 4 "下的"属性 "
打开属性中的“高级 ”
修改自动跃点
自动跃点的修改就笔者目前看来对日常使用影响不大,介意的可以在和好友联机结束以后重新勾选即可。并且由测试来看,只要重新连接了网络,Windows都会设置回为“自动跃点”
将优先级设置为1如果不放心的话可以设置为小一点的数字,不过也许有概率无法自动扫描局域网内其他游戏玩家。
在进行了上面的操作,并且两个用户都处于同一ZeroTier的网络下之后,直接打开游戏存档并进入,应该就能在局域网联机中自动扫描到对方。目前已经测试的游戏有:无主之地3、GTFO等,理论上所有可以使用局域网加入的游戏应该都能用相同的方法进行操作。
Windows下修改网络优先级广播ZeroTier进行游戏
https://halc.top/p/aa5ce7f4
博客在允许 JavaScript 运行的环境下浏览效果更佳
Docker指令和配置手册 - Halcyon Zone
参考链接:
CSDN-Ubuntu 18.04 DOCKER的安装 停止、删除所有的docker容器和镜像 Docker官网文档 设置用户组docker,让用户不需要sudo也可以使用docker相关命令
1 2 3 4 sudo groupadd docker$USER docker
查看当前所有在运行的Docker容器
docker ps -a
在库内搜索需要的docker容器运行
docker search [name]
获取需要的容器
docker pull [name]
停止所有的容器
docker stop $(docker ps -aq)
删除所有的容器
docker rm $(docker ps -aq)
删除所有目前没有在运行的容器
docker container prune
删除所有的镜像
docker rmi $(docker images -q)
删除所有未被使用的镜像
docker image prune
删除所有未被引用的容器,镜像和各种cache
docker system prune
重命名容器
1 docker rename [Docker的Name] [修改后的Name]
Docker在运行的过程中有许多额外设置,其中包括不同的网络结构,不同的运行模式,交互方法等,目前在这里只记录一些简单用得上的,后续如果还有比较常用的指令再进行补充添加。
docker run -d --restart=always --network host --name CloudMusic nondanee/unblockneteasemusic
docker run
运行docker容器
-d
以后台模式运行
--restart-always
每次docker如果重启了的话也总是自动运行
--network host
以host网络模式运行docker容器,而不是以默认的NAT分布
--name CloudMusic
给这个容器命名为CloudMusic
进入容器docker attach <ID>docker -it <ID> /bin/bash或者docker -it <ID> /bin/sh 通过systemctl设置docker开机自启动
systemctl enable docker.service
docker容器使用--restart=always参数启动
如果已经启动了可以通过docker update --restart=always <ID>添加参数 重启系统以后通过docker ps -a可以看到服务已经在正常运行了
用命令修改
1 docker container update --help
使用这个指令可以在不停止容器的情况下更新部分内容,比如容器的启动方式
配置文件修改
首先要停止容器,才能对容器的配置文件进行修改 配置路径为/var/lib/docker/containers/容器ID下的hostconfig.json就是配置文件 Docker指令和配置手册
https://halc.top/p/abf1d877
博客在允许 JavaScript 运行的环境下浏览效果更佳
CS144-Lab1 计算机网络:字节流重组器 - Halcyon Zone
本文最后更新于:2023年4月11日 凌晨
这个方案是采用了一个无限长的字符串cache,所有的TCP段中的部分数据先寄存在cache当中。之后通过创建一个在cache上滑动的写入位指针write_p来将能够顺序写入的内容写入_output当中,其中write_p每次滑动的距离len受限于_output还剩下的可容纳空间。
添加的私有成员:
1 2 3 4 5 6 7 8 size_t write_p;size_t end_p;
对于push_string方法的实现:
检查传入的index是否在可写入范围,如果超出可写入范围则直接退出,保证程序的鲁棒性
因为写入的数据长度不能超过capacity,因此需要将扩容的长度设置为index + data.length()和write_p + _output.remaining_capacity()中较小的那个
将传入的数据(包括可能超过范围的部分)写入cache中,同时将dirty_check中对应的位置标记为1
将cache的长度缩回到正确扩容后应该的长度,这样可以将多余的内容丢弃
检查write_p的位置上是否有数据可以被写入,如果有则通过滑动len来将内容写入_output,否则跳过
检查write_p和end_p是否相同,如果相同则代表写入结束,调用_output.end_input()
具体代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 void StreamReassembler::push_substring (const string &data, const size_t index, const bool eof) size_t extend_size = index + data.length ();if (eof) {if (extend_size > cache.length ()) {resize (extend_size);resize (extend_size);replace (index, data.length (), data);replace (index, data.length (), data.length (), '1' );if (expand_size > cache_raw_length) {resize (expand_size);resize (expand_size);if (dirty_check[write_p]) {size_t len = 0 ;size_t output_remaining = _output.remaining_capacity ();while (dirty_check[write_p + len] && len < output_remaining) {write (cache.substr (write_p, len));if (write_p == end_p) {end_input ();
对于没有统计的字符数量,直接使用一个循环进行统计即可
1 2 3 4 5 6 7 8 9 size_t StreamReassembler::unassembled_bytes () const size_t n = write_p;for (size_t i = write_p; n != cache.length () && not dirty_check[i]; i++) {return cache.length () - n;
对于判断缓冲区是否使用完毕则是
1 2 bool StreamReassembler::empty () const return _output.eof () && not unassembled_bytes (); }
使用上面这种写法的话虽然可以达到100% tests passed,并且时间也都能控制在0.5s以内,但是在复习了真实情况下的重组过程发现这个思路存在一些BUG是测试案例没有检测出来的。
以如下的test为例
1 2 3 4 5 6 7 8 9 10 {6 };execute (SubmitSegment{"defg" , 3 });execute (BytesAssembled (0 ));execute (SubmitSegment{"abc" , 0 });execute (BytesAvailable ("abcdef" ));execute (BytesAssembled (6 ));execute (SubmitSegment{"kmg" , 7 });execute (BytesAvailable ("" ));
运行后可以发现有报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Test Failure on expectation:
可以发现,本来在传入第一个defg的时候,字符g应该因为超出capacity而被抛弃,但是是将并没有,导致g停留在了index为6的位置上。读取了_output的所有内容之后,_output的窗口应该是从index为6的位置上开始准备写入,但是由于这个位置上的g在上一个窗口期中并没有被抛弃,结果导致了index为7的kmg写入的时候,连带前面存在的g一起将gkmg写入了_output的窗口当中,从而出现了以下报错。
The reassembler was expected to have 0 bytes available, but there were 4
同时对于EOF的位置判断也有类似的BUG,测试样例如下
1 2 3 4 5 6 7 8 9 10 11 {6 };execute (SubmitSegment{"defx" , 3 }.with_eof (true ));execute (BytesAssembled (0 ));execute (SubmitSegment{"abc" , 0 });execute (BytesAvailable ("abcdef" ));execute (BytesAssembled (6 ));execute (SubmitSegment{"g" , 6 });execute (BytesAvailable ("g" ));execute (NotAtEof{});
运行后得到如下结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Test Failure on expectation:
本来在第一个操作的时候作为eof的x应该是被抛弃掉并不读取的,但是在最后这个位置的eof_p还是触发了EOF判断,导致产生了不应该出现的EOF。
本质的问题就是没有丢弃掉unacceptable的字节,这里采取了一个比较省事但是很不优雅的操作,我是选择在最后扩容后重新再用resize()函数将不需要的那部分丢弃掉,来达到限制容量的目的,最后修正完毕的实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 void StreamReassembler::push_substring (const string &data, const size_t index, const bool eof) bool eof_flag = false ;size_t expand_size = index + data.length ();if (index > write_p + _output.remaining_capacity ()) {return ;if (index + data.length () <= write_p + _output.remaining_capacity ()) {true ;length ();else {remaining_capacity ();if (eof && eof_flag) {const size_t cache_raw_length = cache.length ();if (expand_size > cache_raw_length) {resize (expand_size);resize (expand_size);replace (index, data.length (), data);replace (index, data.length (), data.length (), '1' );if (expand_size > cache_raw_length) {resize (expand_size);resize (expand_size);if (dirty_check[write_p]) {size_t len = 0 ;size_t output_remaining = _output.remaining_capacity ();while (dirty_check[write_p + len] && len < output_remaining) {write (cache.substr (write_p, len));if (write_p == end_p) {end_input ();
CS144-Lab1 计算机网络:字节流重组器
https://halc.top/p/aeda2510
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux通过alternatives切换程序版本环境 - Halcyon Zone
How to install and switch between different python versions in ubuntu 16.04 在切换Java版本的时候,通过update-alternatives可以很方便的进行版本之间的切换,而在Python里面,如果用Ubuntu自己的apt包管理器同时下载了多个版本的Python的话,则需要自己手动对Python的版本进行切换设定(切换版本还有alias等方法,这里不提及)。指令如下:
在安装了多个版本的Python之后(其他语言同理),通过类似以下指令的格式添加对应的程序优先级:
1 2 sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 1
由上面设置的程序指令为python,接下来通过以下指令对python的版本进行切换:
1 sudo update-alternatives --config python
输入之后可以见到类似如下的选择:
1 2 3 4 5 6 7 8 9 There are 2 choices for the alternative python (providing /usr/bin/python).
只需要在number后面输入对应需要的优先级,即可对python的版本进行切换。
每次都会忘记是update alternatives还是alternatives-update,所以写一篇博客记录一下…自己还是太Native了。
Linux通过alternatives切换程序版本环境
https://halc.top/p/afb272ac
博客在允许 JavaScript 运行的环境下浏览效果更佳
总结:该冲了! - Halcyon Zone
又比常规的每月六号写总结晚了两天,不过索性居然已经坚持了半年每年都对自己的状态进行一个记录,回过头来看感觉还满惊讶的
上个月包括前几天比较刺激的应该就是应付期末考试和科目一了,也正是为了准备科目一所以才搁置了两天才今天动工这个月的总结,还好一个晚上的突击也算是擦边成功过了。上个月经历了期末考试的洗礼以后,整个大学计算机相关的重要考试应该都结束了。目前还不清楚大三的学习课程学校会怎么安排,不过目前来看应该是可以拥有大把的时间来自己进行一个学习的规划了。目前为止ostep的内容已经完成了大半部分,练习上还有小半部分没有跟进。近期则在跟着MIT的 计算机教育中缺失的一课 补充自己缺少和遗漏的基础知识。对于Shell的管道、重定向,Vim的使用,正则表达式的控制都有了更加完备的学习,更加体会到了散装博客相比系统知识所缺失的不足。很多细节和实例的组合都是在完整的课程中才能较好的理解和发现。
期末的时候还有考科目一的时候基本上对个人生活摆烂,完全没有控制饮食和节制的意思,体重直冲180。还好期末考试以后现在开始陆续减下来了,预计七月中旬回到160,然后再逐步看看能不能减到140甚至134)的正常体重,目前感觉较为遥远。。(主要还是懒得动png)
最近已经开始切实感受到自己身体上的一些“放肆”带来的负面影响了,作息基本上颠倒,早上会特别困而且偶尔会间歇性走神不知道自己在做什么,效率极低。家里楼上最近还貌似有将近持续一个月的持续装修,感觉也得要不得不准备找个比较好能用来看书自习的地方安静准备一下了。
完成 Missing-semester 的课程,将原来的散装知识给串起来 完成操作系统并发和文件相关的lab,并且回过头把自己写的lab进行拼装和整理,避免出现只有答案缺少内容的空虚情况 继承期末考试之前自己的意愿!减肥到160-以下 继续调整作息,目前以每天一节课的节奏来说还算不摆烂,希望能继续保持 每天花一个小时的时间出去跑跑走走锻炼下 总结:该冲了!
https://halc.top/p/afda6ca0
博客在允许 JavaScript 运行的环境下浏览效果更佳
修复WSL中env:'bash\r'的冲突问题 - Halcyon Zone
由于之前C/C++环境配置出问题,近期把WSL重装了一次,结果在配置zsh-proxy的时候出现了报错
1 /usr/bin/env: ‘bash\r’: No such file or directory
直接搜索的方案要么是直接屏蔽掉Windows的Path继承,要么是说重启下wsl就好,但都比较模棱两可
后面在查看了proxy相关的报错后,发现只有配置git的proxy时会出现这个问题,同时根据Stack Overflow上别人类似情况的提问,发现npm同样也无法使用。检查后发现是在Windows对应的Path内,git和npm本身没有.exe的后缀就能启动,而wsl内是可以执行Windows下的部分可执行文件的,因此wsl调用了基于Windows的环境变量,从而导致了换行符与wsl的linux格式不兼容。
本来想的是怎么处理屏蔽Windows的相关Path,后面发现只需要在WSL上重新安装好git和npm后重启wsl
1 2 3 wsl --shudown -t Arch
就可以解决问题了。之前在Stack Overflow上其他人能直接通过重启wsl解决问题,应该也是无意中自己已经覆盖安装过了对应的工具,然后重启才取得了效果,在这里做个记录以做备忘。
修复WSL中env:'bash\r'的冲突问题
https://halc.top/p/b3a8b5ef
博客在允许 JavaScript 运行的环境下浏览效果更佳
镜像构建:Windows Cloud Image - Halcyon Zone
Ubuntu和Debian等常见Linux系统都有官方自带cloud-init的cloud image可供下载使用,但是Windows系统在微软中心只找到了ISO镜像的下载路径。当需要在pve等常见虚拟化环境中部署Windows服务器的时候,无论是virtio的驱动,还是iso安装漫长的等待时间都是个问题,所以需要构建cloud image来方便快捷的进行部署
工具使用的是提供给OpenStack的构建工具:
构建出来的镜像可以在各种虚拟化环境中部署和运行。
一台开启了Hyper-V的Windows宿主机,用于构建镜像。 一个Windows Server的部署镜像,这里以Windows2022为例。 Windows虚拟机的virtio驱动,可以在这里 下载到最新的iso。镜像的构建本身不会污染宿主机环境,但是需要在宿主机中启用Hyper-V,以便于创建虚拟机。(启用教程网上很多,不做阐述) 启用了Hyper-V以后,为了尽可能构建稳定独立的镜像环境,需要在Hyper-V中创建一个额外的网卡,用于单独构建虚拟机。 通过Windows的搜索功能打开Hyper-V管理器
根据下面的流程创建一个虚拟交换机
配置虚拟交换机属性
等待应用更改结束后就可以退出Hyper-V管理器了
只要双击打开下载好的Windows2022的iso文件,Windows就会自动对虚拟光驱进行挂载了。这里假设我挂载以后的盘符为D:\
首先在Windows宿主机上克隆构建工具的仓库
1 git clone https://github.com/cloudbase/windows-imaging-tools .git
以管理员权限执行Powershell,并进入刚刚clone的仓库目录下
为当前的Powershell临时加载镜像构建需要的模块
1 2 3 Import-Module .\WinImageBuilder.psm1Import-Module .\Config.psm1Import-Module .\UnattendResources\ini.psm1
指定配置文件的目录,并初始化对应的文件内容
1 2 $ConfigFilePath = ".\config.ini" New-WindowsImageConfig -ConfigFilePath $ConfigFilePath
(可跳过)快速初始化配置文件
1 2 3 Set-IniFileValue -Path (Resolve-Path $ConfigFilePath ) -Section "DEFAULT" `-Key "wim_file_path" `-Value "D:\Sources\install.wim"
因为有一些具体的参数还需要调整,因此这一步可以在下一步手动修改config的时候进行
手动完善刚刚通过命令行创建的config.ini文件,以下是一些注意事项和自己没搞明白的地方
image_name这个配置项需要对install.wim执行Get-WimFileImagesInfo来获取一个列表,然后选出你需要的那个镜像名字。比如对带有桌面环境的Windows Server 2022标准版而言,就是Windows Server 2022 SERVERSTANDARD[vm]的配置参数是指构建用的虚拟机的参数。在构建完成后这个虚拟机会被销毁,一般不用在意。在构建失败的时候可以通过管理员密码进入虚拟机查看信息[vm]的external_switch中需要填入的就是我们刚刚创建好的Hyper-V虚拟网卡名字,比如按照上图中我们选用的是external,这里直接填入即可。[drivers]的部分需要选择你下载的virtio镜像地址time_zone这块不太清楚格式应该怎么填,无论是Asia/Shanghai还是China Standard Time,在自己构建的时候都失败了。如果出现了同样问题的小伙伴建议就默认留空试试其他具体是用qcow2还是vhdx就按需填写即可
执行构建命令,等待镜像构建成功即可
1 New-WindowsOnlineImage -ConfigFilePath $ConfigFilePath
镜像构建的过程中,会有一段时间Powershell一直输出查询日志,这个时候可以去Hyper-V管理器那边查看创建好的虚拟机中的构建状态,如果出现了报错的话直接将虚拟机删除,重新调整配置文件再构建即可。
理论上来说整个构建流程都可以无人值守完成,构建成功了一次以后配置文件和路径在确定的情况下可以保留用于下一次的构建
构建成功后,生成的对应镜像会存放于config.ini中的image_path配置目录下。
整个构建流程对Windows宿主机一般而言不会有环境污染的问题。在构建完成以后,只需要删掉创建的Hyper-V虚拟交换机就可以恢复初始环境。如果在构建用虚拟机构建过程中出现问题,只需要删掉对应的虚拟机和虚拟机对应的磁盘文件即可。
如果是在加载驱动的过程中手动中止了构建,也只需要将挂载的虚拟目录弹出或删除,然后从头开始整个流程即可。
如果构建成功的话,虚拟机会自动关机并重启,这段时间可能会存在一段时间黑屏情况,不用太在意,等待一段时间以后Powershell会接收到虚拟机的配置信息,从而开始镜像的打包流程。
镜像构建:Windows Cloud Image
https://halc.top/p/b9295ba3
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux中不同版本exec函数区分 - Halcyon Zone
该问题为OSTEP第五章进程API上的一个问题,在搜Stack overflow的时候发现一个很好记的答案,单独写一个博客记录一下
what-are-the-different-versions-of-exec-used-for-in-c-and-c 对于exec()函数,在C/C++中有以下几个不同的版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include <unistd.h> extern char **environ;int execl (const char *pathname, const char *arg, ... ) int execlp (const char *file, const char *arg, ... ) int execle (const char *pathname, const char *arg, ... ) int execv (const char *pathname, char *const argv[]) int execvp (const char *file, char *const argv[]) int execvpe (const char *file, char *const argv[], char *const envp[])
其中不同版本的区别通过函数名可以分为以下几个大类:
L:L在这里指的是list,执行的时候的将参数以类似如下方式传入:
1 execl (const char *pathname, const char *arg, ...)
