+
+
+  +
+
+
+
+
+YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset.
+
+This repo shows how to accelerate YOLOv5 model by pruning and quantization.
+
+
+##
Documentation
+
+See the [YOLOv5 Docs](https://docs.ultralytics.com) for full documentation on training, testing and deployment.
+See the [ENOT Docs](https://enot-autodl.rtd.enot.ai/en/latest/) for documentation on pruning and quantization.
+
+##
Quick Start Examples
+
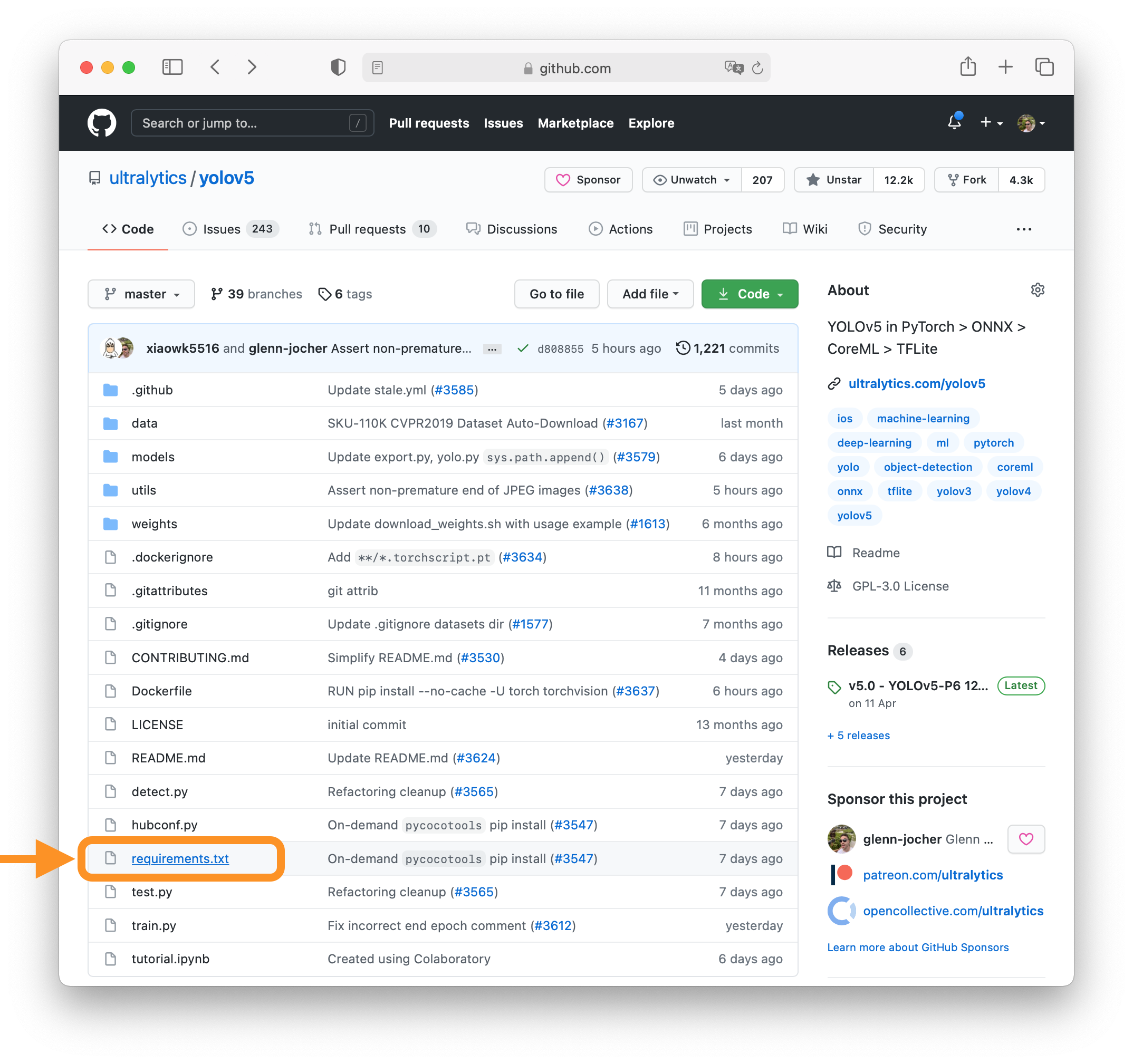
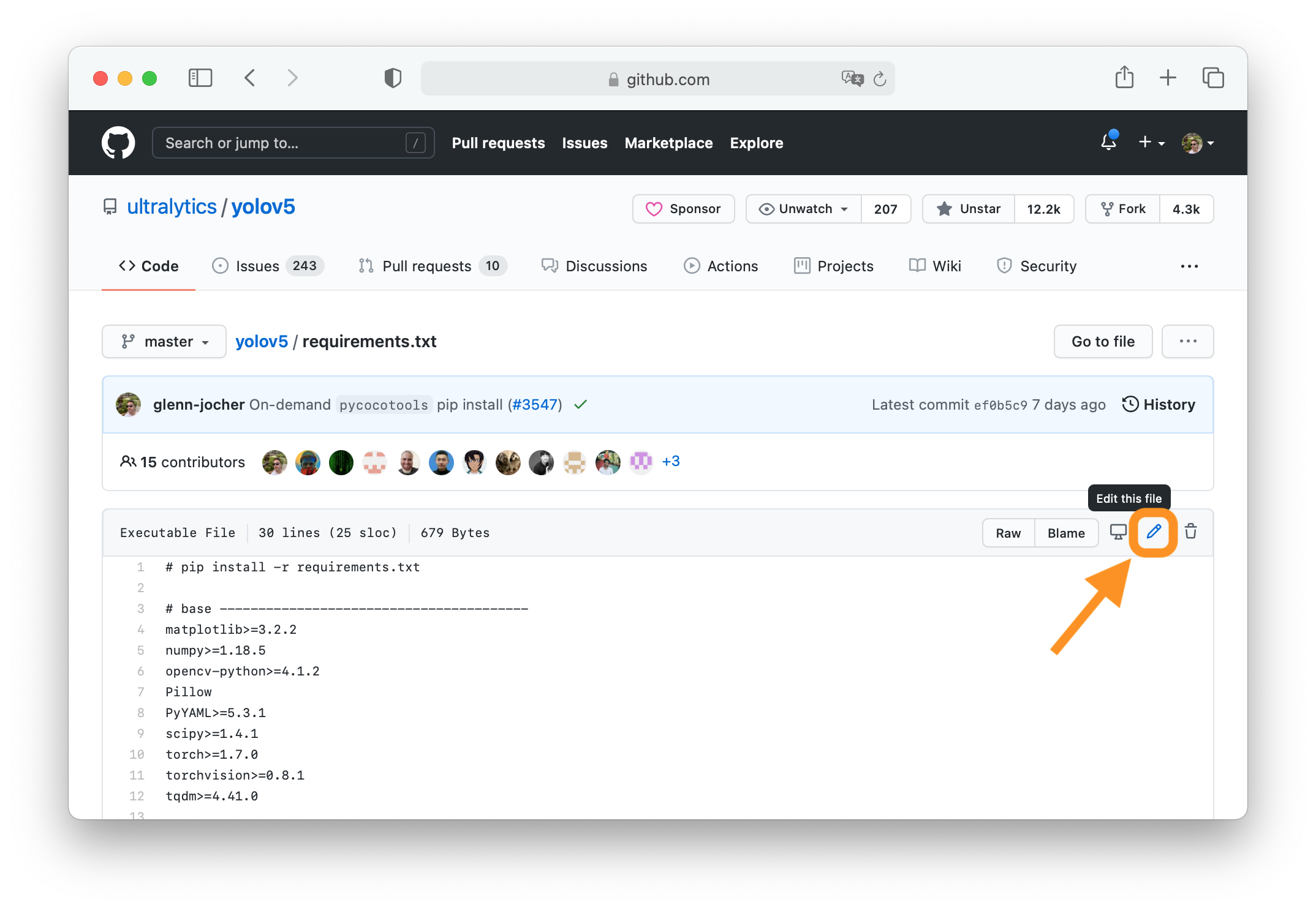
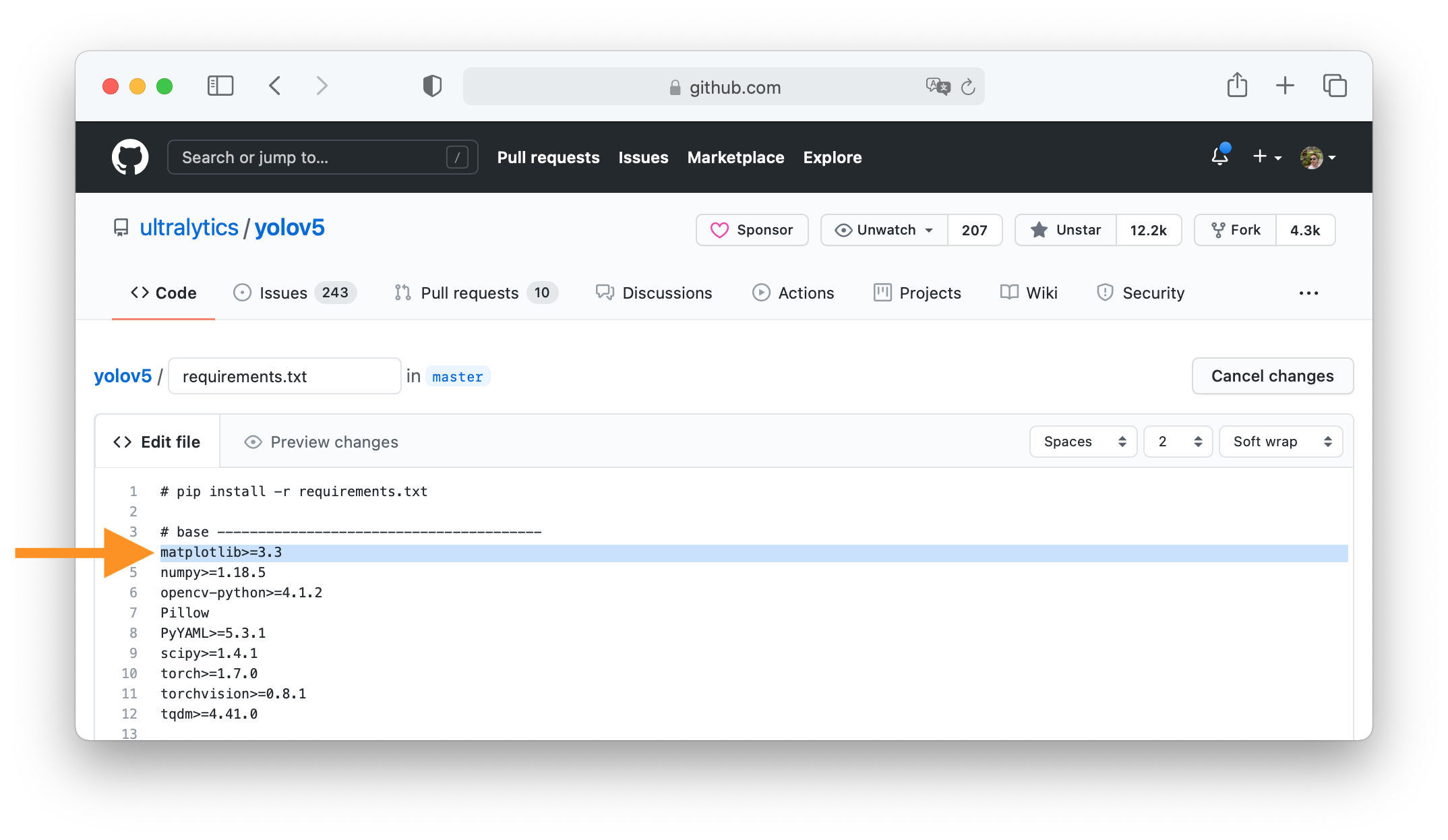
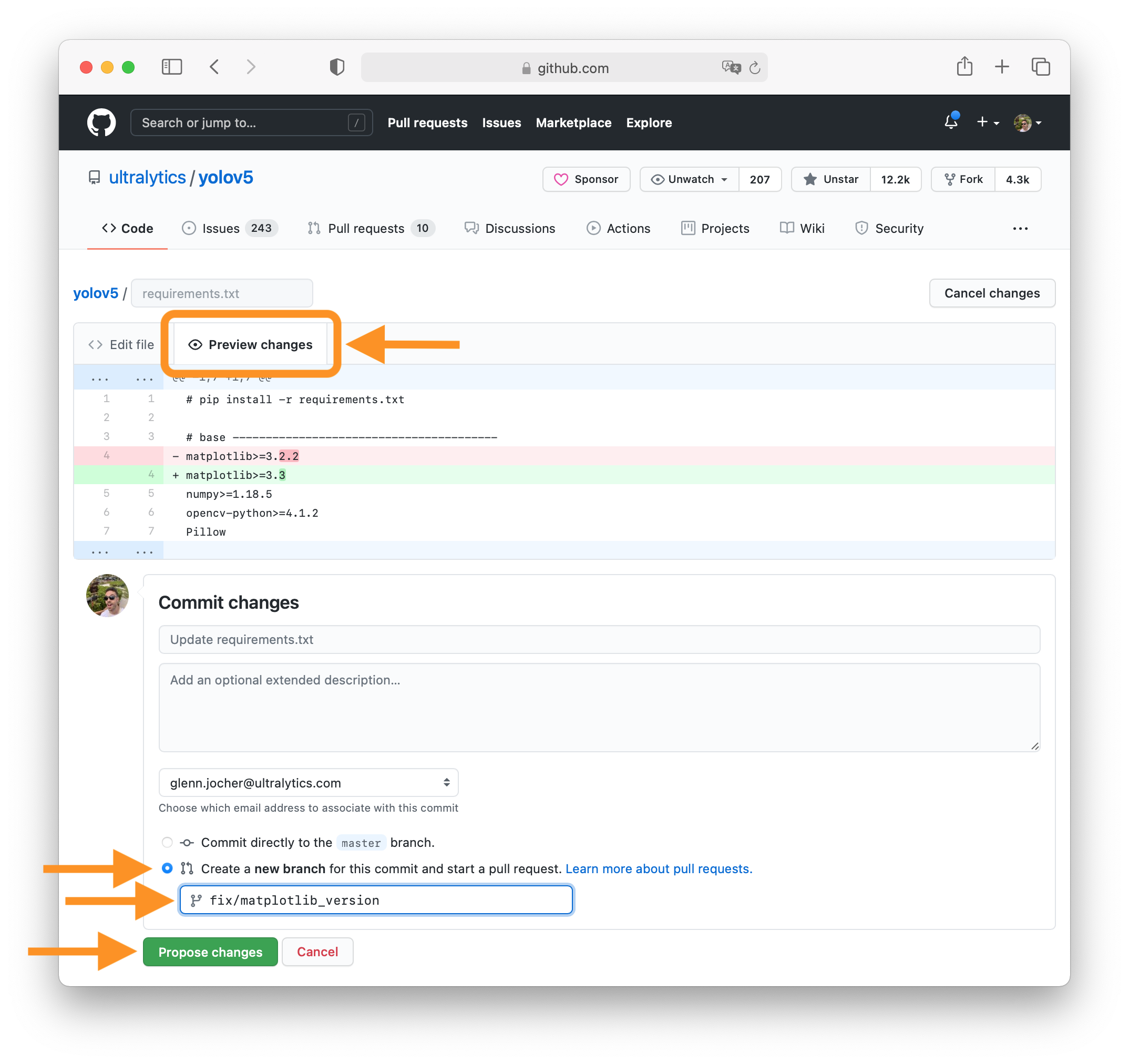
+Clone repo and install [requirements.txt](https://github.com/ENOT-AutoDL/yoqo/blob/master/requirements.txt) in a
+[**Python>=3.8.0**](https://www.python.org/) environment, including
+[**PyTorch==1.13.1**](https://pytorch.org/get-started/locally/).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+Note: We recommend to install **enot-autodl** and **enot-lite** following these instructions:
+[**enot-autodl installation instruction**](https://enot-autodl.rtd.enot.ai/en/latest/installation_guide.html)
+[**enot-lite installation instruction**](https://enot-lite.rtd.enot.ai/en/latest/installation_guide.html)
+
+##
Demo
+There is [**demo notebook**](https://github.com/ENOT-AutoDL/yoqo/blob/master/demo.ipynb) which shows how to prune and quantize YOLOv5 model.
+
+
+##
Contact
+
+**enot@enot.ai**
diff --git a/data/Argoverse.yaml b/data/Argoverse.yaml
new file mode 100755
index 0000000..9d21296
--- /dev/null
+++ b/data/Argoverse.yaml
@@ -0,0 +1,67 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
+# Example usage: python train.py --data Argoverse.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Argoverse ← downloads here (31.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Argoverse # dataset root dir
+train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
+val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
+test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
+
+# Classes
+nc: 8 # number of classes
+names: ['person', 'bicycle', 'car', 'motorcycle', 'bus', 'truck', 'traffic_light', 'stop_sign'] # class names
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import json
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def argoverse2yolo(set):
+ labels = {}
+ a = json.load(open(set, "rb"))
+ for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
+ img_id = annot['image_id']
+ img_name = a['images'][img_id]['name']
+ img_label_name = f'{img_name[:-3]}txt'
+
+ cls = annot['category_id'] # instance class id
+ x_center, y_center, width, height = annot['bbox']
+ x_center = (x_center + width / 2) / 1920.0 # offset and scale
+ y_center = (y_center + height / 2) / 1200.0 # offset and scale
+ width /= 1920.0 # scale
+ height /= 1200.0 # scale
+
+ img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
+ if not img_dir.exists():
+ img_dir.mkdir(parents=True, exist_ok=True)
+
+ k = str(img_dir / img_label_name)
+ if k not in labels:
+ labels[k] = []
+ labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
+
+ for k in labels:
+ with open(k, "w") as f:
+ f.writelines(labels[k])
+
+
+ # Download
+ dir = Path('../datasets/Argoverse') # dataset root dir
+ urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
+ download(urls, dir=dir, delete=False)
+
+ # Convert
+ annotations_dir = 'Argoverse-HD/annotations/'
+ (dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
+ for d in "train.json", "val.json":
+ argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/data/GlobalWheat2020.yaml b/data/GlobalWheat2020.yaml
new file mode 100755
index 0000000..4c43693
--- /dev/null
+++ b/data/GlobalWheat2020.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
+# Example usage: python train.py --data GlobalWheat2020.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── GlobalWheat2020 ← downloads here (7.0 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/GlobalWheat2020 # dataset root dir
+train: # train images (relative to 'path') 3422 images
+ - images/arvalis_1
+ - images/arvalis_2
+ - images/arvalis_3
+ - images/ethz_1
+ - images/rres_1
+ - images/inrae_1
+ - images/usask_1
+val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
+ - images/ethz_1
+test: # test images (optional) 1276 images
+ - images/utokyo_1
+ - images/utokyo_2
+ - images/nau_1
+ - images/uq_1
+
+# Classes
+nc: 1 # number of classes
+names: ['wheat_head'] # class names
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, Path
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
+ download(urls, dir=dir)
+
+ # Make Directories
+ for p in 'annotations', 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+
+ # Move
+ for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
+ 'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
+ (dir / p).rename(dir / 'images' / p) # move to /images
+ f = (dir / p).with_suffix('.json') # json file
+ if f.exists():
+ f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
diff --git a/data/Objects365.yaml b/data/Objects365.yaml
new file mode 100755
index 0000000..4cc9475
--- /dev/null
+++ b/data/Objects365.yaml
@@ -0,0 +1,114 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Objects365 dataset https://www.objects365.org/ by Megvii
+# Example usage: python train.py --data Objects365.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/Objects365 # dataset root dir
+train: images/train # train images (relative to 'path') 1742289 images
+val: images/val # val images (relative to 'path') 80000 images
+test: # test images (optional)
+
+# Classes
+nc: 365 # number of classes
+names: ['Person', 'Sneakers', 'Chair', 'Other Shoes', 'Hat', 'Car', 'Lamp', 'Glasses', 'Bottle', 'Desk', 'Cup',
+ 'Street Lights', 'Cabinet/shelf', 'Handbag/Satchel', 'Bracelet', 'Plate', 'Picture/Frame', 'Helmet', 'Book',
+ 'Gloves', 'Storage box', 'Boat', 'Leather Shoes', 'Flower', 'Bench', 'Potted Plant', 'Bowl/Basin', 'Flag',
+ 'Pillow', 'Boots', 'Vase', 'Microphone', 'Necklace', 'Ring', 'SUV', 'Wine Glass', 'Belt', 'Monitor/TV',
+ 'Backpack', 'Umbrella', 'Traffic Light', 'Speaker', 'Watch', 'Tie', 'Trash bin Can', 'Slippers', 'Bicycle',
+ 'Stool', 'Barrel/bucket', 'Van', 'Couch', 'Sandals', 'Basket', 'Drum', 'Pen/Pencil', 'Bus', 'Wild Bird',
+ 'High Heels', 'Motorcycle', 'Guitar', 'Carpet', 'Cell Phone', 'Bread', 'Camera', 'Canned', 'Truck',
+ 'Traffic cone', 'Cymbal', 'Lifesaver', 'Towel', 'Stuffed Toy', 'Candle', 'Sailboat', 'Laptop', 'Awning',
+ 'Bed', 'Faucet', 'Tent', 'Horse', 'Mirror', 'Power outlet', 'Sink', 'Apple', 'Air Conditioner', 'Knife',
+ 'Hockey Stick', 'Paddle', 'Pickup Truck', 'Fork', 'Traffic Sign', 'Balloon', 'Tripod', 'Dog', 'Spoon', 'Clock',
+ 'Pot', 'Cow', 'Cake', 'Dinning Table', 'Sheep', 'Hanger', 'Blackboard/Whiteboard', 'Napkin', 'Other Fish',
+ 'Orange/Tangerine', 'Toiletry', 'Keyboard', 'Tomato', 'Lantern', 'Machinery Vehicle', 'Fan',
+ 'Green Vegetables', 'Banana', 'Baseball Glove', 'Airplane', 'Mouse', 'Train', 'Pumpkin', 'Soccer', 'Skiboard',
+ 'Luggage', 'Nightstand', 'Tea pot', 'Telephone', 'Trolley', 'Head Phone', 'Sports Car', 'Stop Sign',
+ 'Dessert', 'Scooter', 'Stroller', 'Crane', 'Remote', 'Refrigerator', 'Oven', 'Lemon', 'Duck', 'Baseball Bat',
+ 'Surveillance Camera', 'Cat', 'Jug', 'Broccoli', 'Piano', 'Pizza', 'Elephant', 'Skateboard', 'Surfboard',
+ 'Gun', 'Skating and Skiing shoes', 'Gas stove', 'Donut', 'Bow Tie', 'Carrot', 'Toilet', 'Kite', 'Strawberry',
+ 'Other Balls', 'Shovel', 'Pepper', 'Computer Box', 'Toilet Paper', 'Cleaning Products', 'Chopsticks',
+ 'Microwave', 'Pigeon', 'Baseball', 'Cutting/chopping Board', 'Coffee Table', 'Side Table', 'Scissors',
+ 'Marker', 'Pie', 'Ladder', 'Snowboard', 'Cookies', 'Radiator', 'Fire Hydrant', 'Basketball', 'Zebra', 'Grape',
+ 'Giraffe', 'Potato', 'Sausage', 'Tricycle', 'Violin', 'Egg', 'Fire Extinguisher', 'Candy', 'Fire Truck',
+ 'Billiards', 'Converter', 'Bathtub', 'Wheelchair', 'Golf Club', 'Briefcase', 'Cucumber', 'Cigar/Cigarette',
+ 'Paint Brush', 'Pear', 'Heavy Truck', 'Hamburger', 'Extractor', 'Extension Cord', 'Tong', 'Tennis Racket',
+ 'Folder', 'American Football', 'earphone', 'Mask', 'Kettle', 'Tennis', 'Ship', 'Swing', 'Coffee Machine',
+ 'Slide', 'Carriage', 'Onion', 'Green beans', 'Projector', 'Frisbee', 'Washing Machine/Drying Machine',
+ 'Chicken', 'Printer', 'Watermelon', 'Saxophone', 'Tissue', 'Toothbrush', 'Ice cream', 'Hot-air balloon',
+ 'Cello', 'French Fries', 'Scale', 'Trophy', 'Cabbage', 'Hot dog', 'Blender', 'Peach', 'Rice', 'Wallet/Purse',
+ 'Volleyball', 'Deer', 'Goose', 'Tape', 'Tablet', 'Cosmetics', 'Trumpet', 'Pineapple', 'Golf Ball',
+ 'Ambulance', 'Parking meter', 'Mango', 'Key', 'Hurdle', 'Fishing Rod', 'Medal', 'Flute', 'Brush', 'Penguin',
+ 'Megaphone', 'Corn', 'Lettuce', 'Garlic', 'Swan', 'Helicopter', 'Green Onion', 'Sandwich', 'Nuts',
+ 'Speed Limit Sign', 'Induction Cooker', 'Broom', 'Trombone', 'Plum', 'Rickshaw', 'Goldfish', 'Kiwi fruit',
+ 'Router/modem', 'Poker Card', 'Toaster', 'Shrimp', 'Sushi', 'Cheese', 'Notepaper', 'Cherry', 'Pliers', 'CD',
+ 'Pasta', 'Hammer', 'Cue', 'Avocado', 'Hamimelon', 'Flask', 'Mushroom', 'Screwdriver', 'Soap', 'Recorder',
+ 'Bear', 'Eggplant', 'Board Eraser', 'Coconut', 'Tape Measure/Ruler', 'Pig', 'Showerhead', 'Globe', 'Chips',
+ 'Steak', 'Crosswalk Sign', 'Stapler', 'Camel', 'Formula 1', 'Pomegranate', 'Dishwasher', 'Crab',
+ 'Hoverboard', 'Meat ball', 'Rice Cooker', 'Tuba', 'Calculator', 'Papaya', 'Antelope', 'Parrot', 'Seal',
+ 'Butterfly', 'Dumbbell', 'Donkey', 'Lion', 'Urinal', 'Dolphin', 'Electric Drill', 'Hair Dryer', 'Egg tart',
+ 'Jellyfish', 'Treadmill', 'Lighter', 'Grapefruit', 'Game board', 'Mop', 'Radish', 'Baozi', 'Target', 'French',
+ 'Spring Rolls', 'Monkey', 'Rabbit', 'Pencil Case', 'Yak', 'Red Cabbage', 'Binoculars', 'Asparagus', 'Barbell',
+ 'Scallop', 'Noddles', 'Comb', 'Dumpling', 'Oyster', 'Table Tennis paddle', 'Cosmetics Brush/Eyeliner Pencil',
+ 'Chainsaw', 'Eraser', 'Lobster', 'Durian', 'Okra', 'Lipstick', 'Cosmetics Mirror', 'Curling', 'Table Tennis']
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from tqdm import tqdm
+
+ from utils.general import Path, check_requirements, download, np, xyxy2xywhn
+
+ check_requirements(('pycocotools>=2.0',))
+ from pycocotools.coco import COCO
+
+ # Make Directories
+ dir = Path(yaml['path']) # dataset root dir
+ for p in 'images', 'labels':
+ (dir / p).mkdir(parents=True, exist_ok=True)
+ for q in 'train', 'val':
+ (dir / p / q).mkdir(parents=True, exist_ok=True)
+
+ # Train, Val Splits
+ for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
+ print(f"Processing {split} in {patches} patches ...")
+ images, labels = dir / 'images' / split, dir / 'labels' / split
+
+ # Download
+ url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
+ if split == 'train':
+ download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir, delete=False) # annotations json
+ download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, delete=False, threads=8)
+ elif split == 'val':
+ download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir, delete=False) # annotations json
+ download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, delete=False, threads=8)
+ download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, delete=False, threads=8)
+
+ # Move
+ for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
+ f.rename(images / f.name) # move to /images/{split}
+
+ # Labels
+ coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
+ names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
+ for cid, cat in enumerate(names):
+ catIds = coco.getCatIds(catNms=[cat])
+ imgIds = coco.getImgIds(catIds=catIds)
+ for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
+ width, height = im["width"], im["height"]
+ path = Path(im["file_name"]) # image filename
+ try:
+ with open(labels / path.with_suffix('.txt').name, 'a') as file:
+ annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=None)
+ for a in coco.loadAnns(annIds):
+ x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
+ xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
+ x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
+ file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
+ except Exception as e:
+ print(e)
diff --git a/data/SKU-110K.yaml b/data/SKU-110K.yaml
new file mode 100755
index 0000000..2acf34d
--- /dev/null
+++ b/data/SKU-110K.yaml
@@ -0,0 +1,53 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
+# Example usage: python train.py --data SKU-110K.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── SKU-110K ← downloads here (13.6 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/SKU-110K # dataset root dir
+train: train.txt # train images (relative to 'path') 8219 images
+val: val.txt # val images (relative to 'path') 588 images
+test: test.txt # test images (optional) 2936 images
+
+# Classes
+nc: 1 # number of classes
+names: ['object'] # class names
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import shutil
+ from tqdm import tqdm
+ from utils.general import np, pd, Path, download, xyxy2xywh
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ parent = Path(dir.parent) # download dir
+ urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
+ download(urls, dir=parent, delete=False)
+
+ # Rename directories
+ if dir.exists():
+ shutil.rmtree(dir)
+ (parent / 'SKU110K_fixed').rename(dir) # rename dir
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
+
+ # Convert labels
+ names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
+ for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
+ x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
+ images, unique_images = x[:, 0], np.unique(x[:, 0])
+ with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
+ f.writelines(f'./images/{s}\n' for s in unique_images)
+ for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
+ cls = 0 # single-class dataset
+ with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
+ for r in x[images == im]:
+ w, h = r[6], r[7] # image width, height
+ xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
+ f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
diff --git a/data/VOC.yaml b/data/VOC.yaml
new file mode 100755
index 0000000..740ec5b
--- /dev/null
+++ b/data/VOC.yaml
@@ -0,0 +1,81 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
+# Example usage: python train.py --data VOC.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VOC ← downloads here (2.8 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: /ssd/datasets/VOC
+train: # train images (relative to 'path') 16551 images
+ - images/train2012
+ - images/train2007
+ - images/val2012
+ - images/val2007
+val: # val images (relative to 'path') 4952 images
+ - images/test2007
+test: # test images (optional)
+ - images/test2007
+
+# Classes
+nc: 20 # number of classes
+names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
+ 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ import xml.etree.ElementTree as ET
+
+ from tqdm import tqdm
+ from utils.general import download, Path
+
+
+ def convert_label(path, lb_path, year, image_id):
+ def convert_box(size, box):
+ dw, dh = 1. / size[0], 1. / size[1]
+ x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
+ return x * dw, y * dh, w * dw, h * dh
+
+ in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
+ out_file = open(lb_path, 'w')
+ tree = ET.parse(in_file)
+ root = tree.getroot()
+ size = root.find('size')
+ w = int(size.find('width').text)
+ h = int(size.find('height').text)
+
+ for obj in root.iter('object'):
+ cls = obj.find('name').text
+ if cls in yaml['names'] and not int(obj.find('difficult').text) == 1:
+ xmlbox = obj.find('bndbox')
+ bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
+ cls_id = yaml['names'].index(cls) # class id
+ out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
+ f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
+ f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
+ download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
+
+ # Convert
+ path = dir / 'images/VOCdevkit'
+ for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
+ imgs_path = dir / 'images' / f'{image_set}{year}'
+ lbs_path = dir / 'labels' / f'{image_set}{year}'
+ imgs_path.mkdir(exist_ok=True, parents=True)
+ lbs_path.mkdir(exist_ok=True, parents=True)
+
+ with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
+ image_ids = f.read().strip().split()
+ for id in tqdm(image_ids, desc=f'{image_set}{year}'):
+ f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
+ lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
+ f.rename(imgs_path / f.name) # move image
+ convert_label(path, lb_path, year, id) # convert labels to YOLO format
diff --git a/data/VisDrone.yaml b/data/VisDrone.yaml
new file mode 100755
index 0000000..10337b4
--- /dev/null
+++ b/data/VisDrone.yaml
@@ -0,0 +1,61 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
+# Example usage: python train.py --data VisDrone.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── VisDrone ← downloads here (2.3 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/VisDrone # dataset root dir
+train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
+val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
+test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
+
+# Classes
+nc: 10 # number of classes
+names: ['pedestrian', 'people', 'bicycle', 'car', 'van', 'truck', 'tricycle', 'awning-tricycle', 'bus', 'motor']
+
+
+# Download script/URL (optional) ---------------------------------------------------------------------------------------
+download: |
+ from utils.general import download, os, Path
+
+ def visdrone2yolo(dir):
+ from PIL import Image
+ from tqdm import tqdm
+
+ def convert_box(size, box):
+ # Convert VisDrone box to YOLO xywh box
+ dw = 1. / size[0]
+ dh = 1. / size[1]
+ return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
+
+ (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
+ pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
+ for f in pbar:
+ img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
+ lines = []
+ with open(f, 'r') as file: # read annotation.txt
+ for row in [x.split(',') for x in file.read().strip().splitlines()]:
+ if row[4] == '0': # VisDrone 'ignored regions' class 0
+ continue
+ cls = int(row[5]) - 1
+ box = convert_box(img_size, tuple(map(int, row[:4])))
+ lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
+ with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
+ fl.writelines(lines) # write label.txt
+
+
+ # Download
+ dir = Path(yaml['path']) # dataset root dir
+ urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
+ 'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
+ download(urls, dir=dir, curl=True, threads=4)
+
+ # Convert
+ for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
+ visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
diff --git a/data/coco.yaml b/data/coco.yaml
new file mode 100755
index 0000000..0c0c4ad
--- /dev/null
+++ b/data/coco.yaml
@@ -0,0 +1,45 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO 2017 dataset http://cocodataset.org by Microsoft
+# Example usage: python train.py --data coco.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco ← downloads here (20.1 GB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco # dataset root dir
+train: train2017.txt # train images (relative to 'path') 118287 images
+val: val2017.txt # val images (relative to 'path') 5000 images
+test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
+
+# Classes
+nc: 80 # number of classes
+names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
+ 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
+ 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
+ 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
+ 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
+ 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
+ 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
+ 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
+ 'hair drier', 'toothbrush'] # class names
+
+
+# Download script/URL (optional)
+download: |
+ from utils.general import download, Path
+
+
+ # Download labels
+ segments = False # segment or box labels
+ dir = Path(yaml['path']) # dataset root dir
+ url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
+ urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
+ download(urls, dir=dir.parent)
+
+ # Download data
+ urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
+ 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
+ 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
+ download(urls, dir=dir / 'images', threads=3)
diff --git a/data/coco128.yaml b/data/coco128.yaml
new file mode 100755
index 0000000..2517d20
--- /dev/null
+++ b/data/coco128.yaml
@@ -0,0 +1,30 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
+# Example usage: python train.py --data coco128.yaml
+# parent
+# ├── yolov5
+# └── datasets
+# └── coco128 ← downloads here (7 MB)
+
+
+# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
+path: ../datasets/coco128 # dataset root dir
+train: images/train2017 # train images (relative to 'path') 128 images
+val: images/train2017 # val images (relative to 'path') 128 images
+test: # test images (optional)
+
+# Classes
+nc: 80 # number of classes
+names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
+ 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
+ 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
+ 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
+ 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
+ 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
+ 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
+ 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
+ 'hair drier', 'toothbrush'] # class names
+
+
+# Download script/URL (optional)
+download: https://ultralytics.com/assets/coco128.zip
diff --git a/data/hyps/hyp.Objects365.yaml b/data/hyps/hyp.Objects365.yaml
new file mode 100755
index 0000000..4766d42
--- /dev/null
+++ b/data/hyps/hyp.Objects365.yaml
@@ -0,0 +1,35 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for Objects365 training
+# python train.py --weights yolov5m.pt --data Objects365.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.00258
+lrf: 0.17
+momentum: 0.779
+weight_decay: 0.00058
+warmup_epochs: 1.33
+warmup_momentum: 0.86
+warmup_bias_lr: 0.0711
+box: 0.0539
+cls: 0.299
+cls_pw: 0.825
+obj: 0.632
+obj_pw: 1.0
+iou_t: 0.2
+anchor_t: 3.44
+anchors: 3.2
+fl_gamma: 0.0
+hsv_h: 0.0188
+hsv_s: 0.704
+hsv_v: 0.36
+degrees: 0.0
+rotation_prob: 1.0
+translate: 0.0902
+scale: 0.491
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 1.0
+mixup: 0.0
+copy_paste: 0.0
diff --git a/data/hyps/hyp.VOC.yaml b/data/hyps/hyp.VOC.yaml
new file mode 100755
index 0000000..76e73e7
--- /dev/null
+++ b/data/hyps/hyp.VOC.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for VOC training
+# python train.py --batch 128 --weights yolov5m6.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.scratch-med.yaml --evolve
+# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
+
+# YOLOv5 Hyperparameter Evolution Results
+# Best generation: 467
+# Last generation: 996
+# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
+# 0.87729, 0.85125, 0.91286, 0.72664, 0.0076739, 0.0042529, 0.0013865
+
+lr0: 0.00334
+lrf: 0.15135
+momentum: 0.74832
+weight_decay: 0.00025
+warmup_epochs: 3.3835
+warmup_momentum: 0.59462
+warmup_bias_lr: 0.18657
+box: 0.02
+cls: 0.21638
+cls_pw: 0.5
+obj: 0.51728
+obj_pw: 0.67198
+iou_t: 0.2
+anchor_t: 3.3744
+fl_gamma: 0.0
+hsv_h: 0.01041
+hsv_s: 0.54703
+hsv_v: 0.27739
+degrees: 0.0
+rotation_prob: 1.0
+translate: 0.04591
+scale: 0.75544
+shear: 0.0
+perspective: 0.0
+flipud: 0.0
+fliplr: 0.5
+mosaic: 0.85834
+mixup: 0.04266
+copy_paste: 0.0
+anchors: 3.412
diff --git a/data/hyps/hyp.coco_pruning.yaml b/data/hyps/hyp.coco_pruning.yaml
new file mode 100644
index 0000000..62d2fd7
--- /dev/null
+++ b/data/hyps/hyp.coco_pruning.yaml
@@ -0,0 +1,57 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.0012278
+lrf: 0.7922
+momentum: 0.82344
+weight_decay: 0.00018297
+warmup_epochs: 3.275
+warmup_momentum: 0.49071
+warmup_bias_lr: 0.050513
+box: 0.05
+cls: 0.5
+cls_pw: 1.0
+obj: 1.0
+obj_pw: 1.0
+iou_t: 0.2
+anchor_t: 2.2923
+fl_gamma: 0.0
+hsv_h: 0.215
+hsv_s: 0.7
+hsv_v: 0.4
+degrees: 45.0
+rotation_prob: 0.3
+translate: 0.1
+scale: 0.3
+shear: 0.0
+perspective: 0.0005
+flipud: 0.0
+fliplr: 0.5
+mosaic: 1.0
+mixup: 0.0
+copy_paste: 0.0
+anchors: 5.1285
+pruning:
+ pruning_mode: optimal
+ calibration_steps: null
+ calibration_epochs: 1
+ equal:
+ pruning_ratio: 0.31
+ global_wrt_metric:
+ maximal_acceptable_metric_drop: 0.02
+ minimal_channels_to_prune: 10
+ maximal_channels_to_prune: 150
+ channel_step_to_search: 10
+ optimal:
+ latency_type: flops
+ time:
+ warmup: 10
+ repeat: 50
+ number: 50
+ backend: ort_cpu # choose from ['torch', 'ort_cpu']
+ target_latency: null
+ target_latency_fraction: 0.5
+ n_search_steps: 200
+ latency_penalty: 300
\ No newline at end of file
diff --git a/data/hyps/hyp.scratch-high.yaml b/data/hyps/hyp.scratch-high.yaml
new file mode 100755
index 0000000..d9f0314
--- /dev/null
+++ b/data/hyps/hyp.scratch-high.yaml
@@ -0,0 +1,45 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for high-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+rotation_prob: 1.0 # image rotation probability
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.1 # segment copy-paste (probability)
+
+# WARNING: please run hyperparameter evolution before you run training
+# albumentatuin augs
+blur: 0.01 # blur image using a random-sized kernel
+median_blur: 0.01 # median blur
+gray: 0.01 # convert image to gray
+clahe: 0.01 # CLAHE augmentations
+brightness_contrast: 0.01 # random brightness and contrast augmentation
+random_gamma: 0.01 # random gamma
+image_compression: 0.01 # image compression
diff --git a/data/hyps/hyp.scratch-low.yaml b/data/hyps/hyp.scratch-low.yaml
new file mode 100755
index 0000000..9bc27b1
--- /dev/null
+++ b/data/hyps/hyp.scratch-low.yaml
@@ -0,0 +1,45 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for low-augmentation COCO training from scratch
+# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.5 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 1.0 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+rotation_prob: 1.0 # image rotation probability
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.5 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.0 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
+
+# WARNING: please run hyperparameter evolution before you run training
+# albumentatuin augs
+blur: 0.01 # blur image using a random-sized kernel
+median_blur: 0.01 # median blur
+gray: 0.01 # convert image to gray
+clahe: 0.01 # CLAHE augmentations
+brightness_contrast: 0.01 # random brightness and contrast augmentation
+random_gamma: 0.01 # random gamma
+image_compression: 0.01 # image compression
diff --git a/data/hyps/hyp.scratch-med.yaml b/data/hyps/hyp.scratch-med.yaml
new file mode 100755
index 0000000..9059880
--- /dev/null
+++ b/data/hyps/hyp.scratch-med.yaml
@@ -0,0 +1,45 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for medium-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.937 # SGD momentum/Adam beta1
+weight_decay: 0.0005 # optimizer weight decay 5e-4
+warmup_epochs: 3.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.8 # warmup initial momentum
+warmup_bias_lr: 0.1 # warmup initial bias lr
+box: 0.05 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+# anchors: 3 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+rotation_prob: 1.0 # image rotation probability
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.0 # segment copy-paste (probability)
+
+# WARNING: please run hyperparameter evolution before you run training
+# albumentatuin augs
+blur: 0.01 # blur image using a random-sized kernel
+median_blur: 0.01 # median blur
+gray: 0.01 # convert image to gray
+clahe: 0.01 # CLAHE augmentations
+brightness_contrast: 0.01 # random brightness and contrast augmentation
+random_gamma: 0.01 # random gamma
+image_compression: 0.01 # image compression
diff --git a/data/images/bus.jpg b/data/images/bus.jpg
new file mode 100755
index 0000000..b43e311
Binary files /dev/null and b/data/images/bus.jpg differ
diff --git a/data/images/zidane.jpg b/data/images/zidane.jpg
new file mode 100755
index 0000000..92d72ea
Binary files /dev/null and b/data/images/zidane.jpg differ
diff --git a/data/scripts/download_weights.sh b/data/scripts/download_weights.sh
new file mode 100755
index 0000000..e9fa653
--- /dev/null
+++ b/data/scripts/download_weights.sh
@@ -0,0 +1,20 @@
+#!/bin/bash
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Download latest models from https://github.com/ultralytics/yolov5/releases
+# Example usage: bash path/to/download_weights.sh
+# parent
+# └── yolov5
+# ├── yolov5s.pt ← downloads here
+# ├── yolov5m.pt
+# └── ...
+
+python - <
= cls >= 0, f'incorrect class index {cls}'
+
+ # Write YOLO label
+ if id not in shapes:
+ shapes[id] = Image.open(file).size
+ box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
+ with open((labels / id).with_suffix('.txt'), 'a') as f:
+ f.write(f"{cls} {' '.join(f'{x:.6f}' for x in box[0])}\n") # write label.txt
+ except Exception as e:
+ print(f'WARNING: skipping one label for {file}: {e}')
+
+
+ # Download manually from https://challenge.xviewdataset.org
+ dir = Path(yaml['path']) # dataset root dir
+ # urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
+ # 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
+ # 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
+ # download(urls, dir=dir, delete=False)
+
+ # Convert labels
+ convert_labels(dir / 'xView_train.geojson')
+
+ # Move images
+ images = Path(dir / 'images')
+ images.mkdir(parents=True, exist_ok=True)
+ Path(dir / 'train_images').rename(dir / 'images' / 'train')
+ Path(dir / 'val_images').rename(dir / 'images' / 'val')
+
+ # Split
+ autosplit(dir / 'images' / 'train')
diff --git a/demo.ipynb b/demo.ipynb
new file mode 100755
index 0000000..0410344
--- /dev/null
+++ b/demo.ipynb
@@ -0,0 +1,457 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "be2cc57c",
+ "metadata": {},
+ "source": [
+ "## Evaluate baseline model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cba199ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%env CUDA_VISIBLE_DEVICES=0"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5166c0c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from val import run as run_val\n",
+ "\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'yolov5s.pt',\n",
+ " 'half': True,\n",
+ " 'batch_size': 3, # 32\n",
+ "}\n",
+ "\n",
+ "run_val(**opt);\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "085c9710",
+ "metadata": {},
+ "source": [
+ "## Optimize model with ENOT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58eaeb32",
+ "metadata": {
+ "scrolled": false
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from prune import run as run_prune\n",
+ "\n",
+ "opt = {\n",
+ " 'device': 0,\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'yolov5s.pt',\n",
+ " 'half': True,\n",
+ " 'batch_size': 3, # 32\n",
+ " 'imgsz': 640,\n",
+ " 'hyp': 'data/hyps/hyp.coco_pruning.yaml',\n",
+ " 'name': 'prune_yolov5s_coco',\n",
+ " 'save_before_prune': True,\n",
+ " 'n_search_steps': 3, # This value is just for demo, in production we recommend to use more than 200 steps.\n",
+ " 'target-latency-fraction': 0.5, # It means that optimized model will be 2 times faster that baseline.\n",
+ "}\n",
+ "\n",
+ "run_prune(**opt);\n",
+ "torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed2ac368",
+ "metadata": {},
+ "source": [
+ "## Make onnx for original and optimized models"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "98e762bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from export import run as run_export\n",
+ "\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'runs/prune/prune_yolov5s_coco/weights/original_model.pt',\n",
+ " 'batch_size': 1,\n",
+ " 'imgsz': [640],\n",
+ " 'include': ['onnx'],\n",
+ "}\n",
+ "\n",
+ "run_export(**opt)\n",
+ "\n",
+ "opt['weights'] = 'runs/prune/prune_yolov5s_coco/weights/pruned_model.pt'\n",
+ "\n",
+ "run_export(**opt)\n",
+ "torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f9eee885",
+ "metadata": {},
+ "source": [
+ "## Run optimized model tuning"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "194b6b27",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from train import run as run_tune\n",
+ "\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'runs/prune/prune_yolov5s_coco/weights/pruned_model.pt',\n",
+ " 'batch_size': 3, # 32\n",
+ " 'imgsz': 640,\n",
+ " 'from_pruned': True,\n",
+ " 'epochs': 1,\n",
+ " 'device': 0,\n",
+ " 'name': 'tune_pruned_model',\n",
+ "}\n",
+ "\n",
+ "run_tune(**opt)\n",
+ "torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "80c7ea6d",
+ "metadata": {},
+ "source": [
+ "## Evaluate tuned optimized model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "774184d8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from val import run as run_val\n",
+ "\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'runs/train/tune_pruned_model/weights/best.pt',\n",
+ " 'half': True,\n",
+ " 'batch_size': 3, # 32\n",
+ " 'imgsz': 640,\n",
+ "}\n",
+ "\n",
+ "run_val(**opt);\n",
+ "torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f9dd3d46",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from detect import run as run_detect\n",
+ "\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'source': '../datasets/coco128/images/train2017/',\n",
+ " 'weights': 'runs/train/tune_pruned_model/weights/best.pt',\n",
+ " 'half': True,\n",
+ " 'imgsz': (640, 640),\n",
+ " 'name': 'optimized_model'\n",
+ "}\n",
+ "run_detect(**opt)\n",
+ "torch.cuda.empty_cache()\n",
+ "\n",
+ "opt['name'] = 'original_model'\n",
+ "opt['weights'] = 'yolov5s.pt'\n",
+ "run_detect(**opt)\n",
+ "torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3bcf0558",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Uncomment this if you want to show results\n",
+ "\n",
+ "%matplotlib inline\n",
+ "import cv2\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "original_predict = cv2.imread('runs/detect/original_model/000000000009.jpg')\n",
+ "optimized_predict = cv2.imread('runs/detect/optimized_model/000000000009.jpg')\n",
+ "\n",
+ "figsize = 10\n",
+ "plt.figure(figsize=(figsize, figsize))\n",
+ "plt.imshow(cv2.hconcat([original_predict, optimized_predict])[:,:,::-1])\n",
+ "plt.grid(visible=False)\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb253f6a",
+ "metadata": {},
+ "source": [
+ "# OpenVino quantization"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f89ee8ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from export import run as run_export\n",
+ "\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'runs/train/tune_pruned_model/weights/best.pt',\n",
+ " 'batch_size': 1,\n",
+ " 'imgsz': [640],\n",
+ " 'include': ['onnx'],\n",
+ "}\n",
+ "\n",
+ "run_export(**opt)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b5dcbdf",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "%env CUDA_VISIBLE_DEVICES=0\n",
+ "from quant import run as run_quant\n",
+ "opt = {\n",
+ " 'data': 'data/coco128.yaml',\n",
+ " 'weights': 'runs/train/tune_pruned_model/weights/best.onnx',\n",
+ " 'batch_size': 1,\n",
+ " 'imgsz': 640,\n",
+ " 'device': 'cuda',\n",
+ " 'backend': 'openvino',\n",
+ " 'n_epochs': 2,\n",
+ "}\n",
+ "\n",
+ "run_quant(**opt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0524eaf3",
+ "metadata": {},
+ "source": [
+ "# Run quantized model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "643f857b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from enot_lite.backend import BackendFactory\n",
+ "from enot_lite.type import BackendType\n",
+ "\n",
+ "inputs = np.ones((1,3,640,640), dtype=np.float32)\n",
+ "backend = BackendFactory().create(\n",
+ " 'runs/train/tune_pruned_model/weights/best_quant.onnx',\n",
+ " BackendType.ORT_OPENVINO,\n",
+ " input_example=inputs,\n",
+ ")\n",
+ "\n",
+ "prediction = backend(inputs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5bbb2087",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prediction"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f1bbe923",
+ "metadata": {},
+ "source": [
+ "# Check acceleration"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5ccd79ff",
+ "metadata": {},
+ "source": [
+ "### Baseline"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c4ea1e0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from enot_lite.benchmark import Benchmark\n",
+ "from enot_lite.type import BackendType\n",
+ "\n",
+ "benchmark = Benchmark(\n",
+ " batch_size=1,\n",
+ " onnx_model='runs/prune/prune_yolov5s_coco/weights/original_model.onnx',\n",
+ " onnx_input=(np.ones((1, 3, 640, 640), dtype=np.float32),),\n",
+ " backends=[BackendType.ORT_OPENVINO],\n",
+ " number=10,\n",
+ " warmup=10,\n",
+ " repeat=10\n",
+ ")\n",
+ "\n",
+ "benchmark.run()\n",
+ "benchmark.print_results()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ccaef57",
+ "metadata": {},
+ "source": [
+ "### Pruned"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9d5c9fdf",
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from enot_lite.benchmark import Benchmark\n",
+ "from enot_lite.type import BackendType\n",
+ "\n",
+ "benchmark = Benchmark(\n",
+ " batch_size=1,\n",
+ " onnx_model='runs/train/tune_pruned_model/weights/best.onnx',\n",
+ " onnx_input=(np.ones((1, 3, 640, 640), dtype=np.float32),),\n",
+ " backends=[BackendType.ORT_OPENVINO],\n",
+ " number=10,\n",
+ " warmup=10,\n",
+ " repeat=10\n",
+ ")\n",
+ "\n",
+ "benchmark.run()\n",
+ "benchmark.print_results()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c9f31a5b",
+ "metadata": {},
+ "source": [
+ "### Quantized"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d07c949a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from enot_lite.benchmark import Benchmark\n",
+ "from enot_lite.type import BackendType\n",
+ "\n",
+ "benchmark = Benchmark(\n",
+ " batch_size=1,\n",
+ " onnx_model='runs/train/tune_pruned_model/weights/best_quant.onnx',\n",
+ " onnx_input=(np.ones((1, 3, 640, 640), dtype=np.float32),),\n",
+ " backends=[BackendType.ORT_OPENVINO],\n",
+ " number=10,\n",
+ " warmup=10,\n",
+ " repeat=10,\n",
+ ")\n",
+ "\n",
+ "benchmark.run()\n",
+ "benchmark.print_results()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8341e5cf",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.16"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/detect.py b/detect.py
new file mode 100755
index 0000000..82da4a6
--- /dev/null
+++ b/detect.py
@@ -0,0 +1,257 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Run inference on images, videos, directories, streams, etc.
+
+Usage - sources:
+ $ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
+ img.jpg # image
+ vid.mp4 # video
+ path/ # directory
+ path/*.jpg # glob
+ 'https://youtu.be/Zgi9g1ksQHc' # YouTube
+ 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
+
+Usage - formats:
+ $ python path/to/detect.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s.xml # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+"""
+
+import argparse
+import os
+import platform
+import sys
+from pathlib import Path
+
+import torch
+import torch.backends.cudnn as cudnn
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
+from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
+ increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, smart_inference_mode, time_sync
+
+
+@smart_inference_mode()
+def run(
+ weights=ROOT / 'yolov5s.pt', # model.pt path(s)
+ source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ imgsz=(640, 640), # inference size (height, width)
+ conf_thres=0.25, # confidence threshold
+ iou_thres=0.45, # NMS IOU threshold
+ max_det=1000, # maximum detections per image
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img=False, # show results
+ save_txt=False, # save results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_crop=False, # save cropped prediction boxes
+ nosave=False, # do not save images/videos
+ classes=None, # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms=False, # class-agnostic NMS
+ augment=False, # augmented inference
+ visualize=False, # visualize features
+ update=False, # update all models
+ project=ROOT / 'runs/detect', # save results to project/name
+ name='exp', # save results to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ line_thickness=3, # bounding box thickness (pixels)
+ hide_labels=False, # hide labels
+ hide_conf=False, # hide confidences
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+):
+ source = str(source)
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
+ is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
+ webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
+ if is_url and is_file:
+ source = check_file(source) # download
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, names, pt = model.stride, model.names, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+
+ # Dataloader
+ if webcam:
+ view_img = check_imshow()
+ cudnn.benchmark = True # set True to speed up constant image size inference
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
+ bs = len(dataset) # batch_size
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
+ bs = 1 # batch_size
+ vid_path, vid_writer = [None] * bs, [None] * bs
+
+ # Run inference
+ model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
+ seen, windows, dt = 0, [], [0.0, 0.0, 0.0]
+ for path, im, im0s, vid_cap, s in dataset:
+ t1 = time_sync()
+ im = torch.from_numpy(im).to(device)
+ im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ t2 = time_sync()
+ dt[0] += t2 - t1
+
+ # Inference
+ visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+ t3 = time_sync()
+ dt[1] += t3 - t2
+
+ # NMS
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+ dt[2] += time_sync() - t3
+
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+
+ p = Path(p) # to Path
+ save_path = str(save_dir / p.name) # im.jpg
+ txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(f'{txt_path}.txt', 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ if save_crop:
+ save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
+
+ # Stream results
+ im0 = annotator.result()
+ if view_img:
+ if platform.system() == 'Linux' and p not in windows:
+ windows.append(p)
+ cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
+ cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
+ cv2.imshow(str(p), im0)
+ cv2.waitKey(1) # 1 millisecond
+
+ # Save results (image with detections)
+ if save_img:
+ if dataset.mode == 'image':
+ cv2.imwrite(save_path, im0)
+ else: # 'video' or 'stream'
+ if vid_path[i] != save_path: # new video
+ vid_path[i] = save_path
+ if isinstance(vid_writer[i], cv2.VideoWriter):
+ vid_writer[i].release() # release previous video writer
+ if vid_cap: # video
+ fps = vid_cap.get(cv2.CAP_PROP_FPS)
+ w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ else: # stream
+ fps, w, h = 30, im0.shape[1], im0.shape[0]
+ save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
+ vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ vid_writer[i].write(im0)
+
+ # Print time (inference-only)
+ LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
+
+ # Print results
+ t = tuple(x / seen * 1E3 for x in dt) # speeds per image
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
+ if save_txt or save_img:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ if update:
+ strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--view-img', action='store_true', help='show results')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
+ parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
+ parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
+ parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--visualize', action='store_true', help='visualize features')
+ parser.add_argument('--update', action='store_true', help='update all models')
+ parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
+ parser.add_argument('--name', default='exp', help='save results to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
+ parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
+ parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(exclude=('tensorboard', 'thop', 'fvcore'))
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/export.py b/export.py
new file mode 100755
index 0000000..c88a510
--- /dev/null
+++ b/export.py
@@ -0,0 +1,618 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
+
+Format | `export.py --include` | Model
+--- | --- | ---
+PyTorch | - | yolov5s.pt
+TorchScript | `torchscript` | yolov5s.torchscript
+ONNX | `onnx` | yolov5s.onnx
+OpenVINO | `openvino` | yolov5s_openvino_model/
+TensorRT | `engine` | yolov5s.engine
+CoreML | `coreml` | yolov5s.mlmodel
+TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
+TensorFlow GraphDef | `pb` | yolov5s.pb
+TensorFlow Lite | `tflite` | yolov5s.tflite
+TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
+TensorFlow.js | `tfjs` | yolov5s_web_model/
+
+Requirements:
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
+
+Usage:
+ $ python path/to/export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
+
+Inference:
+ $ python path/to/detect.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s.xml # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+
+TensorFlow.js:
+ $ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
+ $ npm install
+ $ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
+ $ npm start
+"""
+
+import argparse
+import json
+import os
+import platform
+import subprocess
+import sys
+import time
+import warnings
+from pathlib import Path
+
+import pandas as pd
+import torch
+import yaml
+from torch.utils.mobile_optimizer import optimize_for_mobile
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+if platform.system() != 'Windows':
+ ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.experimental import attempt_load
+from models.yolo import Detect
+from utils.dataloaders import LoadImages
+from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, check_version, check_yaml,
+ colorstr, file_size, print_args, url2file)
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def export_formats():
+ # YOLOv5 export formats
+ x = [
+ ['PyTorch', '-', '.pt', True, True],
+ ['TorchScript', 'torchscript', '.torchscript', True, True],
+ ['ONNX', 'onnx', '.onnx', True, True],
+ ['OpenVINO', 'openvino', '_openvino_model', True, False],
+ ['TensorRT', 'engine', '.engine', False, True],
+ ['CoreML', 'coreml', '.mlmodel', True, False],
+ ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
+ ['TensorFlow GraphDef', 'pb', '.pb', True, True],
+ ['TensorFlow Lite', 'tflite', '.tflite', True, False],
+ ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
+ ['TensorFlow.js', 'tfjs', '_web_model', False, False],]
+ return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
+
+
+def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
+ # YOLOv5 TorchScript model export
+ try:
+ LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
+ f = file.with_suffix('.torchscript')
+
+ ts = torch.jit.trace(model, im, strict=False)
+ d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
+ extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
+ if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
+ optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
+ else:
+ ts.save(str(f), _extra_files=extra_files)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure: {e}')
+
+
+def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
+ # YOLOv5 ONNX export
+ try:
+ check_requirements(('onnx',))
+ import onnx
+
+ LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
+ f = file.with_suffix('.onnx')
+
+ torch.onnx.export(
+ model.cpu() if dynamic else model, # --dynamic only compatible with cpu
+ im.cpu() if dynamic else im,
+ f,
+ verbose=False,
+ opset_version=opset,
+ training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
+ do_constant_folding=not train,
+ input_names=['images'],
+ output_names=['output'],
+ dynamic_axes={
+ 'images': {
+ 0: 'batch',
+ 2: 'height',
+ 3: 'width'}, # shape(1,3,640,640)
+ 'output': {
+ 0: 'batch',
+ 1: 'anchors'} # shape(1,25200,85)
+ } if dynamic else None)
+
+ # Checks
+ model_onnx = onnx.load(f) # load onnx model
+ onnx.checker.check_model(model_onnx) # check onnx model
+
+ # Metadata
+ d = {'stride': int(max(model.stride)), 'names': model.names}
+ for k, v in d.items():
+ meta = model_onnx.metadata_props.add()
+ meta.key, meta.value = k, str(v)
+ onnx.save(model_onnx, f)
+
+ # Simplify
+ if simplify:
+ try:
+ cuda = torch.cuda.is_available()
+ check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
+ import onnxsim
+
+ LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
+ model_onnx, check = onnxsim.simplify(model_onnx)
+ assert check, 'assert check failed'
+ onnx.save(model_onnx, f)
+ except Exception as e:
+ LOGGER.info(f'{prefix} simplifier failure: {e}')
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure: {e}')
+
+
+def export_openvino(model, file, half, prefix=colorstr('OpenVINO:')):
+ # YOLOv5 OpenVINO export
+ try:
+ check_requirements(('openvino-dev',)) # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ import openvino.inference_engine as ie
+
+ LOGGER.info(f'\n{prefix} starting export with openvino {ie.__version__}...')
+ f = str(file).replace('.pt', f'_openvino_model{os.sep}')
+
+ cmd = f"mo --input_model {file.with_suffix('.onnx')} --output_dir {f} --data_type {'FP16' if half else 'FP32'}"
+ subprocess.check_output(cmd.split()) # export
+ with open(Path(f) / file.with_suffix('.yaml').name, 'w') as g:
+ yaml.dump({'stride': int(max(model.stride)), 'names': model.names}, g) # add metadata.yaml
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_coreml(model, im, file, int8, half, prefix=colorstr('CoreML:')):
+ # YOLOv5 CoreML export
+ try:
+ check_requirements(('coremltools',))
+ import coremltools as ct
+
+ LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
+ f = file.with_suffix('.mlmodel')
+
+ ts = torch.jit.trace(model, im, strict=False) # TorchScript model
+ ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
+ bits, mode = (8, 'kmeans_lut') if int8 else (16, 'linear') if half else (32, None)
+ if bits < 32:
+ if platform.system() == 'Darwin': # quantization only supported on macOS
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=DeprecationWarning) # suppress numpy==1.20 float warning
+ ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
+ else:
+ print(f'{prefix} quantization only supported on macOS, skipping...')
