diff --git a/docs/source/zh/_toctree.yml b/docs/source/zh/_toctree.yml
index 5f2fa5a172af76..fffa7569f49793 100644
--- a/docs/source/zh/_toctree.yml
+++ b/docs/source/zh/_toctree.yml
@@ -49,6 +49,10 @@
title: 实例化大模型
- local: debugging
title: 问题定位及解决
+ - local: tf_xla
+ title: TensorFlow模型的XLA集成
+ - local: perf_torch_compile
+ title: 使用 `torch.compile()` 优化推理
title: 性能和可扩展性
- sections:
- local: task_summary
diff --git a/docs/source/zh/perf_torch_compile.md b/docs/source/zh/perf_torch_compile.md
new file mode 100644
index 00000000000000..b28dc9567c9174
--- /dev/null
+++ b/docs/source/zh/perf_torch_compile.md
@@ -0,0 +1,362 @@
+
+
+# 使用 torch.compile() 优化推理
+
+本指南旨在为使用[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)在[🤗 Transformers中的计算机视觉模型](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)中引入的推理速度提升提供一个基准。
+
+
+## torch.compile 的优势
+
+根据模型和GPU的不同,`torch.compile()`在推理过程中可以提高多达30%的速度。要使用`torch.compile()`,只需安装2.0及以上版本的`torch`即可。
+
+编译模型需要时间,因此如果您只需要编译一次模型而不是每次推理都编译,那么它非常有用。
+要编译您选择的任何计算机视觉模型,请按照以下方式调用`torch.compile()`:
+
+
+```diff
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
++ model = torch.compile(model)
+```
+
+`compile()` 提供了多种编译模式,它们在编译时间和推理开销上有所不同。`max-autotune` 比 `reduce-overhead` 需要更长的时间,但会得到更快的推理速度。默认模式在编译时最快,但在推理时间上与 `reduce-overhead` 相比效率较低。在本指南中,我们使用了默认模式。您可以在[这里](https://pytorch.org/get-started/pytorch-2.0/#user-experience)了解更多信息。
+
+我们在 PyTorch 2.0.1 版本上使用不同的计算机视觉模型、任务、硬件类型和数据批量大小对 `torch.compile` 进行了基准测试。
+
+## 基准测试代码
+
+以下是每个任务的基准测试代码。我们在推理之前”预热“GPU,并取300次推理的平均值,每次使用相同的图像。
+
+### 使用 ViT 进行图像分类
+
+```python
+import torch
+from PIL import Image
+import requests
+import numpy as np
+from transformers import AutoImageProcessor, AutoModelForImageClassification
+
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
+model = torch.compile(model)
+
+processed_input = processor(image, return_tensors='pt').to(device="cuda")
+
+with torch.no_grad():
+ _ = model(**processed_input)
+
+```
+
+#### 使用 DETR 进行目标检测
+
+```python
+from transformers import AutoImageProcessor, AutoModelForObjectDetection
+
+processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
+model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
+model = torch.compile(model)
+
+texts = ["a photo of a cat", "a photo of a dog"]
+inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ _ = model(**inputs)
+```
+
+#### 使用 Segformer 进行图像分割
+
+```python
+from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
+
+processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
+model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
+model = torch.compile(model)
+seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ _ = model(**seg_inputs)
+```
+
+以下是我们进行基准测试的模型列表。
+
+**图像分类**
+- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
+- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
+- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
+- [microsoft/resnet-50](https://huggingface.co/)
+
+**图像分割**
+- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
+- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
+- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
+
+**目标检测**
+- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
+- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
+- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
+
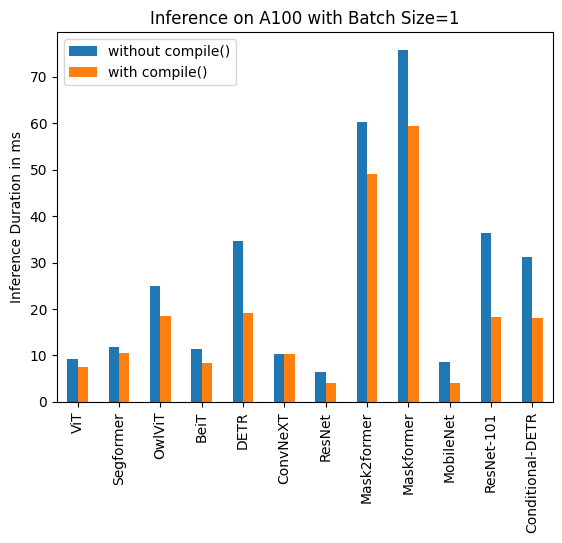
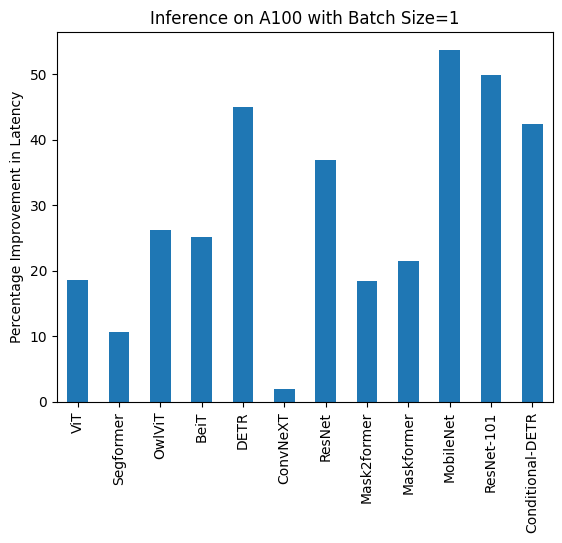
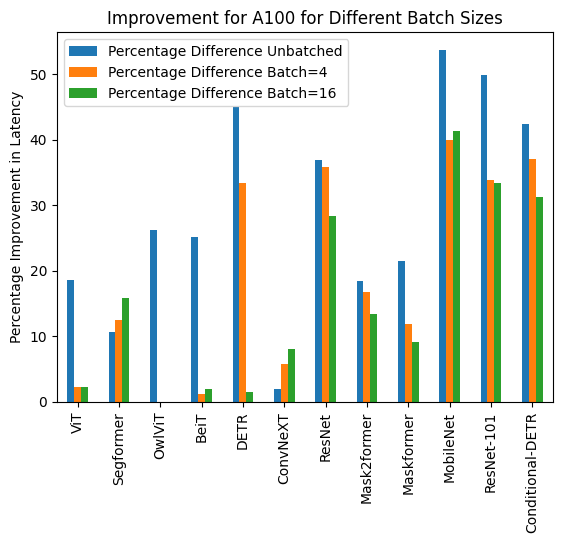
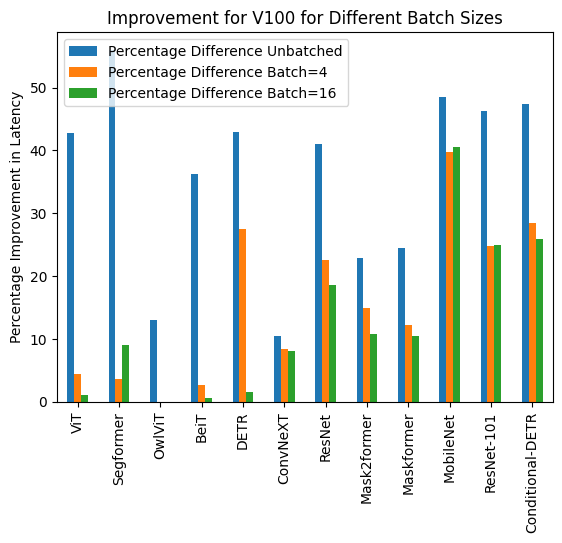
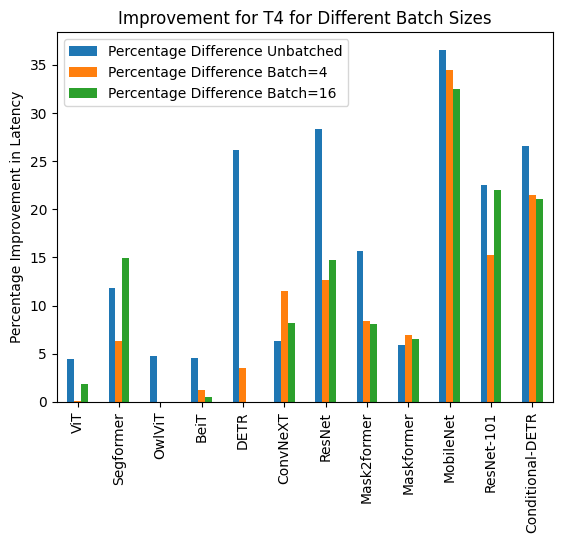
+ 下面是使用和不使用`torch.compile()`的推理持续时间可视化,以及每个模型在不同硬件和数据批量大小下的改进百分比。
+
+
+
+
+
+
+
+
+
+
+
+
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 9.325 | 7.584 |
+| Image Segmentation/Segformer | 11.759 | 10.500 |
+| Object Detection/OwlViT | 24.978 | 18.420 |
+| Image Classification/BeiT | 11.282 | 8.448 |
+| Object Detection/DETR | 34.619 | 19.040 |
+| Image Classification/ConvNeXT | 10.410 | 10.208 |
+| Image Classification/ResNet | 6.531 | 4.124 |
+| Image Segmentation/Mask2former | 60.188 | 49.117 |
+| Image Segmentation/Maskformer | 75.764 | 59.487 |
+| Image Segmentation/MobileNet | 8.583 | 3.974 |
+| Object Detection/Resnet-101 | 36.276 | 18.197 |
+| Object Detection/Conditional-DETR | 31.219 | 17.993 |
+
+
+### A100 (batch size: 4)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 14.832 | 14.499 |
+| Image Segmentation/Segformer | 18.838 | 16.476 |
+| Image Classification/BeiT | 13.205 | 13.048 |
+| Object Detection/DETR | 48.657 | 32.418|
+| Image Classification/ConvNeXT | 22.940 | 21.631 |
+| Image Classification/ResNet | 6.657 | 4.268 |
+| Image Segmentation/Mask2former | 74.277 | 61.781 |
+| Image Segmentation/Maskformer | 180.700 | 159.116 |
+| Image Segmentation/MobileNet | 14.174 | 8.515 |
+| Object Detection/Resnet-101 | 68.101 | 44.998 |
+| Object Detection/Conditional-DETR | 56.470 | 35.552 |
+
+### A100 (batch size: 16)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 40.944 | 40.010 |
+| Image Segmentation/Segformer | 37.005 | 31.144 |
+| Image Classification/BeiT | 41.854 | 41.048 |
+| Object Detection/DETR | 164.382 | 161.902 |
+| Image Classification/ConvNeXT | 82.258 | 75.561 |
+| Image Classification/ResNet | 7.018 | 5.024 |
+| Image Segmentation/Mask2former | 178.945 | 154.814 |
+| Image Segmentation/Maskformer | 638.570 | 579.826 |
+| Image Segmentation/MobileNet | 51.693 | 30.310 |
+| Object Detection/Resnet-101 | 232.887 | 155.021 |
+| Object Detection/Conditional-DETR | 180.491 | 124.032 |
+
+### V100 (batch size: 1)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 10.495 | 6.00 |
+| Image Segmentation/Segformer | 13.321 | 5.862 |