其中省略号代表了后续分别独立传入的参数,其中,第一个参数应是正在执行的文件关联的文件名,并且参数以空字符NULL作为结尾的判定。
V: V在这里指的是vector,执行的时候以char*的形式传入执行指令
1 int execv (const char *pathname, char *const argv[])
对于不确定传入参数的个数的时候,可以使用vector来执行程序。使用带v的函数的时候,首先传入的第一个pathname是指向可执行文件的路径,后面传入的argv[]中,第一个argv的位置上按习惯为可执行文件的名字,后面argv+1等参数则是实际需要调用的可执行文件的参数、
有的命令执行的时候,我们并不知道要传入的参数有几个,而有的命令则必须要一定数量的参数才能运行。通过分别调用带l或带v的函数,在不同的情况下执行某些特定命令很有用
E在这里指代的是Environment,在结尾带e的exec()调用的时候的环境变量env与父进程的env并非一定相同,通过带e的函数即可在调用exec()的同时传入一个env供子进程使用
P在这里指的是系统环境变量中的PATH,含有p的exec()在调用的时候会在系统变量的PATH当中寻找对应的可执行文件,而缺少p的exec()在执行的时候,如果在当前目录下没有对应的文件名字,则需要传入目标可执行文件的绝对或相对路径。
Linux中不同版本exec函数区分
https://halc.top/p/b9e46cb4
博客在允许 JavaScript 运行的环境下浏览效果更佳
总结:2022年2月 - Halcyon Zone
这个月因为游戏的问题,我又犯了拖延症的老毛病,导致计划中的学习任务没有一个完成。玩起游戏的时候总会高估自己的效率,导致就想着一直玩到通关为止。规划的二月份的学习计划没有一个完成的事实,让我感到挺沮丧的。但我还是觉得要写一篇总结来记录这个月的所做所为。
尝试了用Postman工具进行抓包,不过由于自己偷懒没仔细看文档以及对代理设置的不当配置,前前后后断断续续折腾了四五天还是换回Wireshark进行数据抓包,Python抓包发包本身学习倒是简单不少,一到两个小时就完成了学习,Appium目前也还没有开始接触。Rust相关的课程完全搁置没有进度。CS144的lab搭建好环境并在别人现成已有的Blog下完成了第一个实验,但是由于照葫芦画瓢,成就感很低并且了解不彻底,需要重新完成。力扣打卡断断续续持续了半个月,在2.25艾尔登法环发售到3.6通关群星结局过程没有其他进度。
虽然二月份就学习内容上来说摆烂几乎没有进度,但是用了一个礼拜的高强度游戏来感悟宫崎老贼的“魂系”游戏也完全不会让我觉得是在浪费时间。超大的世界观框架+完全自由的探索+五花八门的怪物+永远可以带来惊喜的各种武器,在初高中的时候总幻想一个所有人都可以一起探索的世界,这个世界在玩艾尔登法环的时候完全能够切身体验。在目前的开荒时期,除了自己推图可以发现各种各样的东西,同时最让人流连于其中的则是在目前世界观巨大的情况下,还没有完备的攻略来引导玩家“必须/流水线”的一套教程,同时全网玩家又在一起对这个世界进行发掘,让这个本来“单机”的游戏在某种意义上又变成了全网大家一起探索的异次元,这种开荒的乐趣加上老头环本身庞大的世界观绝对能称为我心中的“年度游戏”。
在不下雨的天气每天跑至少1.2km,同时保持良好的作息习惯 饮食上一个礼拜只吃一次非常规饮食,同时定期吃水果,改掉只吃维生素药片的习惯 这几天玩游戏的时候一直觉得这个月做的事情太少了,心里很不舒服。看到知乎一些“焦虑推送文”的时候也总觉得自己不务正业。造成这种情况的主要原因还是对玩艾尔登法环的时候一心想着开荒,对时间分配及其不合理导致状态的失衡,不过就取舍来说,作为几年难得一遇的优质游戏,和好兄弟一起联机攻克boss和开荒的快感不知下次得等几年,并不觉得这一个礼拜的时间有所亏欠,只是需要在这个月加把劲,把二月欠的任务完成!
总结:2022年2月
https://halc.top/p/ba5740b2
博客在允许 JavaScript 运行的环境下浏览效果更佳
原理分析:UDP和TCP在NAT环境下的P2P打洞实现 - Halcyon Zone
在当前互联网的结构模式下,大部分的数据通信和交互都是以C/S结构进行通信,即一个客户端和一个中心服务器,客户端通过将数据交给服务器,再有服务器将数据进行适当的处理后与客户端进行交互。除了C/S,还有一种常见的结构,即P2P通信。在P2P网络下,主要的通信双方为“节点”,节点和节点之间的通信是直达的,不需要中心服务器对信息进行处理。
由于这篇博客本身的目的并不是非要在C/S和P2P中抉择出一个好坏,重点主要放在P2P的技术实现上,就不做优劣对比了。P2P网络本质上是一种去中心化的网络结构,每个节点都直接与其他节点交互,共享节点和节点之间的资源与服务。这种结构相对来说可以更有效的利用资源,提高传输效率和可靠性(打洞成功的情况下)。
但是既然有这么多好处,那么必然也有相对应的挑战:P2P网络最核心的本质还是需要节点和节点能够直接通信。但是在当前国内的网络环境下,大部分的家庭用户并没有一个自己的公网IP。很多时候想实现节点和节点的直接通信,我们都需要想一个办法跨过防火墙,来让两个节点能够“握手”并“通信”,而这个过程便称为“打洞”。
内网请求 :用户设备(内网IP地址为192.168.1.10)通过端口5000发起对外部服务器的请求。地址转换 :路由器接收到来自内网用户的请求后,使用NAT机制将源地址从内网IP转换为路由器的公网IP地址(203.0.113.45),同时,源端口从5000更改为1024。NAT通过这一端口映射的过程,来维护外网和内网设备的通信。请求转发 :经过地址转换后,路由器将修改后的请求通过互联网转发至目标服务器(IP地址为51.68.141.240)的80端口。s服务器响应 :服务器接收到请求后,对该请求进行处理,并通过相同的端口(80)向互联网发送响应数据。响应数据路由 :互联网将服务器的响应数据发回路由器的公网IP地址(203.0.113.45)的1024端口。反向地址转换 :路由器接收到响应数据后,再次使用NAT机制,将响应数据包的目标地址从路由器的“公网IP地址(203.0.113.45):端口(1024)”映射回用户的”内网IP地址(192.168.1.10)和端口5000“。内网传递响应 :最后,路由器将响应数据发送回内网用户,完成整个通信过程。
注册与穿透服务器 :两个客户端A和B分别与穿透服务器S建立UDP会话。在此过程中,服务器S记录每个客户端的两个Endpoint:客户端自认为用来与S通信的内网Endpoint对,以及服务器观察到的客户端用来进行通信的公网Endpoint。Endpoint信息的记录与交换Endpoint信息,并从IP和UDP头部提取公网Endpoint信息。如果客户端不在NAT后面,这两个Endpoint应该是相同的。发起UDP打洞请求 :假设客户端A想要直接与客户端B建立UDP会话。A首先不知道如何到达B,因此A请求S帮助建立与B的UDP会话。服务器响应 :S回复A,包含B的公网和内网Endpoint信息。同时,S使用其与B的UDP会话向B发送包含A的公网和内网Endpoint的连接请求消息。收到这些消息后,A和B知道了对方的公网和内网Endpoint。双向打洞 :A收到B的公网和内网Endpoint后,开始向这两个Endpoint发送UDP数据包,并锁定首先从B处获得有效响应的Endpoint。类似地,B在收到转发的连接请求后,开始向A的已知Endpoint发送UDP数据包,锁定第一个有效的Endpoint并以此通讯。由于A和B相互发送数据包的操作本身是异步的,因此A和B发送数据包的前后顺序并没有严格要求。
建立会话 :客户端A与服务器S建立UDP会话,NAT分配公网端口62000。端口分配 :客户端B也与服务器S建立UDP会话,NAT为其分配公网端口62005。连接请求 :客户端A请求使用打洞技术与客户端B建立通信,并通过服务器S作为介绍人。交换Endpoint信息 :服务器S向客户端A发送客户端B的公网和内网Endpoint信息,并将客户端A的信息转发给客户端B。尝试直接通信 :客户端A和B尝试向彼此的公网和内网Endpoint发送UDP数据包。选择通信路径 :根据NAT的支持情况,客户端可能通过NAT(支持Hairpin转译)或直接(不支持Hairpin转译)进行通信。Hairpin是NAT中的一种转译技术,其主要实现了让NAT后的两台设备都可以通过公网的IP和端口进行直接通信,具体的效果如下
客户端A发送数据 :假设客户端A想要发送数据到客户端B。首先,客户端A会将数据包发送到NAT设备,目标是客户端B的公网Endpoint(例如155.99.25.11:62005)。NAT设备处理 :NAT设备接收到来自客户端A的数据包,并查看目标地址。这里涉及Hairpin转译,因为数据包的源地址和目标地址都是由NAT设备分配的公网地址。Hairpin转译动作 :如果NAT设备支持Hairpin NAT,它会识别出虽然目标地址是公网地址,但实际上目的地是内网中的另一个客户端。NAT设备将会将数据包的目标地址从B的公网Endpoint转换为B的内网IP地址(10.1.1.3),同时可能还会更改源地址从A的公网Endpoint到A的内网IP地址(10.0.0.1)。数据包转发给客户端B :完成地址转换后,NAT设备将数据包转发到客户端B的内网地址上。此时,数据包好像是从客户端A直接发送给客户端B而不是经过互联网,即使它们实际上是通过NAT设备的公网地址进行通信的。客户端B接收数据 :客户端B收到了来自客户端A的数据包,尽管这些数据包最初是发送到NAT设备的公网地址的。在P2P通信中,由于内网Endpoint比公网的Endpoint要更早到达客户端B,也就是说Hairpin转译的通信流程还没走完,客户端A通过内网Endpoint和B建立的通信就完成了。因此在实际的通信中,由于内网路由通常比经过NAT的路由更快,客户端A和B更倾向于使用内网Endpoint进行后续的常规通信。
会话初始化 :客户端A和B分别从它们的本地端口4321发起到服务器S的1234端口的UDP通信会话。端口映射 :NAT A为客户端A分配公网端口62000,而NAT B为客户端B分配公网端口31000。注册与记录 :A和B向服务器S注册它们的内网和公网Endpoint。请求协助 :客户端A请求服务器S帮助与客户端B建立连接。Endpoint交换 :服务器S向两个客户端交换彼此的公网和内网Endpoint信息。尝试直连 :A和B尝试直接向彼此的公网和内网Endpoint发送UDP数据包。NAT行为 :如果NAT A和NAT B表现良好,它们将保留公网到内网的映射,为P2P通信“打洞”。通信验证 :一旦客户端验证了公网Endpoint的可用性,且因为在两个不同的NAT后,内网Endpoint不可达,它们将停止向内网Endpoint发送消息,只用公网Endpoint通信。
客户端发起连接 - 客户端A和B分别从它们的内网地址发起到服务器S的UDP连接。NAT A和B映射 - NAT A和NAT B各自为客户端A和B创建了公网到内网的地址映射。NAT C建立映射 - 在ISP级别的NAT C为两个会话建立了公网到内网的地址映射。尝试建立P2P连接 - 客户端A和B尝试通过UDP打洞技术建立直接的P2P连接。NAT C的Hairpin转译 - 如果NAT C支持Hairpin转译,它会处理从A到B和从B到A的数据包。数据包路由 - NAT C将数据包正确地路由到另一端的客户端。数据包到达目的地 - 经过NAT的转译,数据包成功到达对方客户端。当NAT不支持Hairpin转发的时候就无能为力了,目前Hairpin的普及度也需要打一个问号。也存在一些特殊的NAT结构,让P2P的成功率更加没有保证。如果希望P2P打洞的成功率变高,则需要整个互联网都推动这一块的发展。
即使在通过上述的几种不同的方法打洞成功,这种方法打出的隧道也并不是可以一直可靠的。大部分的NAT内部都有一个维护UDP转换信息的计时器:如果在一段时间内某个端口上不再有数据通信,那么这个隧道就会因为空闲超时被关闭掉。
如果希望P2P的隧道能不受NAT网关的时间限制,就需要通过发送持续的心跳包来维持这个隧道的活跃状态。
除了心跳包的方法,当然也可以在双方长时间没有数据往来的时候将当前的隧道关闭,并在下一次需要通信的时候建立连接。通过这样的方式避免不必要的流量浪费。
原理分析:UDP和TCP在NAT环境下的P2P打洞实现
https://halc.top/p/bb3a9deb
博客在允许 JavaScript 运行的环境下浏览效果更佳
快速部署rclone为services - Halcyon Zone
在Linux上安装rclone可以直接使用默认发行版仓库的版本,也可以官方脚本安装
1 curl https://rclone.org/install.sh | sudo bash
安装完成了之后通过输入以下指令可以在交互式页面当中添加、修改或删除连接信息
在配置完成之后,如果需要将rclone的内容挂载到本地,执行类似以下格式的指令
1 rclone mount remote_name:path/to/directory path/to/mount_point
其中可以添加以下参数来对本地的文件进行缓存设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 --transfers:该参数控制最大同时传输任务数量,如果你cpu性能差,建议调低,但太低可能会影响多个文档同时传输的速度。
在挂载的时候可以添加--deamon参数来让rclone后台临时挂载,如果要取消挂载则输入以下指令
1 fusermount -u path/to/mount_point
如果需要配置开机自启动挂载对应的Rclone服务,只需要创建以下文件(以onedrive为例,参数和名字可自定义):~/.config/systemd/user/rclone-onedrive.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [Unit]# 挂载在当前用户的~目录的OneDrive文件夹内,需要提前创建好~/OneDrive # Make sure we have network enabled # 启用vfs模式,将onedrive挂载给/home/xxx/OneDrive文件夹 # 取消挂载 # Restart the service whenever rclone exists with non-zero exit code # Autostart after reboot
写入完成之后,通过执行以下两个指令在当前用户下生效该服务
1 2 systemctl --user daemon-reload
快速部署rclone为services
https://halc.top/p/bbde595d
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux下有关用户和组的文件权限变动 - Halcyon Zone
参考文章
1.Ubuntu群组管理
Linux下拥有着不同的用户和群组,群组可以是一个用户的集群,通过修改Linux的用户和对应的群的权限可以较为安全的对文件进行操作。
接下来所有的内容都是基于Ubuntu 20.04 LTS
在我们需要对多个用户进行相同的权限管理的时候,可以通过创建对应群组来进行管理,这里以demog为例
以demo用户为例,在有root权限的情况下输入以下指令来设置demo的初始组为demog
首先是组然后才是用户
要查询当前用户所在的组信息,可以使用类似如下指令
如果要把一个用户添加到多个群组可以用如下指令(先去除后添加,请勿直接尝试指令)
1 groups -G demog1 demog2 demog3 demo
配合-g或者-G参数的时候,会把用户从原本的组里面剔除,然后加入到新的组里面,如果需要的是-a的参数,表示的是“追加”
指令很简单,如下格式
Linux下有关用户和组的文件权限变动
https://halc.top/p/be72c31c
博客在允许 JavaScript 运行的环境下浏览效果更佳
ZeroTier配置Moon服务器 - Halcyon Zone
参考链接:什么值得买-ZeroTier配置Moon节点
2.ZeroTier官方手册
ZeroTier本身的PLANET服务器位于国外,并且由于免费的性质以至于在一些高峰时期经常出现无法打通隧道的情况,这个时候通过自己搭建国内的Moon节点并且进行配置可以达到国内中转加速的作用。
将需要设置moon节点的VPS加入到需要加速的局域网内
zerotier-cli join <network id>
生成moon模板
1 2 cd /var/lib/zerotier-one
修改moon.json
vi moon.json
修改stableEndpoints为VPS的公网IP,可以添加ipv6地址,例如:
"stableEndpoints": [ "10.0.0.2/9993","2001:abcd:abcd::1/9993" ]