+ ct_model.save(f)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return ct_model, f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+ return None, None
+
+
+def export_engine(model, im, file, train, half, dynamic, simplify, workspace=4, verbose=False):
+ # YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
+ prefix = colorstr('TensorRT:')
+ try:
+ assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
+ try:
+ import tensorrt as trt
+ except Exception:
+ if platform.system() == 'Linux':
+ check_requirements(('nvidia-tensorrt',), cmds=('-U --index-url https://pypi.ngc.nvidia.com',))
+ import tensorrt as trt
+
+ if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
+ grid = model.model[-1].anchor_grid
+ model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
+ export_onnx(model, im, file, 12, train, dynamic, simplify) # opset 12
+ model.model[-1].anchor_grid = grid
+ else: # TensorRT >= 8
+ check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
+ export_onnx(model, im, file, 13, train, dynamic, simplify) # opset 13
+ onnx = file.with_suffix('.onnx')
+
+ LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
+ assert onnx.exists(), f'failed to export ONNX file: {onnx}'
+ f = file.with_suffix('.engine') # TensorRT engine file
+ logger = trt.Logger(trt.Logger.INFO)
+ if verbose:
+ logger.min_severity = trt.Logger.Severity.VERBOSE
+
+ builder = trt.Builder(logger)
+ config = builder.create_builder_config()
+ config.max_workspace_size = workspace * 1 << 30
+ # config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
+
+ flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
+ network = builder.create_network(flag)
+ parser = trt.OnnxParser(network, logger)
+ if not parser.parse_from_file(str(onnx)):
+ raise RuntimeError(f'failed to load ONNX file: {onnx}')
+
+ inputs = [network.get_input(i) for i in range(network.num_inputs)]
+ outputs = [network.get_output(i) for i in range(network.num_outputs)]
+ LOGGER.info(f'{prefix} Network Description:')
+ for inp in inputs:
+ LOGGER.info(f'{prefix}\tinput "{inp.name}" with shape {inp.shape} and dtype {inp.dtype}')
+ for out in outputs:
+ LOGGER.info(f'{prefix}\toutput "{out.name}" with shape {out.shape} and dtype {out.dtype}')
+
+ if dynamic:
+ if im.shape[0] <= 1:
+ LOGGER.warning(f"{prefix}WARNING: --dynamic model requires maximum --batch-size argument")
+ profile = builder.create_optimization_profile()
+ for inp in inputs:
+ profile.set_shape(inp.name, (1, *im.shape[1:]), (max(1, im.shape[0] // 2), *im.shape[1:]), im.shape)
+ config.add_optimization_profile(profile)
+
+ LOGGER.info(f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and half else 32} engine in {f}')
+ if builder.platform_has_fast_fp16 and half:
+ config.set_flag(trt.BuilderFlag.FP16)
+ with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
+ t.write(engine.serialize())
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_saved_model(model,
+ im,
+ file,
+ dynamic,
+ tf_nms=False,
+ agnostic_nms=False,
+ topk_per_class=100,
+ topk_all=100,
+ iou_thres=0.45,
+ conf_thres=0.25,
+ keras=False,
+ prefix=colorstr('TensorFlow SavedModel:')):
+ # YOLOv5 TensorFlow SavedModel export
+ try:
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ from models.tf import TFDetect, TFModel
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = str(file).replace('.pt', '_saved_model')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ im = tf.zeros((batch_size, *imgsz, ch)) # BHWC order for TensorFlow
+ _ = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ inputs = tf.keras.Input(shape=(*imgsz, ch), batch_size=None if dynamic else batch_size)
+ outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ keras_model = tf.keras.Model(inputs=inputs, outputs=outputs)
+ keras_model.trainable = False
+ keras_model.summary()
+ if keras:
+ keras_model.save(f, save_format='tf')
+ else:
+ spec = tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(spec)
+ frozen_func = convert_variables_to_constants_v2(m)
+ tfm = tf.Module()
+ tfm.__call__ = tf.function(lambda x: frozen_func(x)[:4] if tf_nms else frozen_func(x)[0], [spec])
+ tfm.__call__(im)
+ tf.saved_model.save(tfm,
+ f,
+ options=tf.saved_model.SaveOptions(experimental_custom_gradients=False)
+ if check_version(tf.__version__, '2.6') else tf.saved_model.SaveOptions())
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return keras_model, f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+ return None, None
+
+
+def export_pb(keras_model, file, prefix=colorstr('TensorFlow GraphDef:')):
+ # YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
+ try:
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = file.with_suffix('.pb')
+
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
+ frozen_func = convert_variables_to_constants_v2(m)
+ frozen_func.graph.as_graph_def()
+ tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_tflite(keras_model, im, file, int8, data, nms, agnostic_nms, prefix=colorstr('TensorFlow Lite:')):
+ # YOLOv5 TensorFlow Lite export
+ try:
+ import tensorflow as tf
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+ f = str(file).replace('.pt', '-fp16.tflite')
+
+ converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
+ converter.target_spec.supported_types = [tf.float16]
+ converter.optimizations = [tf.lite.Optimize.DEFAULT]
+ if int8:
+ from models.tf import representative_dataset_gen
+ dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
+ converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+ converter.target_spec.supported_types = []
+ converter.inference_input_type = tf.uint8 # or tf.int8
+ converter.inference_output_type = tf.uint8 # or tf.int8
+ converter.experimental_new_quantizer = True
+ f = str(file).replace('.pt', '-int8.tflite')
+ if nms or agnostic_nms:
+ converter.target_spec.supported_ops.append(tf.lite.OpsSet.SELECT_TF_OPS)
+
+ tflite_model = converter.convert()
+ open(f, "wb").write(tflite_model)
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_edgetpu(file, prefix=colorstr('Edge TPU:')):
+ # YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
+ try:
+ cmd = 'edgetpu_compiler --version'
+ help_url = 'https://coral.ai/docs/edgetpu/compiler/'
+ assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
+ if subprocess.run(f'{cmd} >/dev/null', shell=True).returncode != 0:
+ LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
+ sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
+ for c in (
+ 'curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
+ 'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
+ 'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
+ subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
+ ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
+
+ LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
+ f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
+ f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
+
+ cmd = f"edgetpu_compiler -s -d -k 10 --out_dir {file.parent} {f_tfl}"
+ subprocess.run(cmd.split(), check=True)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_tfjs(file, prefix=colorstr('TensorFlow.js:')):
+ # YOLOv5 TensorFlow.js export
+ try:
+ check_requirements(('tensorflowjs',))
+ import re
+
+ import tensorflowjs as tfjs
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
+ f = str(file).replace('.pt', '_web_model') # js dir
+ f_pb = file.with_suffix('.pb') # *.pb path
+ f_json = f'{f}/model.json' # *.json path
+
+ cmd = f'tensorflowjs_converter --input_format=tf_frozen_model ' \
+ f'--output_node_names=Identity,Identity_1,Identity_2,Identity_3 {f_pb} {f}'
+ subprocess.run(cmd.split())
+
+ with open(f_json) as j:
+ json = j.read()
+ with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
+ subst = re.sub(
+ r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}}}', r'{"outputs": {"Identity": {"name": "Identity"}, '
+ r'"Identity_1": {"name": "Identity_1"}, '
+ r'"Identity_2": {"name": "Identity_2"}, '
+ r'"Identity_3": {"name": "Identity_3"}}}', json)
+ j.write(subst)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ return f
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+@smart_inference_mode()
+def run(
+ data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # image (height, width)
+ batch_size=1, # batch size
+ device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ include=('torchscript', 'onnx'), # include formats
+ half=False, # FP16 half-precision export
+ inplace=False, # set YOLOv5 Detect() inplace=True
+ train=False, # model.train() mode
+ keras=False, # use Keras
+ optimize=False, # TorchScript: optimize for mobile
+ int8=False, # CoreML/TF INT8 quantization
+ dynamic=False, # ONNX/TF/TensorRT: dynamic axes
+ simplify=False, # ONNX: simplify model
+ opset=12, # ONNX: opset version
+ verbose=False, # TensorRT: verbose log
+ workspace=4, # TensorRT: workspace size (GB)
+ nms=False, # TF: add NMS to model
+ agnostic_nms=False, # TF: add agnostic NMS to model
+ topk_per_class=100, # TF.js NMS: topk per class to keep
+ topk_all=100, # TF.js NMS: topk for all classes to keep
+ iou_thres=0.45, # TF.js NMS: IoU threshold
+ conf_thres=0.25, # TF.js NMS: confidence threshold
+):
+ t = time.time()
+ include = [x.lower() for x in include] # to lowercase
+ fmts = tuple(export_formats()['Argument'][1:]) # --include arguments
+ flags = [x in include for x in fmts]
+ assert sum(flags) == len(include), f'ERROR: Invalid --include {include}, valid --include arguments are {fmts}'
+ jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs = flags # export booleans
+ file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights) # PyTorch weights
+
+ # Load PyTorch model
+ device = select_device(device)
+ if half:
+ assert device.type != 'cpu' or coreml, '--half only compatible with GPU export, i.e. use --device 0'
+ assert not dynamic, '--half not compatible with --dynamic, i.e. use either --half or --dynamic but not both'
+ model = attempt_load(weights, device=device, inplace=True, fuse=True) # load FP32 model
+ nc, names = model.nc, model.names # number of classes, class names
+
+ # Checks
+ imgsz *= 2 if len(imgsz) == 1 else 1 # expand
+ assert nc == len(names), f'Model class count {nc} != len(names) {len(names)}'
+ if optimize:
+ assert device.type == 'cpu', '--optimize not compatible with cuda devices, i.e. use --device cpu'
+
+ # Input
+ gs = int(max(model.stride)) # grid size (max stride)
+ imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
+ im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
+
+ # Update model
+ model.train() if train else model.eval() # training mode = no Detect() layer grid construction
+ for k, m in model.named_modules():
+ if isinstance(m, Detect):
+ m.inplace = inplace
+ m.onnx_dynamic = dynamic
+ m.export = True
+
+ for _ in range(2):
+ y = model(im) # dry runs
+ if half and not coreml:
+ im, model = im.half(), model.half() # to FP16
+ shape = tuple(y[0].shape) # model output shape
+ LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")
+
+ # Exports
+ f = [''] * 10 # exported filenames
+ warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
+ if jit:
+ f[0] = export_torchscript(model, im, file, optimize)
+ if engine: # TensorRT required before ONNX
+ f[1] = export_engine(model, im, file, train, half, dynamic, simplify, workspace, verbose)
+ if onnx or xml: # OpenVINO requires ONNX
+ f[2] = export_onnx(model, im, file, opset, train, dynamic, simplify)
+ if xml: # OpenVINO
+ f[3] = export_openvino(model, file, half)
+ if coreml:
+ _, f[4] = export_coreml(model, im, file, int8, half)
+
+ # TensorFlow Exports
+ if any((saved_model, pb, tflite, edgetpu, tfjs)):
+ if int8 or edgetpu: # TFLite --int8 bug https://github.com/ultralytics/yolov5/issues/5707
+ check_requirements(('flatbuffers==1.12',)) # required before `import tensorflow`
+ assert not tflite or not tfjs, 'TFLite and TF.js models must be exported separately, please pass only one type.'
+ model, f[5] = export_saved_model(model.cpu(),
+ im,
+ file,
+ dynamic,
+ tf_nms=nms or agnostic_nms or tfjs,
+ agnostic_nms=agnostic_nms or tfjs,
+ topk_per_class=topk_per_class,
+ topk_all=topk_all,
+ iou_thres=iou_thres,
+ conf_thres=conf_thres,
+ keras=keras)
+ if pb or tfjs: # pb prerequisite to tfjs
+ f[6] = export_pb(model, file)
+ if tflite or edgetpu:
+ f[7] = export_tflite(model, im, file, int8=int8 or edgetpu, data=data, nms=nms, agnostic_nms=agnostic_nms)
+ if edgetpu:
+ f[8] = export_edgetpu(file)
+ if tfjs:
+ f[9] = export_tfjs(file)
+
+ # Finish
+ f = [str(x) for x in f if x] # filter out '' and None
+ if any(f):
+ h = '--half' if half else '' # --half FP16 inference arg
+ LOGGER.info(f'\nExport complete ({time.time() - t:.2f}s)'
+ f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
+ f"\nDetect: python detect.py --weights {f[-1]} {h}"
+ f"\nValidate: python val.py --weights {f[-1]} {h}"
+ f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}')"
+ f"\nVisualize: https://netron.app")
+ return f # return list of exported files/dirs
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
+ parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
+ parser.add_argument('--train', action='store_true', help='model.train() mode')
+ parser.add_argument('--keras', action='store_true', help='TF: use Keras')
+ parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
+ parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
+ parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')
+ parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
+ parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
+ parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
+ parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
+ parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
+ parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
+ parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
+ parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
+ parser.add_argument('--include',
+ nargs='+',
+ default=['torchscript', 'onnx'],
+ help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/hubconf.py b/hubconf.py
new file mode 100755
index 0000000..011eaa5
--- /dev/null
+++ b/hubconf.py
@@ -0,0 +1,160 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5/
+
+Usage:
+ import torch
+ model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+ model = torch.hub.load('ultralytics/yolov5:master', 'custom', 'path/to/yolov5s.onnx') # file from branch
+"""
+
+import torch
+
+
+def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ """Creates or loads a YOLOv5 model
+
+ Arguments:
+ name (str): model name 'yolov5s' or path 'path/to/best.pt'
+ pretrained (bool): load pretrained weights into the model
+ channels (int): number of input channels
+ classes (int): number of model classes
+ autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
+ verbose (bool): print all information to screen
+ device (str, torch.device, None): device to use for model parameters
+
+ Returns:
+ YOLOv5 model
+ """
+ from pathlib import Path
+
+ from models.common import AutoShape, DetectMultiBackend
+ from models.experimental import attempt_load
+ from models.yolo import Model
+ from utils.downloads import attempt_download
+ from utils.general import LOGGER, check_requirements, intersect_dicts, logging
+ from utils.torch_utils import select_device
+
+ if not verbose:
+ LOGGER.setLevel(logging.WARNING)
+ check_requirements(exclude=('tensorboard', 'thop', 'opencv-python'))
+ name = Path(name)
+ path = name.with_suffix('.pt') if name.suffix == '' and not name.is_dir() else name # checkpoint path
+ try:
+ device = select_device(device)
+ if pretrained and channels == 3 and classes == 80:
+ try:
+ model = DetectMultiBackend(path, device=device, fuse=autoshape) # detection model
+ if autoshape:
+ model = AutoShape(model) # for file/URI/PIL/cv2/np inputs and NMS
+ except Exception:
+ model = attempt_load(path, device=device, fuse=False) # arbitrary model
+ else:
+ cfg = list((Path(__file__).parent / 'models').rglob(f'{path.stem}.yaml'))[0] # model.yaml path
+ model = Model(cfg, channels, classes) # create model
+ if pretrained:
+ ckpt = torch.load(attempt_download(path), map_location=device) # load
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ if len(ckpt['model'].names) == classes:
+ model.names = ckpt['model'].names # set class names attribute
+ if not verbose:
+ LOGGER.setLevel(logging.INFO) # reset to default
+ return model.to(device)
+
+ except Exception as e:
+ help_url = 'https://github.com/ultralytics/yolov5/issues/36'
+ s = f'{e}. Cache may be out of date, try `force_reload=True` or see {help_url} for help.'
+ raise Exception(s) from e
+
+
+def custom(path='path/to/model.pt', autoshape=True, _verbose=True, device=None):
+ # YOLOv5 custom or local model
+ return _create(path, autoshape=autoshape, verbose=_verbose, device=device)
+
+
+def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-nano model https://github.com/ultralytics/yolov5
+ return _create('yolov5n', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-small model https://github.com/ultralytics/yolov5
+ return _create('yolov5s', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-medium model https://github.com/ultralytics/yolov5
+ return _create('yolov5m', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-large model https://github.com/ultralytics/yolov5
+ return _create('yolov5l', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-xlarge model https://github.com/ultralytics/yolov5
+ return _create('yolov5x', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5n6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5s6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5m6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5l6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
+ # YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5x6', pretrained, channels, classes, autoshape, _verbose, device)
+
+
+if __name__ == '__main__':
+ import argparse
+ from pathlib import Path
+
+ import numpy as np
+ from PIL import Image
+
+ from utils.general import cv2, print_args
+
+ # Argparser
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model', type=str, default='yolov5s', help='model name')
+ opt = parser.parse_args()
+ print_args(vars(opt))
+
+ # Model
+ model = _create(name=opt.model, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True)
+ # model = custom(path='path/to/model.pt') # custom
+
+ # Images
+ imgs = [
+ 'data/images/zidane.jpg', # filename
+ Path('data/images/zidane.jpg'), # Path
+ 'https://ultralytics.com/images/zidane.jpg', # URI
+ cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
+ Image.open('data/images/bus.jpg'), # PIL
+ np.zeros((320, 640, 3))] # numpy
+
+ # Inference
+ results = model(imgs, size=320) # batched inference
+
+ # Results
+ results.print()
+ results.save()
diff --git a/models/__init__.py b/models/__init__.py
new file mode 100755
index 0000000..e69de29
diff --git a/models/common.py b/models/common.py
new file mode 100755
index 0000000..afb9323
--- /dev/null
+++ b/models/common.py
@@ -0,0 +1,762 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Common modules
+"""
+
+import json
+import math
+import platform
+import warnings
+from collections import OrderedDict, namedtuple
+from copy import copy
+from pathlib import Path
+
+import cv2
+import numpy as np
+import pandas as pd
+import requests
+import torch
+import torch.nn as nn
+import yaml
+from PIL import Image
+from torch.cuda import amp
+
+from utils.dataloaders import exif_transpose, letterbox
+from utils.general import (LOGGER, check_requirements, check_suffix, check_version, colorstr, increment_path,
+ make_divisible, non_max_suppression, scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import copy_attr, smart_inference_mode, time_sync
+
+
+def autopad(k, p=None): # kernel, padding
+ # Pad to 'same'
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
+ return p
+
+
+class Conv(nn.Module):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
+
+ def forward(self, x):
+ return self.act(self.bn(self.conv(x)))
+
+ def forward_fuse(self, x):
+ return self.act(self.conv(x))
+
+
+class DWConv(Conv):
+ # Depth-wise convolution class
+ def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
+
+
+class DWConvTranspose2d(nn.ConvTranspose2d):
+ # Depth-wise transpose convolution class
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
+ super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
+
+
+class TransformerLayer(nn.Module):
+ # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
+ def __init__(self, c, num_heads):
+ super().__init__()
+ self.q = nn.Linear(c, c, bias=False)
+ self.k = nn.Linear(c, c, bias=False)
+ self.v = nn.Linear(c, c, bias=False)
+ self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
+ self.fc1 = nn.Linear(c, c, bias=False)
+ self.fc2 = nn.Linear(c, c, bias=False)
+
+ def forward(self, x):
+ x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
+ x = self.fc2(self.fc1(x)) + x
+ return x
+
+
+class TransformerBlock(nn.Module):
+ # Vision Transformer https://arxiv.org/abs/2010.11929
+ def __init__(self, c1, c2, num_heads, num_layers):
+ super().__init__()
+ self.conv = None
+ if c1 != c2:
+ self.conv = Conv(c1, c2)
+ self.linear = nn.Linear(c2, c2) # learnable position embedding
+ self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
+ self.c2 = c2
+
+ def forward(self, x):
+ if self.conv is not None:
+ x = self.conv(x)
+ b, _, w, h = x.shape
+ p = x.flatten(2).permute(2, 0, 1)
+ return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
+
+
+class Bottleneck(nn.Module):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_, c2, 3, 1, g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class BottleneckCSP(nn.Module):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
+ self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
+ self.cv4 = Conv(2 * c_, c2, 1, 1)
+ self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
+ self.act = nn.SiLU()
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ y1 = self.cv3(self.m(self.cv1(x)))
+ y2 = self.cv2(x)
+ return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
+
+
+class CrossConv(nn.Module):
+ # Cross Convolution Downsample
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
+ # ch_in, ch_out, kernel, stride, groups, expansion, shortcut
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, (1, k), (1, s))
+ self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class C3(nn.Module):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c1, c_, 1, 1)
+ self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
+
+
+class C3x(C3):
+ # C3 module with cross-convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = nn.Sequential(*(CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)))
+
+
+class C3TR(C3):
+ # C3 module with TransformerBlock()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = TransformerBlock(c_, c_, 4, n)
+
+
+class C3SPP(C3):
+ # C3 module with SPP()
+ def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = SPP(c_, c_, k)
+
+
+class C3Ghost(C3):
+ # C3 module with GhostBottleneck()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e) # hidden channels
+ self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
+
+
+class SPP(nn.Module):
+ # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
+ def __init__(self, c1, c2, k=(5, 9, 13)):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
+ self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
+
+
+class SPPF(nn.Module):
+ # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
+ def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
+
+
+class Focus(nn.Module):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
+ # self.contract = Contract(gain=2)
+
+ def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
+ return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
+ # return self.conv(self.contract(x))
+
+
+class GhostConv(nn.Module):
+ # Ghost Convolution https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
+ super().__init__()
+ c_ = c2 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, k, s, None, g, act)
+ self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
+
+ def forward(self, x):
+ y = self.cv1(x)
+ return torch.cat((y, self.cv2(y)), 1)
+
+
+class GhostBottleneck(nn.Module):
+ # Ghost Bottleneck https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
+ super().__init__()
+ c_ = c2 // 2
+ self.conv = nn.Sequential(
+ GhostConv(c1, c_, 1, 1), # pw
+ DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
+ GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
+ self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False), Conv(c1, c2, 1, 1,
+ act=False)) if s == 2 else nn.Identity()
+
+ def forward(self, x):
+ return self.conv(x) + self.shortcut(x)
+
+
+class Contract(nn.Module):
+ # Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
+ x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
+ return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
+
+
+class Expand(nn.Module):
+ # Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
+ x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
+ return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
+
+
+class Concat(nn.Module):
+ # Concatenate a list of tensors along dimension
+ def __init__(self, dimension=1):
+ super().__init__()
+ self.d = dimension
+
+ def forward(self, x):
+ return torch.cat(x, self.d)
+
+
+class DetectMultiBackend(nn.Module):
+ # YOLOv5 MultiBackend class for python inference on various backends
+ def __init__(self, weights='yolov5s.pt', device=torch.device('cpu'), dnn=False, data=None, fp16=False, fuse=True):
+ # Usage:
+ # PyTorch: weights = *.pt
+ # TorchScript: *.torchscript
+ # ONNX Runtime: *.onnx
+ # ONNX OpenCV DNN: *.onnx with --dnn
+ # OpenVINO: *.xml
+ # CoreML: *.mlmodel
+ # TensorRT: *.engine
+ # TensorFlow SavedModel: *_saved_model
+ # TensorFlow GraphDef: *.pb
+ # TensorFlow Lite: *.tflite
+ # TensorFlow Edge TPU: *_edgetpu.tflite
+ from models.experimental import attempt_download, attempt_load # scoped to avoid circular import
+
+ super().__init__()
+ w = str(weights[0] if isinstance(weights, list) else weights)
+ pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs = self.model_type(w) # get backend
+ w = attempt_download(w) # download if not local
+ fp16 &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16
+ stride, names = 32, [f'class{i}' for i in range(1000)] # assign defaults
+ if data: # assign class names (optional)
+ with open(data, errors='ignore') as f:
+ names = yaml.safe_load(f)['names']
+
+ if pt: # PyTorch
+ model = attempt_load(weights if isinstance(weights, list) else w, device=device, inplace=True, fuse=fuse)
+ stride = max(int(model.stride.max()), 32) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ model.half() if fp16 else model.float()
+ self.model = model # explicitly assign for to(), cpu(), cuda(), half()
+ elif jit: # TorchScript
+ LOGGER.info(f'Loading {w} for TorchScript inference...')
+ extra_files = {'config.txt': ''} # model metadata
+ model = torch.jit.load(w, _extra_files=extra_files)
+ model.half() if fp16 else model.float()
+ if extra_files['config.txt']:
+ d = json.loads(extra_files['config.txt']) # extra_files dict
+ stride, names = int(d['stride']), d['names']
+ elif dnn: # ONNX OpenCV DNN
+ LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
+ check_requirements(('opencv-python>=4.5.4',))
+ net = cv2.dnn.readNetFromONNX(w)
+ elif onnx: # ONNX Runtime
+ LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
+ cuda = torch.cuda.is_available()
+ check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
+ import onnxruntime
+ providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
+ session = onnxruntime.InferenceSession(w, providers=providers)
+ meta = session.get_modelmeta().custom_metadata_map # metadata
+ if 'stride' in meta:
+ stride, names = int(meta['stride']), eval(meta['names'])
+ elif xml: # OpenVINO
+ LOGGER.info(f'Loading {w} for OpenVINO inference...')
+ check_requirements(('openvino',)) # requires openvino-dev: https://pypi.org/project/openvino-dev/
+ from openvino.runtime import Core, Layout, get_batch
+ ie = Core()
+ if not Path(w).is_file(): # if not *.xml
+ w = next(Path(w).glob('*.xml')) # get *.xml file from *_openvino_model dir
+ network = ie.read_model(model=w, weights=Path(w).with_suffix('.bin'))
+ if network.get_parameters()[0].get_layout().empty:
+ network.get_parameters()[0].set_layout(Layout("NCHW"))
+ batch_dim = get_batch(network)
+ if batch_dim.is_static:
+ batch_size = batch_dim.get_length()
+ executable_network = ie.compile_model(network, device_name="CPU") # device_name="MYRIAD" for Intel NCS2
+ output_layer = next(iter(executable_network.outputs))
+ meta = Path(w).with_suffix('.yaml')
+ if meta.exists():
+ stride, names = self._load_metadata(meta) # load metadata
+ elif engine: # TensorRT
+ LOGGER.info(f'Loading {w} for TensorRT inference...')
+ import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
+ check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
+ Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
+ logger = trt.Logger(trt.Logger.INFO)
+ with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
+ model = runtime.deserialize_cuda_engine(f.read())
+ context = model.create_execution_context()
+ bindings = OrderedDict()
+ fp16 = False # default updated below
+ dynamic = False
+ for index in range(model.num_bindings):
+ name = model.get_binding_name(index)
+ dtype = trt.nptype(model.get_binding_dtype(index))
+ if model.binding_is_input(index):
+ if -1 in tuple(model.get_binding_shape(index)): # dynamic
+ dynamic = True
+ context.set_binding_shape(index, tuple(model.get_profile_shape(0, index)[2]))
+ if dtype == np.float16:
+ fp16 = True
+ shape = tuple(context.get_binding_shape(index))
+ data = torch.from_numpy(np.empty(shape, dtype=np.dtype(dtype))).to(device)
+ bindings[name] = Binding(name, dtype, shape, data, int(data.data_ptr()))
+ binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
+ batch_size = bindings['images'].shape[0] # if dynamic, this is instead max batch size
+ elif coreml: # CoreML
+ LOGGER.info(f'Loading {w} for CoreML inference...')
+ import coremltools as ct
+ model = ct.models.MLModel(w)
+ else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
+ if saved_model: # SavedModel
+ LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
+ import tensorflow as tf
+ keras = False # assume TF1 saved_model
+ model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
+ elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
+ LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
+ import tensorflow as tf
+
+ def wrap_frozen_graph(gd, inputs, outputs):
+ x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped
+ ge = x.graph.as_graph_element
+ return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
+
+ gd = tf.Graph().as_graph_def() # graph_def
+ with open(w, 'rb') as f:
+ gd.ParseFromString(f.read())
+ frozen_func = wrap_frozen_graph(gd, inputs="x:0", outputs="Identity:0")
+ elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
+ try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
+ from tflite_runtime.interpreter import Interpreter, load_delegate
+ except ImportError:
+ import tensorflow as tf
+ Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate,
+ if edgetpu: # Edge TPU https://coral.ai/software/#edgetpu-runtime
+ LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
+ delegate = {
+ 'Linux': 'libedgetpu.so.1',
+ 'Darwin': 'libedgetpu.1.dylib',
+ 'Windows': 'edgetpu.dll'}[platform.system()]
+ interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
+ else: # Lite
+ LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
+ interpreter = Interpreter(model_path=w) # load TFLite model
+ interpreter.allocate_tensors() # allocate
+ input_details = interpreter.get_input_details() # inputs
+ output_details = interpreter.get_output_details() # outputs
+ elif tfjs:
+ raise Exception('ERROR: YOLOv5 TF.js inference is not supported')
+ else:
+ raise Exception(f'ERROR: {w} is not a supported format')
+ self.__dict__.update(locals()) # assign all variables to self
+
+ def forward(self, im, augment=False, visualize=False, val=False):
+ # YOLOv5 MultiBackend inference
+ b, ch, h, w = im.shape # batch, channel, height, width
+ if self.fp16 and im.dtype != torch.float16:
+ im = im.half() # to FP16
+
+ if self.pt: # PyTorch
+ y = self.model(im, augment=augment, visualize=visualize)[0]
+ elif self.jit: # TorchScript
+ y = self.model(im)[0]
+ elif self.dnn: # ONNX OpenCV DNN
+ im = im.cpu().numpy() # torch to numpy
+ self.net.setInput(im)
+ y = self.net.forward()
+ elif self.onnx: # ONNX Runtime
+ im = im.cpu().numpy() # torch to numpy
+ y = self.session.run([self.session.get_outputs()[0].name], {self.session.get_inputs()[0].name: im})[0]
+ elif self.xml: # OpenVINO
+ im = im.cpu().numpy() # FP32
+ y = self.executable_network([im])[self.output_layer]
+ elif self.engine: # TensorRT
+ if self.dynamic and im.shape != self.bindings['images'].shape:
+ i_in, i_out = (self.model.get_binding_index(x) for x in ('images', 'output'))
+ self.context.set_binding_shape(i_in, im.shape) # reshape if dynamic
+ self.bindings['images'] = self.bindings['images']._replace(shape=im.shape)
+ self.bindings['output'].data.resize_(tuple(self.context.get_binding_shape(i_out)))
+ s = self.bindings['images'].shape
+ assert im.shape == s, f"input size {im.shape} {'>' if self.dynamic else 'not equal to'} max model size {s}"
+ self.binding_addrs['images'] = int(im.data_ptr())
+ self.context.execute_v2(list(self.binding_addrs.values()))
+ y = self.bindings['output'].data
+ elif self.coreml: # CoreML
+ im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
+ im = Image.fromarray((im[0] * 255).astype('uint8'))
+ # im = im.resize((192, 320), Image.ANTIALIAS)
+ y = self.model.predict({'image': im}) # coordinates are xywh normalized
+ if 'confidence' in y:
+ box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
+ conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
+ y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
+ else:
+ k = 'var_' + str(sorted(int(k.replace('var_', '')) for k in y)[-1]) # output key
+ y = y[k] # output
+ else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
+ im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
+ if self.saved_model: # SavedModel
+ y = (self.model(im, training=False) if self.keras else self.model(im)).numpy()
+ elif self.pb: # GraphDef
+ y = self.frozen_func(x=self.tf.constant(im)).numpy()
+ else: # Lite or Edge TPU
+ input, output = self.input_details[0], self.output_details[0]
+ int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
+ if int8:
+ scale, zero_point = input['quantization']
+ im = (im / scale + zero_point).astype(np.uint8) # de-scale
+ self.interpreter.set_tensor(input['index'], im)
+ self.interpreter.invoke()
+ y = self.interpreter.get_tensor(output['index'])
+ if int8:
+ scale, zero_point = output['quantization']
+ y = (y.astype(np.float32) - zero_point) * scale # re-scale
+ y[..., :4] *= [w, h, w, h] # xywh normalized to pixels
+
+ if isinstance(y, np.ndarray):
+ y = torch.tensor(y, device=self.device)
+ return (y, []) if val else y
+
+ def warmup(self, imgsz=(1, 3, 640, 640)):
+ # Warmup model by running inference once
+ warmup_types = self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb
+ if any(warmup_types) and self.device.type != 'cpu':
+ im = torch.zeros(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # input
+ for _ in range(2 if self.jit else 1): #
+ self.forward(im) # warmup
+
+ @staticmethod
+ def model_type(p='path/to/model.pt'):
+ # Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
+ from export import export_formats
+ suffixes = list(export_formats().Suffix) + ['.xml'] # export suffixes
+ check_suffix(p, suffixes) # checks
+ p = Path(p).name # eliminate trailing separators
+ pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, xml2 = (s in p for s in suffixes)
+ xml |= xml2 # *_openvino_model or *.xml
+ tflite &= not edgetpu # *.tflite
+ return pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs
+
+ @staticmethod
+ def _load_metadata(f='path/to/meta.yaml'):
+ # Load metadata from meta.yaml if it exists
+ with open(f, errors='ignore') as f:
+ d = yaml.safe_load(f)
+ return d['stride'], d['names'] # assign stride, names
+
+
+class AutoShape(nn.Module):
+ # YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
+ conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+ def __init__(self, model, verbose=True):
+ super().__init__()
+ if verbose:
+ LOGGER.info('Adding AutoShape... ')
+ copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributes
+ self.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instance
+ self.pt = not self.dmb or model.pt # PyTorch model
+ self.model = model.eval()
+ if self.pt:
+ m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
+ m.inplace = False # Detect.inplace=False for safe multithread inference
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ if self.pt:
+ m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+ @smart_inference_mode()
+ def forward(self, imgs, size=640, augment=False, profile=False):
+ # Inference from various sources. For height=640, width=1280, RGB images example inputs are:
+ # file: imgs = 'data/images/zidane.jpg' # str or PosixPath
+ # URI: = 'https://ultralytics.com/images/zidane.jpg'
+ # OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
+ # PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
+ # numpy: = np.zeros((640,1280,3)) # HWC
+ # torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
+ # multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
+
+ t = [time_sync()]
+ p = next(self.model.parameters()) if self.pt else torch.zeros(1, device=self.model.device) # for device, type
+ autocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inference
+ if isinstance(imgs, torch.Tensor): # torch
+ with amp.autocast(autocast):
+ return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
+
+ # Pre-process
+ n, imgs = (len(imgs), list(imgs)) if isinstance(imgs, (list, tuple)) else (1, [imgs]) # number, list of images
+ shape0, shape1, files = [], [], [] # image and inference shapes, filenames
+ for i, im in enumerate(imgs):
+ f = f'image{i}' # filename
+ if isinstance(im, (str, Path)): # filename or uri
+ im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
+ im = np.asarray(exif_transpose(im))
+ elif isinstance(im, Image.Image): # PIL Image
+ im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
+ files.append(Path(f).with_suffix('.jpg').name)
+ if im.shape[0] < 5: # image in CHW
+ im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
+ im = im[..., :3] if im.ndim == 3 else np.tile(im[..., None], 3) # enforce 3ch input
+ s = im.shape[:2] # HWC
+ shape0.append(s) # image shape
+ g = (size / max(s)) # gain
+ shape1.append([y * g for y in s])
+ imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
+ shape1 = [make_divisible(x, self.stride) if self.pt else size for x in np.array(shape1).max(0)] # inf shape
+ x = [letterbox(im, shape1, auto=False)[0] for im in imgs] # pad
+ x = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHW
+ x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
+ t.append(time_sync())
+
+ with amp.autocast(autocast):
+ # Inference
+ y = self.model(x, augment, profile) # forward
+ t.append(time_sync())
+
+ # Post-process
+ y = non_max_suppression(y if self.dmb else y[0],
+ self.conf,
+ self.iou,
+ self.classes,
+ self.agnostic,
+ self.multi_label,
+ max_det=self.max_det) # NMS
+ for i in range(n):
+ scale_coords(shape1, y[i][:, :4], shape0[i])
+
+ t.append(time_sync())
+ return Detections(imgs, y, files, t, self.names, x.shape)
+
+
+class Detections:
+ # YOLOv5 detections class for inference results
+ def __init__(self, imgs, pred, files, times=(0, 0, 0, 0), names=None, shape=None):
+ super().__init__()
+ d = pred[0].device # device
+ gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in imgs] # normalizations
+ self.imgs = imgs # list of images as numpy arrays
+ self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
+ self.names = names # class names
+ self.files = files # image filenames
+ self.times = times # profiling times
+ self.xyxy = pred # xyxy pixels
+ self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
+ self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
+ self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
+ self.n = len(self.pred) # number of images (batch size)
+ self.t = tuple((times[i + 1] - times[i]) * 1000 / self.n for i in range(3)) # timestamps (ms)
+ self.s = shape # inference BCHW shape
+
+ def display(self, pprint=False, show=False, save=False, crop=False, render=False, labels=True, save_dir=Path('')):
+ crops = []
+ for i, (im, pred) in enumerate(zip(self.imgs, self.pred)):
+ s = f'image {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
+ if pred.shape[0]:
+ for c in pred[:, -1].unique():
+ n = (pred[:, -1] == c).sum() # detections per class
+ s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
+ if show or save or render or crop:
+ annotator = Annotator(im, example=str(self.names))
+ for *box, conf, cls in reversed(pred): # xyxy, confidence, class
+ label = f'{self.names[int(cls)]} {conf:.2f}'
+ if crop:
+ file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
+ crops.append({
+ 'box': box,
+ 'conf': conf,
+ 'cls': cls,
+ 'label': label,
+ 'im': save_one_box(box, im, file=file, save=save)})
+ else: # all others
+ annotator.box_label(box, label if labels else '', color=colors(cls))
+ im = annotator.im
+ else:
+ s += '(no detections)'
+
+ im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
+ if pprint:
+ print(s.rstrip(', '))
+ if show:
+ im.show(self.files[i]) # show
+ if save:
+ f = self.files[i]
+ im.save(save_dir / f) # save
+ if i == self.n - 1:
+ LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
+ if render:
+ self.imgs[i] = np.asarray(im)
+ if crop:
+ if save:
+ LOGGER.info(f'Saved results to {save_dir}\n')
+ return crops
+
+ def print(self):
+ self.display(pprint=True) # print results
+ print(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {tuple(self.s)}' % self.t)
+
+ def show(self, labels=True):
+ self.display(show=True, labels=labels) # show results
+
+ def save(self, labels=True, save_dir='runs/detect/exp'):
+ save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
+ self.display(save=True, labels=labels, save_dir=save_dir) # save results
+
+ def crop(self, save=True, save_dir='runs/detect/exp'):
+ save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
+ return self.display(crop=True, save=save, save_dir=save_dir) # crop results
+
+ def render(self, labels=True):
+ self.display(render=True, labels=labels) # render results
+ return self.imgs
+
+ def pandas(self):
+ # return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
+ new = copy(self) # return copy
+ ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
+ cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
+ for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
+ a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
+ setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
+ return new
+
+ def tolist(self):
+ # return a list of Detections objects, i.e. 'for result in results.tolist():'
+ r = range(self.n) # iterable
+ x = [Detections([self.imgs[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]
+ # for d in x:
+ # for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
+ # setattr(d, k, getattr(d, k)[0]) # pop out of list
+ return x
+
+ def __len__(self):
+ return self.n # override len(results)
+
+ def __str__(self):
+ self.print() # override print(results)
+ return ''
+
+
+class Classify(nn.Module):
+ # Classification head, i.e. x(b,c1,20,20) to x(b,c2)
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
+ self.flat = nn.Flatten()
+
+ def forward(self, x):
+ z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
+ return self.flat(self.conv(z)) # flatten to x(b,c2)
diff --git a/models/experimental.py b/models/experimental.py
new file mode 100755
index 0000000..0317c75
--- /dev/null
+++ b/models/experimental.py
@@ -0,0 +1,102 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Experimental modules
+"""
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from models.common import Conv
+from utils.downloads import attempt_download
+
+
+class Sum(nn.Module):
+ # Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
+ def __init__(self, n, weight=False): # n: number of inputs
+ super().__init__()
+ self.weight = weight # apply weights boolean
+ self.iter = range(n - 1) # iter object
+ if weight:
+ self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
+
+ def forward(self, x):
+ y = x[0] # no weight
+ if self.weight:
+ w = torch.sigmoid(self.w) * 2
+ for i in self.iter:
+ y = y + x[i + 1] * w[i]
+ else:
+ for i in self.iter:
+ y = y + x[i + 1]
+ return y
+
+
+class MixConv2d(nn.Module):
+ # Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
+ def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
+ super().__init__()
+ n = len(k) # number of convolutions
+ if equal_ch: # equal c_ per group
+ i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
+ c_ = [(i == g).sum() for g in range(n)] # intermediate channels
+ else: # equal weight.numel() per group
+ b = [c2] + [0] * n
+ a = np.eye(n + 1, n, k=-1)
+ a -= np.roll(a, 1, axis=1)
+ a *= np.array(k) ** 2
+ a[0] = 1
+ c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
+
+ self.m = nn.ModuleList([
+ nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU()
+
+ def forward(self, x):
+ return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
+
+
+class Ensemble(nn.ModuleList):
+ # Ensemble of models
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ y = [module(x, augment, profile, visualize)[0] for module in self]
+ # y = torch.stack(y).max(0)[0] # max ensemble
+ # y = torch.stack(y).mean(0) # mean ensemble
+ y = torch.cat(y, 1) # nms ensemble
+ return y, None # inference, train output
+
+
+def attempt_load(weights, device=None, inplace=True, fuse=True):
+ # Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
+ from models.yolo import Detect, Model
+
+ model = Ensemble()
+ for w in weights if isinstance(weights, list) else [weights]:
+ ckpt = torch.load(attempt_download(w), map_location='cpu') # load
+ ckpt = (ckpt.get('ema') or ckpt['model']).to(device).float() # FP32 model
+ model.append(ckpt.fuse().eval() if fuse else ckpt.eval()) # fused or un-fused model in eval mode
+
+ # Compatibility updates
+ for m in model.modules():
+ t = type(m)
+ if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model):
+ m.inplace = inplace # torch 1.7.0 compatibility
+ if t is Detect and not isinstance(m.anchor_grid, list):
+ delattr(m, 'anchor_grid')
+ setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
+ elif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ if len(model) == 1:
+ return model[-1] # return model
+ print(f'Ensemble created with {weights}\n')
+ for k in 'names', 'nc', 'yaml':
+ setattr(model, k, getattr(model[0], k))
+ model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
+ assert all(model[0].nc == m.nc for m in model), f'Models have different class counts: {[m.nc for m in model]}'
+ return model # return ensemble
diff --git a/models/hub/anchors.yaml b/models/hub/anchors.yaml
new file mode 100755
index 0000000..e4d7beb
--- /dev/null
+++ b/models/hub/anchors.yaml
@@ -0,0 +1,59 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Default anchors for COCO data
+
+
+# P5 -------------------------------------------------------------------------------------------------------------------
+# P5-640:
+anchors_p5_640:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+
+# P6 -------------------------------------------------------------------------------------------------------------------
+# P6-640: thr=0.25: 0.9964 BPR, 5.54 anchors past thr, n=12, img_size=640, metric_all=0.281/0.716-mean/best, past_thr=0.469-mean: 9,11, 21,19, 17,41, 43,32, 39,70, 86,64, 65,131, 134,130, 120,265, 282,180, 247,354, 512,387
+anchors_p6_640:
+ - [9,11, 21,19, 17,41] # P3/8
+ - [43,32, 39,70, 86,64] # P4/16
+ - [65,131, 134,130, 120,265] # P5/32
+ - [282,180, 247,354, 512,387] # P6/64
+
+# P6-1280: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1280, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 19,27, 44,40, 38,94, 96,68, 86,152, 180,137, 140,301, 303,264, 238,542, 436,615, 739,380, 925,792
+anchors_p6_1280:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# P6-1920: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1920, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 28,41, 67,59, 57,141, 144,103, 129,227, 270,205, 209,452, 455,396, 358,812, 653,922, 1109,570, 1387,1187
+anchors_p6_1920:
+ - [28,41, 67,59, 57,141] # P3/8
+ - [144,103, 129,227, 270,205] # P4/16
+ - [209,452, 455,396, 358,812] # P5/32
+ - [653,922, 1109,570, 1387,1187] # P6/64
+
+
+# P7 -------------------------------------------------------------------------------------------------------------------
+# P7-640: thr=0.25: 0.9962 BPR, 6.76 anchors past thr, n=15, img_size=640, metric_all=0.275/0.733-mean/best, past_thr=0.466-mean: 11,11, 13,30, 29,20, 30,46, 61,38, 39,92, 78,80, 146,66, 79,163, 149,150, 321,143, 157,303, 257,402, 359,290, 524,372
+anchors_p7_640:
+ - [11,11, 13,30, 29,20] # P3/8
+ - [30,46, 61,38, 39,92] # P4/16
+ - [78,80, 146,66, 79,163] # P5/32
+ - [149,150, 321,143, 157,303] # P6/64
+ - [257,402, 359,290, 524,372] # P7/128
+
+# P7-1280: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1280, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 19,22, 54,36, 32,77, 70,83, 138,71, 75,173, 165,159, 148,334, 375,151, 334,317, 251,626, 499,474, 750,326, 534,814, 1079,818
+anchors_p7_1280:
+ - [19,22, 54,36, 32,77] # P3/8
+ - [70,83, 138,71, 75,173] # P4/16
+ - [165,159, 148,334, 375,151] # P5/32
+ - [334,317, 251,626, 499,474] # P6/64
+ - [750,326, 534,814, 1079,818] # P7/128
+
+# P7-1920: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1920, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 29,34, 81,55, 47,115, 105,124, 207,107, 113,259, 247,238, 222,500, 563,227, 501,476, 376,939, 749,711, 1126,489, 801,1222, 1618,1227
+anchors_p7_1920:
+ - [29,34, 81,55, 47,115] # P3/8
+ - [105,124, 207,107, 113,259] # P4/16
+ - [247,238, 222,500, 563,227] # P5/32
+ - [501,476, 376,939, 749,711] # P6/64
+ - [1126,489, 801,1222, 1618,1227] # P7/128
diff --git a/models/hub/yolov3-spp.yaml b/models/hub/yolov3-spp.yaml
new file mode 100755
index 0000000..c669821
--- /dev/null
+++ b/models/hub/yolov3-spp.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3-SPP head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, SPP, [512, [5, 9, 13]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov3-tiny.yaml b/models/hub/yolov3-tiny.yaml
new file mode 100755
index 0000000..b28b443
--- /dev/null
+++ b/models/hub/yolov3-tiny.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,14, 23,27, 37,58] # P4/16
+ - [81,82, 135,169, 344,319] # P5/32
+
+# YOLOv3-tiny backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [16, 3, 1]], # 0
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
+ [-1, 1, Conv, [32, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
+ [-1, 1, Conv, [64, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
+ [-1, 1, Conv, [128, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
+ [-1, 1, Conv, [256, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
+ [-1, 1, Conv, [512, 3, 1]],
+ [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
+ [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
+ ]
+
+# YOLOv3-tiny head
+head:
+ [[-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
+
+ [[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)
+ ]
diff --git a/models/hub/yolov3.yaml b/models/hub/yolov3.yaml
new file mode 100755
index 0000000..d1ef912
--- /dev/null
+++ b/models/hub/yolov3.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3 head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5-bifpn.yaml b/models/hub/yolov5-bifpn.yaml
new file mode 100755
index 0000000..504815f
--- /dev/null
+++ b/models/hub/yolov5-bifpn.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 BiFPN head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14, 6], 1, Concat, [1]], # cat P4 <--- BiFPN change
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5-fpn.yaml b/models/hub/yolov5-fpn.yaml
new file mode 100755
index 0000000..a23e9c6
--- /dev/null
+++ b/models/hub/yolov5-fpn.yaml
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 FPN head
+head:
+ [[-1, 3, C3, [1024, False]], # 10 (P5/32-large)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 3, C3, [512, False]], # 14 (P4/16-medium)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 3, C3, [256, False]], # 18 (P3/8-small)
+
+ [[18, 14, 10], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5-p2.yaml b/models/hub/yolov5-p2.yaml
new file mode 100755
index 0000000..554117d
--- /dev/null
+++ b/models/hub/yolov5-p2.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head with (P2, P3, P4, P5) outputs
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 2], 1, Concat, [1]], # cat backbone P2
+ [-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
+
+ [-1, 1, Conv, [128, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P3
+ [-1, 3, C3, [256, False]], # 24 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 27 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 30 (P5/32-large)
+
+ [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5-p34.yaml b/models/hub/yolov5-p34.yaml
new file mode 100755
index 0000000..dbf0f85
--- /dev/null
+++ b/models/hub/yolov5-p34.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [ [ -1, 1, Conv, [ 64, 6, 2, 2 ] ], # 0-P1/2
+ [ -1, 1, Conv, [ 128, 3, 2 ] ], # 1-P2/4
+ [ -1, 3, C3, [ 128 ] ],
+ [ -1, 1, Conv, [ 256, 3, 2 ] ], # 3-P3/8
+ [ -1, 6, C3, [ 256 ] ],
+ [ -1, 1, Conv, [ 512, 3, 2 ] ], # 5-P4/16
+ [ -1, 9, C3, [ 512 ] ],
+ [ -1, 1, Conv, [ 1024, 3, 2 ] ], # 7-P5/32
+ [ -1, 3, C3, [ 1024 ] ],
+ [ -1, 1, SPPF, [ 1024, 5 ] ], # 9
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4) outputs
+head:
+ [ [ -1, 1, Conv, [ 512, 1, 1 ] ],
+ [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
+ [ [ -1, 6 ], 1, Concat, [ 1 ] ], # cat backbone P4
+ [ -1, 3, C3, [ 512, False ] ], # 13
+
+ [ -1, 1, Conv, [ 256, 1, 1 ] ],
+ [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
+ [ [ -1, 4 ], 1, Concat, [ 1 ] ], # cat backbone P3
+ [ -1, 3, C3, [ 256, False ] ], # 17 (P3/8-small)
+
+ [ -1, 1, Conv, [ 256, 3, 2 ] ],
+ [ [ -1, 14 ], 1, Concat, [ 1 ] ], # cat head P4
+ [ -1, 3, C3, [ 512, False ] ], # 20 (P4/16-medium)
+
+ [ [ 17, 20 ], 1, Detect, [ nc, anchors ] ], # Detect(P3, P4)
+ ]
diff --git a/models/hub/yolov5-p6.yaml b/models/hub/yolov5-p6.yaml
new file mode 100755
index 0000000..a17202f
--- /dev/null
+++ b/models/hub/yolov5-p6.yaml
@@ -0,0 +1,56 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4, P5, P6) outputs
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/models/hub/yolov5-p7.yaml b/models/hub/yolov5-p7.yaml
new file mode 100755
index 0000000..edd7d13
--- /dev/null
+++ b/models/hub/yolov5-p7.yaml
@@ -0,0 +1,67 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, Conv, [1280, 3, 2]], # 11-P7/128
+ [-1, 3, C3, [1280]],
+ [-1, 1, SPPF, [1280, 5]], # 13
+ ]
+
+# YOLOv5 v6.0 head with (P3, P4, P5, P6, P7) outputs
+head:
+ [[-1, 1, Conv, [1024, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 10], 1, Concat, [1]], # cat backbone P6
+ [-1, 3, C3, [1024, False]], # 17
+
+ [-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 21
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 25
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 29 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 26], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 32 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 22], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 35 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 38 (P6/64-xlarge)
+
+ [-1, 1, Conv, [1024, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P7
+ [-1, 3, C3, [1280, False]], # 41 (P7/128-xxlarge)
+
+ [[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
+ ]
diff --git a/models/hub/yolov5-panet.yaml b/models/hub/yolov5-panet.yaml
new file mode 100755
index 0000000..ccfbf90
--- /dev/null
+++ b/models/hub/yolov5-panet.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 PANet head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5l6.yaml b/models/hub/yolov5l6.yaml
new file mode 100755
index 0000000..632c2cb
--- /dev/null
+++ b/models/hub/yolov5l6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/models/hub/yolov5m6.yaml b/models/hub/yolov5m6.yaml
new file mode 100755
index 0000000..ecc53fd
--- /dev/null
+++ b/models/hub/yolov5m6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/models/hub/yolov5n6.yaml b/models/hub/yolov5n6.yaml
new file mode 100755
index 0000000..0c0c71d
--- /dev/null
+++ b/models/hub/yolov5n6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/models/hub/yolov5s-ghost.yaml b/models/hub/yolov5s-ghost.yaml
new file mode 100755
index 0000000..ff9519c
--- /dev/null
+++ b/models/hub/yolov5s-ghost.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, GhostConv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3Ghost, [128]],
+ [-1, 1, GhostConv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3Ghost, [256]],
+ [-1, 1, GhostConv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3Ghost, [512]],
+ [-1, 1, GhostConv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3Ghost, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, GhostConv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3Ghost, [512, False]], # 13
+
+ [-1, 1, GhostConv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3Ghost, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, GhostConv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3Ghost, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, GhostConv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3Ghost, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5s-transformer.yaml b/models/hub/yolov5s-transformer.yaml
new file mode 100755
index 0000000..100d7c4
--- /dev/null
+++ b/models/hub/yolov5s-transformer.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3TR, [1024]], # 9 <--- C3TR() Transformer module
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/hub/yolov5s6.yaml b/models/hub/yolov5s6.yaml
new file mode 100755
index 0000000..a28fb55
--- /dev/null
+++ b/models/hub/yolov5s6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/models/hub/yolov5x6.yaml b/models/hub/yolov5x6.yaml
new file mode 100755
index 0000000..ba795c4
--- /dev/null
+++ b/models/hub/yolov5x6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/models/tf.py b/models/tf.py
new file mode 100755
index 0000000..b0d98cc
--- /dev/null
+++ b/models/tf.py
@@ -0,0 +1,574 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+TensorFlow, Keras and TFLite versions of YOLOv5
+Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
+
+Usage:
+ $ python models/tf.py --weights yolov5s.pt
+
+Export:
+ $ python path/to/export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
+"""
+
+import argparse
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import numpy as np
+import tensorflow as tf
+import torch
+import torch.nn as nn
+from tensorflow import keras
+
+from models.common import (C3, SPP, SPPF, Bottleneck, BottleneckCSP, C3x, Concat, Conv, CrossConv, DWConv,
+ DWConvTranspose2d, Focus, autopad)
+from models.experimental import MixConv2d, attempt_load
+from models.yolo import Detect
+from utils.activations import SiLU
+from utils.general import LOGGER, make_divisible, print_args
+
+
+class TFBN(keras.layers.Layer):
+ # TensorFlow BatchNormalization wrapper
+ def __init__(self, w=None):
+ super().__init__()
+ self.bn = keras.layers.BatchNormalization(
+ beta_initializer=keras.initializers.Constant(w.bias.numpy()),
+ gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
+ moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
+ moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
+ epsilon=w.eps)
+
+ def call(self, inputs):
+ return self.bn(inputs)
+
+
+class TFPad(keras.layers.Layer):
+ # Pad inputs in spatial dimensions 1 and 2
+ def __init__(self, pad):
+ super().__init__()
+ if isinstance(pad, int):
+ self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
+ else: # tuple/list
+ self.pad = tf.constant([[0, 0], [pad[0], pad[0]], [pad[1], pad[1]], [0, 0]])
+
+ def call(self, inputs):
+ return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
+
+
+class TFConv(keras.layers.Layer):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
+ # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
+ conv = keras.layers.Conv2D(
+ filters=c2,
+ kernel_size=k,
+ strides=s,
+ padding='SAME' if s == 1 else 'VALID',
+ use_bias=not hasattr(w, 'bn'),
+ kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+ self.act = activations(w.act) if act else tf.identity
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFDWConv(keras.layers.Layer):
+ # Depthwise convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert c2 % c1 == 0, f'TFDWConv() output={c2} must be a multiple of input={c1} channels'
+ conv = keras.layers.DepthwiseConv2D(
+ kernel_size=k,
+ depth_multiplier=c2 // c1,
+ strides=s,
+ padding='SAME' if s == 1 else 'VALID',
+ use_bias=not hasattr(w, 'bn'),
+ depthwise_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+ self.act = activations(w.act) if act else tf.identity
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFDWConvTranspose2d(keras.layers.Layer):
+ # Depthwise ConvTranspose2d
+ def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert c1 == c2, f'TFDWConv() output={c2} must be equal to input={c1} channels'
+ assert k == 4 and p1 == 1, 'TFDWConv() only valid for k=4 and p1=1'
+ weight, bias = w.weight.permute(2, 3, 1, 0).numpy(), w.bias.numpy()
+ self.c1 = c1
+ self.conv = [
+ keras.layers.Conv2DTranspose(filters=1,
+ kernel_size=k,
+ strides=s,
+ padding='VALID',
+ output_padding=p2,
+ use_bias=True,
+ kernel_initializer=keras.initializers.Constant(weight[..., i:i + 1]),
+ bias_initializer=keras.initializers.Constant(bias[i])) for i in range(c1)]
+
+ def call(self, inputs):
+ return tf.concat([m(x) for m, x in zip(self.conv, tf.split(inputs, self.c1, 3))], 3)[:, 1:-1, 1:-1]
+
+
+class TFFocus(keras.layers.Layer):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
+
+ def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
+ # inputs = inputs / 255 # normalize 0-255 to 0-1
+ inputs = [inputs[:, ::2, ::2, :], inputs[:, 1::2, ::2, :], inputs[:, ::2, 1::2, :], inputs[:, 1::2, 1::2, :]]
+ return self.conv(tf.concat(inputs, 3))
+
+
+class TFBottleneck(keras.layers.Layer):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFCrossConv(keras.layers.Layer):
+ # Cross Convolution
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False, w=None):
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, (1, k), (1, s), w=w.cv1)
+ self.cv2 = TFConv(c_, c2, (k, 1), (s, 1), g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFConv2d(keras.layers.Layer):
+ # Substitution for PyTorch nn.Conv2D
+ def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ self.conv = keras.layers.Conv2D(filters=c2,
+ kernel_size=k,
+ strides=s,
+ padding='VALID',
+ use_bias=bias,
+ kernel_initializer=keras.initializers.Constant(
+ w.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None)
+
+ def call(self, inputs):
+ return self.conv(inputs)
+
+
+class TFBottleneckCSP(keras.layers.Layer):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
+ self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
+ self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
+ self.bn = TFBN(w.bn)
+ self.act = lambda x: keras.activations.swish(x)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ y1 = self.cv3(self.m(self.cv1(inputs)))
+ y2 = self.cv2(inputs)
+ return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
+
+
+class TFC3(keras.layers.Layer):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFC3x(keras.layers.Layer):
+ # 3 module with cross-convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([
+ TFCrossConv(c_, c_, k=3, s=1, g=g, e=1.0, shortcut=shortcut, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFSPP(keras.layers.Layer):
+ # Spatial pyramid pooling layer used in YOLOv3-SPP
+ def __init__(self, c1, c2, k=(5, 9, 13), w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
+ self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
+
+
+class TFSPPF(keras.layers.Layer):
+ # Spatial pyramid pooling-Fast layer
+ def __init__(self, c1, c2, k=5, w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
+ self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
+
+
+class TFDetect(keras.layers.Layer):
+ # TF YOLOv5 Detect layer
+ def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
+ super().__init__()
+ self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [tf.zeros(1)] * self.nl # init grid
+ self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
+ self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]), [self.nl, 1, -1, 1, 2])
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
+ self.training = False # set to False after building model
+ self.imgsz = imgsz
+ for i in range(self.nl):
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ self.grid[i] = self._make_grid(nx, ny)
+
+ def call(self, inputs):
+ z = [] # inference output
+ x = []
+ for i in range(self.nl):
+ x.append(self.m[i](inputs[i]))
+ # x(bs,20,20,255) to x(bs,3,20,20,85)
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ x[i] = tf.reshape(x[i], [-1, ny * nx, self.na, self.no])
+
+ if not self.training: # inference
+ y = tf.sigmoid(x[i])
+ grid = tf.transpose(self.grid[i], [0, 2, 1, 3]) - 0.5
+ anchor_grid = tf.transpose(self.anchor_grid[i], [0, 2, 1, 3]) * 4
+ xy = (y[..., 0:2] * 2 + grid) * self.stride[i] # xy
+ wh = y[..., 2:4] ** 2 * anchor_grid
+ # Normalize xywh to 0-1 to reduce calibration error
+ xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ y = tf.concat([xy, wh, y[..., 4:]], -1)
+ z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
+
+ return tf.transpose(x, [0, 2, 1, 3]) if self.training else (tf.concat(z, 1), x)
+
+ @staticmethod
+ def _make_grid(nx=20, ny=20):
+ # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
+ # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
+ xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
+ return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
+
+
+class TFUpsample(keras.layers.Layer):
+ # TF version of torch.nn.Upsample()
+ def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
+ super().__init__()
+ assert scale_factor == 2, "scale_factor must be 2"
+ self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * 2, x.shape[2] * 2), method=mode)
+ # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
+ # with default arguments: align_corners=False, half_pixel_centers=False
+ # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
+ # size=(x.shape[1] * 2, x.shape[2] * 2))
+
+ def call(self, inputs):
+ return self.upsample(inputs)
+
+
+class TFConcat(keras.layers.Layer):
+ # TF version of torch.concat()
+ def __init__(self, dimension=1, w=None):
+ super().__init__()
+ assert dimension == 1, "convert only NCHW to NHWC concat"
+ self.d = 3
+
+ def call(self, inputs):
+ return tf.concat(inputs, self.d)
+
+
+def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m_str = m
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [
+ nn.Conv2d, Conv, DWConv, DWConvTranspose2d, Bottleneck, SPP, SPPF, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3x]:
+ c1, c2 = ch[f], args[0]
+ c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3, C3x]:
+ args.insert(2, n)
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
+ elif m is Detect:
+ args.append([ch[x + 1] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ args.append(imgsz)
+ else:
+ c2 = ch[f]
+
+ tf_m = eval('TF' + m_str.replace('nn.', ''))
+ m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
+ else tf_m(*args, w=model.model[i]) # module
+
+ torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in torch_m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ ch.append(c2)
+ return keras.Sequential(layers), sorted(save)
+
+
+class TFModel:
+ # TF YOLOv5 model
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg) as f:
+ self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
+
+ # Define model
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
+
+ def predict(self,
+ inputs,
+ tf_nms=False,
+ agnostic_nms=False,
+ topk_per_class=100,
+ topk_all=100,
+ iou_thres=0.45,
+ conf_thres=0.25):
+ y = [] # outputs
+ x = inputs
+ for m in self.model.layers:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+
+ x = m(x) # run
+ y.append(x if m.i in self.savelist else None) # save output
+
+ # Add TensorFlow NMS
+ if tf_nms:
+ boxes = self._xywh2xyxy(x[0][..., :4])
+ probs = x[0][:, :, 4:5]
+ classes = x[0][:, :, 5:]
+ scores = probs * classes
+ if agnostic_nms:
+ nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
+ else:
+ boxes = tf.expand_dims(boxes, 2)
+ nms = tf.image.combined_non_max_suppression(boxes,
+ scores,
+ topk_per_class,
+ topk_all,
+ iou_thres,
+ conf_thres,
+ clip_boxes=False)
+ return nms, x[1]
+ return x[0] # output only first tensor [1,6300,85] = [xywh, conf, class0, class1, ...]
