
Connector last Release:

This Repository contains sample pipelines and documentation to import and/or export data from DataStax Astra DB leveraging Apache Beam and Dataflow.
Sample Apache Beam pipelines to read and write data from Astra DB and Astra Streaming.
Those flows leverage the AstraDbIO component available at this repo
- 3.1 - Gcs to Astra
- 3.2 - Astra to Gcs
- 3.3 - AstraDb to BigQuery
- 3.4 - BigQuery to AstraDb
- 3.5 - AstraDb to BigQuery Dynamic
- ✅ Install Java Development Kit (JDK) 11+
Use java reference documentation targetting your operating system to install a Java Development Kit. You can then validate your installation with the following command.
java --version- ✅ Install Apache Maven (3.8+)
Samples and tutorials have been designed with Apache Maven. Use the reference documentation top install maven validate your installation with
mvn -version- ✅ Clone this repository
git clone https://github.com/DataStax-Examples/astra-dataflow-starter.git
cd astra-dataflow-starter- ✅ Install the Astra CLI
curl -Ls "https://dtsx.io/get-astra-cli" | bash
source ~/.astra/cli/astra-init.sh✅ As an alternative you can run this in the cloud
↗️ Right Click and select open as a new Tab...

- ✅ Create your DataStax Astra account:
- ✅ Create an Astra Token
An astra token acts as your credentials, it holds the different permissions. The scope of a token is the whole organization (tenant) but permissions can be edited to limit usage to a single database.
To create a token, please follow this guide
The Token is in fact three separate strings: a Client ID, a Client Secret and the token proper. You will need some of these strings to access the database, depending on the type of access you plan. Although the Client ID, strictly speaking, is not a secret, you should regard this whole object as a secret and make sure not to share it inadvertently (e.g. committing it to a Git repository) as it grants access to your databases.
{
"ClientId": "ROkiiDZdvPOvHRSgoZtyAapp",
"ClientSecret": "fakedfaked",
"Token":"AstraCS:fake"
}- ✅ Set up the CLI with your token
astra setup --token AstraCS:fake
- ✅ Create a Database
demoand a keyspacesamples_beam
astra db create demo -k samples_beam --if-not-exists
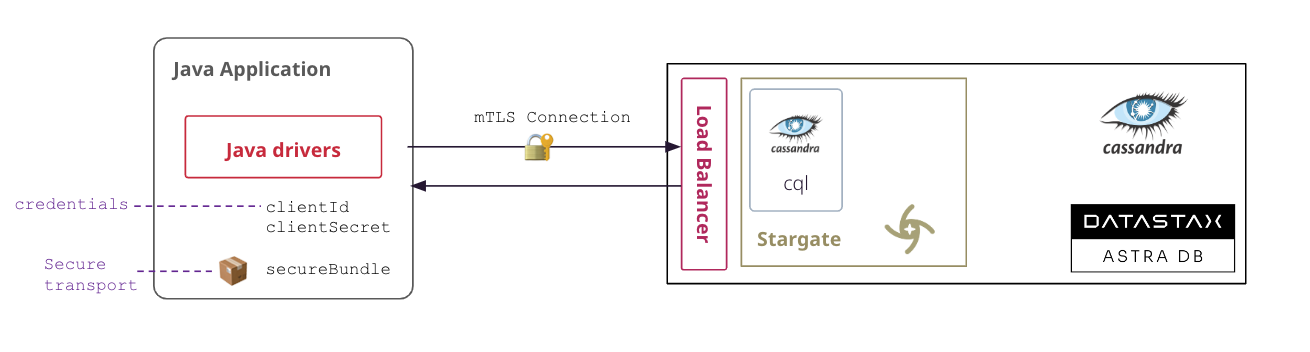
- ✅ Download the Secure Connect Bundle for current database
A Secure Connect Bundle contains the certificates and endpoints informations to open a mTLS connection. Often mentionned as
scbits scope is a database AND a region. If your database is deployed on multiple regions you will have to download the bundle for each one and initiate the connection accordingly. Instructions to download Secure Connect Bundle are here
astra db download-scb demo -f /tmp/secure-connect-bundle-db-demo.zip

cd samples-beam
pwdexport ASTRA_TOKEN=$(astra token)
export ASTRA_SCB_PATH=/tmp/secure-connect-bundle-db-demo.zip
export ASTRA_KEYSPACE=samples_beam mvn clean compile exec:java \
-Dexec.mainClass=com.datastax.astra.beam.Csv_to_AstraDb \
-Dexec.args="\
--astraToken=${ASTRA_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SCB_PATH} \
--keyspace=${ASTRA_KEYSPACE} \
--csvInput=`pwd`/src/test/resources/language-codes.csv"astra db cqlsh demo \
-k samples_beam \
-e "SELECT * FROM languages LIMIT 10;"
cd samples-beam
pwdexport ASTRA_TOKEN=$(astra token)
export ASTRA_SCB_PATH=/tmp/secure-connect-bundle-db-demo.zip
export ASTRA_KEYSPACE=samples_beam mvn clean compile exec:java \
-Dexec.mainClass=com.datastax.astra.beam.AstraDb_To_Csv \
-Dexec.args="\