完整的文件内容示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 {"id" : "deadbeef00" ,"objtype" : "world" ,"roots" : ["identity" : "deadbeef00:0:34031483094..." ,"stableEndpoints" : [ "10.0.0.2/9993" ,"2001:abcd:abcd::1/9993" ]"identity" : "feedbeef11:0:83588158384..." ,"stableEndpoints" : [ "10.0.0.3/9993" ,"2001:abcd:abcd::3/9993" ]"signingKey" : "b324d84cec708d1b51d5ac03e75afba501a12e2124705ec34a614bf8f9b2c800f44d9824ad3ab2e3da1ac52ecb39ac052ce3f54e58d8944b52632eb6d671d0e0" ,"signingKey_SECRET" : "ffc5dd0b2baf1c9b220d1c9cb39633f9e2151cf350a6d0e67c913f8952bafaf3671d2226388e1406e7670dc645851bf7d3643da701fd4599fedb9914c3918db3" ,"updatesMustBeSignedBy" : "b324d84cec708d1b51d5ac03e75afba501a12e2124705ec34a614bf8f9b2c800f44d9824ad3ab2e3da1ac52ecb39ac052ce3f54e58d8944b52632eb6d671d0e0" ,"worldType" : "moon"
生成moon签名文件
zerotier-idtool genmoon moon.json
通过winscp等工具将000000xxxx.moon的签名文件拷贝下来,或者记住moon.json中"id": "idtoremember"的id
将moon节点加入网络
1 2 mkdir moons.dmv ./*.moon ./moons.d
重启ZeroTier,到此Moon服务器的配置结束。
在搭建moon服务器的第五步中,记录下moon节点的id,然后在客户端上运行命令
zerotier-cli orbit idtoremeber idtoremeber
在不同设备的ZeroTier根目录下添加moons.d文件夹
1 2 3 4 5 其中,不同系统对应的ZeroTier的位置如下:
将生成的0000xxx.moon文件放置于moons.d文件夹下
OpenWrt需要修改一个脚本,因为其var目录是一个内存虚拟的临时目录,重启后原有配置不会保留。
通过ssh连接到Openwrt并修改zerotier的启动脚本
在add_join(){}上方插入两行代码
1 2 mkdir -p $CONFIG_PATH /moons.dcp /home/moons.d/* $CONFIG_PATH /moons.d/
如下图所示:
在/home文件夹下创建moons.d文件夹(修改cp /home/moons.d可以修改需要设置的路径)
把moon的签名文件00000xxx.moon放于该文件夹内,并重启ZeroTier即可
启动Openwrt上的ZeroTier
输入以下指令
1 cp -a /var/lib/zerotier-one /etc/zerotier
修改/etc/config/zerotier的配置文件,添加以下内容
option config_path '/etc/zerotier'
ZeroTier配置Moon服务器
https://halc.top/p/c1161a88
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:分页的计算 - Halcyon Zone
对于线性页表,只要知道第一个Page的地址,存于寄存器当中,就可以通过这个地址依次陆续推算下一个或后面任意一个有效的地址范围。对于多级页表,通过多次搜索,依旧可以在只有最初的页表的地址的情况下,通过多次的偏移查询来定位到最后需要的特定地址。
这里取例子说明算法,具体答案通过-c参数可直接输出
这里以seed为0的时候为例
首先,在README.md中可以得到以下信息
Page Size: 32 bytes Virtual Address Space:32 KB(1024个分页 2^15)虚拟地址需要 15 bits (VPN 占 10 bit,offset 占 5 bit) Physical Memory: 128个分页(2^12)物理地址需要 12 bits (PFN 占 7bit, offset 占 5 bit ) Virtual Address Space 的前五位对应了Page Directory的索引 通过seed生成0对应的地址数据,用于PDE查表,内容如下
Page Content 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 page 0:1b1d05051d0b19001e00121c1909190c0f0b0a1218151700100a061c06050514
并且根据模拟生成的PDBR: 108可以知道Page 108对应的内容即是第一级PDE的映射
接下来就可以进行计算了,这里取一个vaild和invaild的答案分析计算过程
1 2 3 4 5 6 7 8 Virtual Address 611c:
Virtual Address 611c
将611c按二进制转换为Virtual Address Space对应的 15 bits 为 11000 01000 11100。对PDE分割前五位有11000(decimal 24)
这个时候对最顶层的PDTR对应的Page 108进行查表操作
首先可以通过Page Content得到Page 108内容如下
1 2 Page 108: 83 fe e0 da 7f d4 7f eb be 9e d5 ad e4 ac 90 d6 92 d8 c1 f8 9f e1 ed e9 a1 e8 c7 c2 a9 d1 db ff
通过查表找到对应Index的内容可以知道24(11000)对应位置的内容是a1,转换为二进制为1010 0001,读取最高位为1可以知道是vaild。再通过后面的0010 0001转换为十进制为33,因此再继续查询Page 33的内容
1 2 Page 33:7f 7f 7f 7f 7f 7f 7f 7f b5 7f 9d 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f 7f f6 b1 7f 7f 7f 7f
611c的[1-5]位为PDE,这时我们则需要通过[6-10]位来通过PTE寻找VPN对应的PFN地址。由611c为11000 01000 11100可以知道这次为01000即(decmial 8),对照上面page 33可以发现第八个对应的内容为53,因此可以知道最终VPN对应上了PFN的Page 53。最后再通过offset的11100,配合Page 53对应的二进制PFN地址11 0101结合offset的11100有110101 11100,也就是最后答案的0x6bc,其中通过offset在Page 53中查表可以找到对应的 Value 为 08
Virtual Address 3da8
和611c同理,将3da8转为二进制01111 01101 01000,得到pde index为01111(15),对应的Value为0xd6(1101 0110),通过1101 0110最高位可以知道目标分页为vaild,去掉vaild bit可以得到索引的pte为0x56(0101 0110 | 86)
检索Page 86,由PTE index为01101可以找到对应的Value为0x7f(0111 1111)由于最高位为0,因此是invaild,也就是说pte无效,无法访问
其他的情况也是依次类推,即可算出结果是否有效
根据个人理解,具体缓存hit或miss的概率主要由对应内存上的数据决定。对于访问次数较多的内容hit缓存加快速度的概率自然更高;而对于不重复的多次查询(比如上面的练习),自然miss的概率会更高。因此对于进程来说,如果能将数据尽量集中在某一块分页上则能有效提高内存访问和处理的速度。
OSTEP:分页的计算
https://halc.top/p/c1ec22c4
博客在允许 JavaScript 运行的环境下浏览效果更佳
Devc++调试相关选项配置 - Halcyon Zone
由于蓝桥杯比赛需要使用Devc作为IDE工具,平时用习惯了vscode的snap和其他功能以后觉得如果不提前适应一下Devc 的编译环境的话在比赛的时候会吃很大的亏,于是决定之后的学习都用Devc进行,在此记录一下Devc 启用调试之前需要的一些基本设置
貌似在按F5准备进行调试的时候,即使自己没有进行以下设置,Devc++依旧会询问并且可以直接打开进行设置,这里只做一个提前设置的记录,并非必须
首先,打开devc++之后,找到上方的Tools(工具),如下图所示,打开其中的Compiler options(编译选项)
然后按下图开启调试信息(设置为yes)
再次打开Tools,并且打开Enviroment options
启用下图黄线部分的选项,开启显示指针所指变量的值
Devc++调试相关选项配置
https://halc.top/p/c9774a05
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux下通过硬盘UUID进行挂载 - Halcyon Zone
重启后盘符发生变化解决办法 将硬盘接入系统
使用以下指令查询目前磁盘分区的盘符
使用以下指令查询特定盘符的UUID
1 blkid /dev/sda1 ## 这里的sda1要看具体情况填
在/etc/fstab/内编辑类似以下内容挂载磁盘
1 UUID=c26cfce4-xxxx-xxxx-xxxx-403439946c8c /opt ext4 defaults 0 0 ## /opt为具体挂载的目录,ext4为磁盘格式
使用以下指令检查是否设置成功,如果成功则不会返回任何异常信息
Linux下通过硬盘UUID进行挂载
https://halc.top/p/c9fc3bb5
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux下7zip的使用手册 - Halcyon Zone
直接使用apt安装即可
压缩文件/文件夹
1 7za a -t7z -r MyTest.7z FolderToZip/*
将FolderToZip文件夹下所有文件压缩到当前目录的MyTest.7z文件中
a 代表添加文件/文件夹到压缩包
解压缩文件夹
将MyTest.7z解压到当前目录
x 代表解压缩文件,并且是以原本文件夹的方式解压(还有一个参数是e,会直接把所有文件从根目录解压)
参考文章:
linux下安装7z命令及7z命令的使用 Linux下7zip的使用手册
https://halc.top/p/cc7f9b10
博客在允许 JavaScript 运行的环境下浏览效果更佳
ArchWSL安装及基础配置 - Halcyon Zone
在Windows上安装ArchWSL直接使用scoop来安装是比较便捷的一种方案,具体如何在Windows上配置·scoop`可以参考这篇教程:
在配置好了scoop以后,首先通过以下指令安装ArchWSL
只要按正常流程,按win+s,通过Windows搜索找“Turn Windows features on or off”或“启用或关闭Windows功能”,然后在里面将 Virtual Machine Platform 和 Windows Subsystem for Linux 勾选上,重启电脑即可。
重启电脑之后只需要在命令行中输入arch即可启动,如果出现报错或无法使用 WSL2 的情况可以通过搜索引擎或在这里下载Linux内核更新包 来解决
在/etc/pacman.d/mirrorlist内已经有Arch预置好的部分国内镜像源,我们只需要将我们对应需要的镜像前面的注释取消即可使用。
或者也可以通过下面这个脚本来一键启用所有China部分的镜像源
1 sed -E '/China/,/##/s/^#S(.)/S\1/g' /etc/pacman.d/mirrorlist~ > /etc/pacman.d/mirrorlist
通过以下指令将archlinuxcn相关源直接写入/etc/pacman.conf当中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat >> /etc/pacman.conf << EOF # 国内archlinuxcn镜像源 [archlinuxcn] Server = https://mirrors.aliyun.com/archlinuxcn/\$arch Server = https://repo.archlinuxcn.org/\$arch Server = https://mirrors.bfsu.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cloud.tencent.com/archlinuxcn/\$arch Server = https://mirrors.163.com/archlinux-cn/\$arch Server = https://repo.huaweicloud.com/archlinuxcn/\$arch Server = https://mirrors.zju.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cqupt.edu.cn/archlinuxcn/\$arch Server = https://mirrors.sjtug.sjtu.edu.cn/archlinux-cn/\$arch Server = https://mirrors.tuna.tsinghua.edu.cn/archlinuxcn/\$arch EOF
首先通过以下指令,来更新软件源、安装archlinuxcn证书、yay和部分基础工具(其中yadm是一个用来备份dotfiles的工具,用于恢复自己常用的Linux环境下的自定义文件)
1 2 pacman -Syyu --noconfirm ;
创建用户 (注意替换下文的用户名)
1 useradd -m -G wheel -s /bin/zsh 用户名
将wheel组内的成员给予sudo的权限
如果希望安全考虑,在sudo之前要输入密码的话,可以输入下面的指令来配置visudo
1 echo '%wheel ALL=(ALL:ALL) ALL' | sudo EDITOR='tee -a' visudo
如果偷懒,不希望每次都输入密码的话可以用下面的指令来配置visudo
1 echo '%wheel ALL=(ALL:ALL) NOPASSWD: ALL' | sudo EDITOR='tee -a' visudo
2.5. 以上所有操作全部可以自动完成,只需要将以下脚本内的用户名替换为自己的用户名即可(默认sudo不需要密码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 sed -E '/China/,/##/s/^#S(.)/S\1/g' /etc/pacman.d/mirrorlist~ > /etc/pacman.d/mirrorlistcat >> /etc/pacman.conf << EOF # 国内archlinuxcn镜像源 [archlinuxcn] Server = https://mirrors.aliyun.com/archlinuxcn/\$arch Server = https://repo.archlinuxcn.org/\$arch Server = https://mirrors.bfsu.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cloud.tencent.com/archlinuxcn/\$arch Server = https://mirrors.163.com/archlinux-cn/\$arch Server = https://repo.huaweicloud.com/archlinuxcn/\$arch Server = https://mirrors.zju.edu.cn/archlinuxcn/\$arch Server = https://mirrors.cqupt.edu.cn/archlinuxcn/\$arch Server = https://mirrors.sjtug.sjtu.edu.cn/archlinux-cn/\$arch Server = https://mirrors.tuna.tsinghua.edu.cn/archlinuxcn/\$arch EOF echo '%wheel ALL=(ALL:ALL) NOPASSWD: ALL' | sudo EDITOR='tee -a' visudo
给root用户和自定义用户设置密码(自行操作)
修改root用户密码
修改自定义用户密码
(可选)切换到自定义用户下并配置oh-my-zsh
通过以下指令切换用户
配置zsh为oh-my-zsh可以参考这篇教程(Ubuntu配置和Arch大同小异,可以选择性参考)
Ubuntu下安装Oh My Zsh引导
如果希望设置ArchWSL为WSL的默认发行版,并将刚刚自己创建的用户作为默认用户的话只需要分别在Powershell下执行这两条指令
1 Arch config --default-user 用户名
ArchWSL安装及基础配置
https://halc.top/p/cdfd3649
博客在允许 JavaScript 运行的环境下浏览效果更佳
通过Python提交ncu每日健康信息 - Halcyon Zone
该方法目前稳定性尚不确定,Token有概率会不定时失效,如果使用后果自负 该方法仅作Python学习使用,了解原理后使用后果自负 疫情期间请以实际情况打卡汇报,切勿身体有状况而依旧以无状况打卡。 简单三步,用 Python 发邮件 - 知乎 (zhihu.com) github action获取仓库secrets 通过Github Actions,在每天通过cron设定的时间实现企业微信打卡