+ # x = x[0][0] # [x(1,6300,85), ...] to x(6300,85)
+ # xywh = x[..., :4] # x(6300,4) boxes
+ # conf = x[..., 4:5] # x(6300,1) confidences
+ # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
+ # return tf.concat([conf, cls, xywh], 1)
+
+ @staticmethod
+ def _xywh2xyxy(xywh):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
+ return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
+
+
+class AgnosticNMS(keras.layers.Layer):
+ # TF Agnostic NMS
+ def call(self, input, topk_all, iou_thres, conf_thres):
+ # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
+ return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres),
+ input,
+ fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
+ name='agnostic_nms')
+
+ @staticmethod
+ def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
+ boxes, classes, scores = x
+ class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
+ scores_inp = tf.reduce_max(scores, -1)
+ selected_inds = tf.image.non_max_suppression(boxes,
+ scores_inp,
+ max_output_size=topk_all,
+ iou_threshold=iou_thres,
+ score_threshold=conf_thres)
+ selected_boxes = tf.gather(boxes, selected_inds)
+ padded_boxes = tf.pad(selected_boxes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
+ mode="CONSTANT",
+ constant_values=0.0)
+ selected_scores = tf.gather(scores_inp, selected_inds)
+ padded_scores = tf.pad(selected_scores,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode="CONSTANT",
+ constant_values=-1.0)
+ selected_classes = tf.gather(class_inds, selected_inds)
+ padded_classes = tf.pad(selected_classes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode="CONSTANT",
+ constant_values=-1.0)
+ valid_detections = tf.shape(selected_inds)[0]
+ return padded_boxes, padded_scores, padded_classes, valid_detections
+
+
+def activations(act=nn.SiLU):
+ # Returns TF activation from input PyTorch activation
+ if isinstance(act, nn.LeakyReLU):
+ return lambda x: keras.activations.relu(x, alpha=0.1)
+ elif isinstance(act, nn.Hardswish):
+ return lambda x: x * tf.nn.relu6(x + 3) * 0.166666667
+ elif isinstance(act, (nn.SiLU, SiLU)):
+ return lambda x: keras.activations.swish(x)
+ else:
+ raise Exception(f'no matching TensorFlow activation found for PyTorch activation {act}')
+
+
+def representative_dataset_gen(dataset, ncalib=100):
+ # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
+ for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
+ im = np.transpose(img, [1, 2, 0])
+ im = np.expand_dims(im, axis=0).astype(np.float32)
+ im /= 255
+ yield [im]
+ if n >= ncalib:
+ break
+
+
+def run(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # inference size h,w
+ batch_size=1, # batch size
+ dynamic=False, # dynamic batch size
+):
+ # PyTorch model
+ im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
+ model = attempt_load(weights, device=torch.device('cpu'), inplace=True, fuse=False)
+ _ = model(im) # inference
+ model.info()
+
+ # TensorFlow model
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ _ = tf_model.predict(im) # inference
+
+ # Keras model
+ im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
+ keras_model.summary()
+
+ LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/models/yolo.py b/models/yolo.py
new file mode 100755
index 0000000..307b748
--- /dev/null
+++ b/models/yolo.py
@@ -0,0 +1,337 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+YOLO-specific modules
+
+Usage:
+ $ python path/to/models/yolo.py --cfg yolov5s.yaml
+"""
+
+import argparse
+import contextlib
+import os
+import platform
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+if platform.system() != 'Windows':
+ ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import *
+from models.experimental import *
+from utils.autoanchor import check_anchor_order
+from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
+from utils.plots import feature_visualization
+from utils.torch_utils import (fuse_conv_and_bn, initialize_weights, model_info, profile, scale_img, select_device,
+ time_sync)
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+class Detect(nn.Module):
+ stride = None # strides computed during build
+ onnx_dynamic = False # ONNX export parameter
+ export = False # export mode
+
+ def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
+ super().__init__()
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [torch.zeros(1)] * self.nl # init grid
+ self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
+ self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.inplace = inplace # use inplace ops (e.g. slice assignment)
+
+ def forward(self, x):
+ z = [] # inference output
+ for i in range(self.nl):
+ x[i] = self.m[i](x[i]) # conv
+ bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
+ x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
+
+ if not self.training: # inference
+ if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
+ self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
+
+ y = x[i].sigmoid()
+ if self.inplace:
+ y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
+ y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
+ else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
+ xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
+ xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
+ wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, conf), 4)
+ z.append(y.view(bs, -1, self.no))
+
+ return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
+
+ def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):
+ d = self.anchors[i].device
+ t = self.anchors[i].dtype
+ shape = 1, self.na, ny, nx, 2 # grid shape
+ y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
+ if torch_1_10: # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
+ yv, xv = torch.meshgrid(y, x, indexing='ij')
+ else:
+ yv, xv = torch.meshgrid(y, x)
+ grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
+ anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
+ return grid, anchor_grid
+
+
+class Model(nn.Module):
+ # YOLOv5 model
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg, encoding='ascii', errors='ignore') as f:
+ self.yaml = yaml.safe_load(f) # model dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ if anchors:
+ LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
+ self.yaml['anchors'] = round(anchors) # override yaml value
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
+ self.names = [str(i) for i in range(self.yaml['nc'])] # default names
+ self.inplace = self.yaml.get('inplace', True)
+
+ # Build strides, anchors
+ m = self.model[-1] # Detect()
+ if isinstance(m, Detect):
+ s = 256 # 2x min stride
+ m.inplace = self.inplace
+ m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
+ check_anchor_order(m) # must be in pixel-space (not grid-space)
+ m.anchors /= m.stride.view(-1, 1, 1)
+ self.stride = m.stride
+ self._initialize_biases() # only run once
+
+ # Init weights, biases
+ initialize_weights(self)
+ self.info()
+ LOGGER.info('')
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ if augment:
+ return self._forward_augment(x) # augmented inference, None
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_augment(self, x):
+ img_size = x.shape[-2:] # height, width
+ s = [1, 0.83, 0.67] # scales
+ f = [None, 3, None] # flips (2-ud, 3-lr)
+ y = [] # outputs
+ for si, fi in zip(s, f):
+ xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
+ yi = self._forward_once(xi)[0] # forward
+ # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
+ yi = self._descale_pred(yi, fi, si, img_size)
+ y.append(yi)
+ y = self._clip_augmented(y) # clip augmented tails
+ return torch.cat(y, 1), None # augmented inference, train
+
+ def _forward_once(self, x, profile=False, visualize=False):
+ y, dt = [], [] # outputs
+ for m in self.model:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ return x
+
+ def _descale_pred(self, p, flips, scale, img_size):
+ # de-scale predictions following augmented inference (inverse operation)
+ if self.inplace:
+ p[..., :4] /= scale # de-scale
+ if flips == 2:
+ p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
+ elif flips == 3:
+ p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
+ else:
+ x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
+ if flips == 2:
+ y = img_size[0] - y # de-flip ud
+ elif flips == 3:
+ x = img_size[1] - x # de-flip lr
+ p = torch.cat((x, y, wh, p[..., 4:]), -1)
+ return p
+
+ def _clip_augmented(self, y):
+ # Clip YOLOv5 augmented inference tails
+ nl = self.model[-1].nl # number of detection layers (P3-P5)
+ g = sum(4 ** x for x in range(nl)) # grid points
+ e = 1 # exclude layer count
+ i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
+ y[0] = y[0][:, :-i] # large
+ i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
+ y[-1] = y[-1][:, i:] # small
+ return y
+
+ def _profile_one_layer(self, m, x, dt):
+ c = isinstance(m, Detect) # is final layer, copy input as inplace fix
+ o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
+ t = time_sync()
+ for _ in range(10):
+ m(x.copy() if c else x)
+ dt.append((time_sync() - t) * 100)
+ if m == self.model[0]:
+ LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} module")
+ LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
+ if c:
+ LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
+
+ def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
+ # https://arxiv.org/abs/1708.02002 section 3.3
+ # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
+ m = self.model[-1] # Detect() module
+ for mi, s in zip(m.m, m.stride): # from
+ b = mi.bias.view(m.na, -1).detach() # conv.bias(255) to (3,85)
+ b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
+ b[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
+ mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
+
+ def _print_biases(self):
+ m = self.model[-1] # Detect() module
+ for mi in m.m: # from
+ b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
+ LOGGER.info(
+ ('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
+
+ # def _print_weights(self):
+ # for m in self.model.modules():
+ # if type(m) is Bottleneck:
+ # LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
+
+ def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
+ LOGGER.info('Fusing layers... ')
+ for m in self.model.modules():
+ if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
+ m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ self.info()
+ return self
+
+ def info(self, verbose=False, img_size=640): # print model information
+ model_info(self, verbose, img_size)
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model[-1] # Detect()
+ if isinstance(m, Detect):
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+
+def parse_model(d, ch): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ with contextlib.suppress(NameError):
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+
+ n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
+ c1, c2 = ch[f], args[0]
+ if c2 != no: # if not output
+ c2 = make_divisible(c2 * gw, 8)
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
+ args.insert(2, n) # number of repeats
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[x] for x in f)
+ elif m is Detect:
+ args.append([ch[x] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ elif m is Contract:
+ c2 = ch[f] * args[0] ** 2
+ elif m is Expand:
+ c2 = ch[f] // args[0] ** 2
+ else:
+ c2 = ch[f]
+
+ m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ if i == 0:
+ ch = []
+ ch.append(c2)
+ return nn.Sequential(*layers), sorted(save)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
+ parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--profile', action='store_true', help='profile model speed')
+ parser.add_argument('--line-profile', action='store_true', help='profile model speed layer by layer')
+ parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
+ opt = parser.parse_args()
+ opt.cfg = check_yaml(opt.cfg) # check YAML
+ print_args(vars(opt))
+ device = select_device(opt.device)
+
+ # Create model
+ im = torch.rand(opt.batch_size, 3, 640, 640).to(device)
+ model = Model(opt.cfg).to(device)
+
+ # Options
+ if opt.line_profile: # profile layer by layer
+ _ = model(im, profile=True)
+
+ elif opt.profile: # profile forward-backward
+ results = profile(input=im, ops=[model], n=3)
+
+ elif opt.test: # test all models
+ for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
+ try:
+ _ = Model(cfg)
+ except Exception as e:
+ print(f'Error in {cfg}: {e}')
+
+ else: # report fused model summary
+ model.fuse()
diff --git a/models/yolov5l.yaml b/models/yolov5l.yaml
new file mode 100755
index 0000000..ce8a5de
--- /dev/null
+++ b/models/yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/yolov5m.yaml b/models/yolov5m.yaml
new file mode 100755
index 0000000..ad13ab3
--- /dev/null
+++ b/models/yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/yolov5n.yaml b/models/yolov5n.yaml
new file mode 100755
index 0000000..8a28a40
--- /dev/null
+++ b/models/yolov5n.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/yolov5s.yaml b/models/yolov5s.yaml
new file mode 100755
index 0000000..524776d
--- /dev/null
+++ b/models/yolov5s.yaml
@@ -0,0 +1,52 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+# - [10,13, 16,30, 33,23] # P3/8
+# - [30,61, 62,45, 59,119] # P4/16
+# - [116,90, 156,198, 373,326] # P5/32
+ - [35,11, 64,22, 96,32] # P4/16
+ - [78,47, 125,41, 151,60] # P5/32
+ - [10,13, 16,30, 33,23] # P3/8
+
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/models/yolov5x.yaml b/models/yolov5x.yaml
new file mode 100755
index 0000000..f617a02
--- /dev/null
+++ b/models/yolov5x.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/prune.py b/prune.py
new file mode 100755
index 0000000..4bd0d90
--- /dev/null
+++ b/prune.py
@@ -0,0 +1,439 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Prune a YOLOv5 model on a custom dataset.
+
+Models and datasets download automatically from the latest YOLOv5 release.
+Models: https://github.com/ultralytics/yolov5/tree/master/models
+Datasets: https://github.com/ultralytics/yolov5/tree/master/data
+Tutorial: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
+
+Usage:
+ $ python prune.py --data data/coco128.yaml --weights yolov5s.pt --img 640
+"""
+
+import argparse
+import os
+import sys
+from copy import deepcopy
+from datetime import datetime
+from functools import partial
+from pathlib import Path
+
+import numpy as np
+import torch
+import yaml
+from enot.pruning import calibrate_and_prune_model_equal
+from enot.pruning import calibrate_and_prune_model_global_wrt_metric_drop
+from enot.pruning import calibrate_and_prune_model_optimal
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val # for end-of-epoch mAP
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.downloads import attempt_download
+from utils.general import (LOGGER, check_dataset, check_file, check_git_status, check_img_size,
+ check_requirements, check_suffix, check_yaml, colorstr, increment_path,
+ labels_to_class_weights, methods, print_args)
+from utils.loggers import Loggers
+from utils.loss import ComputeLoss
+from utils.pruning import count_mmac
+from utils.pruning import loss_function
+from utils.pruning import measure_inference_time_ort_cpu_single_thread
+from utils.pruning import measure_inference_time_torch
+from utils.pruning import sample_to_model_inputs
+from utils.pruning import sample_to_n_samples
+
+from utils.torch_utils import de_parallel, select_device, fix_model_compatibility_between_version
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+
+
+def prune(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
+ save_dir, epochs, batch_size, weights, single_cls, data, cfg, workers = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.data, opt.cfg, \
+ opt.workers
+ callbacks.run('on_pretrain_routine_start')
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ w.mkdir(parents=True, exist_ok=True) # make dir
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+
+ # Save run settings
+ with open(save_dir / 'opt.yaml', 'w') as f:
+ yaml.safe_dump(vars(opt), f, sort_keys=False)
+
+ # Loggers
+ data_dict = None
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.wandb:
+ data_dict = loggers.wandb.data_dict
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Config
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ if not weights.endswith('.pt'):
+ raise ValueError(f'wrong checkpoint name {weights}')
+
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
+
+ if ckpt.get('ema'):
+ model = ckpt['ema']
+ else:
+ model = ckpt['model']
+
+ model.float().to(device)
+ model = fix_model_compatibility_between_version(model)
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path,
+ imgsz,
+ batch_size,
+ gs,
+ single_cls,
+ hyp=hyp,
+ augment=True,
+ workers=workers,
+ prefix=colorstr('train: '),
+ shuffle=True)
+ mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ val_loader = create_dataloader(val_path,
+ imgsz,
+ batch_size * 2,
+ gs,
+ single_cls,
+ rect=True,
+ hyp=hyp,
+ workers=workers * 2,
+ pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ callbacks.run('on_pretrain_routine_end')
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Prepare for prune
+ compute_loss = ComputeLoss(model) # init loss class
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ 'Starting pruning...')
+
+ # Save original model
+ if opt.save_before_prune:
+ ckpt = {
+ 'epoch': -1,
+ 'best_fitness': 0.0,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': None,
+ 'updates': None,
+ 'optimizer': None,
+ 'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, w / 'original_model.pt')
+
+ # Test model before pruning
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size * 2,
+ imgsz=imgsz,
+ model=model.eval(),
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ model.train()
+ loss_fn = partial(loss_function, loss_fn=compute_loss, device=device)
+ pruning_hyps = hyp['pruning']
+ pruning_mode = pruning_hyps['pruning_mode']
+ calibration_steps = pruning_hyps['calibration_steps']
+ calibration_epochs = pruning_hyps['calibration_epochs']
+ sample_to_inputs = partial(sample_to_model_inputs, device=device)
+
+ cost_function = partial(
+ count_mmac,
+ dataloader=train_loader,
+ device=device
+ )
+ latency_units = 'MMACs'
+ original_model_cost = cost_function(model.eval())
+
+ LOGGER.info(f"Original model cost: {original_model_cost:.2f} {latency_units}")
+ model.train()
+
+ if pruning_mode == 'equal':
+ equal_pruning_mode_hyps = pruning_hyps[pruning_mode]
+ pruned_model = calibrate_and_prune_model_equal(
+ model=model,
+ dataloader=train_loader,
+ loss_function=loss_fn,
+ pruning_ratio=equal_pruning_mode_hyps['pruning_ratio'],
+ finetune_bn=True,
+ sample_to_n_samples=sample_to_n_samples,
+ sample_to_model_inputs=sample_to_inputs,
+ calibration_epochs=calibration_epochs,
+ calibration_steps=calibration_steps,
+ show_tqdm=True,
+ )
+ elif pruning_mode == 'optimal':
+ optimal_pruning_mode_hyps = pruning_hyps[pruning_mode]
+ if opt.n_search_steps is not None:
+ optimal_pruning_mode_hyps['n_search_steps'] = opt.n_search_steps
+
+ latency_type = optimal_pruning_mode_hyps['latency_type']
+
+ if latency_type == 'time':
+ time_hyps = optimal_pruning_mode_hyps['time']
+ if time_hyps['backend'] == 'ort_cpu':
+ cost_function = partial(
+ measure_inference_time_ort_cpu_single_thread,
+ image_size=imgsz,
+ model_device=device,
+ warmup=time_hyps['warmup'],
+ repeat=time_hyps['repeat'],
+ number=time_hyps['number'],
+ )
+ elif time_hyps['backend'] == 'torch':
+ cost_function = partial(
+ measure_inference_time_torch,
+ bs=opt.batch_size,
+ size=imgsz,
+ device=device,
+ warmup=time_hyps['warmup'],
+ repeat=time_hyps['repeat'],
+ number=time_hyps['number'],
+ )
+
+ latency_units = 'ms'
+
+ elif latency_type != 'flops':
+ raise ValueError(f'Unknown latency type {latency_type}, should be one of'
+ f'["flops", "time"]')
+
+ original_model_cost = cost_function(model.eval())
+ LOGGER.info(f"Original model cost: {original_model_cost:.2f} {latency_units}")
+
+ if opt.target_latency_fraction is not None:
+ optimal_pruning_mode_hyps['target_latency_fraction'] = opt.target_latency_fraction
+
+ target_latency = original_model_cost * optimal_pruning_mode_hyps['target_latency_fraction']
+ LOGGER.info(f"Target model cost: {target_latency:.2f} {latency_units}")
+
+ if optimal_pruning_mode_hyps['target_latency']:
+ target_latency = optimal_pruning_mode_hyps['target_latency']
+
+ model.train()
+
+ pruned_model = calibrate_and_prune_model_optimal(
+ model=model,
+ dataloader=train_loader,
+ loss_function=loss_fn,
+ latency_calculation_function=cost_function,
+ target_latency=target_latency,
+ finetune_bn=True,
+ calibration_steps=calibration_steps,
+ calibration_epochs=calibration_epochs,
+ n_search_steps=optimal_pruning_mode_hyps['n_search_steps'],
+ sample_to_model_inputs=sample_to_inputs,
+ sample_to_n_samples=sample_to_n_samples,
+ show_tqdm=True,
+ latency_penalty=optimal_pruning_mode_hyps['latency_penalty'],
+ )
+
+ elif pruning_mode == 'global_wrt_metric':
+ global_pruning_mode_hyps = pruning_hyps[pruning_mode]
+
+ def eval_map(pruned_model):
+ results, maps, _ = val.run(
+ data_dict,
+ batch_size=batch_size * 2,
+ imgsz=imgsz,
+ model=pruned_model,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ compute_loss=compute_loss,
+ )
+ pruned_model.train()
+ # results is sequence of mean_precision, mean_recall, map50, map and some detection losses
+ # here we optimize map firstly
+ return results[3]
+
+ pruned_model = calibrate_and_prune_model_global_wrt_metric_drop(
+ model=model.train(),
+ dataloader=train_loader,
+ loss_function=loss_fn,
+ validation_function=eval_map,
+ maximal_acceptable_metric_drop=global_pruning_mode_hyps['maximal_acceptable_metric_drop'],
+ minimal_channels_to_prune=global_pruning_mode_hyps['minimal_channels_to_prune'],
+ maximal_channels_to_prune=global_pruning_mode_hyps['maximal_channels_to_prune'],
+ channel_step_to_search=global_pruning_mode_hyps['channel_step_to_search'],
+ finetune_bn=True,
+ calibration_steps=calibration_steps,
+ calibration_epochs=calibration_epochs,
+ sample_to_model_inputs=sample_to_inputs,
+ sample_to_n_samples=sample_to_n_samples,
+ show_tqdm=True,
+ )
+ else:
+ raise ValueError(f'No such pruning mode:{pruning_mode}. Possible values: equal, global_wrt_metric, optimal.')
+
+ pruned_model.to(device)
+ pruned_model_cost = cost_function(pruned_model.eval())
+
+ LOGGER.info(f"Pruned model cost: {pruned_model_cost:.2f} {latency_units}")
+ LOGGER.info(f"Acceleration x{original_model_cost / pruned_model_cost:.4f} after pruning")
+
+ LOGGER.info(f"Eval pruned model")
+ # eval pruned model
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size * 2,
+ imgsz=imgsz,
+ model=pruned_model,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ compute_loss=compute_loss)
+
+ if opt.save_after_prune:
+ ckpt = {
+ 'epoch': -1,
+ 'best_fitness': 0.0,
+ 'model': deepcopy(de_parallel(pruned_model)).half(),
+ 'ema': None,
+ 'updates': None,
+ 'optimizer': None,
+ 'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
+ 'date': datetime.now().isoformat(),
+ 'map095': results[3],
+ }
+
+ # Save last, best and delete
+ torch.save(ckpt, w / 'pruned_model.pt')
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300)
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/prune', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+ parser.add_argument(
+ '--save_before_prune',
+ action='store_true',
+ help='Save checkpoint for original model.',
+ )
+ parser.add_argument(
+ '--save_after_prune',
+ type=bool,
+ default=True,
+ help='Save checkpoint for pruned model.',
+ )
+ parser.add_argument(
+ '--n-search-steps',
+ type=int,
+ default=None,
+ help='Number of steps for optimal architecture search.'
+ 'Default value is None, which means that value from hyp will be used.'
+ )
+ parser.add_argument(
+ '--target-latency-fraction',
+ type=float,
+ default=None,
+ help='Fraction of target latency for optimal architecture.'
+ 'Default value is None, which means that value from hyp will be used.'
+ )
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ return opt
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ print_args(vars(opt))
+ check_git_status()
+ check_requirements(exclude=['thop'])
+
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.name == 'cfg':
+ opt.name = Path(opt.cfg).stem # use model.yaml as name
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ prune(opt.hyp, opt, device, callbacks)
+
+
+def run(**kwargs):
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/quant.py b/quant.py
new file mode 100755
index 0000000..6fbb0bd
--- /dev/null
+++ b/quant.py
@@ -0,0 +1,116 @@
+import argparse
+from functools import partial
+
+import torch
+from enot.quantization import DefaultQuantizationDistiller
+from enot.quantization import OpenvinoFakeQuantizedModel
+from enot.quantization import TrtFakeQuantizedModel
+from onnx2torch import convert
+
+from utils.dataloaders import create_dataloader
+from utils.general import check_dataset
+
+
+def sample_to_model_inputs(x, device):
+ # x[0] is the first item from dataloader sample. Sample is a tuple where 0'th element is a tensor with images.
+ x = x[0]
+
+ # Model is on CUDA, so input images should also be on CUDA.
+ x = x.to(device)
+
+ # Converting tensor from int8 to float data type.
+ x = x.float()
+
+ # YOLOv5 image normalization (0-255 to 0-1 normalization)
+ x /= 255
+ return (x,), {}
+
+
+def main(opt):
+ if isinstance(opt.device, str):
+ device = torch.device(opt.device)
+ IMG_SHAPE = (opt.batch_size, 3, opt.imgsz, opt.imgsz)
+
+ data = check_dataset(opt.data)
+
+ valid_dataloader = create_dataloader(
+ path=data['val'],
+ imgsz=opt.imgsz,
+ batch_size=opt.batch_size,
+ stride=32,
+ single_cls=False,
+ pad=0.5,
+ rect=False,
+ workers=opt.workers,
+ hyp=opt.hyp,
+ )[0]
+
+ regular_model = convert(opt.weights).to(device)
+ regular_model.eval()
+
+ # Please consider to specify `quantization_scheme` for `OpenvinoFakeQuantizedModel`,
+ # quantization scheme can affect the perfomance of the quantized model.
+ # See for details: https://enot-autodl.rtd.enot.ai/en/stable/reference_documentation/quantization.html#enot.quantization.TrtFakeQuantizedModel
+
+ if opt.backend == 'openvino':
+ fake_quantized_model = OpenvinoFakeQuantizedModel(regular_model).to(device)
+ elif opt.backend == 'tensorrt':
+ fake_quantized_model = TrtFakeQuantizedModel(regular_model).to(device)
+ else:
+ ValueError('Invalid backend argument!')
+
+ # TODO: maybe use train dataloader
+ dist = DefaultQuantizationDistiller(
+ quantized_model=fake_quantized_model,
+ dataloader=valid_dataloader,
+ sample_to_model_inputs=partial(sample_to_model_inputs, device=device),
+ device=device,
+ logdir=opt.log_dir,
+ verbose=2,
+ )
+
+ dist.distill()
+
+ fake_quantized_model.to('cpu')
+ fake_quantized_model.enable_quantization_mode(True)
+ fake_quantized_model.to('cpu')
+
+ torch.onnx.export(
+ model=fake_quantized_model,
+ args=torch.ones(*IMG_SHAPE),
+ f=opt.weights.replace('.onnx', '_quant.onnx'),
+ input_names=['images'],
+ output_names=['output'],
+ opset_version=13,
+ )
+
+
+def run(**kwargs):
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ ROOT = './runs/'
+ parser.add_argument('--weights', type=str, default=ROOT + 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--data', type=str, default=ROOT + 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT + 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='Max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--backend', type=str, choices=['tensorrt', 'openvino'])
+ parser.add_argument('--log-dir', type=str, help='Path to dir for quantization log')
+ parser.add_argument('--epochs', type=int, default=1, help='Number of epochs for distillation')
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ return opt
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
diff --git a/requirements.txt b/requirements.txt
new file mode 100755
index 0000000..9b61246
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,49 @@
+# YOLOv5 requirements
+# Usage: pip install -r requirements.txt
+
+# Base ----------------------------------------
+matplotlib>=3.2.2
+numpy>=1.18.5
+opencv-python>=4.1.1
+Pillow>=7.1.2
+PyYAML>=5.3.1
+requests>=2.23.0
+scipy>=1.4.1
+torch==1.13.1
+torchvision==0.14.1
+tqdm>=4.64.0
+protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
+
+# Logging -------------------------------------
+tensorboard>=2.4.1
+# wandb
+# clearml
+
+# Plotting ------------------------------------
+pandas>=1.1.4
+seaborn>=0.11.0
+
+# Export --------------------------------------
+# coremltools>=5.2 # CoreML export
+# onnx>=1.9.0 # ONNX export
+onnx-simplifier==0.3.8 # ONNX simplifier
+# nvidia-pyindex # TensorRT export
+# nvidia-tensorrt # TensorRT export
+# scikit-learn==0.19.2 # CoreML quantization
+# tensorflow>=2.4.1 # TFLite export (or tensorflow-cpu, tensorflow-aarch64)
+# tensorflowjs>=3.9.0 # TF.js export
+# openvino-dev # OpenVINO export
+
+# Extras --------------------------------------
+ipython # interactive notebook
+psutil # system utilization
+thop>=0.1.1 # FLOPs computation
+# albumentations>=1.0.3
+# pycocotools>=2.0 # COCO mAP
+optuna
+# roboflow
+
+
+#ENOT
+enot-autodl
+enot-lite
diff --git a/setup.cfg b/setup.cfg
new file mode 100755
index 0000000..020a757
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,59 @@
+# Project-wide configuration file, can be used for package metadata and other toll configurations
+# Example usage: global configuration for PEP8 (via flake8) setting or default pytest arguments
+# Local usage: pip install pre-commit, pre-commit run --all-files
+
+[metadata]
+license_file = LICENSE
+description_file = README.md
+
+
+[tool:pytest]
+norecursedirs =
+ .git
+ dist
+ build
+addopts =
+ --doctest-modules
+ --durations=25
+ --color=yes
+
+
+[flake8]
+max-line-length = 120
+exclude = .tox,*.egg,build,temp
+select = E,W,F
+doctests = True
+verbose = 2
+# https://pep8.readthedocs.io/en/latest/intro.html#error-codes
+format = pylint
+# see: https://www.flake8rules.com/
+ignore =
+ E731 # Do not assign a lambda expression, use a def
+ F405 # name may be undefined, or defined from star imports: module
+ E402 # module level import not at top of file
+ F401 # module imported but unused
+ W504 # line break after binary operator
+ E127 # continuation line over-indented for visual indent
+ W504 # line break after binary operator
+ E231 # missing whitespace after ‘,’, ‘;’, or ‘:’
+ E501 # line too long
+ F403 # ‘from module import *’ used; unable to detect undefined names
+
+
+[isort]
+# https://pycqa.github.io/isort/docs/configuration/options.html
+line_length = 120
+# see: https://pycqa.github.io/isort/docs/configuration/multi_line_output_modes.html
+multi_line_output = 0
+
+
+[yapf]
+based_on_style = pep8
+spaces_before_comment = 2
+COLUMN_LIMIT = 120
+COALESCE_BRACKETS = True
+SPACES_AROUND_POWER_OPERATOR = True
+SPACE_BETWEEN_ENDING_COMMA_AND_CLOSING_BRACKET = False
+SPLIT_BEFORE_CLOSING_BRACKET = False
+SPLIT_BEFORE_FIRST_ARGUMENT = False
+# EACH_DICT_ENTRY_ON_SEPARATE_LINE = False
diff --git a/tests/hyp.test-hyps.yaml b/tests/hyp.test-hyps.yaml
new file mode 100755
index 0000000..0f1a720
--- /dev/null
+++ b/tests/hyp.test-hyps.yaml
@@ -0,0 +1,45 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Hyperparameters for high-augmentation COCO training from scratch
+# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
+# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
+
+lr0: 0.1 # initial learning rate (SGD=1E-2, Adam=1E-3)
+lrf: 1.0 # final OneCycleLR learning rate (lr0 * lrf)
+momentum: 0.000001 # SGD momentum/Adam beta1
+weight_decay: 0.0 # optimizer weight decay 5e-4
+warmup_epochs: 0.0 # warmup epochs (fractions ok)
+warmup_momentum: 0.0 # warmup initial momentum
+warmup_bias_lr: 0.0 # warmup initial bias lr
+box: 0.1 # box loss gain
+cls: 0.3 # cls loss gain
+cls_pw: 1.0 # cls BCELoss positive_weight
+obj: 0.7 # obj loss gain (scale with pixels)
+obj_pw: 1.0 # obj BCELoss positive_weight
+iou_t: 0.20 # IoU training threshold
+anchor_t: 4.0 # anchor-multiple threshold
+anchors: 2 # anchors per output layer (0 to ignore)
+fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
+hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
+hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
+hsv_v: 0.4 # image HSV-Value augmentation (fraction)
+degrees: 0.0 # image rotation (+/- deg)
+rotation_prob: 1.0 # image rotation probability
+translate: 0.1 # image translation (+/- fraction)
+scale: 0.9 # image scale (+/- gain)
+shear: 0.0 # image shear (+/- deg)
+perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
+flipud: 0.0 # image flip up-down (probability)
+fliplr: 0.5 # image flip left-right (probability)
+mosaic: 1.0 # image mosaic (probability)
+mixup: 0.1 # image mixup (probability)
+copy_paste: 0.1 # segment copy-paste (probability)
+
+# WARNING: please run hyperparameter evolution before you run training
+# albumentatuin augs
+blur: 0.01 # blur image using a random-sized kernel
+median_blur: 0.01 # median blur
+gray: 0.01 # convert image to gray
+clahe: 0.01 # CLAHE augmentations
+brightness_contrast: 0.01 # random brightness and contrast augmentation
+random_gamma: 0.01 # random gamma
+image_compression: 0.01 # image compression
diff --git a/tests/optuna_test.py b/tests/optuna_test.py
new file mode 100755
index 0000000..3b65ffb
--- /dev/null
+++ b/tests/optuna_test.py
@@ -0,0 +1,118 @@
+from itertools import product
+import sys
+from pathlib import Path
+import pandas as pd
+import numpy as np
+import yaml
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+import train
+from train import ROOT
+
+
+def test_trials():
+
+ weights_path = ROOT / 'yolov5n6.pt'
+ data_path = ROOT / 'data/coco128.yaml'
+ hyp_path = ROOT / 'tests/hyp.test-hyps.yaml'
+ project_path = ROOT / 'runs/tests'
+ task_name = 'tests_optuna_first_trial'
+
+ test_opt = dict(
+ weights=weights_path,
+ data=data_path,
+ hyp=hyp_path,
+ project=project_path,
+ name=task_name,
+ nosave=True,
+ noplots=True,
+ exist_ok=True,
+ autoanchor=False,
+ # small batch size is used for training instability
+ batch_size=32,
+ epochs=3,
+ evolve=200,
+ no_augs_evolving=True,
+ optuna=True,
+ # set default clearml name
+ clearml_project='optuna_tests',
+ clearml_task='test_trials',
+ )
+
+ opt = train.run(**test_opt)
+ hyp_evolve_path = Path(opt.save_dir) / 'hyp_evolve.yaml'
+ with open(hyp_evolve_path, errors='ignore') as f:
+ results = f.readlines()
+
+ for result_line in results:
+ if 'Best generation' in result_line:
+ assert ' 0' not in result_line, 'Best generation is 0'
+
+ return opt.save_dir
+
+def test_optuna_gridsearch():
+ weights_path = ROOT / 'yolov5n6.pt'
+ data_path = ROOT / 'data/coco128.yaml'
+ hyp_path = ROOT / 'tests/hyp.test-hyps.yaml'
+ project_path = ROOT / 'runs'
+ task_name = 'tests/tests_optuna_grid_search'
+
+ test_opt = dict(
+ weights=weights_path,
+ data=data_path,
+ hyp=hyp_path,
+ project=project_path,
+ name=task_name,
+ nosave=True,
+ noval=True,
+ noplots=True,
+ exist_ok=True,
+ noautoanchor=True,
+ # small batch size is used for training instability
+ batch_size=64,
+ imgsz=640,
+ epochs=1,
+ optuna=False,
+ # set default clearml name
+ clearml_project='optuna_tests',
+ clearml_task='test_gridsearch',
+ )
+
+ hyp_path = ROOT / 'tests/hyp.test-hyps.yaml'
+ with open(hyp_path, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+
+ grid_cell_num = 4
+ lr0_grid = np.linspace(1e-7, 0.07, grid_cell_num)
+ lrf_grid = np.linspace(0.01, 1.0, grid_cell_num)
+ weight_decay_grid = np.linspace(0.0, 0.0001, grid_cell_num)
+ warmup_epochs_grid = np.linspace(0.5, 5.0, grid_cell_num)
+
+ for grid_hyps in product(
+ lr0_grid,
+ lrf_grid,
+ weight_decay_grid,
+ warmup_epochs_grid
+ ):
+ hyp['lr0'] = float(grid_hyps[0])
+ hyp['lrf'] = float(grid_hyps[1])
+ hyp['weight_decay'] = float(grid_hyps[2])
+ hyp['warmup_epochs'] = float(grid_hyps[3])
+
+ test_opt['hyp'] = hyp
+ opt = train.run(**test_opt)
+
+ grid_search_result = pd.read_csv(Path(opt.save_dir) / 'results.csv')
+
+ optuna_result = pd.read_csv(project_path / 'tests/tests_optuna_first_trial' / 'results.csv')
+ map_str = 'metrics/mAP_0.5:0.95'
+ assert max(grid_search_result[map_str]) < max(optuna_result[map_str])
+
+
+if __name__ == '__main__':
+ test_trials()
+ test_optuna_gridsearch()
diff --git a/train.py b/train.py
new file mode 100755
index 0000000..049df83
--- /dev/null
+++ b/train.py
@@ -0,0 +1,976 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset.
+
+Models and datasets download automatically from the latest YOLOv5 release.
+Models: https://github.com/ultralytics/yolov5/tree/master/models
+Datasets: https://github.com/ultralytics/yolov5/tree/master/data
+Tutorial: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
+
+Usage:
+ $ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640 # from pretrained (RECOMMENDED)
+ $ python path/to/train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # from scratch
+"""
+
+import argparse
+import math
+import os
+import pickle
+import random
+import shutil
+import sys
+import time
+import warnings
+from copy import deepcopy
+from datetime import datetime
+from functools import partial
+from pathlib import Path
+
+import numpy as np
+import optuna
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from optuna.exceptions import ExperimentalWarning
+from optuna.storages import RetryFailedTrialCallback
+from torch.optim import lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.downloads import attempt_download, is_url
+from utils.general import (LOGGER, check_amp, check_dataset, check_file, check_git_status, check_img_size,
+ check_requirements, check_suffix, check_yaml, colorstr, emojis, get_latest_run,
+ increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
+ labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer)
+from utils.loggers import Loggers
+from utils.loggers.wandb.wandb_utils import check_wandb_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve, plot_labels
+from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
+ smart_resume, torch_distributed_zero_first)
+from utils.torch_utils import fix_model_compatibility_between_version, save_ckpt
+
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+# Disabling optuna logging
+optuna.logging.set_verbosity(optuna.logging.WARNING)
+
+
+def train(hyp, opt, device, callbacks, loggers=None): # hyp is path/to/hyp.yaml or hyp dictionary
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+ callbacks.run('on_pretrain_routine_start')
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve and not opt.save_every_trial else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ if opt.optuna:
+ # `trial_last` should have the following form: `runs/evolve/exp/trial_last`
+ if opt.save_every_trial:
+ # `w` has the following form: `runs/evolve/exp/trial_0/weights`
+ trial_last = w.parents[1] / 'trial_last'
+ else:
+ # `w` has standard form: `runs/evolve/exp/weights`
+ trial_last = w.parent / 'trial_last'
+
+ if os.path.exists(trial_last):
+ shutil.rmtree(trial_last)
+ trial_last.mkdir(parents=True)
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+ opt.hyp = hyp.copy() # for saving hyps to checkpoints
+
+ # Save run settings
+ if not evolve or opt.save_every_trial:
+ with open(save_dir / 'hyp.yaml', 'w') as f:
+ yaml.safe_dump(hyp, f, sort_keys=False)
+
+ with open(save_dir / 'opt.yaml', 'w') as f:
+ yaml.safe_dump(vars(opt), f, sort_keys=False)
+
+ # Save data configuration
+ if isinstance(data, str):
+ with open(data, errors='ignore') as f:
+ data_to_dump = yaml.safe_load(f)
+
+ with open(save_dir / 'data.yaml', 'w') as f:
+ yaml.safe_dump(data_to_dump, f, sort_keys=False)
+
+ # Loggers
+ data_dict = None
+ if RANK in {-1, 0} and loggers is None:
+ if not opt.optuna or opt.save_every_trial:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+
+ if loggers.clearml:
+ data_dict = loggers.clearml.data_dict # None if no ClearML dataset or filled in by ClearML
+ if loggers.wandb:
+ data_dict = loggers.wandb.data_dict
+ if resume:
+ weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ if opt.optuna:
+ loggers_cur_trial = Loggers(trial_last, weights, opt, hyp, LOGGER) # loggers for `trial_last` instance
+
+ for k in methods(loggers_cur_trial):
+ callbacks.register_action(k, callback=getattr(loggers_cur_trial, k))
+
+ # Config
+ plots = not evolve and not opt.noplots # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(opt.seed + 1 + RANK, deterministic=True)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
+ if opt.from_pruned:
+ model = ckpt['model'].float().to(device)
+ model = fix_model_compatibility_between_version(model)
+ else:
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ amp = check_amp(model) # check AMP
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ # v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz, amp)
+ if loggers is not None:
+ loggers.on_params_update({"batch_size": batch_size})
+ if opt.optuna:
+ loggers_cur_trial.on_params_update({"batch_size": batch_size})
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
+
+ # Scheduler
+ if opt.cos_lr:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ else:
+ lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in {-1, 0} else None
+
+ # Resume
+ best_fitness, start_epoch = 0.0, 0
+ if pretrained:
+ if resume:
+ best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
+ del ckpt
+ if not opt.from_pruned:
+ del csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path,
+ imgsz,
+ batch_size // WORLD_SIZE,
+ gs,
+ single_cls,
+ hyp=hyp,
+ augment=True,
+ cache=None if opt.cache == 'val' else opt.cache,
+ rect=opt.rect,
+ rank=LOCAL_RANK,
+ workers=workers,
+ image_weights=opt.image_weights,
+ quad=opt.quad,
+ prefix=colorstr('train: '),
+ shuffle=True)
+ labels = np.concatenate(dataset.labels, 0)
+ mlc = int(labels[:, 0].max()) # max label class
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in {-1, 0}:
+ val_loader = create_dataloader(val_path,
+ imgsz,
+ batch_size // WORLD_SIZE * 2,
+ gs,
+ single_cls,
+ hyp=hyp,
+ cache=None if noval else opt.cache,
+ rect=True,
+ rank=-1,
+ workers=workers * 2,
+ pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ if plots:
+ plot_labels(labels, names, save_dir)
+
+ # Anchors
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end')
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = smart_DDP(model)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nb = len(train_loader) # number of batches
+ nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = torch.cuda.amp.GradScaler(enabled=amp)
+ stopper, stop = EarlyStopping(patience=opt.patience), False
+ compute_loss = ComputeLoss(model) # init loss class
+ callbacks.run('on_train_start')
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ callbacks.run('on_train_epoch_start')
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
+ if RANK in {-1, 0}:
+ pbar = tqdm(pbar, total=nb, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ callbacks.run('on_train_batch_start')
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with torch.cuda.amp.autocast(amp):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
+ if ni - last_opt_step >= accumulate:
+ scaler.unscale_(optimizer) # unscale gradients
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in {-1, 0}:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%10s' * 2 + '%10.4g' * 5) %
+ (f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots)
+ if callbacks.stop_training:
+ return
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in {-1, 0}:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ half=amp,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ stop = stopper(epoch=epoch, fitness=fi) # early stop check
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ save = not nosave
+ is_final_epoch = final_epoch and not evolve
+
+ if save or is_final_epoch or opt.optuna: # if save
+ ckpt = {
+ 'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'wandb_id': loggers.wandb.wandb_run.id if (loggers is not None and loggers.wandb) else None,
+ 'opt': vars(opt),
+ 'date': datetime.now().isoformat()}
+
+ save_on_epoch = opt.save_period > 0 and epoch % opt.save_period == 0
+ is_best = best_fitness == fi
+
+ if not evolve or opt.save_every_trial:
+ save_ckpt(
+ ckpt=ckpt,
+ dir_to_save=w,
+ is_best=is_best,
+ save_on_epoch=save_on_epoch,
+ epoch=epoch,
+ )
+
+ # Save for optuna
+ if opt.optuna:
+ # Save current trial data
+ save_ckpt(
+ ckpt=ckpt,
+ dir_to_save=trial_last,
+ is_best=is_best,
+ save_on_epoch=save_on_epoch,
+ epoch=epoch,
+ )
+
+ with open(trial_last / 'hyp.yaml', 'w') as f:
+ yaml.safe_dump(hyp, f, sort_keys=False)
+
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ callbacks.run('after_model_save', log_vals, epoch, fi)
+
+ # EarlyStopping
+ if RANK != -1: # if DDP training
+ broadcast_list = [stop if RANK == 0 else None]
+ dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
+ if RANK != 0:
+ stop = broadcast_list[0]
+ if stop:
+ break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in {-1, 0}:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = val.run(
+ data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=plots,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ # We don't report this metric in optuna trial
+ if is_coco and not opt.optuna:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, plots, epoch, results)
+
+ torch.cuda.empty_cache()
+ return results
+
+
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300)
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW', 'RAdam', 'RMSProp'], default='SGD',
+ help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # ClearML arguments
+ parser.add_argument('--clearml_project', help='Project name for ClearML')
+ parser.add_argument('--clearml_task', help='Task name for ClearML')
+
+ # pruning arguments
+ parser.add_argument('--from_pruned', action='store_true', help='Load weights from pruned model')
+
+ # hyperparameter optimization arguments
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--no-augs-evolving', action='store_true',
+ help='Disable evolution search for augmentations, only works with --evolve')
+ parser.add_argument('--no-loss-evolving', action='store_true',
+ help='Disable evolution search for loss, only works with --evolve')
+ parser.add_argument('--only-wu-epochs-and-lr', action='store_true',
+ help='Evolution search only for warmup epochs and learning rate')
+
+ # optuna hyperparameter optimization arguments
+ parser.add_argument('--optuna', action='store_true',
+ help='Evolve hyperparameters with Optuna, only works with --evolve')
+ parser.add_argument('--save-every-trial', action='store_true',
+ help='Save best and last checkpoints in every Optuna\'s trial')
+ parser.add_argument('--min-res', type=int, default=1,
+ help='Minimal resources for HyperbandPruner, represent min number of epochs, '
+ 'only works with --optuna')
+ parser.add_argument('--max-res', default='auto',
+ help='Maximal resources for HyperbandPruner, represent max number of epochs, '
+ 'only works with --optuna')
+ parser.add_argument('--reduction-factor', type=int, default=3, help='Reduction factor of HyperbandPruner, '
+ 'only works with --optuna')
+ parser.add_argument(
+ '--max_map_drop',
+ type=float,
+ default=0.02,
+ help='maximum map drop while hyper-parameters search. Works only with optuna and from-pruned flags',
+ )
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ # max_res should be 'auto' or int
+ opt.max_res = int(opt.max_res) if opt.max_res != 'auto' else opt.max_res
+
+ is_optuna_params = opt.min_res != 1 or opt.max_res != 'auto' or opt.reduction_factor != 3
+
+ if not opt.optuna and is_optuna_params:
+ raise ValueError('--min_res, --max_res, --reduction_factor parameters only works with --optuna')
+
+ if not opt.optuna and opt.save_every_trial:
+ raise NotImplementedError('Every generation logging only works with --optuna')
+
+ return opt
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in {-1, 0}:
+ print_args(vars(opt))
+ # We use our custom version of yolo
+ # check_git_status()
+ check_requirements(exclude=['thop', 'fvcore'])
+
+ # Resume
+ opt.resume_optuna = opt.evolve and opt.optuna and opt.resume
+ if opt.resume and not (check_wandb_resume(opt) or opt.evolve): # resume from specified or most recent last.pt
+ last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
+ opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
+ opt_data = opt.data # original dataset
+ if opt_yaml.is_file():
+ with open(opt_yaml, errors='ignore') as f:
+ resume_opt = argparse.Namespace(**yaml.safe_load(f))
+ resume_opt.device = opt.device
+ opt = resume_opt # replace
+ opt.cfg, opt.weights, opt.resume = '', str(last), True # reinstate
+ if is_url(opt_data):
+ opt.data = check_file(opt_data) # avoid HUB resume auth timeout
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ if opt.name == 'cfg':
+ opt.name = Path(opt.cfg).stem # use model.yaml as name
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
+ assert not opt.image_weights, f'--image-weights {msg}'
+ assert not opt.evolve, f'--evolve {msg}'
+ assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
+ assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {
+ 'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'rotation_prob': (0, 0.0, 1.0), # probability of image rotation
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0), # segment copy-paste (probability)
+ 'blur': (1, 0.0, 0.9), # image blurring using a random-sized kernel
+ 'median_blur': (1, 0.0, 0.9), # image blurring using a median kernel
+ 'gray': (1, 0.0, 0.9), # image convert to gray
+ 'clahe': (1, 0.0, 0.9), # image clahe augmentation
+ 'random_gamma': (1, 0.0, 0.9), # image random gamma perturbation
+ 'brightness_contrast': (1, 0.0, 0.9), # random brightness and contrast augmentation
+ 'image_compression': (1, 0.0, 0.9), # image compression
+ }
+ if not isinstance(opt.hyp, dict):
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ else:
+ hyp = opt.hyp
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ if opt.noautoanchor:
+ del hyp['anchors'], meta['anchors']
+
+ data_dict = check_dataset(opt.data)
+ nc = 1 if opt.single_cls else int(data_dict['nc']) # number of classes
+ if nc == 1: # disable cls loss optimization
+ meta['cls'] = (0, 0.2, 4.0) # cls loss gain
+ meta['cls_pw'] = (0, 0.5, 2.0) # cls BCELoss positive_weight
+
+ if opt.no_augs_evolving:
+ # Disabling augmentations as the first number in the tuple is mutation scale
+ meta['hsv_h'] = (0, 0.0, 0.1) # image HSV-Hue augmentation (fraction)
+ meta['hsv_s'] = (0, 0.0, 0.9) # image HSV-Saturation augmentation (fraction)
+ meta['hsv_v'] = (0, 0.0, 0.9) # image HSV-Value augmentation (fraction)
+ meta['degrees'] = (0, 0.0, 45.0) # image rotation (+/- deg)
+ meta['rotation_prob'] = (0, 0.0, 1.0) # probability of image rotation
+ meta['translate'] = (0, 0.0, 0.9) # image translation (+/- fraction)
+ meta['scale'] = (0, 0.0, 0.9) # image scale (+/- gain)
+ meta['shear'] = (0, 0.0, 10.0) # image shear (+/- deg)
+ meta['perspective'] = (0, 0.0, 0.001) # image perspective (+/- fraction), range 0-0.001
+ meta['flipud'] = (0, 0.0, 1.0) # image flip up-down (probability)
+ meta['fliplr'] = (0, 0.0, 1.0) # image flip left-right (probability)
+ meta['mosaic'] = (0, 0.0, 1.0) # image mixup (probability)
+ meta['mixup'] = (0, 0.0, 1.0) # image mixup (probability)
+ meta['copy_paste'] = (0, 0.0, 1.0) # segment copy-paste (probability)
+
+ meta['blur'] = (0, 0.0, 0.9) # image blurring using a random-sized kernel
+ meta['median_blur'] = (0, 0.0, 0.9) # image blurring using a median kernel
+ meta['gray'] = (0, 0.0, 0.9) # image convert to gray
+ meta['clahe'] = (0, 0.0, 0.9) # image clahe augmentation
+ meta['random_gamma'] = (0, 0.0, 0.9) # image random gamma perturbation
+ meta['brightness_contrast'] = (0, 0.0, 0.9) # random brightness and contrast augmentation
+ meta['image_compression'] = (0, 0.0, 0.9) # image compression
+
+ if opt.no_loss_evolving: # disable losses weights optimization
+ meta['box'] = (0, 0.0, 0.2) # box loss gain
+ meta['cls'] = (0, 0.0, 4.0) # cls loss gain
+ meta['cls_pw'] = (0, 0.0, 2.0) # cls BCELoss positive_weight
+ meta['obj'] = (0, 0.0, 4.0) # obj loss gain (scale with pixels)
+ meta['obj_pw'] = (0, 0.0, 2.0) # obj BCELoss positive_weight
+
+ if opt.only_wu_epochs_and_lr: # optimize only lr0 and warmup_epochs
+ for param_name, param_range in meta.items():
+ meta[param_name] = (0, 0.0, param_range[-1])
+ meta['lr0'] = (1, 1e-5, 1e-1)
+ meta['warmup_epochs'] = (1, 1, 15)
+
+ # only val/save final epoch
+ opt.noval, opt.nosave, save_dir = not opt.optuna, not opt.save_every_trial, Path(opt.save_dir)
+
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {evolve_csv}') # download evolve.csv if exists
+
+ if not opt.optuna: # genetics evolving case
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+ callbacks = Callbacks()
+ # Write mutation results
+ print_mutation(results, hyp.copy(), save_dir, opt.bucket)
+
+ else: # optuna evolving case
+ no_train_map = torch.load(opt.weights, map_location='cpu')['map095'] if opt.from_pruned else None
+ pruner = optuna.pruners.HyperbandPruner(
+ min_resource=opt.min_res,
+ max_resource=opt.max_res,
+ reduction_factor=opt.reduction_factor,
+ )
+
+ save_dir.mkdir(parents=True, exist_ok=opt.exist_ok)
+ study_name = (save_dir / 'study').as_posix()
+ storage_name = f"sqlite:///{study_name}.db"
+
+ # we want to re-run failed trials
+ storage = optuna.storages.RDBStorage(
+ storage_name,
+ heartbeat_interval=1,
+ failed_trial_callback=RetryFailedTrialCallback(),
+ )
+
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=ExperimentalWarning) # suppress optuna warnings
+
+ # we need to save sampler and load it separately when resuming
+ # because it is not stored in the Optuna's study
+ if opt.resume_optuna:
+ # load TPE sampler, see https://github.com/optuna/optuna/pull/3992
+ sampler = pickle.load(open(save_dir / 'sampler.pkl', 'rb'))
+ else:
+ # create TPE sampler
+ sampler = optuna.samplers.TPESampler(
+ seed=(opt.seed + 1 + RANK),
+ multivariate=True
+ )
+
+ study = optuna.create_study(
+ direction="maximize", # in case of metric optimization
+ pruner=pruner,
+ sampler=sampler,
+ study_name=study_name,
+ storage=storage,
+ load_if_exists=True,
+ )
+
+ # Add parameters from hyp config as initial optuna parameters
+ root_save_dir = opt.save_dir
+ trail_hyps_keys = [hyp_name for hyp_name in hyp if meta[hyp_name][0]]
+ format_save_dir_with_hyps = len(trail_hyps_keys) < 5
+ # Initialize parameters of first trial
+ start_trial_hyp = {hyp_name: hyp[hyp_name] for hyp_name in trail_hyps_keys}
+
+ if not opt.resume_optuna:
+ # start with start_trial_hyp
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=ExperimentalWarning) # suppress optuna warnings
+ # Add first trial in study's queue
+ study.enqueue_trial(start_trial_hyp)
+
+ def optuna_pruning_callback(log_vals, epoch, fi, trial, no_train_map, study, root_dir):
+ # Report current fitness value
+ trial.report(float(fi), step=epoch)
+
+ is_max_epochs = epoch >= opt.max_res if isinstance(opt.max_res, int) else False
+ results = tuple(val if val > 0 else 0 for val in log_vals[3:-3]) # Get results from log_vals
+
+ # get the list of trial fitness
+ trial_fitness = [x.values[0]
+ for x in study.trials
+ if x.state in (optuna.trial.TrialState.PRUNED, optuna.trial.TrialState.COMPLETE)]
+
+ best_fitness = max(trial_fitness) if trial_fitness else 0
+
+ if float(fi) >= best_fitness:
+ # copy the best checkpoints from last
+ trial_best = Path(root_dir) / 'trial_best'
+ trial_last = Path(root_dir) / 'trial_last'
+
+ if os.path.exists(trial_best):
+ shutil.rmtree(trial_best)
+ shutil.copytree(trial_last, trial_best)
+
+ if trial.should_prune() or is_max_epochs or (no_train_map and (
+ results[3] - no_train_map < -opt.max_map_drop)):
+
+ # Replacing standard hyperparameters with parameters from trial
+ trial_hyp = {**hyp, **trial.params}
+ # log_vals contains losses, results and lr
+ print_mutation(results, trial_hyp, save_dir, opt.bucket)
+ opt.save_dir = root_save_dir
+
+ torch.cuda.empty_cache()
+ # raise optuna exception
+ raise optuna.TrialPruned()
+
+ def optuna_criterion(trial):
+ torch.cuda.empty_cache()
+
+ clearml_task = opt.clearml_task
+
+ # dump sampler
+ with open(save_dir / 'sampler.pkl', 'wb') as fout:
+ pickle.dump(study.sampler, fout)
+
+ # Suggest hyps
+ for hyp_name in trail_hyps_keys:
+ _, start, end = meta[hyp_name]
+ trial.suggest_float(hyp_name, start, end)
+
+ # Replacing standard hyperparameters with parameters from trial
+ trial_hyp = {**hyp, **trial.params}
+
+ if opt.save_every_trial:
+ # Set log directory
+ trial_dir_name = f'trial_{trial.number}'
+ opt.save_dir += ('/' + trial_dir_name)
+ opt.clearml_task += ('_' + trial_dir_name)
+ if format_save_dir_with_hyps:
+ # Formation of the save directory name as a combination of hyperparameter values
+ hyps_str = '#'.join(f'{k}_{round(v, 5)}' for k, v in trial.params.items())
+ opt.save_dir += hyps_str
+ else:
+ LOGGER.info(emojis(
+ f'WARNING: Generation save dir is set default name: {opt.save_dir}.'