+| Object Detection/OwlViT | 25.769 | 22.395 |
+| Image Classification/BeiT | 11.347 | 7.234 |
+| Object Detection/DETR | 33.951 | 19.388 |
+| Image Classification/ConvNeXT | 11.623 | 10.412 |
+| Image Classification/ResNet | 6.484 | 3.820 |
+| Image Segmentation/Mask2former | 64.640 | 49.873 |
+| Image Segmentation/Maskformer | 95.532 | 72.207 |
+| Image Segmentation/MobileNet | 9.217 | 4.753 |
+| Object Detection/Resnet-101 | 52.818 | 28.367 |
+| Object Detection/Conditional-DETR | 39.512 | 20.816 |
+
+### V100 (batch size: 4)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 15.181 | 14.501 |
+| Image Segmentation/Segformer | 16.787 | 16.188 |
+| Image Classification/BeiT | 15.171 | 14.753 |
+| Object Detection/DETR | 88.529 | 64.195 |
+| Image Classification/ConvNeXT | 29.574 | 27.085 |
+| Image Classification/ResNet | 6.109 | 4.731 |
+| Image Segmentation/Mask2former | 90.402 | 76.926 |
+| Image Segmentation/Maskformer | 234.261 | 205.456 |
+| Image Segmentation/MobileNet | 24.623 | 14.816 |
+| Object Detection/Resnet-101 | 134.672 | 101.304 |
+| Object Detection/Conditional-DETR | 97.464 | 69.739 |
+
+### V100 (batch size: 16)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 52.209 | 51.633 |
+| Image Segmentation/Segformer | 61.013 | 55.499 |
+| Image Classification/BeiT | 53.938 | 53.581 |
+| Object Detection/DETR | OOM | OOM |
+| Image Classification/ConvNeXT | 109.682 | 100.771 |
+| Image Classification/ResNet | 14.857 | 12.089 |
+| Image Segmentation/Mask2former | 249.605 | 222.801 |
+| Image Segmentation/Maskformer | 831.142 | 743.645 |
+| Image Segmentation/MobileNet | 93.129 | 55.365 |
+| Object Detection/Resnet-101 | 482.425 | 361.843 |
+| Object Detection/Conditional-DETR | 344.661 | 255.298 |
+
+### T4 (batch size: 1)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 16.520 | 15.786 |
+| Image Segmentation/Segformer | 16.116 | 14.205 |
+| Object Detection/OwlViT | 53.634 | 51.105 |
+| Image Classification/BeiT | 16.464 | 15.710 |
+| Object Detection/DETR | 73.100 | 53.99 |
+| Image Classification/ConvNeXT | 32.932 | 30.845 |
+| Image Classification/ResNet | 6.031 | 4.321 |
+| Image Segmentation/Mask2former | 79.192 | 66.815 |
+| Image Segmentation/Maskformer | 200.026 | 188.268 |
+| Image Segmentation/MobileNet | 18.908 | 11.997 |
+| Object Detection/Resnet-101 | 106.622 | 82.566 |
+| Object Detection/Conditional-DETR | 77.594 | 56.984 |
+
+### T4 (batch size: 4)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 43.653 | 43.626 |
+| Image Segmentation/Segformer | 45.327 | 42.445 |
+| Image Classification/BeiT | 52.007 | 51.354 |
+| Object Detection/DETR | 277.850 | 268.003 |
+| Image Classification/ConvNeXT | 119.259 | 105.580 |
+| Image Classification/ResNet | 13.039 | 11.388 |
+| Image Segmentation/Mask2former | 201.540 | 184.670 |