Github Actions
QQ号以及QQ的SMTP密码
在打卡界面中"复制链接",并在电脑上打开
电脑浏览器打开链接,按F12,此时可能是电子ID,不用管,在右上角找到Network,并打开。
(如果提示要按Ctrl+R,按就行)
在Network下方找到loginByToken,并且找到右边的Token信息,复制保存。
百度搜索:获取QQ邮箱的SMTP密码
大致思路就是通过对应接口抓包后发包即可,更新Token通过接口LoginByToken实现,打卡通过SignIn接口实现。Scripts/ncu.py
为了仓库的信息安全,所有的密码通过Github仓库下secrets来进行设置,然后参考 github action获取仓库secrets 中提及的方法修改设置即可。
每个人都有义务在疫情大环境下对自己的真实信息负责
通过Python提交ncu每日健康信息
https://halc.top/p/cf0fd528
博客在允许 JavaScript 运行的环境下浏览效果更佳
SSH技巧总结 - Halcyon Zone
在客户端电脑上输入以下指令生成rsa私钥和公钥
ssh-keygen -t rsa -C "your@email.com"
生成一对以你的邮箱为标签的密钥
在/.ssh/文件夹下的id_rsa为密钥文件,id_rsa.pub为公钥文件
在当前用户的主目录中的/.ssh/中添加或者修改authorized_keys文件,将刚刚客户端的id_rsa.pub内容复制到authorized_keys中 编辑sshd_config文件
vi /etc/ssh/sshd_config
禁用密码验证
将PasswordAuthentication的注释取消,并修改为
PasswordAuthentication no
重启SSH服务
注意,重启SSH服务之前建议保留一个会话,以免出现密码登入失败的情况
在建立连接的时候,如果是第一次对一个服务器建立连接,经常会问到我们是否信任对方,并且在第一次建立连接之后,如果同一个IP地址后的服务器有过重装,还会因为之前保存的证书而出现连接失败的情况。
因此可以在~/.ssh/config文件中添加以下配置
1 2 StrictHostKeyChecking no # 关闭主机公钥的确认信息,去掉了连接时候的提问,不过也因此有安全隐患,需要自己权衡
同时,有的时候我们需要频繁访问同一个服务器,反复输入ssh root@xxx.xxx.xxx.xxx是很令人恼火的一件事(即使有的域名或历史记录)。这个时候我们就可以通过在config中添加一个Host来给我们需要的服务器添加一个简单易懂的别名来建立连接
1 2 3 Host router
假设我们路由器的IP地址是192.168.100.123,那么我们就可以将原本的
1 ssh root@192.168.100.123
改为
这样ssh就会使用root用户来登入192.168.100.123了
对于一些有GUI的Linux系统来说,有的时候我们并不希望远程整个桌面,而是通过SSH来运行部分图形化的程序。在Windows当中,我们可以通过安装VcXsrv来提供一个SSH的转发接口,然后在~/.ssh/config中对应的服务器添加如下参数
1 2 3 4 5 Host study
这样我们在和对应服务器建立连接以后,就可以通过在自己电脑上的cli运行远程服务器中带有GUI
在有的时候ssh需要连接的主机可能很多,放在一个文件里面可能会不便于管理。这个时候我们就可以通过Include关键字,来添加其他的config合并进来。
假设当前我们的.ssh目录的结构如下
1 2 3 4 5 6 7 8 ~ [ tree .ssh ] 1:40 PM
那么我们就可以在config当中添加Include conf.d/home来实现对于home文件的多文件配置涵盖。参考如下
1 2 3 4 5 6 7 8 9 10 11 StrictHostKeyChecking no
在home当中就可以添加正常的ssh配置了
SSH技巧总结
https://halc.top/p/cff2e0b5
博客在允许 JavaScript 运行的环境下浏览效果更佳
C++学习记录 - const限定符 - Halcyon Zone
总结自C++ Primer,仅供自己学习参考
引用本身只是目标对象的一个别名,自己本身并不是对象
变量引用可以间接对变量进行修改
常量别名代表的只能是常量 ,如果常量别名一个变量,也是先通过创建一个临时量 ,然后对这个临时量 创建别名
变量别名不能指向一个常量 ,也不能指向运算后的值 后的结果,e.g.
1 2 3 4 5 6 7 8 9 10 11 int pi = 3 ;const int PI = 3 ;int &revPI = pi; int &revPIt = pi *2 ; const int &cRevPI = pi; int &cstRevPI = PI; const int &cstcRevPI = PI;
引用在decltype出并非是对象的同义词,而表示的是对应类型的引用
1 2 3 4 const int ci = 0 , &cj = ci;decltype (ci) x = 0 ; decltype (cj) y = x; decltype (cj) z;
而对于表达式,在使用decltype关键词的时候,由于表达式本身可以返回一个值,所以会被识别为一个引用类型
1 2 3 int i = 0 ;decltype ((i)) d; decltype (i) e;
指针本身是一个对象,其含义为指向目标对象的地址 void指针可以指向任意一种变量代表的地址常量指针必须初始化 ,其中通过const关键词有两种表达意思:int *const ptr指的是常量指针,地址不可改变,指向一个int类型的变量 const int *ptr指的是常量的指针是常量类型,地址可改变,指向的是const int类型的常量 对于*const关键词修改的指针,虽然地址不能改变,但是依旧可以通过这个指针修改对应变量的值 。 顶层const:指针本身是一个常量
底层const:指针所指的对象是一个常量
C++学习记录 - const限定符
https://halc.top/p/d08cfaf4
博客在允许 JavaScript 运行的环境下浏览效果更佳
Oh My Posh美化Windows Terminal引导 - Halcyon Zone
更新PowerShell本身和Windows Terminal没啥直接关系,单纯做个提醒放一个一键更新指令在这里:
1 iex "& { $ (irm https://aka.ms/install-powershell.ps1) } -UseMSI"
这条命令的作用是安装最新版本的PowerShell,截至发博客为止可用于安装PowerShell 7
打开Microsoft Store 搜索Windows Terminal 安装 在Win+R中输入wt回车即可呼出Windows Terminal Windows Terminal中链接了一些Linux下可用的指令,诸如ls等如果要在Windows Terminal下使用vim编辑器,只需要在安装了Git的前提下将C:\Program Files\Git\usr\bin设置为环境变量即可。(如果Git安装在其他目录下进行相对应的调整就好,设置好了以后重启一次Windows Terminal即可) 如未特别说明,接下来将用wt作为Windows Terminal的简写
注:本文个性化配置包括:
修改Windows Terminal的配色
安装posh-git和oh-my-posh
安装Nerd Font字体
配置oh-my-posh来修改wt的配色和样式
不包括(以下设置在最新版的wt设置中已经包含):
在mbadolato/iTerm2-Color-Schemes 下滑,找到自己喜欢的配色的截图,在截图的左上方会有该配色的代号。
在iTerm2-Color-Schemes/windowsterminal 上找到配色对应的json文件并复制所有的内容。
在wt中打开设置,以下图为例:
打开JSON设置,以图下为例:
将刚刚复制的代码粘贴到有scheme字样的配置目录下,以下图为例:
保存后,回到wt的设置,选择平时主要使用的窗口界面(e.g.PowerShell)然后选择外观,然后选择自己添加的主题,以下图为例:
教程以Hack NF字体为例,如果需要使用其他字体请自行选择。
在这个页面下载的Hack.zip:
ryanoasis/nerd-fonts
解压Hack.zip,然后全选所有文件,右键点击安装
在wt中需要的终端,按配色修改 第6步修改字体为Hack NF即可。
以下教程需要电脑上安装了Git才能使用
使用PowerShell安装post-git和oh-my-posh
指给当前用户(非Administrator)安装:
1 2 Install-Module posh-git -Scope CurrentUserInstall-Module oh -my-posh -Scope CurrentUser
给所有用户安装:
1 2 Install-Module posh-git -Scope AllUsersInstall-Module oh -my-posh -Scope AllUsers
列出所有可用主题
找到自己喜欢的主题,然后使用指令预览(这里以spaceship为例):
1 Set-PoshPrompt -Theme spaceship
在预览结束以后,为了让主题每次启动都生效,需要创建一个脚本。
输入以下指令:
按下按键i,进入插入模式,然后填入以下内容:
1 2 3 Import-Module posh-git
键盘键入:wq然后回车,代表保存并退出。
重新启动wt即可看到自己个性化配置的Windows Terminal界面了。
Oh My Posh美化Windows Terminal引导
https://halc.top/p/d26abad0
博客在允许 JavaScript 运行的环境下浏览效果更佳
CS144-Lab5 计算机网络:Network Interface的功能 - Halcyon Zone
在通过TCP协议将数据包进行封装准备好以后,就需要“快递公司”来对这些数据包进行分发了。这个过程可以划分为两个部分,一个是数据包在中转转发的过程中需要经过的“中转”设备有哪些,其次就是如何选择“中转”的线路。
在网络接口的部分,主要实现的逻辑是作为发送的某一个节点,在知道了下一个中转站的IP地址以后,如何将数据包进行交付。
首先对目前的知识进行一个梳理。首先在前面四个Lab里面,主要完成的是TCP数据包从一串简单的字符串,到最后封装成一个完整的,可以用于建立连接沟通的TCP数据包。TCP数据包本身并不关心数据包是如何从源IP到目标IP的,这一部分的主要实现是由网络层的IP路由和数据链路层进行沟通。
在数据链路层中,我们假设已经通过网络层的路由知道了下一条的IP地址,但是要知道一个网口今天可以是192.168.1.1,明天就可以是10.0.0.1,因此我们只知道IP地址是不足以让我们从硬件层面将数据包进行中转发送的,我们还需要针对每一个特定网口本身的硬件地址,也就是MAC地址,来硬件和硬件之间可以正确的发送数据。
由于硬件地址和IP地址的映射关系有可能是动态的,而每次发送数据都向所有设备广播询问一次MAC和IP的映射关系的话在交流频繁的网络情况下资源利用率十分低下,因此我们也需要在中转设备中动态维护一个缓存用的映射表,同时为这个映射表中每一个条目设定对应的TTL来保证数据的实时性,在超过一定时间以后就删除该缓存。
1 2 3 4 5 6 7 8 9 10 11 12 struct ArpEntry {uint32_t raw_ip_addr;bool operator <(const ArpEntry &rhs) const { return raw_ip_addr < rhs.raw_ip_addr; }const size_t arp_max_ttl = 30000 ;size_t > _arp_table{};
而获取IP和MAC地址对应关系的这个步骤则是由ARP协议实现,在硬件自己不知道要发送的下一个网口的MAC地址的时候,他就会给所有的网口广播ARP,正确的设备识别到了这个ARP是发送给自己的以后就返回自己的MAC地址,如果不是发送给自己的则丢弃不处理。同时和TCP中的超时重传一样,ARP探针自己也有可能会因为硬件链路的问题而导致对方没有收到自己的报文,所以也需要有一个超时重传的逻辑,来让自己尽可能的收到对方的回复。
1 2 3 4 5 6 7 8 9 10 11 12 struct ArpEntry {uint32_t raw_ip_addr;bool operator <(const ArpEntry &rhs) const { return raw_ip_addr < rhs.raw_ip_addr; }const size_t arp_probe_ttl = 5000 ;size_t > _probe_table{};
在有了以上两个大体部分以后,我们就只需要实现
发送(IPV4/ARP)报文 接受(IPV4/ARP)报文 超时重传探针,以及管理ARP映射的TTL 两个部分即可。
在发送报文之前,我们首先需要将IP地址转换为uint_32,以用于报文的封装,然后检查这个IP地址我们是否已经缓存了它对应的MAC地址
1 2 3 4 5 6 7 8 9 10 11 const uint32_t next_hop_ip = next_hop.ipv4_numeric ();for (const auto &entry : _arp_table) {if (entry.first.raw_ip_addr == next_hop_ip) {break ;
如果这个IP地址对应的MAC地址我们已经缓存了,那么就只需要将这个IP报文封装成网络帧进行发送
1 2 3 4 5 6 7 8 if (next_eth.has_value ()) {header () = {next_eth.value (), _ethernet_address, EthernetHeader::TYPE_IPv4};payload () = dgram.serialize ();push (eth_frame);return ;
如果这个IP地址在我们维护的ARP映射表中并不存在对应的映射关系,那么我们首先要判断我们是否就这个IP发送过ARP探针,如果发送过探针了那么我们也没必要再发送一次,只要等待之前的探针让对方返回正确的MAC地址给我们即可。
1 2 3 4 5 6 for (auto &probe : _probe_table) {if (probe.first.raw_ip_addr == next_hop_ip) {return ;
如果没有发送的话,那么我们就需要封装一个ARP探针,用于检测目标IP对应的MAC地址,探针目标的IP地址就是IP数据包下一跳的IP,MAC地址则是广播地址(在该实验中直接将目标MAC设置为空即可)。
1 2 3 4 5 6 7 8 9 10 11 ipv4_numeric ();header () = {ETHERNET_BROADCAST, _ethernet_address, EthernetHeader::TYPE_ARP};payload () = arp_probe.serialize ();push (probe_frame);
同时由于探针有超时重传的机制,因此对于这个新发送的报文,我们也需要将其加入缓存表中并设定TTL
1 2 3
所有的代码
在接受报文的部分,我们无非会收到两种报文,一种是包含IP数据的报文,一种是对方给我们发过来的ARP报文
对于这两种报文,首先我们判断它是不是要发送给我们的或是否是一个广播的网络帧
1 2 3 4 if (frame.header ().dst != _ethernet_address && frame.header ().dst != ETHERNET_BROADCAST) {return {};
如果这是一个确定源MAC和目标MAC的IP数据包,那么我们只需要接受这个数据包然后返回对应的数据即可
1 2 3 4 5 6 if (frame.header ().type == EthernetHeader::TYPE_IPv4) {parse (frame.payload ());return datagram;
但是如果这是一个ARP探针,我们首先对其进行分析
1 2 3 4 5 6 7 parse (frame.payload ());
其中_update_arp_table用于更新arp表,具体代码如下
1 2 3 4 5 6 void NetworkInterface::_update_arp_table(initializer_list<ArpEntry> arp_entry) {for (auto &entry : arp_entry) {
在解析了网络帧之后,我们大致可以得到以下三种分类
丢弃过滤
1 2 3 4 if (dst.raw_ip_addr != _ip_address.ipv4_numeric ()) {return {};
返回我们的MAC地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (arp_msg.opcode == ARPMessage::OPCODE_REQUEST) {ipv4_numeric ();header () = {src.eth_addr, _ethernet_address, EthernetHeader::TYPE_ARP};payload () = reply.serialize ();push (reply_frame);return {};