+ f'Too many hyperparameters of optimization is specified ⚠️'))
+
+ # Create callbacks and loggers instances
+ callbacks = Callbacks()
+
+ # Set pruning callback
+ trial_pruning_callback = partial(optuna_pruning_callback, trial=trial, no_train_map=no_train_map,
+ study=study, root_dir=root_save_dir)
+ # Report trial's results in on_fit_epoch_end action
+ callbacks.register_action(
+ 'after_model_save',
+ name='prune_optuna_trial',
+ callback=trial_pruning_callback
+ )
+
+ opt.clearml_task = clearml_task
+
+ LOGGER.info(f"{colorstr(f'Start training trial {trial.number}')}\n")
+
+ # Run training
+ results = train(trial_hyp, opt, device, callbacks)
+ opt.save_dir = root_save_dir
+
+ print_mutation(results, trial_hyp, save_dir, opt.bucket)
+
+ # If trial is not pruned report value of fitness function
+ return fitness(np.array(results).reshape(1, -1))
+
+ # In case of resume we must keep number of trials
+ n_prev_trials = len([trial
+ for trial in study.get_trials()
+ if trial.state in (optuna.trial.TrialState.PRUNED, optuna.trial.TrialState.COMPLETE)])
+ n_trials = opt.evolve - n_prev_trials
+ study.optimize(optuna_criterion, n_trials=n_trials)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Usage example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+ return opt
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/tutorial.ipynb b/tutorial.ipynb
new file mode 100755
index 0000000..61641ba
--- /dev/null
+++ b/tutorial.ipynb
@@ -0,0 +1,1141 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "YOLOv5 Tutorial",
+ "provenance": [],
+ "collapsed_sections": [],
+ "machine_shape": "hm",
+ "toc_visible": true,
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU",
+ "widgets": {
+ "application/vnd.jupyter.widget-state+json": {
+ "c31d2039ccf74c22b67841f4877d1186": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HBoxModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HBoxModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HBoxView",
+ "box_style": "",
+ "children": [
+ "IPY_MODEL_d4bba1727c714d94ad58a72bffa07c4c",
+ "IPY_MODEL_9aeff9f1780b45f892422fdc96e56913",
+ "IPY_MODEL_bf55a7c71d074d3fa88b10b997820825"
+ ],
+ "layout": "IPY_MODEL_d8b66044e2fb4f5b916696834d880c81"
+ }
+ },
+ "d4bba1727c714d94ad58a72bffa07c4c": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_102e1deda239436fa72751c58202fa0f",
+ "placeholder": "",
+ "style": "IPY_MODEL_4fd4431ced6c42368e18424912b877e4",
+ "value": "100%"
+ }
+ },
+ "9aeff9f1780b45f892422fdc96e56913": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "FloatProgressModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "FloatProgressModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "ProgressView",
+ "bar_style": "success",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_cdd709c4f40941bea1b2053523c9fac8",
+ "max": 818322941,
+ "min": 0,
+ "orientation": "horizontal",
+ "style": "IPY_MODEL_a1ef2d8de2b741c78ca5d938e2ddbcdf",
+ "value": 818322941
+ }
+ },
+ "bf55a7c71d074d3fa88b10b997820825": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "HTMLModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_dom_classes": [],
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "HTMLModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/controls",
+ "_view_module_version": "1.5.0",
+ "_view_name": "HTMLView",
+ "description": "",
+ "description_tooltip": null,
+ "layout": "IPY_MODEL_0dbce99bb6184238842cbec0587d564a",
+ "placeholder": "",
+ "style": "IPY_MODEL_91ff5f93f2a24c5790ab29e347965946",
+ "value": " 780M/780M [01:10<00:00, 10.5MB/s]"
+ }
+ },
+ "d8b66044e2fb4f5b916696834d880c81": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "model_module_version": "1.2.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "102e1deda239436fa72751c58202fa0f": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "model_module_version": "1.2.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "4fd4431ced6c42368e18424912b877e4": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ },
+ "cdd709c4f40941bea1b2053523c9fac8": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "model_module_version": "1.2.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "a1ef2d8de2b741c78ca5d938e2ddbcdf": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "ProgressStyleModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "ProgressStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "bar_color": null,
+ "description_width": ""
+ }
+ },
+ "0dbce99bb6184238842cbec0587d564a": {
+ "model_module": "@jupyter-widgets/base",
+ "model_name": "LayoutModel",
+ "model_module_version": "1.2.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/base",
+ "_model_module_version": "1.2.0",
+ "_model_name": "LayoutModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "LayoutView",
+ "align_content": null,
+ "align_items": null,
+ "align_self": null,
+ "border": null,
+ "bottom": null,
+ "display": null,
+ "flex": null,
+ "flex_flow": null,
+ "grid_area": null,
+ "grid_auto_columns": null,
+ "grid_auto_flow": null,
+ "grid_auto_rows": null,
+ "grid_column": null,
+ "grid_gap": null,
+ "grid_row": null,
+ "grid_template_areas": null,
+ "grid_template_columns": null,
+ "grid_template_rows": null,
+ "height": null,
+ "justify_content": null,
+ "justify_items": null,
+ "left": null,
+ "margin": null,
+ "max_height": null,
+ "max_width": null,
+ "min_height": null,
+ "min_width": null,
+ "object_fit": null,
+ "object_position": null,
+ "order": null,
+ "overflow": null,
+ "overflow_x": null,
+ "overflow_y": null,
+ "padding": null,
+ "right": null,
+ "top": null,
+ "visibility": null,
+ "width": null
+ }
+ },
+ "91ff5f93f2a24c5790ab29e347965946": {
+ "model_module": "@jupyter-widgets/controls",
+ "model_name": "DescriptionStyleModel",
+ "model_module_version": "1.5.0",
+ "state": {
+ "_model_module": "@jupyter-widgets/controls",
+ "_model_module_version": "1.5.0",
+ "_model_name": "DescriptionStyleModel",
+ "_view_count": null,
+ "_view_module": "@jupyter-widgets/base",
+ "_view_module_version": "1.2.0",
+ "_view_name": "StyleView",
+ "description_width": ""
+ }
+ }
+ }
+ }
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "t6MPjfT5NrKQ"
+ },
+ "source": [
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "t6MPjfT5NrKQ"
+ },
+ "source": [
+ "\n",
+ " \n",
+ "\n",
+ "This is the **official YOLOv5 🚀 notebook** by **Ultralytics**, and is freely available for redistribution under the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/). \n",
+ "For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7mGmQbAO5pQb"
+ },
+ "source": [
+ "# Setup\n",
+ "\n",
+ "Clone repo, install dependencies and check PyTorch and GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wbvMlHd_QwMG",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "185d0979-edcd-4860-e6fb-b8a27dbf5096"
+ },
+ "source": [
+ "!git clone https://github.com/ultralytics/yolov5 # clone\n",
+ "%cd yolov5\n",
+ "%pip install -qr requirements.txt # install\n",
+ "\n",
+ "import torch\n",
+ "import utils\n",
+ "display = utils.notebook_init() # checks"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "YOLOv5 🚀 v6.1-370-g20f1b7e Python-3.7.13 torch-1.12.0+cu113 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n"
+ ]
+ },
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Setup complete ✅ (8 CPUs, 51.0 GB RAM, 37.4/166.8 GB disk)\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4JnkELT0cIJg"
+ },
+ "source": [
+ "# 1. Inference\n",
+ "\n",
+ "`detect.py` runs YOLOv5 inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/detect`. Example inference sources are:\n",
+ "\n",
+ "```shell\n",
+ "python detect.py --source 0 # webcam\n",
+ " img.jpg # image \n",
+ " vid.mp4 # video\n",
+ " path/ # directory\n",
+ " 'path/*.jpg' # glob\n",
+ " 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n",
+ " 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "zR9ZbuQCH7FX",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "4b13989f-32a4-4ef0-b403-06ff3aac255c"
+ },
+ "source": [
+ "!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images\n",
+ "#display.Image(filename='runs/detect/exp/zidane.jpg', width=600)"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mdetect: \u001b[0mweights=['yolov5s.pt'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False\n",
+ "YOLOv5 🚀 v6.1-370-g20f1b7e Python-3.7.13 torch-1.12.0+cu113 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt to yolov5s.pt...\n",
+ "100% 14.1M/14.1M [00:00<00:00, 53.9MB/s]\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.016s)\n",
+ "image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 2 ties, Done. (0.021s)\n",
+ "Speed: 0.6ms pre-process, 18.6ms inference, 25.0ms NMS per image at shape (1, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/detect/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hkAzDWJ7cWTr"
+ },
+ "source": [
+ " \n",
+ "
\n",
+ "\n",
+ "This is the **official YOLOv5 🚀 notebook** by **Ultralytics**, and is freely available for redistribution under the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/). \n",
+ "For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7mGmQbAO5pQb"
+ },
+ "source": [
+ "# Setup\n",
+ "\n",
+ "Clone repo, install dependencies and check PyTorch and GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wbvMlHd_QwMG",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "185d0979-edcd-4860-e6fb-b8a27dbf5096"
+ },
+ "source": [
+ "!git clone https://github.com/ultralytics/yolov5 # clone\n",
+ "%cd yolov5\n",
+ "%pip install -qr requirements.txt # install\n",
+ "\n",
+ "import torch\n",
+ "import utils\n",
+ "display = utils.notebook_init() # checks"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "YOLOv5 🚀 v6.1-370-g20f1b7e Python-3.7.13 torch-1.12.0+cu113 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n"
+ ]
+ },
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Setup complete ✅ (8 CPUs, 51.0 GB RAM, 37.4/166.8 GB disk)\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4JnkELT0cIJg"
+ },
+ "source": [
+ "# 1. Inference\n",
+ "\n",
+ "`detect.py` runs YOLOv5 inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/detect`. Example inference sources are:\n",
+ "\n",
+ "```shell\n",
+ "python detect.py --source 0 # webcam\n",
+ " img.jpg # image \n",
+ " vid.mp4 # video\n",
+ " path/ # directory\n",
+ " 'path/*.jpg' # glob\n",
+ " 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n",
+ " 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "zR9ZbuQCH7FX",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "4b13989f-32a4-4ef0-b403-06ff3aac255c"
+ },
+ "source": [
+ "!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images\n",
+ "#display.Image(filename='runs/detect/exp/zidane.jpg', width=600)"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mdetect: \u001b[0mweights=['yolov5s.pt'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False\n",
+ "YOLOv5 🚀 v6.1-370-g20f1b7e Python-3.7.13 torch-1.12.0+cu113 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt to yolov5s.pt...\n",
+ "100% 14.1M/14.1M [00:00<00:00, 53.9MB/s]\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.016s)\n",
+ "image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 2 ties, Done. (0.021s)\n",
+ "Speed: 0.6ms pre-process, 18.6ms inference, 25.0ms NMS per image at shape (1, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/detect/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hkAzDWJ7cWTr"
+ },
+ "source": [
+ " \n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on [COCO](https://cocodataset.org/#home) val or test-dev datasets. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag. Note that `pycocotools` metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyTZYGgRjnMc"
+ },
+ "source": [
+ "## COCO val\n",
+ "Download [COCO val 2017](https://github.com/ultralytics/yolov5/blob/74b34872fdf41941cddcf243951cdb090fbac17b/data/coco.yaml#L14) dataset (1GB - 5000 images), and test model accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 49,
+ "referenced_widgets": [
+ "c31d2039ccf74c22b67841f4877d1186",
+ "d4bba1727c714d94ad58a72bffa07c4c",
+ "9aeff9f1780b45f892422fdc96e56913",
+ "bf55a7c71d074d3fa88b10b997820825",
+ "d8b66044e2fb4f5b916696834d880c81",
+ "102e1deda239436fa72751c58202fa0f",
+ "4fd4431ced6c42368e18424912b877e4",
+ "cdd709c4f40941bea1b2053523c9fac8",
+ "a1ef2d8de2b741c78ca5d938e2ddbcdf",
+ "0dbce99bb6184238842cbec0587d564a",
+ "91ff5f93f2a24c5790ab29e347965946"
+ ]
+ },
+ "outputId": "a9004b06-37a6-41ed-a1f2-ac956f3963b3"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "text/plain": [
+ " 0%| | 0.00/780M [00:00
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on [COCO](https://cocodataset.org/#home) val or test-dev datasets. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag. Note that `pycocotools` metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyTZYGgRjnMc"
+ },
+ "source": [
+ "## COCO val\n",
+ "Download [COCO val 2017](https://github.com/ultralytics/yolov5/blob/74b34872fdf41941cddcf243951cdb090fbac17b/data/coco.yaml#L14) dataset (1GB - 5000 images), and test model accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 49,
+ "referenced_widgets": [
+ "c31d2039ccf74c22b67841f4877d1186",
+ "d4bba1727c714d94ad58a72bffa07c4c",
+ "9aeff9f1780b45f892422fdc96e56913",
+ "bf55a7c71d074d3fa88b10b997820825",
+ "d8b66044e2fb4f5b916696834d880c81",
+ "102e1deda239436fa72751c58202fa0f",
+ "4fd4431ced6c42368e18424912b877e4",
+ "cdd709c4f40941bea1b2053523c9fac8",
+ "a1ef2d8de2b741c78ca5d938e2ddbcdf",
+ "0dbce99bb6184238842cbec0587d564a",
+ "91ff5f93f2a24c5790ab29e347965946"
+ ]
+ },
+ "outputId": "a9004b06-37a6-41ed-a1f2-ac956f3963b3"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "text/plain": [
+ " 0%| | 0.00/780M [00:00 \n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "\n",
+ "Train a YOLOv5s model on the [COCO128](https://www.kaggle.com/ultralytics/coco128) dataset with `--data coco128.yaml`, starting from pretrained `--weights yolov5s.pt`, or from randomly initialized `--weights '' --cfg yolov5s.yaml`.\n",
+ "\n",
+ "- **Pretrained [Models](https://github.com/ultralytics/yolov5/tree/master/models)** are downloaded\n",
+ "automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases)\n",
+ "- **[Datasets](https://github.com/ultralytics/yolov5/tree/master/data)** available for autodownload include: [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [COCO128](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [Argoverse](https://github.com/ultralytics/yolov5/blob/master/data/Argoverse.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml), [xView](https://github.com/ultralytics/yolov5/blob/master/data/xView.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [SKU-110K](https://github.com/ultralytics/yolov5/blob/master/data/SKU-110K.yaml).\n",
+ "- **Training Results** are saved to `runs/train/` with incrementing run directories, i.e. `runs/train/exp2`, `runs/train/exp3` etc.\n",
+ "
\n",
+ "\n",
+ "A **Mosaic Dataloader** is used for training which combines 4 images into 1 mosaic.\n",
+ "\n",
+ "## Train on Custom Data with Roboflow 🌟 NEW\n",
+ "\n",
+ "[Roboflow](https://roboflow.com/?ref=ultralytics) enables you to easily **organize, label, and prepare** a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the `roboflow` pip package.\n",
+ "\n",
+ "- Custom Training Example: [https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/](https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/?ref=ultralytics)\n",
+ "- Custom Training Notebook: [](https://colab.research.google.com/github/roboflow-ai/yolov5-custom-training-tutorial/blob/main/yolov5-custom-training.ipynb)\n",
+ "
\n",
+ "\n",
+ "
Label images lightning fast (including with model-assisted labeling)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "bOy5KI2ncnWd"
+ },
+ "source": [
+ "# Tensorboard (optional)\n",
+ "%load_ext tensorboard\n",
+ "%tensorboard --logdir runs/train"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# ClearML (optional)\n",
+ "%pip install -q clearml\n",
+ "!clearml-init"
+ ],
+ "metadata": {
+ "id": "DQhI6vvaRWjR"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "2fLAV42oNb7M"
+ },
+ "source": [
+ "# Weights & Biases (optional)\n",
+ "%pip install -q wandb\n",
+ "import wandb\n",
+ "wandb.login()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "1NcFxRcFdJ_O",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "bce1b4bd-1a14-4c07-aebd-6c11e91ad24b"
+ },
+ "source": [
+ "# Train YOLOv5s on COCO128 for 3 epochs\n",
+ "!python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mtrain: \u001b[0mweights=yolov5s.pt, cfg=, data=coco128.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest\n",
+ "\u001b[34m\u001b[1mgithub: \u001b[0mup to date with https://github.com/ultralytics/yolov5 ✅\n",
+ "YOLOv5 🚀 v6.1-370-g20f1b7e Python-3.7.13 torch-1.12.0+cu113 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "\u001b[34m\u001b[1mhyperparameters: \u001b[0mlr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0\n",
+ "\u001b[34m\u001b[1mWeights & Biases: \u001b[0mrun 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases\n",
+ "\u001b[34m\u001b[1mClearML: \u001b[0mrun 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 runs in ClearML\n",
+ "\u001b[34m\u001b[1mTensorBoard: \u001b[0mStart with 'tensorboard --logdir runs/train', view at http://localhost:6006/\n",
+ "\n",
+ "Dataset not found ⚠️, missing paths ['/content/datasets/coco128/images/train2017']\n",
+ "Downloading https://ultralytics.com/assets/coco128.zip to coco128.zip...\n",
+ "100% 6.66M/6.66M [00:00<00:00, 75.2MB/s]\n",
+ "Dataset download success ✅ (0.7s), saved to \u001b[1m/content/datasets\u001b[0m\n",
+ "\n",
+ " from n params module arguments \n",
+ " 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] \n",
+ " 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] \n",
+ " 2 -1 1 18816 models.common.C3 [64, 64, 1] \n",
+ " 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] \n",
+ " 4 -1 2 115712 models.common.C3 [128, 128, 2] \n",
+ " 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] \n",
+ " 6 -1 3 625152 models.common.C3 [256, 256, 3] \n",
+ " 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] \n",
+ " 8 -1 1 1182720 models.common.C3 [512, 512, 1] \n",
+ " 9 -1 1 656896 models.common.SPPF [512, 512, 5] \n",
+ " 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] \n",
+ " 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \n",
+ " 12 [-1, 6] 1 0 models.common.Concat [1] \n",
+ " 13 -1 1 361984 models.common.C3 [512, 256, 1, False] \n",
+ " 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] \n",
+ " 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] \n",
+ " 16 [-1, 4] 1 0 models.common.Concat [1] \n",
+ " 17 -1 1 90880 models.common.C3 [256, 128, 1, False] \n",
+ " 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] \n",
+ " 19 [-1, 14] 1 0 models.common.Concat [1] \n",
+ " 20 -1 1 296448 models.common.C3 [256, 256, 1, False] \n",
+ " 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] \n",
+ " 22 [-1, 10] 1 0 models.common.Concat [1] \n",
+ " 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] \n",
+ " 24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]\n",
+ "Model summary: 270 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs\n",
+ "\n",
+ "Transferred 349/349 items from yolov5s.pt\n",
+ "\u001b[34m\u001b[1mAMP: \u001b[0mchecks passed ✅\n",
+ "\u001b[34m\u001b[1moptimizer:\u001b[0m SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias\n",
+ "\u001b[34m\u001b[1malbumentations: \u001b[0mBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), MedianBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), ToGray(always_apply=False, p=0.01), CLAHE(always_apply=False, p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mScanning '/content/datasets/coco128/labels/train2017' images and labels...128 found, 0 missing, 2 empty, 0 corrupt: 100% 128/128 [00:00<00:00, 7926.40it/s]\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mNew cache created: /content/datasets/coco128/labels/train2017.cache\n",
+ "\u001b[34m\u001b[1mtrain: \u001b[0mCaching images (0.1GB ram): 100% 128/128 [00:00<00:00, 975.81it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning '/content/datasets/coco128/labels/train2017.cache' images and labels... 128 found, 0 missing, 2 empty, 0 corrupt: 100% 128/128 [00:00\n",
+ " "
+ ],
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DLI1JmHU7B0l"
+ },
+ "source": [
+ "## Weights & Biases Logging\n",
+ "\n",
+ "[Weights & Biases](https://wandb.ai/site?utm_campaign=repo_yolo_notebook) (W&B) is integrated with YOLOv5 for real-time visualization and cloud logging of training runs. This allows for better run comparison and introspection, as well improved visibility and collaboration for teams. To enable W&B `pip install wandb`, and then train normally (you will be guided through setup on first use). \n",
+ "\n",
+ "During training you will see live updates at [https://wandb.ai/home](https://wandb.ai/home?utm_campaign=repo_yolo_notebook), and you can create and share detailed [Reports](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY) of your results. For more information see the [YOLOv5 Weights & Biases Tutorial](https://github.com/ultralytics/yolov5/issues/1289). \n",
+ "\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DLI1JmHU7B0l"
+ },
+ "source": [
+ "## Weights & Biases Logging\n",
+ "\n",
+ "[Weights & Biases](https://wandb.ai/site?utm_campaign=repo_yolo_notebook) (W&B) is integrated with YOLOv5 for real-time visualization and cloud logging of training runs. This allows for better run comparison and introspection, as well improved visibility and collaboration for teams. To enable W&B `pip install wandb`, and then train normally (you will be guided through setup on first use). \n",
+ "\n",
+ "During training you will see live updates at [https://wandb.ai/home](https://wandb.ai/home?utm_campaign=repo_yolo_notebook), and you can create and share detailed [Reports](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY) of your results. For more information see the [YOLOv5 Weights & Biases Tutorial](https://github.com/ultralytics/yolov5/issues/1289). \n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Google Colab and Kaggle** notebooks with free GPU:
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Google Colab and Kaggle** notebooks with free GPU:  \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
\n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below for PyTorch Hub, CI, reproducing results, profiling speeds, VOC training, classification training and TensorRT example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "import torch\n",
+ "\n",
+ "# PyTorch Hub Model\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom\n",
+ "\n",
+ "# Images\n",
+ "img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list\n",
+ "\n",
+ "# Inference\n",
+ "results = model(img)\n",
+ "\n",
+ "# Results\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FGH0ZjkGjejy"
+ },
+ "source": [
+ "# YOLOv5 CI\n",
+ "%%shell\n",
+ "rm -rf runs # remove runs/\n",
+ "m=yolov5n # official weights\n",
+ "b=runs/train/exp/weights/best # best.pt checkpoint\n",
+ "python train.py --imgsz 64 --batch 32 --weights $m.pt --cfg $m.yaml --epochs 1 --device 0 # train\n",
+ "for d in 0 cpu; do # devices\n",
+ " for w in $m $b; do # weights\n",
+ " python val.py --imgsz 64 --batch 32 --weights $w.pt --device $d # val\n",
+ " python detect.py --imgsz 64 --weights $w.pt --device $d # detect\n",
+ " done\n",
+ "done\n",
+ "python hubconf.py --model $m # hub\n",
+ "python models/tf.py --weights $m.pt # build TF model\n",
+ "python models/yolo.py --cfg $m.yaml # build PyTorch model\n",
+ "python export.py --weights $m.pt --img 64 --include torchscript # export"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mcKoSIK2WSzj"
+ },
+ "source": [
+ "# Reproduce\n",
+ "for x in (f'yolov5{x}' for x in 'nsmlx'):\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --task speed # speed\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gogI-kwi3Tye"
+ },
+ "source": [
+ "# Profile\n",
+ "from utils.torch_utils import profile\n",
+ "\n",
+ "m1 = lambda x: x * torch.sigmoid(x)\n",
+ "m2 = torch.nn.SiLU()\n",
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BSgFCAcMbk1R"
+ },
+ "source": [
+ "# VOC\n",
+ "for b, m in zip([64, 64, 64, 32, 16], [f'yolov5{x}' for x in 'nsmlx']): # batch, model\n",
+ " !python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.VOC.yaml --project VOC --name {m} --cache"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Classification\n",
+ "for m in [*(f'yolov5{x}.pt' for x in 'nsmlx'), 'resnet50.pt', 'efficientnet_b0.pt']:\n",
+ " for d in 'mnist', 'fashion-mnist', 'cifar10', 'cifar100', 'imagenette160', 'imagenette320', 'imagenette', 'imagewoof160', 'imagewoof320', 'imagewoof':\n",
+ " !python classify/train.py --model {m} --data {d} --epochs 10 --project YOLOv5-cls --name {m}-{d}"
+ ],
+ "metadata": {
+ "id": "UWGH7H6yakVl"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "VTRwsvA9u7ln"
+ },
+ "source": [
+ "# TensorRT \n",
+ "!pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # install\n",
+ "!python export.py --weights yolov5s.pt --include engine --imgsz 640 --device 0 # export\n",
+ "!python detect.py --weights yolov5s.engine --imgsz 640 --device 0 # inference"
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
\ No newline at end of file
diff --git a/utils/__init__.py b/utils/__init__.py
new file mode 100755
index 0000000..a63c473
--- /dev/null
+++ b/utils/__init__.py
@@ -0,0 +1,36 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+utils/initialization
+"""
+
+
+def notebook_init(verbose=True):
+ # Check system software and hardware
+ print('Checking setup...')
+
+ import os
+ import shutil
+
+ from utils.general import check_requirements, emojis, is_colab
+ from utils.torch_utils import select_device # imports
+
+ check_requirements(('psutil', 'IPython'))
+ import psutil
+ from IPython import display # to display images and clear console output
+
+ if is_colab():
+ shutil.rmtree('/content/sample_data', ignore_errors=True) # remove colab /sample_data directory
+
+ # System info
+ if verbose:
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ ram = psutil.virtual_memory().total
+ total, used, free = shutil.disk_usage("/")
+ display.clear_output()
+ s = f'({os.cpu_count()} CPUs, {ram / gb:.1f} GB RAM, {(total - free) / gb:.1f}/{total / gb:.1f} GB disk)'
+ else:
+ s = ''
+
+ select_device(newline=False)
+ print(emojis(f'Setup complete ✅ {s}'))
+ return display
diff --git a/utils/activations.py b/utils/activations.py
new file mode 100755
index 0000000..084ce8c
--- /dev/null
+++ b/utils/activations.py
@@ -0,0 +1,103 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Activation functions
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class SiLU(nn.Module):
+ # SiLU activation https://arxiv.org/pdf/1606.08415.pdf
+ @staticmethod
+ def forward(x):
+ return x * torch.sigmoid(x)
+
+
+class Hardswish(nn.Module):
+ # Hard-SiLU activation
+ @staticmethod
+ def forward(x):
+ # return x * F.hardsigmoid(x) # for TorchScript and CoreML
+ return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
+
+
+class Mish(nn.Module):
+ # Mish activation https://github.com/digantamisra98/Mish
+ @staticmethod
+ def forward(x):
+ return x * F.softplus(x).tanh()
+
+
+class MemoryEfficientMish(nn.Module):
+ # Mish activation memory-efficient
+ class F(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x):
+ ctx.save_for_backward(x)
+ return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x = ctx.saved_tensors[0]
+ sx = torch.sigmoid(x)
+ fx = F.softplus(x).tanh()
+ return grad_output * (fx + x * sx * (1 - fx * fx))
+
+ def forward(self, x):
+ return self.F.apply(x)
+
+
+class FReLU(nn.Module):
+ # FReLU activation https://arxiv.org/abs/2007.11824
+ def __init__(self, c1, k=3): # ch_in, kernel
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
+ self.bn = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ return torch.max(x, self.bn(self.conv(x)))
+
+
+class AconC(nn.Module):
+ r""" ACON activation (activate or not)
+ AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
+ according to "Activate or Not: Learning Customized Activation" .
+ """
+
+ def __init__(self, c1):
+ super().__init__()
+ self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
+
+ def forward(self, x):
+ dpx = (self.p1 - self.p2) * x
+ return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
+
+
+class MetaAconC(nn.Module):
+ r""" ACON activation (activate or not)
+ MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
+ according to "Activate or Not: Learning Customized Activation" .
+ """
+
+ def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
+ super().__init__()
+ c2 = max(r, c1 // r)
+ self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
+ self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
+ # self.bn1 = nn.BatchNorm2d(c2)
+ # self.bn2 = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
+ # batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
+ # beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
+ beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
+ dpx = (self.p1 - self.p2) * x
+ return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
diff --git a/utils/augmentations.py b/utils/augmentations.py
new file mode 100755
index 0000000..30139aa
--- /dev/null
+++ b/utils/augmentations.py
@@ -0,0 +1,289 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from utils.general import LOGGER, check_version, colorstr, resample_segments, segment2box
+from utils.metrics import bbox_ioa
+
+
+class Albumentations:
+ # YOLOv5 Albumentations class (optional, only used if package is installed)
+ def __init__(self, hyp):
+ self.transform = None
+ try:
+ import albumentations as A
+ check_version(A.__version__, '1.0.3', hard=True) # version requirement
+
+ T = [
+ A.Blur(p=hyp.get('blur', 0.01)),
+ A.MedianBlur(p=hyp.get('median_blur', 0.01)),
+ A.ToGray(p=hyp.get('gray', 0.01)),
+ A.CLAHE(p=hyp.get('clahe', 0.01)),
+ A.RandomBrightnessContrast(p=hyp.get('brightness_contrast', 0.01)),
+ A.RandomGamma(p=hyp.get('random_gamma', 0.01)),
+ A.ImageCompression(quality_lower=75, p=hyp.get('image_compression', 0.01))] # transforms
+ self.transform = A.Compose(T, bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
+
+ LOGGER.info(colorstr('albumentations: ') + ', '.join(f'{x}' for x in self.transform.transforms if x.p))
+ except ImportError: # package not installed, skip
+ pass
+ except Exception as e:
+ LOGGER.info(colorstr('albumentations: ') + f'{e}')
+
+ def __call__(self, im, labels, p=1.0):
+ if self.transform and random.random() < p:
+ new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
+ im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
+ return im, labels
+
+
+def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
+ # HSV color-space augmentation
+ if hgain or sgain or vgain:
+ r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
+ hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
+ dtype = im.dtype # uint8
+
+ x = np.arange(0, 256, dtype=r.dtype)
+ lut_hue = ((x * r[0]) % 180).astype(dtype)
+ lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
+ lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
+
+ im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
+ cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
+
+
+def hist_equalize(im, clahe=True, bgr=False):
+ # Equalize histogram on BGR image 'im' with im.shape(n,m,3) and range 0-255
+ yuv = cv2.cvtColor(im, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
+ if clahe:
+ c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
+ yuv[:, :, 0] = c.apply(yuv[:, :, 0])
+ else:
+ yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
+ return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
+
+
+def replicate(im, labels):
+ # Replicate labels
+ h, w = im.shape[:2]
+ boxes = labels[:, 1:].astype(int)
+ x1, y1, x2, y2 = boxes.T
+ s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels)
+ for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices
+ x1b, y1b, x2b, y2b = boxes[i]
+ bh, bw = y2b - y1b, x2b - x1b
+ yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
+ x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
+ im[y1a:y2a, x1a:x2a] = im[y1b:y2b, x1b:x2b] # im4[ymin:ymax, xmin:xmax]
+ labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
+
+ return im, labels
+
+
+def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
+ # Resize and pad image while meeting stride-multiple constraints
+ shape = im.shape[:2] # current shape [height, width]
+ if isinstance(new_shape, int):
+ new_shape = (new_shape, new_shape)
+
+ # Scale ratio (new / old)
+ r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
+ if not scaleup: # only scale down, do not scale up (for better val mAP)
+ r = min(r, 1.0)
+
+ # Compute padding
+ ratio = r, r # width, height ratios
+ new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
+ dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
+ if auto: # minimum rectangle
+ dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
+ elif scaleFill: # stretch
+ dw, dh = 0.0, 0.0
+ new_unpad = (new_shape[1], new_shape[0])
+ ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
+
+ dw /= 2 # divide padding into 2 sides
+ dh /= 2
+
+ if shape[::-1] != new_unpad: # resize
+ im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
+ top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
+ left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
+ im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
+ return im, ratio, (dw, dh)
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ rotation_prob=1.0,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(0.1, 0.1), scale=(0.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ rotation = random.random() < rotation_prob
+ if rotation:
+ a = random.uniform(-degrees, degrees)
+ else:
+ a = 0
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
+ T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ if n:
+ use_segments = any(x.any() for x in segments)
+ new = np.zeros((n, 4))
+ if use_segments: # warp segments
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+
+ else: # warp boxes
+ xy = np.ones((n * 4, 3))
+ xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
+
+ # create new boxes
+ x = xy[:, [0, 2, 4, 6]]
+ y = xy[:, [1, 3, 5, 7]]
+ new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
+
+ # clip
+ new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
+ new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+
+ return im, targets
+
+
+def copy_paste(im, labels, segments, p=0.5):
+ # Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
+ n = len(segments)
+ if p and n:
+ h, w, c = im.shape # height, width, channels
+ im_new = np.zeros(im.shape, np.uint8)
+ for j in random.sample(range(n), k=round(p * n)):
+ l, s = labels[j], segments[j]
+ box = w - l[3], l[2], w - l[1], l[4]
+ ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
+ if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
+ labels = np.concatenate((labels, [[l[0], *box]]), 0)
+ segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
+ cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
+
+ result = cv2.bitwise_and(src1=im, src2=im_new)
+ result = cv2.flip(result, 1) # augment segments (flip left-right)
+ i = result > 0 # pixels to replace
+ # i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
+ im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
+
+ return im, labels, segments
+
+
+def cutout(im, labels, p=0.5):
+ # Applies image cutout augmentation https://arxiv.org/abs/1708.04552
+ if random.random() < p:
+ h, w = im.shape[:2]
+ scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
+ for s in scales:
+ mask_h = random.randint(1, int(h * s)) # create random masks
+ mask_w = random.randint(1, int(w * s))
+
+ # box
+ xmin = max(0, random.randint(0, w) - mask_w // 2)
+ ymin = max(0, random.randint(0, h) - mask_h // 2)
+ xmax = min(w, xmin + mask_w)
+ ymax = min(h, ymin + mask_h)
+
+ # apply random color mask
+ im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
+
+ # return unobscured labels
+ if len(labels) and s > 0.03:
+ box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
+ ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
+ labels = labels[ioa < 0.60] # remove >60% obscured labels
+
+ return labels
+
+
+def mixup(im, labels, im2, labels2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ return im, labels
+
+
+def box_candidates(box1, box2, wh_thr=2, ar_thr=100, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
+ # Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
+ w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
+ w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
+ ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
+ return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
diff --git a/utils/autoanchor.py b/utils/autoanchor.py
new file mode 100755
index 0000000..f222220
--- /dev/null
+++ b/utils/autoanchor.py
@@ -0,0 +1,170 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+AutoAnchor utils
+"""
+
+import random
+
+import numpy as np
+import torch
+import yaml
+from tqdm import tqdm
+
+from utils.general import LOGGER, colorstr
+
+PREFIX = colorstr('AutoAnchor: ')
+
+
+def check_anchor_order(m):
+ # Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
+ a = m.anchors.prod(-1).mean(-1).view(-1) # mean anchor area per output layer
+ da = a[-1] - a[0] # delta a
+ ds = m.stride[-1] - m.stride[0] # delta s
+ if da and (da.sign() != ds.sign()): # same order
+ LOGGER.info(f'{PREFIX}Reversing anchor order')
+ m.anchors[:] = m.anchors.flip(0)
+
+
+def check_anchors(dataset, model, thr=4.0, imgsz=640):
+ # Check anchor fit to data, recompute if necessary
+ m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
+ shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
+ scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
+ wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
+
+ def metric(k): # compute metric
+ r = wh[:, None] / k[None]
+ x = torch.min(r, 1 / r).min(2)[0] # ratio metric
+ best = x.max(1)[0] # best_x
+ aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
+ bpr = (best > 1 / thr).float().mean() # best possible recall
+ return bpr, aat
+
+ stride = m.stride.to(m.anchors.device).view(-1, 1, 1) # model strides
+ anchors = m.anchors.clone() * stride # current anchors
+ bpr, aat = metric(anchors.cpu().view(-1, 2))
+ s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
+ if bpr > 0.98: # threshold to recompute
+ LOGGER.info(f'{s}Current anchors are a good fit to dataset ✅')
+ else:
+ LOGGER.info(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...')
+ na = m.anchors.numel() // 2 # number of anchors
+ try:
+ anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
+ except Exception as e:
+ LOGGER.info(f'{PREFIX}ERROR: {e}')
+ new_bpr = metric(anchors)[0]
+ if new_bpr > bpr: # replace anchors
+ anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
+ m.anchors[:] = anchors.clone().view_as(m.anchors)
+ check_anchor_order(m) # must be in pixel-space (not grid-space)
+ m.anchors /= stride
+ s = f'{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)'
+ else:
+ s = f'{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)'
+ LOGGER.info(s)
+
+
+def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
+ """ Creates kmeans-evolved anchors from training dataset
+
+ Arguments:
+ dataset: path to data.yaml, or a loaded dataset
+ n: number of anchors
+ img_size: image size used for training
+ thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
+ gen: generations to evolve anchors using genetic algorithm
+ verbose: print all results
+
+ Return:
+ k: kmeans evolved anchors
+
+ Usage:
+ from utils.autoanchor import *; _ = kmean_anchors()
+ """
+ from scipy.cluster.vq import kmeans
+
+ npr = np.random
+ thr = 1 / thr
+
+ def metric(k, wh): # compute metrics
+ r = wh[:, None] / k[None]
+ x = torch.min(r, 1 / r).min(2)[0] # ratio metric
+ # x = wh_iou(wh, torch.tensor(k)) # iou metric
+ return x, x.max(1)[0] # x, best_x
+
+ def anchor_fitness(k): # mutation fitness
+ _, best = metric(torch.tensor(k, dtype=torch.float32), wh)
+ return (best * (best > thr).float()).mean() # fitness
+
+ def print_results(k, verbose=True):
+ k = k[np.argsort(k.prod(1))] # sort small to large
+ x, best = metric(k, wh0)
+ bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
+ s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
+ f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
+ f'past_thr={x[x > thr].mean():.3f}-mean: '
+ for x in k:
+ s += '%i,%i, ' % (round(x[0]), round(x[1]))
+ if verbose:
+ LOGGER.info(s[:-2])
+ return k
+
+ if isinstance(dataset, str): # *.yaml file
+ with open(dataset, errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # model dict
+ from utils.dataloaders import LoadImagesAndLabels
+ dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
+
+ # Get label wh
+ shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
+ wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
+
+ # Filter
+ i = (wh0 < 3.0).any(1).sum()
+ if i:
+ LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found: {i} of {len(wh0)} labels are < 3 pixels in size')
+ wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
+ # wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
+
+ # Kmeans init
+ try:
+ LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
+ assert n <= len(wh) # apply overdetermined constraint
+ s = wh.std(0) # sigmas for whitening
+ k = kmeans(wh / s, n, iter=30)[0] * s # points
+ assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
+ except Exception:
+ LOGGER.warning(f'{PREFIX}WARNING: switching strategies from kmeans to random init')
+ k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
+ wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
+ k = print_results(k, verbose=False)
+
+ # Plot
+ # k, d = [None] * 20, [None] * 20
+ # for i in tqdm(range(1, 21)):
+ # k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
+ # fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
+ # ax = ax.ravel()
+ # ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
+ # fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
+ # ax[0].hist(wh[wh[:, 0]<100, 0],400)
+ # ax[1].hist(wh[wh[:, 1]<100, 1],400)
+ # fig.savefig('wh.png', dpi=200)
+
+ # Evolve
+ f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
+ pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ for _ in pbar:
+ v = np.ones(sh)
+ while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
+ v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
+ kg = (k.copy() * v).clip(min=2.0)
+ fg = anchor_fitness(kg)
+ if fg > f:
+ f, k = fg, kg.copy()
+ pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
+ if verbose:
+ print_results(k, verbose)
+
+ return print_results(k)
diff --git a/utils/autobatch.py b/utils/autobatch.py
new file mode 100755
index 0000000..c231d24
--- /dev/null
+++ b/utils/autobatch.py
@@ -0,0 +1,66 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Auto-batch utils
+"""
+
+from copy import deepcopy
+
+import numpy as np
+import torch
+
+from utils.general import LOGGER, colorstr
+from utils.torch_utils import profile
+
+
+def check_train_batch_size(model, imgsz=640, amp=True):
+ # Check YOLOv5 training batch size
+ with torch.cuda.amp.autocast(amp):
+ return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
+
+
+def autobatch(model, imgsz=640, fraction=0.9, batch_size=16):
+ # Automatically estimate best batch size to use `fraction` of available CUDA memory
+ # Usage:
+ # import torch
+ # from utils.autobatch import autobatch
+ # model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False)
+ # print(autobatch(model))
+
+ # Check device
+ prefix = colorstr('AutoBatch: ')
+ LOGGER.info(f'{prefix}Computing optimal batch size for --imgsz {imgsz}')
+ device = next(model.parameters()).device # get model device
+ if device.type == 'cpu':
+ LOGGER.info(f'{prefix}CUDA not detected, using default CPU batch-size {batch_size}')
+ return batch_size
+
+ # Inspect CUDA memory
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ d = str(device).upper() # 'CUDA:0'
+ properties = torch.cuda.get_device_properties(device) # device properties
+ t = properties.total_memory / gb # GiB total
+ r = torch.cuda.memory_reserved(device) / gb # GiB reserved
+ a = torch.cuda.memory_allocated(device) / gb # GiB allocated
+ f = t - (r + a) # GiB free
+ LOGGER.info(f'{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
+
+ # Profile batch sizes
+ batch_sizes = [1, 2, 4, 8, 16]
+ try:
+ img = [torch.zeros(b, 3, imgsz, imgsz) for b in batch_sizes]
+ results = profile(img, model, n=3, device=device)
+ except Exception as e:
+ LOGGER.warning(f'{prefix}{e}')
+
+ # Fit a solution
+ y = [x[2] for x in results if x] # memory [2]
+ p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
+ b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
+ if None in results: # some sizes failed
+ i = results.index(None) # first fail index
+ if b >= batch_sizes[i]: # y intercept above failure point
+ b = batch_sizes[max(i - 1, 0)] # select prior safe point
+
+ fraction = np.polyval(p, b) / t # actual fraction predicted
+ LOGGER.info(f'{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%) ✅')
+ return b
diff --git a/utils/aws/__init__.py b/utils/aws/__init__.py
new file mode 100755
index 0000000..e69de29
diff --git a/utils/aws/mime.sh b/utils/aws/mime.sh
new file mode 100755
index 0000000..c319a83
--- /dev/null
+++ b/utils/aws/mime.sh
@@ -0,0 +1,26 @@
+# AWS EC2 instance startup 'MIME' script https://aws.amazon.com/premiumsupport/knowledge-center/execute-user-data-ec2/
+# This script will run on every instance restart, not only on first start
+# --- DO NOT COPY ABOVE COMMENTS WHEN PASTING INTO USERDATA ---
+
+Content-Type: multipart/mixed; boundary="//"
+MIME-Version: 1.0
+
+--//
+Content-Type: text/cloud-config; charset="us-ascii"
+MIME-Version: 1.0
+Content-Transfer-Encoding: 7bit
+Content-Disposition: attachment; filename="cloud-config.txt"
+
+#cloud-config
+cloud_final_modules:
+- [scripts-user, always]
+
+--//
+Content-Type: text/x-shellscript; charset="us-ascii"
+MIME-Version: 1.0
+Content-Transfer-Encoding: 7bit
+Content-Disposition: attachment; filename="userdata.txt"
+
+#!/bin/bash
+# --- paste contents of userdata.sh here ---
+--//
diff --git a/utils/aws/resume.py b/utils/aws/resume.py
new file mode 100755
index 0000000..b21731c
--- /dev/null
+++ b/utils/aws/resume.py
@@ -0,0 +1,40 @@
+# Resume all interrupted trainings in yolov5/ dir including DDP trainings
+# Usage: $ python utils/aws/resume.py
+
+import os
+import sys
+from pathlib import Path
+
+import torch
+import yaml
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[2] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+port = 0 # --master_port
+path = Path('').resolve()
+for last in path.rglob('*/**/last.pt'):
+ ckpt = torch.load(last)
+ if ckpt['optimizer'] is None:
+ continue
+
+ # Load opt.yaml
+ with open(last.parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = yaml.safe_load(f)
+
+ # Get device count
+ d = opt['device'].split(',') # devices
+ nd = len(d) # number of devices
+ ddp = nd > 1 or (nd == 0 and torch.cuda.device_count() > 1) # distributed data parallel
+
+ if ddp: # multi-GPU
+ port += 1
+ cmd = f'python -m torch.distributed.run --nproc_per_node {nd} --master_port {port} train.py --resume {last}'
+ else: # single-GPU
+ cmd = f'python train.py --resume {last}'
+
+ cmd += ' > /dev/null 2>&1 &' # redirect output to dev/null and run in daemon thread
+ print(cmd)
+ os.system(cmd)
diff --git a/utils/aws/userdata.sh b/utils/aws/userdata.sh
new file mode 100755
index 0000000..5fc1332
--- /dev/null
+++ b/utils/aws/userdata.sh
@@ -0,0 +1,27 @@
+#!/bin/bash
+# AWS EC2 instance startup script https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/user-data.html
+# This script will run only once on first instance start (for a re-start script see mime.sh)
+# /home/ubuntu (ubuntu) or /home/ec2-user (amazon-linux) is working dir
+# Use >300 GB SSD
+
+cd home/ubuntu
+if [ ! -d yolov5 ]; then
+ echo "Running first-time script." # install dependencies, download COCO, pull Docker
+ git clone https://github.com/ultralytics/yolov5 -b master && sudo chmod -R 777 yolov5
+ cd yolov5
+ bash data/scripts/get_coco.sh && echo "COCO done." &
+ sudo docker pull ultralytics/yolov5:latest && echo "Docker done." &
+ python -m pip install --upgrade pip && pip install -r requirements.txt && python detect.py && echo "Requirements done." &
+ wait && echo "All tasks done." # finish background tasks
+else
+ echo "Running re-start script." # resume interrupted runs
+ i=0
+ list=$(sudo docker ps -qa) # container list i.e. $'one\ntwo\nthree\nfour'
+ while IFS= read -r id; do
+ ((i++))
+ echo "restarting container $i: $id"
+ sudo docker start $id
+ # sudo docker exec -it $id python train.py --resume # single-GPU
+ sudo docker exec -d $id python utils/aws/resume.py # multi-scenario
+ done <<<"$list"
+fi
diff --git a/utils/benchmarks.py b/utils/benchmarks.py
new file mode 100755
index 0000000..d412653
--- /dev/null
+++ b/utils/benchmarks.py
@@ -0,0 +1,157 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Run YOLOv5 benchmarks on all supported export formats
+
+Format | `export.py --include` | Model
+--- | --- | ---
+PyTorch | - | yolov5s.pt
+TorchScript | `torchscript` | yolov5s.torchscript
+ONNX | `onnx` | yolov5s.onnx
+OpenVINO | `openvino` | yolov5s_openvino_model/
+TensorRT | `engine` | yolov5s.engine
+CoreML | `coreml` | yolov5s.mlmodel
+TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
+TensorFlow GraphDef | `pb` | yolov5s.pb
+TensorFlow Lite | `tflite` | yolov5s.tflite
+TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
+TensorFlow.js | `tfjs` | yolov5s_web_model/
+
+Requirements:
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
+ $ pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # TensorRT
+
+Usage:
+ $ python utils/benchmarks.py --weights yolov5s.pt --img 640
+"""
+
+import argparse
+import platform
+import sys
+import time
+from pathlib import Path
+
+import pandas as pd
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import export
+import val
+from utils import notebook_init
+from utils.general import LOGGER, check_yaml, file_size, print_args
+from utils.torch_utils import select_device
+
+
+def run(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=640, # inference size (pixels)
+ batch_size=1, # batch size
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half=False, # use FP16 half-precision inference
+ test=False, # test exports only
+ pt_only=False, # test PyTorch only
+ hard_fail=False, # throw error on benchmark failure
+):
+ y, t = [], time.time()
+ device = select_device(device)
+ for i, (name, f, suffix, cpu, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, CPU, GPU)
+ try:
+ assert i not in (9, 10), 'inference not supported' # Edge TPU and TF.js are unsupported
+ assert i != 5 or platform.system() == 'Darwin', 'inference only supported on macOS>=10.13' # CoreML
+ if 'cpu' in device.type:
+ assert cpu, 'inference not supported on CPU'
+ if 'cuda' in device.type:
+ assert gpu, 'inference not supported on GPU'
+
+ # Export
+ if f == '-':
+ w = weights # PyTorch format
+ else:
+ w = export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # all others
+ assert suffix in str(w), 'export failed'
+
+ # Validate
+ result = val.run(data, w, batch_size, imgsz, plots=False, device=device, task='benchmark', half=half)
+ metrics = result[0] # metrics (mp, mr, map50, map, *losses(box, obj, cls))
+ speeds = result[2] # times (preprocess, inference, postprocess)
+ y.append([name, round(file_size(w), 1), round(metrics[3], 4), round(speeds[1], 2)]) # MB, mAP, t_inference
+ except Exception as e:
+ if hard_fail:
+ assert type(e) is AssertionError, f'Benchmark --hard-fail for {name}: {e}'
+ LOGGER.warning(f'WARNING: Benchmark failure for {name}: {e}')
+ y.append([name, None, None, None]) # mAP, t_inference
+ if pt_only and i == 0:
+ break # break after PyTorch
+
+ # Print results
+ LOGGER.info('\n')
+ parse_opt()
+ notebook_init() # print system info
+ c = ['Format', 'Size (MB)', 'mAP@0.5:0.95', 'Inference time (ms)'] if map else ['Format', 'Export', '', '']
+ py = pd.DataFrame(y, columns=c)
+ LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
+ LOGGER.info(str(py if map else py.iloc[:, :2]))
+ return py
+
+
+def test(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=640, # inference size (pixels)
+ batch_size=1, # batch size
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half=False, # use FP16 half-precision inference
+ test=False, # test exports only
+ pt_only=False, # test PyTorch only
+ hard_fail=False, # throw error on benchmark failure
+):
+ y, t = [], time.time()
+ device = select_device(device)
+ for i, (name, f, suffix, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, gpu-capable)
+ try:
+ w = weights if f == '-' else \
+ export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # weights
+ assert suffix in str(w), 'export failed'
+ y.append([name, True])
+ except Exception:
+ y.append([name, False]) # mAP, t_inference
+
+ # Print results
+ LOGGER.info('\n')
+ parse_opt()
+ notebook_init() # print system info
+ py = pd.DataFrame(y, columns=['Format', 'Export'])
+ LOGGER.info(f'\nExports complete ({time.time() - t:.2f}s)')
+ LOGGER.info(str(py))
+ return py
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--test', action='store_true', help='test exports only')
+ parser.add_argument('--pt-only', action='store_true', help='test PyTorch only')
+ parser.add_argument('--hard-fail', action='store_true', help='throw error on benchmark failure')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ test(**vars(opt)) if opt.test else run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/utils/callbacks.py b/utils/callbacks.py
new file mode 100755
index 0000000..463ede7
--- /dev/null
+++ b/utils/callbacks.py
@@ -0,0 +1,72 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Callback utils
+"""
+
+
+class Callbacks:
+ """"
+ Handles all registered callbacks for YOLOv5 Hooks
+ """
+
+ def __init__(self):
+ # Define the available callbacks
+ self._callbacks = {
+ 'on_pretrain_routine_start': [],
+ 'on_pretrain_routine_end': [],
+ 'on_train_start': [],
+ 'on_train_epoch_start': [],
+ 'on_train_batch_start': [],
+ 'optimizer_step': [],
+ 'on_before_zero_grad': [],
+ 'on_train_batch_end': [],
+ 'on_train_epoch_end': [],
+ 'on_val_start': [],
+ 'on_val_batch_start': [],
+ 'on_val_image_end': [],
+ 'on_val_batch_end': [],
+ 'on_val_end': [],
+ 'on_fit_epoch_end': [], # fit = train + val
+ 'on_model_save': [],
+ 'after_model_save': [],
+ 'on_train_end': [],
+ 'on_params_update': [],
+ 'teardown': [],}
+ self.stop_training = False # set True to interrupt training
+
+ def register_action(self, hook, name='', callback=None):
+ """
+ Register a new action to a callback hook
+
+ Args:
+ hook: The callback hook name to register the action to
+ name: The name of the action for later reference
+ callback: The callback to fire
+ """
+ assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
+ assert callable(callback), f"callback '{callback}' is not callable"
+ self._callbacks[hook].append({'name': name, 'callback': callback})
+
+ def get_registered_actions(self, hook=None):
+ """"
+ Returns all the registered actions by callback hook
+
+ Args:
+ hook: The name of the hook to check, defaults to all
+ """
+ return self._callbacks[hook] if hook else self._callbacks
+
+ def run(self, hook, *args, **kwargs):
+ """
+ Loop through the registered actions and fire all callbacks
+
+ Args:
+ hook: The name of the hook to check, defaults to all
+ args: Arguments to receive from YOLOv5
+ kwargs: Keyword Arguments to receive from YOLOv5
+ """
+
+ assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
+
+ for logger in self._callbacks[hook]:
+ logger['callback'](*args, **kwargs)
diff --git a/utils/dataloaders.py b/utils/dataloaders.py
new file mode 100755
index 0000000..444080a
--- /dev/null
+++ b/utils/dataloaders.py
@@ -0,0 +1,1097 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Dataloaders and dataset utils
+"""
+
+import contextlib
+import glob
+import hashlib
+import json
+import math
+import os
+import random
+import shutil
+import time
+from itertools import repeat
+from multiprocessing.pool import Pool, ThreadPool
+from pathlib import Path
+from threading import Thread
+from urllib.parse import urlparse
+from zipfile import ZipFile
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+import yaml
+from PIL import ExifTags, Image, ImageOps
+from torch.utils.data import DataLoader, Dataset, dataloader, distributed
+from tqdm import tqdm
+
+from utils.augmentations import Albumentations, augment_hsv, copy_paste, letterbox, mixup, random_perspective
+from utils.general import (DATASETS_DIR, LOGGER, NUM_THREADS, check_dataset, check_requirements, check_yaml, clean_str,
+ cv2, is_colab, is_kaggle, segments2boxes, xyn2xy, xywh2xyxy, xywhn2xyxy, xyxy2xywhn)
+from utils.torch_utils import torch_distributed_zero_first
+
+# Parameters
+HELP_URL = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
+IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp' # include image suffixes
+VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes
+BAR_FORMAT = '{l_bar}{bar:10}{r_bar}{bar:-10b}' # tqdm bar format
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+
+# Get orientation exif tag
+for orientation in ExifTags.TAGS.keys():
+ if ExifTags.TAGS[orientation] == 'Orientation':
+ break
+
+
+def get_hash(paths):
+ # Returns a single hash value of a list of paths (files or dirs)
+ size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
+ h = hashlib.md5(str(size).encode()) # hash sizes
+ h.update(''.join(paths).encode()) # hash paths
+ return h.hexdigest() # return hash
+
+
+def exif_size(img):
+ # Returns exif-corrected PIL size
+ s = img.size # (width, height)
+ with contextlib.suppress(Exception):
+ rotation = dict(img._getexif().items())[orientation]
+ if rotation in [6, 8]: # rotation 270 or 90
+ s = (s[1], s[0])
+ return s
+
+
+def exif_transpose(image):
+ """
+ Transpose a PIL image accordingly if it has an EXIF Orientation tag.
+ Inplace version of https://github.com/python-pillow/Pillow/blob/master/src/PIL/ImageOps.py exif_transpose()
+
+ :param image: The image to transpose.
+ :return: An image.
+ """
+ exif = image.getexif()
+ orientation = exif.get(0x0112, 1) # default 1
+ if orientation > 1:
+ method = {
+ 2: Image.FLIP_LEFT_RIGHT,
+ 3: Image.ROTATE_180,
+ 4: Image.FLIP_TOP_BOTTOM,
+ 5: Image.TRANSPOSE,
+ 6: Image.ROTATE_270,
+ 7: Image.TRANSVERSE,
+ 8: Image.ROTATE_90,}.get(orientation)
+ if method is not None:
+ image = image.transpose(method)
+ del exif[0x0112]
+ image.info["exif"] = exif.tobytes()
+ return image
+
+
+def seed_worker(worker_id):
+ # Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloader
+ worker_seed = torch.initial_seed() % 2 ** 32
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False):
+ if rect and shuffle:
+ LOGGER.warning('WARNING: --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabels(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(0)
+ return loader(dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=False,
+ collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ drop_last=True,
+ ), dataset
+
+
+class InfiniteDataLoader(dataloader.DataLoader):
+ """ Dataloader that reuses workers
+
+ Uses same syntax as vanilla DataLoader
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
+ self.iterator = super().__iter__()
+
+ def __len__(self):
+ return len(self.batch_sampler.sampler)
+
+ def __iter__(self):
+ for _ in range(len(self)):
+ yield next(self.iterator)
+
+
+class _RepeatSampler:
+ """ Sampler that repeats forever
+
+ Args:
+ sampler (Sampler)
+ """
+
+ def __init__(self, sampler):
+ self.sampler = sampler
+
+ def __iter__(self):
+ while True:
+ yield from iter(self.sampler)
+
+
+class LoadImages:
+ # YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
+ def __init__(self, path, img_size=640, stride=32, auto=True):
+ files = []
+ for p in sorted(path) if isinstance(path, (list, tuple)) else [path]:
+ p = str(Path(p).resolve())
+ if '*' in p:
+ files.extend(sorted(glob.glob(p, recursive=True))) # glob
+ elif os.path.isdir(p):
+ files.extend(sorted(glob.glob(os.path.join(p, '*.*')))) # dir
+ elif os.path.isfile(p):
+ files.append(p) # files
+ else:
+ raise FileNotFoundError(f'{p} does not exist')
+
+ images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
+ videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
+ ni, nv = len(images), len(videos)
+
+ self.img_size = img_size
+ self.stride = stride
+ self.files = images + videos
+ self.nf = ni + nv # number of files
+ self.video_flag = [False] * ni + [True] * nv
+ self.mode = 'image'
+ self.auto = auto
+ if any(videos):
+ self.new_video(videos[0]) # new video
+ else:
+ self.cap = None
+ assert self.nf > 0, f'No images or videos found in {p}. ' \
+ f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'
+
+ def __iter__(self):
+ self.count = 0
+ return self
+
+ def __next__(self):
+ if self.count == self.nf:
+ raise StopIteration
+ path = self.files[self.count]
+
+ if self.video_flag[self.count]:
+ # Read video
+ self.mode = 'video'
+ ret_val, img0 = self.cap.read()
+ while not ret_val:
+ self.count += 1
+ self.cap.release()
+ if self.count == self.nf: # last video
+ raise StopIteration
+ path = self.files[self.count]
+ self.new_video(path)
+ ret_val, img0 = self.cap.read()
+
+ self.frame += 1
+ s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '
+
+ else:
+ # Read image
+ self.count += 1
+ img0 = cv2.imread(path) # BGR
+ assert img0 is not None, f'Image Not Found {path}'
+ s = f'image {self.count}/{self.nf} {path}: '
+
+ # Padded resize
+ img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0]
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return path, img, img0, self.cap, s
+
+ def new_video(self, path):
+ self.frame = 0
+ self.cap = cv2.VideoCapture(path)
+ self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
+
+ def __len__(self):
+ return self.nf # number of files
+
+
+class LoadWebcam: # for inference
+ # YOLOv5 local webcam dataloader, i.e. `python detect.py --source 0`
+ def __init__(self, pipe='0', img_size=640, stride=32):
+ self.img_size = img_size
+ self.stride = stride
+ self.pipe = eval(pipe) if pipe.isnumeric() else pipe
+ self.cap = cv2.VideoCapture(self.pipe) # video capture object
+ self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
+
+ def __iter__(self):
+ self.count = -1
+ return self
+
+ def __next__(self):
+ self.count += 1
+ if cv2.waitKey(1) == ord('q'): # q to quit
+ self.cap.release()
+ cv2.destroyAllWindows()
+ raise StopIteration
+
+ # Read frame
+ ret_val, img0 = self.cap.read()
+ img0 = cv2.flip(img0, 1) # flip left-right
+
+ # Print
+ assert ret_val, f'Camera Error {self.pipe}'
+ img_path = 'webcam.jpg'
+ s = f'webcam {self.count}: '
+
+ # Padded resize
+ img = letterbox(img0, self.img_size, stride=self.stride)[0]
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return img_path, img, img0, None, s
+
+ def __len__(self):
+ return 0
+
+
+class LoadStreams:
+ # YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
+ def __init__(self, sources='streams.txt', img_size=640, stride=32, auto=True):
+ self.mode = 'stream'
+ self.img_size = img_size
+ self.stride = stride
+
+ if os.path.isfile(sources):
+ with open(sources) as f:
+ sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
+ else:
+ sources = [sources]
+
+ n = len(sources)
+ self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
+ self.sources = [clean_str(x) for x in sources] # clean source names for later
+ self.auto = auto
+ for i, s in enumerate(sources): # index, source
+ # Start thread to read frames from video stream
+ st = f'{i + 1}/{n}: {s}... '
+ if urlparse(s).hostname in ('www.youtube.com', 'youtube.com', 'youtu.be'): # if source is YouTube video
+ check_requirements(('pafy', 'youtube_dl==2020.12.2'))
+ import pafy
+ s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
+ s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
+ if s == 0:
+ assert not is_colab(), '--source 0 webcam unsupported on Colab. Rerun command in a local environment.'
+ assert not is_kaggle(), '--source 0 webcam unsupported on Kaggle. Rerun command in a local environment.'
+ cap = cv2.VideoCapture(s)
+ assert cap.isOpened(), f'{st}Failed to open {s}'
+ w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = cap.get(cv2.CAP_PROP_FPS) # warning: may return 0 or nan
+ self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
+ self.fps[i] = max((fps if math.isfinite(fps) else 0) % 100, 0) or 30 # 30 FPS fallback
+
+ _, self.imgs[i] = cap.read() # guarantee first frame
+ self.threads[i] = Thread(target=self.update, args=([i, cap, s]), daemon=True)
+ LOGGER.info(f"{st} Success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
+ self.threads[i].start()
+ LOGGER.info('') # newline
+
+ # check for common shapes
+ s = np.stack([letterbox(x, self.img_size, stride=self.stride, auto=self.auto)[0].shape for x in self.imgs])
+ self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
+ if not self.rect:
+ LOGGER.warning('WARNING: Stream shapes differ. For optimal performance supply similarly-shaped streams.')
+
+ def update(self, i, cap, stream):
+ # Read stream `i` frames in daemon thread
+ n, f, read = 0, self.frames[i], 1 # frame number, frame array, inference every 'read' frame
+ while cap.isOpened() and n < f:
+ n += 1
+ # _, self.imgs[index] = cap.read()
+ cap.grab()
+ if n % read == 0:
+ success, im = cap.retrieve()
+ if success:
+ self.imgs[i] = im
+ else:
+ LOGGER.warning('WARNING: Video stream unresponsive, please check your IP camera connection.')
+ self.imgs[i] = np.zeros_like(self.imgs[i])
+ cap.open(stream) # re-open stream if signal was lost
+ time.sleep(0.0) # wait time
+
+ def __iter__(self):
+ self.count = -1
+ return self
+
+ def __next__(self):
+ self.count += 1
+ if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
+ cv2.destroyAllWindows()
+ raise StopIteration
+
+ # Letterbox
+ img0 = self.imgs.copy()
+ img = [letterbox(x, self.img_size, stride=self.stride, auto=self.rect and self.auto)[0] for x in img0]
+
+ # Stack
+ img = np.stack(img, 0)
+
+ # Convert
+ img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
+ img = np.ascontiguousarray(img)
+
+ return self.sources, img, img0, None, ''
+
+ def __len__(self):
+ return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
+
+
+def img2label_paths(img_paths):
+ # Define label paths as a function of image paths
+ sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
+ return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
+
+
+class LoadImagesAndLabels(Dataset):
+ # YOLOv5 train_loader/val_loader, loads images and labels for training and validation
+ cache_version = 0.6 # dataset labels *.cache version
+ rand_interp_methods = [cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4]
+
+ def __init__(self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0.0,
+ prefix=''):
+ self.img_size = img_size
+ self.augment = augment
+ self.hyp = hyp
+ self.image_weights = image_weights
+ self.rect = False if image_weights else rect
+ self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
+ self.mosaic_border = [-img_size // 2, -img_size // 2]
+ self.stride = stride
+ self.path = path
+ self.albumentations = Albumentations(hyp) if augment else None
+
+ try:
+ f = [] # image files
+ for p in path if isinstance(path, list) else [path]:
+ p = Path(p) # os-agnostic
+ if p.is_dir(): # dir
+ f += glob.glob(str(p / '**' / '*.*'), recursive=True)
+ # f = list(p.rglob('*.*')) # pathlib
+ elif p.is_file(): # file
+ with open(p) as t:
+ t = t.read().strip().splitlines()
+ parent = str(p.parent) + os.sep
+ f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
+ # f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
+ else:
+ raise FileNotFoundError(f'{prefix}{p} does not exist')
+ self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
+ # self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
+ assert self.im_files, f'{prefix}No images found'
+ except Exception as e:
+ raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {HELP_URL}')
+
+ # Check cache
+ self.label_files = img2label_paths(self.im_files) # labels
+ cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
+ try:
+ cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
+ assert cache['version'] == self.cache_version # matches current version
+ assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
+ except Exception:
+ cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops
+
+ # Display cache
+ nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
+ if exists and LOCAL_RANK in {-1, 0}:
+ d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupt"
+ tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=BAR_FORMAT) # display cache results
+ if cache['msgs']:
+ LOGGER.info('\n'.join(cache['msgs'])) # display warnings
+ assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {HELP_URL}'
+
+ # Read cache
+ [cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
+ labels, shapes, self.segments = zip(*cache.values())
+ self.labels = list(labels)
+ self.shapes = np.array(shapes)
+ self.im_files = list(cache.keys()) # update
+ self.label_files = img2label_paths(cache.keys()) # update
+ n = len(shapes) # number of images
+ bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
+ nb = bi[-1] + 1 # number of batches
+ self.batch = bi # batch index of image
+ self.n = n
+ self.indices = range(n)
+
+ # Update labels
+ include_class = [] # filter labels to include only these classes (optional)
+ include_class_array = np.array(include_class).reshape(1, -1)
+ for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
+ if include_class:
+ j = (label[:, 0:1] == include_class_array).any(1)
+ self.labels[i] = label[j]
+ if segment:
+ self.segments[i] = segment[j]
+ if single_cls: # single-class training, merge all classes into 0
+ self.labels[i][:, 0] = 0
+ if segment:
+ self.segments[i][:, 0] = 0
+
+ # Rectangular Training
+ if self.rect:
+ # Sort by aspect ratio
+ s = self.shapes # wh
+ ar = s[:, 1] / s[:, 0] # aspect ratio
+ irect = ar.argsort()
+ self.im_files = [self.im_files[i] for i in irect]
+ self.label_files = [self.label_files[i] for i in irect]
+ self.labels = [self.labels[i] for i in irect]
+ self.shapes = s[irect] # wh
+ ar = ar[irect]
+
+ # Set training image shapes
+ shapes = [[1, 1]] * nb
+ for i in range(nb):
+ ari = ar[bi == i]
+ mini, maxi = ari.min(), ari.max()
+ if maxi < 1:
+ shapes[i] = [maxi, 1]
+ elif mini > 1:
+ shapes[i] = [1, 1 / mini]
+
+ self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
+
+ # Cache images into RAM/disk for faster training (WARNING: large datasets may exceed system resources)
+ self.ims = [None] * n
+ self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
+ if cache_images:
+ gb = 0 # Gigabytes of cached images
+ self.im_hw0, self.im_hw = [None] * n, [None] * n
+ fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
+ results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
+ pbar = tqdm(enumerate(results), total=n, bar_format=BAR_FORMAT, disable=LOCAL_RANK > 0)
+ for i, x in pbar:
+ if cache_images == 'disk':
+ gb += self.npy_files[i].stat().st_size
+ else: # 'ram'
+ self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
+ gb += self.ims[i].nbytes
+ pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB {cache_images})'
+ pbar.close()
+
+ def cache_labels(self, path=Path('./labels.cache'), prefix=''):
+ # Cache dataset labels, check images and read shapes
+ x = {} # dict
+ nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
+ desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..."
+ with Pool(NUM_THREADS) as pool:
+ pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
+ desc=desc,
+ total=len(self.im_files),
+ bar_format=BAR_FORMAT)
+ for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
+ nm += nm_f
+ nf += nf_f
+ ne += ne_f
+ nc += nc_f
+ if im_file:
+ x[im_file] = [lb, shape, segments]
+ if msg:
+ msgs.append(msg)
+ pbar.desc = f"{desc}{nf} found, {nm} missing, {ne} empty, {nc} corrupt"
+
+ pbar.close()
+ if msgs:
+ LOGGER.info('\n'.join(msgs))
+ if nf == 0:
+ LOGGER.warning(f'{prefix}WARNING: No labels found in {path}. See {HELP_URL}')
+ x['hash'] = get_hash(self.label_files + self.im_files)
+ x['results'] = nf, nm, ne, nc, len(self.im_files)
+ x['msgs'] = msgs # warnings
+ x['version'] = self.cache_version # cache version
+ try:
+ np.save(path, x) # save cache for next time
+ path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
+ LOGGER.info(f'{prefix}New cache created: {path}')
+ except Exception as e:
+ LOGGER.warning(f'{prefix}WARNING: Cache directory {path.parent} is not writeable: {e}') # not writeable
+ return x
+
+ def __len__(self):
+ return len(self.im_files)
+
+ # def __iter__(self):
+ # self.count = -1
+ # print('ran dataset iter')
+ # #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
+ # return self
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ if mosaic:
+ # Load mosaic
+ img, labels = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels = mixup(img, labels, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels = random_perspective(img,
+ labels,
+ degrees=hyp['degrees'],
+ rotation_prob=hyp['rotation_prob'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
+
+ if self.augment:
+ # Albumentations
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+
+ # Cutouts
+ # labels = cutout(img, labels, p=0.5)
+ # nl = len(labels) # update after cutout
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return torch.from_numpy(img), labels_out, self.im_files[index], shapes
+
+ def load_image(self, i):
+ # Loads 1 image from dataset index 'i', returns (im, original hw, resized hw)
+ im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i],
+ if im is None: # not cached in RAM
+ if fn.exists(): # load npy
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ assert im is not None, f'Image Not Found {f}'
+ h0, w0 = im.shape[:2] # orig hw
+ r = self.img_size / max(h0, w0) # ratio
+ if r != 1: # if sizes are not equal
+ interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
+ im = cv2.resize(im, (int(w0 * r), int(h0 * r)), interpolation=interp)
+ return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
+ return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
+
+ def cache_images_to_disk(self, i):
+ # Saves an image as an *.npy file for faster loading
+ f = self.npy_files[i]
+ if not f.exists():
+ np.save(f.as_posix(), cv2.imread(self.im_files[i]))
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ random.shuffle(indices)
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ # Labels
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ rotation_prob=self.hyp['rotation_prob'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+
+ return img4, labels4
+
+ def load_mosaic9(self, index):
+ # YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
+ labels9, segments9 = [], []
+ s = self.img_size
+ indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
+ random.shuffle(indices)
+ hp, wp = -1, -1 # height, width previous
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img9
+ if i == 0: # center
+ img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ h0, w0 = h, w
+ c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
+ elif i == 1: # top
+ c = s, s - h, s + w, s
+ elif i == 2: # top right
+ c = s + wp, s - h, s + wp + w, s
+ elif i == 3: # right
+ c = s + w0, s, s + w0 + w, s + h
+ elif i == 4: # bottom right
+ c = s + w0, s + hp, s + w0 + w, s + hp + h
+ elif i == 5: # bottom
+ c = s + w0 - w, s + h0, s + w0, s + h0 + h
+ elif i == 6: # bottom left
+ c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
+ elif i == 7: # left
+ c = s - w, s + h0 - h, s, s + h0
+ elif i == 8: # top left
+ c = s - w, s + h0 - hp - h, s, s + h0 - hp
+
+ padx, pady = c[:2]
+ x1, y1, x2, y2 = (max(x, 0) for x in c) # allocate coords
+
+ # Labels
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
+ labels9.append(labels)
+ segments9.extend(segments)
+
+ # Image
+ img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
+ hp, wp = h, w # height, width previous
+
+ # Offset
+ yc, xc = (int(random.uniform(0, s)) for _ in self.mosaic_border) # mosaic center x, y
+ img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
+
+ # Concat/clip labels
+ labels9 = np.concatenate(labels9, 0)
+ labels9[:, [1, 3]] -= xc
+ labels9[:, [2, 4]] -= yc
+ c = np.array([xc, yc]) # centers
+ segments9 = [x - c for x in segments9]
+
+ for x in (labels9[:, 1:], *segments9):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img9, labels9 = replicate(img9, labels9) # replicate
+
+ # Augment
+ img9, labels9 = random_perspective(img9,
+ labels9,
+ segments9,
+ degrees=self.hyp['degrees'],
+ rotation_prob=self.hyp['rotation_prob'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+
+ return img9, labels9
+
+ @staticmethod
+ def collate_fn(batch):
+ im, label, path, shapes = zip(*batch) # transposed
+ for i, lb in enumerate(label):
+ lb[:, 0] = i # add target image index for build_targets()
+ return torch.stack(im, 0), torch.cat(label, 0), path, shapes
+
+ @staticmethod
+ def collate_fn4(batch):
+ img, label, path, shapes = zip(*batch) # transposed
+ n = len(shapes) // 4
+ im4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
+
+ ho = torch.tensor([[0.0, 0, 0, 1, 0, 0]])
+ wo = torch.tensor([[0.0, 0, 1, 0, 0, 0]])
+ s = torch.tensor([[1, 1, 0.5, 0.5, 0.5, 0.5]]) # scale
+ for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
+ i *= 4
+ if random.random() < 0.5:
+ im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2.0, mode='bilinear',
+ align_corners=False)[0].type(img[i].type())
+ lb = label[i]
+ else:
+ im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
+ lb = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
+ im4.append(im)
+ label4.append(lb)
+
+ for i, lb in enumerate(label4):
+ lb[:, 0] = i # add target image index for build_targets()
+
+ return torch.stack(im4, 0), torch.cat(label4, 0), path4, shapes4
+
+
+# Ancillary functions --------------------------------------------------------------------------------------------------
+def flatten_recursive(path=DATASETS_DIR / 'coco128'):
+ # Flatten a recursive directory by bringing all files to top level
+ new_path = Path(f'{str(path)}_flat')
+ if os.path.exists(new_path):
+ shutil.rmtree(new_path) # delete output folder
+ os.makedirs(new_path) # make new output folder
+ for file in tqdm(glob.glob(f'{str(Path(path))}/**/*.*', recursive=True)):
+ shutil.copyfile(file, new_path / Path(file).name)
+
+
+def extract_boxes(path=DATASETS_DIR / 'coco128'): # from utils.dataloaders import *; extract_boxes()
+ # Convert detection dataset into classification dataset, with one directory per class
+ path = Path(path) # images dir
+ shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None # remove existing
+ files = list(path.rglob('*.*'))
+ n = len(files) # number of files
+ for im_file in tqdm(files, total=n):
+ if im_file.suffix[1:] in IMG_FORMATS:
+ # image
+ im = cv2.imread(str(im_file))[..., ::-1] # BGR to RGB
+ h, w = im.shape[:2]
+
+ # labels
+ lb_file = Path(img2label_paths([str(im_file)])[0])
+ if Path(lb_file).exists():
+ with open(lb_file) as f:
+ lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # labels
+
+ for j, x in enumerate(lb):
+ c = int(x[0]) # class
+ f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
+ if not f.parent.is_dir():
+ f.parent.mkdir(parents=True)
+
+ b = x[1:] * [w, h, w, h] # box
+ # b[2:] = b[2:].max() # rectangle to square
+ b[2:] = b[2:] * 1.2 + 3 # pad
+ b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int)
+
+ b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image
+ b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
+ assert cv2.imwrite(str(f), im[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
+
+
+def autosplit(path=DATASETS_DIR / 'coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
+ """ Autosplit a dataset into train/val/test splits and save path/autosplit_*.txt files
+ Usage: from utils.dataloaders import *; autosplit()
+ Arguments
+ path: Path to images directory
+ weights: Train, val, test weights (list, tuple)
+ annotated_only: Only use images with an annotated txt file
+ """
+ path = Path(path) # images dir
+ files = sorted(x for x in path.rglob('*.*') if x.suffix[1:].lower() in IMG_FORMATS) # image files only
+ n = len(files) # number of files
+ random.seed(0) # for reproducibility
+ indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
+
+ txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
+ [(path.parent / x).unlink(missing_ok=True) for x in txt] # remove existing
+
+ print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
+ for i, img in tqdm(zip(indices, files), total=n):
+ if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
+ with open(path.parent / txt[i], 'a') as f:
+ f.write(f'./{img.relative_to(path.parent).as_posix()}' + '\n') # add image to txt file
+
+
+def verify_image_label(args):
+ # Verify one image-label pair
+ im_file, lb_file, prefix = args
+ nm, nf, ne, nc, msg, segments = 0, 0, 0, 0, '', [] # number (missing, found, empty, corrupt), message, segments
+ try:
+ # verify images
+ im = Image.open(im_file)
+ im.verify() # PIL verify
+ shape = exif_size(im) # image size
+ assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
+ assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
+ if im.format.lower() in ('jpg', 'jpeg'):
+ with open(im_file, 'rb') as f:
+ f.seek(-2, 2)
+ if f.read() != b'\xff\xd9': # corrupt JPEG
+ ImageOps.exif_transpose(Image.open(im_file)).save(im_file, 'JPEG', subsampling=0, quality=100)
+ msg = f'{prefix}WARNING: {im_file}: corrupt JPEG restored and saved'
+
+ # verify labels
+ if os.path.isfile(lb_file):
+ nf = 1 # label found
+ with open(lb_file) as f:
+ lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
+ if any(len(x) > 6 for x in lb): # is segment
+ classes = np.array([x[0] for x in lb], dtype=np.float32)
+ segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in lb] # (cls, xy1...)