--astraToken=${ASTRA_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SCB_PATH} \
--keyspace=${ASTRA_KEYSPACE} \
--table=languages \
--csvOutput=`pwd`/src/test/resources/out/language"ls -l `pwd`/src/test/resources/out
cat `pwd`/src/test/resources/out/language-00001-of-00004
cd samples-beam
pwddocker-compose -f ./src/main/docker/docker-compose.yml up -dWait a few seconds for Cassandra to Start.
docker-compose -f ./src/main/docker/docker-compose.yml ps | cut -b 55-61docker exec -it `docker ps | grep cassandra:4.1.1 | cut -b 1-12` cqlsh -e "SELECT data_center FROM system.local;"export ASTRA_TOKEN=$(astra token)
export ASTRA_SCB_PATH=/tmp/secure-connect-bundle-db-demo.zip
export ASTRA_KEYSPACE=samples_beamastra db cqlsh demo \
-k samples_beam \
-e "TRUNCATE languages;" mvn clean compile exec:java \
-Dexec.mainClass=com.datastax.astra.beam.Cassandra_To_AstraDb \
-Dexec.args="\
--astraToken=${ASTRA_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SCB_PATH} \
--keyspace=${ASTRA_KEYSPACE} \
--cassandraHost=localhost \
--cassandraPort=9042 \
--tableName=languages"docker exec -it `docker ps \
| grep cassandra:4.1.1 \
| cut -b 1-12` \
cqlsh -e "SELECT * FROM samples_beam.languages LIMIT 10;"astra db cqlsh demo \
-k samples_beam \
-e "SELECT * FROM languages LIMIT 10;"
Note: If you don't plan to keep the resources that you create in this guide, create a project instead of selecting an existing project. After you finish these steps, you can delete the project, removing all resources associated with the project. Create a new Project in Google Cloud Console or select an existing one.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project
Make sure that billing is enabled for your Cloud project. Learn how to check if billing is enabled on a project
The project identifier is available in the column ID. We will need it so let's save it as an environment variable
export GCP_PROJECT_ID=integrations-379317
export GCP_PROJECT_CODE=747469159044
export [email protected]
export GCP_COMPUTE_ENGINE=747469159044-compute@developer.gserviceaccount.comcurl https://sdk.cloud.google.com | bash
Run the following command to authenticate with Google Cloud:
gcloud auth login
3.1.6 - ✅ Set your project: If you haven't set your project yet, use the following command to set your project ID:
gcloud config set project ${GCP_PROJECT_ID}
gcloud projects describe ${GCP_PROJECT_ID}
gcloud services enable dataflow compute_component \
logging storage_component storage_api \
bigquery pubsub datastore.googleapis.com \
cloudresourcemanager.googleapis.com
3.1.8 - ✅ Add Roles to dataflow users:** To complete the steps, your user account must have the Dataflow Admin role and the Service Account User role. The Compute Engine default service account must have the Dataflow Worker role. To add the required roles in the Google Cloud console:
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="user:${GCP_USER}" \
--role=roles/iam.serviceAccountUser
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role=roles/dataflow.admin
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role=roles/dataflow.worker
gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role=roles/storage.objectAdmin
cd samples-dataflow
pwdgsutil mb -c STANDARD -l US gs://astra_dataflow_inputs
gsutil cp src/test/resources/language-codes.csv gs://astra_dataflow_inputs/csv/
gsutil ls
3.1.11 - ✅ Create secrets for the project in secret manager**. To connect to AstraDB you need a token (credentials) and a zip used to secure the transport. Those two inputs should be defined as secrets.