更新自己的ARP映射表,同时检查是否有对应目标MAC地址的报文等待发送
1 2 3 4 5 6 7 8 9 for (auto entry = _probe_table.begin (); entry != _probe_table.end ();) {if (entry->first.raw_ip_addr == src.raw_ip_addr) {send_datagram (entry->first.datagram, Address::from_ipv4_numeric (entry->first.raw_ip_addr));erase (entry);else {
在这里我们只需要做两件事
对于正常的条目和探针,我们只需要让其TTL减少即可,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void NetworkInterface::tick (const size_t ms_since_last_tick) for (auto entry = _arp_table.begin (); entry != _arp_table.end ();) {if (entry->second < ms_since_last_tick) {erase (entry);else {for (auto entry = _probe_table.begin (); entry != _probe_table.end (); entry++) {if (entry->second < ms_since_last_tick) {ipv4_numeric ();header () = {ETHERNET_BROADCAST, _ethernet_address, EthernetHeader::TYPE_ARP};payload () = re_probe_arp.serialize ();push (re_probe_frame);else {
这个实验主要实现的逻辑都是数据链路层的,和之前几个Lab没有直接的关系。不过值得一提的就是在Lab4测试的时候运行的TUN和TAP很有意思。这两个词之前好奇还是在使用Clash的时候既可以是TUN也可以是TAP模式,而且通常来说TUN模式的性能要比TAP要好。当时还不知道为什么,在写完这个实验以后搜了一些资料,目前浅显的理解大致认为是TAP的网络代理模拟是有处理到数据链路层的,也就是MAC地址也进行了模拟,而TUN则只是模拟到了IP层,并没有自己的MAC地址,因此损耗也要少一些。
CS144-Lab5 计算机网络:Network Interface的功能
https://halc.top/p/db490294
博客在允许 JavaScript 运行的环境下浏览效果更佳
Shell:管道符与重定向 - Halcyon Zone
到目前位置自己还没专门花时间研究过Linux上那些日日都在用的工具(如Shell和Vim)他们本来的用法和含义,本来觉得没必要,不过在看了missing-semester之后顿时感觉效率提高了不少。因此做一个笔记,把一些很实用但是自己并不会去关注的简单用法给记录一下。
在使用最基础的bash作为命令行的时候,常常能发现用户后面有的时候是$二有的时候是#
1 2 [halc@Zephyrus blog]$ su
这里$代表了当前用户为普通用户,而#的含义则代表当前是在root用户下
在shell程序中,程序的执行主要分为 输入流 和 输出流 两种不同的流,程序会从输入流中读取信息,然后在通过处理之后打印到输出流当中。
以cat为例,其作用为将一个文件的内容打印到输出流当中,通过使用 > file 和 < file 来对流进行重定向,可以覆写或者创建对应内容的文件
1 2 3 4 5 6 7 8 # 将我存于github的pubkey打印输出成id_rsa.pub文件 # 将id_rsa.pub的内容重定向 **追加** 到authorized_keys当中 # 将id_rsa.pub的内容先重定向给cat ,再由cat 输出到pubkey当中
拓展补充 1:所有的Linux进程都包含3个文件描述符,分别是 标准输入 ,标准输出 和 错误输出 。<或<<来操作>或>>来操作2>或2>>来操作
补充拓展 2:>/dev/null 2>&1和2>&1 >/dev/null的区别
对于>/dev/null 2>&1是指先将标准输出指向黑洞设备,然后再将错误输出指向标准输出的指向内容(此时是黑洞),因此标准输出和错误输出都将不输出 对于2>&1 >/dev/null是先将错误输出指向标准输出(此时为屏幕),然后将标准输出指向黑洞,因此此时错误输出将打印到屏幕,而标准输出将不输出 1 2 # 运行example.sh,并将标准输出重定向至stdout.log,将错误输出重定向至stderr.log
以一个简单的test.cpp程序为例
1 2 3 4 5 6 7 8 #include <iostream> using namespace std;int main () "This is stand output" << endl;"This is error output" << endl;return 0 ;
通过编译并重定向运行
1 2 3 4 5 6 7 8 [halc@Zephyrus ~]$ g++ test.cpp -o test
如果希望将对应的文件描述符关闭的话有两种方法
1 2 3 4 # $-指关闭对应的文件操作符 # /dev/null为linux内的黑洞设备
对于>操作符,首先会判断右侧的文件是否存在,如果存在就删除再创建,如果不存在则直接创建,并且右侧的文件一定会置空。 一条命令执行前会检查0,1,2三个I/O设备是否正常,如果异常则不会进行命令执行 如果想要将内容输出重定向到某个文件,以cat举例有两种不同的办法
1 2 3 4 # 将read.md的内容重定向至write.md # "<< EOF" 指对流进行重定向输入,直到遇到"EOF" (可修改)作为末尾则结束
摘自:How does “<<” operator work in linux shell?
<< 操作符主要有以下三个操作逻辑
首先执行该操作符左侧的程序,在上面的例子中就是cat 抓取用户包括换行等所有的输入内容,直到输入的内容为用户指定的EOF结尾内容(在上面的例子中则恰好也是EOF)则停止 将所有除了EOF的内容都作为(1)程序的标准输入执行 实例:通过bash脚本创建一个test.cpp文件
1 2 3 4 5 6 7 8 9 10 11 #!/bin/bash cat > test.cpp << EOF #include<iostream> using namespace std; int main() { cout << "This is stand output" << endl; cerr << "This is error output" << endl; return 0; } EOF
1、文件类型上
2、管道触发两个子进程执行 “|” 两边的程序,而重定向是在一个进程内执行。
1 2 3 4 5 $ (sed -n '1,$p' | grep -n 'output' ) < test.cpp # 等价于 sed -n '1,$p' < test.cpp | grep -n 'output' # 对于管道运算符,如果希望将`test.cpp`传递给前面的第一个可执行文件`sed`,则需要使用单括号将整个管道传输看作一个单独的指令,否则`test.cpp`将传入`grep`内
由于标准输入和标准输出在管道运算符中的重定向是发生在"内容输出"之前的,因此可以通过重定向来修改管道中传输的数据
Because pipeline assignment of standard input or standard output or both takes place before redirection, it can be modified by redirection.
举个例子来说,本来管道传输默认只传输标准输出的内容,并不会传输错误输出
1 [halc@Zephyrus ~]$ command1 2>&1 | command2
通过上面的指令,首先command1的 错误输出 会在执行前被重定向至标准输入,然后command1执行,将 标准输出 和 错误输出 一并通过管道进行传输,作为command2的标准输入
1 2 3 4 # 首先将test.sh的内容通过cat 打印到标准输出, 然后管道传输该输出给tee , # 在tee 执行之前通过&>将tee 的标准输入和错误输出都重定向至/dev/null中, # 然后执行tee 将管道获取的内容写入text.txt,并且将相同的内容写入null设备当中
> 输出重定向,往往在命令最右边(也可以用到命令中间),接收左边命令的输出结果,重定向到指定文件。
1 2 3 4 5 6 7 8 # 如果管道符左侧的程序已经将标准重定向指向了其他文件,那么在bash中管道传输的数据将为空 # 此时无输出 # 但是log 内应该是有内容匹配的
在自己实验的时候发现zsh下即使重定向了标准输出和错误输出依旧可以通过管道读取内容,这主要是zsh有一个可以将输出重定向给多个文件的特性,对于管道也会进行二次传递
参考 Redirection and pipe behavior in bash vs. zsh
Read the MULTIOS documentation in the zshmisc man page. It’s a feature of zsh which causes it to redirect the output to multiple files at the same time, and it can also be a pipe.
具体举例
上面这个命令在bash当中只有文件a会有内容,而b中并没有获取到标准输出。但是在zsh下执行上面的命令,则a和b中都会拥有相同的输出内容。
Shell:管道符与重定向
https://halc.top/p/db6cc46f
博客在允许 JavaScript 运行的环境下浏览效果更佳
Ubuntu禁用系统休眠 - Halcyon Zone
由于用笔记本做服务器的时候并不需要屏幕显示,并且屏幕显示会带来多余的耗电,于是就想试着把笔记本屏幕关上的同时能让Ubuntu Server正常运行,而不是进入休眠模式,索性在网上查阅资料以后发现并不是很困难,以此在这里记录需要修改的操作以便以后查阅
修改logind.conf文件
sudo vim /etc/systemd/logind.conf
修改logind.conf中的选项,使得笔记本忽略关闭屏幕对系统的影响
将原本的
改为
1 2 HandleLidSwitch=ignore HandleLidSwitchExternalPower=ignore
使用reboot指令来重启电脑即可。
Ubuntu禁用系统休眠
https://halc.top/p/dea4f344
博客在允许 JavaScript 运行的环境下浏览效果更佳
OSTEP:进程的概念理解 - Halcyon Zone
作业来自: ostep-homework
两个程序都只使用CPU,所以CPU的利用率是100%,测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Time PID: 0 PID: 1 CPU IOs
总共使用了11 ticks的时间,测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 Time PID: 0 PID: 1 CPU IOs
交换顺序后,在PID0进行io操作的时候,PID1会切换成RUNNING的状态,提高了CPU的利用效率,所以交换顺序重要。测试可得:
1 2 3 4 5 6 7 8 Time PID: 0 PID: 1 CPU IOs
由于加上了SWITCH_ON_END的标签,此时PID0进行IO操作的时候CPU会空闲等待至IO操作完成,浪费了一定的时间。测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 Time PID: 0 PID: 1 CPU IOs
由于这次会在等待IO的时候进行进程的切换,所以在io操作时,CPU没有等待,而是切换到了另外一个进程上继续工作,提高了利用率。测试可得:
1 2 3 4 5 6 7 8 Time PID: 0 PID: 1 CPU IOs
由于IO操作的优先级不是最高的,即使io操作的WAITING结束了,也会等待CPU先将其他进程执行之后,再对IO进行切换,由于IO操作需要消耗比较多的额外时间,而这部分时间没有被CPU利用,所以系统资源没有得到有效利用。测试可得:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Time PID: 0 PID: 1 PID: 2 PID: 3 CPU IOs
在使用了IMMEDIATE标签后,每次io_done之后CPU都会先切换io操作,然后用io处理的时间来处理其他进程,提高了系统资源的利用率。测试如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Time PID: 0 PID: 1 PID: 2 PID: 3 CPU IOs
开放题随机,和前七题大致相同。
OSTEP:进程的概念理解
https://halc.top/p/e328a303
博客在允许 JavaScript 运行的环境下浏览效果更佳
知识复盘:操作系统的作用 - Halcyon Zone
该部分博客为自己在学习《程序员的自我修养:链接、装载与库》的时候对于过去零碎知识点的一个整理和复盘,并非照搬原文,其中会加入一些自己的联想与理解,如有错误还请指出。
操作系统在计算机中主要有两个功能:
在计算机的使用过程中,需要消耗时间的任务部分大致可以分为两种情况:
消耗CPU算力的计算密集型操作 需要等待设备响应处理的I/O密集型操作 我们知道在计算机中有南桥和北桥两个概念,北桥连同了CPU等高速芯片,而南桥则负责了磁盘、鼠标、键盘等低速设备。因此我们可以抽象出一个结论:计算密集型操作 和 I/O密集型操作 是由不同的设备分别处理的。接下来对于操作系统调度分析则会都以这一前提条件进行分析。
假设我们现在需要完成一个很复杂的数学问题,且假设完成这个数学问题分为两个步骤:
在草稿纸上"随意"的打草稿并推演计算过程,最终计算出答案(计算密集型操作) 将整个推演过程有条理并工整的誊抄在答卷上,便于他人阅读自己的答案(I/O密集型操作) 那么如果我们有很多个这样的题目需要完成。那么最高效的方法自然是分配两个同学A和B。假设同学A的计算能力很强,同学B的书写则十分端正,同时可以看懂同学A的草稿,那么我们便可以让同学A只需要负责计算和打草稿,只要做完了第一题就直接开始写第二题,而同学B则在同学A开始计算第二题的过程中开始誊抄第一题的答案。这样便可以让同学A和同学B的时间都统筹利用起来,以此提升效率。
在计算机中也是同样的道理。在计算机刚刚发展的时候,每次执行一个任务都需要先让CPU计算完后,CPU还要等待诸如打印机等设备输出了结果以后,再进行下一个问题的计算。
为了解决这个问题,人们便想到使用一个监控程序来监管CPU的运算,当监控程序发现在CPU进行完毕某一次运算以后,如果后续还有其他问题需要使用CPU进行计算的话,则让CPU直接进行下一个问题的计算,而不是等待第一个问题的I/O操作进行完毕以后再进行第二个问题的计算。这就是多道程序的雏形
但是随着计算机功能的逐步发展,多道程序则体现出了一个弊端:那就是任务的执行需要所有人都依次排队,前面的人如果没有解决他的问题就轮不到下一个人。
假设在银行中有一个人的业务处理需要花费特别特别长的时间,从而导致后面所有人直到银行下班都没完成自己的业务,这无疑是非常令人恼火的一件事情。但是如果这个人将自己的一个任务拆分成多个不同的部分,每完成一个部分就让后面的人先处理下,这样相对而言就能顾及他人的感受,有利于提高处理问题数量的效率。
因此,我们就了分时系统的概念,在分时系统中,程序可以通过在编写的时候主动调用某个“系统调用”来实现通知操作系统我现在这部分的工作已经完成了一部分,如果后面有其他任务需要执行的话可以先执行其他的任务,再来执行我的任务。从而在一定程度上解决了阻塞问题。
但是分时系统在计算机的衍变过程中也展现出了自己的弊端。
依据以下两个分时系统 的特点:
是否让出CPU是由程序自身决定的。程序需要主动调用特定的系统调用来通知操作系统它愿意让出CPU。 这种机制的问题是,如果一个程序不主动让出CPU(例如,由于编程错误或恶意行为),那么操作系统不能强制地从该程序中夺回CPU控制权。因此,其他程序可能会被迫等待,导致整个系统的响应性下降。 假设我们遇到一个程序员在程序中忘记调用分时的“系统调用”,还写了一个死循环的错误代码。那么整个操作系统都将会因为这个问题而出现宕机。
由此我们就需要一个更高端的操作系统来解决我们的问题,即现代操作系统的解决方案:多任务系统。
多任务系统 的基础是建立在此时操作系统对所有硬件资源进行了直接的接管。而所有的应用程序都以进程(Process)的方式运行在操作系统这个大Boss之下。所有进程的调度都需要受到操作系统的管理,并且每个进程和进程之间就像是一个小房间,他们的地址空间也都是相互隔离且独立的。
在这种情况下,CPU就变成了操作系统大Boss来进行管理的一个资源,而不是和之前分时系统一样由应用自己直接对CPU进行管理了。这样的好处是可以让所有程序都听操作系统这个领导的话,而不是和之前一样我想一直占用CPU就一直占用,如果我不调用接口主动释放CPU你们谁都别想用上CPU。