+ lb = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
+ lb = np.array(lb, dtype=np.float32)
+ nl = len(lb)
+ if nl:
+ assert lb.shape[1] == 5, f'labels require 5 columns, {lb.shape[1]} columns detected'
+ assert (lb >= 0).all(), f'negative label values {lb[lb < 0]}'
+ assert (lb[:, 1:] <= 1).all(), f'non-normalized or out of bounds coordinates {lb[:, 1:][lb[:, 1:] > 1]}'
+ _, i = np.unique(lb, axis=0, return_index=True)
+ if len(i) < nl: # duplicate row check
+ lb = lb[i] # remove duplicates
+ if segments:
+ segments = segments[i]
+ msg = f'{prefix}WARNING: {im_file}: {nl - len(i)} duplicate labels removed'
+ else:
+ ne = 1 # label empty
+ lb = np.zeros((0, 5), dtype=np.float32)
+ else:
+ nm = 1 # label missing
+ lb = np.zeros((0, 5), dtype=np.float32)
+ return im_file, lb, shape, segments, nm, nf, ne, nc, msg
+ except Exception as e:
+ nc = 1
+ msg = f'{prefix}WARNING: {im_file}: ignoring corrupt image/label: {e}'
+ return [None, None, None, None, nm, nf, ne, nc, msg]
+
+
+class HUBDatasetStats():
+ """ Return dataset statistics dictionary with images and instances counts per split per class
+ To run in parent directory: export PYTHONPATH="$PWD/yolov5"
+ Usage1: from utils.dataloaders import *; HUBDatasetStats('coco128.yaml', autodownload=True)
+ Usage2: from utils.dataloaders import *; HUBDatasetStats('path/to/coco128_with_yaml.zip')
+ Arguments
+ path: Path to data.yaml or data.zip (with data.yaml inside data.zip)
+ autodownload: Attempt to download dataset if not found locally
+ """
+
+ def __init__(self, path='coco128.yaml', autodownload=False):
+ # Initialize class
+ zipped, data_dir, yaml_path = self._unzip(Path(path))
+ try:
+ with open(check_yaml(yaml_path), errors='ignore') as f:
+ data = yaml.safe_load(f) # data dict
+ if zipped:
+ data['path'] = data_dir
+ except Exception as e:
+ raise Exception("error/HUB/dataset_stats/yaml_load") from e
+
+ check_dataset(data, autodownload) # download dataset if missing
+ self.hub_dir = Path(data['path'] + '-hub')
+ self.im_dir = self.hub_dir / 'images'
+ self.im_dir.mkdir(parents=True, exist_ok=True) # makes /images
+ self.stats = {'nc': data['nc'], 'names': data['names']} # statistics dictionary
+ self.data = data
+
+ @staticmethod
+ def _find_yaml(dir):
+ # Return data.yaml file
+ files = list(dir.glob('*.yaml')) or list(dir.rglob('*.yaml')) # try root level first and then recursive
+ assert files, f'No *.yaml file found in {dir}'
+ if len(files) > 1:
+ files = [f for f in files if f.stem == dir.stem] # prefer *.yaml files that match dir name
+ assert files, f'Multiple *.yaml files found in {dir}, only 1 *.yaml file allowed'
+ assert len(files) == 1, f'Multiple *.yaml files found: {files}, only 1 *.yaml file allowed in {dir}'
+ return files[0]
+
+ def _unzip(self, path):
+ # Unzip data.zip
+ if not str(path).endswith('.zip'): # path is data.yaml
+ return False, None, path
+ assert Path(path).is_file(), f'Error unzipping {path}, file not found'
+ ZipFile(path).extractall(path=path.parent) # unzip
+ dir = path.with_suffix('') # dataset directory == zip name
+ assert dir.is_dir(), f'Error unzipping {path}, {dir} not found. path/to/abc.zip MUST unzip to path/to/abc/'
+ return True, str(dir), self._find_yaml(dir) # zipped, data_dir, yaml_path
+
+ def _hub_ops(self, f, max_dim=1920):
+ # HUB ops for 1 image 'f': resize and save at reduced quality in /dataset-hub for web/app viewing
+ f_new = self.im_dir / Path(f).name # dataset-hub image filename
+ try: # use PIL
+ im = Image.open(f)
+ r = max_dim / max(im.height, im.width) # ratio
+ if r < 1.0: # image too large
+ im = im.resize((int(im.width * r), int(im.height * r)))
+ im.save(f_new, 'JPEG', quality=50, optimize=True) # save
+ except Exception as e: # use OpenCV
+ print(f'WARNING: HUB ops PIL failure {f}: {e}')
+ im = cv2.imread(f)
+ im_height, im_width = im.shape[:2]
+ r = max_dim / max(im_height, im_width) # ratio
+ if r < 1.0: # image too large
+ im = cv2.resize(im, (int(im_width * r), int(im_height * r)), interpolation=cv2.INTER_AREA)
+ cv2.imwrite(str(f_new), im)
+
+ def get_json(self, save=False, verbose=False):
+ # Return dataset JSON for Ultralytics HUB
+ def _round(labels):
+ # Update labels to integer class and 6 decimal place floats
+ return [[int(c), *(round(x, 4) for x in points)] for c, *points in labels]
+
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ self.stats[split] = None # i.e. no test set
+ continue
+ dataset = LoadImagesAndLabels(self.data[split]) # load dataset
+ x = np.array([
+ np.bincount(label[:, 0].astype(int), minlength=self.data['nc'])
+ for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics')]) # shape(128x80)
+ self.stats[split] = {
+ 'instance_stats': {
+ 'total': int(x.sum()),
+ 'per_class': x.sum(0).tolist()},
+ 'image_stats': {
+ 'total': dataset.n,
+ 'unlabelled': int(np.all(x == 0, 1).sum()),
+ 'per_class': (x > 0).sum(0).tolist()},
+ 'labels': [{
+ str(Path(k).name): _round(v.tolist())} for k, v in zip(dataset.im_files, dataset.labels)]}
+
+ # Save, print and return
+ if save:
+ stats_path = self.hub_dir / 'stats.json'
+ print(f'Saving {stats_path.resolve()}...')
+ with open(stats_path, 'w') as f:
+ json.dump(self.stats, f) # save stats.json
+ if verbose:
+ print(json.dumps(self.stats, indent=2, sort_keys=False))
+ return self.stats
+
+ def process_images(self):
+ # Compress images for Ultralytics HUB
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ continue
+ dataset = LoadImagesAndLabels(self.data[split]) # load dataset
+ desc = f'{split} images'
+ for _ in tqdm(ThreadPool(NUM_THREADS).imap(self._hub_ops, dataset.im_files), total=dataset.n, desc=desc):
+ pass
+ print(f'Done. All images saved to {self.im_dir}')
+ return self.im_dir
diff --git a/utils/docker/Dockerfile b/utils/docker/Dockerfile
new file mode 100755
index 0000000..2280f20
--- /dev/null
+++ b/utils/docker/Dockerfile
@@ -0,0 +1,68 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Builds ultralytics/yolov5:latest image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is CUDA-optimized for YOLOv5 single/multi-GPU training and inference
+
+# Start FROM NVIDIA PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
+FROM nvcr.io/nvidia/pytorch:22.07-py3
+RUN rm -rf /opt/pytorch # remove 1.2GB dir
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update && apt install --no-install-recommends -y zip htop screen libgl1-mesa-glx
+
+# Install pip packages
+COPY requirements.txt .
+RUN python -m pip install --upgrade pip wheel
+RUN pip uninstall -y Pillow torchtext # torch torchvision
+RUN pip install --no-cache -r requirements.txt albumentations wandb gsutil notebook Pillow>=9.1.0 \
+ 'opencv-python<4.6.0.66' \
+ --extra-index-url https://download.pytorch.org/whl/cu113
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+# Set environment variables
+ENV OMP_NUM_THREADS=8
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest && sudo docker build -f utils/docker/Dockerfile -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
+
+# Pull and Run with local directory access
+# t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/datasets:/usr/src/datasets $t
+
+# Kill all
+# sudo docker kill $(sudo docker ps -q)
+
+# Kill all image-based
+# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/yolov5:latest)
+
+# Bash into running container
+# sudo docker exec -it 5a9b5863d93d bash
+
+# Bash into stopped container
+# id=$(sudo docker ps -qa) && sudo docker start $id && sudo docker exec -it $id bash
+
+# Clean up
+# docker system prune -a --volumes
+
+# Update Ubuntu drivers
+# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
+
+# DDP test
+# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
+
+# GCP VM from Image
+# docker.io/ultralytics/yolov5:latest
diff --git a/utils/docker/Dockerfile-arm64 b/utils/docker/Dockerfile-arm64
new file mode 100755
index 0000000..fe92c8d
--- /dev/null
+++ b/utils/docker/Dockerfile-arm64
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Builds ultralytics/yolov5:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is aarch64-compatible for Apple M1 and other ARM architectures i.e. Jetson Nano and Raspberry Pi
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM arm64v8/ubuntu:20.04
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update
+RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop gcc \
+ libgl1-mesa-glx libglib2.0-0 libpython3.8-dev
+# RUN alias python=python3
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt gsutil notebook \
+ tensorflow-aarch64
+ # tensorflowjs \
+ # onnx onnx-simplifier onnxruntime \
+ # coremltools openvino-dev \
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest-M1 && sudo docker build --platform linux/arm64 -f utils/docker/Dockerfile-arm64 -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest-M1 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/utils/docker/Dockerfile-cpu b/utils/docker/Dockerfile-cpu
new file mode 100755
index 0000000..d61dfef
--- /dev/null
+++ b/utils/docker/Dockerfile-cpu
@@ -0,0 +1,39 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Builds ultralytics/yolov5:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv5 deployments
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM ubuntu:20.04
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update
+RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3.8-dev
+# RUN alias python=python3
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt albumentations gsutil notebook \
+ coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu tensorflowjs \
+ --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest-cpu && sudo docker build -f utils/docker/Dockerfile-cpu -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/utils/downloads.py b/utils/downloads.py
new file mode 100755
index 0000000..9d4780a
--- /dev/null
+++ b/utils/downloads.py
@@ -0,0 +1,180 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Download utils
+"""
+
+import logging
+import os
+import platform
+import subprocess
+import time
+import urllib
+from pathlib import Path
+from zipfile import ZipFile
+
+import requests
+import torch
+
+
+def is_url(url, check_online=True):
+ # Check if online file exists
+ try:
+ url = str(url)
+ result = urllib.parse.urlparse(url)
+ assert all([result.scheme, result.netloc, result.path]) # check if is url
+ return (urllib.request.urlopen(url).getcode() == 200) if check_online else True # check if exists online
+ except (AssertionError, urllib.request.HTTPError):
+ return False
+
+
+def gsutil_getsize(url=''):
+ # gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du
+ s = subprocess.check_output(f'gsutil du {url}', shell=True).decode('utf-8')
+ return eval(s.split(' ')[0]) if len(s) else 0 # bytes
+
+
+def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):
+ # Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
+ from utils.general import LOGGER
+
+ file = Path(file)
+ assert_msg = f"Downloaded file '{file}' does not exist or size is < min_bytes={min_bytes}"
+ try: # url1
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, str(file), progress=LOGGER.level <= logging.INFO)
+ assert file.exists() and file.stat().st_size > min_bytes, assert_msg # check
+ except Exception as e: # url2
+ file.unlink(missing_ok=True) # remove partial downloads
+ LOGGER.info(f'ERROR: {e}\nRe-attempting {url2 or url} to {file}...')
+ os.system(f"curl -L '{url2 or url}' -o '{file}' --retry 3 -C -") # curl download, retry and resume on fail
+ finally:
+ if not file.exists() or file.stat().st_size < min_bytes: # check
+ file.unlink(missing_ok=True) # remove partial downloads
+ LOGGER.info(f"ERROR: {assert_msg}\n{error_msg}")
+ LOGGER.info('')
+
+
+def attempt_download(file, repo='ultralytics/yolov5', release='v6.1'):
+ # Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v6.1', etc.
+ from utils.general import LOGGER
+
+ def github_assets(repository, version='latest'):
+ # Return GitHub repo tag (i.e. 'v6.1') and assets (i.e. ['yolov5s.pt', 'yolov5m.pt', ...])
+ if version != 'latest':
+ version = f'tags/{version}' # i.e. tags/v6.1
+ response = requests.get(f'https://api.github.com/repos/{repository}/releases/{version}').json() # github api
+ return response['tag_name'], [x['name'] for x in response['assets']] # tag, assets
+
+ file = Path(str(file).strip().replace("'", ''))
+ if not file.exists():
+ # URL specified
+ name = Path(urllib.parse.unquote(str(file))).name # decode '%2F' to '/' etc.
+ if str(file).startswith(('http:/', 'https:/')): # download
+ url = str(file).replace(':/', '://') # Pathlib turns :// -> :/
+ file = name.split('?')[0] # parse authentication https://url.com/file.txt?auth...
+ if Path(file).is_file():
+ LOGGER.info(f'Found {url} locally at {file}') # file already exists
+ else:
+ safe_download(file=file, url=url, min_bytes=1E5)
+ return file
+
+ # GitHub assets
+ assets = [
+ 'yolov5n.pt', 'yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt', 'yolov5n6.pt', 'yolov5s6.pt',
+ 'yolov5m6.pt', 'yolov5l6.pt', 'yolov5x6.pt']
+ try:
+ tag, assets = github_assets(repo, release)
+ except Exception:
+ try:
+ tag, assets = github_assets(repo) # latest release
+ except Exception:
+ try:
+ tag = subprocess.check_output('git tag', shell=True, stderr=subprocess.STDOUT).decode().split()[-1]
+ except Exception:
+ tag = release
+
+ file.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required)
+ if name in assets:
+ url3 = 'https://drive.google.com/drive/folders/1EFQTEUeXWSFww0luse2jB9M1QNZQGwNl' # backup gdrive mirror
+ safe_download(
+ file,
+ url=f'https://github.com/{repo}/releases/download/{tag}/{name}',
+ url2=f'https://storage.googleapis.com/{repo}/{tag}/{name}', # backup url (optional)
+ min_bytes=1E5,
+ error_msg=f'{file} missing, try downloading from https://github.com/{repo}/releases/{tag} or {url3}')
+
+ return str(file)
+
+
+def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'):
+ # Downloads a file from Google Drive. from yolov5.utils.downloads import *; gdrive_download()
+ t = time.time()
+ file = Path(file)
+ cookie = Path('cookie') # gdrive cookie
+ print(f'Downloading https://drive.google.com/uc?export=download&id={id} as {file}... ', end='')
+ file.unlink(missing_ok=True) # remove existing file
+ cookie.unlink(missing_ok=True) # remove existing cookie
+
+ # Attempt file download
+ out = "NUL" if platform.system() == "Windows" else "/dev/null"
+ os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={id}" > {out}')
+ if os.path.exists('cookie'): # large file
+ s = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={get_token()}&id={id}" -o {file}'
+ else: # small file
+ s = f'curl -s -L -o {file} "drive.google.com/uc?export=download&id={id}"'
+ r = os.system(s) # execute, capture return
+ cookie.unlink(missing_ok=True) # remove existing cookie
+
+ # Error check
+ if r != 0:
+ file.unlink(missing_ok=True) # remove partial
+ print('Download error ') # raise Exception('Download error')
+ return r
+
+ # Unzip if archive
+ if file.suffix == '.zip':
+ print('unzipping... ', end='')
+ ZipFile(file).extractall(path=file.parent) # unzip
+ file.unlink() # remove zip
+
+ print(f'Done ({time.time() - t:.1f}s)')
+ return r
+
+
+def get_token(cookie="./cookie"):
+ with open(cookie) as f:
+ for line in f:
+ if "download" in line:
+ return line.split()[-1]
+ return ""
+
+
+# Google utils: https://cloud.google.com/storage/docs/reference/libraries ----------------------------------------------
+#
+#
+# def upload_blob(bucket_name, source_file_name, destination_blob_name):
+# # Uploads a file to a bucket
+# # https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
+#
+# storage_client = storage.Client()
+# bucket = storage_client.get_bucket(bucket_name)
+# blob = bucket.blob(destination_blob_name)
+#
+# blob.upload_from_filename(source_file_name)
+#
+# print('File {} uploaded to {}.'.format(
+# source_file_name,
+# destination_blob_name))
+#
+#
+# def download_blob(bucket_name, source_blob_name, destination_file_name):
+# # Uploads a blob from a bucket
+# storage_client = storage.Client()
+# bucket = storage_client.get_bucket(bucket_name)
+# blob = bucket.blob(source_blob_name)
+#
+# blob.download_to_filename(destination_file_name)
+#
+# print('Blob {} downloaded to {}.'.format(
+# source_blob_name,
+# destination_file_name))
diff --git a/utils/flask_rest_api/README.md b/utils/flask_rest_api/README.md
new file mode 100755
index 0000000..a726acb
--- /dev/null
+++ b/utils/flask_rest_api/README.md
@@ -0,0 +1,73 @@
+# Flask REST API
+
+[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) [API](https://en.wikipedia.org/wiki/API)s are
+commonly used to expose Machine Learning (ML) models to other services. This folder contains an example REST API
+created using Flask to expose the YOLOv5s model from [PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5/).
+
+## Requirements
+
+[Flask](https://palletsprojects.com/p/flask/) is required. Install with:
+
+```shell
+$ pip install Flask
+```
+
+## Run
+
+After Flask installation run:
+
+```shell
+$ python3 restapi.py --port 5000
+```
+
+Then use [curl](https://curl.se/) to perform a request:
+
+```shell
+$ curl -X POST -F image=@zidane.jpg 'http://localhost:5000/v1/object-detection/yolov5s'
+```
+
+The model inference results are returned as a JSON response:
+
+```json
+[
+ {
+ "class": 0,
+ "confidence": 0.8900438547,
+ "height": 0.9318675399,
+ "name": "person",
+ "width": 0.3264600933,
+ "xcenter": 0.7438579798,
+ "ycenter": 0.5207948685
+ },
+ {
+ "class": 0,
+ "confidence": 0.8440024257,
+ "height": 0.7155083418,
+ "name": "person",
+ "width": 0.6546785235,
+ "xcenter": 0.427829951,
+ "ycenter": 0.6334488392
+ },
+ {
+ "class": 27,
+ "confidence": 0.3771208823,
+ "height": 0.3902671337,
+ "name": "tie",
+ "width": 0.0696444362,
+ "xcenter": 0.3675483763,
+ "ycenter": 0.7991207838
+ },
+ {
+ "class": 27,
+ "confidence": 0.3527112305,
+ "height": 0.1540903747,
+ "name": "tie",
+ "width": 0.0336618312,
+ "xcenter": 0.7814827561,
+ "ycenter": 0.5065554976
+ }
+]
+```
+
+An example python script to perform inference using [requests](https://docs.python-requests.org/en/master/) is given
+in `example_request.py`
diff --git a/utils/flask_rest_api/example_request.py b/utils/flask_rest_api/example_request.py
new file mode 100755
index 0000000..773ad89
--- /dev/null
+++ b/utils/flask_rest_api/example_request.py
@@ -0,0 +1,19 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Perform test request
+"""
+
+import pprint
+
+import requests
+
+DETECTION_URL = "http://localhost:5000/v1/object-detection/yolov5s"
+IMAGE = "zidane.jpg"
+
+# Read image
+with open(IMAGE, "rb") as f:
+ image_data = f.read()
+
+response = requests.post(DETECTION_URL, files={"image": image_data}).json()
+
+pprint.pprint(response)
diff --git a/utils/flask_rest_api/restapi.py b/utils/flask_rest_api/restapi.py
new file mode 100755
index 0000000..8482435
--- /dev/null
+++ b/utils/flask_rest_api/restapi.py
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Run a Flask REST API exposing one or more YOLOv5s models
+"""
+
+import argparse
+import io
+
+import torch
+from flask import Flask, request
+from PIL import Image
+
+app = Flask(__name__)
+models = {}
+
+DETECTION_URL = "/v1/object-detection/"
+
+
+@app.route(DETECTION_URL, methods=["POST"])
+def predict(model):
+ if request.method != "POST":
+ return
+
+ if request.files.get("image"):
+ # Method 1
+ # with request.files["image"] as f:
+ # im = Image.open(io.BytesIO(f.read()))
+
+ # Method 2
+ im_file = request.files["image"]
+ im_bytes = im_file.read()
+ im = Image.open(io.BytesIO(im_bytes))
+
+ if model in models:
+ results = models[model](im, size=640) # reduce size=320 for faster inference
+ return results.pandas().xyxy[0].to_json(orient="records")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Flask API exposing YOLOv5 model")
+ parser.add_argument("--port", default=5000, type=int, help="port number")
+ parser.add_argument('--model', nargs='+', default=['yolov5s'], help='model(s) to run, i.e. --model yolov5n yolov5s')
+ opt = parser.parse_args()
+
+ for m in opt.model:
+ models[m] = torch.hub.load("ultralytics/yolov5", m, force_reload=True, skip_validation=True)
+
+ app.run(host="0.0.0.0", port=opt.port) # debug=True causes Restarting with stat
diff --git a/utils/general.py b/utils/general.py
new file mode 100755
index 0000000..4a4aadb
--- /dev/null
+++ b/utils/general.py
@@ -0,0 +1,1034 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+General utils
+"""
+
+import contextlib
+import glob
+import inspect
+import logging
+import math
+import os
+import platform
+import random
+import re
+import shutil
+import signal
+import sys
+import threading
+import time
+import urllib
+from datetime import datetime
+from itertools import repeat
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+from subprocess import check_output
+from typing import Optional
+from zipfile import ZipFile
+
+import cv2
+import numpy as np
+import pandas as pd
+import pkg_resources as pkg
+import torch
+import torchvision
+import yaml
+
+from utils.downloads import gsutil_getsize
+from utils.metrics import box_iou, fitness
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+RANK = int(os.getenv('RANK', -1))
+
+# Settings
+DATASETS_DIR = ROOT.parent / 'datasets' # YOLOv5 datasets directory
+NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
+AUTOINSTALL = str(os.getenv('YOLOv5_AUTOINSTALL', True)).lower() == 'true' # global auto-install mode
+VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true' # global verbose mode
+FONT = 'Arial.ttf' # https://ultralytics.com/assets/Arial.ttf
+
+torch.set_printoptions(linewidth=320, precision=5, profile='long')
+np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
+pd.options.display.max_columns = 10
+cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
+os.environ['NUMEXPR_MAX_THREADS'] = str(NUM_THREADS) # NumExpr max threads
+os.environ['OMP_NUM_THREADS'] = '1' if platform.system() == 'darwin' else str(NUM_THREADS) # OpenMP (PyTorch and SciPy)
+
+
+def is_ascii(s=''):
+ # Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
+ s = str(s) # convert list, tuple, None, etc. to str
+ return len(s.encode().decode('ascii', 'ignore')) == len(s)
+
+
+def is_chinese(s='人工智能'):
+ # Is string composed of any Chinese characters?
+ return bool(re.search('[\u4e00-\u9fff]', str(s)))
+
+
+def is_colab():
+ # Is environment a Google Colab instance?
+ return 'COLAB_GPU' in os.environ
+
+
+def is_kaggle():
+ # Is environment a Kaggle Notebook?
+ return os.environ.get('PWD') == '/kaggle/working' and os.environ.get('KAGGLE_URL_BASE') == 'https://www.kaggle.com'
+
+
+def is_docker() -> bool:
+ """Check if the process runs inside a docker container."""
+ if Path("/.dockerenv").exists():
+ return True
+ try: # check if docker is in control groups
+ with open("/proc/self/cgroup") as file:
+ return any("docker" in line for line in file)
+ except OSError:
+ return False
+
+
+def is_writeable(dir, test=False):
+ # Return True if directory has write permissions, test opening a file with write permissions if test=True
+ if not test:
+ return os.access(dir, os.W_OK) # possible issues on Windows
+ file = Path(dir) / 'tmp.txt'
+ try:
+ with open(file, 'w'): # open file with write permissions
+ pass
+ file.unlink() # remove file
+ return True
+ except OSError:
+ return False
+
+
+def set_logging(name=None, verbose=VERBOSE):
+ # Sets level and returns logger
+ if is_kaggle() or is_colab():
+ for h in logging.root.handlers:
+ logging.root.removeHandler(h) # remove all handlers associated with the root logger object
+ rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
+ level = logging.INFO if verbose and rank in {-1, 0} else logging.ERROR
+ log = logging.getLogger(name)
+ log.setLevel(level)
+ handler = logging.StreamHandler()
+ handler.setFormatter(logging.Formatter("%(message)s"))
+ handler.setLevel(level)
+ log.addHandler(handler)
+
+
+set_logging() # run before defining LOGGER
+LOGGER = logging.getLogger("yolov5") # define globally (used in train.py, val.py, detect.py, etc.)
+if platform.system() == 'Windows':
+ for fn in LOGGER.info, LOGGER.warning:
+ setattr(LOGGER, fn.__name__, lambda x: fn(emojis(x))) # emoji safe logging
+
+
+def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
+ # Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
+ env = os.getenv(env_var)
+ if env:
+ path = Path(env) # use environment variable
+ else:
+ cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
+ path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
+ path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
+ path.mkdir(exist_ok=True) # make if required
+ return path
+
+
+CONFIG_DIR = user_config_dir() # Ultralytics settings dir
+
+
+class Profile(contextlib.ContextDecorator):
+ # Usage: @Profile() decorator or 'with Profile():' context manager
+ def __enter__(self):
+ self.start = time.time()
+
+ def __exit__(self, type, value, traceback):
+ print(f'Profile results: {time.time() - self.start:.5f}s')
+
+
+class Timeout(contextlib.ContextDecorator):
+ # Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
+ def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
+ self.seconds = int(seconds)
+ self.timeout_message = timeout_msg
+ self.suppress = bool(suppress_timeout_errors)
+
+ def _timeout_handler(self, signum, frame):
+ raise TimeoutError(self.timeout_message)
+
+ def __enter__(self):
+ if platform.system() != 'Windows': # not supported on Windows
+ signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
+ signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ if platform.system() != 'Windows':
+ signal.alarm(0) # Cancel SIGALRM if it's scheduled
+ if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
+ return True
+
+
+class WorkingDirectory(contextlib.ContextDecorator):
+ # Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager
+ def __init__(self, new_dir):
+ self.dir = new_dir # new dir
+ self.cwd = Path.cwd().resolve() # current dir
+
+ def __enter__(self):
+ os.chdir(self.dir)
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ os.chdir(self.cwd)
+
+
+def try_except(func):
+ # try-except function. Usage: @try_except decorator
+ def handler(*args, **kwargs):
+ try:
+ func(*args, **kwargs)
+ except Exception as e:
+ print(e)
+
+ return handler
+
+
+def threaded(func):
+ # Multi-threads a target function and returns thread. Usage: @threaded decorator
+ def wrapper(*args, **kwargs):
+ thread = threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True)
+ thread.start()
+ return thread
+
+ return wrapper
+
+
+def methods(instance):
+ # Get class/instance methods
+ return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith("__")]
+
+
+def print_args(args: Optional[dict] = None, show_file=True, show_fcn=False):
+ # Print function arguments (optional args dict)
+ x = inspect.currentframe().f_back # previous frame
+ file, _, fcn, _, _ = inspect.getframeinfo(x)
+ if args is None: # get args automatically
+ args, _, _, frm = inspect.getargvalues(x)
+ args = {k: v for k, v in frm.items() if k in args}
+ s = (f'{Path(file).stem}: ' if show_file else '') + (f'{fcn}: ' if show_fcn else '')
+ LOGGER.info(colorstr(s) + ', '.join(f'{k}={v}' for k, v in args.items()))
+
+
+def init_seeds(seed=0, deterministic=False):
+ # Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
+ # cudnn seed 0 settings are slower and more reproducible, else faster and less reproducible
+ import torch.backends.cudnn as cudnn
+
+ if deterministic and check_version(torch.__version__, '1.12.0'): # https://github.com/ultralytics/yolov5/pull/8213
+ torch.use_deterministic_algorithms(True)
+ os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
+ os.environ['PYTHONHASHSEED'] = str(seed)
+
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ cudnn.benchmark, cudnn.deterministic = (False, True) if seed == 0 else (True, False)
+ torch.cuda.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed) # for Multi-GPU, exception safe
+
+
+def intersect_dicts(da, db, exclude=()):
+ # Dictionary intersection of matching keys and shapes, omitting 'exclude' keys, using da values
+ return {k: v for k, v in da.items() if k in db and not any(x in k for x in exclude) and v.shape == db[k].shape}
+
+
+def get_latest_run(search_dir='.'):
+ # Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
+ last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
+ return max(last_list, key=os.path.getctime) if last_list else ''
+
+
+def emojis(str=''):
+ # Return platform-dependent emoji-safe version of string
+ return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
+
+
+def file_age(path=__file__):
+ # Return days since last file update
+ dt = (datetime.now() - datetime.fromtimestamp(Path(path).stat().st_mtime)) # delta
+ return dt.days # + dt.seconds / 86400 # fractional days
+
+
+def file_date(path=__file__):
+ # Return human-readable file modification date, i.e. '2021-3-26'
+ t = datetime.fromtimestamp(Path(path).stat().st_mtime)
+ return f'{t.year}-{t.month}-{t.day}'
+
+
+def file_size(path):
+ # Return file/dir size (MB)
+ mb = 1 << 20 # bytes to MiB (1024 ** 2)
+ path = Path(path)
+ if path.is_file():
+ return path.stat().st_size / mb
+ elif path.is_dir():
+ return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / mb
+ else:
+ return 0.0
+
+
+def check_online():
+ # Check internet connectivity
+ import socket
+ try:
+ socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
+ return True
+ except OSError:
+ return False
+
+
+def git_describe(path=ROOT): # path must be a directory
+ # Return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
+ try:
+ assert (Path(path) / '.git').is_dir()
+ return check_output(f'git -C {path} describe --tags --long --always', shell=True).decode()[:-1]
+ except Exception:
+ return ''
+
+
+@try_except
+@WorkingDirectory(ROOT)
+def check_git_status(repo='ultralytics/yolov5'):
+ # YOLOv5 status check, recommend 'git pull' if code is out of date
+ url = f'https://github.com/{repo}'
+ msg = f', for updates see {url}'
+ s = colorstr('github: ') # string
+ assert Path('.git').exists(), s + 'skipping check (not a git repository)' + msg
+ assert check_online(), s + 'skipping check (offline)' + msg
+
+ splits = re.split(pattern=r'\s', string=check_output('git remote -v', shell=True).decode())
+ matches = [repo in s for s in splits]
+ if any(matches):
+ remote = splits[matches.index(True) - 1]
+ else:
+ remote = 'ultralytics'
+ check_output(f'git remote add {remote} {url}', shell=True)
+ check_output(f'git fetch {remote}', shell=True, timeout=5) # git fetch
+ branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
+ n = int(check_output(f'git rev-list {branch}..{remote}/master --count', shell=True)) # commits behind
+ if n > 0:
+ pull = 'git pull' if remote == 'origin' else f'git pull {remote} master'
+ s += f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use `{pull}` or `git clone {url}` to update."
+ else:
+ s += f'up to date with {url} ✅'
+ LOGGER.info(s)
+
+
+def check_python(minimum='3.7.0'):
+ # Check current python version vs. required python version
+ check_version(platform.python_version(), minimum, name='Python ', hard=True)
+
+
+def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
+ # Check version vs. required version
+ current, minimum = (pkg.parse_version(x) for x in (current, minimum))
+ result = (current == minimum) if pinned else (current >= minimum) # bool
+ s = f'{name}{minimum} required by YOLOv5, but {name}{current} is currently installed' # string
+ if hard:
+ assert result, s # assert min requirements met
+ if verbose and not result:
+ LOGGER.warning(s)
+ return result
+
+
+@try_except
+def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True, cmds=()):
+ # Check installed dependencies meet requirements (pass *.txt file or list of packages)
+ prefix = colorstr('red', 'bold', 'requirements:')
+ check_python() # check python version
+ if isinstance(requirements, (str, Path)): # requirements.txt file
+ file = Path(requirements)
+ assert file.exists(), f"{prefix} {file.resolve()} not found, check failed."
+ with file.open() as f:
+ requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(f) if x.name not in exclude]
+ else: # list or tuple of packages
+ requirements = [x for x in requirements if x not in exclude]
+
+ n = 0 # number of packages updates
+ for i, r in enumerate(requirements):
+ try:
+ pkg.require(r)
+ except Exception: # DistributionNotFound or VersionConflict if requirements not met
+ s = f"{prefix} {r} not found and is required by YOLOv5"
+ if install and AUTOINSTALL: # check environment variable
+ LOGGER.info(f"{s}, attempting auto-update...")
+ try:
+ assert check_online(), f"'pip install {r}' skipped (offline)"
+ LOGGER.info(check_output(f'pip install "{r}" {cmds[i] if cmds else ""}', shell=True).decode())
+ n += 1
+ except Exception as e:
+ LOGGER.warning(f'{prefix} {e}')
+ else:
+ LOGGER.info(f'{s}. Please install and rerun your command.')
+
+ if n: # if packages updated
+ source = file.resolve() if 'file' in locals() else requirements
+ s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
+ f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
+ LOGGER.info(s)
+
+
+def check_img_size(imgsz, s=32, floor=0):
+ # Verify image size is a multiple of stride s in each dimension
+ if isinstance(imgsz, int): # integer i.e. img_size=640
+ new_size = max(make_divisible(imgsz, int(s)), floor)
+ else: # list i.e. img_size=[640, 480]
+ imgsz = list(imgsz) # convert to list if tuple
+ new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
+ if new_size != imgsz:
+ LOGGER.warning(f'WARNING: --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
+ return new_size
+
+
+def check_imshow():
+ # Check if environment supports image displays
+ try:
+ assert not is_docker(), 'cv2.imshow() is disabled in Docker environments'
+ assert not is_colab(), 'cv2.imshow() is disabled in Google Colab environments'
+ cv2.imshow('test', np.zeros((1, 1, 3)))
+ cv2.waitKey(1)
+ cv2.destroyAllWindows()
+ cv2.waitKey(1)
+ return True
+ except Exception as e:
+ LOGGER.warning(f'WARNING: Environment does not support cv2.imshow() or PIL Image.show() image displays\n{e}')
+ return False
+
+
+def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
+ # Check file(s) for acceptable suffix
+ if file and suffix:
+ if isinstance(suffix, str):
+ suffix = [suffix]
+ for f in file if isinstance(file, (list, tuple)) else [file]:
+ s = Path(f).suffix.lower() # file suffix
+ if len(s):
+ assert s in suffix, f"{msg}{f} acceptable suffix is {suffix}"
+
+
+def check_yaml(file, suffix=('.yaml', '.yml')):
+ # Search/download YAML file (if necessary) and return path, checking suffix
+ return check_file(file, suffix)
+
+
+def check_file(file, suffix=''):
+ # File can be dict or pathlike
+ if isinstance(file, dict):
+ return file
+ # Search/download file (if necessary) and return path
+ check_suffix(file, suffix) # optional
+ file = str(file) # convert to str()
+ if Path(file).is_file() or not file: # exists
+ return file
+ elif file.startswith(('http:/', 'https:/')): # download
+ url = file # warning: Pathlib turns :// -> :/
+ file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
+ if Path(file).is_file():
+ LOGGER.info(f'Found {url} locally at {file}') # file already exists
+ else:
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, file)
+ assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
+ return file
+ elif file.startswith('clearml://'): # ClearML Dataset ID
+ assert 'clearml' in sys.modules, "ClearML is not installed, so cannot use ClearML dataset. Try running 'pip install clearml'."
+ return file
+ else: # search
+ files = []
+ for d in 'data', 'models', 'utils': # search directories
+ files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
+ assert len(files), f'File not found: {file}' # assert file was found
+ assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
+ return files[0] # return file
+
+
+def check_font(font=FONT, progress=False):
+ # Download font to CONFIG_DIR if necessary
+ font = Path(font)
+ file = CONFIG_DIR / font.name
+ if not font.exists() and not file.exists():
+ url = "https://ultralytics.com/assets/" + font.name
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, str(file), progress=progress)
+
+
+def check_dataset(data, autodownload=True):
+ # Download, check and/or unzip dataset if not found locally
+
+ # Download (optional)
+ extract_dir = ''
+ if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
+ download(data, dir=f'{DATASETS_DIR}/{Path(data).stem}', unzip=True, delete=False, curl=False, threads=1)
+ data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
+ extract_dir, autodownload = data.parent, False
+
+ # Read yaml (optional)
+ if isinstance(data, (str, Path)):
+ with open(data, errors='ignore') as f:
+ data = yaml.safe_load(f) # dictionary
+
+ # Checks
+ for k in 'train', 'val', 'nc':
+ assert k in data, f"data.yaml '{k}:' field missing ❌"
+ if 'names' not in data:
+ LOGGER.warning("data.yaml 'names:' field missing ⚠️, assigning default names 'class0', 'class1', etc.")
+ data['names'] = [f'class{i}' for i in range(data['nc'])] # default names
+
+ # Resolve paths
+ path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
+ if not path.is_absolute():
+ path = (ROOT / path).resolve()
+ for k in 'train', 'val', 'test':
+ if data.get(k): # prepend path
+ data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]
+
+ # Parse yaml
+ train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
+ if val:
+ val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
+ if not all(x.exists() for x in val):
+ LOGGER.info('\nDataset not found ⚠️, missing paths %s' % [str(x) for x in val if not x.exists()])
+ if not s or not autodownload:
+ raise Exception('Dataset not found ❌')
+ t = time.time()
+ root = path.parent if 'path' in data else '..' # unzip directory i.e. '../'
+ if s.startswith('http') and s.endswith('.zip'): # URL
+ f = Path(s).name # filename
+ LOGGER.info(f'Downloading {s} to {f}...')
+ torch.hub.download_url_to_file(s, f)
+ Path(root).mkdir(parents=True, exist_ok=True) # create root
+ ZipFile(f).extractall(path=root) # unzip
+ Path(f).unlink() # remove zip
+ r = None # success
+ elif s.startswith('bash '): # bash script
+ LOGGER.info(f'Running {s} ...')
+ r = os.system(s)
+ else: # python script
+ r = exec(s, {'yaml': data}) # return None
+ dt = f'({round(time.time() - t, 1)}s)'
+ s = f"success ✅ {dt}, saved to {colorstr('bold', root)}" if r in (0, None) else f"failure {dt} ❌"
+ LOGGER.info(f"Dataset download {s}")
+ check_font('Arial.ttf' if is_ascii(data['names']) else 'Arial.Unicode.ttf', progress=True) # download fonts
+ return data # dictionary
+
+
+def check_amp(model):
+ # Check PyTorch Automatic Mixed Precision (AMP) functionality. Return True on correct operation
+ from models.common import AutoShape, DetectMultiBackend
+
+ def amp_allclose(model, im):
+ # All close FP32 vs AMP results
+ m = AutoShape(model, verbose=False) # model
+ a = m(im).xywhn[0] # FP32 inference
+ m.amp = True
+ b = m(im).xywhn[0] # AMP inference
+ return a.shape == b.shape and torch.allclose(a, b, atol=0.1) # close to 10% absolute tolerance
+
+ prefix = colorstr('AMP: ')
+ device = next(model.parameters()).device # get model device
+ if device.type == 'cpu':
+ return False # AMP disabled on CPU
+ f = ROOT / 'data' / 'images' / 'bus.jpg' # image to check
+ im = f if f.exists() else 'https://ultralytics.com/images/bus.jpg' if check_online() else np.ones((640, 640, 3))
+ try:
+ assert amp_allclose(model, im) or amp_allclose(DetectMultiBackend('yolov5n.pt', device), im)
+ LOGGER.info(f'{prefix}checks passed ✅')
+ return True
+ except Exception:
+ help_url = 'https://github.com/ultralytics/yolov5/issues/7908'
+ LOGGER.warning(f'{prefix}checks failed ❌, disabling Automatic Mixed Precision. See {help_url}')
+ return False
+
+
+def url2file(url):
+ # Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
+ url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
+ return Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
+
+
+def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1, retry=3):
+ # Multi-threaded file download and unzip function, used in data.yaml for autodownload
+ def download_one(url, dir):
+ # Download 1 file
+ success = True
+ f = dir / Path(url).name # filename
+ if Path(url).is_file(): # exists in current path
+ Path(url).rename(f) # move to dir
+ elif not f.exists():
+ LOGGER.info(f'Downloading {url} to {f}...')
+ for i in range(retry + 1):
+ if curl:
+ s = 'sS' if threads > 1 else '' # silent
+ r = os.system(f'curl -{s}L "{url}" -o "{f}" --retry 9 -C -') # curl download with retry, continue
+ success = r == 0
+ else:
+ torch.hub.download_url_to_file(url, f, progress=threads == 1) # torch download
+ success = f.is_file()
+ if success:
+ break
+ elif i < retry:
+ LOGGER.warning(f'Download failure, retrying {i + 1}/{retry} {url}...')
+ else:
+ LOGGER.warning(f'Failed to download {url}...')
+
+ if unzip and success and f.suffix in ('.zip', '.tar', '.gz'):
+ LOGGER.info(f'Unzipping {f}...')
+ if f.suffix == '.zip':
+ ZipFile(f).extractall(path=dir) # unzip
+ elif f.suffix == '.tar':
+ os.system(f'tar xf {f} --directory {f.parent}') # unzip
+ elif f.suffix == '.gz':
+ os.system(f'tar xfz {f} --directory {f.parent}') # unzip
+ if delete:
+ f.unlink() # remove zip
+
+ dir = Path(dir)
+ dir.mkdir(parents=True, exist_ok=True) # make directory
+ if threads > 1:
+ pool = ThreadPool(threads)
+ pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multi-threaded
+ pool.close()
+ pool.join()
+ else:
+ for u in [url] if isinstance(url, (str, Path)) else url:
+ download_one(u, dir)
+
+
+def make_divisible(x, divisor):
+ # Returns nearest x divisible by divisor
+ if isinstance(divisor, torch.Tensor):
+ divisor = int(divisor.max()) # to int
+ return math.ceil(x / divisor) * divisor
+
+
+def clean_str(s):
+ # Cleans a string by replacing special characters with underscore _
+ return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
+
+
+def one_cycle(y1=0.0, y2=1.0, steps=100):
+ # lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
+ return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
+
+
+def colorstr(*input):
+ # Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
+ *args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
+ colors = {
+ 'black': '\033[30m', # basic colors
+ 'red': '\033[31m',
+ 'green': '\033[32m',
+ 'yellow': '\033[33m',
+ 'blue': '\033[34m',
+ 'magenta': '\033[35m',
+ 'cyan': '\033[36m',
+ 'white': '\033[37m',
+ 'bright_black': '\033[90m', # bright colors
+ 'bright_red': '\033[91m',
+ 'bright_green': '\033[92m',
+ 'bright_yellow': '\033[93m',
+ 'bright_blue': '\033[94m',
+ 'bright_magenta': '\033[95m',
+ 'bright_cyan': '\033[96m',
+ 'bright_white': '\033[97m',
+ 'end': '\033[0m', # misc
+ 'bold': '\033[1m',
+ 'underline': '\033[4m'}
+ return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
+
+
+def labels_to_class_weights(labels, nc=80):
+ # Get class weights (inverse frequency) from training labels
+ if labels[0] is None: # no labels loaded
+ return torch.Tensor()
+
+ labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
+ classes = labels[:, 0].astype(int) # labels = [class xywh]
+ weights = np.bincount(classes, minlength=nc) # occurrences per class
+
+ # Prepend gridpoint count (for uCE training)
+ # gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
+ # weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
+
+ weights[weights == 0] = 1 # replace empty bins with 1
+ weights = 1 / weights # number of targets per class
+ weights /= weights.sum() # normalize
+ return torch.from_numpy(weights).float()
+
+
+def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
+ # Produces image weights based on class_weights and image contents
+ # Usage: index = random.choices(range(n), weights=image_weights, k=1) # weighted image sample
+ class_counts = np.array([np.bincount(x[:, 0].astype(int), minlength=nc) for x in labels])
+ return (class_weights.reshape(1, nc) * class_counts).sum(1)
+
+
+def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
+ # https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
+ # a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
+ # b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
+ # x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
+ # x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
+ return [
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
+ 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
+ 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
+
+
+def xyxy2xywh(x):
+ # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
+ y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
+ y[:, 2] = x[:, 2] - x[:, 0] # width
+ y[:, 3] = x[:, 3] - x[:, 1] # height
+ return y
+
+
+def xywh2xyxy(x):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
+ y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
+ y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
+ y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
+ return y
+
+
+def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
+ # Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
+ y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
+ y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
+ y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
+ return y
+
+
+def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
+ # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
+ if clip:
+ clip_coords(x, (h - eps, w - eps)) # warning: inplace clip
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
+ y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
+ y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
+ y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
+ return y
+
+
+def xyn2xy(x, w=640, h=640, padw=0, padh=0):
+ # Convert normalized segments into pixel segments, shape (n,2)
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = w * x[:, 0] + padw # top left x
+ y[:, 1] = h * x[:, 1] + padh # top left y
+ return y
+
+
+def segment2box(segment, width=640, height=640):
+ # Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
+ x, y = segment.T # segment xy
+ inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
+ x, y, = x[inside], y[inside]
+ return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
+
+
+def segments2boxes(segments):
+ # Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
+ boxes = []
+ for s in segments:
+ x, y = s.T # segment xy
+ boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
+ return xyxy2xywh(np.array(boxes)) # cls, xywh
+
+
+def resample_segments(segments, n=1000):
+ # Up-sample an (n,2) segment
+ for i, s in enumerate(segments):
+ s = np.concatenate((s, s[0:1, :]), axis=0)
+ x = np.linspace(0, len(s) - 1, n)
+ xp = np.arange(len(s))
+ segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
+ return segments
+
+
+def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
+ # Rescale coords (xyxy) from img1_shape to img0_shape
+ if ratio_pad is None: # calculate from img0_shape
+ gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
+ pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+
+ coords[:, [0, 2]] -= pad[0] # x padding
+ coords[:, [1, 3]] -= pad[1] # y padding
+ coords[:, :4] /= gain
+ clip_coords(coords, img0_shape)
+ return coords
+
+
+def clip_coords(boxes, shape):
+ # Clip bounding xyxy bounding boxes to image shape (height, width)
+ if isinstance(boxes, torch.Tensor): # faster individually
+ boxes[:, 0].clamp_(0, shape[1]) # x1
+ boxes[:, 1].clamp_(0, shape[0]) # y1
+ boxes[:, 2].clamp_(0, shape[1]) # x2
+ boxes[:, 3].clamp_(0, shape[0]) # y2
+ else: # np.array (faster grouped)
+ boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
+ boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
+
+
+def non_max_suppression(prediction,
+ conf_thres=0.25,
+ iou_thres=0.45,
+ classes=None,
+ agnostic=False,
+ multi_label=False,
+ labels=(),
+ max_det=300):
+ """Non-Maximum Suppression (NMS) on inference results to reject overlapping bounding boxes
+
+ Returns:
+ list of detections, on (n,6) tensor per image [xyxy, conf, cls]
+ """
+
+ bs = prediction.shape[0] # batch size
+ nc = prediction.shape[2] - 5 # number of classes
+ xc = prediction[..., 4] > conf_thres # candidates
+
+ # Checks
+ assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
+ assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
+
+ # Settings
+ # min_wh = 2 # (pixels) minimum box width and height
+ max_wh = 7680 # (pixels) maximum box width and height
+ max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
+ time_limit = 0.3 + 0.03 * bs # seconds to quit after
+ redundant = True # require redundant detections
+ multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
+ merge = False # use merge-NMS
+
+ t = time.time()
+ output = [torch.zeros((0, 6), device=prediction.device)] * bs
+ for xi, x in enumerate(prediction): # image index, image inference
+ # Apply constraints
+ # x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
+ x = x[xc[xi]] # confidence
+
+ # Cat apriori labels if autolabelling
+ if labels and len(labels[xi]):
+ lb = labels[xi]
+ v = torch.zeros((len(lb), nc + 5), device=x.device)
+ v[:, :4] = lb[:, 1:5] # box
+ v[:, 4] = 1.0 # conf
+ v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
+ x = torch.cat((x, v), 0)
+
+ # If none remain process next image
+ if not x.shape[0]:
+ continue
+
+ # Compute conf
+ x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
+
+ # Box (center x, center y, width, height) to (x1, y1, x2, y2)
+ box = xywh2xyxy(x[:, :4])
+
+ # Detections matrix nx6 (xyxy, conf, cls)
+ if multi_label:
+ i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
+ x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
+ else: # best class only
+ conf, j = x[:, 5:].max(1, keepdim=True)
+ x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
+
+ # Filter by class
+ if classes is not None:
+ x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
+
+ # Apply finite constraint
+ # if not torch.isfinite(x).all():
+ # x = x[torch.isfinite(x).all(1)]
+
+ # Check shape
+ n = x.shape[0] # number of boxes
+ if not n: # no boxes
+ continue
+ elif n > max_nms: # excess boxes
+ x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
+
+ # Batched NMS
+ c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
+ boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
+ i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
+ if i.shape[0] > max_det: # limit detections
+ i = i[:max_det]
+ if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
+ # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
+ iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
+ weights = iou * scores[None] # box weights
+ x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
+ if redundant:
+ i = i[iou.sum(1) > 1] # require redundancy
+
+ output[xi] = x[i]
+
+ return output
+
+
+def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
+ # Strip optimizer from 'f' to finalize training, optionally save as 's'
+ x = torch.load(f, map_location=torch.device('cpu'))
+ if x.get('ema'):
+ x['model'] = x['ema'] # replace model with ema
+ for k in 'optimizer', 'best_fitness', 'wandb_id', 'ema', 'updates': # keys
+ x[k] = None
+ x['epoch'] = -1
+ x['model'].half() # to FP16
+ for p in x['model'].parameters():
+ p.requires_grad = False
+ torch.save(x, s or f)
+ mb = os.path.getsize(s or f) / 1E6 # filesize
+ LOGGER.info(f"Optimizer stripped from {f},{f' saved as {s},' if s else ''} {mb:.1f}MB")
+
+
+def print_mutation(results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
+ evolve_csv = save_dir / 'evolve.csv'
+ evolve_yaml = save_dir / 'hyp_evolve.yaml'
+ keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss',
+ 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys()) # [results + hyps]
+ keys = tuple(x.strip() for x in keys)
+ vals = results + tuple(hyp.values())
+ n = len(keys)
+
+ # Download (optional)
+ if bucket:
+ url = f'gs://{bucket}/evolve.csv'
+ if gsutil_getsize(url) > (evolve_csv.stat().st_size if evolve_csv.exists() else 0):
+ os.system(f'gsutil cp {url} {save_dir}') # download evolve.csv if larger than local
+
+ # Log to evolve.csv
+ s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
+ with open(evolve_csv, 'a') as f:
+ f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
+
+ # Save yaml
+ with open(evolve_yaml, 'w') as f:
+ data = pd.read_csv(evolve_csv)
+ data = data.rename(columns=lambda x: x.strip()) # strip keys
+ i = np.argmax(fitness(data.values[:, :4])) #
+ generations = len(data)
+ f.write('# YOLOv5 Hyperparameter Evolution Results\n' + f'# Best generation: {i}\n' +
+ f'# Last generation: {generations - 1}\n' + '# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) +
+ '\n' + '# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
+ yaml.safe_dump(data.loc[i][7:].to_dict(), f, sort_keys=False)
+
+ # Print to screen
+ LOGGER.info(prefix + f'{generations} generations finished, current result:\n' + prefix +
+ ', '.join(f'{x.strip():>20s}' for x in keys) + '\n' + prefix + ', '.join(f'{x:20.5g}'
+ for x in vals) + '\n\n')
+
+ if bucket:
+ os.system(f'gsutil cp {evolve_csv} {evolve_yaml} gs://{bucket}') # upload
+
+
+def apply_classifier(x, model, img, im0):
+ # Apply a second stage classifier to YOLO outputs
+ # Example model = torchvision.models.__dict__['efficientnet_b0'](pretrained=True).to(device).eval()
+ im0 = [im0] if isinstance(im0, np.ndarray) else im0
+ for i, d in enumerate(x): # per image
+ if d is not None and len(d):
+ d = d.clone()
+
+ # Reshape and pad cutouts
+ b = xyxy2xywh(d[:, :4]) # boxes
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
+ b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
+ d[:, :4] = xywh2xyxy(b).long()
+
+ # Rescale boxes from img_size to im0 size
+ scale_coords(img.shape[2:], d[:, :4], im0[i].shape)
+
+ # Classes
+ pred_cls1 = d[:, 5].long()
+ ims = []
+ for a in d:
+ cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
+ im = cv2.resize(cutout, (224, 224)) # BGR
+
+ im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
+ im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ ims.append(im)
+
+ pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
+ x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
+
+ return x
+
+
+def increment_path(path, exist_ok=False, sep='', mkdir=False):
+ # Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
+ path = Path(path) # os-agnostic
+ if path.exists() and not exist_ok:
+ path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
+
+ # Method 1
+ for n in range(2, 9999):
+ p = f'{path}{sep}{n}{suffix}' # increment path
+ if not os.path.exists(p): #
+ break
+ path = Path(p)
+
+ # Method 2 (deprecated)
+ # dirs = glob.glob(f"{path}{sep}*") # similar paths
+ # matches = [re.search(rf"{path.stem}{sep}(\d+)", d) for d in dirs]
+ # i = [int(m.groups()[0]) for m in matches if m] # indices
+ # n = max(i) + 1 if i else 2 # increment number
+ # path = Path(f"{path}{sep}{n}{suffix}") # increment path
+
+ if mkdir:
+ path.mkdir(parents=True, exist_ok=True) # make directory
+
+ return path
+
+
+# OpenCV Chinese-friendly functions ------------------------------------------------------------------------------------
+imshow_ = cv2.imshow # copy to avoid recursion errors
+
+
+def imread(path, flags=cv2.IMREAD_COLOR):
+ return cv2.imdecode(np.fromfile(path, np.uint8), flags)
+
+
+def imwrite(path, im):
+ try:
+ cv2.imencode(Path(path).suffix, im)[1].tofile(path)
+ return True
+ except Exception:
+ return False
+
+
+def imshow(path, im):
+ imshow_(path.encode('unicode_escape').decode(), im)
+
+
+cv2.imread, cv2.imwrite, cv2.imshow = imread, imwrite, imshow # redefine
+
+# Variables ------------------------------------------------------------------------------------------------------------
+NCOLS = 0 if is_docker() else shutil.get_terminal_size().columns # terminal window size for tqdm
diff --git a/utils/google_app_engine/Dockerfile b/utils/google_app_engine/Dockerfile
new file mode 100755
index 0000000..0155618
--- /dev/null
+++ b/utils/google_app_engine/Dockerfile
@@ -0,0 +1,25 @@
+FROM gcr.io/google-appengine/python
+
+# Create a virtualenv for dependencies. This isolates these packages from
+# system-level packages.
+# Use -p python3 or -p python3.7 to select python version. Default is version 2.
+RUN virtualenv /env -p python3
+
+# Setting these environment variables are the same as running
+# source /env/bin/activate.
+ENV VIRTUAL_ENV /env
+ENV PATH /env/bin:$PATH
+
+RUN apt-get update && apt-get install -y python-opencv
+
+# Copy the application's requirements.txt and run pip to install all
+# dependencies into the virtualenv.
+ADD requirements.txt /app/requirements.txt
+RUN pip install -r /app/requirements.txt
+
+# Add the application source code.
+ADD . /app
+
+# Run a WSGI server to serve the application. gunicorn must be declared as
+# a dependency in requirements.txt.
+CMD gunicorn -b :$PORT main:app
diff --git a/utils/google_app_engine/additional_requirements.txt b/utils/google_app_engine/additional_requirements.txt
new file mode 100755
index 0000000..42d7ffc
--- /dev/null
+++ b/utils/google_app_engine/additional_requirements.txt
@@ -0,0 +1,4 @@
+# add these requirements in your app on top of the existing ones
+pip==21.1
+Flask==1.0.2
+gunicorn==19.9.0
diff --git a/utils/google_app_engine/app.yaml b/utils/google_app_engine/app.yaml
new file mode 100755
index 0000000..5056b7c
--- /dev/null
+++ b/utils/google_app_engine/app.yaml
@@ -0,0 +1,14 @@
+runtime: custom
+env: flex
+
+service: yolov5app
+
+liveness_check:
+ initial_delay_sec: 600
+
+manual_scaling:
+ instances: 1
+resources:
+ cpu: 1
+ memory_gb: 4
+ disk_size_gb: 20
diff --git a/utils/loggers/__init__.py b/utils/loggers/__init__.py
new file mode 100755
index 0000000..d46be8e
--- /dev/null
+++ b/utils/loggers/__init__.py
@@ -0,0 +1,235 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Logging utils
+"""
+
+import os
+import warnings
+
+import pkg_resources as pkg
+import torch
+from torch.utils.tensorboard import SummaryWriter
+
+from utils.general import colorstr, cv2
+from utils.loggers.clearml.clearml_utils import ClearmlLogger
+from utils.loggers.wandb.wandb_utils import WandbLogger
+from utils.plots import plot_images, plot_results
+from utils.torch_utils import de_parallel
+
+LOGGERS = ('csv', 'tb', 'wandb', 'clearml') # *.csv, TensorBoard, Weights & Biases, ClearML
+RANK = int(os.getenv('RANK', -1))
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+ if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.2') and RANK in {0, -1}:
+ try:
+ wandb_login_success = wandb.login(timeout=30)
+ except wandb.errors.UsageError: # known non-TTY terminal issue
+ wandb_login_success = False
+ if not wandb_login_success:
+ wandb = None
+except (ImportError, AssertionError):
+ wandb = None
+
+try:
+ import clearml
+
+ assert hasattr(clearml, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ clearml = None
+
+
+class Loggers():
+ # YOLOv5 Loggers class
+ def __init__(self, save_dir=None, weights=None, opt=None, hyp=None, logger=None, include=LOGGERS):
+ self.save_dir = save_dir
+ self.weights = weights
+ self.opt = opt
+ self.hyp = hyp
+ self.logger = logger # for printing results to console
+ self.include = include
+ self.keys = [
+ 'train/box_loss',
+ 'train/obj_loss',
+ 'train/cls_loss', # train loss
+ 'metrics/precision',
+ 'metrics/recall',
+ 'metrics/mAP_0.5',
+ 'metrics/mAP_0.5:0.95', # metrics
+ 'val/box_loss',
+ 'val/obj_loss',
+ 'val/cls_loss', # val loss
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2'] # params
+ self.best_keys = ['best/epoch', 'best/precision', 'best/recall', 'best/mAP_0.5', 'best/mAP_0.5:0.95']
+ for k in LOGGERS:
+ setattr(self, k, None) # init empty logger dictionary
+ self.csv = True # always log to csv
+
+ # Messages
+ if not wandb:
+ prefix = colorstr('Weights & Biases: ')
+ s = f"{prefix}run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases"
+ self.logger.info(s)
+ if not clearml:
+ prefix = colorstr('ClearML: ')
+ s = f"{prefix}run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 runs in ClearML"
+ self.logger.info(s)
+
+ # TensorBoard
+ s = self.save_dir
+ if 'tb' in self.include and (not self.opt.evolve or self.opt.optuna):
+ prefix = colorstr('TensorBoard: ')
+ self.logger.info(f"{prefix}Start with 'tensorboard --logdir {s.parent}', view at http://localhost:6006/")
+ self.tb = SummaryWriter(str(s))
+
+ # W&B
+ if wandb and 'wandb' in self.include:
+ wandb_artifact_resume = isinstance(self.opt.resume, str) and self.opt.resume.startswith('wandb-artifact://')
+ run_id = torch.load(self.weights).get('wandb_id') if self.opt.resume and not wandb_artifact_resume else None
+ self.opt.hyp = self.hyp # add hyperparameters
+ self.wandb = WandbLogger(self.opt, run_id)
+ # temp warn. because nested artifacts not supported after 0.12.10
+ if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.11'):
+ s = "YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected."