+| Image Segmentation/Maskformer | 764.052 | 711.280 |
+| Image Segmentation/MobileNet | 74.289 | 48.677 |
+| Object Detection/Resnet-101 | 421.859 | 357.614 |
+| Object Detection/Conditional-DETR | 289.002 | 226.945 |
+
+### T4 (batch size: 16)
+
+| **Task/Model** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|
+| Image Classification/ViT | 163.914 | 160.907 |
+| Image Segmentation/Segformer | 192.412 | 163.620 |
+| Image Classification/BeiT | 188.978 | 187.976 |
+| Object Detection/DETR | OOM | OOM |
+| Image Classification/ConvNeXT | 422.886 | 388.078 |
+| Image Classification/ResNet | 44.114 | 37.604 |
+| Image Segmentation/Mask2former | 756.337 | 695.291 |
+| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
+| Image Segmentation/MobileNet | 299.003 | 201.942 |
+| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
+| Object Detection/Conditional-DETR | 1137.513 | 897.390|
+
+## PyTorch Nightly
+我们还在 PyTorch Nightly 版本(2.1.0dev)上进行了基准测试,可以在[这里](https://download.pytorch.org/whl/nightly/cu118)找到 Nightly 版本的安装包,并观察到了未编译和编译模型的延迟性能改善。
+
+### A100
+
+| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|:---:|
+| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
+| Image Classification/BeiT | 4 | 14.109 | 12.851 |
+| Image Classification/BeiT | 16 | 42.179 | 42.147 |
+| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
+| Object Detection/DETR | 4 | 46.816 | 30.942 |
+| Object Detection/DETR | 16 | 163.749 | 163.706 |
+
+### T4
+
+| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|:---:|
+| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
+| Image Classification/BeiT | 4 | 47.381 | 46.604 |
+| Image Classification/BeiT | 16 | 42.179 | 42.147 |
+| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
+| Object Detection/DETR | 4 | 269.615 | 204.785 |
+| Object Detection/DETR | 16 | OOM | OOM |
+
+### V100
+
+| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|:---:|
+| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
+| Image Classification/BeiT | 4 | 15.103 | 14.378 |
+| Image Classification/BeiT | 16 | 52.517 | 51.691 |
+| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
+| Object Detection/DETR | 4 | 88.402 | 62.949|
+| Object Detection/DETR | 16 | OOM | OOM |
+
+
+## 降低开销
+我们在 PyTorch Nightly 版本中为 A100 和 T4 进行了 `reduce-overhead` 编译模式的性能基准测试。
+
+### A100
+
+| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|:---:|
+| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
+| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
+| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
+| Image Classification/ResNet | 4 | 7.261 | 2.187 |
+| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
+| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
+| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
+| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
+
+
+### T4
+
+| **Task/Model** | **Batch Size** | **torch 2.0 -
no compile** | **torch 2.0 -
compile** |
+|:---:|:---:|:---:|:---:|
+| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
+| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
+| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
+| Image Classification/ResNet | 4 | 15.215 | 13.871 |
+| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
+| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
+| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
+| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
+
+
diff --git a/docs/source/zh/tf_xla.md b/docs/source/zh/tf_xla.md
new file mode 100644
index 00000000000000..da8d13d8d04bac
--- /dev/null
+++ b/docs/source/zh/tf_xla.md
@@ -0,0 +1,179 @@
+
+
+# 用于 TensorFlow 模型的 XLA 集成
+
+[[open-in-colab]]
+
+加速线性代数,也称为XLA,是一个用于加速TensorFlow模型运行时间的编译器。从[官方文档](https://www.tensorflow.org/xla)中可以看到:
+
+XLA(加速线性代数)是一种针对线性代数的特定领域编译器,可以在可能不需要更改源代码的情况下加速TensorFlow模型。
+
+在TensorFlow中使用XLA非常简单——它包含在`tensorflow`库中,并且可以使用任何图创建函数中的`jit_compile`参数来触发,例如[`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs)。在使用Keras方法如`fit()`和`predict()`时,只需将`jit_compile`参数传递给`model.compile()`即可启用XLA。然而,XLA不仅限于这些方法 - 它还可以用于加速任何任意的`tf.function`。
+
+在🤗 Transformers中,几个TensorFlow方法已经被重写为与XLA兼容,包括[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)、[T5](https://huggingface.co/docs/transformers/model_doc/t5)和[OPT](https://huggingface.co/docs/transformers/model_doc/opt)等文本生成模型,以及[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)等语音处理模型。
+
+虽然确切的加速倍数很大程度上取决于模型,但对于🤗 Transformers中的TensorFlow文本生成模型,我们注意到速度提高了约100倍。本文档将解释如何在这些模型上使用XLA获得最大的性能。如果您有兴趣了解更多关于基准测试和我们在XLA集成背后的设计哲学的信息,我们还将提供额外的资源链接。
+
+
+## 使用 XLA 运行 TensorFlow 函数
+
+让我们考虑以下TensorFlow 中的模型:
+
+```py
+import tensorflow as tf
+
+model = tf.keras.Sequential(
+ [tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
+)
+```
+
+上述模型接受维度为 `(10,)` 的输入。我们可以像下面这样使用模型进行前向传播:
+
+```py
+# Generate random inputs for the model.
+batch_size = 16
+input_vector_dim = 10
+random_inputs = tf.random.normal((batch_size, input_vector_dim))
+
+# Run a forward pass.
+_ = model(random_inputs)
+```
+
+为了使用 XLA 编译的函数运行前向传播,我们需要执行以下操作:
+
+```py
+xla_fn = tf.function(model, jit_compile=True)
+_ = xla_fn(random_inputs)
+```
+
+`model`的默认`call()`函数用于编译XLA图。但如果你想将其他模型函数编译成XLA,也是可以的,如下所示:
+
+```py
+my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
+```
+
+## 在🤗 Transformers库中使用XLA运行TensorFlow文本生成模型
+
+要在🤗 Transformers中启用XLA加速生成,您需要安装最新版本的`transformers`。您可以通过运行以下命令来安装它:
+
+```bash
+pip install transformers --upgrade
+```
+
+然后您可以运行以下代码:
+
+```py
+import tensorflow as tf
+from transformers import AutoTokenizer, TFAutoModelForCausalLM
+
+# Will error if the minimal version of Transformers is not installed.