对于操作系统来说,每个进程就是一个任务,每个任务则又有自己的任务优先级。对于优先级高的任务,操作系统会先进行;对优先级低的任务则后执行。如果一个进程的运行时间超过了某个限制,则会将该程序暂停以分配给其他同时间内也许更需要CPU资源的线程任务。
在此基础上还会牵扯到一些诸如多级反馈队列、上下文切换开销等问题。这里就不做过多的展开。
这里放一个之前写OSTEP课后实验相关的博客链接,便于自己查阅
有关于设备驱动的内容直接概述过于枯燥无味,因此下面这段解释为使用 GPT-4 生成的一个概述,觉得生动有趣就搬上来了
想象一下,你正在玩一个超级复杂的电子游戏,但你只需要按下一个按钮,就能完成一个复杂的动作,比如打怪兽或跳跃。这个按钮就像是操作系统,而那些复杂的动作就是硬件的操作。你不需要知道每一个细节,只需要按下按钮,游戏就会为你完成所有的事情。
操作系统就是这样的“神奇按钮”。它位于硬件之上,为上层的应用程序提供了一个统一的方式来访问硬件。想象一下,如果每次你想在屏幕上画一条线,都需要知道你的电脑使用的是什么显卡、屏幕的大小和分辨率,然后写一大堆复杂的代码。这听起来很麻烦,对吧?但是,有了操作系统,你只需要调用一个简单的函数,比如LineTo(),然后操作系统会为你处理所有的细节。
在操作系统的早期,程序员确实需要直接与硬件交互,这是一件非常繁琐和复杂的事情。但随着时间的发展,操作系统逐渐成熟,它开始为程序员提供了一系列的“抽象”概念,使得程序员可以更加轻松地开发应用程序,而不需要关心硬件的细节。比如,在UNIX系统中,访问硬件设备就像访问普通文件一样简单;在Windows系统中,图形和声音设备被抽象成了特定的对象。
但是,谁来处理这些复杂的硬件操作呢?答案是:硬件驱动程序 。它们是操作系统的一部分 ,专门负责与特定的硬件设备交互。这些驱动程序通常由硬件制造商开发,而操作系统提供了一系列的接口和框架,使得这些驱动程序可以在操作系统上运行。
最后,让我们以读取文件为例。当你想读取一个文件时,你不需要知道这个文件在硬盘上的具体位置。你只需要告诉操作系统你想读取的文件名,然后操作系统会找到这个文件在硬盘上的位置,读取它,并将数据返回给你。这一切都是由文件系统和硬盘驱动程序共同完成的。
总之,操作系统就像是一个超级英雄,它为我们处理了所有复杂的硬件操作,使得我们可以更加轻松地开发和使用计算机程序。
知识复盘:操作系统的作用
https://halc.top/p/e429c37a
博客在允许 JavaScript 运行的环境下浏览效果更佳
二分查找 - Halcyon Zone
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int bsl (int l, int r) while (l < r)int mid = l + r >> 1 ;if (check (mid)) else 1 ; return l;int bsr (int l, int r) while (l < r)int mid = l + r + 1 >> 1 ;if (check (mid)) else 1 ;
bsl为例 二分的主要的作用,是取得一个“分界点”。采取的思路为测试中间点是否符合条件,如果不符合则对区间进行缩小操作,重新测试区间,直到区间为一个数字。在模板一中,首先确定中间点mid,然后测试中间点mid是否符合条件,如果符合条件,则每次都会 将区间的右端点进行左移的操作,直到不能左移为止 ,所以返回的最后位置为最接近答案的最左边的端点 。如果不符合条件,由于**确定了mid的位置为无效位置,所以下一次刷新区间的时候将mid剔除掉。**剔除的操作可以达到防止死循环的效果
由于二分是每次都将一个区间一分为二,并且对整个区间进行一次操作,所以最后的时间复杂度为O(logN)
在bsr中,由于在每次正确的时候修改的都是左边界l,但是在计算除2的时候会存在mid/2取整为l的情况,这样会导致最后结果的死循环。所以需要定义mid为mid = l+r+1>>1来避免死循环。可以记为 返回右边界的时候需要+1,因为右边比左边大(bushi 二分查找
https://halc.top/p/e8eb0481
博客在允许 JavaScript 运行的环境下浏览效果更佳
获取Cloudflare Tunnel下用户真实IP - Halcyon Zone
部署在内网中,在80端口部署了PHP的服务器一台。 使用了Cloudflare Tunnel对内网http://127.0.0.1进行了转发,并提供https支持 SSPanel需要拥有https的情况下才可以正常使用,但是使用Cloudflare Tunnel默认的设置的情况下,所有的用户登入请求都会被记录为Tunnel的转发地址(在这种情况下即127.0.0.1)。
在这种情况下,当用户通过Tunnel访问我的网站时,Cloudflare会通过CF-Connecting-IP这个HTTP请求头传递原始访问者的IP地址。因此也就可以通过修改Nginx配置的方法来获取到对应用户的真实IP地址了。
先在这里贴上修改了的配置文件和注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 server {listen 80 ;listen [::]:80 ;root /path/to/site/public;index index.php;server_name your.domain.com;set_real_ip_from 127.0.0.1 /32 ; real_ip_header CF-Connecting-IP;location / {try_files $uri /index.php$is_args $args ;location ~ \.php$ {try_files $fastcgi_script_name =404 ;include fastcgi_params;fastcgi_index index.php;fastcgi_buffers 8 16k ;fastcgi_buffer_size 32k ;fastcgi_pass unix:/run/php/php-fpm.sock;fastcgi_param DOCUMENT_ROOT $realpath_root ;fastcgi_param SCRIPT_FILENAME $realpath_root $fastcgi_script_name ;fastcgi_param REMOTE_ADDR $remote_addr ;
对于上面修改的不同配置项的作用如下
set_real_ip_from 127.0.0.1/32;
set_real_ip_from指令用于指定哪些IP地址可以设置真实IP地址。在这种情况下,127.0.0.1/32表示本地地址。这是因为Cloudflare Tunnel将流量转发到您的本地服务器,通常表现为来自127.0.0.1(即本地主机)的请求。 这条指令告诉Nginx,如果请求来自本地主机(127.0.0.1/32),则应该考虑使用另一个HTTP头中的IP地址作为访问者的真实IP地址。 real_ip_header CF-Connecting-IP;
real_ip_header指令用于指定包含真实客户端IP地址的HTTP头。CF-Connecting-IP是由Cloudflare设置的一个特殊的HTTP头,它包含了发起请求的原始访问者的IP地址。通过这个配置,Nginx将使用CF-Connecting-IP头中的值来重写访问者的IP地址,这样PHP应用程序就可以获取到访问者的真实IP,而不是Cloudflare Tunnel的本地地址。 在PHP FastCGI 配置块中添加的指令:
fastcgi_param REMOTE_ADDR $remote_addr;这一行将Nginx内部变量$remote_addr的值传递给FastCGI进程。由于我们已经使用set_real_ip_from和real_ip_header配置了Nginx,$remote_addr将包含经过Cloudflare处理的真实客户端IP。 通过将此参数传递给FastCGI(在这种情况下是PHP-FPM),在PHP应用程序中的$_SERVER['REMOTE_ADDR']将包含正确的客户端IP地址。 获取Cloudflare Tunnel下用户真实IP
https://halc.top/p/f09b73d7
博客在允许 JavaScript 运行的环境下浏览效果更佳
Windows上通过Scoop管理和安装软件 - Halcyon Zone
「一行代码」搞定软件安装卸载,用 Scoop 管理你的 Windows 软件 Scoop - 最好用的 Windows 包管理器 - P3TERX ZONE 在知道并安装Scoop的时候只是稍微听说过winget-cli一类的工具,不过由于一直对Windows系统的软件管理早就绝望,下意识的认为对Windows来说,这种终端的程序管理应该几乎没什么用。但在前几天偶然希望在Windows Terminal上寻找一个类似Linux的sudo的程序,发现了Scoop这个神器,并且在使用了一两天尝到甜头后,决定写一篇博客把大概的使用功能都记录一下。
安装在联网的情况下有直接的指令,但是安装之前需要保证环境满足以下要求:
Windows 的版本不低于 Windows 7 Windows 的 PowerShell 版本不低于 PowerShell 3 拥有能自由前往Github,保证传输稳定的网络环境 Windows的用户名为英文或者数字(非中文)用户名 Scoop默认情况下和Linux中一样,只有普通用户的权限,其中Scoop本身和他默认安装的软件,会安装在%USERPROFILE\scoop目录下,使用管理员权限进行全局安装的软件会在C:\ProgramData\scoop目录下。
打开PowerShell
设置用户的安装路径
1 2 $env:SCOOP ='\PathTo\' Environment ]::SetEnvironmentVariable('SCOOP' , $env:SCOOP , 'User' )
设置全局安装的路径
1 2 $env:SCOOP_GLOBAL ='\PathToGlobal\' Environment ]::SetEnvironmentVariable('SCOOP_GLOBAL' , $env:SCOOP_GLOBAL , 'Machine' )
然后就可以开始愉快的安装了。
在PowerShell中输入以下内容,来保证本地脚本的执行:
1 set-executionpolicy remotesigned -scope currentuser
用下面的命令来安装Scoop
1 iex (new-object net.webclient).downloadstring('https://get.scoop.sh' )
安装完成,可以通过以下指令来查询帮助
由于网络可能有的时候不稳定,大部分Scoop的软件在安装的时候可能会出现安装失败的情况,就需要我们自己手动进行代理的设置,设置代理的命令如下:
1 scoop config proxy [IP /DNS ]:[端口]
aria2
常用的强力下载工具,设置好aria2的conf文件并创建session文件,配合以下vbs脚本,创建快捷方式以后,在Win+R后运行Shell:Common Startup,将快捷方式放于其中,就可以当日用的下载工具了。
VBScript:
1 CreateObject ("WScript.Shell" ).Run "aria2c.exe --conf-path=aria2.conf" ,0
在安装完毕aria2后,scoop会默认用aria2来下载所有其他的软件,如果有的时候发现aria2下载不好使了,可以通过下面的指令来禁用aria2下载
1 scoop config aria2-enabled false
另外参考P3TERX大佬的博客中,其他选项可以按如下设置:
单任务最大连接数设置为 32,单服务器最大连接数设置为 16,最小文件分片大小设置为 1M
1 2 3 >scoop config aria2-split 32 -max-connection-per-server 16 -min-split-size 1 M
sudo
一个提权工具,可以让Windows下实现和Linux类似的提权效果
git
应该没啥好说的,必备安装。
nerd-fonts字体
在终端美化中常见的一种Powerline字体,使用以下指令添加库然后就能安装
1 scoop bucket add nerd-fonts
查询可以用的所有字体
因为安装字体需要管理员权限,所以需要添加sudo,指令如下(以Hack NF为例)
1 sudo scoop install Hack-NF
LANDrop 局域网文件分享
一个很好用的局域网文件共享工具,可以高速在不同系统平台之间分享文件。
大部分的使用帮助通过scoop help命令都可以直接列出并查看,常见的search、install、update和uninstall等指令不多做赘述。这里提供一些常见自己需要查阅的指令,以供日后使用参考。
Scoop 会保留下载的安装包,对于卸载后又想再安装的情况,不需要重复下载。但长期累积会占用大量的磁盘空间,如果用不到就成了垃圾。这时可以使用 scoop cache 命令来清理。
scoop cache show - 显示安装包缓存scoop cache rm <app> - 删除指定应用的安装包缓存scoop cache rm * - 删除所有的安装包缓存如果你不希望安装和更新软件时保留安装包缓存,可以加上 -k 或 --no-cache 选项来禁用缓存:
scoop install -k <app>scoop update -k *当软件被更新后 Scoop 还会保留软件的旧版本,更新软件后可以通过 scoop cleanup 命令进行删除。
scoop cleanup <app> - 删除指定软件的旧版本scoop cleanup * - 删除所有软件的旧版本与安装软件一样,删除旧版本软件的同时也可以清理安装包缓存,同样是加上 -k 选项。
scoop cleanup -k <app> - 删除指定软件的旧版本并清除安装包缓存scoop cleanup -k * - 删除所有软件的旧版本并清除安装包缓存全局安装就是给系统中的所有用户都安装,且环境变量是系统变量,对于需要设置系统变量的一些软件就需要全局安装,比如 Node.js、Python ,否则某些情况会出现无法找到命令的问题。
使用 scoop install <app> 命令加上 -g 或 --global 选项可对软件进行全局安装,全局安装需要管理员权限,所以需要提前以管理员权限运行的 PowerShell 。更简单的方式是先安装 sudo,然后用 sudo 命令来提权执行:
1 2 scoop install sudo
达成在 Windows 上使用sudo的成就
使用 scoop list 命令查看已装软件时,全局安装的软件末尾会有 *global* 标志。
此外对于全局软件的更新和卸载等其它操作,都需要加上 -g 选项:
sudo scoop update -g * - 更新所有软件(且包含全局软件)sudo scoop uninstall -g <app> - 卸载全局软件sudo scoop uninstall -gp <app> - 卸载全局软件(并删除配置文件)sudo scoop cleanup -g * - 删除所有全局软件的旧版本sudo scoop cleanup -gk * - 删除所有全局软件的旧版本(并清除安装包包缓存)Windows上通过Scoop管理和安装软件
https://halc.top/p/f15c20eb
博客在允许 JavaScript 运行的环境下浏览效果更佳
Linux通过修改init.d脚本自启动脚本 - Halcyon Zone
创建脚本文件,这里以startup.sh示例
给脚本添加可执行权限,并移动脚本位置
1 2 chmod +x startup.sh
设置为开机脚本
1 2 sudo update-rc.d /etc/init.d/startup.sh defaults 100#
如果需要删除脚本,用remove即可
1 2 sudo update-rc.d /etc/init.d/startup.sh remove
Linux通过修改init.d脚本自启动脚本
https://halc.top/p/f3eca903
博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
+
+
+ https://halc.top/about/index.html
+
+ 2024-01-31
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/css/round.css
+
+ 2024-01-31
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/bb3a9deb
+
+ 2024-01-31
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/b9295ba3
+
+ 2024-01-30
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/59e029c8
+
+ 2024-01-27
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/87299c69
+
+ 2024-01-24
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/f09b73d7