+ self.logger.warning(s)
+ else:
+ self.wandb = None
+
+ # ClearML
+ if clearml and 'clearml' in self.include:
+ self.clearml = ClearmlLogger(self.opt, self.hyp)
+ else:
+ self.clearml = None
+
+ def on_train_start(self):
+ # Callback runs on train start
+ pass
+
+ def on_pretrain_routine_end(self):
+ # Callback runs on pre-train routine end
+ paths = self.save_dir.glob('*labels*.jpg') # training labels
+ if self.wandb:
+ self.wandb.log({"Labels": [wandb.Image(str(x), caption=x.name) for x in paths]})
+ if self.clearml:
+ pass # ClearML saves these images automatically using hooks
+
+ def on_train_batch_end(self, ni, model, imgs, targets, paths, plots):
+ # Callback runs on train batch end
+ # ni: number integrated batches (since train start)
+ if plots:
+ if ni == 0:
+ if self.tb and not self.opt.sync_bn: # --sync known issue https://github.com/ultralytics/yolov5/issues/3754
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress jit trace warning
+ self.tb.add_graph(torch.jit.trace(de_parallel(model), imgs[0:1], strict=False), [])
+ if ni < 3:
+ f = self.save_dir / f'train_batch{ni}.jpg' # filename
+ plot_images(imgs, targets, paths, f)
+ if (self.wandb or self.clearml) and ni == 10:
+ files = sorted(self.save_dir.glob('train*.jpg'))
+ if self.wandb:
+ self.wandb.log({'Mosaics': [wandb.Image(str(f), caption=f.name) for f in files if f.exists()]})
+ if self.clearml:
+ self.clearml.log_debug_samples(files, title='Mosaics')
+
+ def on_train_epoch_end(self, epoch):
+ # Callback runs on train epoch end
+ if self.wandb:
+ self.wandb.current_epoch = epoch + 1
+
+ def on_val_image_end(self, pred, predn, path, names, im):
+ # Callback runs on val image end
+ if self.wandb:
+ self.wandb.val_one_image(pred, predn, path, names, im)
+ if self.clearml:
+ self.clearml.log_image_with_boxes(path, pred, names, im)
+
+ def on_val_end(self):
+ # Callback runs on val end
+ if self.wandb or self.clearml:
+ files = sorted(self.save_dir.glob('val*.jpg'))
+ if self.wandb:
+ self.wandb.log({"Validation": [wandb.Image(str(f), caption=f.name) for f in files]})
+ if self.clearml:
+ self.clearml.log_debug_samples(files, title='Validation')
+
+ def on_fit_epoch_end(self, vals, epoch, best_fitness, fi):
+ # Callback runs at the end of each fit (train+val) epoch
+ x = dict(zip(self.keys, vals))
+ if self.csv:
+ file = self.save_dir / 'results.csv'
+ n = len(x) + 1 # number of cols
+ s = '' if file.exists() else (('%20s,' * n % tuple(['epoch'] + self.keys)).rstrip(',') + '\n') # add header
+ with open(file, 'a') as f:
+ f.write(s + ('%20.5g,' * n % tuple([epoch] + vals)).rstrip(',') + '\n')
+
+ if self.tb:
+ for k, v in x.items():
+ self.tb.add_scalar(k, v, epoch)
+ elif self.clearml: # log to ClearML if TensorBoard not used
+ for k, v in x.items():
+ title, series = k.split('/')
+ self.clearml.task.get_logger().report_scalar(title, series, v, epoch)
+
+ if self.wandb:
+ if best_fitness == fi:
+ best_results = [epoch] + vals[3:7]
+ for i, name in enumerate(self.best_keys):
+ self.wandb.wandb_run.summary[name] = best_results[i] # log best results in the summary
+ self.wandb.log(x)
+ self.wandb.end_epoch(best_result=best_fitness == fi)
+
+ if self.clearml:
+ self.clearml.current_epoch_logged_images = set() # reset epoch image limit
+ self.clearml.current_epoch += 1
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ # Callback runs on model save event
+ if self.wandb:
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.wandb.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ if self.clearml:
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.clearml.task.update_output_model(model_path=str(last),
+ model_name='Latest Model',
+ auto_delete_file=False)
+
+ def on_train_end(self, last, best, plots, epoch, results):
+ # Callback runs on training end
+ if plots:
+ plot_results(file=self.save_dir / 'results.csv') # save results.png
+ files = ['results.png', 'confusion_matrix.png', *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(self.save_dir / f) for f in files if (self.save_dir / f).exists()] # filter
+ self.logger.info(f"Results saved to {colorstr('bold', self.save_dir)}")
+
+ if self.tb and not self.clearml: # These images are already captured by ClearML by now, we don't want doubles
+ for f in files:
+ self.tb.add_image(f.stem, cv2.imread(str(f))[..., ::-1], epoch, dataformats='HWC')
+
+ if self.wandb:
+ self.wandb.log(dict(zip(self.keys[3:10], results)))
+ self.wandb.log({"Results": [wandb.Image(str(f), caption=f.name) for f in files]})
+ # Calling wandb.log. TODO: Refactor this into WandbLogger.log_model
+ if not self.opt.evolve:
+ wandb.log_artifact(str(best if best.exists() else last),
+ type='model',
+ name=f'run_{self.wandb.wandb_run.id}_model',
+ aliases=['latest', 'best', 'stripped'])
+ self.wandb.finish_run()
+
+ if self.clearml:
+ # Save the best model here
+ if not self.opt.evolve:
+ self.clearml.task.update_output_model(model_path=str(best if best.exists() else last),
+ name='Best Model', auto_delete_file=False)
+
+ def on_params_update(self, params):
+ # Update hyperparams or configs of the experiment
+ # params: A dict containing {param: value} pairs
+ if self.wandb:
+ self.wandb.wandb_run.config.update(params, allow_val_change=True)
diff --git a/utils/loggers/clearml/README.md b/utils/loggers/clearml/README.md
new file mode 100755
index 0000000..64eef6b
--- /dev/null
+++ b/utils/loggers/clearml/README.md
@@ -0,0 +1,222 @@
+# ClearML Integration
+
+
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below for PyTorch Hub, CI, reproducing results, profiling speeds, VOC training, classification training and TensorRT example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "import torch\n",
+ "\n",
+ "# PyTorch Hub Model\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom\n",
+ "\n",
+ "# Images\n",
+ "img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list\n",
+ "\n",
+ "# Inference\n",
+ "results = model(img)\n",
+ "\n",
+ "# Results\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FGH0ZjkGjejy"
+ },
+ "source": [
+ "# YOLOv5 CI\n",
+ "%%shell\n",
+ "rm -rf runs # remove runs/\n",
+ "m=yolov5n # official weights\n",
+ "b=runs/train/exp/weights/best # best.pt checkpoint\n",
+ "python train.py --imgsz 64 --batch 32 --weights $m.pt --cfg $m.yaml --epochs 1 --device 0 # train\n",
+ "for d in 0 cpu; do # devices\n",
+ " for w in $m $b; do # weights\n",
+ " python val.py --imgsz 64 --batch 32 --weights $w.pt --device $d # val\n",
+ " python detect.py --imgsz 64 --weights $w.pt --device $d # detect\n",
+ " done\n",
+ "done\n",
+ "python hubconf.py --model $m # hub\n",
+ "python models/tf.py --weights $m.pt # build TF model\n",
+ "python models/yolo.py --cfg $m.yaml # build PyTorch model\n",
+ "python export.py --weights $m.pt --img 64 --include torchscript # export"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mcKoSIK2WSzj"
+ },
+ "source": [
+ "# Reproduce\n",
+ "for x in (f'yolov5{x}' for x in 'nsmlx'):\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --task speed # speed\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gogI-kwi3Tye"
+ },
+ "source": [
+ "# Profile\n",
+ "from utils.torch_utils import profile\n",
+ "\n",
+ "m1 = lambda x: x * torch.sigmoid(x)\n",
+ "m2 = torch.nn.SiLU()\n",
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BSgFCAcMbk1R"
+ },
+ "source": [
+ "# VOC\n",
+ "for b, m in zip([64, 64, 64, 32, 16], [f'yolov5{x}' for x in 'nsmlx']): # batch, model\n",
+ " !python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.VOC.yaml --project VOC --name {m} --cache"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "source": [
+ "# Classification\n",
+ "for m in [*(f'yolov5{x}.pt' for x in 'nsmlx'), 'resnet50.pt', 'efficientnet_b0.pt']:\n",
+ " for d in 'mnist', 'fashion-mnist', 'cifar10', 'cifar100', 'imagenette160', 'imagenette320', 'imagenette', 'imagewoof160', 'imagewoof320', 'imagewoof':\n",
+ " !python classify/train.py --model {m} --data {d} --epochs 10 --project YOLOv5-cls --name {m}-{d}"
+ ],
+ "metadata": {
+ "id": "UWGH7H6yakVl"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "VTRwsvA9u7ln"
+ },
+ "source": [
+ "# TensorRT \n",
+ "!pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # install\n",
+ "!python export.py --weights yolov5s.pt --include engine --imgsz 640 --device 0 # export\n",
+ "!python detect.py --weights yolov5s.engine --imgsz 640 --device 0 # inference"
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
\ No newline at end of file
diff --git a/utils/__init__.py b/utils/__init__.py
new file mode 100755
index 0000000..a63c473
--- /dev/null
+++ b/utils/__init__.py
@@ -0,0 +1,36 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+utils/initialization
+"""
+
+
+def notebook_init(verbose=True):
+ # Check system software and hardware
+ print('Checking setup...')
+
+ import os
+ import shutil
+
+ from utils.general import check_requirements, emojis, is_colab
+ from utils.torch_utils import select_device # imports
+
+ check_requirements(('psutil', 'IPython'))
+ import psutil
+ from IPython import display # to display images and clear console output
+
+ if is_colab():
+ shutil.rmtree('/content/sample_data', ignore_errors=True) # remove colab /sample_data directory
+
+ # System info
+ if verbose:
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ ram = psutil.virtual_memory().total
+ total, used, free = shutil.disk_usage("/")
+ display.clear_output()
+ s = f'({os.cpu_count()} CPUs, {ram / gb:.1f} GB RAM, {(total - free) / gb:.1f}/{total / gb:.1f} GB disk)'
+ else:
+ s = ''
+
+ select_device(newline=False)
+ print(emojis(f'Setup complete ✅ {s}'))
+ return display
diff --git a/utils/activations.py b/utils/activations.py
new file mode 100755
index 0000000..084ce8c
--- /dev/null
+++ b/utils/activations.py
@@ -0,0 +1,103 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Activation functions
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class SiLU(nn.Module):
+ # SiLU activation https://arxiv.org/pdf/1606.08415.pdf
+ @staticmethod
+ def forward(x):
+ return x * torch.sigmoid(x)
+
+
+class Hardswish(nn.Module):
+ # Hard-SiLU activation
+ @staticmethod
+ def forward(x):
+ # return x * F.hardsigmoid(x) # for TorchScript and CoreML
+ return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
+
+
+class Mish(nn.Module):
+ # Mish activation https://github.com/digantamisra98/Mish
+ @staticmethod
+ def forward(x):
+ return x * F.softplus(x).tanh()
+
+
+class MemoryEfficientMish(nn.Module):
+ # Mish activation memory-efficient
+ class F(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, x):
+ ctx.save_for_backward(x)
+ return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x = ctx.saved_tensors[0]
+ sx = torch.sigmoid(x)
+ fx = F.softplus(x).tanh()
+ return grad_output * (fx + x * sx * (1 - fx * fx))
+
+ def forward(self, x):
+ return self.F.apply(x)
+
+
+class FReLU(nn.Module):
+ # FReLU activation https://arxiv.org/abs/2007.11824
+ def __init__(self, c1, k=3): # ch_in, kernel
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
+ self.bn = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ return torch.max(x, self.bn(self.conv(x)))
+
+
+class AconC(nn.Module):
+ r""" ACON activation (activate or not)
+ AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
+ according to "Activate or Not: Learning Customized Activation" .
+ """
+
+ def __init__(self, c1):
+ super().__init__()
+ self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
+
+ def forward(self, x):
+ dpx = (self.p1 - self.p2) * x
+ return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
+
+
+class MetaAconC(nn.Module):
+ r""" ACON activation (activate or not)
+ MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
+ according to "Activate or Not: Learning Customized Activation" .
+ """
+
+ def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
+ super().__init__()
+ c2 = max(r, c1 // r)
+ self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
+ self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
+ self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
+ # self.bn1 = nn.BatchNorm2d(c2)
+ # self.bn2 = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
+ # batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
+ # beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
+ beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
+ dpx = (self.p1 - self.p2) * x
+ return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
diff --git a/utils/augmentations.py b/utils/augmentations.py
new file mode 100755
index 0000000..30139aa
--- /dev/null
+++ b/utils/augmentations.py
@@ -0,0 +1,289 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from utils.general import LOGGER, check_version, colorstr, resample_segments, segment2box
+from utils.metrics import bbox_ioa
+
+
+class Albumentations:
+ # YOLOv5 Albumentations class (optional, only used if package is installed)
+ def __init__(self, hyp):
+ self.transform = None
+ try:
+ import albumentations as A
+ check_version(A.__version__, '1.0.3', hard=True) # version requirement
+
+ T = [
+ A.Blur(p=hyp.get('blur', 0.01)),
+ A.MedianBlur(p=hyp.get('median_blur', 0.01)),
+ A.ToGray(p=hyp.get('gray', 0.01)),
+ A.CLAHE(p=hyp.get('clahe', 0.01)),
+ A.RandomBrightnessContrast(p=hyp.get('brightness_contrast', 0.01)),
+ A.RandomGamma(p=hyp.get('random_gamma', 0.01)),
+ A.ImageCompression(quality_lower=75, p=hyp.get('image_compression', 0.01))] # transforms
+ self.transform = A.Compose(T, bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
+
+ LOGGER.info(colorstr('albumentations: ') + ', '.join(f'{x}' for x in self.transform.transforms if x.p))
+ except ImportError: # package not installed, skip
+ pass
+ except Exception as e:
+ LOGGER.info(colorstr('albumentations: ') + f'{e}')
+
+ def __call__(self, im, labels, p=1.0):
+ if self.transform and random.random() < p:
+ new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
+ im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
+ return im, labels
+
+
+def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
+ # HSV color-space augmentation
+ if hgain or sgain or vgain:
+ r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
+ hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
+ dtype = im.dtype # uint8
+
+ x = np.arange(0, 256, dtype=r.dtype)
+ lut_hue = ((x * r[0]) % 180).astype(dtype)
+ lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
+ lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
+
+ im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
+ cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
+
+
+def hist_equalize(im, clahe=True, bgr=False):
+ # Equalize histogram on BGR image 'im' with im.shape(n,m,3) and range 0-255
+ yuv = cv2.cvtColor(im, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
+ if clahe:
+ c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
+ yuv[:, :, 0] = c.apply(yuv[:, :, 0])
+ else:
+ yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
+ return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
+
+
+def replicate(im, labels):
+ # Replicate labels
+ h, w = im.shape[:2]
+ boxes = labels[:, 1:].astype(int)
+ x1, y1, x2, y2 = boxes.T
+ s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels)
+ for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices
+ x1b, y1b, x2b, y2b = boxes[i]
+ bh, bw = y2b - y1b, x2b - x1b
+ yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
+ x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
+ im[y1a:y2a, x1a:x2a] = im[y1b:y2b, x1b:x2b] # im4[ymin:ymax, xmin:xmax]
+ labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
+
+ return im, labels
+
+
+def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
+ # Resize and pad image while meeting stride-multiple constraints
+ shape = im.shape[:2] # current shape [height, width]
+ if isinstance(new_shape, int):
+ new_shape = (new_shape, new_shape)
+
+ # Scale ratio (new / old)
+ r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
+ if not scaleup: # only scale down, do not scale up (for better val mAP)
+ r = min(r, 1.0)
+
+ # Compute padding
+ ratio = r, r # width, height ratios
+ new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
+ dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
+ if auto: # minimum rectangle
+ dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
+ elif scaleFill: # stretch
+ dw, dh = 0.0, 0.0
+ new_unpad = (new_shape[1], new_shape[0])
+ ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
+
+ dw /= 2 # divide padding into 2 sides
+ dh /= 2
+
+ if shape[::-1] != new_unpad: # resize
+ im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
+ top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
+ left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
+ im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
+ return im, ratio, (dw, dh)
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ rotation_prob=1.0,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(0.1, 0.1), scale=(0.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ rotation = random.random() < rotation_prob
+ if rotation:
+ a = random.uniform(-degrees, degrees)
+ else:
+ a = 0
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
+ T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ if n:
+ use_segments = any(x.any() for x in segments)
+ new = np.zeros((n, 4))
+ if use_segments: # warp segments
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+
+ else: # warp boxes
+ xy = np.ones((n * 4, 3))
+ xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
+
+ # create new boxes
+ x = xy[:, [0, 2, 4, 6]]
+ y = xy[:, [1, 3, 5, 7]]
+ new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
+
+ # clip
+ new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
+ new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+
+ return im, targets
+
+
+def copy_paste(im, labels, segments, p=0.5):
+ # Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
+ n = len(segments)
+ if p and n:
+ h, w, c = im.shape # height, width, channels
+ im_new = np.zeros(im.shape, np.uint8)
+ for j in random.sample(range(n), k=round(p * n)):
+ l, s = labels[j], segments[j]
+ box = w - l[3], l[2], w - l[1], l[4]
+ ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
+ if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
+ labels = np.concatenate((labels, [[l[0], *box]]), 0)
+ segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
+ cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
+
+ result = cv2.bitwise_and(src1=im, src2=im_new)
+ result = cv2.flip(result, 1) # augment segments (flip left-right)
+ i = result > 0 # pixels to replace
+ # i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
+ im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
+
+ return im, labels, segments
+
+
+def cutout(im, labels, p=0.5):
+ # Applies image cutout augmentation https://arxiv.org/abs/1708.04552
+ if random.random() < p:
+ h, w = im.shape[:2]
+ scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
+ for s in scales:
+ mask_h = random.randint(1, int(h * s)) # create random masks
+ mask_w = random.randint(1, int(w * s))
+
+ # box
+ xmin = max(0, random.randint(0, w) - mask_w // 2)
+ ymin = max(0, random.randint(0, h) - mask_h // 2)
+ xmax = min(w, xmin + mask_w)
+ ymax = min(h, ymin + mask_h)
+
+ # apply random color mask
+ im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
+
+ # return unobscured labels
+ if len(labels) and s > 0.03:
+ box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
+ ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
+ labels = labels[ioa < 0.60] # remove >60% obscured labels
+
+ return labels
+
+
+def mixup(im, labels, im2, labels2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ return im, labels
+
+
+def box_candidates(box1, box2, wh_thr=2, ar_thr=100, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
+ # Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
+ w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
+ w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
+ ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
+ return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
diff --git a/utils/autoanchor.py b/utils/autoanchor.py
new file mode 100755
index 0000000..f222220
--- /dev/null
+++ b/utils/autoanchor.py
@@ -0,0 +1,170 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+AutoAnchor utils
+"""
+
+import random
+
+import numpy as np
+import torch
+import yaml
+from tqdm import tqdm
+
+from utils.general import LOGGER, colorstr
+
+PREFIX = colorstr('AutoAnchor: ')
+
+
+def check_anchor_order(m):
+ # Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
+ a = m.anchors.prod(-1).mean(-1).view(-1) # mean anchor area per output layer
+ da = a[-1] - a[0] # delta a
+ ds = m.stride[-1] - m.stride[0] # delta s
+ if da and (da.sign() != ds.sign()): # same order
+ LOGGER.info(f'{PREFIX}Reversing anchor order')
+ m.anchors[:] = m.anchors.flip(0)
+
+
+def check_anchors(dataset, model, thr=4.0, imgsz=640):
+ # Check anchor fit to data, recompute if necessary
+ m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
+ shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
+ scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
+ wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
+
+ def metric(k): # compute metric
+ r = wh[:, None] / k[None]
+ x = torch.min(r, 1 / r).min(2)[0] # ratio metric
+ best = x.max(1)[0] # best_x
+ aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
+ bpr = (best > 1 / thr).float().mean() # best possible recall
+ return bpr, aat
+
+ stride = m.stride.to(m.anchors.device).view(-1, 1, 1) # model strides
+ anchors = m.anchors.clone() * stride # current anchors
+ bpr, aat = metric(anchors.cpu().view(-1, 2))
+ s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
+ if bpr > 0.98: # threshold to recompute
+ LOGGER.info(f'{s}Current anchors are a good fit to dataset ✅')
+ else:
+ LOGGER.info(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...')
+ na = m.anchors.numel() // 2 # number of anchors
+ try:
+ anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
+ except Exception as e:
+ LOGGER.info(f'{PREFIX}ERROR: {e}')
+ new_bpr = metric(anchors)[0]
+ if new_bpr > bpr: # replace anchors
+ anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
+ m.anchors[:] = anchors.clone().view_as(m.anchors)
+ check_anchor_order(m) # must be in pixel-space (not grid-space)
+ m.anchors /= stride
+ s = f'{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)'
+ else:
+ s = f'{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)'
+ LOGGER.info(s)
+
+
+def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
+ """ Creates kmeans-evolved anchors from training dataset
+
+ Arguments:
+ dataset: path to data.yaml, or a loaded dataset
+ n: number of anchors
+ img_size: image size used for training
+ thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
+ gen: generations to evolve anchors using genetic algorithm
+ verbose: print all results
+
+ Return:
+ k: kmeans evolved anchors
+
+ Usage:
+ from utils.autoanchor import *; _ = kmean_anchors()
+ """
+ from scipy.cluster.vq import kmeans
+
+ npr = np.random
+ thr = 1 / thr
+
+ def metric(k, wh): # compute metrics
+ r = wh[:, None] / k[None]
+ x = torch.min(r, 1 / r).min(2)[0] # ratio metric
+ # x = wh_iou(wh, torch.tensor(k)) # iou metric
+ return x, x.max(1)[0] # x, best_x
+
+ def anchor_fitness(k): # mutation fitness
+ _, best = metric(torch.tensor(k, dtype=torch.float32), wh)
+ return (best * (best > thr).float()).mean() # fitness
+
+ def print_results(k, verbose=True):
+ k = k[np.argsort(k.prod(1))] # sort small to large
+ x, best = metric(k, wh0)
+ bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
+ s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
+ f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
+ f'past_thr={x[x > thr].mean():.3f}-mean: '
+ for x in k:
+ s += '%i,%i, ' % (round(x[0]), round(x[1]))
+ if verbose:
+ LOGGER.info(s[:-2])
+ return k
+
+ if isinstance(dataset, str): # *.yaml file
+ with open(dataset, errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # model dict
+ from utils.dataloaders import LoadImagesAndLabels
+ dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
+
+ # Get label wh
+ shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
+ wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
+
+ # Filter
+ i = (wh0 < 3.0).any(1).sum()
+ if i:
+ LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found: {i} of {len(wh0)} labels are < 3 pixels in size')
+ wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
+ # wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
+
+ # Kmeans init
+ try:
+ LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
+ assert n <= len(wh) # apply overdetermined constraint
+ s = wh.std(0) # sigmas for whitening
+ k = kmeans(wh / s, n, iter=30)[0] * s # points
+ assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
+ except Exception:
+ LOGGER.warning(f'{PREFIX}WARNING: switching strategies from kmeans to random init')
+ k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
+ wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
+ k = print_results(k, verbose=False)
+
+ # Plot
+ # k, d = [None] * 20, [None] * 20
+ # for i in tqdm(range(1, 21)):
+ # k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
+ # fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
+ # ax = ax.ravel()
+ # ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
+ # fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
+ # ax[0].hist(wh[wh[:, 0]<100, 0],400)
+ # ax[1].hist(wh[wh[:, 1]<100, 1],400)
+ # fig.savefig('wh.png', dpi=200)
+
+ # Evolve
+ f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
+ pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ for _ in pbar:
+ v = np.ones(sh)
+ while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
+ v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
+ kg = (k.copy() * v).clip(min=2.0)
+ fg = anchor_fitness(kg)
+ if fg > f:
+ f, k = fg, kg.copy()
+ pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
+ if verbose:
+ print_results(k, verbose)
+
+ return print_results(k)
diff --git a/utils/autobatch.py b/utils/autobatch.py
new file mode 100755
index 0000000..c231d24
--- /dev/null
+++ b/utils/autobatch.py
@@ -0,0 +1,66 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Auto-batch utils
+"""
+
+from copy import deepcopy
+
+import numpy as np
+import torch
+
+from utils.general import LOGGER, colorstr
+from utils.torch_utils import profile
+
+
+def check_train_batch_size(model, imgsz=640, amp=True):
+ # Check YOLOv5 training batch size
+ with torch.cuda.amp.autocast(amp):
+ return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
+
+
+def autobatch(model, imgsz=640, fraction=0.9, batch_size=16):
+ # Automatically estimate best batch size to use `fraction` of available CUDA memory
+ # Usage:
+ # import torch
+ # from utils.autobatch import autobatch
+ # model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False)
+ # print(autobatch(model))
+
+ # Check device
+ prefix = colorstr('AutoBatch: ')
+ LOGGER.info(f'{prefix}Computing optimal batch size for --imgsz {imgsz}')
+ device = next(model.parameters()).device # get model device
+ if device.type == 'cpu':
+ LOGGER.info(f'{prefix}CUDA not detected, using default CPU batch-size {batch_size}')
+ return batch_size
+
+ # Inspect CUDA memory
+ gb = 1 << 30 # bytes to GiB (1024 ** 3)
+ d = str(device).upper() # 'CUDA:0'
+ properties = torch.cuda.get_device_properties(device) # device properties
+ t = properties.total_memory / gb # GiB total
+ r = torch.cuda.memory_reserved(device) / gb # GiB reserved
+ a = torch.cuda.memory_allocated(device) / gb # GiB allocated
+ f = t - (r + a) # GiB free
+ LOGGER.info(f'{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
+
+ # Profile batch sizes
+ batch_sizes = [1, 2, 4, 8, 16]
+ try:
+ img = [torch.zeros(b, 3, imgsz, imgsz) for b in batch_sizes]
+ results = profile(img, model, n=3, device=device)
+ except Exception as e:
+ LOGGER.warning(f'{prefix}{e}')
+
+ # Fit a solution
+ y = [x[2] for x in results if x] # memory [2]
+ p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
+ b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
+ if None in results: # some sizes failed
+ i = results.index(None) # first fail index
+ if b >= batch_sizes[i]: # y intercept above failure point
+ b = batch_sizes[max(i - 1, 0)] # select prior safe point
+
+ fraction = np.polyval(p, b) / t # actual fraction predicted
+ LOGGER.info(f'{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%) ✅')
+ return b
diff --git a/utils/aws/__init__.py b/utils/aws/__init__.py
new file mode 100755
index 0000000..e69de29
diff --git a/utils/aws/mime.sh b/utils/aws/mime.sh
new file mode 100755
index 0000000..c319a83
--- /dev/null
+++ b/utils/aws/mime.sh
@@ -0,0 +1,26 @@
+# AWS EC2 instance startup 'MIME' script https://aws.amazon.com/premiumsupport/knowledge-center/execute-user-data-ec2/
+# This script will run on every instance restart, not only on first start
+# --- DO NOT COPY ABOVE COMMENTS WHEN PASTING INTO USERDATA ---
+
+Content-Type: multipart/mixed; boundary="//"
+MIME-Version: 1.0
+
+--//
+Content-Type: text/cloud-config; charset="us-ascii"
+MIME-Version: 1.0
+Content-Transfer-Encoding: 7bit
+Content-Disposition: attachment; filename="cloud-config.txt"
+
+#cloud-config
+cloud_final_modules:
+- [scripts-user, always]
+
+--//
+Content-Type: text/x-shellscript; charset="us-ascii"
+MIME-Version: 1.0
+Content-Transfer-Encoding: 7bit
+Content-Disposition: attachment; filename="userdata.txt"
+
+#!/bin/bash
+# --- paste contents of userdata.sh here ---
+--//
diff --git a/utils/aws/resume.py b/utils/aws/resume.py
new file mode 100755
index 0000000..b21731c
--- /dev/null
+++ b/utils/aws/resume.py
@@ -0,0 +1,40 @@
+# Resume all interrupted trainings in yolov5/ dir including DDP trainings
+# Usage: $ python utils/aws/resume.py
+
+import os
+import sys
+from pathlib import Path
+
+import torch
+import yaml
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[2] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+port = 0 # --master_port
+path = Path('').resolve()
+for last in path.rglob('*/**/last.pt'):
+ ckpt = torch.load(last)
+ if ckpt['optimizer'] is None:
+ continue
+
+ # Load opt.yaml
+ with open(last.parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = yaml.safe_load(f)
+
+ # Get device count
+ d = opt['device'].split(',') # devices
+ nd = len(d) # number of devices
+ ddp = nd > 1 or (nd == 0 and torch.cuda.device_count() > 1) # distributed data parallel
+
+ if ddp: # multi-GPU
+ port += 1
+ cmd = f'python -m torch.distributed.run --nproc_per_node {nd} --master_port {port} train.py --resume {last}'
+ else: # single-GPU
+ cmd = f'python train.py --resume {last}'
+
+ cmd += ' > /dev/null 2>&1 &' # redirect output to dev/null and run in daemon thread
+ print(cmd)
+ os.system(cmd)
diff --git a/utils/aws/userdata.sh b/utils/aws/userdata.sh
new file mode 100755
index 0000000..5fc1332
--- /dev/null
+++ b/utils/aws/userdata.sh
@@ -0,0 +1,27 @@
+#!/bin/bash
+# AWS EC2 instance startup script https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/user-data.html
+# This script will run only once on first instance start (for a re-start script see mime.sh)
+# /home/ubuntu (ubuntu) or /home/ec2-user (amazon-linux) is working dir
+# Use >300 GB SSD
+
+cd home/ubuntu
+if [ ! -d yolov5 ]; then
+ echo "Running first-time script." # install dependencies, download COCO, pull Docker
+ git clone https://github.com/ultralytics/yolov5 -b master && sudo chmod -R 777 yolov5
+ cd yolov5
+ bash data/scripts/get_coco.sh && echo "COCO done." &
+ sudo docker pull ultralytics/yolov5:latest && echo "Docker done." &
+ python -m pip install --upgrade pip && pip install -r requirements.txt && python detect.py && echo "Requirements done." &
+ wait && echo "All tasks done." # finish background tasks
+else
+ echo "Running re-start script." # resume interrupted runs
+ i=0
+ list=$(sudo docker ps -qa) # container list i.e. $'one\ntwo\nthree\nfour'
+ while IFS= read -r id; do
+ ((i++))
+ echo "restarting container $i: $id"
+ sudo docker start $id
+ # sudo docker exec -it $id python train.py --resume # single-GPU
+ sudo docker exec -d $id python utils/aws/resume.py # multi-scenario
+ done <<<"$list"
+fi
diff --git a/utils/benchmarks.py b/utils/benchmarks.py
new file mode 100755
index 0000000..d412653
--- /dev/null
+++ b/utils/benchmarks.py
@@ -0,0 +1,157 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Run YOLOv5 benchmarks on all supported export formats
+
+Format | `export.py --include` | Model
+--- | --- | ---
+PyTorch | - | yolov5s.pt
+TorchScript | `torchscript` | yolov5s.torchscript
+ONNX | `onnx` | yolov5s.onnx
+OpenVINO | `openvino` | yolov5s_openvino_model/
+TensorRT | `engine` | yolov5s.engine
+CoreML | `coreml` | yolov5s.mlmodel
+TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
+TensorFlow GraphDef | `pb` | yolov5s.pb
+TensorFlow Lite | `tflite` | yolov5s.tflite
+TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
+TensorFlow.js | `tfjs` | yolov5s_web_model/
+
+Requirements:
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
+ $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
+ $ pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # TensorRT
+
+Usage:
+ $ python utils/benchmarks.py --weights yolov5s.pt --img 640
+"""
+
+import argparse
+import platform
+import sys
+import time
+from pathlib import Path
+
+import pandas as pd
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import export
+import val
+from utils import notebook_init
+from utils.general import LOGGER, check_yaml, file_size, print_args
+from utils.torch_utils import select_device
+
+
+def run(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=640, # inference size (pixels)
+ batch_size=1, # batch size
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half=False, # use FP16 half-precision inference
+ test=False, # test exports only
+ pt_only=False, # test PyTorch only
+ hard_fail=False, # throw error on benchmark failure
+):
+ y, t = [], time.time()
+ device = select_device(device)
+ for i, (name, f, suffix, cpu, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, CPU, GPU)
+ try:
+ assert i not in (9, 10), 'inference not supported' # Edge TPU and TF.js are unsupported
+ assert i != 5 or platform.system() == 'Darwin', 'inference only supported on macOS>=10.13' # CoreML
+ if 'cpu' in device.type:
+ assert cpu, 'inference not supported on CPU'
+ if 'cuda' in device.type:
+ assert gpu, 'inference not supported on GPU'
+
+ # Export
+ if f == '-':
+ w = weights # PyTorch format
+ else:
+ w = export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # all others
+ assert suffix in str(w), 'export failed'
+
+ # Validate
+ result = val.run(data, w, batch_size, imgsz, plots=False, device=device, task='benchmark', half=half)
+ metrics = result[0] # metrics (mp, mr, map50, map, *losses(box, obj, cls))
+ speeds = result[2] # times (preprocess, inference, postprocess)
+ y.append([name, round(file_size(w), 1), round(metrics[3], 4), round(speeds[1], 2)]) # MB, mAP, t_inference
+ except Exception as e:
+ if hard_fail:
+ assert type(e) is AssertionError, f'Benchmark --hard-fail for {name}: {e}'
+ LOGGER.warning(f'WARNING: Benchmark failure for {name}: {e}')
+ y.append([name, None, None, None]) # mAP, t_inference
+ if pt_only and i == 0:
+ break # break after PyTorch
+
+ # Print results
+ LOGGER.info('\n')
+ parse_opt()
+ notebook_init() # print system info
+ c = ['Format', 'Size (MB)', 'mAP@0.5:0.95', 'Inference time (ms)'] if map else ['Format', 'Export', '', '']
+ py = pd.DataFrame(y, columns=c)
+ LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
+ LOGGER.info(str(py if map else py.iloc[:, :2]))
+ return py
+
+
+def test(
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=640, # inference size (pixels)
+ batch_size=1, # batch size
+ data=ROOT / 'data/coco128.yaml', # dataset.yaml path
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half=False, # use FP16 half-precision inference
+ test=False, # test exports only
+ pt_only=False, # test PyTorch only
+ hard_fail=False, # throw error on benchmark failure
+):
+ y, t = [], time.time()
+ device = select_device(device)
+ for i, (name, f, suffix, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, gpu-capable)
+ try:
+ w = weights if f == '-' else \
+ export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # weights
+ assert suffix in str(w), 'export failed'
+ y.append([name, True])
+ except Exception:
+ y.append([name, False]) # mAP, t_inference
+
+ # Print results
+ LOGGER.info('\n')
+ parse_opt()
+ notebook_init() # print system info
+ py = pd.DataFrame(y, columns=['Format', 'Export'])
+ LOGGER.info(f'\nExports complete ({time.time() - t:.2f}s)')
+ LOGGER.info(str(py))
+ return py
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--test', action='store_true', help='test exports only')
+ parser.add_argument('--pt-only', action='store_true', help='test PyTorch only')
+ parser.add_argument('--hard-fail', action='store_true', help='throw error on benchmark failure')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ test(**vars(opt)) if opt.test else run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/utils/callbacks.py b/utils/callbacks.py
new file mode 100755
index 0000000..463ede7
--- /dev/null
+++ b/utils/callbacks.py
@@ -0,0 +1,72 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Callback utils
+"""
+
+
+class Callbacks:
+ """"
+ Handles all registered callbacks for YOLOv5 Hooks
+ """
+
+ def __init__(self):
+ # Define the available callbacks
+ self._callbacks = {
+ 'on_pretrain_routine_start': [],
+ 'on_pretrain_routine_end': [],
+ 'on_train_start': [],
+ 'on_train_epoch_start': [],
+ 'on_train_batch_start': [],
+ 'optimizer_step': [],
+ 'on_before_zero_grad': [],
+ 'on_train_batch_end': [],
+ 'on_train_epoch_end': [],
+ 'on_val_start': [],
+ 'on_val_batch_start': [],
+ 'on_val_image_end': [],
+ 'on_val_batch_end': [],
+ 'on_val_end': [],
+ 'on_fit_epoch_end': [], # fit = train + val
+ 'on_model_save': [],
+ 'after_model_save': [],
+ 'on_train_end': [],
+ 'on_params_update': [],
+ 'teardown': [],}
+ self.stop_training = False # set True to interrupt training
+
+ def register_action(self, hook, name='', callback=None):
+ """
+ Register a new action to a callback hook
+
+ Args:
+ hook: The callback hook name to register the action to
+ name: The name of the action for later reference
+ callback: The callback to fire
+ """
+ assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
+ assert callable(callback), f"callback '{callback}' is not callable"
+ self._callbacks[hook].append({'name': name, 'callback': callback})
+
+ def get_registered_actions(self, hook=None):
+ """"
+ Returns all the registered actions by callback hook
+
+ Args:
+ hook: The name of the hook to check, defaults to all
+ """
+ return self._callbacks[hook] if hook else self._callbacks
+
+ def run(self, hook, *args, **kwargs):
+ """
+ Loop through the registered actions and fire all callbacks
+
+ Args:
+ hook: The name of the hook to check, defaults to all
+ args: Arguments to receive from YOLOv5
+ kwargs: Keyword Arguments to receive from YOLOv5
+ """
+
+ assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
+
+ for logger in self._callbacks[hook]:
+ logger['callback'](*args, **kwargs)
diff --git a/utils/dataloaders.py b/utils/dataloaders.py
new file mode 100755
index 0000000..444080a
--- /dev/null
+++ b/utils/dataloaders.py
@@ -0,0 +1,1097 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Dataloaders and dataset utils
+"""
+
+import contextlib
+import glob
+import hashlib
+import json
+import math
+import os
+import random
+import shutil
+import time
+from itertools import repeat
+from multiprocessing.pool import Pool, ThreadPool
+from pathlib import Path
+from threading import Thread
+from urllib.parse import urlparse
+from zipfile import ZipFile
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+import yaml
+from PIL import ExifTags, Image, ImageOps
+from torch.utils.data import DataLoader, Dataset, dataloader, distributed
+from tqdm import tqdm
+
+from utils.augmentations import Albumentations, augment_hsv, copy_paste, letterbox, mixup, random_perspective
+from utils.general import (DATASETS_DIR, LOGGER, NUM_THREADS, check_dataset, check_requirements, check_yaml, clean_str,
+ cv2, is_colab, is_kaggle, segments2boxes, xyn2xy, xywh2xyxy, xywhn2xyxy, xyxy2xywhn)
+from utils.torch_utils import torch_distributed_zero_first
+
+# Parameters
+HELP_URL = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
+IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp' # include image suffixes
+VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes
+BAR_FORMAT = '{l_bar}{bar:10}{r_bar}{bar:-10b}' # tqdm bar format
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+
+# Get orientation exif tag
+for orientation in ExifTags.TAGS.keys():
+ if ExifTags.TAGS[orientation] == 'Orientation':
+ break
+
+
+def get_hash(paths):
+ # Returns a single hash value of a list of paths (files or dirs)
+ size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
+ h = hashlib.md5(str(size).encode()) # hash sizes
+ h.update(''.join(paths).encode()) # hash paths
+ return h.hexdigest() # return hash
+
+
+def exif_size(img):
+ # Returns exif-corrected PIL size
+ s = img.size # (width, height)
+ with contextlib.suppress(Exception):
+ rotation = dict(img._getexif().items())[orientation]
+ if rotation in [6, 8]: # rotation 270 or 90
+ s = (s[1], s[0])
+ return s
+
+
+def exif_transpose(image):
+ """
+ Transpose a PIL image accordingly if it has an EXIF Orientation tag.
+ Inplace version of https://github.com/python-pillow/Pillow/blob/master/src/PIL/ImageOps.py exif_transpose()
+
+ :param image: The image to transpose.
+ :return: An image.
+ """
+ exif = image.getexif()
+ orientation = exif.get(0x0112, 1) # default 1
+ if orientation > 1:
+ method = {
+ 2: Image.FLIP_LEFT_RIGHT,
+ 3: Image.ROTATE_180,
+ 4: Image.FLIP_TOP_BOTTOM,
+ 5: Image.TRANSPOSE,
+ 6: Image.ROTATE_270,
+ 7: Image.TRANSVERSE,
+ 8: Image.ROTATE_90,}.get(orientation)
+ if method is not None:
+ image = image.transpose(method)
+ del exif[0x0112]
+ image.info["exif"] = exif.tobytes()
+ return image
+
+
+def seed_worker(worker_id):
+ # Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloader
+ worker_seed = torch.initial_seed() % 2 ** 32
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False):
+ if rect and shuffle:
+ LOGGER.warning('WARNING: --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabels(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(0)
+ return loader(dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=False,
+ collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ drop_last=True,
+ ), dataset
+
+
+class InfiniteDataLoader(dataloader.DataLoader):
+ """ Dataloader that reuses workers
+
+ Uses same syntax as vanilla DataLoader
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
+ self.iterator = super().__iter__()
+
+ def __len__(self):
+ return len(self.batch_sampler.sampler)
+
+ def __iter__(self):
+ for _ in range(len(self)):
+ yield next(self.iterator)
+
+
+class _RepeatSampler:
+ """ Sampler that repeats forever
+
+ Args:
+ sampler (Sampler)
+ """
+
+ def __init__(self, sampler):
+ self.sampler = sampler
+
+ def __iter__(self):
+ while True:
+ yield from iter(self.sampler)
+
+
+class LoadImages:
+ # YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
+ def __init__(self, path, img_size=640, stride=32, auto=True):
+ files = []
+ for p in sorted(path) if isinstance(path, (list, tuple)) else [path]:
+ p = str(Path(p).resolve())
+ if '*' in p:
+ files.extend(sorted(glob.glob(p, recursive=True))) # glob
+ elif os.path.isdir(p):
+ files.extend(sorted(glob.glob(os.path.join(p, '*.*')))) # dir
+ elif os.path.isfile(p):
+ files.append(p) # files
+ else:
+ raise FileNotFoundError(f'{p} does not exist')
+
+ images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
+ videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
+ ni, nv = len(images), len(videos)
+
+ self.img_size = img_size
+ self.stride = stride
+ self.files = images + videos
+ self.nf = ni + nv # number of files
+ self.video_flag = [False] * ni + [True] * nv
+ self.mode = 'image'
+ self.auto = auto
+ if any(videos):
+ self.new_video(videos[0]) # new video
+ else:
+ self.cap = None
+ assert self.nf > 0, f'No images or videos found in {p}. ' \
+ f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'
+
+ def __iter__(self):
+ self.count = 0
+ return self
+
+ def __next__(self):
+ if self.count == self.nf:
+ raise StopIteration
+ path = self.files[self.count]
+
+ if self.video_flag[self.count]:
+ # Read video
+ self.mode = 'video'
+ ret_val, img0 = self.cap.read()
+ while not ret_val:
+ self.count += 1
+ self.cap.release()
+ if self.count == self.nf: # last video
+ raise StopIteration
+ path = self.files[self.count]
+ self.new_video(path)
+ ret_val, img0 = self.cap.read()
+
+ self.frame += 1
+ s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '
+
+ else:
+ # Read image
+ self.count += 1
+ img0 = cv2.imread(path) # BGR
+ assert img0 is not None, f'Image Not Found {path}'
+ s = f'image {self.count}/{self.nf} {path}: '
+
+ # Padded resize
+ img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0]
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return path, img, img0, self.cap, s
+
+ def new_video(self, path):
+ self.frame = 0
+ self.cap = cv2.VideoCapture(path)
+ self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
+
+ def __len__(self):
+ return self.nf # number of files
+
+
+class LoadWebcam: # for inference
+ # YOLOv5 local webcam dataloader, i.e. `python detect.py --source 0`
+ def __init__(self, pipe='0', img_size=640, stride=32):
+ self.img_size = img_size
+ self.stride = stride
+ self.pipe = eval(pipe) if pipe.isnumeric() else pipe
+ self.cap = cv2.VideoCapture(self.pipe) # video capture object
+ self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
+
+ def __iter__(self):
+ self.count = -1
+ return self
+
+ def __next__(self):
+ self.count += 1
+ if cv2.waitKey(1) == ord('q'): # q to quit
+ self.cap.release()
+ cv2.destroyAllWindows()
+ raise StopIteration
+
+ # Read frame
+ ret_val, img0 = self.cap.read()
+ img0 = cv2.flip(img0, 1) # flip left-right
+
+ # Print
+ assert ret_val, f'Camera Error {self.pipe}'
+ img_path = 'webcam.jpg'
+ s = f'webcam {self.count}: '
+
+ # Padded resize
+ img = letterbox(img0, self.img_size, stride=self.stride)[0]
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return img_path, img, img0, None, s
+
+ def __len__(self):
+ return 0
+
+
+class LoadStreams:
+ # YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
+ def __init__(self, sources='streams.txt', img_size=640, stride=32, auto=True):
+ self.mode = 'stream'
+ self.img_size = img_size
+ self.stride = stride
+
+ if os.path.isfile(sources):
+ with open(sources) as f:
+ sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
+ else:
+ sources = [sources]
+
+ n = len(sources)
+ self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
+ self.sources = [clean_str(x) for x in sources] # clean source names for later
+ self.auto = auto
+ for i, s in enumerate(sources): # index, source
+ # Start thread to read frames from video stream
+ st = f'{i + 1}/{n}: {s}... '
+ if urlparse(s).hostname in ('www.youtube.com', 'youtube.com', 'youtu.be'): # if source is YouTube video
+ check_requirements(('pafy', 'youtube_dl==2020.12.2'))
+ import pafy
+ s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
+ s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
+ if s == 0:
+ assert not is_colab(), '--source 0 webcam unsupported on Colab. Rerun command in a local environment.'
+ assert not is_kaggle(), '--source 0 webcam unsupported on Kaggle. Rerun command in a local environment.'
+ cap = cv2.VideoCapture(s)
+ assert cap.isOpened(), f'{st}Failed to open {s}'
+ w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
+ h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ fps = cap.get(cv2.CAP_PROP_FPS) # warning: may return 0 or nan
+ self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
+ self.fps[i] = max((fps if math.isfinite(fps) else 0) % 100, 0) or 30 # 30 FPS fallback
+
+ _, self.imgs[i] = cap.read() # guarantee first frame
+ self.threads[i] = Thread(target=self.update, args=([i, cap, s]), daemon=True)
+ LOGGER.info(f"{st} Success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
+ self.threads[i].start()
+ LOGGER.info('') # newline
+
+ # check for common shapes
+ s = np.stack([letterbox(x, self.img_size, stride=self.stride, auto=self.auto)[0].shape for x in self.imgs])
+ self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
+ if not self.rect:
+ LOGGER.warning('WARNING: Stream shapes differ. For optimal performance supply similarly-shaped streams.')
+
+ def update(self, i, cap, stream):
+ # Read stream `i` frames in daemon thread
+ n, f, read = 0, self.frames[i], 1 # frame number, frame array, inference every 'read' frame
+ while cap.isOpened() and n < f:
+ n += 1
+ # _, self.imgs[index] = cap.read()
+ cap.grab()
+ if n % read == 0:
+ success, im = cap.retrieve()
+ if success:
+ self.imgs[i] = im
+ else:
+ LOGGER.warning('WARNING: Video stream unresponsive, please check your IP camera connection.')
+ self.imgs[i] = np.zeros_like(self.imgs[i])
+ cap.open(stream) # re-open stream if signal was lost
+ time.sleep(0.0) # wait time
+
+ def __iter__(self):
+ self.count = -1
+ return self
+
+ def __next__(self):
+ self.count += 1
+ if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
+ cv2.destroyAllWindows()
+ raise StopIteration
+
+ # Letterbox
+ img0 = self.imgs.copy()
+ img = [letterbox(x, self.img_size, stride=self.stride, auto=self.rect and self.auto)[0] for x in img0]
+
+ # Stack
+ img = np.stack(img, 0)
+
+ # Convert
+ img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
+ img = np.ascontiguousarray(img)
+
+ return self.sources, img, img0, None, ''
+
+ def __len__(self):
+ return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
+
+
+def img2label_paths(img_paths):
+ # Define label paths as a function of image paths
+ sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
+ return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
+
+
+class LoadImagesAndLabels(Dataset):
+ # YOLOv5 train_loader/val_loader, loads images and labels for training and validation
+ cache_version = 0.6 # dataset labels *.cache version
+ rand_interp_methods = [cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_LANCZOS4]
+
+ def __init__(self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0.0,
+ prefix=''):
+ self.img_size = img_size
+ self.augment = augment
+ self.hyp = hyp
+ self.image_weights = image_weights
+ self.rect = False if image_weights else rect
+ self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
+ self.mosaic_border = [-img_size // 2, -img_size // 2]
+ self.stride = stride
+ self.path = path
+ self.albumentations = Albumentations(hyp) if augment else None
+
+ try:
+ f = [] # image files
+ for p in path if isinstance(path, list) else [path]:
+ p = Path(p) # os-agnostic
+ if p.is_dir(): # dir
+ f += glob.glob(str(p / '**' / '*.*'), recursive=True)
+ # f = list(p.rglob('*.*')) # pathlib
+ elif p.is_file(): # file
+ with open(p) as t:
+ t = t.read().strip().splitlines()
+ parent = str(p.parent) + os.sep
+ f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
+ # f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
+ else:
+ raise FileNotFoundError(f'{prefix}{p} does not exist')
+ self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
+ # self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
+ assert self.im_files, f'{prefix}No images found'
+ except Exception as e:
+ raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {HELP_URL}')
+
+ # Check cache
+ self.label_files = img2label_paths(self.im_files) # labels
+ cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
+ try:
+ cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
+ assert cache['version'] == self.cache_version # matches current version
+ assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
+ except Exception:
+ cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops
+
+ # Display cache
+ nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
+ if exists and LOCAL_RANK in {-1, 0}:
+ d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupt"
+ tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=BAR_FORMAT) # display cache results
+ if cache['msgs']:
+ LOGGER.info('\n'.join(cache['msgs'])) # display warnings
+ assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {HELP_URL}'
+
+ # Read cache
+ [cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
+ labels, shapes, self.segments = zip(*cache.values())
+ self.labels = list(labels)
+ self.shapes = np.array(shapes)
+ self.im_files = list(cache.keys()) # update
+ self.label_files = img2label_paths(cache.keys()) # update
+ n = len(shapes) # number of images
+ bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index
+ nb = bi[-1] + 1 # number of batches
+ self.batch = bi # batch index of image
+ self.n = n
+ self.indices = range(n)
+
+ # Update labels
+ include_class = [] # filter labels to include only these classes (optional)
+ include_class_array = np.array(include_class).reshape(1, -1)
+ for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
+ if include_class:
+ j = (label[:, 0:1] == include_class_array).any(1)
+ self.labels[i] = label[j]
+ if segment:
+ self.segments[i] = segment[j]
+ if single_cls: # single-class training, merge all classes into 0
+ self.labels[i][:, 0] = 0
+ if segment:
+ self.segments[i][:, 0] = 0
+
+ # Rectangular Training
+ if self.rect:
+ # Sort by aspect ratio
+ s = self.shapes # wh
+ ar = s[:, 1] / s[:, 0] # aspect ratio
+ irect = ar.argsort()
+ self.im_files = [self.im_files[i] for i in irect]
+ self.label_files = [self.label_files[i] for i in irect]
+ self.labels = [self.labels[i] for i in irect]
+ self.shapes = s[irect] # wh
+ ar = ar[irect]
+
+ # Set training image shapes
+ shapes = [[1, 1]] * nb
+ for i in range(nb):
+ ari = ar[bi == i]
+ mini, maxi = ari.min(), ari.max()
+ if maxi < 1:
+ shapes[i] = [maxi, 1]
+ elif mini > 1:
+ shapes[i] = [1, 1 / mini]
+
+ self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
+
+ # Cache images into RAM/disk for faster training (WARNING: large datasets may exceed system resources)
+ self.ims = [None] * n
+ self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
+ if cache_images:
+ gb = 0 # Gigabytes of cached images
+ self.im_hw0, self.im_hw = [None] * n, [None] * n
+ fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
+ results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
+ pbar = tqdm(enumerate(results), total=n, bar_format=BAR_FORMAT, disable=LOCAL_RANK > 0)
+ for i, x in pbar:
+ if cache_images == 'disk':
+ gb += self.npy_files[i].stat().st_size
+ else: # 'ram'
+ self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
+ gb += self.ims[i].nbytes
+ pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB {cache_images})'
+ pbar.close()
+
+ def cache_labels(self, path=Path('./labels.cache'), prefix=''):
+ # Cache dataset labels, check images and read shapes
+ x = {} # dict
+ nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
+ desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..."
+ with Pool(NUM_THREADS) as pool:
+ pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
+ desc=desc,
+ total=len(self.im_files),
+ bar_format=BAR_FORMAT)
+ for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
+ nm += nm_f
+ nf += nf_f
+ ne += ne_f
+ nc += nc_f
+ if im_file:
+ x[im_file] = [lb, shape, segments]
+ if msg:
+ msgs.append(msg)
+ pbar.desc = f"{desc}{nf} found, {nm} missing, {ne} empty, {nc} corrupt"
+
+ pbar.close()
+ if msgs:
+ LOGGER.info('\n'.join(msgs))
+ if nf == 0:
+ LOGGER.warning(f'{prefix}WARNING: No labels found in {path}. See {HELP_URL}')
+ x['hash'] = get_hash(self.label_files + self.im_files)
+ x['results'] = nf, nm, ne, nc, len(self.im_files)
+ x['msgs'] = msgs # warnings
+ x['version'] = self.cache_version # cache version
+ try:
+ np.save(path, x) # save cache for next time
+ path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
+ LOGGER.info(f'{prefix}New cache created: {path}')
+ except Exception as e:
+ LOGGER.warning(f'{prefix}WARNING: Cache directory {path.parent} is not writeable: {e}') # not writeable
+ return x
+
+ def __len__(self):
+ return len(self.im_files)
+
+ # def __iter__(self):
+ # self.count = -1
+ # print('ran dataset iter')
+ # #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
+ # return self
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ if mosaic:
+ # Load mosaic
+ img, labels = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp['mixup']:
+ img, labels = mixup(img, labels, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels = random_perspective(img,
+ labels,
+ degrees=hyp['degrees'],
+ rotation_prob=hyp['rotation_prob'],
+ translate=hyp['translate'],
+ scale=hyp['scale'],
+ shear=hyp['shear'],
+ perspective=hyp['perspective'])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
+
+ if self.augment:
+ # Albumentations
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
+
+ # Flip up-down
+ if random.random() < hyp['flipud']:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+
+ # Flip left-right
+ if random.random() < hyp['fliplr']:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+
+ # Cutouts
+ # labels = cutout(img, labels, p=0.5)
+ # nl = len(labels) # update after cutout
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return torch.from_numpy(img), labels_out, self.im_files[index], shapes
+
+ def load_image(self, i):
+ # Loads 1 image from dataset index 'i', returns (im, original hw, resized hw)
+ im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i],
+ if im is None: # not cached in RAM
+ if fn.exists(): # load npy
+ im = np.load(fn)
+ else: # read image
+ im = cv2.imread(f) # BGR
+ assert im is not None, f'Image Not Found {f}'
+ h0, w0 = im.shape[:2] # orig hw
+ r = self.img_size / max(h0, w0) # ratio
+ if r != 1: # if sizes are not equal
+ interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
+ im = cv2.resize(im, (int(w0 * r), int(h0 * r)), interpolation=interp)
+ return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
+ return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
+
+ def cache_images_to_disk(self, i):
+ # Saves an image as an *.npy file for faster loading
+ f = self.npy_files[i]
+ if not f.exists():
+ np.save(f.as_posix(), cv2.imread(self.im_files[i]))
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ random.shuffle(indices)
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ # Labels
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
+ img4, labels4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp['degrees'],
+ rotation_prob=self.hyp['rotation_prob'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+
+ return img4, labels4
+
+ def load_mosaic9(self, index):
+ # YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
+ labels9, segments9 = [], []
+ s = self.img_size
+ indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
+ random.shuffle(indices)
+ hp, wp = -1, -1 # height, width previous
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img9
+ if i == 0: # center
+ img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ h0, w0 = h, w
+ c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
+ elif i == 1: # top
+ c = s, s - h, s + w, s
+ elif i == 2: # top right
+ c = s + wp, s - h, s + wp + w, s
+ elif i == 3: # right
+ c = s + w0, s, s + w0 + w, s + h
+ elif i == 4: # bottom right
+ c = s + w0, s + hp, s + w0 + w, s + hp + h
+ elif i == 5: # bottom
+ c = s + w0 - w, s + h0, s + w0, s + h0 + h
+ elif i == 6: # bottom left
+ c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
+ elif i == 7: # left
+ c = s - w, s + h0 - h, s, s + h0
+ elif i == 8: # top left
+ c = s - w, s + h0 - hp - h, s, s + h0 - hp
+
+ padx, pady = c[:2]
+ x1, y1, x2, y2 = (max(x, 0) for x in c) # allocate coords
+
+ # Labels
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
+ labels9.append(labels)
+ segments9.extend(segments)
+
+ # Image
+ img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
+ hp, wp = h, w # height, width previous
+
+ # Offset
+ yc, xc = (int(random.uniform(0, s)) for _ in self.mosaic_border) # mosaic center x, y
+ img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
+
+ # Concat/clip labels
+ labels9 = np.concatenate(labels9, 0)
+ labels9[:, [1, 3]] -= xc
+ labels9[:, [2, 4]] -= yc
+ c = np.array([xc, yc]) # centers
+ segments9 = [x - c for x in segments9]
+
+ for x in (labels9[:, 1:], *segments9):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img9, labels9 = replicate(img9, labels9) # replicate
+
+ # Augment
+ img9, labels9 = random_perspective(img9,
+ labels9,
+ segments9,
+ degrees=self.hyp['degrees'],
+ rotation_prob=self.hyp['rotation_prob'],
+ translate=self.hyp['translate'],
+ scale=self.hyp['scale'],
+ shear=self.hyp['shear'],
+ perspective=self.hyp['perspective'],
+ border=self.mosaic_border) # border to remove
+
+ return img9, labels9
+
+ @staticmethod
+ def collate_fn(batch):
+ im, label, path, shapes = zip(*batch) # transposed
+ for i, lb in enumerate(label):
+ lb[:, 0] = i # add target image index for build_targets()
+ return torch.stack(im, 0), torch.cat(label, 0), path, shapes
+
+ @staticmethod
+ def collate_fn4(batch):
+ img, label, path, shapes = zip(*batch) # transposed
+ n = len(shapes) // 4
+ im4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
+
+ ho = torch.tensor([[0.0, 0, 0, 1, 0, 0]])
+ wo = torch.tensor([[0.0, 0, 1, 0, 0, 0]])
+ s = torch.tensor([[1, 1, 0.5, 0.5, 0.5, 0.5]]) # scale
+ for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
+ i *= 4
+ if random.random() < 0.5:
+ im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2.0, mode='bilinear',
+ align_corners=False)[0].type(img[i].type())
+ lb = label[i]
+ else:
+ im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
+ lb = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
+ im4.append(im)
+ label4.append(lb)
+
+ for i, lb in enumerate(label4):
+ lb[:, 0] = i # add target image index for build_targets()
+
+ return torch.stack(im4, 0), torch.cat(label4, 0), path4, shapes4
+
+
+# Ancillary functions --------------------------------------------------------------------------------------------------
+def flatten_recursive(path=DATASETS_DIR / 'coco128'):
+ # Flatten a recursive directory by bringing all files to top level
+ new_path = Path(f'{str(path)}_flat')
+ if os.path.exists(new_path):
+ shutil.rmtree(new_path) # delete output folder
+ os.makedirs(new_path) # make new output folder
+ for file in tqdm(glob.glob(f'{str(Path(path))}/**/*.*', recursive=True)):
+ shutil.copyfile(file, new_path / Path(file).name)
+
+
+def extract_boxes(path=DATASETS_DIR / 'coco128'): # from utils.dataloaders import *; extract_boxes()
+ # Convert detection dataset into classification dataset, with one directory per class
+ path = Path(path) # images dir
+ shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None # remove existing
+ files = list(path.rglob('*.*'))
+ n = len(files) # number of files
+ for im_file in tqdm(files, total=n):
+ if im_file.suffix[1:] in IMG_FORMATS:
+ # image
+ im = cv2.imread(str(im_file))[..., ::-1] # BGR to RGB
+ h, w = im.shape[:2]
+
+ # labels
+ lb_file = Path(img2label_paths([str(im_file)])[0])
+ if Path(lb_file).exists():
+ with open(lb_file) as f:
+ lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # labels
+
+ for j, x in enumerate(lb):
+ c = int(x[0]) # class
+ f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
+ if not f.parent.is_dir():
+ f.parent.mkdir(parents=True)
+
+ b = x[1:] * [w, h, w, h] # box
+ # b[2:] = b[2:].max() # rectangle to square
+ b[2:] = b[2:] * 1.2 + 3 # pad
+ b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int)
+
+ b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image
+ b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
+ assert cv2.imwrite(str(f), im[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
+
+
+def autosplit(path=DATASETS_DIR / 'coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
+ """ Autosplit a dataset into train/val/test splits and save path/autosplit_*.txt files
+ Usage: from utils.dataloaders import *; autosplit()
+ Arguments
+ path: Path to images directory
+ weights: Train, val, test weights (list, tuple)
+ annotated_only: Only use images with an annotated txt file
+ """
+ path = Path(path) # images dir
+ files = sorted(x for x in path.rglob('*.*') if x.suffix[1:].lower() in IMG_FORMATS) # image files only
+ n = len(files) # number of files
+ random.seed(0) # for reproducibility
+ indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
+
+ txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
+ [(path.parent / x).unlink(missing_ok=True) for x in txt] # remove existing
+
+ print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
+ for i, img in tqdm(zip(indices, files), total=n):
+ if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
+ with open(path.parent / txt[i], 'a') as f:
+ f.write(f'./{img.relative_to(path.parent).as_posix()}' + '\n') # add image to txt file
+
+
+def verify_image_label(args):
+ # Verify one image-label pair
+ im_file, lb_file, prefix = args
+ nm, nf, ne, nc, msg, segments = 0, 0, 0, 0, '', [] # number (missing, found, empty, corrupt), message, segments
+ try:
+ # verify images
+ im = Image.open(im_file)
+ im.verify() # PIL verify
+ shape = exif_size(im) # image size
+ assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
+ assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
+ if im.format.lower() in ('jpg', 'jpeg'):
+ with open(im_file, 'rb') as f:
+ f.seek(-2, 2)
+ if f.read() != b'\xff\xd9': # corrupt JPEG
+ ImageOps.exif_transpose(Image.open(im_file)).save(im_file, 'JPEG', subsampling=0, quality=100)
+ msg = f'{prefix}WARNING: {im_file}: corrupt JPEG restored and saved'
+
+ # verify labels
+ if os.path.isfile(lb_file):
+ nf = 1 # label found
+ with open(lb_file) as f:
+ lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
+ if any(len(x) > 6 for x in lb): # is segment
+ classes = np.array([x[0] for x in lb], dtype=np.float32)
+ segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in lb] # (cls, xy1...)