+from transformers.utils import check_min_version
+
+check_min_version("4.21.0")
+
+
+tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
+model = TFAutoModelForCausalLM.from_pretrained("gpt2")
+input_string = ["TensorFlow is"]
+
+# One line to create an XLA generation function
+xla_generate = tf.function(model.generate, jit_compile=True)
+
+tokenized_input = tokenizer(input_string, return_tensors="tf")
+generated_tokens = xla_generate(**tokenized_input, num_beams=2)
+
+decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
+print(f"Generated -- {decoded_text}")
+# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
+```
+
+正如您所注意到的,在`generate()`上启用XLA只需要一行代码。其余部分代码保持不变。然而,上面的代码片段中有一些与XLA相关的注意事项。您需要了解这些注意事项,以充分利用XLA可能带来的性能提升。我们将在下面的部分讨论这些内容。
+
+## 需要关注的注意事项
+
+当您首次执行启用XLA的函数(如上面的`xla_generate()`)时,它将在内部尝试推断计算图,这是一个耗时的过程。这个过程被称为[“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing)。
+
+您可能会注意到生成时间并不快。连续调用`xla_generate()`(或任何其他启用了XLA的函数)不需要再次推断计算图,只要函数的输入与最初构建计算图时的形状相匹配。对于具有固定输入形状的模态(例如图像),这不是问题,但如果您正在处理具有可变输入形状的模态(例如文本),则必须注意。
+
+为了确保`xla_generate()`始终使用相同的输入形状,您可以在调用`tokenizer`时指定`padding`参数。
+
+```py
+import tensorflow as tf
+from transformers import AutoTokenizer, TFAutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
+model = TFAutoModelForCausalLM.from_pretrained("gpt2")
+input_string = ["TensorFlow is"]
+
+xla_generate = tf.function(model.generate, jit_compile=True)
+
+# Here, we call the tokenizer with padding options.
+tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
+
+generated_tokens = xla_generate(**tokenized_input, num_beams=2)
+decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
+print(f"Generated -- {decoded_text}")
+```
+
+通过这种方式,您可以确保`xla_generate()`的输入始终具有它跟踪的形状,从而加速生成时间。您可以使用以下代码来验证这一点:
+
+```py
+import time
+import tensorflow as tf
+from transformers import AutoTokenizer, TFAutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
+model = TFAutoModelForCausalLM.from_pretrained("gpt2")
+
+xla_generate = tf.function(model.generate, jit_compile=True)
+
+for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
+ tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
+ start = time.time_ns()
+ generated_tokens = xla_generate(**tokenized_input, num_beams=2)
+ end = time.time_ns()
+ print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
+```
+
+在Tesla T4 GPU上,您可以期望如下的输出:
+
+```bash
+Execution time -- 30819.6 ms
+
+Execution time -- 79.0 ms
+
+Execution time -- 78.9 ms
+```
+
+第一次调用`xla_generate()`会因为`tracing`而耗时,但后续的调用会快得多。请注意,任何时候对生成选项的更改都会触发重新`tracing`,从而导致生成时间减慢。
+
+在本文档中,我们没有涵盖🤗 Transformers提供的所有文本生成选项。我们鼓励您阅读文档以了解高级用例。
+
+## 附加资源
+
+以下是一些附加资源,如果您想深入了解在🤗 Transformers和其他库下使用XLA:
+
+* [这个Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) 提供了一个互动演示,让您可以尝试使用XLA兼容的编码器-解码器(例如[T5](https://huggingface.co/docs/transformers/model_doc/t5))和仅解码器(例如[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2))文本生成模型。
+
+* [这篇博客文章](https://huggingface.co/blog/tf-xla-generate) 提供了XLA兼容模型的比较基准概述,以及关于在TensorFlow中使用XLA的友好介绍。
+
+* [这篇博客文章](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) 讨论了我们在🤗 Transformers中为TensorFlow模型添加XLA支持的设计理念。
+
+* 推荐用于更多学习XLA和TensorFlow图的资源:
+ * [XLA:面向机器学习的优化编译器](https://www.tensorflow.org/xla)
+ * [图和tf.function简介](https://www.tensorflow.org/guide/intro_to_graphs)
+ * [使用tf.function获得更好的性能](https://www.tensorflow.org/guide/function)
\ No newline at end of file
 +
+  +
+  +
+