```
gcloud secrets create astra-token \
--data-file <(echo -n "${ASTRA_TOKEN}") \
--replication-policy="automatic"
gcloud secrets create cedrick-demo-scb \
--data-file ${ASTRA_SCB_PATH} \
--replication-policy="automatic"
gcloud secrets add-iam-policy-binding cedrick-demo-scb \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role='roles/secretmanager.secretAccessor'
gcloud secrets add-iam-policy-binding astra-token \
--member="serviceAccount:${GCP_COMPUTE_ENGINE}" \
--role='roles/secretmanager.secretAccessor'
gcloud secrets list
```
astra db create-keyspace demo -k samples_dataflow --if-not-existexport ASTRA_KEYSPACE=samples_dataflow
export ASTRA_SECRET_TOKEN=projects/747469159044/secrets/astra-token/versions/2
export ASTRA_SECRET_SECURE_BUNDLE=projects/747469159044/secrets/secure-connect-bundle-demo/versions/1
export GCP_INPUT_CSV=gs://astra_dataflow_inputs/csv/language-codes.csv mvn compile exec:java \
-Dexec.mainClass=com.datastax.astra.dataflow.Gcs_To_AstraDb \
-Dexec.args="\
--astraToken=${ASTRA_SECRET_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SECRET_SECURE_BUNDLE} \
--keyspace=${ASTRA_KEYSPACE} \
--csvInput=${GCP_INPUT_CSV} \
--project=${GCP_PROJECT_ID} \
--runner=DataflowRunner \
--region=us-central1"astra db cqlsh demo \
-k samples_dataflow \
-e "SELECT * FROM languages LIMIT 10;"
We assume that you have already executed pipeline described in 3.1 and that gloud is set up.
export ASTRA_KEYSPACE=samples_dataflow
export ASTRA_SECRET_TOKEN=projects/747469159044/secrets/astra-token/versions/2
export ASTRA_SECRET_SECURE_BUNDLE=projects/747469159044/secrets/secure-connect-bundle-demo/versions/1
export GCP_PROJECT_ID=integrations-379317gsutil mb -c STANDARD -l US gs://astra_dataflow_outputs
export GCP_OUTPUT_CSV=gs://astra_dataflow_outputscd samples-dataflow
pwd mvn compile exec:java \
-Dexec.mainClass=com.datastax.astra.dataflow.AstraDb_To_Gcs \
-Dexec.args="\
--astraToken=projects/747469159044/secrets/astra-token/versions/2 \
--astraSecureConnectBundle=projects/747469159044/secrets/secure-connect-bundle-demo/versions/1 \
--keyspace=samples_dataflow \
--table=languages \
--outputFolder=gs://astra_dataflow_output \
--runner=DataflowRunner \
--project=integrations-379317 \
--region=us-central1"
⚠ Prerequisites: - To setup the gcp project please follows setups in `3.1`
cd samples-dataflow
pwdexport ASTRA_KEYSPACE=samples_dataflow
export ASTRA_SECRET_TOKEN=projects/747469159044/secrets/astra-token/versions/2
export ASTRA_SECRET_SECURE_BUNDLE=projects/747469159044/secrets/secure-connect-bundle-demo/versions/1
export GCP_OUTPUT_CSV=gs://astra_dataflow_outputs/csv/language-codes.csv
export GCP_PROJECT_ID=integrations-379317export GCP_BIGQUERY_DATASET=dataflow_input_us
bq mk ${GCP_BIGQUERY_DATASET}
bq ls --format=pretty3.3.4 - ✅ Create a json schema_language_codes.json file with the schema of the table** We have created it for you here
[
{
"mode": "REQUIRED",
"name": "code",
"type": "STRING"
},
{