+ lb = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
+ lb = np.array(lb, dtype=np.float32)
+ nl = len(lb)
+ if nl:
+ assert lb.shape[1] == 5, f'labels require 5 columns, {lb.shape[1]} columns detected'
+ assert (lb >= 0).all(), f'negative label values {lb[lb < 0]}'
+ assert (lb[:, 1:] <= 1).all(), f'non-normalized or out of bounds coordinates {lb[:, 1:][lb[:, 1:] > 1]}'
+ _, i = np.unique(lb, axis=0, return_index=True)
+ if len(i) < nl: # duplicate row check
+ lb = lb[i] # remove duplicates
+ if segments:
+ segments = segments[i]
+ msg = f'{prefix}WARNING: {im_file}: {nl - len(i)} duplicate labels removed'
+ else:
+ ne = 1 # label empty
+ lb = np.zeros((0, 5), dtype=np.float32)
+ else:
+ nm = 1 # label missing
+ lb = np.zeros((0, 5), dtype=np.float32)
+ return im_file, lb, shape, segments, nm, nf, ne, nc, msg
+ except Exception as e:
+ nc = 1
+ msg = f'{prefix}WARNING: {im_file}: ignoring corrupt image/label: {e}'
+ return [None, None, None, None, nm, nf, ne, nc, msg]
+
+
+class HUBDatasetStats():
+ """ Return dataset statistics dictionary with images and instances counts per split per class
+ To run in parent directory: export PYTHONPATH="$PWD/yolov5"
+ Usage1: from utils.dataloaders import *; HUBDatasetStats('coco128.yaml', autodownload=True)
+ Usage2: from utils.dataloaders import *; HUBDatasetStats('path/to/coco128_with_yaml.zip')
+ Arguments
+ path: Path to data.yaml or data.zip (with data.yaml inside data.zip)
+ autodownload: Attempt to download dataset if not found locally
+ """
+
+ def __init__(self, path='coco128.yaml', autodownload=False):
+ # Initialize class
+ zipped, data_dir, yaml_path = self._unzip(Path(path))
+ try:
+ with open(check_yaml(yaml_path), errors='ignore') as f:
+ data = yaml.safe_load(f) # data dict
+ if zipped:
+ data['path'] = data_dir
+ except Exception as e:
+ raise Exception("error/HUB/dataset_stats/yaml_load") from e
+
+ check_dataset(data, autodownload) # download dataset if missing
+ self.hub_dir = Path(data['path'] + '-hub')
+ self.im_dir = self.hub_dir / 'images'
+ self.im_dir.mkdir(parents=True, exist_ok=True) # makes /images
+ self.stats = {'nc': data['nc'], 'names': data['names']} # statistics dictionary
+ self.data = data
+
+ @staticmethod
+ def _find_yaml(dir):
+ # Return data.yaml file
+ files = list(dir.glob('*.yaml')) or list(dir.rglob('*.yaml')) # try root level first and then recursive
+ assert files, f'No *.yaml file found in {dir}'
+ if len(files) > 1:
+ files = [f for f in files if f.stem == dir.stem] # prefer *.yaml files that match dir name
+ assert files, f'Multiple *.yaml files found in {dir}, only 1 *.yaml file allowed'
+ assert len(files) == 1, f'Multiple *.yaml files found: {files}, only 1 *.yaml file allowed in {dir}'
+ return files[0]
+
+ def _unzip(self, path):
+ # Unzip data.zip
+ if not str(path).endswith('.zip'): # path is data.yaml
+ return False, None, path
+ assert Path(path).is_file(), f'Error unzipping {path}, file not found'
+ ZipFile(path).extractall(path=path.parent) # unzip
+ dir = path.with_suffix('') # dataset directory == zip name
+ assert dir.is_dir(), f'Error unzipping {path}, {dir} not found. path/to/abc.zip MUST unzip to path/to/abc/'
+ return True, str(dir), self._find_yaml(dir) # zipped, data_dir, yaml_path
+
+ def _hub_ops(self, f, max_dim=1920):
+ # HUB ops for 1 image 'f': resize and save at reduced quality in /dataset-hub for web/app viewing
+ f_new = self.im_dir / Path(f).name # dataset-hub image filename
+ try: # use PIL
+ im = Image.open(f)
+ r = max_dim / max(im.height, im.width) # ratio
+ if r < 1.0: # image too large
+ im = im.resize((int(im.width * r), int(im.height * r)))
+ im.save(f_new, 'JPEG', quality=50, optimize=True) # save
+ except Exception as e: # use OpenCV
+ print(f'WARNING: HUB ops PIL failure {f}: {e}')
+ im = cv2.imread(f)
+ im_height, im_width = im.shape[:2]
+ r = max_dim / max(im_height, im_width) # ratio
+ if r < 1.0: # image too large
+ im = cv2.resize(im, (int(im_width * r), int(im_height * r)), interpolation=cv2.INTER_AREA)
+ cv2.imwrite(str(f_new), im)
+
+ def get_json(self, save=False, verbose=False):
+ # Return dataset JSON for Ultralytics HUB
+ def _round(labels):
+ # Update labels to integer class and 6 decimal place floats
+ return [[int(c), *(round(x, 4) for x in points)] for c, *points in labels]
+
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ self.stats[split] = None # i.e. no test set
+ continue
+ dataset = LoadImagesAndLabels(self.data[split]) # load dataset
+ x = np.array([
+ np.bincount(label[:, 0].astype(int), minlength=self.data['nc'])
+ for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics')]) # shape(128x80)
+ self.stats[split] = {
+ 'instance_stats': {
+ 'total': int(x.sum()),
+ 'per_class': x.sum(0).tolist()},
+ 'image_stats': {
+ 'total': dataset.n,
+ 'unlabelled': int(np.all(x == 0, 1).sum()),
+ 'per_class': (x > 0).sum(0).tolist()},
+ 'labels': [{
+ str(Path(k).name): _round(v.tolist())} for k, v in zip(dataset.im_files, dataset.labels)]}
+
+ # Save, print and return
+ if save:
+ stats_path = self.hub_dir / 'stats.json'
+ print(f'Saving {stats_path.resolve()}...')
+ with open(stats_path, 'w') as f:
+ json.dump(self.stats, f) # save stats.json
+ if verbose:
+ print(json.dumps(self.stats, indent=2, sort_keys=False))
+ return self.stats
+
+ def process_images(self):
+ # Compress images for Ultralytics HUB
+ for split in 'train', 'val', 'test':
+ if self.data.get(split) is None:
+ continue
+ dataset = LoadImagesAndLabels(self.data[split]) # load dataset
+ desc = f'{split} images'
+ for _ in tqdm(ThreadPool(NUM_THREADS).imap(self._hub_ops, dataset.im_files), total=dataset.n, desc=desc):
+ pass
+ print(f'Done. All images saved to {self.im_dir}')
+ return self.im_dir
diff --git a/utils/docker/Dockerfile b/utils/docker/Dockerfile
new file mode 100755
index 0000000..2280f20
--- /dev/null
+++ b/utils/docker/Dockerfile
@@ -0,0 +1,68 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Builds ultralytics/yolov5:latest image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is CUDA-optimized for YOLOv5 single/multi-GPU training and inference
+
+# Start FROM NVIDIA PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
+FROM nvcr.io/nvidia/pytorch:22.07-py3
+RUN rm -rf /opt/pytorch # remove 1.2GB dir
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update && apt install --no-install-recommends -y zip htop screen libgl1-mesa-glx
+
+# Install pip packages
+COPY requirements.txt .
+RUN python -m pip install --upgrade pip wheel
+RUN pip uninstall -y Pillow torchtext # torch torchvision
+RUN pip install --no-cache -r requirements.txt albumentations wandb gsutil notebook Pillow>=9.1.0 \
+ 'opencv-python<4.6.0.66' \
+ --extra-index-url https://download.pytorch.org/whl/cu113
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+# Set environment variables
+ENV OMP_NUM_THREADS=8
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest && sudo docker build -f utils/docker/Dockerfile -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
+
+# Pull and Run with local directory access
+# t=ultralytics/yolov5:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/datasets:/usr/src/datasets $t
+
+# Kill all
+# sudo docker kill $(sudo docker ps -q)
+
+# Kill all image-based
+# sudo docker kill $(sudo docker ps -qa --filter ancestor=ultralytics/yolov5:latest)
+
+# Bash into running container
+# sudo docker exec -it 5a9b5863d93d bash
+
+# Bash into stopped container
+# id=$(sudo docker ps -qa) && sudo docker start $id && sudo docker exec -it $id bash
+
+# Clean up
+# docker system prune -a --volumes
+
+# Update Ubuntu drivers
+# https://www.maketecheasier.com/install-nvidia-drivers-ubuntu/
+
+# DDP test
+# python -m torch.distributed.run --nproc_per_node 2 --master_port 1 train.py --epochs 3
+
+# GCP VM from Image
+# docker.io/ultralytics/yolov5:latest
diff --git a/utils/docker/Dockerfile-arm64 b/utils/docker/Dockerfile-arm64
new file mode 100755
index 0000000..fe92c8d
--- /dev/null
+++ b/utils/docker/Dockerfile-arm64
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Builds ultralytics/yolov5:latest-arm64 image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is aarch64-compatible for Apple M1 and other ARM architectures i.e. Jetson Nano and Raspberry Pi
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM arm64v8/ubuntu:20.04
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update
+RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop gcc \
+ libgl1-mesa-glx libglib2.0-0 libpython3.8-dev
+# RUN alias python=python3
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt gsutil notebook \
+ tensorflow-aarch64
+ # tensorflowjs \
+ # onnx onnx-simplifier onnxruntime \
+ # coremltools openvino-dev \
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest-M1 && sudo docker build --platform linux/arm64 -f utils/docker/Dockerfile-arm64 -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest-M1 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/utils/docker/Dockerfile-cpu b/utils/docker/Dockerfile-cpu
new file mode 100755
index 0000000..d61dfef
--- /dev/null
+++ b/utils/docker/Dockerfile-cpu
@@ -0,0 +1,39 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Builds ultralytics/yolov5:latest-cpu image on DockerHub https://hub.docker.com/r/ultralytics/yolov5
+# Image is CPU-optimized for ONNX, OpenVINO and PyTorch YOLOv5 deployments
+
+# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
+FROM ubuntu:20.04
+
+# Downloads to user config dir
+ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Arial.Unicode.ttf /root/.config/Ultralytics/
+
+# Install linux packages
+RUN apt update
+RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3.8-dev
+# RUN alias python=python3
+
+# Install pip packages
+COPY requirements.txt .
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache -r requirements.txt albumentations gsutil notebook \
+ coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu tensorflowjs \
+ --extra-index-url https://download.pytorch.org/whl/cpu
+
+# Create working directory
+RUN mkdir -p /usr/src/app
+WORKDIR /usr/src/app
+
+# Copy contents
+# COPY . /usr/src/app (issues as not a .git directory)
+RUN git clone https://github.com/ultralytics/yolov5 /usr/src/app
+
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/yolov5:latest-cpu && sudo docker build -f utils/docker/Dockerfile-cpu -t $t . && sudo docker push $t
+
+# Pull and Run
+# t=ultralytics/yolov5:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/datasets:/usr/src/datasets $t
diff --git a/utils/downloads.py b/utils/downloads.py
new file mode 100755
index 0000000..9d4780a
--- /dev/null
+++ b/utils/downloads.py
@@ -0,0 +1,180 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Download utils
+"""
+
+import logging
+import os
+import platform
+import subprocess
+import time
+import urllib
+from pathlib import Path
+from zipfile import ZipFile
+
+import requests
+import torch
+
+
+def is_url(url, check_online=True):
+ # Check if online file exists
+ try:
+ url = str(url)
+ result = urllib.parse.urlparse(url)
+ assert all([result.scheme, result.netloc, result.path]) # check if is url
+ return (urllib.request.urlopen(url).getcode() == 200) if check_online else True # check if exists online
+ except (AssertionError, urllib.request.HTTPError):
+ return False
+
+
+def gsutil_getsize(url=''):
+ # gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du
+ s = subprocess.check_output(f'gsutil du {url}', shell=True).decode('utf-8')
+ return eval(s.split(' ')[0]) if len(s) else 0 # bytes
+
+
+def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):
+ # Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
+ from utils.general import LOGGER
+
+ file = Path(file)
+ assert_msg = f"Downloaded file '{file}' does not exist or size is < min_bytes={min_bytes}"
+ try: # url1
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, str(file), progress=LOGGER.level <= logging.INFO)
+ assert file.exists() and file.stat().st_size > min_bytes, assert_msg # check
+ except Exception as e: # url2
+ file.unlink(missing_ok=True) # remove partial downloads
+ LOGGER.info(f'ERROR: {e}\nRe-attempting {url2 or url} to {file}...')
+ os.system(f"curl -L '{url2 or url}' -o '{file}' --retry 3 -C -") # curl download, retry and resume on fail
+ finally:
+ if not file.exists() or file.stat().st_size < min_bytes: # check
+ file.unlink(missing_ok=True) # remove partial downloads
+ LOGGER.info(f"ERROR: {assert_msg}\n{error_msg}")
+ LOGGER.info('')
+
+
+def attempt_download(file, repo='ultralytics/yolov5', release='v6.1'):
+ # Attempt file download from GitHub release assets if not found locally. release = 'latest', 'v6.1', etc.
+ from utils.general import LOGGER
+
+ def github_assets(repository, version='latest'):
+ # Return GitHub repo tag (i.e. 'v6.1') and assets (i.e. ['yolov5s.pt', 'yolov5m.pt', ...])
+ if version != 'latest':
+ version = f'tags/{version}' # i.e. tags/v6.1
+ response = requests.get(f'https://api.github.com/repos/{repository}/releases/{version}').json() # github api
+ return response['tag_name'], [x['name'] for x in response['assets']] # tag, assets
+
+ file = Path(str(file).strip().replace("'", ''))
+ if not file.exists():
+ # URL specified
+ name = Path(urllib.parse.unquote(str(file))).name # decode '%2F' to '/' etc.
+ if str(file).startswith(('http:/', 'https:/')): # download
+ url = str(file).replace(':/', '://') # Pathlib turns :// -> :/
+ file = name.split('?')[0] # parse authentication https://url.com/file.txt?auth...
+ if Path(file).is_file():
+ LOGGER.info(f'Found {url} locally at {file}') # file already exists
+ else:
+ safe_download(file=file, url=url, min_bytes=1E5)
+ return file
+
+ # GitHub assets
+ assets = [
+ 'yolov5n.pt', 'yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt', 'yolov5n6.pt', 'yolov5s6.pt',
+ 'yolov5m6.pt', 'yolov5l6.pt', 'yolov5x6.pt']
+ try:
+ tag, assets = github_assets(repo, release)
+ except Exception:
+ try:
+ tag, assets = github_assets(repo) # latest release
+ except Exception:
+ try:
+ tag = subprocess.check_output('git tag', shell=True, stderr=subprocess.STDOUT).decode().split()[-1]
+ except Exception:
+ tag = release
+
+ file.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required)
+ if name in assets:
+ url3 = 'https://drive.google.com/drive/folders/1EFQTEUeXWSFww0luse2jB9M1QNZQGwNl' # backup gdrive mirror
+ safe_download(
+ file,
+ url=f'https://github.com/{repo}/releases/download/{tag}/{name}',
+ url2=f'https://storage.googleapis.com/{repo}/{tag}/{name}', # backup url (optional)
+ min_bytes=1E5,
+ error_msg=f'{file} missing, try downloading from https://github.com/{repo}/releases/{tag} or {url3}')
+
+ return str(file)
+
+
+def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'):
+ # Downloads a file from Google Drive. from yolov5.utils.downloads import *; gdrive_download()
+ t = time.time()
+ file = Path(file)
+ cookie = Path('cookie') # gdrive cookie
+ print(f'Downloading https://drive.google.com/uc?export=download&id={id} as {file}... ', end='')
+ file.unlink(missing_ok=True) # remove existing file
+ cookie.unlink(missing_ok=True) # remove existing cookie
+
+ # Attempt file download
+ out = "NUL" if platform.system() == "Windows" else "/dev/null"
+ os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={id}" > {out}')
+ if os.path.exists('cookie'): # large file
+ s = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={get_token()}&id={id}" -o {file}'
+ else: # small file
+ s = f'curl -s -L -o {file} "drive.google.com/uc?export=download&id={id}"'
+ r = os.system(s) # execute, capture return
+ cookie.unlink(missing_ok=True) # remove existing cookie
+
+ # Error check
+ if r != 0:
+ file.unlink(missing_ok=True) # remove partial
+ print('Download error ') # raise Exception('Download error')
+ return r
+
+ # Unzip if archive
+ if file.suffix == '.zip':
+ print('unzipping... ', end='')
+ ZipFile(file).extractall(path=file.parent) # unzip
+ file.unlink() # remove zip
+
+ print(f'Done ({time.time() - t:.1f}s)')
+ return r
+
+
+def get_token(cookie="./cookie"):
+ with open(cookie) as f:
+ for line in f:
+ if "download" in line:
+ return line.split()[-1]
+ return ""
+
+
+# Google utils: https://cloud.google.com/storage/docs/reference/libraries ----------------------------------------------
+#
+#
+# def upload_blob(bucket_name, source_file_name, destination_blob_name):
+# # Uploads a file to a bucket
+# # https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
+#
+# storage_client = storage.Client()
+# bucket = storage_client.get_bucket(bucket_name)
+# blob = bucket.blob(destination_blob_name)
+#
+# blob.upload_from_filename(source_file_name)
+#
+# print('File {} uploaded to {}.'.format(
+# source_file_name,
+# destination_blob_name))
+#
+#
+# def download_blob(bucket_name, source_blob_name, destination_file_name):
+# # Uploads a blob from a bucket
+# storage_client = storage.Client()
+# bucket = storage_client.get_bucket(bucket_name)
+# blob = bucket.blob(source_blob_name)
+#
+# blob.download_to_filename(destination_file_name)
+#
+# print('Blob {} downloaded to {}.'.format(
+# source_blob_name,
+# destination_file_name))
diff --git a/utils/flask_rest_api/README.md b/utils/flask_rest_api/README.md
new file mode 100755
index 0000000..a726acb
--- /dev/null
+++ b/utils/flask_rest_api/README.md
@@ -0,0 +1,73 @@
+# Flask REST API
+
+[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) [API](https://en.wikipedia.org/wiki/API)s are
+commonly used to expose Machine Learning (ML) models to other services. This folder contains an example REST API
+created using Flask to expose the YOLOv5s model from [PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5/).
+
+## Requirements
+
+[Flask](https://palletsprojects.com/p/flask/) is required. Install with:
+
+```shell
+$ pip install Flask
+```
+
+## Run
+
+After Flask installation run:
+
+```shell
+$ python3 restapi.py --port 5000
+```
+
+Then use [curl](https://curl.se/) to perform a request:
+
+```shell
+$ curl -X POST -F image=@zidane.jpg 'http://localhost:5000/v1/object-detection/yolov5s'
+```
+
+The model inference results are returned as a JSON response:
+
+```json
+[
+ {
+ "class": 0,
+ "confidence": 0.8900438547,
+ "height": 0.9318675399,
+ "name": "person",
+ "width": 0.3264600933,
+ "xcenter": 0.7438579798,
+ "ycenter": 0.5207948685
+ },
+ {
+ "class": 0,
+ "confidence": 0.8440024257,
+ "height": 0.7155083418,
+ "name": "person",
+ "width": 0.6546785235,
+ "xcenter": 0.427829951,
+ "ycenter": 0.6334488392
+ },
+ {
+ "class": 27,
+ "confidence": 0.3771208823,
+ "height": 0.3902671337,
+ "name": "tie",
+ "width": 0.0696444362,
+ "xcenter": 0.3675483763,
+ "ycenter": 0.7991207838
+ },
+ {
+ "class": 27,
+ "confidence": 0.3527112305,
+ "height": 0.1540903747,
+ "name": "tie",
+ "width": 0.0336618312,
+ "xcenter": 0.7814827561,
+ "ycenter": 0.5065554976
+ }
+]
+```
+
+An example python script to perform inference using [requests](https://docs.python-requests.org/en/master/) is given
+in `example_request.py`
diff --git a/utils/flask_rest_api/example_request.py b/utils/flask_rest_api/example_request.py
new file mode 100755
index 0000000..773ad89
--- /dev/null
+++ b/utils/flask_rest_api/example_request.py
@@ -0,0 +1,19 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Perform test request
+"""
+
+import pprint
+
+import requests
+
+DETECTION_URL = "http://localhost:5000/v1/object-detection/yolov5s"
+IMAGE = "zidane.jpg"
+
+# Read image
+with open(IMAGE, "rb") as f:
+ image_data = f.read()
+
+response = requests.post(DETECTION_URL, files={"image": image_data}).json()
+
+pprint.pprint(response)
diff --git a/utils/flask_rest_api/restapi.py b/utils/flask_rest_api/restapi.py
new file mode 100755
index 0000000..8482435
--- /dev/null
+++ b/utils/flask_rest_api/restapi.py
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Run a Flask REST API exposing one or more YOLOv5s models
+"""
+
+import argparse
+import io
+
+import torch
+from flask import Flask, request
+from PIL import Image
+
+app = Flask(__name__)
+models = {}
+
+DETECTION_URL = "/v1/object-detection/"
+
+
+@app.route(DETECTION_URL, methods=["POST"])
+def predict(model):
+ if request.method != "POST":
+ return
+
+ if request.files.get("image"):
+ # Method 1
+ # with request.files["image"] as f:
+ # im = Image.open(io.BytesIO(f.read()))
+
+ # Method 2
+ im_file = request.files["image"]
+ im_bytes = im_file.read()
+ im = Image.open(io.BytesIO(im_bytes))
+
+ if model in models:
+ results = models[model](im, size=640) # reduce size=320 for faster inference
+ return results.pandas().xyxy[0].to_json(orient="records")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Flask API exposing YOLOv5 model")
+ parser.add_argument("--port", default=5000, type=int, help="port number")
+ parser.add_argument('--model', nargs='+', default=['yolov5s'], help='model(s) to run, i.e. --model yolov5n yolov5s')
+ opt = parser.parse_args()
+
+ for m in opt.model:
+ models[m] = torch.hub.load("ultralytics/yolov5", m, force_reload=True, skip_validation=True)
+
+ app.run(host="0.0.0.0", port=opt.port) # debug=True causes Restarting with stat
diff --git a/utils/general.py b/utils/general.py
new file mode 100755
index 0000000..4a4aadb
--- /dev/null
+++ b/utils/general.py
@@ -0,0 +1,1034 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+General utils
+"""
+
+import contextlib
+import glob
+import inspect
+import logging
+import math
+import os
+import platform
+import random
+import re
+import shutil
+import signal
+import sys
+import threading
+import time
+import urllib
+from datetime import datetime
+from itertools import repeat
+from multiprocessing.pool import ThreadPool
+from pathlib import Path
+from subprocess import check_output
+from typing import Optional
+from zipfile import ZipFile
+
+import cv2
+import numpy as np
+import pandas as pd
+import pkg_resources as pkg
+import torch
+import torchvision
+import yaml
+
+from utils.downloads import gsutil_getsize
+from utils.metrics import box_iou, fitness
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+RANK = int(os.getenv('RANK', -1))
+
+# Settings
+DATASETS_DIR = ROOT.parent / 'datasets' # YOLOv5 datasets directory
+NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
+AUTOINSTALL = str(os.getenv('YOLOv5_AUTOINSTALL', True)).lower() == 'true' # global auto-install mode
+VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true' # global verbose mode
+FONT = 'Arial.ttf' # https://ultralytics.com/assets/Arial.ttf
+
+torch.set_printoptions(linewidth=320, precision=5, profile='long')
+np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
+pd.options.display.max_columns = 10
+cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
+os.environ['NUMEXPR_MAX_THREADS'] = str(NUM_THREADS) # NumExpr max threads
+os.environ['OMP_NUM_THREADS'] = '1' if platform.system() == 'darwin' else str(NUM_THREADS) # OpenMP (PyTorch and SciPy)
+
+
+def is_ascii(s=''):
+ # Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
+ s = str(s) # convert list, tuple, None, etc. to str
+ return len(s.encode().decode('ascii', 'ignore')) == len(s)
+
+
+def is_chinese(s='人工智能'):
+ # Is string composed of any Chinese characters?
+ return bool(re.search('[\u4e00-\u9fff]', str(s)))
+
+
+def is_colab():
+ # Is environment a Google Colab instance?
+ return 'COLAB_GPU' in os.environ
+
+
+def is_kaggle():
+ # Is environment a Kaggle Notebook?
+ return os.environ.get('PWD') == '/kaggle/working' and os.environ.get('KAGGLE_URL_BASE') == 'https://www.kaggle.com'
+
+
+def is_docker() -> bool:
+ """Check if the process runs inside a docker container."""
+ if Path("/.dockerenv").exists():
+ return True
+ try: # check if docker is in control groups
+ with open("/proc/self/cgroup") as file:
+ return any("docker" in line for line in file)
+ except OSError:
+ return False
+
+
+def is_writeable(dir, test=False):
+ # Return True if directory has write permissions, test opening a file with write permissions if test=True
+ if not test:
+ return os.access(dir, os.W_OK) # possible issues on Windows
+ file = Path(dir) / 'tmp.txt'
+ try:
+ with open(file, 'w'): # open file with write permissions
+ pass
+ file.unlink() # remove file
+ return True
+ except OSError:
+ return False
+
+
+def set_logging(name=None, verbose=VERBOSE):
+ # Sets level and returns logger
+ if is_kaggle() or is_colab():
+ for h in logging.root.handlers:
+ logging.root.removeHandler(h) # remove all handlers associated with the root logger object
+ rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
+ level = logging.INFO if verbose and rank in {-1, 0} else logging.ERROR
+ log = logging.getLogger(name)
+ log.setLevel(level)
+ handler = logging.StreamHandler()
+ handler.setFormatter(logging.Formatter("%(message)s"))
+ handler.setLevel(level)
+ log.addHandler(handler)
+
+
+set_logging() # run before defining LOGGER
+LOGGER = logging.getLogger("yolov5") # define globally (used in train.py, val.py, detect.py, etc.)
+if platform.system() == 'Windows':
+ for fn in LOGGER.info, LOGGER.warning:
+ setattr(LOGGER, fn.__name__, lambda x: fn(emojis(x))) # emoji safe logging
+
+
+def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
+ # Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
+ env = os.getenv(env_var)
+ if env:
+ path = Path(env) # use environment variable
+ else:
+ cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
+ path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
+ path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
+ path.mkdir(exist_ok=True) # make if required
+ return path
+
+
+CONFIG_DIR = user_config_dir() # Ultralytics settings dir
+
+
+class Profile(contextlib.ContextDecorator):
+ # Usage: @Profile() decorator or 'with Profile():' context manager
+ def __enter__(self):
+ self.start = time.time()
+
+ def __exit__(self, type, value, traceback):
+ print(f'Profile results: {time.time() - self.start:.5f}s')
+
+
+class Timeout(contextlib.ContextDecorator):
+ # Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
+ def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
+ self.seconds = int(seconds)
+ self.timeout_message = timeout_msg
+ self.suppress = bool(suppress_timeout_errors)
+
+ def _timeout_handler(self, signum, frame):
+ raise TimeoutError(self.timeout_message)
+
+ def __enter__(self):
+ if platform.system() != 'Windows': # not supported on Windows
+ signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
+ signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ if platform.system() != 'Windows':
+ signal.alarm(0) # Cancel SIGALRM if it's scheduled
+ if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
+ return True
+
+
+class WorkingDirectory(contextlib.ContextDecorator):
+ # Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager
+ def __init__(self, new_dir):
+ self.dir = new_dir # new dir
+ self.cwd = Path.cwd().resolve() # current dir
+
+ def __enter__(self):
+ os.chdir(self.dir)
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ os.chdir(self.cwd)
+
+
+def try_except(func):
+ # try-except function. Usage: @try_except decorator
+ def handler(*args, **kwargs):
+ try:
+ func(*args, **kwargs)
+ except Exception as e:
+ print(e)
+
+ return handler
+
+
+def threaded(func):
+ # Multi-threads a target function and returns thread. Usage: @threaded decorator
+ def wrapper(*args, **kwargs):
+ thread = threading.Thread(target=func, args=args, kwargs=kwargs, daemon=True)
+ thread.start()
+ return thread
+
+ return wrapper
+
+
+def methods(instance):
+ # Get class/instance methods
+ return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith("__")]
+
+
+def print_args(args: Optional[dict] = None, show_file=True, show_fcn=False):
+ # Print function arguments (optional args dict)
+ x = inspect.currentframe().f_back # previous frame
+ file, _, fcn, _, _ = inspect.getframeinfo(x)
+ if args is None: # get args automatically
+ args, _, _, frm = inspect.getargvalues(x)
+ args = {k: v for k, v in frm.items() if k in args}
+ s = (f'{Path(file).stem}: ' if show_file else '') + (f'{fcn}: ' if show_fcn else '')
+ LOGGER.info(colorstr(s) + ', '.join(f'{k}={v}' for k, v in args.items()))
+
+
+def init_seeds(seed=0, deterministic=False):
+ # Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
+ # cudnn seed 0 settings are slower and more reproducible, else faster and less reproducible
+ import torch.backends.cudnn as cudnn
+
+ if deterministic and check_version(torch.__version__, '1.12.0'): # https://github.com/ultralytics/yolov5/pull/8213
+ torch.use_deterministic_algorithms(True)
+ os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
+ os.environ['PYTHONHASHSEED'] = str(seed)
+
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ cudnn.benchmark, cudnn.deterministic = (False, True) if seed == 0 else (True, False)
+ torch.cuda.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed) # for Multi-GPU, exception safe
+
+
+def intersect_dicts(da, db, exclude=()):
+ # Dictionary intersection of matching keys and shapes, omitting 'exclude' keys, using da values
+ return {k: v for k, v in da.items() if k in db and not any(x in k for x in exclude) and v.shape == db[k].shape}
+
+
+def get_latest_run(search_dir='.'):
+ # Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
+ last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
+ return max(last_list, key=os.path.getctime) if last_list else ''
+
+
+def emojis(str=''):
+ # Return platform-dependent emoji-safe version of string
+ return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
+
+
+def file_age(path=__file__):
+ # Return days since last file update
+ dt = (datetime.now() - datetime.fromtimestamp(Path(path).stat().st_mtime)) # delta
+ return dt.days # + dt.seconds / 86400 # fractional days
+
+
+def file_date(path=__file__):
+ # Return human-readable file modification date, i.e. '2021-3-26'
+ t = datetime.fromtimestamp(Path(path).stat().st_mtime)
+ return f'{t.year}-{t.month}-{t.day}'
+
+
+def file_size(path):
+ # Return file/dir size (MB)
+ mb = 1 << 20 # bytes to MiB (1024 ** 2)
+ path = Path(path)
+ if path.is_file():
+ return path.stat().st_size / mb
+ elif path.is_dir():
+ return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / mb
+ else:
+ return 0.0
+
+
+def check_online():
+ # Check internet connectivity
+ import socket
+ try:
+ socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
+ return True
+ except OSError:
+ return False
+
+
+def git_describe(path=ROOT): # path must be a directory
+ # Return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
+ try:
+ assert (Path(path) / '.git').is_dir()
+ return check_output(f'git -C {path} describe --tags --long --always', shell=True).decode()[:-1]
+ except Exception:
+ return ''
+
+
+@try_except
+@WorkingDirectory(ROOT)
+def check_git_status(repo='ultralytics/yolov5'):
+ # YOLOv5 status check, recommend 'git pull' if code is out of date
+ url = f'https://github.com/{repo}'
+ msg = f', for updates see {url}'
+ s = colorstr('github: ') # string
+ assert Path('.git').exists(), s + 'skipping check (not a git repository)' + msg
+ assert check_online(), s + 'skipping check (offline)' + msg
+
+ splits = re.split(pattern=r'\s', string=check_output('git remote -v', shell=True).decode())
+ matches = [repo in s for s in splits]
+ if any(matches):
+ remote = splits[matches.index(True) - 1]
+ else:
+ remote = 'ultralytics'
+ check_output(f'git remote add {remote} {url}', shell=True)
+ check_output(f'git fetch {remote}', shell=True, timeout=5) # git fetch
+ branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
+ n = int(check_output(f'git rev-list {branch}..{remote}/master --count', shell=True)) # commits behind
+ if n > 0:
+ pull = 'git pull' if remote == 'origin' else f'git pull {remote} master'
+ s += f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use `{pull}` or `git clone {url}` to update."
+ else:
+ s += f'up to date with {url} ✅'
+ LOGGER.info(s)
+
+
+def check_python(minimum='3.7.0'):
+ # Check current python version vs. required python version
+ check_version(platform.python_version(), minimum, name='Python ', hard=True)
+
+
+def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
+ # Check version vs. required version
+ current, minimum = (pkg.parse_version(x) for x in (current, minimum))
+ result = (current == minimum) if pinned else (current >= minimum) # bool
+ s = f'{name}{minimum} required by YOLOv5, but {name}{current} is currently installed' # string
+ if hard:
+ assert result, s # assert min requirements met
+ if verbose and not result:
+ LOGGER.warning(s)
+ return result
+
+
+@try_except
+def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True, cmds=()):
+ # Check installed dependencies meet requirements (pass *.txt file or list of packages)
+ prefix = colorstr('red', 'bold', 'requirements:')
+ check_python() # check python version
+ if isinstance(requirements, (str, Path)): # requirements.txt file
+ file = Path(requirements)
+ assert file.exists(), f"{prefix} {file.resolve()} not found, check failed."
+ with file.open() as f:
+ requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(f) if x.name not in exclude]
+ else: # list or tuple of packages
+ requirements = [x for x in requirements if x not in exclude]
+
+ n = 0 # number of packages updates
+ for i, r in enumerate(requirements):
+ try:
+ pkg.require(r)
+ except Exception: # DistributionNotFound or VersionConflict if requirements not met
+ s = f"{prefix} {r} not found and is required by YOLOv5"
+ if install and AUTOINSTALL: # check environment variable
+ LOGGER.info(f"{s}, attempting auto-update...")
+ try:
+ assert check_online(), f"'pip install {r}' skipped (offline)"
+ LOGGER.info(check_output(f'pip install "{r}" {cmds[i] if cmds else ""}', shell=True).decode())
+ n += 1
+ except Exception as e:
+ LOGGER.warning(f'{prefix} {e}')
+ else:
+ LOGGER.info(f'{s}. Please install and rerun your command.')
+
+ if n: # if packages updated
+ source = file.resolve() if 'file' in locals() else requirements
+ s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
+ f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
+ LOGGER.info(s)
+
+
+def check_img_size(imgsz, s=32, floor=0):
+ # Verify image size is a multiple of stride s in each dimension
+ if isinstance(imgsz, int): # integer i.e. img_size=640
+ new_size = max(make_divisible(imgsz, int(s)), floor)
+ else: # list i.e. img_size=[640, 480]
+ imgsz = list(imgsz) # convert to list if tuple
+ new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
+ if new_size != imgsz:
+ LOGGER.warning(f'WARNING: --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
+ return new_size
+
+
+def check_imshow():
+ # Check if environment supports image displays
+ try:
+ assert not is_docker(), 'cv2.imshow() is disabled in Docker environments'
+ assert not is_colab(), 'cv2.imshow() is disabled in Google Colab environments'
+ cv2.imshow('test', np.zeros((1, 1, 3)))
+ cv2.waitKey(1)
+ cv2.destroyAllWindows()
+ cv2.waitKey(1)
+ return True
+ except Exception as e:
+ LOGGER.warning(f'WARNING: Environment does not support cv2.imshow() or PIL Image.show() image displays\n{e}')
+ return False
+
+
+def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
+ # Check file(s) for acceptable suffix
+ if file and suffix:
+ if isinstance(suffix, str):
+ suffix = [suffix]
+ for f in file if isinstance(file, (list, tuple)) else [file]:
+ s = Path(f).suffix.lower() # file suffix
+ if len(s):
+ assert s in suffix, f"{msg}{f} acceptable suffix is {suffix}"
+
+
+def check_yaml(file, suffix=('.yaml', '.yml')):
+ # Search/download YAML file (if necessary) and return path, checking suffix
+ return check_file(file, suffix)
+
+
+def check_file(file, suffix=''):
+ # File can be dict or pathlike
+ if isinstance(file, dict):
+ return file
+ # Search/download file (if necessary) and return path
+ check_suffix(file, suffix) # optional
+ file = str(file) # convert to str()
+ if Path(file).is_file() or not file: # exists
+ return file
+ elif file.startswith(('http:/', 'https:/')): # download
+ url = file # warning: Pathlib turns :// -> :/
+ file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
+ if Path(file).is_file():
+ LOGGER.info(f'Found {url} locally at {file}') # file already exists
+ else:
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, file)
+ assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
+ return file
+ elif file.startswith('clearml://'): # ClearML Dataset ID
+ assert 'clearml' in sys.modules, "ClearML is not installed, so cannot use ClearML dataset. Try running 'pip install clearml'."
+ return file
+ else: # search
+ files = []
+ for d in 'data', 'models', 'utils': # search directories
+ files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
+ assert len(files), f'File not found: {file}' # assert file was found
+ assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
+ return files[0] # return file
+
+
+def check_font(font=FONT, progress=False):
+ # Download font to CONFIG_DIR if necessary
+ font = Path(font)
+ file = CONFIG_DIR / font.name
+ if not font.exists() and not file.exists():
+ url = "https://ultralytics.com/assets/" + font.name
+ LOGGER.info(f'Downloading {url} to {file}...')
+ torch.hub.download_url_to_file(url, str(file), progress=progress)
+
+
+def check_dataset(data, autodownload=True):
+ # Download, check and/or unzip dataset if not found locally
+
+ # Download (optional)
+ extract_dir = ''
+ if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
+ download(data, dir=f'{DATASETS_DIR}/{Path(data).stem}', unzip=True, delete=False, curl=False, threads=1)
+ data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
+ extract_dir, autodownload = data.parent, False
+
+ # Read yaml (optional)
+ if isinstance(data, (str, Path)):
+ with open(data, errors='ignore') as f:
+ data = yaml.safe_load(f) # dictionary
+
+ # Checks
+ for k in 'train', 'val', 'nc':
+ assert k in data, f"data.yaml '{k}:' field missing ❌"
+ if 'names' not in data:
+ LOGGER.warning("data.yaml 'names:' field missing ⚠️, assigning default names 'class0', 'class1', etc.")
+ data['names'] = [f'class{i}' for i in range(data['nc'])] # default names
+
+ # Resolve paths
+ path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
+ if not path.is_absolute():
+ path = (ROOT / path).resolve()
+ for k in 'train', 'val', 'test':
+ if data.get(k): # prepend path
+ data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]
+
+ # Parse yaml
+ train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
+ if val:
+ val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
+ if not all(x.exists() for x in val):
+ LOGGER.info('\nDataset not found ⚠️, missing paths %s' % [str(x) for x in val if not x.exists()])
+ if not s or not autodownload:
+ raise Exception('Dataset not found ❌')
+ t = time.time()
+ root = path.parent if 'path' in data else '..' # unzip directory i.e. '../'
+ if s.startswith('http') and s.endswith('.zip'): # URL
+ f = Path(s).name # filename
+ LOGGER.info(f'Downloading {s} to {f}...')
+ torch.hub.download_url_to_file(s, f)
+ Path(root).mkdir(parents=True, exist_ok=True) # create root
+ ZipFile(f).extractall(path=root) # unzip
+ Path(f).unlink() # remove zip
+ r = None # success
+ elif s.startswith('bash '): # bash script
+ LOGGER.info(f'Running {s} ...')
+ r = os.system(s)
+ else: # python script
+ r = exec(s, {'yaml': data}) # return None
+ dt = f'({round(time.time() - t, 1)}s)'
+ s = f"success ✅ {dt}, saved to {colorstr('bold', root)}" if r in (0, None) else f"failure {dt} ❌"
+ LOGGER.info(f"Dataset download {s}")
+ check_font('Arial.ttf' if is_ascii(data['names']) else 'Arial.Unicode.ttf', progress=True) # download fonts
+ return data # dictionary
+
+
+def check_amp(model):
+ # Check PyTorch Automatic Mixed Precision (AMP) functionality. Return True on correct operation
+ from models.common import AutoShape, DetectMultiBackend
+
+ def amp_allclose(model, im):
+ # All close FP32 vs AMP results
+ m = AutoShape(model, verbose=False) # model
+ a = m(im).xywhn[0] # FP32 inference
+ m.amp = True
+ b = m(im).xywhn[0] # AMP inference
+ return a.shape == b.shape and torch.allclose(a, b, atol=0.1) # close to 10% absolute tolerance
+
+ prefix = colorstr('AMP: ')
+ device = next(model.parameters()).device # get model device
+ if device.type == 'cpu':
+ return False # AMP disabled on CPU
+ f = ROOT / 'data' / 'images' / 'bus.jpg' # image to check
+ im = f if f.exists() else 'https://ultralytics.com/images/bus.jpg' if check_online() else np.ones((640, 640, 3))
+ try:
+ assert amp_allclose(model, im) or amp_allclose(DetectMultiBackend('yolov5n.pt', device), im)
+ LOGGER.info(f'{prefix}checks passed ✅')
+ return True
+ except Exception:
+ help_url = 'https://github.com/ultralytics/yolov5/issues/7908'
+ LOGGER.warning(f'{prefix}checks failed ❌, disabling Automatic Mixed Precision. See {help_url}')
+ return False
+
+
+def url2file(url):
+ # Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
+ url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
+ return Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
+
+
+def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1, retry=3):
+ # Multi-threaded file download and unzip function, used in data.yaml for autodownload
+ def download_one(url, dir):
+ # Download 1 file
+ success = True
+ f = dir / Path(url).name # filename
+ if Path(url).is_file(): # exists in current path
+ Path(url).rename(f) # move to dir
+ elif not f.exists():
+ LOGGER.info(f'Downloading {url} to {f}...')
+ for i in range(retry + 1):
+ if curl:
+ s = 'sS' if threads > 1 else '' # silent
+ r = os.system(f'curl -{s}L "{url}" -o "{f}" --retry 9 -C -') # curl download with retry, continue
+ success = r == 0
+ else:
+ torch.hub.download_url_to_file(url, f, progress=threads == 1) # torch download
+ success = f.is_file()
+ if success:
+ break
+ elif i < retry:
+ LOGGER.warning(f'Download failure, retrying {i + 1}/{retry} {url}...')
+ else:
+ LOGGER.warning(f'Failed to download {url}...')
+
+ if unzip and success and f.suffix in ('.zip', '.tar', '.gz'):
+ LOGGER.info(f'Unzipping {f}...')
+ if f.suffix == '.zip':
+ ZipFile(f).extractall(path=dir) # unzip
+ elif f.suffix == '.tar':
+ os.system(f'tar xf {f} --directory {f.parent}') # unzip
+ elif f.suffix == '.gz':
+ os.system(f'tar xfz {f} --directory {f.parent}') # unzip
+ if delete:
+ f.unlink() # remove zip
+
+ dir = Path(dir)
+ dir.mkdir(parents=True, exist_ok=True) # make directory
+ if threads > 1:
+ pool = ThreadPool(threads)
+ pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multi-threaded
+ pool.close()
+ pool.join()
+ else:
+ for u in [url] if isinstance(url, (str, Path)) else url:
+ download_one(u, dir)
+
+
+def make_divisible(x, divisor):
+ # Returns nearest x divisible by divisor
+ if isinstance(divisor, torch.Tensor):
+ divisor = int(divisor.max()) # to int
+ return math.ceil(x / divisor) * divisor
+
+
+def clean_str(s):
+ # Cleans a string by replacing special characters with underscore _
+ return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
+
+
+def one_cycle(y1=0.0, y2=1.0, steps=100):
+ # lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
+ return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
+
+
+def colorstr(*input):
+ # Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
+ *args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
+ colors = {
+ 'black': '\033[30m', # basic colors
+ 'red': '\033[31m',
+ 'green': '\033[32m',
+ 'yellow': '\033[33m',
+ 'blue': '\033[34m',
+ 'magenta': '\033[35m',
+ 'cyan': '\033[36m',
+ 'white': '\033[37m',
+ 'bright_black': '\033[90m', # bright colors
+ 'bright_red': '\033[91m',
+ 'bright_green': '\033[92m',
+ 'bright_yellow': '\033[93m',
+ 'bright_blue': '\033[94m',
+ 'bright_magenta': '\033[95m',
+ 'bright_cyan': '\033[96m',
+ 'bright_white': '\033[97m',
+ 'end': '\033[0m', # misc
+ 'bold': '\033[1m',
+ 'underline': '\033[4m'}
+ return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
+
+
+def labels_to_class_weights(labels, nc=80):
+ # Get class weights (inverse frequency) from training labels
+ if labels[0] is None: # no labels loaded
+ return torch.Tensor()
+
+ labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
+ classes = labels[:, 0].astype(int) # labels = [class xywh]
+ weights = np.bincount(classes, minlength=nc) # occurrences per class
+
+ # Prepend gridpoint count (for uCE training)
+ # gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
+ # weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
+
+ weights[weights == 0] = 1 # replace empty bins with 1
+ weights = 1 / weights # number of targets per class
+ weights /= weights.sum() # normalize
+ return torch.from_numpy(weights).float()
+
+
+def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
+ # Produces image weights based on class_weights and image contents
+ # Usage: index = random.choices(range(n), weights=image_weights, k=1) # weighted image sample
+ class_counts = np.array([np.bincount(x[:, 0].astype(int), minlength=nc) for x in labels])
+ return (class_weights.reshape(1, nc) * class_counts).sum(1)
+
+
+def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
+ # https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
+ # a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
+ # b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
+ # x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
+ # x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
+ return [
+ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
+ 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
+ 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
+
+
+def xyxy2xywh(x):
+ # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
+ y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
+ y[:, 2] = x[:, 2] - x[:, 0] # width
+ y[:, 3] = x[:, 3] - x[:, 1] # height
+ return y
+
+
+def xywh2xyxy(x):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
+ y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
+ y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
+ y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
+ return y
+
+
+def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
+ # Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
+ y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
+ y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
+ y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
+ return y
+
+
+def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
+ # Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
+ if clip:
+ clip_coords(x, (h - eps, w - eps)) # warning: inplace clip
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
+ y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
+ y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
+ y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
+ return y
+
+
+def xyn2xy(x, w=640, h=640, padw=0, padh=0):
+ # Convert normalized segments into pixel segments, shape (n,2)
+ y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
+ y[:, 0] = w * x[:, 0] + padw # top left x
+ y[:, 1] = h * x[:, 1] + padh # top left y
+ return y
+
+
+def segment2box(segment, width=640, height=640):
+ # Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
+ x, y = segment.T # segment xy
+ inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
+ x, y, = x[inside], y[inside]
+ return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
+
+
+def segments2boxes(segments):
+ # Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
+ boxes = []
+ for s in segments:
+ x, y = s.T # segment xy
+ boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
+ return xyxy2xywh(np.array(boxes)) # cls, xywh
+
+
+def resample_segments(segments, n=1000):
+ # Up-sample an (n,2) segment
+ for i, s in enumerate(segments):
+ s = np.concatenate((s, s[0:1, :]), axis=0)
+ x = np.linspace(0, len(s) - 1, n)
+ xp = np.arange(len(s))
+ segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
+ return segments
+
+
+def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
+ # Rescale coords (xyxy) from img1_shape to img0_shape
+ if ratio_pad is None: # calculate from img0_shape
+ gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
+ pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
+ else:
+ gain = ratio_pad[0][0]
+ pad = ratio_pad[1]
+
+ coords[:, [0, 2]] -= pad[0] # x padding
+ coords[:, [1, 3]] -= pad[1] # y padding
+ coords[:, :4] /= gain
+ clip_coords(coords, img0_shape)
+ return coords
+
+
+def clip_coords(boxes, shape):
+ # Clip bounding xyxy bounding boxes to image shape (height, width)
+ if isinstance(boxes, torch.Tensor): # faster individually
+ boxes[:, 0].clamp_(0, shape[1]) # x1
+ boxes[:, 1].clamp_(0, shape[0]) # y1
+ boxes[:, 2].clamp_(0, shape[1]) # x2
+ boxes[:, 3].clamp_(0, shape[0]) # y2
+ else: # np.array (faster grouped)
+ boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
+ boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
+
+
+def non_max_suppression(prediction,
+ conf_thres=0.25,
+ iou_thres=0.45,
+ classes=None,
+ agnostic=False,
+ multi_label=False,
+ labels=(),
+ max_det=300):
+ """Non-Maximum Suppression (NMS) on inference results to reject overlapping bounding boxes
+
+ Returns:
+ list of detections, on (n,6) tensor per image [xyxy, conf, cls]
+ """
+
+ bs = prediction.shape[0] # batch size
+ nc = prediction.shape[2] - 5 # number of classes
+ xc = prediction[..., 4] > conf_thres # candidates
+
+ # Checks
+ assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
+ assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
+
+ # Settings
+ # min_wh = 2 # (pixels) minimum box width and height
+ max_wh = 7680 # (pixels) maximum box width and height
+ max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
+ time_limit = 0.3 + 0.03 * bs # seconds to quit after
+ redundant = True # require redundant detections
+ multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
+ merge = False # use merge-NMS
+
+ t = time.time()
+ output = [torch.zeros((0, 6), device=prediction.device)] * bs
+ for xi, x in enumerate(prediction): # image index, image inference
+ # Apply constraints
+ # x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
+ x = x[xc[xi]] # confidence
+
+ # Cat apriori labels if autolabelling
+ if labels and len(labels[xi]):
+ lb = labels[xi]
+ v = torch.zeros((len(lb), nc + 5), device=x.device)
+ v[:, :4] = lb[:, 1:5] # box
+ v[:, 4] = 1.0 # conf
+ v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
+ x = torch.cat((x, v), 0)
+
+ # If none remain process next image
+ if not x.shape[0]:
+ continue
+
+ # Compute conf
+ x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
+
+ # Box (center x, center y, width, height) to (x1, y1, x2, y2)
+ box = xywh2xyxy(x[:, :4])
+
+ # Detections matrix nx6 (xyxy, conf, cls)
+ if multi_label:
+ i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
+ x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
+ else: # best class only
+ conf, j = x[:, 5:].max(1, keepdim=True)
+ x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
+
+ # Filter by class
+ if classes is not None:
+ x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
+
+ # Apply finite constraint
+ # if not torch.isfinite(x).all():
+ # x = x[torch.isfinite(x).all(1)]
+
+ # Check shape
+ n = x.shape[0] # number of boxes
+ if not n: # no boxes
+ continue
+ elif n > max_nms: # excess boxes
+ x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
+
+ # Batched NMS
+ c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
+ boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
+ i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
+ if i.shape[0] > max_det: # limit detections
+ i = i[:max_det]
+ if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
+ # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
+ iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
+ weights = iou * scores[None] # box weights
+ x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
+ if redundant:
+ i = i[iou.sum(1) > 1] # require redundancy
+
+ output[xi] = x[i]
+
+ return output
+
+
+def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
+ # Strip optimizer from 'f' to finalize training, optionally save as 's'
+ x = torch.load(f, map_location=torch.device('cpu'))
+ if x.get('ema'):
+ x['model'] = x['ema'] # replace model with ema
+ for k in 'optimizer', 'best_fitness', 'wandb_id', 'ema', 'updates': # keys
+ x[k] = None
+ x['epoch'] = -1
+ x['model'].half() # to FP16
+ for p in x['model'].parameters():
+ p.requires_grad = False
+ torch.save(x, s or f)
+ mb = os.path.getsize(s or f) / 1E6 # filesize
+ LOGGER.info(f"Optimizer stripped from {f},{f' saved as {s},' if s else ''} {mb:.1f}MB")
+
+
+def print_mutation(results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
+ evolve_csv = save_dir / 'evolve.csv'
+ evolve_yaml = save_dir / 'hyp_evolve.yaml'
+ keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss',
+ 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys()) # [results + hyps]
+ keys = tuple(x.strip() for x in keys)
+ vals = results + tuple(hyp.values())
+ n = len(keys)
+
+ # Download (optional)
+ if bucket:
+ url = f'gs://{bucket}/evolve.csv'
+ if gsutil_getsize(url) > (evolve_csv.stat().st_size if evolve_csv.exists() else 0):
+ os.system(f'gsutil cp {url} {save_dir}') # download evolve.csv if larger than local
+
+ # Log to evolve.csv
+ s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
+ with open(evolve_csv, 'a') as f:
+ f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
+
+ # Save yaml
+ with open(evolve_yaml, 'w') as f:
+ data = pd.read_csv(evolve_csv)
+ data = data.rename(columns=lambda x: x.strip()) # strip keys
+ i = np.argmax(fitness(data.values[:, :4])) #
+ generations = len(data)
+ f.write('# YOLOv5 Hyperparameter Evolution Results\n' + f'# Best generation: {i}\n' +
+ f'# Last generation: {generations - 1}\n' + '# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) +
+ '\n' + '# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
+ yaml.safe_dump(data.loc[i][7:].to_dict(), f, sort_keys=False)
+
+ # Print to screen
+ LOGGER.info(prefix + f'{generations} generations finished, current result:\n' + prefix +
+ ', '.join(f'{x.strip():>20s}' for x in keys) + '\n' + prefix + ', '.join(f'{x:20.5g}'
+ for x in vals) + '\n\n')
+
+ if bucket:
+ os.system(f'gsutil cp {evolve_csv} {evolve_yaml} gs://{bucket}') # upload
+
+
+def apply_classifier(x, model, img, im0):
+ # Apply a second stage classifier to YOLO outputs
+ # Example model = torchvision.models.__dict__['efficientnet_b0'](pretrained=True).to(device).eval()
+ im0 = [im0] if isinstance(im0, np.ndarray) else im0
+ for i, d in enumerate(x): # per image
+ if d is not None and len(d):
+ d = d.clone()
+
+ # Reshape and pad cutouts
+ b = xyxy2xywh(d[:, :4]) # boxes
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
+ b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
+ d[:, :4] = xywh2xyxy(b).long()
+
+ # Rescale boxes from img_size to im0 size
+ scale_coords(img.shape[2:], d[:, :4], im0[i].shape)
+
+ # Classes
+ pred_cls1 = d[:, 5].long()
+ ims = []
+ for a in d:
+ cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
+ im = cv2.resize(cutout, (224, 224)) # BGR
+
+ im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
+ im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ ims.append(im)
+
+ pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
+ x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
+
+ return x
+
+
+def increment_path(path, exist_ok=False, sep='', mkdir=False):
+ # Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
+ path = Path(path) # os-agnostic
+ if path.exists() and not exist_ok:
+ path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
+
+ # Method 1
+ for n in range(2, 9999):
+ p = f'{path}{sep}{n}{suffix}' # increment path
+ if not os.path.exists(p): #
+ break
+ path = Path(p)
+
+ # Method 2 (deprecated)
+ # dirs = glob.glob(f"{path}{sep}*") # similar paths
+ # matches = [re.search(rf"{path.stem}{sep}(\d+)", d) for d in dirs]
+ # i = [int(m.groups()[0]) for m in matches if m] # indices
+ # n = max(i) + 1 if i else 2 # increment number
+ # path = Path(f"{path}{sep}{n}{suffix}") # increment path
+
+ if mkdir:
+ path.mkdir(parents=True, exist_ok=True) # make directory
+
+ return path
+
+
+# OpenCV Chinese-friendly functions ------------------------------------------------------------------------------------
+imshow_ = cv2.imshow # copy to avoid recursion errors
+
+
+def imread(path, flags=cv2.IMREAD_COLOR):
+ return cv2.imdecode(np.fromfile(path, np.uint8), flags)
+
+
+def imwrite(path, im):
+ try:
+ cv2.imencode(Path(path).suffix, im)[1].tofile(path)
+ return True
+ except Exception:
+ return False
+
+
+def imshow(path, im):
+ imshow_(path.encode('unicode_escape').decode(), im)
+
+
+cv2.imread, cv2.imwrite, cv2.imshow = imread, imwrite, imshow # redefine
+
+# Variables ------------------------------------------------------------------------------------------------------------
+NCOLS = 0 if is_docker() else shutil.get_terminal_size().columns # terminal window size for tqdm
diff --git a/utils/google_app_engine/Dockerfile b/utils/google_app_engine/Dockerfile
new file mode 100755
index 0000000..0155618
--- /dev/null
+++ b/utils/google_app_engine/Dockerfile
@@ -0,0 +1,25 @@
+FROM gcr.io/google-appengine/python
+
+# Create a virtualenv for dependencies. This isolates these packages from
+# system-level packages.
+# Use -p python3 or -p python3.7 to select python version. Default is version 2.
+RUN virtualenv /env -p python3
+
+# Setting these environment variables are the same as running
+# source /env/bin/activate.
+ENV VIRTUAL_ENV /env
+ENV PATH /env/bin:$PATH
+
+RUN apt-get update && apt-get install -y python-opencv
+
+# Copy the application's requirements.txt and run pip to install all
+# dependencies into the virtualenv.
+ADD requirements.txt /app/requirements.txt
+RUN pip install -r /app/requirements.txt
+
+# Add the application source code.
+ADD . /app
+
+# Run a WSGI server to serve the application. gunicorn must be declared as
+# a dependency in requirements.txt.
+CMD gunicorn -b :$PORT main:app
diff --git a/utils/google_app_engine/additional_requirements.txt b/utils/google_app_engine/additional_requirements.txt
new file mode 100755
index 0000000..42d7ffc
--- /dev/null
+++ b/utils/google_app_engine/additional_requirements.txt
@@ -0,0 +1,4 @@
+# add these requirements in your app on top of the existing ones
+pip==21.1
+Flask==1.0.2
+gunicorn==19.9.0
diff --git a/utils/google_app_engine/app.yaml b/utils/google_app_engine/app.yaml
new file mode 100755
index 0000000..5056b7c
--- /dev/null
+++ b/utils/google_app_engine/app.yaml
@@ -0,0 +1,14 @@
+runtime: custom
+env: flex
+
+service: yolov5app
+
+liveness_check:
+ initial_delay_sec: 600
+
+manual_scaling:
+ instances: 1
+resources:
+ cpu: 1
+ memory_gb: 4
+ disk_size_gb: 20
diff --git a/utils/loggers/__init__.py b/utils/loggers/__init__.py
new file mode 100755
index 0000000..d46be8e
--- /dev/null
+++ b/utils/loggers/__init__.py
@@ -0,0 +1,235 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Logging utils
+"""
+
+import os
+import warnings
+
+import pkg_resources as pkg
+import torch
+from torch.utils.tensorboard import SummaryWriter
+
+from utils.general import colorstr, cv2
+from utils.loggers.clearml.clearml_utils import ClearmlLogger
+from utils.loggers.wandb.wandb_utils import WandbLogger
+from utils.plots import plot_images, plot_results
+from utils.torch_utils import de_parallel
+
+LOGGERS = ('csv', 'tb', 'wandb', 'clearml') # *.csv, TensorBoard, Weights & Biases, ClearML
+RANK = int(os.getenv('RANK', -1))
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+ if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.2') and RANK in {0, -1}:
+ try:
+ wandb_login_success = wandb.login(timeout=30)
+ except wandb.errors.UsageError: # known non-TTY terminal issue
+ wandb_login_success = False
+ if not wandb_login_success:
+ wandb = None
+except (ImportError, AssertionError):
+ wandb = None
+
+try:
+ import clearml
+
+ assert hasattr(clearml, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ clearml = None
+
+
+class Loggers():
+ # YOLOv5 Loggers class
+ def __init__(self, save_dir=None, weights=None, opt=None, hyp=None, logger=None, include=LOGGERS):
+ self.save_dir = save_dir
+ self.weights = weights
+ self.opt = opt
+ self.hyp = hyp
+ self.logger = logger # for printing results to console
+ self.include = include
+ self.keys = [
+ 'train/box_loss',
+ 'train/obj_loss',
+ 'train/cls_loss', # train loss
+ 'metrics/precision',
+ 'metrics/recall',
+ 'metrics/mAP_0.5',
+ 'metrics/mAP_0.5:0.95', # metrics
+ 'val/box_loss',
+ 'val/obj_loss',
+ 'val/cls_loss', # val loss
+ 'x/lr0',
+ 'x/lr1',
+ 'x/lr2'] # params
+ self.best_keys = ['best/epoch', 'best/precision', 'best/recall', 'best/mAP_0.5', 'best/mAP_0.5:0.95']
+ for k in LOGGERS:
+ setattr(self, k, None) # init empty logger dictionary
+ self.csv = True # always log to csv
+
+ # Messages
+ if not wandb:
+ prefix = colorstr('Weights & Biases: ')
+ s = f"{prefix}run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases"
+ self.logger.info(s)
+ if not clearml:
+ prefix = colorstr('ClearML: ')
+ s = f"{prefix}run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 runs in ClearML"
+ self.logger.info(s)
+
+ # TensorBoard
+ s = self.save_dir
+ if 'tb' in self.include and (not self.opt.evolve or self.opt.optuna):
+ prefix = colorstr('TensorBoard: ')
+ self.logger.info(f"{prefix}Start with 'tensorboard --logdir {s.parent}', view at http://localhost:6006/")
+ self.tb = SummaryWriter(str(s))
+
+ # W&B
+ if wandb and 'wandb' in self.include:
+ wandb_artifact_resume = isinstance(self.opt.resume, str) and self.opt.resume.startswith('wandb-artifact://')
+ run_id = torch.load(self.weights).get('wandb_id') if self.opt.resume and not wandb_artifact_resume else None
+ self.opt.hyp = self.hyp # add hyperparameters
+ self.wandb = WandbLogger(self.opt, run_id)
+ # temp warn. because nested artifacts not supported after 0.12.10
+ if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.11'):
+ s = "YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected."