+
+ 2024-01-23
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/4416e368
+
+ 2023-11-28
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/e429c37a
+
+ 2023-10-20
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/3930e42b
+
+ 2023-08-03
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/23c3db21
+
+ 2023-07-30
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/83fa91fc
+
+ 2023-06-19
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/82bd449c
+
+ 2023-06-17
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/195b5fa9
+
+ 2023-04-24
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/db490294
+
+ 2023-04-24
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/4e68707
+
+ 2023-04-10
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/73e1b791
+
+ 2023-04-10
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/aeda2510
+
+ 2023-04-10
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/10e77bc5
+
+ 2023-04-10
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/4457ea2b
+
+ 2022-12-12
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/2ca0860a
+
+ 2022-11-30
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/cdfd3649
+
+ 2022-07-09
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/db6cc46f
+
+ 2022-07-04
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/9232cf7b
+
+ 2022-07-02
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/92f7b8a
+
+ 2022-06-29
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/bbde595d
+
+ 2022-06-28
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/795cfa1d
+
+ 2022-06-07
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/c1ec22c4
+
+ 2022-05-12
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/20416971
+
+ 2022-05-09
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/44838b9c
+
+ 2022-05-08
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/3d85131
+
+ 2022-05-07
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/8d2011c6
+
+ 2022-05-07
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/6088c65c
+
+ 2022-04-30
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/22453a61
+
+ 2022-04-28
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/28ea7a49
+
+ 2022-04-23
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/783d8b13
+
+ 2022-04-20
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/1724953e
+
+ 2022-04-19
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/b3a8b5ef
+
+ 2022-04-18
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/7bfa5e14
+
+ 2022-04-15
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/20c326f2
+
+ 2022-04-13
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/264bf58c
+
+ 2022-04-10
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/13271c5f
+
+ 2022-04-09
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/80f884dc
+
+ 2022-04-07
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/18b05b6b
+
+ 2022-04-05
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/4b65fa48
+
+ 2022-03-25
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/897b63ef
+
+ 2022-03-23
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/840f43e7
+
+ 2022-03-23
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/b9e46cb4
+
+ 2022-03-19
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/cf0fd528
+
+ 2022-03-18
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/a126ef4d
+
+ 2022-03-15
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/e328a303
+
+ 2022-03-12
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/ba5740b2
+
+ 2022-03-06
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/2f2e6810
+
+ 2022-02-08
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/9130a701
+
+ 2022-02-06
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/afb272ac
+
+ 2022-01-29
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/1153f279
+
+ 2022-01-06
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/76495b47
+
+ 2021-12-02
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/2362a8ea
+
+ 2021-12-02
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/98326a13
+
+ 2021-10-29
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/d08cfaf4
+
+ 2021-10-21
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/f15c20eb
+
+ 2021-10-04
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/87ec6922
+
+ 2021-10-03
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/d26abad0
+
+ 2021-09-18
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/447b77e9
+
+ 2021-09-09
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/aa5ce7f4
+
+ 2021-08-30
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/690287f9
+
+ 2021-08-06
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/6d032e05
+
+ 2021-08-04
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/f3eca903
+
+ 2021-08-04
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/14cd2588
+
+ 2021-08-02
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/abf1d877
+
+ 2021-07-22
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/be72c31c
+
+ 2021-07-22
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/39b9efc1
+
+ 2021-06-13
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/c9fc3bb5
+
+ 2021-05-22
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/1dcf9daa
+
+ 2021-05-11
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/1e0fb80b
+
+ 2021-05-10
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/77f84830
+
+ 2021-05-07
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/2f594679
+
+ 2021-05-07
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/cc7f9b10
+
+ 2021-04-30
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/6a6a7409
+
+ 2021-04-27
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/24f916f9
+
+ 2021-04-24
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/a2277ea0
+
+ 2021-04-20
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/15b685e1
+
+ 2021-04-20
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/cff2e0b5
+
+ 2021-04-19
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/e8eb0481
+
+ 2021-04-12
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/713e2886
+
+ 2021-04-06
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/12aa3ef8
+
+ 2021-04-04
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/3efcbb51
+
+ 2021-03-25
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/5a7c7761
+
+ 2021-03-25
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/c1161a88
+
+ 2021-03-24
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/99e48799
+
+ 2021-03-20
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/2dda2597
+
+ 2021-03-17
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/a9706dff
+
+ 2021-03-17
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/41385a4a
+
+ 2021-03-16
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/c9774a05
+
+ 2021-03-15
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/1d3a895d
+
+ 2021-03-14
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/dea4f344
+
+ 2021-03-14
+
+ monthly
+ 0.6
+
+
+
+ https://halc.top/p/15b28479
+
+ 2021-03-14
+
+ monthly
+ 0.6
+
+
+
+
+ https://halc.top/
+ 2024-01-31
+ daily
+ 1.0
+
+
+
+