"mode": "REQUIRED",
"name": "language",
"type": "STRING"
}
]export GCP_BIGQUERY_TABLE=destination
bq mk --table --schema src/main/resources/schema_language_codes.json ${GCP_BIGQUERY_DATASET}.${GCP_BIGQUERY_TABLE}bq ls --format=pretty ${GCP_PROJECT_ID}:${GCP_BIGQUERY_DATASET}bq show --schema --format=prettyjson ${GCP_PROJECT_ID}:${GCP_BIGQUERY_DATASET}.${GCP_BIGQUERY_TABLE}mvn compile exec:java \
-Dexec.mainClass=com.datastax.astra.dataflow.AstraDb_To_BigQuery \
-Dexec.args="\
--astraToken=${ASTRA_SECRET_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SECRET_SECURE_BUNDLE} \
--keyspace=samples_dataflow \
--table=languages \
--bigQueryDataset=${GCP_BIGQUERY_DATASET} \
--bigQueryTable=${GCP_BIGQUERY_TABLE} \
--runner=DataflowRunner \
--project=${GCP_PROJECT_ID} \
--region=us-central1"bq head -n 10 ${GCP_BIGQUERY_DATASET}.${GCP_BIGQUERY_TABLE}
⚠ Prerequisites: - To setup the gcp project please follows setups in `3.1` - To have the BigQuery table populated follows steps in `3.3`
cd samples-dataflow
pwdReplace with values coming from your gcp project.
The destination table has been created in flow 3.3
export ASTRA_KEYSPACE=samples_dataflow
export ASTRA_SECRET_TOKEN=projects/747469159044/secrets/astra-token/versions/2
export ASTRA_SECRET_SECURE_BUNDLE=projects/747469159044/secrets/secure-connect-bundle-demo/versions/1
export GCP_PROJECT_ID=integrations-379317
export GCP_BIGQUERY_DATASET=dataflow_input_us
export GCP_BIGQUERY_TABLE=destinationastra db cqlsh demo \
-k ${ASTRA_KEYSPACE} \
-e "TRUNCATE languages;"mvn compile exec:java \
-Dexec.mainClass=com.datastax.astra.dataflow.BigQuery_To_AstraDb \
-Dexec.args="\
--astraToken=${ASTRA_SECRET_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SECRET_SECURE_BUNDLE} \
--keyspace=samples_dataflow \
--bigQueryDataset=${GCP_BIGQUERY_DATASET} \
--bigQueryTable=${GCP_BIGQUERY_TABLE} \
--runner=DataflowRunner \
--project=${GCP_PROJECT_ID} \
--region=us-central1"astra db cqlsh demo \
-k ${ASTRA_KEYSPACE} \
-e "select * FROM languages LIMIT 10;"
⚠ Prerequisites: - To setup the gcp project please follows setups in `3.1`
cd samples-dataflow
pwdWe assume the table languages exists and has been populated in 3.1
export ASTRA_SECRET_TOKEN=projects/747469159044/secrets/astra-token/versions/2
export ASTRA_SECRET_SECURE_BUNDLE=projects/747469159044/secrets/secure-connect-bundle-demo/versions/1
export ASTRA_KEYSPACE=samples_dataflow
export ASTRA_TABLE=languages
export GCP_PROJECT_ID=integrations-379317mvn compile exec:java \
-Dexec.mainClass=com.datastax.astra.dataflow.AstraDb_To_BigQuery_Dynamic \
-Dexec.args="\
--astraToken=${ASTRA_SECRET_TOKEN} \
--astraSecureConnectBundle=${ASTRA_SECRET_SECURE_BUNDLE} \
--keyspace=${ASTRA_KEYSPACE} \
--table=${ASTRA_TABLE} \
--runner=DataflowRunner \
--project=${GCP_PROJECT_ID} \
--region=us-central1"A dataset with the keyspace name and a table with the table name have been created in BigQuery.
bq head -n 10 ${ASTRA_KEYSPACE}.${ASTRA_TABLE}