+ self.logger.warning(s)
+ else:
+ self.wandb = None
+
+ # ClearML
+ if clearml and 'clearml' in self.include:
+ self.clearml = ClearmlLogger(self.opt, self.hyp)
+ else:
+ self.clearml = None
+
+ def on_train_start(self):
+ # Callback runs on train start
+ pass
+
+ def on_pretrain_routine_end(self):
+ # Callback runs on pre-train routine end
+ paths = self.save_dir.glob('*labels*.jpg') # training labels
+ if self.wandb:
+ self.wandb.log({"Labels": [wandb.Image(str(x), caption=x.name) for x in paths]})
+ if self.clearml:
+ pass # ClearML saves these images automatically using hooks
+
+ def on_train_batch_end(self, ni, model, imgs, targets, paths, plots):
+ # Callback runs on train batch end
+ # ni: number integrated batches (since train start)
+ if plots:
+ if ni == 0:
+ if self.tb and not self.opt.sync_bn: # --sync known issue https://github.com/ultralytics/yolov5/issues/3754
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress jit trace warning
+ self.tb.add_graph(torch.jit.trace(de_parallel(model), imgs[0:1], strict=False), [])
+ if ni < 3:
+ f = self.save_dir / f'train_batch{ni}.jpg' # filename
+ plot_images(imgs, targets, paths, f)
+ if (self.wandb or self.clearml) and ni == 10:
+ files = sorted(self.save_dir.glob('train*.jpg'))
+ if self.wandb:
+ self.wandb.log({'Mosaics': [wandb.Image(str(f), caption=f.name) for f in files if f.exists()]})
+ if self.clearml:
+ self.clearml.log_debug_samples(files, title='Mosaics')
+
+ def on_train_epoch_end(self, epoch):
+ # Callback runs on train epoch end
+ if self.wandb:
+ self.wandb.current_epoch = epoch + 1
+
+ def on_val_image_end(self, pred, predn, path, names, im):
+ # Callback runs on val image end
+ if self.wandb:
+ self.wandb.val_one_image(pred, predn, path, names, im)
+ if self.clearml:
+ self.clearml.log_image_with_boxes(path, pred, names, im)
+
+ def on_val_end(self):
+ # Callback runs on val end
+ if self.wandb or self.clearml:
+ files = sorted(self.save_dir.glob('val*.jpg'))
+ if self.wandb:
+ self.wandb.log({"Validation": [wandb.Image(str(f), caption=f.name) for f in files]})
+ if self.clearml:
+ self.clearml.log_debug_samples(files, title='Validation')
+
+ def on_fit_epoch_end(self, vals, epoch, best_fitness, fi):
+ # Callback runs at the end of each fit (train+val) epoch
+ x = dict(zip(self.keys, vals))
+ if self.csv:
+ file = self.save_dir / 'results.csv'
+ n = len(x) + 1 # number of cols
+ s = '' if file.exists() else (('%20s,' * n % tuple(['epoch'] + self.keys)).rstrip(',') + '\n') # add header
+ with open(file, 'a') as f:
+ f.write(s + ('%20.5g,' * n % tuple([epoch] + vals)).rstrip(',') + '\n')
+
+ if self.tb:
+ for k, v in x.items():
+ self.tb.add_scalar(k, v, epoch)
+ elif self.clearml: # log to ClearML if TensorBoard not used
+ for k, v in x.items():
+ title, series = k.split('/')
+ self.clearml.task.get_logger().report_scalar(title, series, v, epoch)
+
+ if self.wandb:
+ if best_fitness == fi:
+ best_results = [epoch] + vals[3:7]
+ for i, name in enumerate(self.best_keys):
+ self.wandb.wandb_run.summary[name] = best_results[i] # log best results in the summary
+ self.wandb.log(x)
+ self.wandb.end_epoch(best_result=best_fitness == fi)
+
+ if self.clearml:
+ self.clearml.current_epoch_logged_images = set() # reset epoch image limit
+ self.clearml.current_epoch += 1
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ # Callback runs on model save event
+ if self.wandb:
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.wandb.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ if self.clearml:
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.clearml.task.update_output_model(model_path=str(last),
+ model_name='Latest Model',
+ auto_delete_file=False)
+
+ def on_train_end(self, last, best, plots, epoch, results):
+ # Callback runs on training end
+ if plots:
+ plot_results(file=self.save_dir / 'results.csv') # save results.png
+ files = ['results.png', 'confusion_matrix.png', *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
+ files = [(self.save_dir / f) for f in files if (self.save_dir / f).exists()] # filter
+ self.logger.info(f"Results saved to {colorstr('bold', self.save_dir)}")
+
+ if self.tb and not self.clearml: # These images are already captured by ClearML by now, we don't want doubles
+ for f in files:
+ self.tb.add_image(f.stem, cv2.imread(str(f))[..., ::-1], epoch, dataformats='HWC')
+
+ if self.wandb:
+ self.wandb.log(dict(zip(self.keys[3:10], results)))
+ self.wandb.log({"Results": [wandb.Image(str(f), caption=f.name) for f in files]})
+ # Calling wandb.log. TODO: Refactor this into WandbLogger.log_model
+ if not self.opt.evolve:
+ wandb.log_artifact(str(best if best.exists() else last),
+ type='model',
+ name=f'run_{self.wandb.wandb_run.id}_model',
+ aliases=['latest', 'best', 'stripped'])
+ self.wandb.finish_run()
+
+ if self.clearml:
+ # Save the best model here
+ if not self.opt.evolve:
+ self.clearml.task.update_output_model(model_path=str(best if best.exists() else last),
+ name='Best Model', auto_delete_file=False)
+
+ def on_params_update(self, params):
+ # Update hyperparams or configs of the experiment
+ # params: A dict containing {param: value} pairs
+ if self.wandb:
+ self.wandb.wandb_run.config.update(params, allow_val_change=True)
diff --git a/utils/loggers/clearml/README.md b/utils/loggers/clearml/README.md
new file mode 100755
index 0000000..64eef6b
--- /dev/null
+++ b/utils/loggers/clearml/README.md
@@ -0,0 +1,222 @@
+# ClearML Integration
+
+
 +
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+And so much more. It's up to you how many of these tools you want to use, you can stick to the experiment manager, or chain them all together into an impressive pipeline!
+
+
+
+
+
+
+
+
+
+## 🦾 Setting Things Up
+
+To keep track of your experiments and/or data, ClearML needs to communicate to a server. You have 2 options to get one:
+
+Either sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-tutorial-clearml) or you can set up your own server, see [here](https://clear.ml/docs/latest/docs/deploying_clearml/clearml_server). Even the server is open-source, so even if you're dealing with sensitive data, you should be good to go!
+
+1. Install the `clearml` python package:
+
+ ```bash
+ pip install clearml
+ ```
+
+1. Connect the ClearML SDK to the server by [creating credentials](https://app.clear.ml/settings/workspace-configuration) (go right top to Settings -> Workspace -> Create new credentials), then execute the command below and follow the instructions:
+
+ ```bash
+ clearml-init
+ ```
+
+That's it! You're done 😎
+
+
+
+## 🚀 Training YOLOv5 With ClearML
+
+To enable ClearML experiment tracking, simply install the ClearML pip package.
+
+```bash
+pip install clearml
+```
+
+This will enable integration with the YOLOv5 training script. Every training run from now on, will be captured and stored by the ClearML experiment manager. If you want to change the `project_name` or `task_name`, head over to our custom logger, where you can change it: `utils/loggers/clearml/clearml_utils.py`
+
+```bash
+python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
+```
+
+This will capture:
+- Source code + uncommitted changes
+- Installed packages
+- (Hyper)parameters
+- Model files (use `--save-period n` to save a checkpoint every n epochs)
+- Console output
+- Scalars (mAP_0.5, mAP_0.5:0.95, precision, recall, losses, learning rates, ...)
+- General info such as machine details, runtime, creation date etc.
+- All produced plots such as label correlogram and confusion matrix
+- Images with bounding boxes per epoch
+- Mosaic per epoch
+- Validation images per epoch
+- ...
+
+That's a lot right? 🤯
+Now, we can visualize all of this information in the ClearML UI to get an overview of our training progress. Add custom columns to the table view (such as e.g. mAP_0.5) so you can easily sort on the best performing model. Or select multiple experiments and directly compare them!
+
+There even more we can do with all of this information, like hyperparameter optimization and remote execution, so keep reading if you want to see how that works!
+
+
+
+## 🔗 Dataset Version Management
+
+Versioning your data separately from your code is generally a good idea and makes it easy to aqcuire the latest version too. This repository supports supplying a dataset version ID and it will make sure to get the data if it's not there yet. Next to that, this workflow also saves the used dataset ID as part of the task parameters, so you will always know for sure which data was used in which experiment!
+
+
+
+### Prepare Your Dataset
+
+The YOLOv5 repository supports a number of different datasets by using yaml files containing their information. By default datasets are downloaded to the `../datasets` folder in relation to the repository root folder. So if you downloaded the `coco128` dataset using the link in the yaml or with the scripts provided by yolov5, you get this folder structure:
+
+```
+..
+|_ yolov5
+|_ datasets
+ |_ coco128
+ |_ images
+ |_ labels
+ |_ LICENSE
+ |_ README.txt
+```
+But this can be any dataset you wish. Feel free to use your own, as long as you keep to this folder structure.
+
+Next, ⚠️**copy the corresponding yaml file to the root of the dataset folder**⚠️. This yaml files contains the information ClearML will need to properly use the dataset. You can make this yourself too, of course, just follow the structure of the example yamls.
+
+Basically we need the following keys: `path`, `train`, `test`, `val`, `nc`, `names`.
+
+```
+..
+|_ yolov5
+|_ datasets
+ |_ coco128
+ |_ images
+ |_ labels
+ |_ coco128.yaml # <---- HERE!
+ |_ LICENSE
+ |_ README.txt
+```
+
+### Upload Your Dataset
+
+To get this dataset into ClearML as a versionned dataset, go to the dataset root folder and run the following command:
+```bash
+cd coco128
+clearml-data sync --project YOLOv5 --name coco128 --folder .
+```
+
+The command `clearml-data sync` is actually a shorthand command. You could also run these commands one after the other:
+```bash
+# Optionally add --parent if you want to base
+# this version on another dataset version, so no duplicate files are uploaded!
+clearml-data create --name coco128 --project YOLOv5
+clearml-data add --files .
+clearml-data close
+```
+
+### Run Training Using A ClearML Dataset
+
+Now that you have a ClearML dataset, you can very simply use it to train custom YOLOv5 🚀 models!
+
+```bash
+python train.py --img 640 --batch 16 --epochs 3 --data clearml:// --weights yolov5s.pt --cache
+```
+
+
+
+## 👀 Hyperparameter Optimization
+
+Now that we have our experiments and data versioned, it's time to take a look at what we can build on top!
+
+Using the code information, installed packages and environment details, the experiment itself is now **completely reproducible**. In fact, ClearML allows you to clone an experiment and even change its parameters. We can then just rerun it with these new parameters automatically, this is basically what HPO does!
+
+To **run hyperparameter optimization locally**, we've included a pre-made script for you. Just make sure a training task has been run at least once, so it is in the ClearML experiment manager, we will essentially clone it and change its hyperparameters.
+
+You'll need to fill in the ID of this `template task` in the script found at `utils/loggers/clearml/hpo.py` and then just run it :) You can change `task.execute_locally()` to `task.execute()` to put it in a ClearML queue and have a remote agent work on it instead.
+
+```bash
+# To use optuna, install it first, otherwise you can change the optimizer to just be RandomSearch
+pip install optuna
+python utils/loggers/clearml/hpo.py
+```
+
+
+
+## 🤯 Remote Execution (advanced)
+
+Running HPO locally is really handy, but what if we want to run our experiments on a remote machine instead? Maybe you have access to a very powerful GPU machine on-site or you have some budget to use cloud GPUs.
+This is where the ClearML Agent comes into play. Check out what the agent can do here:
+
+- [YouTube video](https://youtu.be/MX3BrXnaULs)
+- [Documentation](https://clear.ml/docs/latest/docs/clearml_agent)
+
+In short: every experiment tracked by the experiment manager contains enough information to reproduce it on a different machine (installed packages, uncommitted changes etc.). So a ClearML agent does just that: it listens to a queue for incoming tasks and when it finds one, it recreates the environment and runs it while still reporting scalars, plots etc. to the experiment manager.
+
+You can turn any machine (a cloud VM, a local GPU machine, your own laptop ... ) into a ClearML agent by simply running:
+```bash
+clearml-agent daemon --queue [--docker]
+```
+
+### Cloning, Editing And Enqueuing
+
+With our agent running, we can give it some work. Remember from the HPO section that we can clone a task and edit the hyperparameters? We can do that from the interface too!
+
+🪄 Clone the experiment by right clicking it
+
+🎯 Edit the hyperparameters to what you wish them to be
+
+⏳ Enqueue the task to any of the queues by right clicking it
+
+
+
+### Executing A Task Remotely
+
+Now you can clone a task like we explained above, or simply mark your current script by adding `task.execute_remotely()` and on execution it will be put into a queue, for the agent to start working on!
+
+To run the YOLOv5 training script remotely, all you have to do is add this line to the training.py script after the clearml logger has been instatiated:
+```python
+# ...
+# Loggers
+data_dict = None
+if RANK in {-1, 0}:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.clearml:
+ loggers.clearml.task.execute_remotely(queue='my_queue') # <------ ADD THIS LINE
+ # Data_dict is either None is user did not choose for ClearML dataset or is filled in by ClearML
+ data_dict = loggers.clearml.data_dict
+# ...
+```
+When running the training script after this change, python will run the script up until that line, after which it will package the code and send it to the queue instead!
+
+### Autoscaling workers
+
+ClearML comes with autoscalers too! This tool will automatically spin up new remote machines in the cloud of your choice (AWS, GCP, Azure) and turn them into ClearML agents for you whenever there are experiments detected in the queue. Once the tasks are processed, the autoscaler will automatically shut down the remote machines and you stop paying!
+
+Check out the autoscalers getting started video below.
+
+[](https://youtu.be/j4XVMAaUt3E)
diff --git a/utils/loggers/clearml/__init__.py b/utils/loggers/clearml/__init__.py
new file mode 100755
index 0000000..e69de29
diff --git a/utils/loggers/clearml/clearml_utils.py b/utils/loggers/clearml/clearml_utils.py
new file mode 100755
index 0000000..7923fa1
--- /dev/null
+++ b/utils/loggers/clearml/clearml_utils.py
@@ -0,0 +1,154 @@
+"""Main Logger class for ClearML experiment tracking."""
+import glob
+import re
+from pathlib import Path
+
+import yaml
+from torchvision.transforms import ToPILImage
+
+try:
+ import clearml
+ from clearml import Dataset, Task
+ from torchvision.utils import draw_bounding_boxes # WARNING: requires torchvision>=0.9.0
+
+ assert hasattr(clearml, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ clearml = None
+
+
+def construct_dataset(clearml_info_string):
+ dataset_id = clearml_info_string.replace('clearml://', '')
+ dataset = Dataset.get(dataset_id=dataset_id)
+ dataset_root_path = Path(dataset.get_local_copy())
+
+ # We'll search for the yaml file definition in the dataset
+ yaml_filenames = list(glob.glob(str(dataset_root_path / "*.yaml")) + glob.glob(str(dataset_root_path / "*.yml")))
+ if len(yaml_filenames) > 1:
+ raise ValueError('More than one yaml file was found in the dataset root, cannot determine which one contains '
+ 'the dataset definition this way.')
+ elif len(yaml_filenames) == 0:
+ raise ValueError('No yaml definition found in dataset root path, check that there is a correct yaml file '
+ 'inside the dataset root path.')
+ with open(yaml_filenames[0]) as f:
+ dataset_definition = yaml.safe_load(f)
+
+ assert set(dataset_definition.keys()).issuperset(
+ {'train', 'test', 'val', 'nc', 'names'}
+ ), "The right keys were not found in the yaml file, make sure it at least has the following keys: ('train', 'test', 'val', 'nc', 'names')"
+
+ data_dict = dict()
+ data_dict['train'] = str(
+ (dataset_root_path / dataset_definition['train']).resolve()) if dataset_definition['train'] else None
+ data_dict['test'] = str(
+ (dataset_root_path / dataset_definition['test']).resolve()) if dataset_definition['test'] else None
+ data_dict['val'] = str(
+ (dataset_root_path / dataset_definition['val']).resolve()) if dataset_definition['val'] else None
+ data_dict['nc'] = dataset_definition['nc']
+ data_dict['names'] = dataset_definition['names']
+
+ return data_dict
+
+
+class ClearmlLogger:
+ """Log training runs, datasets, models, and predictions to ClearML.
+
+ This logger sends information to ClearML at app.clear.ml or to your own hosted server. By default,
+ this information includes hyperparameters, system configuration and metrics, model metrics, code information and
+ basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+ """
+
+ def __init__(self, opt, hyp):
+ """
+ - Initialize ClearML Task, this object will capture the experiment
+ - Upload dataset version to ClearML Data if opt.upload_dataset is True
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ hyp (dict) -- Hyperparameters for this run
+
+ """
+ self.current_epoch = 0
+ # Keep tracked of amount of logged images to enforce a limit
+ self.current_epoch_logged_images = set()
+ # Maximum number of images to log to clearML per epoch
+ self.max_imgs_to_log_per_epoch = 16
+ # Get the interval of epochs when bounding box images should be logged
+ self.bbox_interval = opt.bbox_interval
+ self.clearml = clearml
+ self.task = None
+ self.data_dict = None
+ if self.clearml:
+ if opt.clearml_project is None or opt.clearml_task is None:
+ raise ValueError("ClearML project and task should be specified for correct logging."
+ "You should provide --clearml_project and --clearml_task arguments.")
+
+ self.task = Task.init(
+ project_name=opt.clearml_project,
+ task_name=opt.clearml_task,
+ tags=['YOLOv5'],
+ output_uri=True,
+ auto_connect_frameworks={'pytorch': False}
+ # We disconnect pytorch auto-detection, because we added manual model save points in the code
+ )
+ # ClearML's hooks will already grab all general parameters
+ # Only the hyperparameters coming from the yaml config file
+ # will have to be added manually!
+ self.task.connect(hyp, name='Hyperparameters')
+
+ # Get ClearML Dataset Version if requested
+ if opt.data.startswith('clearml://'):
+ # data_dict should have the following keys:
+ # names, nc (number of classes), test, train, val (all three relative paths to ../datasets)
+ self.data_dict = construct_dataset(opt.data)
+ # Set data to data_dict because wandb will crash without this information and opt is the best way
+ # to give it to them
+ opt.data = self.data_dict
+
+ def log_debug_samples(self, files, title='Debug Samples'):
+ """
+ Log files (images) as debug samples in the ClearML task.
+
+ arguments:
+ files (List(PosixPath)) a list of file paths in PosixPath format
+ title (str) A title that groups together images with the same values
+ """
+ for f in files:
+ if f.exists():
+ it = re.search(r'_batch(\d+)', f.name)
+ iteration = int(it.groups()[0]) if it else 0
+ self.task.get_logger().report_image(title=title,
+ series=f.name.replace(it.group(), ''),
+ local_path=str(f),
+ iteration=iteration)
+
+ def log_image_with_boxes(self, image_path, boxes, class_names, image):
+ """
+ Draw the bounding boxes on a single image and report the result as a ClearML debug sample
+
+ arguments:
+ image_path (PosixPath) the path the original image file
+ boxes (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ class_names (dict): dict containing mapping of class int to class name
+ image (Tensor): A torch tensor containing the actual image data
+ """
+ if len(self.current_epoch_logged_images) < self.max_imgs_to_log_per_epoch and self.current_epoch >= 0:
+ # Log every bbox_interval times and deduplicate for any intermittend extra eval runs
+ if self.current_epoch % self.bbox_interval == 0 and image_path not in self.current_epoch_logged_images:
+ converter = ToPILImage()
+ labels = []
+ for conf, class_nr in zip(boxes[:, 4], boxes[:, 5]):
+ class_name = class_names[int(class_nr)]
+ confidence = round(float(conf) * 100, 2)
+ labels.append(f"{class_name}: {confidence}%")
+ annotated_image = converter(
+ draw_bounding_boxes(image=image.mul(255).clamp(0, 255).byte().cpu(),
+ boxes=boxes[:, :4],
+ labels=labels))
+ self.task.get_logger().report_image(title='Bounding Boxes',
+ series=image_path.name,
+ iteration=self.current_epoch,
+ image=annotated_image)
+ self.current_epoch_logged_images.add(image_path)
diff --git a/utils/loggers/clearml/hpo.py b/utils/loggers/clearml/hpo.py
new file mode 100755
index 0000000..96c2c54
--- /dev/null
+++ b/utils/loggers/clearml/hpo.py
@@ -0,0 +1,84 @@
+from clearml import Task
+# Connecting ClearML with the current process,
+# from here on everything is logged automatically
+from clearml.automation import HyperParameterOptimizer, UniformParameterRange
+from clearml.automation.optuna import OptimizerOptuna
+
+task = Task.init(project_name='Hyper-Parameter Optimization',
+ task_name='YOLOv5',
+ task_type=Task.TaskTypes.optimizer,
+ reuse_last_task_id=False)
+
+# Example use case:
+optimizer = HyperParameterOptimizer(
+ # This is the experiment we want to optimize
+ base_task_id='',
+ # here we define the hyper-parameters to optimize
+ # Notice: The parameter name should exactly match what you see in the UI: /
+ # For Example, here we see in the base experiment a section Named: "General"
+ # under it a parameter named "batch_size", this becomes "General/batch_size"
+ # If you have `argparse` for example, then arguments will appear under the "Args" section,
+ # and you should instead pass "Args/batch_size"
+ hyper_parameters=[
+ UniformParameterRange('Hyperparameters/lr0', min_value=1e-5, max_value=1e-1),
+ UniformParameterRange('Hyperparameters/lrf', min_value=0.01, max_value=1.0),
+ UniformParameterRange('Hyperparameters/momentum', min_value=0.6, max_value=0.98),
+ UniformParameterRange('Hyperparameters/weight_decay', min_value=0.0, max_value=0.001),
+ UniformParameterRange('Hyperparameters/warmup_epochs', min_value=0.0, max_value=5.0),
+ UniformParameterRange('Hyperparameters/warmup_momentum', min_value=0.0, max_value=0.95),
+ UniformParameterRange('Hyperparameters/warmup_bias_lr', min_value=0.0, max_value=0.2),
+ UniformParameterRange('Hyperparameters/box', min_value=0.02, max_value=0.2),
+ UniformParameterRange('Hyperparameters/cls', min_value=0.2, max_value=4.0),
+ UniformParameterRange('Hyperparameters/cls_pw', min_value=0.5, max_value=2.0),
+ UniformParameterRange('Hyperparameters/obj', min_value=0.2, max_value=4.0),
+ UniformParameterRange('Hyperparameters/obj_pw', min_value=0.5, max_value=2.0),
+ UniformParameterRange('Hyperparameters/iou_t', min_value=0.1, max_value=0.7),
+ UniformParameterRange('Hyperparameters/anchor_t', min_value=2.0, max_value=8.0),
+ UniformParameterRange('Hyperparameters/fl_gamma', min_value=0.0, max_value=4.0),
+ UniformParameterRange('Hyperparameters/hsv_h', min_value=0.0, max_value=0.1),
+ UniformParameterRange('Hyperparameters/hsv_s', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/hsv_v', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/degrees', min_value=0.0, max_value=45.0),
+ UniformParameterRange('Hyperparameters/translate', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/scale', min_value=0.0, max_value=0.9),
+ UniformParameterRange('Hyperparameters/shear', min_value=0.0, max_value=10.0),
+ UniformParameterRange('Hyperparameters/perspective', min_value=0.0, max_value=0.001),
+ UniformParameterRange('Hyperparameters/flipud', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/fliplr', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/mosaic', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/mixup', min_value=0.0, max_value=1.0),
+ UniformParameterRange('Hyperparameters/copy_paste', min_value=0.0, max_value=1.0)],
+ # this is the objective metric we want to maximize/minimize
+ objective_metric_title='metrics',
+ objective_metric_series='mAP_0.5',
+ # now we decide if we want to maximize it or minimize it (accuracy we maximize)
+ objective_metric_sign='max',
+ # let us limit the number of concurrent experiments,
+ # this in turn will make sure we do dont bombard the scheduler with experiments.
+ # if we have an auto-scaler connected, this, by proxy, will limit the number of machine
+ max_number_of_concurrent_tasks=1,
+ # this is the optimizer class (actually doing the optimization)
+ # Currently, we can choose from GridSearch, RandomSearch or OptimizerBOHB (Bayesian optimization Hyper-Band)
+ optimizer_class=OptimizerOptuna,
+ # If specified only the top K performing Tasks will be kept, the others will be automatically archived
+ save_top_k_tasks_only=5, # 5,
+ compute_time_limit=None,
+ total_max_jobs=20,
+ min_iteration_per_job=None,
+ max_iteration_per_job=None,
+)
+
+# report every 10 seconds, this is way too often, but we are testing here
+optimizer.set_report_period(10)
+# You can also use the line below instead to run all the optimizer tasks locally, without using queues or agent
+# an_optimizer.start_locally(job_complete_callback=job_complete_callback)
+# set the time limit for the optimization process (2 hours)
+optimizer.set_time_limit(in_minutes=120.0)
+# Start the optimization process in the local environment
+optimizer.start_locally()
+# wait until process is done (notice we are controlling the optimization process in the background)
+optimizer.wait()
+# make sure background optimization stopped
+optimizer.stop()
+
+print('We are done, good bye')
diff --git a/utils/loggers/wandb/README.md b/utils/loggers/wandb/README.md
new file mode 100755
index 0000000..d78324b
--- /dev/null
+++ b/utils/loggers/wandb/README.md
@@ -0,0 +1,162 @@
+📚 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 🚀. UPDATED 29 September 2021.
+
+- [About Weights & Biases](#about-weights-&-biases)
+- [First-Time Setup](#first-time-setup)
+- [Viewing runs](#viewing-runs)
+- [Disabling wandb](#disabling-wandb)
+- [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
+- [Reports: Share your work with the world!](#reports)
+
+## About Weights & Biases
+
+Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models — architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
+
+Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
+
+- [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
+- [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
+- [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
+- [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
+- [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
+- [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
+
+## First-Time Setup
+
+
+ Toggle Details
+When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device.
+
+W&B will create a cloud **project** (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run **name** within that project as project/name. You can also manually set your project and run name as:
+
+```shell
+$ python train.py --project ... --name ...
+```
+
+YOLOv5 notebook example: 
 +
+ +
+
+
+
+
+## Viewing Runs
+
+
+ Toggle Details
+Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in realtime . All important information is logged:
+
+- Training & Validation losses
+- Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95
+- Learning Rate over time
+- A bounding box debugging panel, showing the training progress over time
+- GPU: Type, **GPU Utilization**, power, temperature, **CUDA memory usage**
+- System: Disk I/0, CPU utilization, RAM memory usage
+- Your trained model as W&B Artifact
+- Environment: OS and Python types, Git repository and state, **training command**
+
+
+
+
+## Disabling wandb
+
+- training after running `wandb disabled` inside that directory creates no wandb run
+ 
+
+- To enable wandb again, run `wandb online`
+ 
+
+## Advanced Usage
+
+You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
+
+
+ 1: Train and Log Evaluation simultaneousy
+ This is an extension of the previous section, but it'll also training after uploading the dataset. This also evaluation Table
+ Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
+ so no images will be uploaded from your system more than once.
+
+ Usage
+ Code $ python train.py --upload_data val
+
+
+
+
+
+2. Visualize and Version Datasets
+ Log, visualize, dynamically query, and understand your data with W&B Tables. You can use the following command to log your dataset as a W&B Table. This will generate a {dataset}_wandb.yaml file which can be used to train from dataset artifact.
+
+ Usage
+ Code $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data ..
+
+
+
+
+
+ 3: Train using dataset artifact
+ When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that
+ can be used to train a model directly from the dataset artifact. This also logs evaluation
+
+ Usage
+ Code $ python train.py --data {data}_wandb.yaml
+
+
+
+
+
+ 4: Save model checkpoints as artifacts
+ To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval.
+ You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be logged
+
+
+ Usage
+ Code $ python train.py --save_period 1
+
+
+
+
+
+
+
+ 5: Resume runs from checkpoint artifacts.
+Any run can be resumed using artifacts if the --resume argument starts with wandb-artifact:// prefix followed by the run path, i.e, wandb-artifact://username/project/runid . This doesn't require the model checkpoint to be present on the local system.
+
+
+ Usage
+ Code $ python train.py --resume wandb-artifact://{run_path}
+
+
+
+
+
+ 6: Resume runs from dataset artifact & checkpoint artifacts.
+ Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device
+ The syntax is same as the previous section, but you'll need to lof both the dataset and model checkpoints as artifacts, i.e, set bot --upload_dataset or
+ train from _wandb.yaml file and set --save_period
+
+
+ Usage
+ Code $ python train.py --resume wandb-artifact://{run_path}
+
+
+
+
+
+
+
+ Reports
+W&B Reports can be created from your saved runs for sharing online. Once a report is created you will receive a link you can use to publically share your results. Here is an example report created from the COCO128 tutorial trainings of all four YOLOv5 models ([link](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY)).
+
+ +
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  +
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/utils/loggers/wandb/__init__.py b/utils/loggers/wandb/__init__.py
new file mode 100755
index 0000000..e69de29
diff --git a/utils/loggers/wandb/log_dataset.py b/utils/loggers/wandb/log_dataset.py
new file mode 100755
index 0000000..06e81fb
--- /dev/null
+++ b/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/utils/loggers/wandb/sweep.py b/utils/loggers/wandb/sweep.py
new file mode 100755
index 0000000..d49ea6f
--- /dev/null
+++ b/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent. Copy because train() modifies parameters which confused wandb.
+ hyp_dict = vars(wandb.config).get("_items").copy()
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/utils/loggers/wandb/sweep.yaml b/utils/loggers/wandb/sweep.yaml
new file mode 100755
index 0000000..688b1ea
--- /dev/null
+++ b/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 4.0
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
new file mode 100755
index 0000000..e850d2a
--- /dev/null
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,584 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.dataloaders import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if isinstance(data_file, dict):
+ # In that case another dataset manager has already processed it and we don't have to
+ return data_file
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = isinstance(data_dict['train'],
+ str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX)
+ is_valset_wandb_artifact = isinstance(data_dict['val'],
+ str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX)
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup training processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if isinstance(opt.data, dict):
+ # This means another dataset manager has already processed the dataset info (e.g. ClearML)
+ # and they will have stored the already processed dict in opt.data
+ self.data_dict = opt.data
+ elif opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict}, allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.wandb_run.config.update({"upload_dataset": True})
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data, opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs,\
+ config.hyp, config.imgsz
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(
+ data_dict.get('train'), opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(
+ data_dict.get('val'), opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ if opt.evolve or opt.noplots:
+ self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ # epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model',
+ type='model',
+ metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score})
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(data['train'], rect=True, batch_size=1),
+ names,
+ name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
+ self.val_artifact = self.create_dataset_table(
+ LoadImagesAndLabels(data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = ROOT / 'data' / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.im_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file), name='data/labels/' +
+ label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "middle": [xywh[0], xywh[1]],
+ "width": xywh[2],
+ "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": cls,
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"})
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch, id, self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ *avg_conf_per_class)
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[int(cls)]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}"
+ )
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact,
+ aliases=[
+ 'latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/utils/loss.py b/utils/loss.py
new file mode 100755
index 0000000..9b9c3d9
--- /dev/null
+++ b/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/utils/metrics.py b/utils/metrics.py
new file mode 100755
index 0000000..08880cd
--- /dev/null
+++ b/utils/metrics.py
@@ -0,0 +1,364 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for i, gc in enumerate(gt_classes):
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # background FP
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # background FN
+
+ def matrix(self):
+ return self.matrix
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ def plot(self, normalize=True, save_dir='', names=()):
+ try:
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig = plt.figure(figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ annot=nc < 30,
+ annot_kws={
+ "size": 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=names + ['background FP'] if labels else "auto",
+ yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
+ fig.axes[0].set_xlabel('True')
+ fig.axes[0].set_ylabel('Predicted')
+ plt.title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close()
+ except Exception as e:
+ print(f'WARNING: ConfusionMatrix plot failure: {e}')
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, 1), box2.chunk(4, 1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, 1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, 1)
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / (h2 + eps)) - torch.atan(w1 / (h1 + eps)), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_area(box):
+ # box = xyxy(4,n)
+ return (box[2] - box[0]) * (box[3] - box[1])
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1[:, None].chunk(2, 2), box2.chunk(2, 1)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / (box_area(box1.T)[:, None] + box_area(box2.T) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ plt.title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close()
+
+
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ plt.title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close()
diff --git a/utils/plots.py b/utils/plots.py
new file mode 100755
index 0000000..7763e0b
--- /dev/null
+++ b/utils/plots.py
@@ -0,0 +1,516 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils.general import (CONFIG_DIR, FONT, LOGGER, Timeout, check_font, check_requirements, clip_coords,
+ increment_path, is_ascii, threaded, try_except, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255)):
+ # Add text to image (PIL-only)
+ w, h = self.font.getsize(text) # text width, height
+ self.draw.text((xy[0], xy[1] - h + 1), text, fill=txt_color, font=self.font)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.title('Features')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
+ targets = []
+ for i, o in enumerate(output):
+ for *box, conf, cls in o.cpu().numpy():
+ targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
+ return np.array(targets)
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=1920, max_subplots=16):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None):
+ save_dir = Path(file).parent if file else Path(dir)
+
+ fig_metrics, ax_metrics = plt.subplots(2, 2, figsize=(10, 5), tight_layout=True)
+ ax_metrics = ax_metrics.ravel()
+ fig_time, ax_time = plt.subplots(1, 3, figsize=(10, 2.5), tight_layout=True)
+ ax_time = ax_time.ravel()
+
+ fig, ax = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+
+ if file != '':
+ files_to_plot = [Path(file)]
+ else:
+ files_to_plot = save_dir.glob('study*.txt')
+
+ for f in sorted(files_to_plot):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ y_title = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)',
+ 't_inference (ms/img)', 't_NMS (ms/img)']
+ title = [y_t + ' vs image size' for y_t in y_title]
+
+ for i in range(4):
+ ax_metrics[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax_metrics[i].set_title(title[i])
+ ax_metrics[i].grid(alpha=0.2)
+ for i in range(3):
+ ax_time[i].plot(x, y[i + 4], '.-', linewidth=2, markersize=8)
+ ax_time[i].set_title(title[i + 4])
+ ax_time[i].grid(alpha=0.2)
+
+ # y[3] is the 3rd column of the resulting txt data ('mAP@.5:.95')
+ # y[5] is the 5th column ('t_inference (ms/img)')
+ map_95, t_infer = y[3], y[5]
+ # we want to plot up to the resolution with the best mAP@0.5:0.95
+ # and also one point to the right
+ max_res_ind = map_95.argmax() + 2
+
+ ax.plot(t_infer[1:max_res_ind],
+ map_95[1:max_res_ind] * 1E2,
+ linestyle='-',
+ marker='.',
+ linewidth=2,
+ markersize=8,
+ label=f.stem)
+ for i in range(len(map_95)):
+ if i < 1 or i > max_res_ind:
+ continue
+ ax.annotate(x[i], (t_infer[i], map_95[i] * 1E2))
+
+ ax.grid(alpha=0.2)
+ ax.set_xlabel('GPU Speed (ms/img)')
+ ax.set_ylabel('mAP@.5:.95 val')
+ ax.legend(loc='lower right')
+
+ print(f'Saving figures into {save_dir.resolve()}...')
+ fig_metrics.savefig(save_dir / 'Metrics.png')
+ fig_time.savefig(save_dir / 'Time.png')
+ fig.savefig(save_dir / 'mAP_vs_time.png')
+
+
+@try_except # known issue https://github.com/ultralytics/yolov5/issues/5395
+@Timeout(30) # known issue https://github.com/ultralytics/yolov5/issues/5611
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ try: # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ except Exception:
+ pass
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(names, rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+
+ # find best factorization of keys_len
+ keys_len = len(keys[7:])
+ plot_rows_cols = math.ceil(math.sqrt(keys_len))
+ plot_rows = plot_rows_cols
+ while keys_len % plot_rows_cols != 0:
+ plot_rows_cols -= 1
+ plot_rows = min(plot_rows_cols, keys_len // plot_rows_cols) if plot_rows_cols > 1 else plot_rows
+ plot_cols = math.ceil(keys_len / plot_rows)
+
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(plot_rows, plot_cols, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_coords(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/utils/pruning.py b/utils/pruning.py
new file mode 100755
index 0000000..bc1365b
--- /dev/null
+++ b/utils/pruning.py
@@ -0,0 +1,114 @@
+""" Functions that are used in prune.py """
+import tempfile
+from copy import deepcopy
+from pathlib import Path
+
+import numpy as np
+import torch
+from enot_lite.benchmark import Benchmark
+from enot_lite.type import BackendType
+from fvcore.nn.flop_count import FlopCountAnalysis
+
+from models.common import DetectMultiBackend
+from utils.torch_utils import time_sync
+
+
+def sample_to_n_samples(sample):
+ """Function which computes the number of instances (objects to process)
+ in single dataloader batch (dataloader sample)."""
+ return sample[0].shape[0]
+
+
+def sample_to_model_inputs(sample, device):
+ """Function to map dataloader samples to model input format."""
+ images = sample[0].to(device)
+ images = images.float()
+ images /= 255
+ return (images,), {}
+
+
+def count_mmac(model, dataloader, device):
+ """Computes FLOPs (in MMACs)."""
+ inputs, _ = sample_to_model_inputs(next(iter(dataloader)), device)
+ flop_counter = FlopCountAnalysis(model=model.eval(), inputs=inputs)
+ flop_counter.unsupported_ops_warnings(False)
+ flop_counter.uncalled_modules_warnings(False)
+ mflops = flop_counter.total() / 1e+6
+ return mflops
+
+
+def loss_function(model_output, sample, loss_fn, device):
+ """Compute loss between model output and dataset sample."""
+ labels = sample[1].to(device)
+ loss, _ = loss_fn(model_output, labels)
+ return loss
+
+
+def measure_inference_time_torch(model, bs, size, device, warmup=50, repeat=50, number=50):
+ """Compute inference time for the model"""
+ inputs = torch.ones(bs, 3, size, size).to(device)
+
+ # we want to measure time exactly as in val.py where we load model via
+ # DetectMultiBackend and fuse weights
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # save model
+ ckpt_name = Path(tmpdir) / 'temp.pt'
+ ckpt = {'model': deepcopy(model).half()}
+ torch.save(ckpt, ckpt_name)
+ # load
+ model_dmb = DetectMultiBackend(ckpt_name, device=device, dnn=False, fp16=False)
+
+ model_dmb.eval()
+
+ times = []
+
+ for _ in range(warmup): # Warmup.
+ with torch.no_grad():
+ model_dmb(inputs)
+
+ for i in range(repeat):
+ for _ in range(number):
+ with torch.no_grad():
+ start = time_sync()
+ model_dmb(inputs)
+ end = time_sync()
+
+ times.append(end - start)
+
+ return np.mean(times) * 10 ** 3 / bs
+
+
+def measure_inference_time_ort_cpu_single_thread(model, image_size, model_device, warmup=50, repeat=50, number=50):
+ """Compute inference time using enot_lite ORT_CPU in single thread"""
+ input_shape = (1, 3, image_size, image_size)
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # save model
+ onnx_name = Path(tmpdir) / 'temp.onnx'
+ torch.onnx.export(
+ model=model,
+ args=torch.zeros(input_shape, device=model_device),
+ f=str(onnx_name),
+ export_params=True,
+ do_constant_folding=True,
+ input_names=['input'],
+ output_names=['output'],
+ )
+
+ # load
+ benchmark = Benchmark(
+ batch_size=1,
+ onnx_model=onnx_name,
+ onnx_input=np.ones(input_shape, dtype=np.float32),
+ backends=[BackendType.ORT_CPU],
+ warmup=warmup,
+ repeat=repeat,
+ number=number,
+ no_data_transfer=True,
+ inter_op_num_threads=1,
+ intra_op_num_threads=1,
+ )
+
+ benchmark.run()
+ results = benchmark.results
+ return results['ORT_CPU'][1]
diff --git a/utils/torch_utils.py b/utils/torch_utils.py
new file mode 100755
index 0000000..7d316ab
--- /dev/null
+++ b/utils/torch_utils.py
@@ -0,0 +1,407 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return torch.no_grad()(fn) # ENOT pruning don't work with torch.inference_mode, so use no_grad
+
+ return decorate
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not (cpu or mps) and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ # YOLOv5 speed/memory/FLOPs profiler
+ #
+ # Usage:
+ # input = torch.randn(16, 3, 640, 640)
+ # m1 = lambda x: x * torch.sigmoid(x)
+ # m2 = nn.SiLU()
+ # profile(input, [m1, m2], n=100) # profile over 100 iterations
+
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.zeros((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f"{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
+ g[2].append(v.bias)
+ if isinstance(v, bn): # weight (no decay)
+ g[1].append(v.weight)
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
+ g[0].append(v.weight)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RAdam':
+ optimizer = torch.optim.RAdam(g[2], lr=lr, betas=(momentum, 0.999))
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f"{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias")
+ return optimizer
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ # if next(model.parameters()).device.type != 'cpu':
+ # self.ema.half() # FP16 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ @smart_inference_mode()
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point:
+ v *= d
+ v += (1 - d) * msd[k].detach()
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
+
+
+def fix_model_compatibility_between_version(model: torch.nn.Module) -> torch.nn.Module:
+ for m in model.modules():
+ if isinstance(m, torch.nn.Upsample) and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ return model
+
+
+def save_ckpt(ckpt, dir_to_save, is_best, save_on_epoch, epoch):
+ torch.save(ckpt, dir_to_save / 'last.pt')
+ if is_best:
+ torch.save(ckpt, dir_to_save / 'best.pt')
+ if save_on_epoch:
+ torch.save(ckpt, dir_to_save / f'epoch{epoch}.pt')
diff --git a/val.py b/val.py
new file mode 100755
index 0000000..d1afa7e
--- /dev/null
+++ b/val.py
@@ -0,0 +1,395 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 model accuracy on a custom dataset
+
+Usage:
+ $ python path/to/val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python path/to/val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s.xml # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+"""
+
+import argparse
+import json
+import os
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, check_yaml,
+ coco80_to_coco91_class, colorstr, increment_path, non_max_suppression, print_args,
+ scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode, time_sync
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct predictions matrix. Both sets of boxes are in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (Array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad = 0.0 if task in ('speed', 'benchmark') else 0.5
+ rect = False if task in ('speed', 'study', 'benchmark') else pt # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = dict(enumerate(model.names if hasattr(model, 'names') else model.module.names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%20s' + '%11s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', 'mAP@.5', 'mAP@.5:.95')
+ dt, p, r, f1, mp, mr, map50, map = [0.0, 0.0, 0.0], 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ t1 = time_sync()
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+ t2 = time_sync()
+ dt[0] += t2 - t1
+
+ # Inference
+ out, train_out = model(im) if training else model(im, augment=augment, val=True) # inference, loss outputs
+ dt[1] += time_sync() - t2
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss([x.float() for x in train_out], targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ t3 = time_sync()
+ out = non_max_suppression(out, conf_thres, iou_thres, labels=lb, multi_label=True, agnostic=single_cls)
+ dt[2] += time_sync() - t3
+
+ # Metrics
+ for si, pred in enumerate(out):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_coords(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_coords(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(out), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end')
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%20s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING: no labels found in {task} set, can not compute metrics without labels ⚠️')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end')
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path(data.get('path', '../coco')) / 'annotations/instances_val2017.json') # annotations json
+ pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements(['pycocotools'])
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop', 'fvcore'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING: confidence threshold {opt.conf_thres} > 0.001 produces invalid results ⚠️')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ os.system('zip -r study.zip study_*.txt')
+ plot_val_study(x=x) # plot
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/utils/loggers/wandb/__init__.py b/utils/loggers/wandb/__init__.py
new file mode 100755
index 0000000..e69de29
diff --git a/utils/loggers/wandb/log_dataset.py b/utils/loggers/wandb/log_dataset.py
new file mode 100755
index 0000000..06e81fb
--- /dev/null
+++ b/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/utils/loggers/wandb/sweep.py b/utils/loggers/wandb/sweep.py
new file mode 100755
index 0000000..d49ea6f
--- /dev/null
+++ b/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent. Copy because train() modifies parameters which confused wandb.
+ hyp_dict = vars(wandb.config).get("_items").copy()
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/utils/loggers/wandb/sweep.yaml b/utils/loggers/wandb/sweep.yaml
new file mode 100755
index 0000000..688b1ea
--- /dev/null
+++ b/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 4.0
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
new file mode 100755
index 0000000..e850d2a
--- /dev/null
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,584 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.dataloaders import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if isinstance(data_file, dict):
+ # In that case another dataset manager has already processed it and we don't have to
+ return data_file
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = isinstance(data_dict['train'],
+ str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX)
+ is_valset_wandb_artifact = isinstance(data_dict['val'],
+ str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX)
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup training processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if isinstance(opt.data, dict):
+ # This means another dataset manager has already processed the dataset info (e.g. ClearML)
+ # and they will have stored the already processed dict in opt.data
+ self.data_dict = opt.data
+ elif opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict}, allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.wandb_run.config.update({"upload_dataset": True})
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data, opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs,\
+ config.hyp, config.imgsz
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(
+ data_dict.get('train'), opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(
+ data_dict.get('val'), opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ if opt.evolve or opt.noplots:
+ self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ # epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model',
+ type='model',
+ metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score})
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(data['train'], rect=True, batch_size=1),
+ names,
+ name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
+ self.val_artifact = self.create_dataset_table(
+ LoadImagesAndLabels(data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = ROOT / 'data' / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.im_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file), name='data/labels/' +
+ label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "middle": [xywh[0], xywh[1]],
+ "width": xywh[2],
+ "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": cls,
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"})
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch, id, self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ *avg_conf_per_class)
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[int(cls)]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}"
+ )
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact,
+ aliases=[
+ 'latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/utils/loss.py b/utils/loss.py
new file mode 100755
index 0000000..9b9c3d9
--- /dev/null
+++ b/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/utils/metrics.py b/utils/metrics.py
new file mode 100755
index 0000000..08880cd
--- /dev/null
+++ b/utils/metrics.py
@@ -0,0 +1,364 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for i, gc in enumerate(gt_classes):
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # background FP
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # background FN
+
+ def matrix(self):
+ return self.matrix
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ def plot(self, normalize=True, save_dir='', names=()):
+ try:
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig = plt.figure(figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ annot=nc < 30,
+ annot_kws={
+ "size": 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=names + ['background FP'] if labels else "auto",
+ yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
+ fig.axes[0].set_xlabel('True')
+ fig.axes[0].set_ylabel('Predicted')
+ plt.title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close()
+ except Exception as e:
+ print(f'WARNING: ConfusionMatrix plot failure: {e}')
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, 1), box2.chunk(4, 1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, 1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, 1)
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / (h2 + eps)) - torch.atan(w1 / (h1 + eps)), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_area(box):
+ # box = xyxy(4,n)
+ return (box[2] - box[0]) * (box[3] - box[1])
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1[:, None].chunk(2, 2), box2.chunk(2, 1)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / (box_area(box1.T)[:, None] + box_area(box2.T) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ plt.title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close()
+
+
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ plt.title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close()
diff --git a/utils/plots.py b/utils/plots.py
new file mode 100755
index 0000000..7763e0b
--- /dev/null
+++ b/utils/plots.py
@@ -0,0 +1,516 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils.general import (CONFIG_DIR, FONT, LOGGER, Timeout, check_font, check_requirements, clip_coords,
+ increment_path, is_ascii, threaded, try_except, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255)):
+ # Add text to image (PIL-only)
+ w, h = self.font.getsize(text) # text width, height
+ self.draw.text((xy[0], xy[1] - h + 1), text, fill=txt_color, font=self.font)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.title('Features')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
+ targets = []
+ for i, o in enumerate(output):
+ for *box, conf, cls in o.cpu().numpy():
+ targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
+ return np.array(targets)
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=1920, max_subplots=16):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None):
+ save_dir = Path(file).parent if file else Path(dir)
+
+ fig_metrics, ax_metrics = plt.subplots(2, 2, figsize=(10, 5), tight_layout=True)
+ ax_metrics = ax_metrics.ravel()
+ fig_time, ax_time = plt.subplots(1, 3, figsize=(10, 2.5), tight_layout=True)
+ ax_time = ax_time.ravel()
+
+ fig, ax = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+
+ if file != '':
+ files_to_plot = [Path(file)]
+ else:
+ files_to_plot = save_dir.glob('study*.txt')
+
+ for f in sorted(files_to_plot):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ y_title = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)',
+ 't_inference (ms/img)', 't_NMS (ms/img)']
+ title = [y_t + ' vs image size' for y_t in y_title]
+
+ for i in range(4):
+ ax_metrics[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax_metrics[i].set_title(title[i])
+ ax_metrics[i].grid(alpha=0.2)
+ for i in range(3):
+ ax_time[i].plot(x, y[i + 4], '.-', linewidth=2, markersize=8)
+ ax_time[i].set_title(title[i + 4])
+ ax_time[i].grid(alpha=0.2)
+
+ # y[3] is the 3rd column of the resulting txt data ('mAP@.5:.95')
+ # y[5] is the 5th column ('t_inference (ms/img)')
+ map_95, t_infer = y[3], y[5]
+ # we want to plot up to the resolution with the best mAP@0.5:0.95
+ # and also one point to the right
+ max_res_ind = map_95.argmax() + 2
+
+ ax.plot(t_infer[1:max_res_ind],
+ map_95[1:max_res_ind] * 1E2,
+ linestyle='-',
+ marker='.',
+ linewidth=2,
+ markersize=8,
+ label=f.stem)
+ for i in range(len(map_95)):
+ if i < 1 or i > max_res_ind:
+ continue
+ ax.annotate(x[i], (t_infer[i], map_95[i] * 1E2))
+
+ ax.grid(alpha=0.2)
+ ax.set_xlabel('GPU Speed (ms/img)')
+ ax.set_ylabel('mAP@.5:.95 val')
+ ax.legend(loc='lower right')
+
+ print(f'Saving figures into {save_dir.resolve()}...')
+ fig_metrics.savefig(save_dir / 'Metrics.png')
+ fig_time.savefig(save_dir / 'Time.png')
+ fig.savefig(save_dir / 'mAP_vs_time.png')
+
+
+@try_except # known issue https://github.com/ultralytics/yolov5/issues/5395
+@Timeout(30) # known issue https://github.com/ultralytics/yolov5/issues/5611
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ try: # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ except Exception:
+ pass
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(names, rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+
+ # find best factorization of keys_len
+ keys_len = len(keys[7:])
+ plot_rows_cols = math.ceil(math.sqrt(keys_len))
+ plot_rows = plot_rows_cols
+ while keys_len % plot_rows_cols != 0:
+ plot_rows_cols -= 1
+ plot_rows = min(plot_rows_cols, keys_len // plot_rows_cols) if plot_rows_cols > 1 else plot_rows
+ plot_cols = math.ceil(keys_len / plot_rows)
+
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(plot_rows, plot_cols, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_coords(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/utils/pruning.py b/utils/pruning.py
new file mode 100755
index 0000000..bc1365b
--- /dev/null
+++ b/utils/pruning.py
@@ -0,0 +1,114 @@
+""" Functions that are used in prune.py """
+import tempfile
+from copy import deepcopy
+from pathlib import Path
+
+import numpy as np
+import torch
+from enot_lite.benchmark import Benchmark
+from enot_lite.type import BackendType
+from fvcore.nn.flop_count import FlopCountAnalysis
+
+from models.common import DetectMultiBackend
+from utils.torch_utils import time_sync
+
+
+def sample_to_n_samples(sample):
+ """Function which computes the number of instances (objects to process)
+ in single dataloader batch (dataloader sample)."""
+ return sample[0].shape[0]
+
+
+def sample_to_model_inputs(sample, device):
+ """Function to map dataloader samples to model input format."""
+ images = sample[0].to(device)
+ images = images.float()
+ images /= 255
+ return (images,), {}
+
+
+def count_mmac(model, dataloader, device):
+ """Computes FLOPs (in MMACs)."""
+ inputs, _ = sample_to_model_inputs(next(iter(dataloader)), device)
+ flop_counter = FlopCountAnalysis(model=model.eval(), inputs=inputs)
+ flop_counter.unsupported_ops_warnings(False)
+ flop_counter.uncalled_modules_warnings(False)
+ mflops = flop_counter.total() / 1e+6
+ return mflops
+
+
+def loss_function(model_output, sample, loss_fn, device):
+ """Compute loss between model output and dataset sample."""
+ labels = sample[1].to(device)
+ loss, _ = loss_fn(model_output, labels)
+ return loss
+
+
+def measure_inference_time_torch(model, bs, size, device, warmup=50, repeat=50, number=50):
+ """Compute inference time for the model"""
+ inputs = torch.ones(bs, 3, size, size).to(device)
+
+ # we want to measure time exactly as in val.py where we load model via
+ # DetectMultiBackend and fuse weights
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # save model
+ ckpt_name = Path(tmpdir) / 'temp.pt'
+ ckpt = {'model': deepcopy(model).half()}
+ torch.save(ckpt, ckpt_name)
+ # load
+ model_dmb = DetectMultiBackend(ckpt_name, device=device, dnn=False, fp16=False)
+
+ model_dmb.eval()
+
+ times = []
+
+ for _ in range(warmup): # Warmup.
+ with torch.no_grad():
+ model_dmb(inputs)
+
+ for i in range(repeat):
+ for _ in range(number):
+ with torch.no_grad():
+ start = time_sync()
+ model_dmb(inputs)
+ end = time_sync()
+
+ times.append(end - start)
+
+ return np.mean(times) * 10 ** 3 / bs
+
+
+def measure_inference_time_ort_cpu_single_thread(model, image_size, model_device, warmup=50, repeat=50, number=50):
+ """Compute inference time using enot_lite ORT_CPU in single thread"""
+ input_shape = (1, 3, image_size, image_size)
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # save model
+ onnx_name = Path(tmpdir) / 'temp.onnx'
+ torch.onnx.export(
+ model=model,
+ args=torch.zeros(input_shape, device=model_device),
+ f=str(onnx_name),
+ export_params=True,
+ do_constant_folding=True,
+ input_names=['input'],
+ output_names=['output'],
+ )
+
+ # load
+ benchmark = Benchmark(
+ batch_size=1,
+ onnx_model=onnx_name,
+ onnx_input=np.ones(input_shape, dtype=np.float32),
+ backends=[BackendType.ORT_CPU],
+ warmup=warmup,
+ repeat=repeat,
+ number=number,
+ no_data_transfer=True,
+ inter_op_num_threads=1,
+ intra_op_num_threads=1,
+ )
+
+ benchmark.run()
+ results = benchmark.results
+ return results['ORT_CPU'][1]
diff --git a/utils/torch_utils.py b/utils/torch_utils.py
new file mode 100755
index 0000000..7d316ab
--- /dev/null
+++ b/utils/torch_utils.py
@@ -0,0 +1,407 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return torch.no_grad()(fn) # ENOT pruning don't work with torch.inference_mode, so use no_grad
+
+ return decorate
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not (cpu or mps) and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ # YOLOv5 speed/memory/FLOPs profiler
+ #
+ # Usage:
+ # input = torch.randn(16, 3, 640, 640)
+ # m1 = lambda x: x * torch.sigmoid(x)
+ # m2 = nn.SiLU()
+ # profile(input, [m1, m2], n=100) # profile over 100 iterations
+
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.zeros((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f"{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias (no decay)
+ g[2].append(v.bias)
+ if isinstance(v, bn): # weight (no decay)
+ g[1].append(v.weight)
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
+ g[0].append(v.weight)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RAdam':
+ optimizer = torch.optim.RAdam(g[2], lr=lr, betas=(momentum, 0.999))
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f"{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias")
+ return optimizer
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ # if next(model.parameters()).device.type != 'cpu':
+ # self.ema.half() # FP16 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ @smart_inference_mode()
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point:
+ v *= d
+ v += (1 - d) * msd[k].detach()
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
+
+
+def fix_model_compatibility_between_version(model: torch.nn.Module) -> torch.nn.Module:
+ for m in model.modules():
+ if isinstance(m, torch.nn.Upsample) and not hasattr(m, 'recompute_scale_factor'):
+ m.recompute_scale_factor = None # torch 1.11.0 compatibility
+
+ return model
+
+
+def save_ckpt(ckpt, dir_to_save, is_best, save_on_epoch, epoch):
+ torch.save(ckpt, dir_to_save / 'last.pt')
+ if is_best:
+ torch.save(ckpt, dir_to_save / 'best.pt')
+ if save_on_epoch:
+ torch.save(ckpt, dir_to_save / f'epoch{epoch}.pt')
diff --git a/val.py b/val.py
new file mode 100755
index 0000000..d1afa7e
--- /dev/null
+++ b/val.py
@@ -0,0 +1,395 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 model accuracy on a custom dataset
+
+Usage:
+ $ python path/to/val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python path/to/val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s.xml # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+"""
+
+import argparse
+import json
+import os
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, check_yaml,
+ coco80_to_coco91_class, colorstr, increment_path, non_max_suppression, print_args,
+ scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode, time_sync
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct predictions matrix. Both sets of boxes are in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (Array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad = 0.0 if task in ('speed', 'benchmark') else 0.5
+ rect = False if task in ('speed', 'study', 'benchmark') else pt # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = dict(enumerate(model.names if hasattr(model, 'names') else model.module.names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%20s' + '%11s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', 'mAP@.5', 'mAP@.5:.95')
+ dt, p, r, f1, mp, mr, map50, map = [0.0, 0.0, 0.0], 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ t1 = time_sync()
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+ t2 = time_sync()
+ dt[0] += t2 - t1
+
+ # Inference
+ out, train_out = model(im) if training else model(im, augment=augment, val=True) # inference, loss outputs
+ dt[1] += time_sync() - t2
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss([x.float() for x in train_out], targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ t3 = time_sync()
+ out = non_max_suppression(out, conf_thres, iou_thres, labels=lb, multi_label=True, agnostic=single_cls)
+ dt[2] += time_sync() - t3
+
+ # Metrics
+ for si, pred in enumerate(out):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_coords(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_coords(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(out), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end')
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%20s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING: no labels found in {task} set, can not compute metrics without labels ⚠️')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end')
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path(data.get('path', '../coco')) / 'annotations/instances_val2017.json') # annotations json
+ pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements(['pycocotools'])
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop', 'fvcore'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING: confidence threshold {opt.conf_thres} > 0.001 produces invalid results ⚠️')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ os.system('zip -r study.zip study_*.txt')
+ plot_val_study(x=x) # plot
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
 +
+ +
+  +
+  +
+ +
+
+
+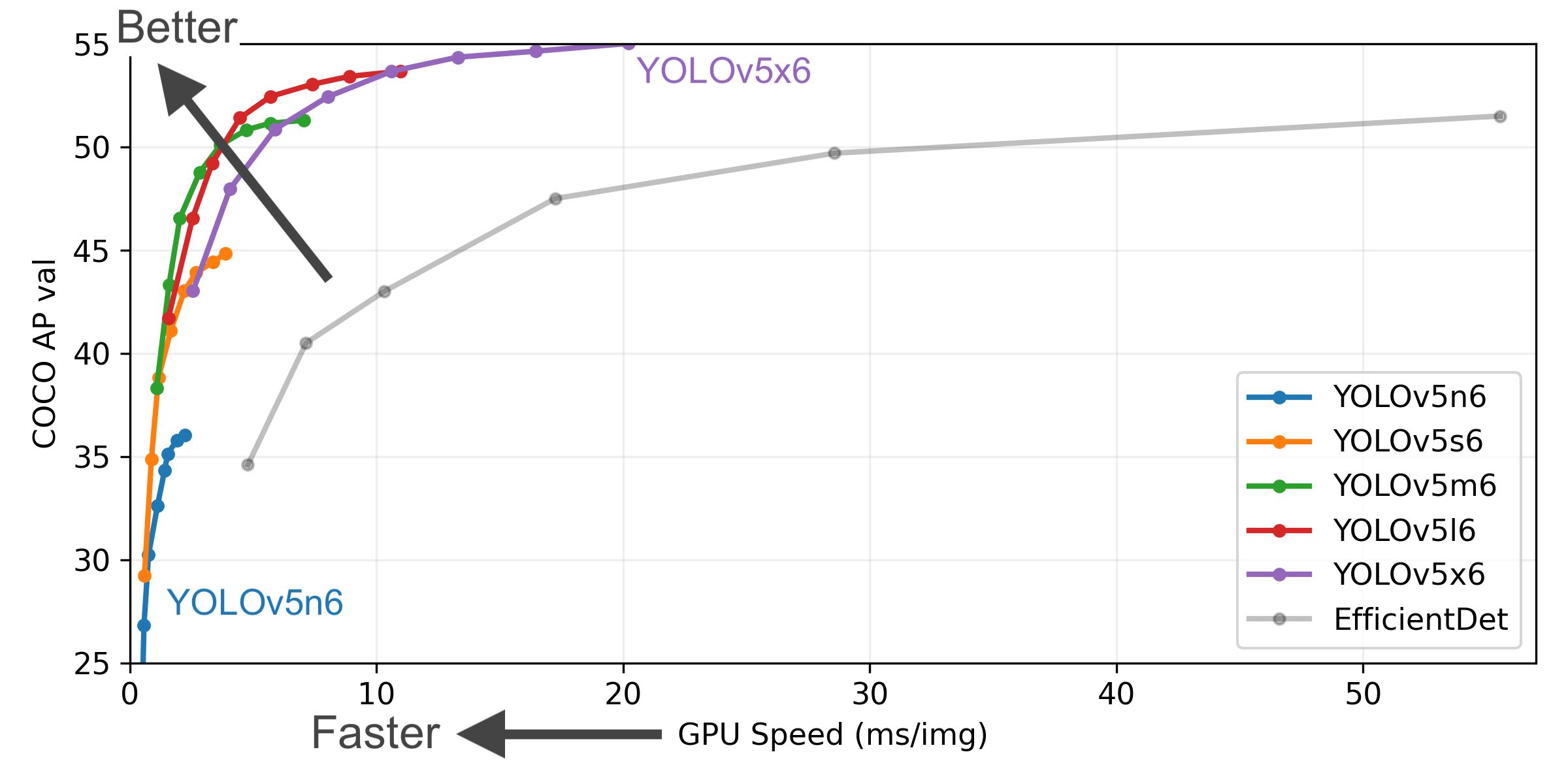
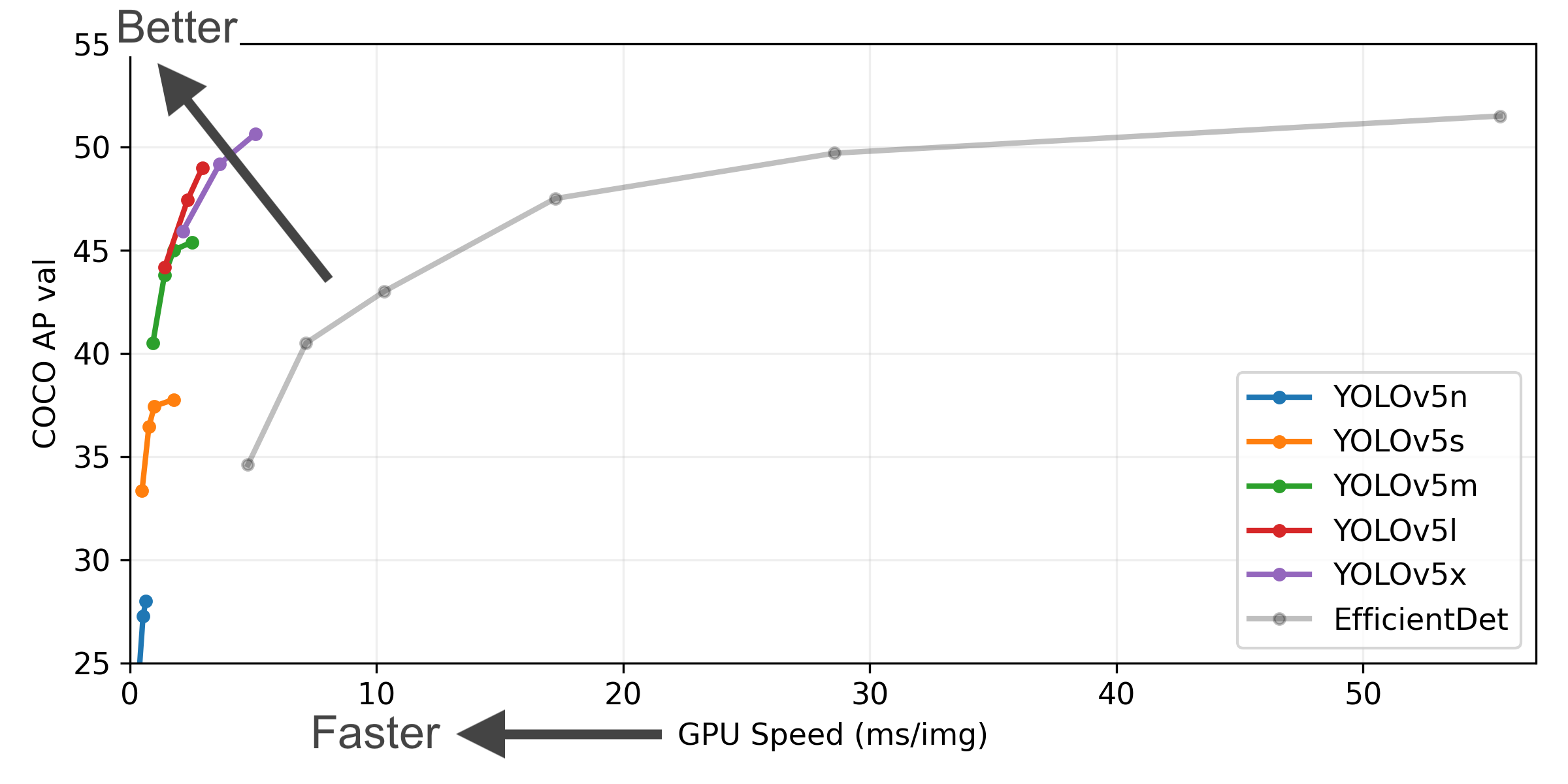
 +
+##
+
+##