+ https://halc.top/tags/Markdown/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Frp/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Ubuntu/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Linux/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Vim/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Devc/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/ZeroTier/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Windows/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/OpenWRT/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Docker/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Algorithm/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/SSH/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Nginx/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/CDN/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Minecraft/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/PowerShell/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Scoop/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/cpp/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/zsh/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/%E7%AE%97%E6%B3%95/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/%E6%80%BB%E7%BB%93/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/OS/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Github/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/python/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/os/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/hexo/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/WSL/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Clash/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/qbittorrent/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/jellyfin/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/docker/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/rclone/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/missing-semester/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/shell/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Arch/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/cs144/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/network/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Yadm/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/cmd/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Wireshark/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/DNS/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/iommu/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/cloudflare/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Rathole/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/V2Ray/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/%E5%86%85%E7%BD%91%E7%A9%BF%E9%80%8F/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/tags/Cloud/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+
+
+ https://halc.top/categories/%E7%9F%A5%E8%AF%86%E8%AE%B0%E5%BD%95/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/categories/%E5%AE%89%E8%A3%85%E5%BC%95%E5%AF%BC/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/categories/%E5%B0%8F%E6%8A%80%E5%B7%A7/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
+ https://halc.top/categories/%E4%B8%AA%E4%BA%BA%E6%80%BB%E7%BB%93/
+ 2024-01-31
+ weekly
+ 0.2
+
+
+
diff --git a/tags/Algorithm/index.html b/tags/Algorithm/index.html
new file mode 100644
index 00000000..365ae2a7
--- /dev/null
+++ b/tags/Algorithm/index.html
@@ -0,0 +1,2 @@
+标签 - Algorithm - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Arch - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - CDN - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Clash - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Cloud - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - DNS - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Devc++ - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Docker - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Frp - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Github - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Linux - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Linux - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Linux - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Markdown - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Minecraft - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Nginx - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - OS - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - OS - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - OpenWRT - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - PowerShell - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Rathole - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - SSH - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Scoop - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Ubuntu - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - V2Ray - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Vim - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - WSL - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Windows - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Wireshark - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Yadm - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - ZeroTier - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - cloudflare - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - cmd - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - cpp - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - cs144 - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - docker - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - hexo - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - iommu - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - jellyfin - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - missing-semester - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - network - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - os - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - python - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - qbittorrent - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - rclone - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - shell - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - zsh - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - 内网穿透 - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - 总结 - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
标签 - 算法 - Halcyon Zone 博客在允许 JavaScript 运行的环境下浏览效果更佳
+ {% if posts %}
+ {% for post in posts.toArray() %}
+ {% if post.indexing == undefined or post.indexing %}
+
+ {{ post.title }}
+ {{ [url, post.path] | urlJoin | uriencode }}
+ {% if content %}
+
+ {% for cate in post.categories.toArray() %}
+ {{ cate.name }}
+ {% endfor %}
+
+ {% endif %}
+ {% if post.tags and post.tags.length>0 %}
+
+ {% for tag in post.tags.toArray() %}
+ {{ tag.name }}
+ {% endfor %}
+
+ {% endif %}
+
+ {% endif %}
+ {% endfor %}
+ {% endif %}
+ {% if pages %}
+ {% for page in pages.toArray() %}
+ {% if post.indexing == undefined or post.indexing %}
+
+ {{ page.title }}
+ {{ [url, post.path] | urlJoin | uriencode }}
+ {% if content %}
+
+ {% endif %}
+ {% endfor %}
+ {% endif %}
+





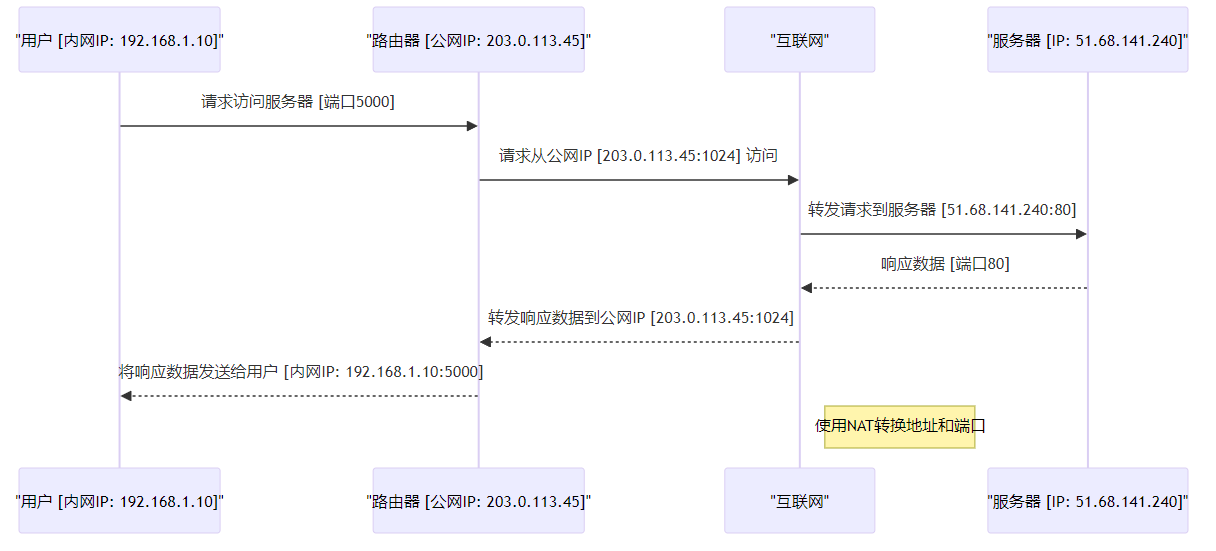
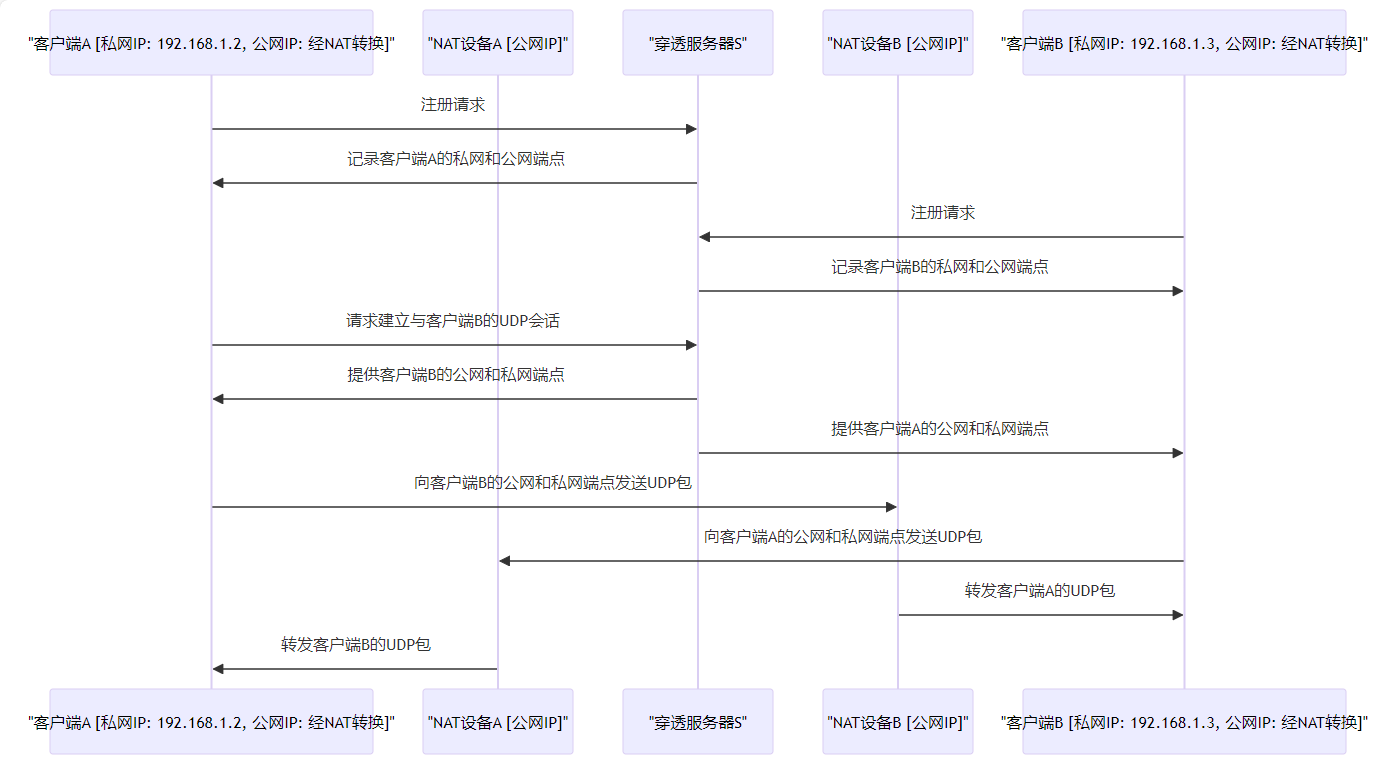
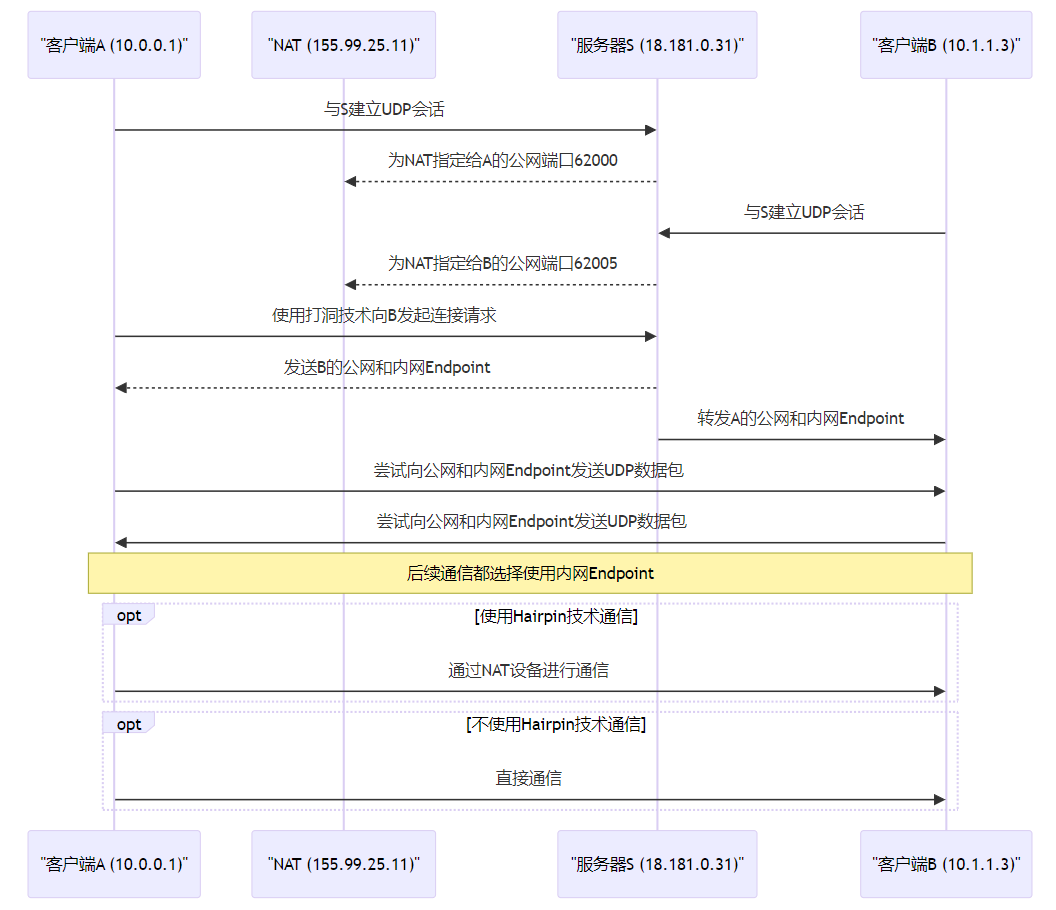
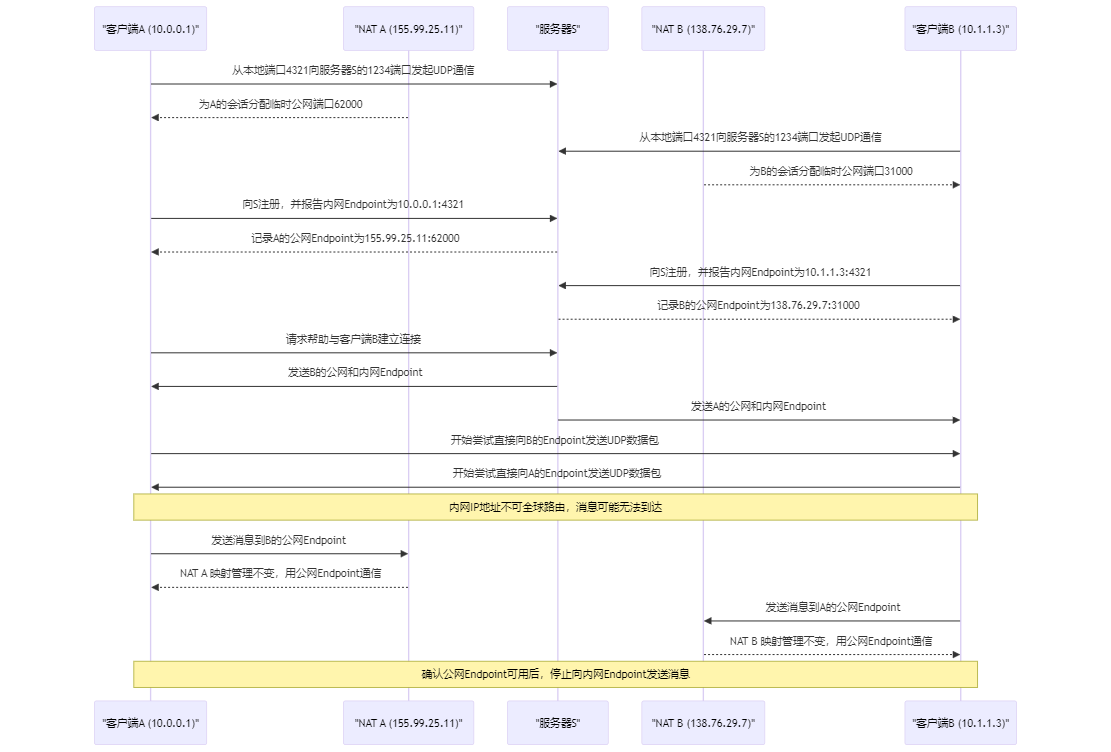
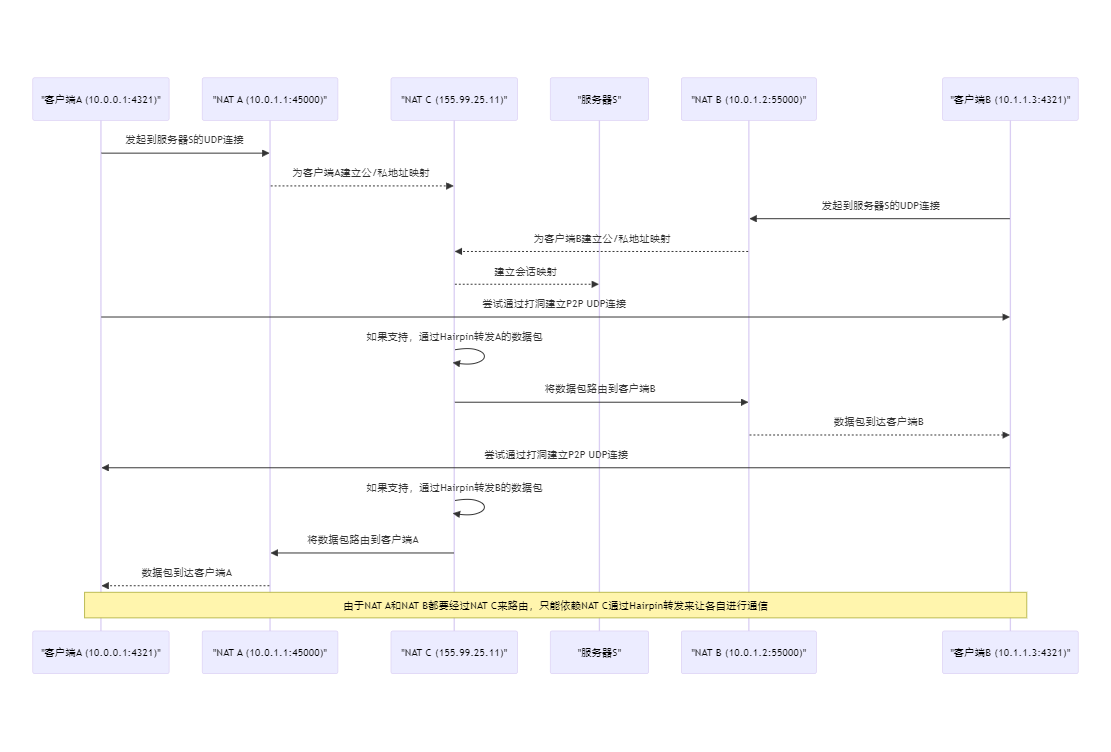
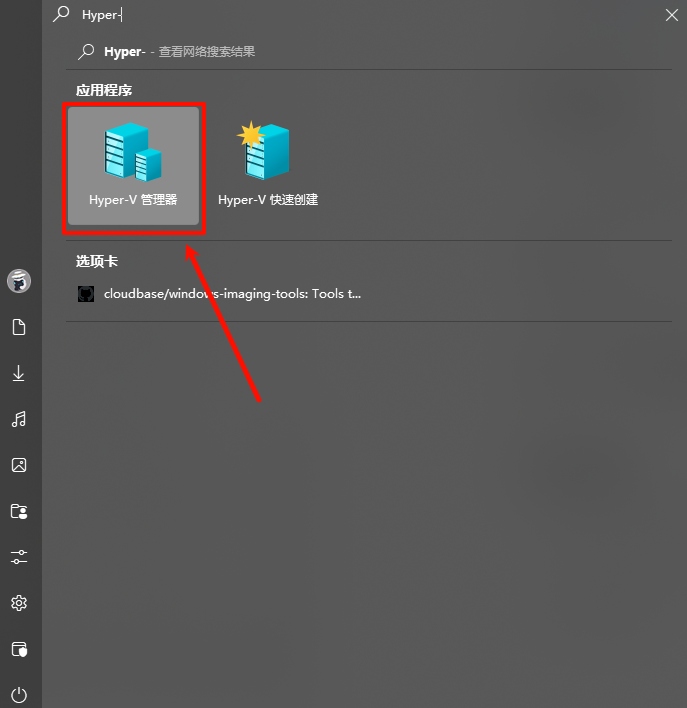
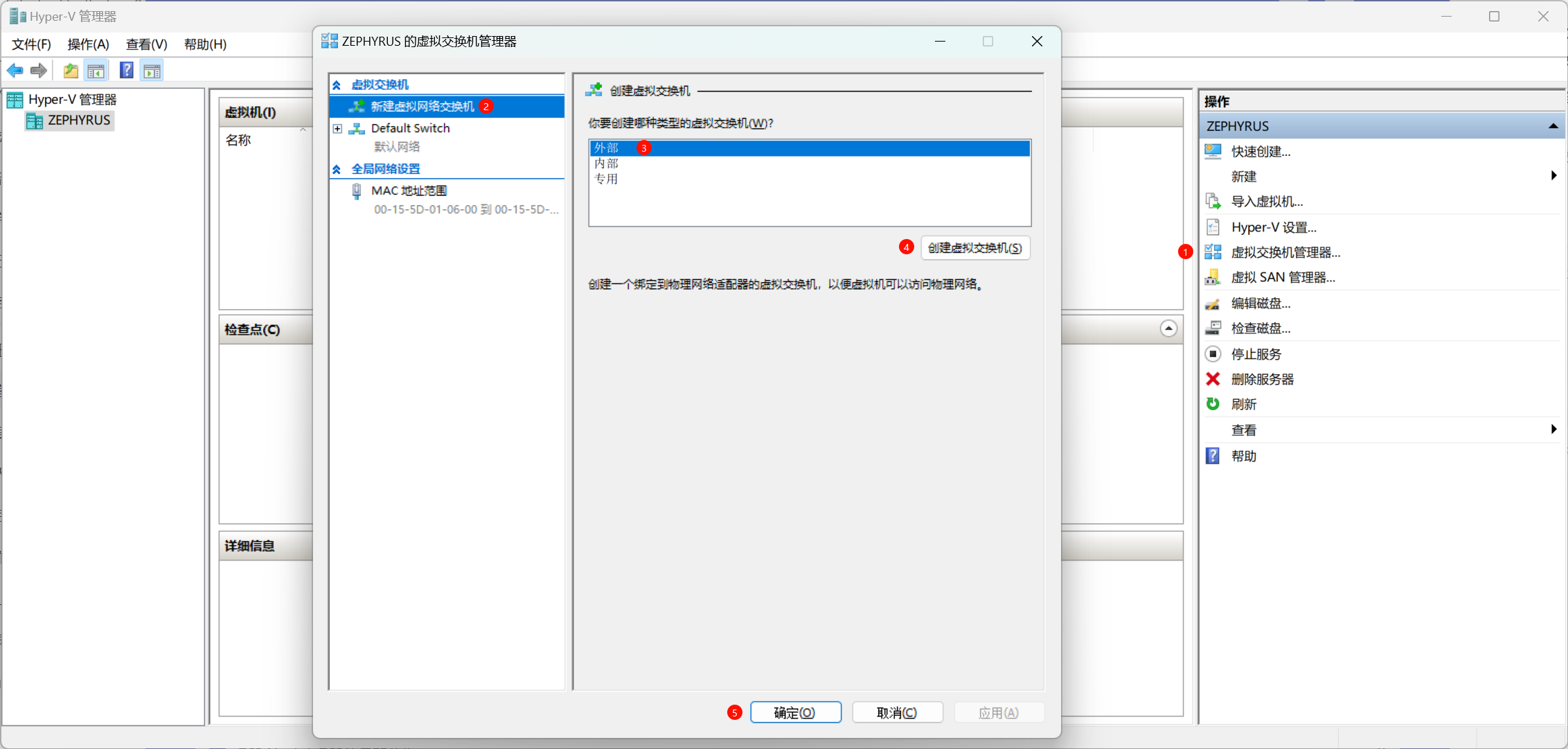
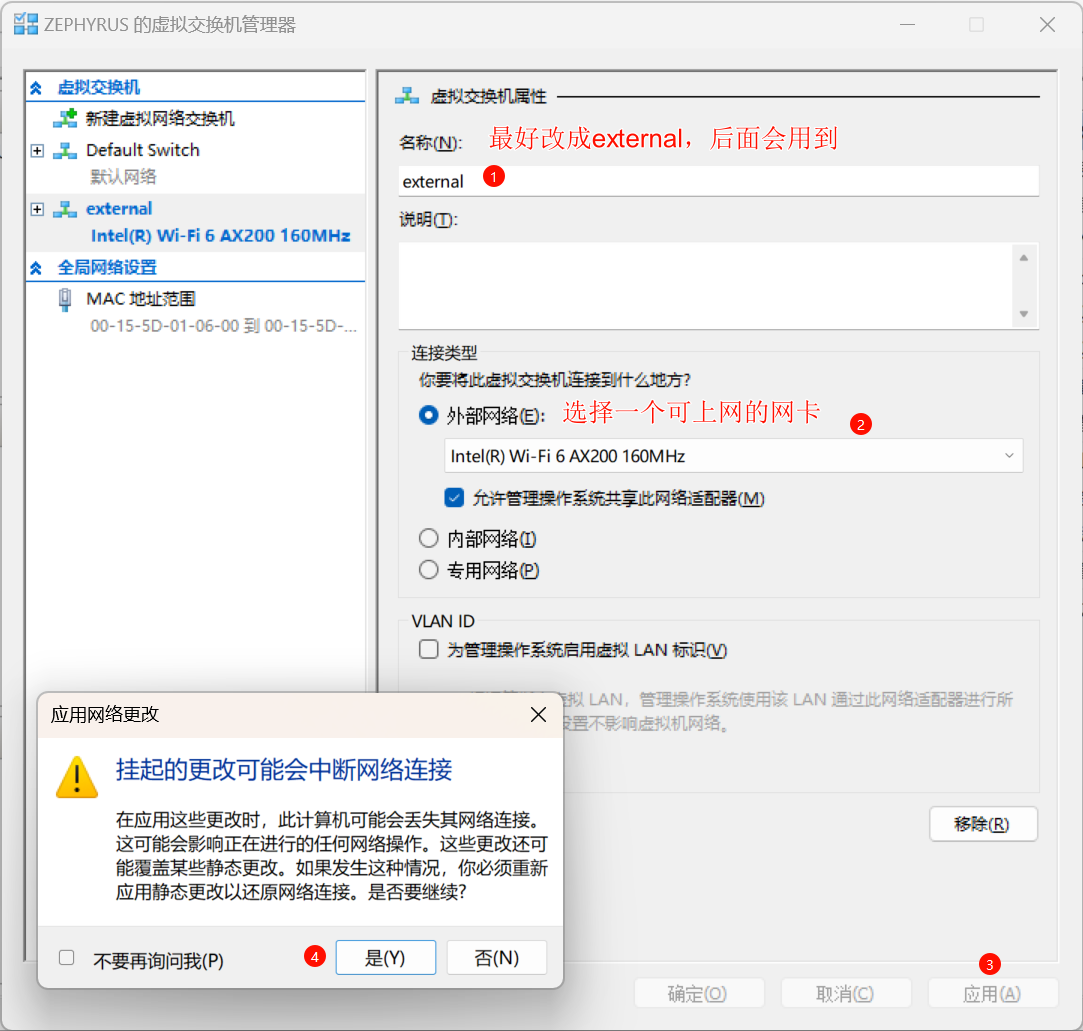
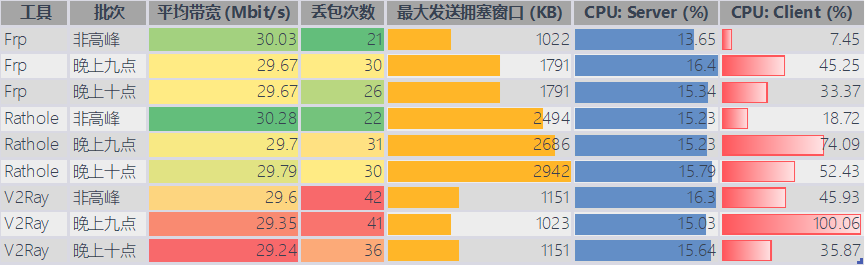
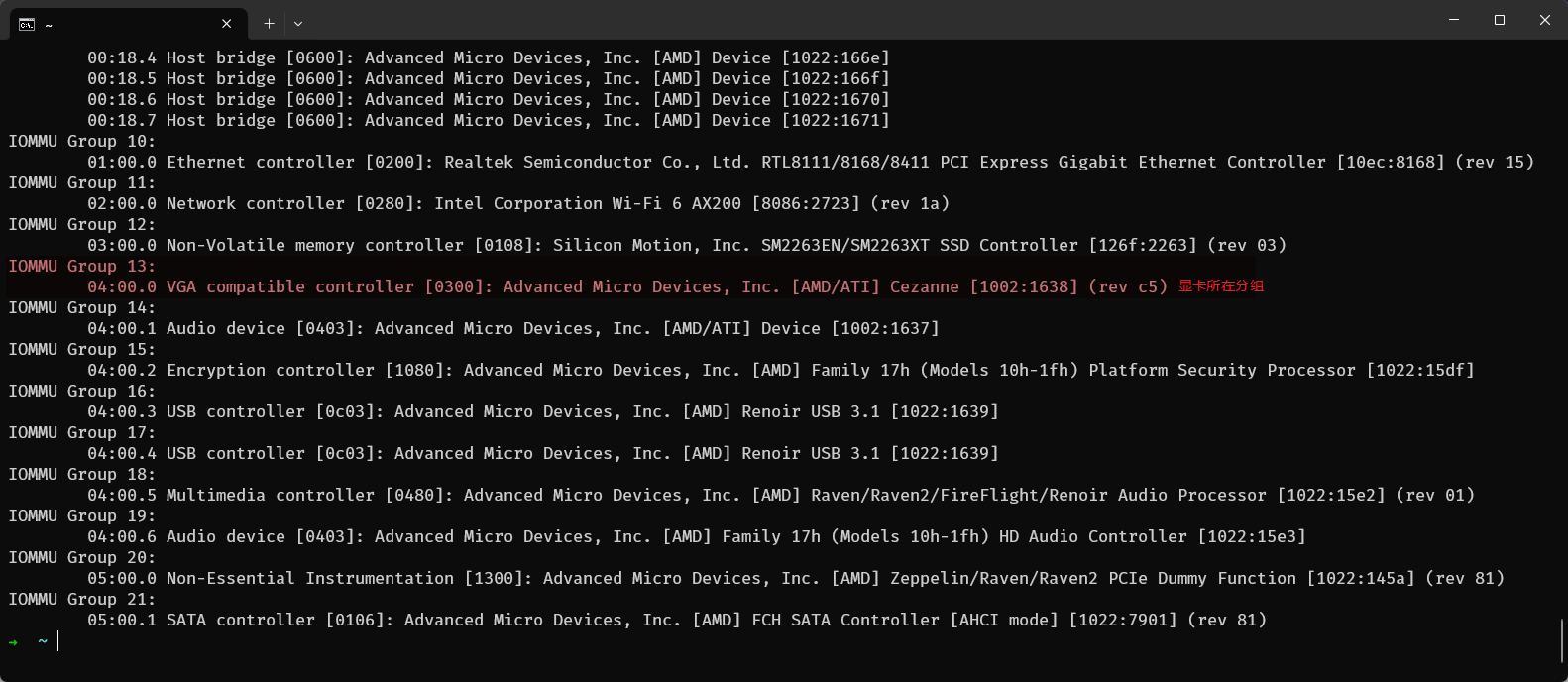
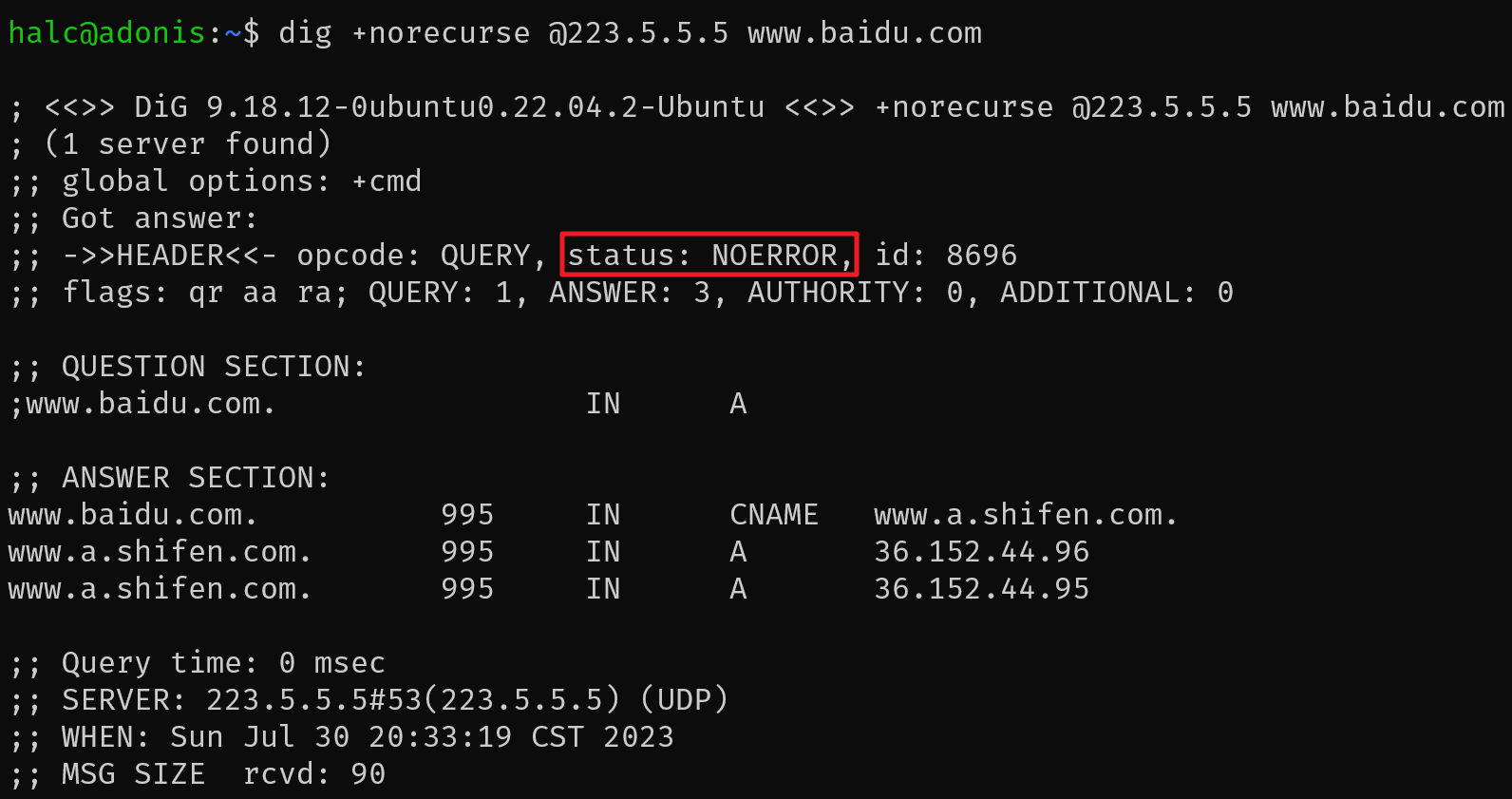
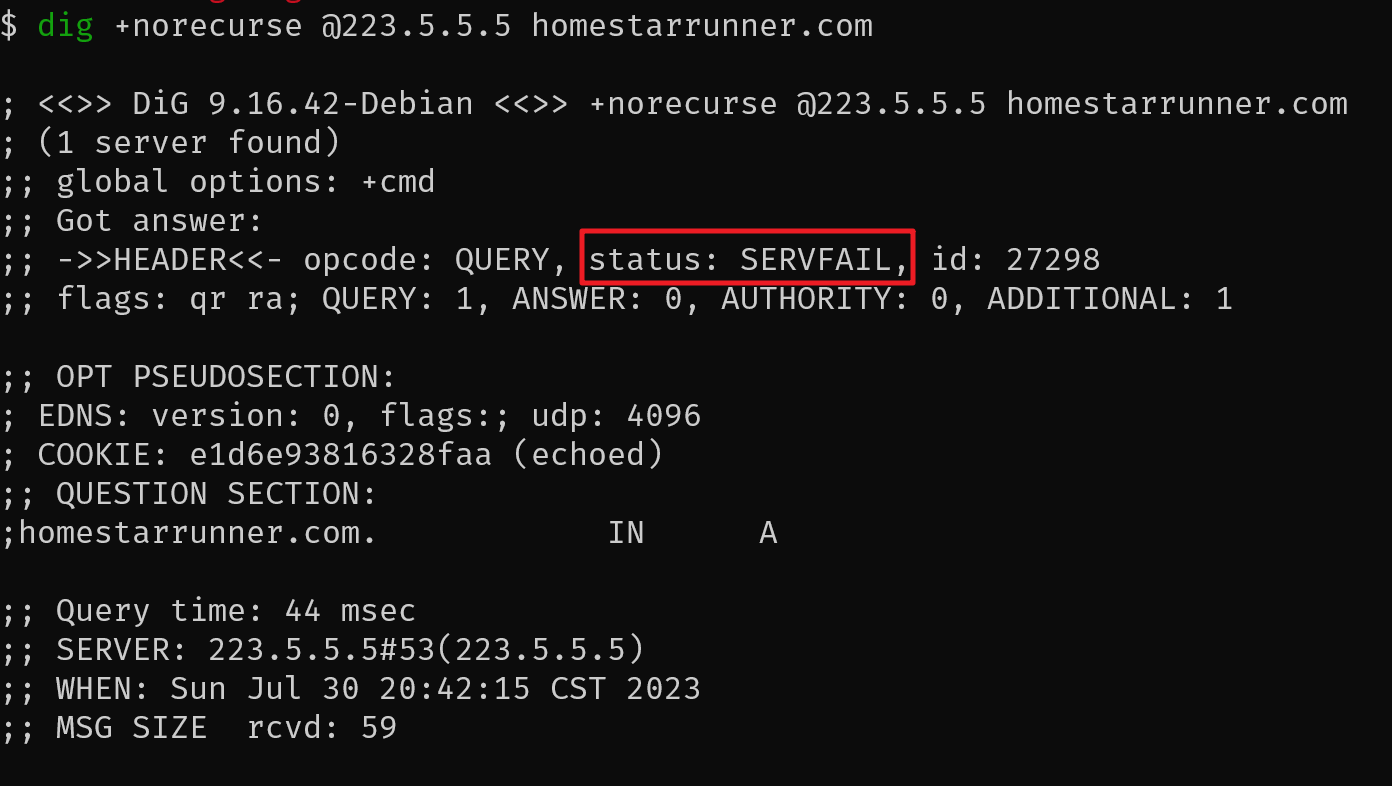

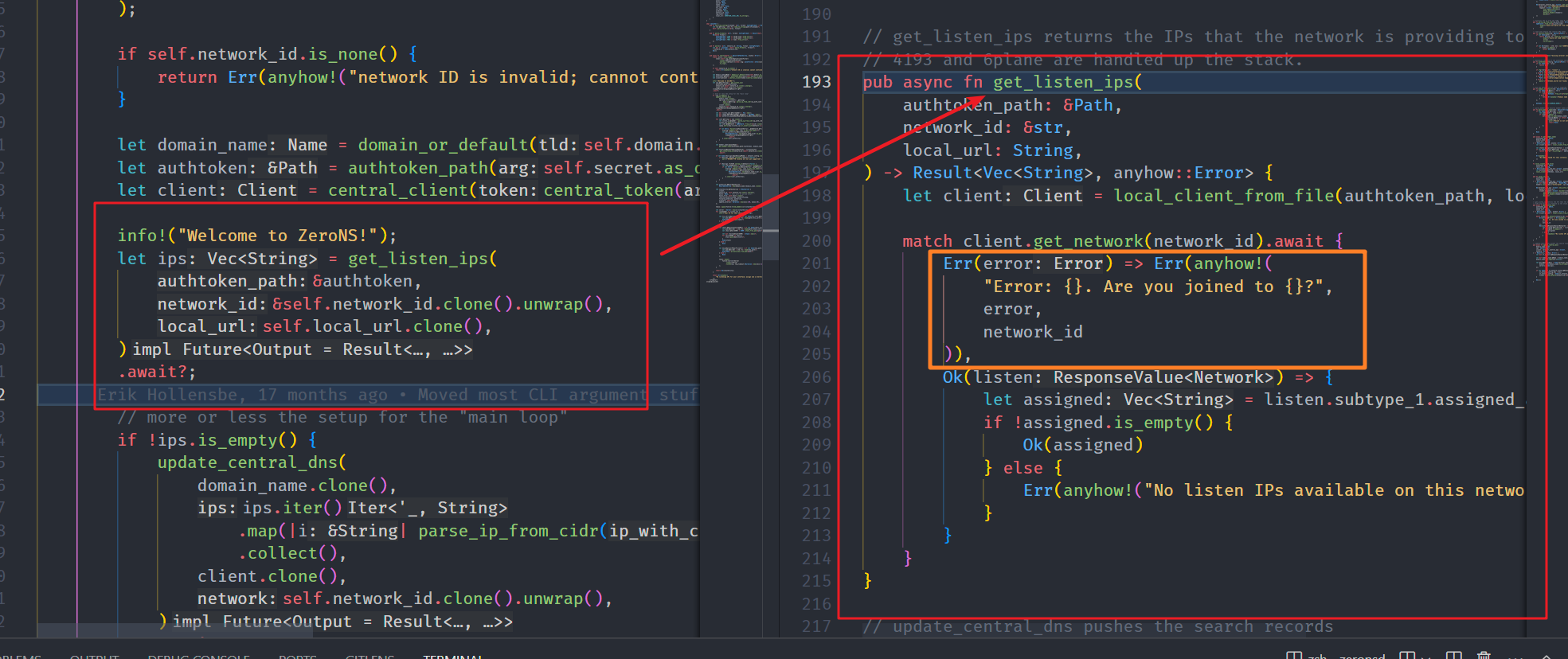
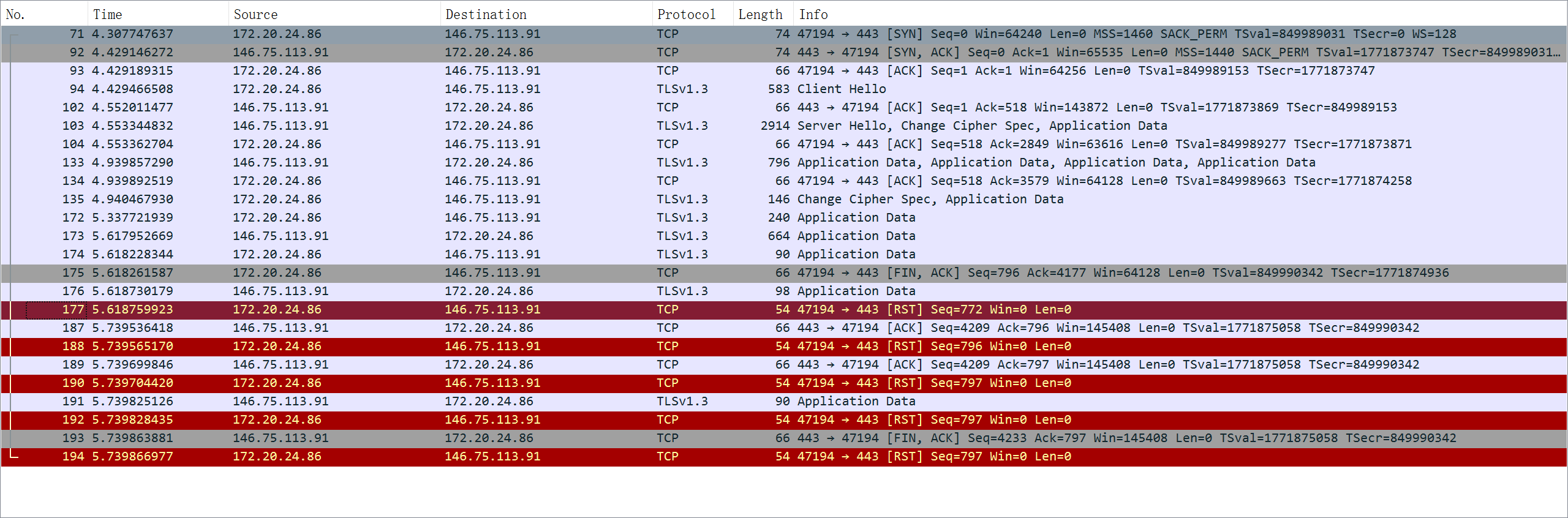
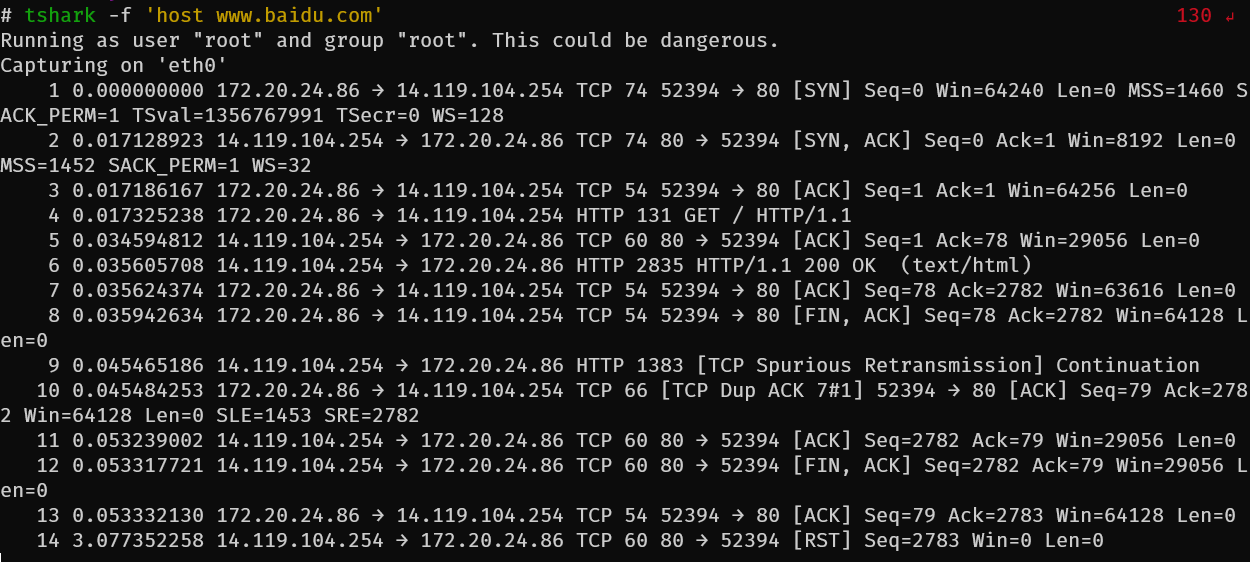

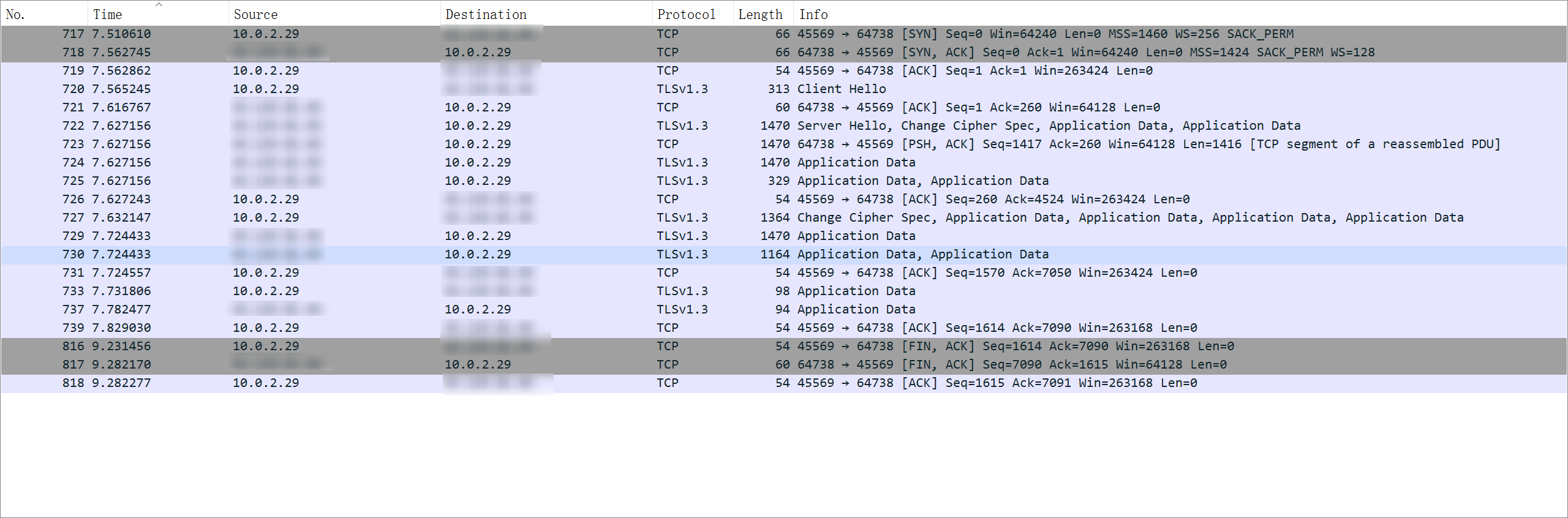
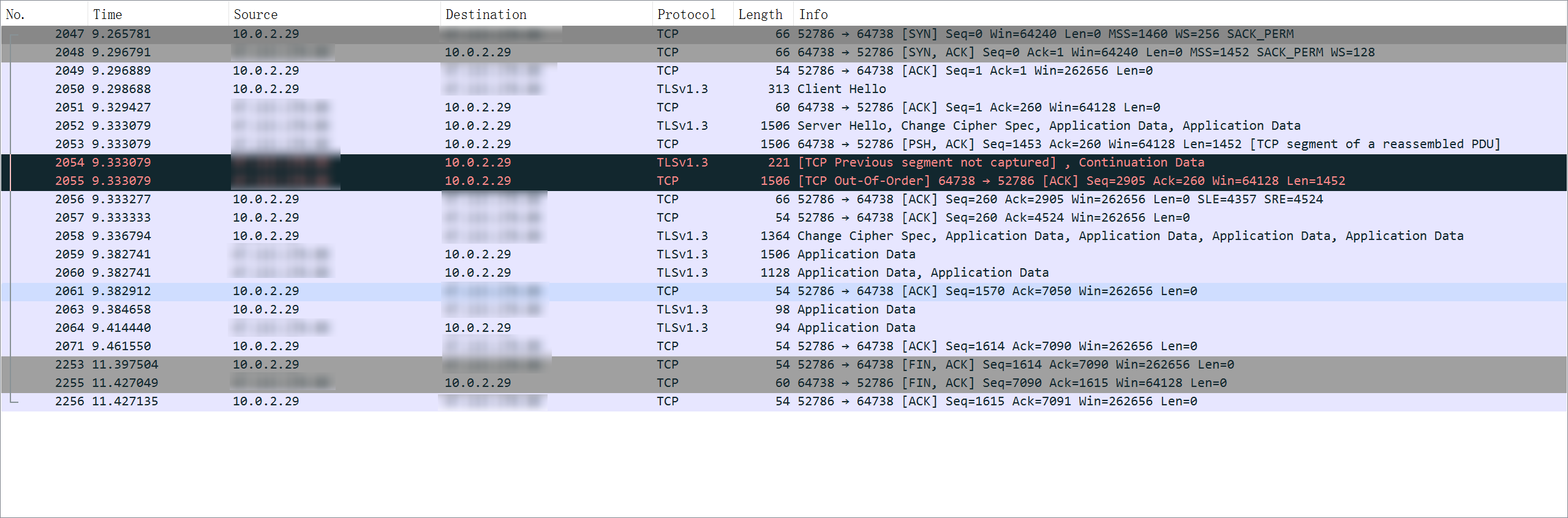
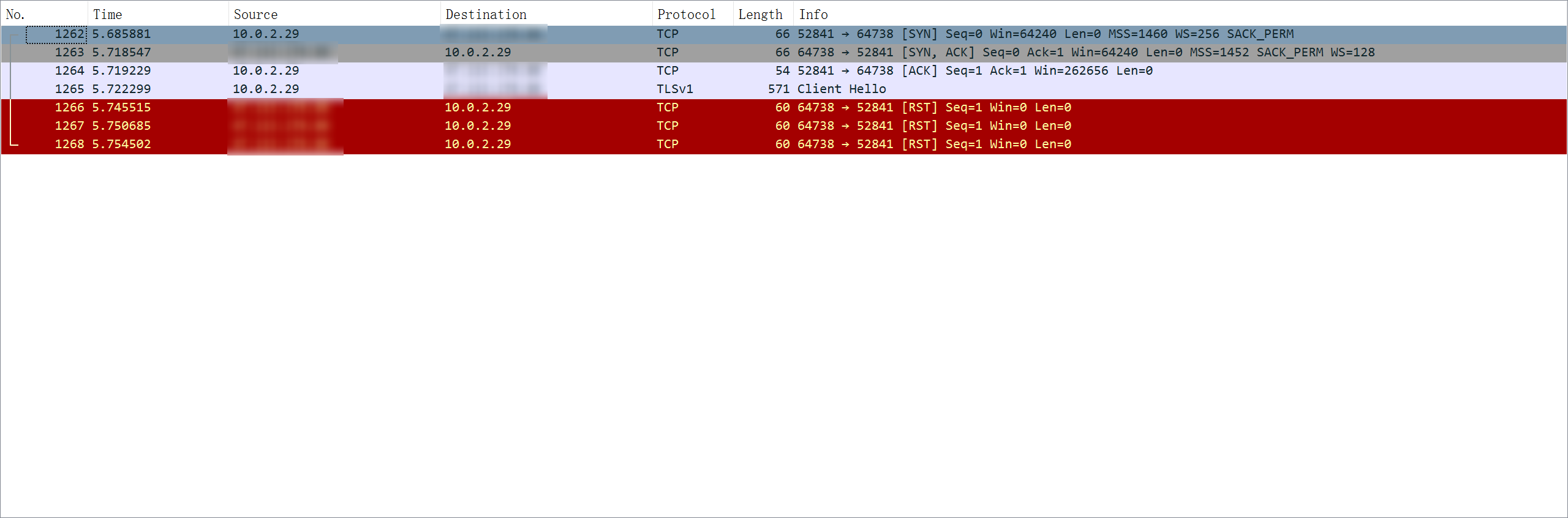

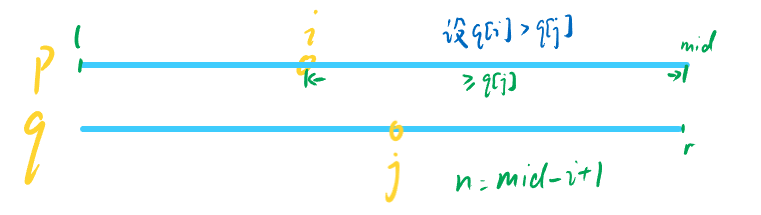

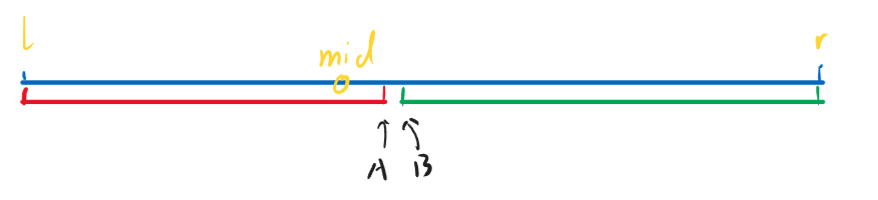
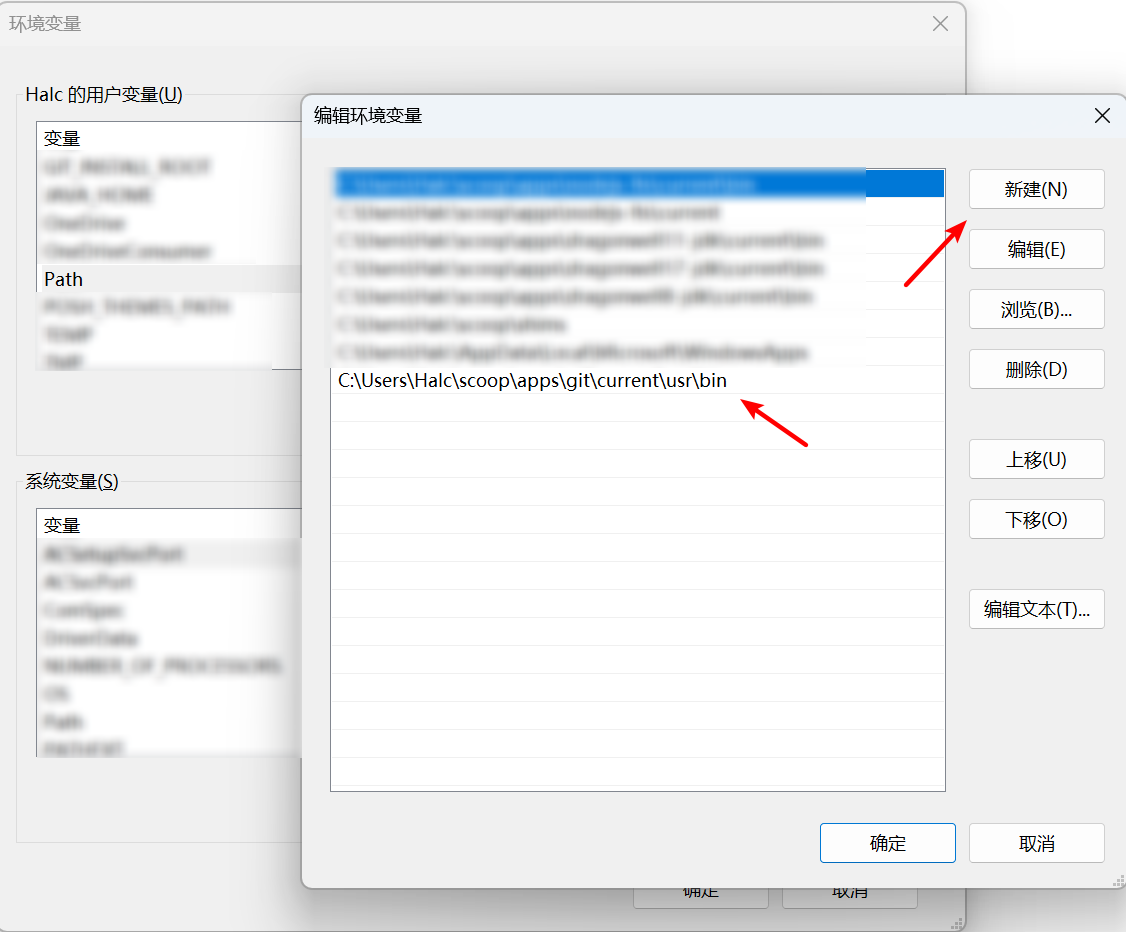
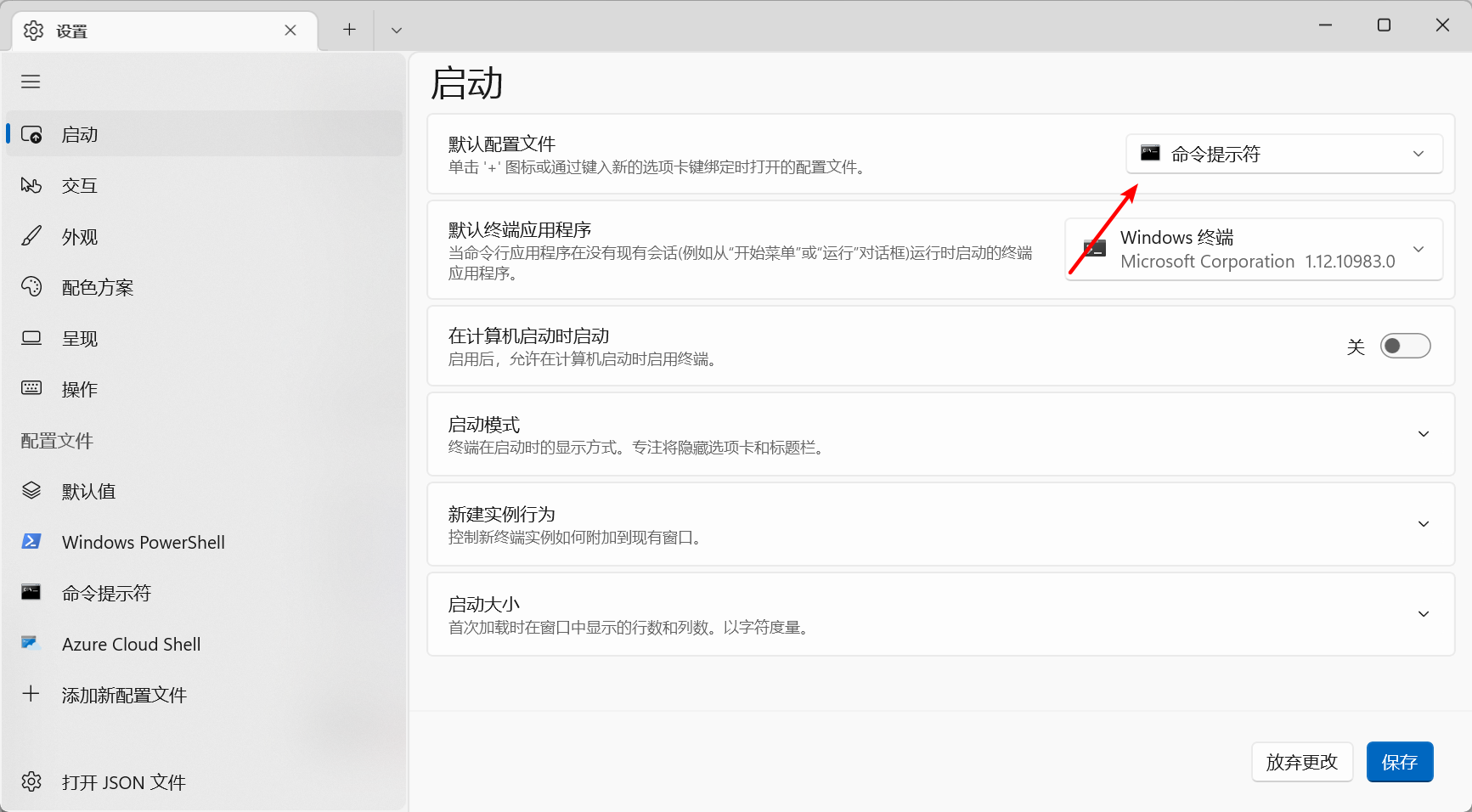 ]]>
]]>